W3C | TAG | Agenda | Previous meeting: 3 Feb
teleconf
Minutes of 6-7 Feb 2003 TAG ftf meeting
Irvine, CA
Inside: Administrativa |
Issues review |
Architecture Document
Nearby: IRC log 1 | IRC log 2 | IRC
log 3
Roll call 6 February: Stuart Williams (Chair), Tim Berners-Lee, Dan
Connolly, Chris Lilley, Paul Cotton, David Orchard, Roy Fielding, Ian Jacobs
(Scribe)
Roll call 7 February: Same, with Tim Bray as well.
Regrets: Norm Walsh

The TAG resolved to thank The
Institute for Software Research at the U. of California, Irvine,
and Day Software for hosting this
meeting.
- Mailing list usage
- Tracking action items
- Planning for 2003
Also addressed:
- Approved 27 Jan
minutes
- Next meeting: 17 February. Norm Walsh will Chair; IJ will work with NW
on agenda for 17 and 24 Feb meetings.
- Discuss PC/TB action regarding namespaceDocument-8
- Re-confirmed Stuart Williams as Co-Chair
- Same teleconference time.
- Face-to-face meetings:
- Resolved May in Budapest: 21
(afternoon), 22, 23 (morning)
Action PC: Talk to meeting planners
about this schedule (noting that it overlaps with W3C track so there
may be absences).
- Resolved July in Vancouver: 21
(afternoon), 22, 23. Likely regrets DC for 21 July.:
- Proposed November in Japan: 14-15
Action IJ: Talk to Nov AC meeting
planners to see if 14-15 ok for TAG meeting.
Completed action items:
The TAG discussed the volume of mail on www-tag and agreed that it needs
to managed discussion more effectively. The TAG focused on ensuring that
subscribers are aware of the mailing list policy (see related tips for getting the TAG's
attention).
- [Ian]
- TBL: Need to remind people more often what list policy is.
- PC: We need to manage discussion more.
- DC: Whoever owns an issue should manage discussion; if we don't have
an owner for an issue, that is info. If someone says "change x to y" in
the arch doc, I'd like to see response from the editor straight away.
We will get higher quality comments on the doc if we encourage comments
and respond appropriately to them.
- [Discussion of separate comments list for spec.]
- CL: I'd rather comments be sent to www-tag. Monthly reminder to
people how to use www-tag.
- DC: Comments that are not about an issue and not about the arch doc
are out of order. I need owners of issues to, say, moderate
discussion.
- Action SW: Send draft mailing list policy
to tag@w3.org.
- Summarizing thoughts on policy:
- Please refer to issue number in subject line.
- Please indicate whether you are raising a new issue; TAG does not
guarantee will be taken up.
- Please send text for the arch doc.
- PC: Need to give feedback to the list to make sure discussion goes in
a direction that is useful to us.
- TBL: Refurbish the idea of issue owner (who moderates discussion)
- PC: When new issues are brought up, need to do a better job of
getting on agenda, and closing thread quickly if we are not
interested.
- DC: Not responding is better. if the threads get out of control, I
expect the Chair to do something.
- IJ: Start mailing list policy by looking at what's already on home
page; then we'll just update that; then send out monthly reminder.
- SW: I'd like to have a single action item list.
- DC: Action items falling on the floor is part of life. If someone
forgot to carry an action item forward then that's life; if we forgot
then it must not have been that important
- [Ian]
DC: Infoworld
article on top technologies referred to GET in Web Services. I am
pleased that somebody noticed this.
PC: We have a goal of going to last call (arch doc) mid-year (per 6 Jan 2003
minutes).
- DC: I'd rather revisit that at the end of the meeting.
- PC: Our ftf meeting schedule should take our milestones into account
(e.g., we close document at summer meeting).
Technical Plenary planning
- PC: DO, PC think the TAG session should be technical. However, JD
thinks we will be bombarded with process-like questions.
- Role of TAG (10 mins)
- Architecture Document (15 mins)
- Three issues, with discussion (60 mins)
- BOFs at lunch..
- PC: Others on planning committee suggested walk-through of arch
doc.
- RF: I will try to arrange to be in Boston on 5 March
- PC: Proposed issues - 29, 8, 32
- DO: I pushed back on discussing xlink issue.
- TBL: I'd like to get WGs involved in the discussion, where they have
real-life issues. I'd like to connect with people in WGs: E.g, for
namespace doc, show three slides of pros and cons, then ask for
comments.
- DO: I'd like to have pros/cons for each one.
- DC: 29/32 are pretty close.
- DC: How about a protocol issue?
- PC: Steve Zilles has agreed to moderate the session.
- DC: I'd prefer HTTPSubstrate-16 to 29. I'd (reluctantly) be willing
to present. I endorse IRIEverywhere
- PC: I'd like to know, by the end of this meeting, who will lead
discussion of each part of the presentation.
The following discussion about the Tech Plenary took place on 7
Feb:
- Three issues, overview of arch doc, relationship of TAG to
community.
- CL: issue 32
- PC: Issue 8
- NW (not confirmed: 29
- DC: Walk-through of arch doc.
- TBL: Role of the TAG (10 mins).
- Action PC: Report this plan to the tech
plenary planning committee.
The TAG walked through its Issues list, updating issue
"owners" and reviewing pending actions.
rdfmsQnameUriMapping-6 : Algorithm for
creating a URI from a QName?
Issue
rdfmsQnameUriMapping-6
- [Ian]
DC: The XML Schema WG released a requirements doc for XML Scheme
1.1. They have accepted as a "desideratum" (not a requirement) to make
URI names for schema components. That's not acceptable to me. We need
more than that.
- SW: Will these be HTTP URIs?
- DC: It's not relevant.
- See 2.5.1.1
First class objects (RQ-23): "Define an algorithm for generating a
URI for any construct in a schema (or, possibly, in a schema document),
thus making schema constructs first-class objects in the Web. Minimally
the algorithm should cover element( type)s, attributes, simple types,
complex types, and notations. Optionally it may also cover other
constructs such as named groups and items in enumerations of legal
values."
- SW: Who owns issue 6? TB indicated, but last issue was for DC.
- DC: I'm willing to take this up, and that we contact the Schema WG
and tell them that the desideratum is insufficient.
- RF: Is it really the Schema WG's job? Or more general?
- TBL: What the Schema WG does has an impact on a lot of users (of
schemas).
- DO: This is starting to come up in Web Services.
- PC: See "XML Schema: Component
Designators", which I think speaks
to RQ-23. We should look at current status of "XML Schema: Component
Designators" as well as requirements doc.
- ActionDC:
propose TAG response to XML Schema desideratum (RQ-23)
Issue
whenToUseGet-7
- [Ian]
- [DO comments on WSDL 1.1]
- DO: WG had, I think, forgotten the part about mapping from (WSDL)
"parts" to URIs. I reminded them. This is now part of their
requirements (see WSDL requirement 128 in CVS
version of requirements document 22 Jan 2003 draft).
- DC: When I last looked at WSDL, I thought that when you did binding,
you could map to GET. But seems most useful, when person is making
interface, that they could state a preference for GET. I have seen
failure modes when people think at the wrong moment of the design
process. It would be useful for me if DO sent details about state of
WSDL.
- Action DO: Report on status of WSDL
requirements doc.
- DC: It's worth it for me to keep a queue open, and look at their spec
when it's done.
- Action IJ: Fix issues list to show that
actions/pending are orthogonal to decisions.
Issue
namespaceDocument-8
Previous actions:
- namespaceDocument-8 : PC, TB 2003/01/13: Write up a Working Draft that recommends
a data format for namespace docs (not compulsory) and that such a
document should follow the Rec track process. The initial content of
the document should be taken from the RDDL challenge proposals; they
are isomorphic in technical content. Please include drawbacks in the
draft.
- [Ian]
- PC: TB and I have an action pending on this:
- PC: Please put on TAG agenda for 17 Feb
Issue
uriMediaType-9
- [Ian]
- DC: TAG did a finding; we asked IETF; we had liaison blunders; we did
an Internet
draft; Mark Baker and I had not addressed some feedback from Larry
Masinter.
- DC: So we updated the appendix. That is issued as an Internet
draft.
- DC: We've not called for discussion on www-tag.
- DC: There are several paths to take at this point.
- http://www.markbaker.ca/2002/09/draft-w3c-accessible-registries-00.txt
- RF: IANA won't do anything unless it's an RFC. We could make an
addendum to the media type registration process, and put through IETF
group.
- DC: I just want to ask for a policy statement that they won't break
their Web space. The proposal says that they will give 1 year notice
given, etc.
- RF: Problem is IANA has no leader, and not aware of WG doing work in
this area.
- DC: looks like discussion in discuss@apps.ietf.org is critical path.
I want to start discussion when I have bandwidth to deal with it.
- Action DC: Start discussion on
discuss@apps.ietf.org, but not urgent.
Issue
mixedNamespaceMeaning-13
The TAG resolved to split this issue into three smaller issues.
- [Ian]
CL: I've written some text on this.: I think this is an umbrella
issue and that we would do well to attack smaller pieces. We already
have agreement on subsumed bits.
- DC: I don't feel obliged to answer it. There is no general purpose
solution for how to compose things.
- TBL: There are two crying needs (1) to be able to mix xforms, svg,
math, xhtml ....
- [Discussion of some embedding issues]
- TBL: In the area of graphics, I'd like to see schema used to express
these constraints. Second problem is, e.g., how do you introduce
something like encryption. I think that we need to at least point to
questions that need to be addressed by a WG.
- DC: Please replace 13 with three issues: (1) One issue with mixing
some known specs (2) One issue on encryption (3) Maybe RDF in HTML as
third issue.
- CL proposed: "Composability for user interface-oriented XML
namespaces", mixingUIXMLns-33
- [Chris]
- xmlTransformations-34
- [Ian]
- CL proposed: "XML functions: Encryption, XSLT, XInclude and other XML
transformations"
- [Discussion of RDF in HTML]
- [Chris]
- [and RDF in SVG]
- [Ian]
- change xmlTransformations -> xmlFunctions
- TBL Proposed: RDFinHTML-35, "Syntax and semantics for embedding RDF
in HTML." [SVG, MathML, SMIL, HTML]
- Resolved: Accept mixedUIXMLNamespace-33
"Composability for user interface-oriented XML namespaces", owner
CL
- TBL for second one: "Specifying languages (e.g., encryption, xslt,
xinclude) which operate in the context of other arbitrary languages and
affect their processing."
- PC: Is this work for Core?
- TBL: Perhaps. But I don't like talking about processing model; I like
to talk about what things mean. What is common among these things is
that they stand for some function of their contents, not their
contents. XSLT, etc. have the common property of having to be
elaborated first.
- [Roy]
- The effect of intermediate XML processing on namespace semantics?
- [Ian]
- TBL: There is a default processing model (and only one that makes
sense).
- [Chris]
- I note as important that TimBL just said that XMLFunc is a
default processing model so an external processing
pipeline language could override it
- so XMLFunc is about what happens with no other information
- [Ian]
- PC: "Transformation and composability (e.g., XSLT, XInclude,
Encryption"
- Proposed: xmlFunctions-##, "Transformation and composability (e.g.,
XSLT, XInclude, Encryption)", owner TBL
- SW: I would like to assign an action to get a crisp articulation of
the problem before we accept the issue.
- DO: What is our expected deliverable ? What happens to frag ids in
this situation?
- TBL, DC: That question seems in scope to me.
- Resolved: Accept xmlFunctions-##,
"Transformation and composability (e.g., XSLT, XInclude, Encryption)",
owner TBL
- Action TBL: Please crisply state the
issue with a reference to XML Core work. Deadline 17 Feb.
- Proposed: RDFinHTML-35, "Syntax and semantics for embedding RDF in
XHTML."
- DC: I have to address this elsewhere. Ok by me if TAG does not
accept.
- DC Proposed: RDFinHTML-35, "Syntax and semantics for embedding RDF in
XHTML." To address, e.g., whether someone is accountable for RDF
statements made inside an HTML document.
- TBL: Is the RDF ignorable in an HTML document?
- PC: I think that's a good question. I think DC is hypothesizing that
nobody is currently answering this question.
- RF: "RDF semantics in HTML" is the issue then.
- [Chris]
- how is that different from "whether someone is accountable for RDF
statements"
- [DanC_jam]
- re how different: I didn't intend it to be different
- [Ian]
- Resolved: Accept RDFinHTML-35, "Syntax
and semantics for embedding RDF in XHTML." Owner: DC (with low
expectations).
- Action DC: Write up a crisp articulation
of issue RDFINHTML-35. [DC says - don't expect results before May 2003
meeting]
- Proposed: Replace mixedNamespaceMeaning-13, explaining that we
identified three subissues (may be others) and that initial issue was
deemed to large.
- Resolved: Replace
mixedNamespaceMeaning-13, explaining that we identified three subissues
(may be others) and that initial issue was deemed to large.
- Action SW: Report to www-tag on
disposition of this issue. Deadline 13 Feb.
Issue
HTTPSubstrate-16
- [Ian]
- RF: I agree with RFC
3205. Does anyone disagree?
- Summarizing issue: For each application, use a different
port.
- RF: The RFC is about recommended practice for IETF docs (not whether
the battle has already been lost since, e.g., one can do TCP/IP over
HTTP...).
- TBL: Suppose I publish Ical using HTTP. It is very very useful to
serve the same data in different contexts, or to have very different
data over the same port.
- RF: Keith is talking about using HTTP for presence protocols, e.g.
IPP is an awful protocol; should have been HTTP. IPP doesn't use HTTP
(violation or arch principle); uses a POST.
- CL: If you are getting the status of a printer, use GET. If you are
sending data to a printer, use POST.
- DC: We could phrase a question to the editor (e.g., a SOAP
scenario).
- TBL: I'd like to point out that reuse of HTTP is a good thing. Reuse
for many types of clients and data is a good thing.: We could say that
we fear that the tone of the document suggests otherwise. If the
document is meant to criticize tunneling one protocol over another,
then it should say so.
- See original
mail from RF: "After spending another night trying to figure out
what we would like to say in regard to RFC 3205, I am ready to declare
this as a "waste of time"."
- TBL: I am dissatisfied with simply sweeping under the rung.
- RF: Please tell me what to say and I'll send it to them.
- DC: What's an example of a well-designed Web service?
DO: Purchase orders.
- DC: How about SOAP primer example?
Action RF: Write a response to IESG asking
whether the Web services example in the SOAP 1.2 primer is intended to
be excluded from RFC 3205.
Issue
errorHandling-20
- [Ian]
- CL: The QAWG has marked up this issue as "solved"; see their guideline
7 in the QA Framework.
- [Chris]
- related: http://www.w3.org/TR/SVG11/implnote.html#ErrorProcessing
- [Ian]
- PC: But QAWG resolution is about deprecation, not error-handling.
- DC: Silent failures are evil.
- CL: Depends on what you define as an error. E.g., is it an error if
you have an invalid HTML file?
- DC: What are you doing with it?
- CL: Once you've decided you've got an error, you're all set. But
deciding is the hard part.
- PC: I think that this issue was raised essentially in the QAWG and
that they've closed it for themselves. We could read their proposed
resolution and see whether we agree.
- CL: Don't fix things silently; people come to rely on a particular
type of correction (that's not part of a spec).
- [Chris]
- "I'd like to request that the TAG come up with generalized guidance
on the appropriateness of error recovery in web software." It all
depends on how you define an error. It relates to composability, and to
validation. The person raising the issue is asking for guidance for
writers of specifications.
- [Ian]
- DC: Where could we put info from finding on Mime type finding on
interpretation in arch doc?
- [Discussion about where in arch doc.]
- [Chris]
- conflict between "strict generate/loose accept" and the general
failure of that paradigm
- [Ian]
- PC: This is the conflict between xpath and xquery. Most xquery people
want static type-checking. Most xpath 1.0 people want to allow
flexibility in what they want xpath to work over. People should at
least be conscious of the trade-off.
- [Chris]
- other people should define classes of error. scope for tag finding on
handling of errors once identified (such as silent recovery and fixup
being bad)
- [Ian]
- DC: I just want to take a piece of the finding and find a place to
put it in the arch doc.
- Action CL: Write a draft finding
(deadline 1 month) on the topic of (1) early/late detection of errors
(2) late/early binding (3) robustness (4) definition of errors (5)
recovery once error has been signaled. Deadline first week of
March.
Issue
xlinkScope-23
- [Chris]
- everyone should use it once it has been rewritten and got through a
much stricter CR ;-)
- [Ian]
- SW: I am confirmed as owner of this issue.
- DC: Next discussion at tech plenary.
- PC: Lunchtime BOF.
- SW: Should we reconfirm our position from Sep 2002?
- [Not for today]
Issue
contentTypeOverride-24
- [Chris]
- A URI reference may be accompanied by a media type that indicates the
content type of the resource identified by the URI. When specified,
this type value takes precedence over other possible sources of the
media type (for instance, the "Content-type" field in an HTTP exchange,
or the file extension). The exception to this behavior is that when the
protocol indicates a media type that is known by the grammar processor
as a grammar format type then the media type in
- Informative: use of the type attribute should be considered a last
resort. For instance, the type may be appropriate when a grammar is
fetched via HTTP but (1) a web server cannot be configured to indicate
the correct media type, and (2) the grammar processor is unable to
automatically detect the media type.
From "Speech
Recognition Grammar Specification Version 1.0,: section 2.2.2.
- [Ian]
- CL: Some specs have attributes that are advisory only (e.g., likely
media type). This seems different; sounds like an override; "don't
believe the server."
- RF: If you were able to do this with an applet, it would be a
security hole. But for this particular problem they are trying to
solve, may not be.
- CL: But it may not be a good idea, either.
- [TAG notes that this spec is still as CR.]
- CL: TAG should tell this WG that they shouldn't try to do this sort
of thing.
- SW: Owner?
- DC: I endorse such a comment "don't do this."
- IJ, noting in section 2.2.2 of same specification: "*the* content
type" is problematic.
- DC: What the server sends back is the authoritative media type.
- RF: When client expectation is different from media type from server,
there should be a user interrupt where the user can override the
behavior. It's reasonable to allow the user to override an error; it's
unreasonable to override automatically.
- DC: Another example of silent recovery from error being harmful.
- Action DC: Send an email to the Voice WG
that third para of 2.2.2 CR of Speech Recognition Grammar Spec is wrong
regarding override of media type.
- CL: I will then propose to the TAG to adopt that position.
The following minutes are from 7 February.
Issue
contentPresentation-26
- Action CL: Create a draft finding in this
space. Deadline 3 March.
Issue
IRIEverywhere-27
Previous actions:
- [Ian]
- CL: There is movement here; Martin commented on CL / IJ draft.
Interrelated with URIEquivalence. Decision there affects IRIEquivalence.
I had a proposal, but discussion happening and consensus shifting.
- Action CL: post document to www-tag, with
notation that MD doesn't agree.
Issues fragmentInXML-28
and xmlIDSemantics-32
- [Ian]
TB: I think they are related. If you are solving the ID problem,
you need to also decide how to solve the frag id problem.
PC: I am willing to be owner of 32
- On xmlProfiles-29
- PC: Henry Thompson asks what the TAG wants to happen. They are
looking for more details than we have given them.
- DC: Liam Quin has the ball on this; he has accepted this.
Issue
binaryXML-30
Previous actions:
- [Ian]
(for XML ID, see msg
from CL to tag)
- CL: I wrote up stuff for TAG, processing input on it.
- TB: Is there a sense that W3C should do something in this space?
- CL: There are issues, e.g., streaming (been demonstrated). BIM is
patent-encumbered.
- TB: I am not favorable to W3C doing work in this area.
- DC: We should publish what we've done.
- Action CL: Write up this work on binary
XML.
Issue
metadataInURI-31
- Action SW: Draft finding for this one.
Issue
deepLinking-25
See Tim Bray's
draft finding
- [Ian]
DC: I have some questions on how to compare URIs. I want to tell
people that if they use strcmp that they can get the right answer.
- TB: It's clear that strcmp won't produce a false positive, but may
produce some false negatives, but that's ok for some apps. People feel
that appropriate place for this material is RFC2396
- Action TB: Send URI equiv draft finding
to uri@w3.org.
- Resolved: Accept Tim Bray's draft
finding on deep linking.
- Action IJ: Publish Deep Linking finding
as accepted finding.
Issue
URIEquivalence-15
Previous action items:
- TBL 2003/01/20: Send email to uri@w3.org requesting
terminology change (regarding definition of "URI").
Dan Connolly did a slide presentation on some issues related to URI
comparison.
- [timbl]
- Clients should only assume foo and foo/ are equiv when redot
occurs
- [Ian]
- DC: Redirection [Slide on information hiding]
- TBL: We should say here "Don't do this!" ; there's a high cost to
reserved names here.
- TB: robots.txt has problems; could have been done lots better.
- [timbl]
- We should actually look at a a technical solution to the robots.txt
problem in future, and even think of transitioning
- [Ian]
- TB: Two things should happen:
- I should take several things from DC's slides and give a
different takeaway message to thefinding on URI
Equivalence.
- DC should dress up your slides and publish it as a service to the
world.
Action DC: Publish slides on URI
Equivalence.
- TBL: You can look at 2 URIs some times and sometimes tell they are
equivalent; you can never tell (just by looking at the URIs) that they
are different
- TBL (on robots.txt): If this is bad, should we invest time into
asking some group to do it properly. A generic hook for putting site
metadata on a header.
- RF: It's a design trade-off. Latency with every GET, or reserved
space to look for information.
- Action TBL: Write up a proposal for a new
issue regarding generic metadata hooks (related to robots.txt).
Previous actions:
- CL 2002/09/25: Redraft section 3 based on resolutions of 18 Nov 2002 ftf
meeting.
- DC 2003/01/27: write two pages on correct and
incorrect application of REST to an actual web page design
- DO 2003/01/27: Please send writings on Web services to
tag@w3.org. DO grants DC license to cut and paste and put into DC
writing.
- CL 2003/01/27: Draft language for arch doc
that takes language from Internet media type registration, propose for
arch doc, include sentiment of TB's second sentence from CP10.
Reference draft is 12 December 2002
Editor's draft, but we also discussed 6 Feb 2003 Editor's
Draft with changes from CL.
- General comments about the architecture
document
- URIs, Resources, Identification
(httpRange-14)
- Arch Doc Scheduling
- Review of text from Chris Lilley on content and
protocols
- Review of comments from Tim Bray
- [Ian]
- SW: I like the structure of the document; but I don't think this
document tells me what the architecture of the Web is. Could talk more
about people building on top of the platform that is the Web. I'd like
a conceptual model to be presented up front. We get into good practice
without establishing the model . I'd like the doc to be as short as
possible, with links out to more info.
- TBL: The style of the doc is close to what I think is reasonable. We
spend a lot of time talking about nuggets, but have as a goal to
produce an all-encompassing work. We should allow ourselves to produce
a document that is uneven. I think that we should assume that the
reader knows a fair amount about the Web. We should use terms
consistently, but we needn't be overly formal. If we want to be formal,
doing a mathematical ontology would be unbelievably useful, but I see
that as something separate. The document is morphing slowly; I don't
know when to read it. HTTPRange-14 has become a discussion between me
and Roy. I think that if we come up with a consistent story, people
will probably go along with that.
- RF: I think we need to ensure that we are using the terms
consistently.
- TB: I think I would like the doc to be thin and consist of bald
statements ("this is the way it is") with examples in the document.
Whenever you need historical exegesis, good place for a finding. Still
need to clear up principle v. constraint v. choice. Need to clean up or
throw out. Pace has been unsatisfactory over last 4 months. I'm
unlikely to use CVS; Happy to use Ian as a single point of editing.
- CL: I'm getting more comfortable since I've started editing.
- PC: I don't have many concerns right now. What is public perception
of the document?
- TB: We haven't had much feedback.
- PC: I don't know whether we're doing enough to get people to comment
on this document. Do we really expect to go to last call in 5 months?
We have to have real targets about what we want in the document at last
call .For last call, this document has to describe the Web as it is
today. I'm not convinced we have to describe the Web of the future in v
1.0.
- TBL: We need to make clear in status of this document that we don't
expect to be done in v 1.0.
- PC: We need to agree to the scope of v 1.0.
- CL: We need to make clear whether we are following, e.g., the Process
Doc model or model of a technical spec.
- RF: I'd like to add more scenarios and more background. I think we
need to do a better job explaining the framework. I can deal with
people using different terms; but not happy with people using same
terms differently. I would prefer to have an agreed upon TAG /
attribute mechanism so I can edit in place.
- Action IJ: Explain how TAG participants
can edit the source of the arch document.
- DO: To me, a lot of things are missing about the Web architecture. We
don't say what we mean by an architecture. There are things like data,
connectors, etc. in RF's thesis. Those are useful; I'd like to be able
to relate WSA to Web Arch via this framework. E.g., definition of
"agent" used in arch doc caused criticism of term in WSA community.
- [DanC_jam]
- (odd... I see those things [constraints, etc.] in our arch doc.)
- [Ian]
- DO: Clearer glossary terms
- PC to DO: Should arch doc be limited to Web today or Web with Web
services?
- DO: Let's discuss later. We need treatment in other areas than URIs.
E.g., architecture of XML.
DC: I'm invested in arch doc up to 2.1. Swimming in rest of 2. Not
much opinion of rest of doc. Process has been sort of ok for me. I
don't understand why there are pent up comments; people should send
text. On the challenge of brevity v. understandability; I see that what
we are doing is having some effect. Probably ok with terse prose and
elaboration elsewhere. In many cases, I find that rationale is
economic, not logical. That's ok. There are a few cases where the
principle is something I agree with, but not expressed exactly
correctly .Often problematic in quantifiers. I owe text on this.
Diagrams would be nice. I'd like to see more discussion of the text
that we've got.
- RF: I'd like to get all of us writing into the document. Fine to have
10x the text, and then reduce it from there.
- RF: I have affinity for the section on interactions, but not as it
stands.
Issue
httpRange-14
DC's original image on the white board:
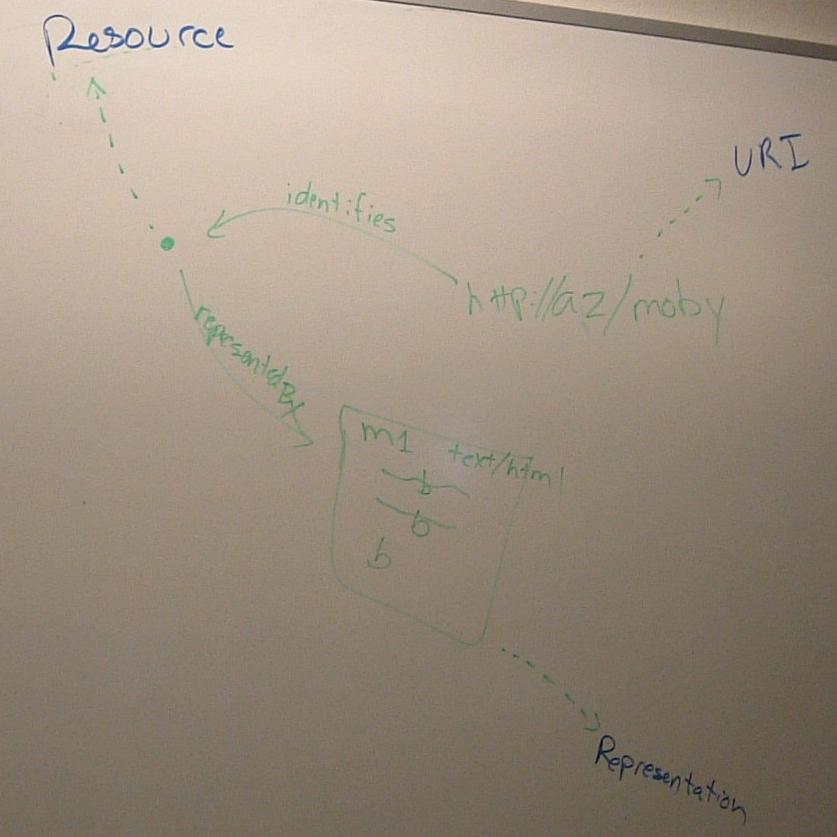
DC in action trying to build consensus around httpRange-14:

White board after remodeling by TBL:
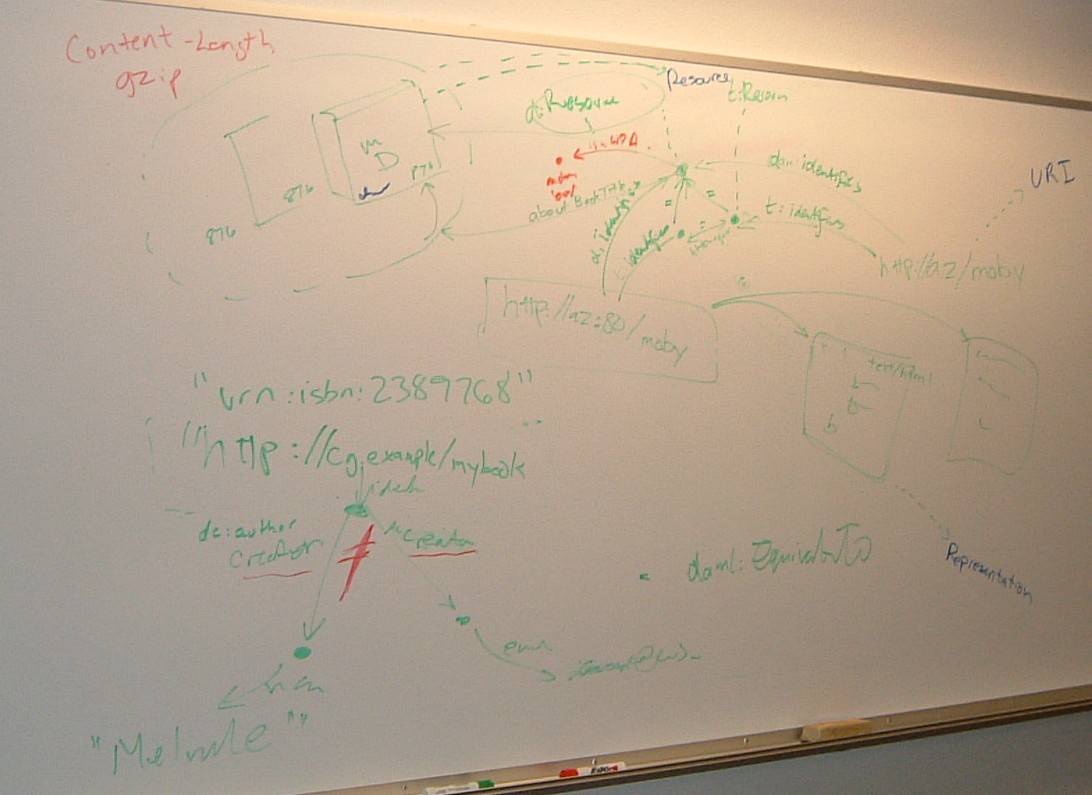
- Discussion of terms:
- URI ----Identifies---> Resource
- Resource ----RepresentedBy----> bag of bits + media type
- Representation includes bits and other metadata about the
representation
- RF: I note that Content-Length is implemented inconsistently in user
agents.
- TBL: Web Architecture doesn't tell you whether two resources are the
same. Difference between URI-equivalence and HTTP-equivalence.
- TB: Both DC and TBL are right. We know that moby and moby.html are
quite possibly the same thing in real life. But the Web arch doesn't
have the notion of "same in real life" built in.
- TB: We need to ack the fact that (1) this occurs in real life but
that (2) just by looking at the URI there's no way to tell.
- DC: I don't agree to TBL's constraint that only one URI identifies a
resource and no way to talk about URI-equivalence.
- TB: Web arch doesn't have a built-in relationship "isEquivalentTo"
that applies to multiple URIs.
- TBL: We agree on URIs (as set of bits) and Representations (as set of
bits) since we have machines that can work on them. We don't have
agreement in the abstract realm (Resources). You can't claim that
"resource" is a shared term.
- [Disagreement about identity relationship.]
- DC: To me, the URI spec is a worldwide agreement for a convention for
making up identifiers and how they take on meaning through use. You
share your understanding of their meaning by servicing GET
requests.
- [Discussion of range of "Resource"]
- [Question: Can you use ANY URI to talk about ANY
Resource?]
- TBL: My expectation is for consistent information about a resource
from one representation to the next. What keeps the Web working is that
the form of identity is that representations for a resource continue to
convey the same information.
- PC: I think DC's original diagram should be included in arch doc. I
still haven't heard pros and cons of TBL's model v. DC's model.
- TBL: Problem with DC model is that when you have a URI for a real
book, you can get two inconsistent DC:Creator assertions for the same
URI (either email address of person who created page about the book v.
Herman Melville).
- [RF writes "urn:isbn:2389768" on the white board]
- TBL: Following the specs can lead to an inconsistency.
- RF:
DC:Creator specifically refers to the creator of the
representation.: DC:Author is another identifiers
- [DC moves to reopen issue HTTPRange-14 for a variety of
reasons.]
- DC: I think an arch doc that addresses knowledge representation is a
valuable asset; I would like to spend my time there.
- DO: I'd prefer to not reopen this issue.
- PC: I'd rather not reopen.
- PC: The second diagram may be a refinement of the first diagram
(DC's) but we can do that later.
- TBL: I'm not trying to go down path of KR, just trying to use terms
precisely. Without getting the diagram nailed down, we will not have a
precise definition of these terms.
- RF: WSA does need to verify that HTTP URIs don't always refer to
documents.
- For - 4, Against - 3, Abstain 1
- [DanC_jam]
- Resolved to reopen issue
HTTPRange-14.
- [Ian]
- RF: I don't think we will have a document in July unless we resolve
this issue.
- TBL: I have a hard time contributing to the document without clear
term usage.
- SW: I think we have to agree to a foundation model and put it up
front in document.
- SW: Does CR period make sense? I think we should see, e.g., whether
we help two WGs get to Rec.
6 Feb 2003
Editor's Draft
- [Ian]
" 1. An Internet Media Type, which may include optional or
mandatory parameters"
- TB: I disagree with this. There are other parameters. Does Internet
media type include charset, etc.?
- DC: I'd feel better with citation of the relevant spec.
- RF: The whole first paragraph is bogus.
- TB: Do we consider that representation includes just data, or just
media type header, or all headers....?
- From HTTP 1.1 spec
definition of "representation": An entity included with a response that
is subject to content
- negotiation, as described in section 12. There may exist multiple
representations associated with a particular response status."
- RF: Representation is data and metadata.
- TB: Representation = body + one or more headers that are included in
the message response (but not part of body).
- TBL: Mime type is particularly important since determines how to
interpret bag of bits.
- [Chris]
- the representation is payload in the message
- current text assumes a one way server to client delivery, need to
widen to include sending *to* the server
- metadata is more stuff than just the media type
- eg content transfer encoding
- draw attention to the media type as a fundamental part of the
metadata
- metadata in the body (eg rdf in html) is not being considered
here
- .... or is it (html meta http-equiv stuff)
- rrsagent, pointer?
- [RRSAgent]
- See http://www.w3.org/2003/02/07-tagmem-irc#T22-44-20
- [Ian]
- TBL: Some parts of an HTTP header are not part of a
representation
- DC: E.g., Date.
- CL: Slicing half of the headers as being in or out of the
representation is a pain.
- DC: That's part of life as we know it. "Not modified' means previous
representation not modified. But the transfer metadata can change.
- TB: I think I agree with CL. From the perspective of agents, I have
access to all headers and status. In principle and practice, this is
information that is available to the agent. It doesn't seem to me to be
harmful to dispatch processing based on, e.g., transfer encoding.
Furthermore, other headers will be invented. I propose that we assert
that the representation is data + all metadata.
- [DO distinguishes metadata about content from metadata about the
message.]
- DO: I would like to distinguish message from representation in the
arch doc.
- RF: Representation defined this way so that it has the same meaning
in both PUT and POST situations. You don't create messages on a server;
you create representations.
- [Chris]
- messages contain representations and other header stuff;
representations contain formats and header stuff
- message metadata and representation metadata
- [Ian]
- RF: We know that that it was a mistake in HTTP to not be able to
distinguish msg metadata from representation data. We would fix that in
the next protocol spec.
- RF proposal: Resource rep consists of metadata about the
representation and data for the representation.
- DO: We need to talk about msgs in the arch doc.
- [Chris]
- message consists of message metadata and representation.
- in http headers the two types of metadata are unfortunately
co-mingled
- [TBray]
- What I think we agreed on (just joined IRC so pardon if
redundant)
- A representation includes some data, e.g.. arbitrary bag of bits,
plus some metadata about the data
- [Chris]
- rrsagent, pointer?
- [RRSAgent]
- See http://www.w3.org/2003/02/07-tagmem-irc#T22-58-35
- [DanC_jam]
- where is "representation data" used, Roy?
- [TBray]
- In the case of HTTP, some of the headers are part of the
representation, e.g. Media-type and Content-length; others are not,
e.g. Date and Content-encoding
- [Chris]
- add diagrams to document
- diagrams reuse existing concepts
- [Ian]
- PC: I'd like to have a diagram, reuse existing definitions, link to
authoritative specs that define these terms.
- DC: "entity" "entity body".
- RF: "representation data" comes from Roy's PhD.
- [DanC_jam]
- I asked whether we intend to import "body" from the MIME spec (RFC
2045) ; the question went unanswered. Lilley said he had sufficient
advice on the matter to produce another draft. Nothing was decided.
- [Chris]
- add +xml to processing model section
- [Ian]
- TB: In section on processing model, include info about following mime
type, support for 3203, xml namespaces....
- [Chris]
- these are properties arising from using xml
- xml as a constraint
- [Ian]
- PC: Main reason to use XML is neutral format for interoperability
- [Chris]
- xml gives interop
- major reason
- [Ian]
- RF: Application-independent at the parser level.
- CL: Facilitates composability.
- [Chris]
- facilitates composability
- xml for interop
- namespaces without schemas
- [Ian]
- PC: namespaces w/o schemas help define parts of xml doc.
- [Chris]
- namespaces with schemas
- [Ian]
- PC: When you add schemas, you get a more powerful definition
language.
- [DaveO]
- for definition purposes, from wsd document: A Message is the basic
unit of communication between a Web Service and a Client; data to be
communicated to or from a Web Service as a single logical
transmission.]
- [Chris]
- well known namespaces confer meaning
- [Ian]
- CL: I try to present things as a continuum.
- TBL: I like "presentation", I don't like abstract/concrete.
- [Chris]
- tim wants me to avoid the term semantics here - great!
- [Ian]
- CL: Need to clarify use of term "interaction": network interaction or
human-computer interaction.
- TB: "Protocol" is heavily overloaded.
- RF: There are multiple architectures of the Web - at the agent level,
at the UI level, etc...
Tim Bray comments refer to 12 December 2002
Editor's draft.
- [Ian]
- TB: Lose distinctions (principles, constraints, etc.)
- IJ: I find three distinctions useful: best practice, design choices,
and axioms ("it is this way"). It's one thing to design the doc with
these things explicitly in mind; another to label them explicitly.
- TB: I'm not convinced that it's valuable to create a taxonomy and
label things in the document according to this taxonomy.
- RF: Useful to distinguish goal, way to get to that goal, and a
property established by making that decision. Allows other communities
to see that, by relaxing a particular constraint, they may lose a
particular goal.
- TBL: I don't find property/goal distinction useful.
- RF: Constraint is "The only identifiers in the Web are URIs." But
arch doc is not expressed that way.
- TB: however, it's useful to instruct in terms of best practice.
- [DanC_jam]
- i.e., "if you're pointing from one thing to another, use URIs". Yes,
that's a constraint.
- [Ian]
- ===
- TB proposal: Delete "Fortunately... " .to end of 2.1.1.
- CL: There are examples there.
- TB: Add an example to the second paragraph to illustrate that
point.
- Proposal: Make third bullet third para and delete the rest.
- TB: The point is that people want to determine that two resources are
the same; not currently part of Web arch; people are working on this.
TBL: I'd like to see the various levels of equivalence stated more
clearly. Please say that you can't tell that two resources different;
but that in some situations you can tell that they are the same.
- TB: I think that's covered elsewhere.
- TBL: The URI draft should not talk about HTTP equivalence.
- TB proposed:
- Move some of DanC's slides to this section (or elsewhere).
- Make bullet 3 its own para
- TB to produce new URI EQ draft, possibly pulling DanC slide
material
- [DanC_jam]
- for ref, take-aways from my presentation: [[
- 1. If you mean the same thing, say it the same way.
- 2. When choosing names for distinct things, choose clearly distinct
names
- 3. Absolute URIs* are the basis of comparison
- * w/optional fragments
- 4. Clients/consumers should not usurp servers'/providers' naming
rights
- ]]
- [Ian]
- 2.2.1 comparing identifiers.
- TB: Propose to shorten this and reference finding. Proposed at
beginning of 2.2: "URIs exist to identify resources. The two operations
that can be performed on them are to compare them and to dereference
them."
- RF: Doesn't google use them for other things? What about "establish
relationships"?
- [DanC_jam]
- changing "The two primary" to "Two primary..." would do it for me.
- [Ian]
- IJ: Primary operations may depend on who is doing what. For author,
"create links". For spec writer, "Define data type", etc.: These are
also operations on URIs that are about Web arch.
- [Chris]
- ok but say 'uri reference' and then you can do a syntax check on it
....
- [Ian]
- IJ: What if we recast this section as "The good thing about the Web
is that there are (at least) two useful things that you can do on a
URI..." I'll take a whack at this (to try to make this less
constraining).
- [timbl]
- Two important operations on URIs are
- [Ian]
- TB: Delete first para of "2.2.4. Consistent representations"
- DC: The para means to say "Whatever you get back from the HTTP Server
is 'correct'" The world has agreed that what you get back is a valid
representation.
- TB: Is there such a thing as an invalid representation?
- [DanC_jam]
- Action DC: attempt a redrafting of 1st
para under 2.2.4
- [Ian]
- IJ: I think we are missing a clear statement of where were are trying
to get by the end of section 2. Why are we talking so much about
meaning/equivalence/identity? What is the value/importance of being
able to say that two resources are the same, or that the meaning of the
resource is such and such?
- SW: That's why we need a conceptual model up front....