The evolution of languages by adding, deleting, or
changing syntax or semantics is called versioning. Making versioning work in
practice is one of the most difficult problems in computing. Arguably,
the Web rose dramatically in popularity because evolution and
versioning were built into HTML and HTTP. Both systems provide
explicit extensibility points and rules for understanding extensions
that enable their decentralized extension and versioning.
This finding describes general problems and techniques in evolving systems in compatible and incompatible ways. These
techniques are designed to allow compatible changes with or without
schema propagation. A number of questions, design patterns and rules
are discussed with a focus towards enabling versioning in XML
vocabularies, making use of XML Namespaces and XML Schema constructs.
This includes not only general rules, but also rules for working with
languages that provide an extensible container model, notably
SOAP.
1.1 Terminology
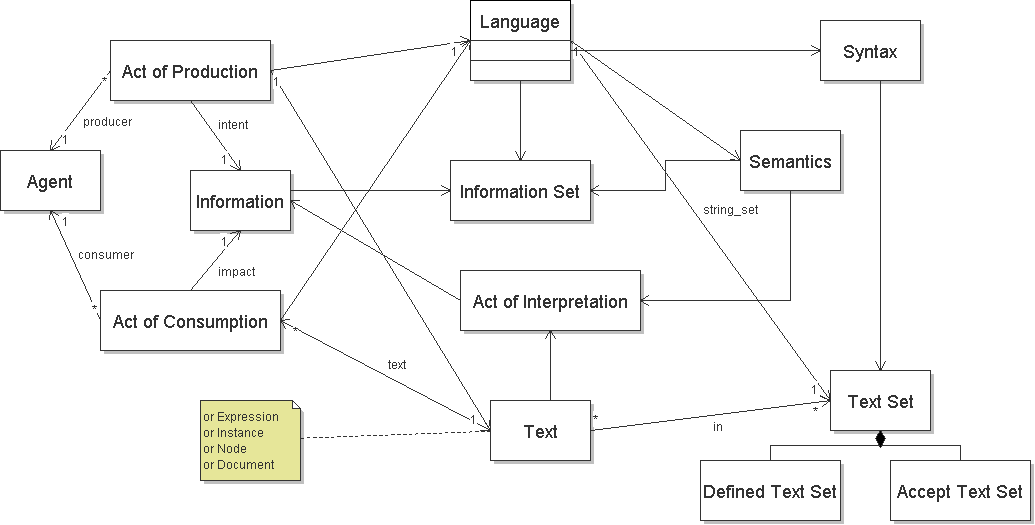
The terminology for describing languages, producers, consumers, information, constraints, syntax, evolvability etc. follows. Let us consider an example. Two or more systems need to exchange name information. Names may not be the perfect choice of example because of internationalization reasons, but it resonates strongly with a very large audience. The Name Language is created to be exchanged.
[Definition: A producer is an agent that creates text. ] Continuing our example, Fred is a producer of Name Language text.
[Definition: An Act of Production is the creation of text.]. A producer produces text for the intent of conveying information. When Fred does the actual creation of the text, that is an act of production. [Definition: A consumer
is an agent that consumes text.] We will use Barney and Wilma as consumers of text.
[Definition: An Act of Consumption is the processing of text of a language.] Wilma and Barney consume the text separately from each other, each of these being a consumption event. A consumer is impacted by the instance that it consumes. That is, it interprets that instance and bases future processing, in part, on the information that it believes was present in that instance. Text can be consumed many times, by many consumers, and have many different impacts.
[Definition: A Language consists of a set of text, any syntactic constraints on the text, a set of information, any semantic constraints on the information, and the mapping between texts and information. ][Definition: Text is a specific, discrete sequence of characters]. Given that there are constraints on a language, any particular text may or may not have membership in a language. Indeed, a particular string of characters may be a member of many languages, and there may be many different strings of characters that are members of a given language. The text of the language are the units of exchange. Documents are texts of a language. The Name Language consists of text set that have 3 terms and specifies syntactic constraints: that a name consists of a given and a family. [Definition: A language has a set of constraints that apply to the set of strings in the language. ] These constraints can be defined in machine processable syntactic constraint languages such as XML Schema, microformats, human readable textual descriptions such as HTML descriptions, or are embodied in software. Languages may or may not be defined by a schema in any particular schema language. The constraints on a language determine the strings that qualify for membership in the language. Vocabulary terms contribute to the set of strings, but they are not the only source of characters to the set of strings in a given language. The language strings may include characters outside of terms, such as punctuation. One reason for additional characters is to distinguish or separate terms, such as whitespace and markup.
<name>
<given>Dave</given>
<family>Orchard</family>
</name>
name="Dave Orchard"
<span class="fn">Dave Orchard</span>
urn:nameschem:given:Dave:family:Orchard
The set of information in a language almost always has semantics. In the Name Language, given and family have the semantics of given and family names of people. The language also has the binding from the items in the information set to the text set. Any potential act of interpretation, that is any consumption or production, conveys information from text according to the language's binding. The language is designed for acts of interpretation, that being the purpose of languages. In our example, this mapping is obvious and trivial, but many languages it is not. Two languages may have the exact same strings but different meanings for them. In general, the intended meaning of a vocabulary term is scoped by the language in which the term is found. However, there is some expectation that terms drawn from a given vocabulary will have a consistent meaning across all languages in which they are used. Confusion often arises when terms have inconsistent meaning across language. The Name terms might be used in other languages, but it is generally expected that they will still be "the same" in some meaningful sense.
These terms and their relationships are shown below
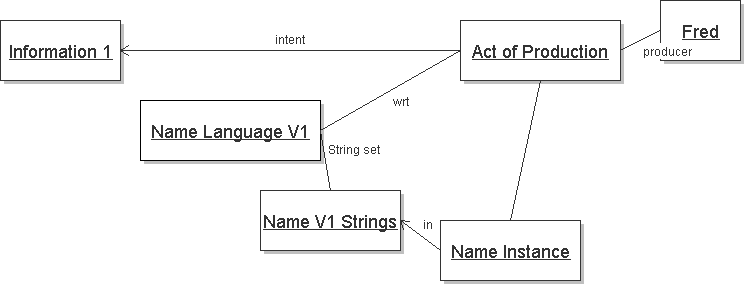
We say that Fred engages in an Act of Production that results a Name Instance with respect to Name Language V1. The Name Instance is in the set of Name V1 Texts, that is the set of strings in the Name Language V1. The production of the Name Instance has the intent of conveying Information, which we call Information 1. This is shown below:
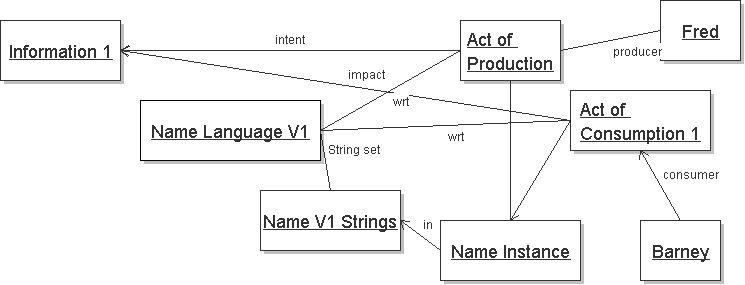
We say that Barney engages in an Act of Consumption of a Name Instance with respect to Name Language V1. The consumption of the Name Instance has the impact of conveying Information 1. This is shown below:
Versioning is an issue that effects almost all applications
eventually. Whether it's a processor styling
documents in batch to produce PDF files, Web services engaged in
financial transactions, HTML browsers, the language and instances will likely change over time. The versioning policies for a language, particularly whether the language is mutable or immutable, should be specified by the language owner. Versioning is closely related to extensibility as extensible languages may allow different versions of instances than those known by the language designer. Applications may receive versions of a
language that they aren't expecting.
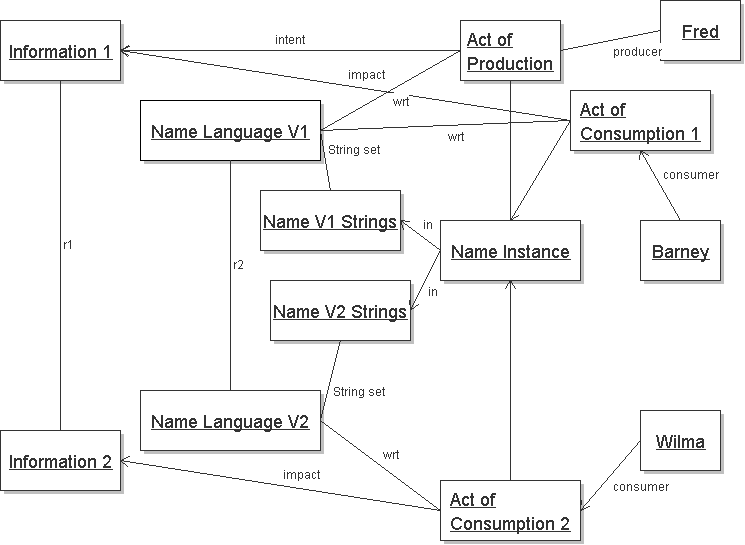
If a Name Language V2 exists, with its set of strings and Information set, Wilma may consume the same Name Instance but with respect to the Name Language V2 and have impact of Information 2. Name Language V2 relates to V1 by relationship r2, which is forwards compatible comparing language V1 to V2 instances, and backwards compatible comparing language V2 to V1 instances. Similarly, Information 2 - as conveyed by Consumption 2 - relates to Information 1 - as conveyed by Consumption 1 - by relationship r1.
Extensibility is a property that enables evolvability of software.
It is perhaps the biggest contributor to loose coupling in systems as
it enables the independent and potentially compatible evolution of
languages. Languages are defined to be [Definition: Extensible if the syntax of a language allows information that is not defined in the current version of the language.]. The Name Language is extensible if it can include terms that aren't defined in the language, like a new middle term.
1.1.1 Compatibility
As languages evolve, it is possible to speak of backwards
and forwards compatibility. A language change is
backwards compatible if newer processors can process all instances of the old language. Backwards compatibility means that a newer version of a
consumer can be rolled out in a way that does not break existing producers. A
producer can send an older version of a message to a consumer that understands
the new version and still have the message successfully processed. A software example is a word processor at version 5 being able to
read and process version 4 documents. A schema example is a schema at version 5 being able to
validate version 4 documents. This means that a
producer can send an old version of a message to a consumer that
understands the new version and still have the message successfully
processed. In the case of Web services, this means that
new Web services consumers, ones designed for the new version, will be
able to process all instances of the old language.
A language change is
forwards compatible if older processors can process all instances of the newer language.
Forwards
compatibility means that a newer version of a producer can be deployed in a
way that does not break existing consumers. Of course the older consumer will
not implement any new behavior, but a producer can send a newer version of an
instance and still have the instance successfully processed. An example is a word processing software at version 4 being able to read and process version 5 documents.
A schema example is a schema at version 4 being able to validate version 5 documents. This means that a producer
can send a newer version of a message to an existing consumer and still
have the message successfully processed. In the case of Web services,
this means that existing Web service consumers,
designed for a previous version of the language, will be able to
process all instances of the new language.
In general, backwards compatibility means that existing
texts can be used by updated consumers, and forwards compatibility
means that newer texts can be used by existing consumers. Another
way of thinking of this is in terms of message exchanges. Backwards
compatibility is where the consumer is updated and forwards
compatibility is where the producer is updated, as shown below:
With respect to consumers and producers, backwards compatibility means that newer consumers
can continue to use existing producers, and forwards compatibility
means that existing consumers can be used by newer producers.
We need to be more precise in our definitions of what parts of our definitions are compatible with what other parts. Every language has a Defined Text set, which contains only Texts that contain the texts explicitly defined by the language constraints. Typically, a language will define a mapping from each of the definitions to information. Each language has an Accept Text set, which contains texts that are allowed by the language constraints. Typically, the Accept Text set contains Texts that are not in the Accept Text set and do not have a mapping to information. For example, a language that has a syntax that says names consists of given followed by family followed by anything. A text that consists of a name with only a given and a family falls in the Defined and Accept Text set. A text that consists of a name with a given, a family and an extension such as a middle falls in the Accept Text set but not the Defined text set. By definition, the Accept Text set is a superset of the Defined Text set.
We have discussed backwards and forwards compatibility in general, but there other flavours of compatibility, based upon compatibility between the Accept Text set, Defined Text set and Information conveyed. Syntactic compatibility is compatibility that is wrt the Texts only, not the information conveyed. Because languages have Accept and Defined Text sets, some producers will adhere to the Defined Text set, and others may generate extensions that fall in the Accept Text set. Compatibility with Producers that produce only Defined Text sets is called "strict" compatibility. Compatibility with Producers that may produce Texts in the Accept Text Set that are not in the Defined Text Set is called "full" compatibility.
A more precise definition of compatibility is with respect to the texts, that is whether all the texts in one language are also texts
in another language. Another precise form of compatibility is with respect to the information conveyed, that is whether the information conveyed by a text in one language is conveyed by the same text interpreted in another language. The texts could be compatible but the information conveyed is not compatible. For example, the same text could mean different and incompatible things in the different language. Most systems have different layers of software, each of which can view a text differently and affect compatibility. For example, the XML Schema PSVI view is different from the actual text. We can also differentiate between language compatibility and application compatibility. While it is often the
case that they are directly related, sometimes they are not, that is 2 languages may be compatible but an application might be incompatible with one of them.
We provide mathematical definitions of a text's compatibility based up on our terminology.
Let L1 and L2 be Languages, where L2 is introduced "after" L1.
Let T be a text.
T is in L1 iff (T is valid per L1 | T is in L1's set of Texts).
Let I1 be the information conveyed by Text T1 per language L1.
Let I2 be the information conveyed by Text T per language L2.
Text T is "fully compatible" with language L2 if and only if I1 is compatible with I2 and (T is valid per L2 | T is in L2's set of Texts).
Text T is incompatible if any of the
information in I2 is wrong (I.e. replaces a value in I1 with a different one) | (T is invalid per L2 | T is not in L2's set of Texts).
We can also provide mathematical definitions of language compatibility:
L2 is "fully backwards compatible" with L1 if every text in L1 Accept Text set is fully compatible with L2.
L2 is "strictly backwards compatible" with L1 if every text in L1 Defined Text set is fully compatible with L2.
L2 is "strictly backwards incompatible" with L1 if any text in L1 Defined Text set is incompatible with L2.
L1 is "fully forwards compatible" with L2 if every text in L2 Accept Text set is fully compatible with L1.
L1 is "strictly forwards compatible" with L2 if every text in L2 Defined Text set is fully compatible with L1.
L1 is "forwards incompatible with L2" if any text in L2 is incompatible with L1.
And combined together is: L1 is strictly compatible with L2 if if every text in L2 Defined Text set is fully compatible with L1 AND if every text in L1 Defined Text set is fully compatible with L2.
We can draw a few conclusions. Given L2 is strictly backwards incompatible with L1 if any text in L1 Defined Text set is incompatible with L2, the only way that L2 can be backwards compatible with L1 is if the L2 Defined Text Set is a superset of L1 Defined Text set. Roughly, that means the addition of optional items in L2. Given L1 is "fully forwards compatible" with L2 if every text in L2 Accept Text set is fully compatible with L1, the only way that L1 can be forwards compatible with L2 is if the L1 Accept Text is is a superset of the L2 Accept Text set. Roughly, that means L1 allows all of L2 and more. It is this superset relationship that is a key to forwards compatibility, the allowing of texts by L1 that will become defined in L2.
Compatibility can be restated in terms of superset/subset relationships.
Language L2 is strictly backwards compatible with Language L1 if L2 Defined Text set > (superset) L1 Defined Text Set AND every text in L1 Defined Text set is compatible with L2.
Language L1 is strictly forwards compatible with Language L2 if L1 Accept Text set > (superset) Language L2 Accept Text set AND every text in L2 Accept Text set is compatible with L1.
Language L2 is fully strictly compatible with Language L1 if L1 Accept Text set > (superset) Language L2 Accept Text set > (superset) L2 Defined Text set > (superset) L1 Defined Text Set AND every text in L1 Defined Text set is compatible with L2 AND every text in L2 Accept Text set is compatible with L1.
We have shown that forwards and backwards compatibility is only achievable through extensibility, and compatible versioning is a process of gradually increasing the Defined Text Set, reducing the Accept Text Set and ensuring the information conveyed is compatible, If ever the set relationships defined earlier do not hold, then the versions are not compatible.
1.1.1.1 Partial Understanding
We have defined compatibility for all possible expressions of the language, that is full compatibility. There are many scenarios where a consumer will consume only part of the information set. Partial understanding affects the Text set and the Information conveyed. Partial understanding usually results in a subset of the information (because only part of the information is understand). Interestingly, partial understanding is an increases or supersets the Accept Text Set and a parallel decrease or subset of the Defined Text Set. This is because the process of extracting a part of the text means that extra content, even those illegal under V1 syntax, becomes part of the Accept Text Set.
We can imagine an application that only looks at given names and everything else is ignored. My favourite example of this is a "Baby Name" Wizard. The application might use a simple XPath expression to extract the given name from inside the name. This is a different version of the Name Language, which we will call the Given Name Language. The Accept Text set for the Given Name Language is anything, given, anything. The Defined Text set for the Given Name Language is given. The information set for the Given Name language is given. Because the Given Name Language syntax set is more relaxed that the Name Language V1, an addition of the middle name between the given and family is a compatible change for the Given Name Language. There are a variety of other now acceptable names in the Given Name Language.
Our principles with respect to compatibility and language versioning need no change to deal with partial understanding. Partial understanding a language is the creation of Language L1' that is compatible with Language L1. This is true if L1' Accept Text set > (superset) Language L1 Accept Text set > (superset) L1 Defined Text set > (superset) L1' Defined Text Set AND every text in L1' Defined Text set is compatible with L1 AND every text in L1' Accept Text set is compatible with L1'.
Interestingly, partially understanding a language is creating a language V1', such that the V1 language is a compatible change with the V1'. There may be many different versions that are all partial understandings of a language. We call these related languages "flavours". It may be very difficult for a language designer to know how many different language flavours are in existence. However, a language designer can sometimes use the different flavours to their advantage in designing for a mixture of compatible and incompatible changes. Some changes could be compatible with some flavours but not other. It may be very useful to have some changes be compatible with some flavours, that is those consumers do not need to be updated or changed.
It is crucial to point out that the consumers of partially understood versions of the language are not also producers of the partially understood language. They have relaxed the restrictions on the consuming side, but should not do so on the production side of the language. If a flavour of a language was also used for production, it should have to create an instance that is valid according to the Language V1 rules, not the Language V1'. Perhaps the only exceptions are if they are guaranteed that they will be producing for compatible flavours. Typically this is not the case and hard to determine, so the safest course is to produce according to the Language V1 rules.
We have shown how relaxing the constraints on a language when consuming instances of it can turn an otherwise incompatible change into a compatible change. We have also shown that abiding by the language constraints when producing instances is the safest course. Said more eloquently is the internet robustness principle, "be conservative in what you do, be liberal in what you accept from others" from [tcp].
We will call this style of versioning the "liberal" style of versioning. The "liberal" style of versioning is codified in:
Good Practice
Use Least Partial Languages for "liberal" versioning: Consumers should use a flavour of a language that has the least amount of understanding.
The least amount of understanding will be the most liberal or have the largest syntax set possible.
The "liberal" style of versioning has a significant downside in that it can lead to very fragile and hard to evolve software because the "liberal"ness is difficult to code and it does not force producers to be correct in what they produce, causing a vicious cycle of complexity.
There is an opposite style of versioning that says the most effective way of evolving is to force producers to be correct by having strict consumers. We will call this the "conservative" style of versioning. The "conservative" style of versioning is codified in:
Good Practice
Use No Partial Languages for "conservative" versioning: Consumers should fully use and validate a language.
The fullest amount of understanding will find the most errors.
In either "liberal" or "conservative" versioning of consumers, the advice to a producer is the same:
Good Practice
Produce no partial languages: Producers should use the complete version of a language and no partial flavours of a language.
However, the difference between them is that "liberal" consumers might allow producers that aren't fully compatible with the Language whereas "conservative" consumers will be less fault tolerant.
EdNote: I think related to principle of least power. The least powerful the language, the easier to have partial understanding?
EdNote: I think there is a relationship between conservative/liberal and description. Perhaps there is problem when a text is treated as being in the language even when the description doesn't allow it. So the producer has "drifted" away from the documentation, and a conservative consumer will fault and a liberal consumer will pass.
Compatibility is defined for the producer and consumer of an
individual text. Most messaging specifications, such as Web Services,
provide inputs and outputs. Using these definitions of
compatibility, a Web service that updates its output message is
considered a newer producer because it is sending a newer version of the message. Conversely, updating the
input message makes the service a newer consumer because it is consuming a newer version of the message. All systems of inputs and outputs must
consider both when making changes and determining compatibility. For full compatibility, any output messages changes must be forwards compatible (for the older receivers aka consumers) and any input message changes must be backwards compatible (for the older senders aka producers).
1.1.2 Open or Closed systems
The cost of changes that are not backward or forward compatible is
often very high. All the software that uses the language must be
updated to the newer version. The magnitude of that cost is directly
related to whether the system in question is open or closed.
[Definition: A closed
system is one in which all of the producers and consumers are
more-or-less tightly connected and under the control of a single
organization.] Closed systems can often provide integrity
constraints across the entire system. A traditional database is a good
example of a closed system: all of the database schemas are known at
once, all of the tables are known to conform to the appropriate
schema, and all of the elements in the each row are known to be valid
for the schema to which the table conforms.
From a versioning perspective, it might be practical in a closed
system to say that a new version of a particular language is being
introduced into the system at such and such a time and all of the data
that conforms to the previous version of the schema will be migrated
to the new schema.
[Definition: An open
system is one in which some producers and consumers are loosely
connected or are not controlled by the same organization. The internet
is a good example of an open system.]
In an open system, it's simply not practical to handle language
evolution with universal, simultaneous, atomic upgrades to all of the
affected software components. Existing producers and receivers outside the
immediate control of the organization that has publishing a changed
language will continue to use the previous version for some
(possibly long) period of time.
Finally, it's important to remember that systems evolve
over time and have different requirements at different stages in their
life cycle. During development, when the first version of a language
is under active development, it may be valuable to pursue a much more
aggressive, draconian versioning strategy. After a system is in production and
there is an expectation of stability in the language, it may be
necessary to proceed with more caution. Being prepared to move forward
in a backwards and forwards compatible manner is the strongest
argument for worrying about versioning at the very beginning of a project.
1.2 Why Worry About Extensibility and Versioning?
As texts, or messages, are exchanged between applications, they
are processed. Most applications are designed to discriminate between
valid and invalid inputs. In order to have any sort of
interoperability, a language must be defined or described in some
normative way so that the terms "invalid" and
"valid" have meaning.
There are a variety of tools that might be employed for this
purpose (DTDs, W3C XML Schema, RELAX NG, Schematron, etc.). These
tools might be augmented with normative prose documentation or even
some application-specific validation logic. In many cases, the schema language is the only validation logic that is available.
It is almost unheard of for a single version of a language to be
deployed without requiring some kind of augmentation. Invariably, the
original language designer did not include certain terms and
constraints. In fact, good designers should not try to define all the
possible terms and constraints. This is sometimes called
"boiling the ocean". Knowing that a language will not be
all things to all people, a language designer can allow parties to
extend instances of the language or the language itself. Typically the
tools will allow the language designer to specify where extensions in
the instance and extensions in the language are allowed. Of note, we
do not call extending a text of a language
a new version. This limits our discussion of versioning to
changes in a language, not changes to instances.
Whether you've deployed ten resources, or a hundred, or a million,
if you change a language in such a way that all those resources will
consider instances of the new language invalid, you've introduced
a versioning problem with real costs.
Once a language is used outside of its development environment,
there will be some cost associated with changing it: software, user
expectations, and documentation may have to be updated to accommodate the
change. Once a language is used in environments outside of a single
realm of control, any changes made will introduce multiple versions of
the language.
