1 Introduction
XML is designed for the creation of tag sets, languages of elements
and attributes. XML is self-describing in the minimal sense that any
XML parser can recognize the namespaced elements and attributes,
attribute values, and text content of a document. It is designed for
the combination of languages in instance documents.
Most XML languages should be designed so that other XML languages
can be added to them when appropriate. One aspect of extensibility is
the ability to mix languages. In any but the most simple applications,
languages evolve over time. As soon two different definitions exist
for a given vocabulariy, you have introduced versioning, whether you
are prepared for it or not.
This finding discusses how developers can design with extensibility and change in mind,
making backward and forward-compatible changes possible in
the future.
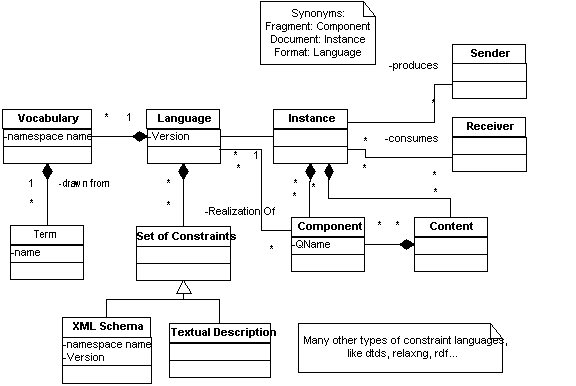
1.1 Terminology
Extensibility is a property that enables evolvability of software.
It is perhaps the biggest contributor to loose coupling in systems as
it enables the independent and potentially compatible evolution of
languages. Languages are defined to be [Definition: Extensible if instances of the
language can include terms from other vocabularies.]
An XML Namespace is a convenient container for collecting terms
that are intended to be used together within a language or across
languages. It provides a mechanism for creating globally unique names.
A language has a vocabulary that may be drawn from one or more XML
Namespaces (or none). [Definition: A vocabulary is a set of terms]. The syntactic structure of the language is
constrained by the use of DTDs, XML Schema, other schema languages or
narrative constraints expressed in the relevant language
specification.
In general, the intended meaning of a vocabulary term is scoped by
the language in which the term is found. However, there is some
expectation that terms drawn from an XML Namespace have a consistent
meaning across all languages in which they are used.
For our purposes, [Definition: a
language is an identifiable set of vocabulary terms that has defined constraints.]
For example, the elements and attributes of XHTML 1.0 or the
names of built-in functions in XPath 2.0.
Languages may or may not be defined by a schema in any particular
schema language. By language, we just mean the set of elements and
attributes, or components, used by a particular application.
[Definition: An instance is a realization of a language]. Documents are instances of a language. They must have a root element in XML.
[Definition:
Content is data that is part of an instance of a language.] Content is part of a document. Content has one or more components.
[Definition: a Component is a realization of a term in a language.] XML elements and attributes are components.
In this finding, we describe interaction between applications and
languages in terms of senders and receivers.
[Definition: A sender creates or
produces an instance for processing by another application.
]
[Definition: A receiver
consumes an instance that it obtained from a
sender.]
These terms and their relationships are shown below
In the examples mentioned above, the stylesheet processor is a
receiver of the XML document that it is processing (the sender isn't
mentioned); in the Web services context the roles of sender and
receiver alternate as messages are passed back and forth.
Note that most Web service specifications provide definitions of
inputs and outputs. By our definitions of compatibility, a Web service
that updates its output schema is considered a new sender. A service
that updates its input schema is a new receiver.
Versioning is an issue that effects almost all XML applications
eventually. Whether it's a processor styling
documents in batch to produce PDF files or Web services engaged in
financial transactions, applications may receive versions of a
language that they aren't expecting.
As languages evolve, it becomes possible to speak of both backwards
and forwards compatability. We base our definitions of backwards and
forwards compatibility on the [FOLDOC] definitions.
There are two aspects of compatibility that are called out:
software compatibility and schema compatibility. While it is often the
case that they are directly related, sometimes they are not.
[Definition: A language change is
backwards compatible if newer processors can process all instances of the old language. ]
A software example is a word processor at version 5 being able to
read and process version 4 documents. A schema example is a schema at version 5 being able to
validate version 4 documents. In the case of Web services, this means that
new Web services receivers, ones designed for the new version, will be
able to process all instances of the old language. This means that a
sender can send an old version of a message to a receiver that
understands the new version and still have the message successfully
processed.
[Definition: A language change is
forwards compatible if older processors can process all instances of the newer language.]
An example is a word processing software at version 4 being able to read and process version 5 documents. A schema example is a schema at version 4 being able to validate version 5 documents. In the case of Web services,
this means that existing Web service receivers,
designed for a previous version of the language, will be able to
process all instances of the new language. This means that a sender
can send a newer version of a message to an existing receiver and still
have the message successfully processed.
In broad terms, backwards compatibility means that newer senders
can continue to use existing services, and forwards compatibility
means that existing senders can use newer services
The cost of changes that are not backward or forward compatible is
often very high. All the software that uses the language must be
updated to the newer version. The magnitude of that cost is directly
related to whether the system in question is open or closed.
[Definition: A closed
system is one in which all of the senders and receivers are
more-or-less tightly connected and under the control of a single
organization.] Closed systems can often provide integrity
constraints across the entire system. A traditional database is a good
example of a closed system: all of the database schemas are known at
once, all of the tables are known to conform to the appropriate
schema, and all of the elements in the each row are known to be valid
for the schema to which the table conforms.
From a versioning perspective, it might be practical in a closed
system to say that a new version of a particular language is being
introduced into the system at such and such a time and all of the data
that conforms to the previous version of the schema will be migrated
to the new schema.
[Definition: An open
system is one in which some senders and receivers are loosely
connected or are not controlled by the same organization. The internet
is a good example of an open system.]
In an open system, it's simply not practical to handle language
evolution with universal, simultaneous, atomic upgrades to all of the
software components. Existing senders and recievers outside the
immediate control of the organization that's publishing a changed
language will continue to use the previous version for some
(possibly long) period of time.
Finally, it's important to remember that systems evolve
over time and have different requirements at different stages in their
life cycle. During development, when the first version of a language
is under active development, it may be valuable to persue a much more
aggressive, draconian versioning strategy. After a system is in production and
there is an expectation of stability in the language, it may be
necessary to proceed with more caution. Being prepared to move forward
in a backwards and forwards compatible manner is the strongest
argument for worrying about versioning at the very beginning of a project.
1.2 Why Worry About Extensibility and Versioning?
As documents, or messages, are exchanged between applications, they
are processed. Most applications are designed to discriminate between
valid and invalid inputs. In order to have any sort of
interoperability, a language must be defined or described in some
normative way so that the terms "invalid" and
"valid" have meaning.
There are a variety of tools that might be employed for this
purpose (DTDs, W3C XML Schema, RELAX NG, Schematron, etc.). These
tools might be augmented with normative prose documentation or even
some application-specific validation logic. In many cases, the schema language is the only validation logic that is available.
It is almost unheard of for a single version of a language to be
deployed without requiring some kind of augmentation. Invariably, the
original language designer did not include certain terms and
constraints. In fact, good designers should not try to define all the
possible terms and constraints. This is sometimes called
"boiling the ocean". Knowing that a language will not be
all things to all people, a language designer can allow parties to
extend instances of the language or the language itself. Typically the
tools will allow the language designer to specify where extensions in
the instance and extensions in the language are allowed. Of note, we
do not call extending an instances of a language
a new version. This scopes our discussion of versioning to
changes in a language, not changes to instaces.
Whether you've deployed ten services, or a hundred, or a million,
if you change a language in such a way that all those services will
consider instances of the new language invalid, you've introduced
a versioning problem with real costs.
Once a language is used outside of its development environment,
there will be some cost associated with changing it: software, user
expectations, and documentation may have to be updated to accomodate the
change. Once a language is used in environments outside of a single
realm of control, any changes made will introduce multiple versions of
the language.
1.3 Why Extend languages?
The primary motivation to allow instances of a language to be
extended is to decentralize the task of designing, maintaining,
and implementing extensions. It allows
senders to change the instances without going through a centralized
authority. It means that changes can occur at the sender or receiver
without the language owner approving of them. Consider the effort that
the HTML Working Group put into modularity of HTML. Without some decentralized
process for extension, every single variant of HTML would have to be called
something else or the HTML Working Group would have to agree
to include it in the next revision of HTML.
Good Practice
Allow Extensibility: Languages designers SHOULD create extensible languages.
1.4 Why Do Languages Change?
There are many reasons why a different version of a language may
be needed. A few of them include:
Bugs may need to be fixed. Production use may reveal defects
or oversights that need to be fixed. This may involve changes to components
of the language or changes to the semantics of existing components.
Changing requirements may motivate changes in the schema design.
For example, a callback may be added to a service that performs some processing
so that it is able to notify the caller when processing has completed.
Different flavors of a schema may be desirable. For example, the
XHTML 1.0 Recommendation defines strict, transitional, and frameset
schemas. All three of those schemas purport to define the same namespace,
but they describe very different languages.
And additional schemas may be defined by other specifications, such
as the XHTML Basic Recommendation.
Whatever the cause, over time, different versions of the language
exist and designing applications to deal with this change in a
predictable, useful way requires a versioning
strategy.
1.5 How Do Languages Change?
At the most basic level, languages can change in only a few ways:
Elements: New elements can be added, existing elements can
be removed, or the acceptable number of occurences of an element can change.
In addition, the content of an element could change from element only content
to mixed content, or vice versa.
For elements with simple content, the type or range of values that are
acceptable can change.
Attributes: New attributes can be added, existing attributes
can be removed, or the type or range of values that are acceptable can change.
Semantics: The meaning of a an existing element or attribute
can change.
Of course, the difference between two versions of a language can
be an arbitrary number of these changes.
One of the most important aspects of a change is whether or not it is
backwards or forwards compatible. For example:
Adding new optional elements or attributes is both backwards and
forwards compatible.
Increasing the allowed number of occurrences of an element is
backwards compatible. Similarly, extending the allowed range of an element
with simple content or an attribute is a backwards compatible change.
Decreasing the allowed number of occurrences of an element is
forwards compatible. Decreasing the allowed range of an element or attribute
is forwards compatible.
1.6 Kinds of Languages
Ultimately, there are different kinds of languages. The
versioning approaches and strategies that are appropriate for one kind
of language may not be appropriate for another. Among the various kinds
of vocabulares, we find:
Just Names: some languages don't actually identify elements
or attributes, they're just lists of names. Using QNames to identify words
in the WordNet database, for example, or the names of functions and operators
in XPath2 are examples of "just name" languages.
Standalone: languages designed to be used
more-or-less by themselves, for example XHTML, DocBook, or The TEI.
Containers: languages designed to be used as a
wrapper or framework for some other language or payload, for example
SOAP or WSDL.
Container Extensions: languages designed to extend
or augment a particular class of container. Specifications that extend SOAP by defining SOAP
header blocks, for example, to provide security, asynchrony or reliable messaging
are examples of container extension languages.
There are a couple types of extension languages, element extension and attribute extension.
Element Extension. Languages that are elements. SOAP, etc. are element extensions.
Attribute or type Extensions. Langages that are types or attributes. These languages must exist in the context of an element. Sometimes called "parasite" languages as they require a "host" element. XLink is an example.
Mixtures: languages designed for, or often used for,
encapsulating some semantics inside another language. For example, MathML
might be mixed inside of another language.
This is by no means an exhaustive list. Nor are these categories
completely clear cut. MathML can certainly be used standalone, for
example, and languages like SVG are a combination of standalone,
containers, and mixtures.
2 Versioning Strategies
Versioning is a broad and complex issue. Different communities have
different notions about what constitutes a version, what constitutes a
reasonable policy, and what the appropriate behavior is in the face of
deviations from that policy. Historically, it has always proved more
complicated in practice than in theory.
In broad terms, the approaches to versioning fall into a number of
classes ranging from "none" to a "big bang":
None. No distinction is made
between versions of the language. Applications are either expected
not to care, or they are expected to cope with any version they
encounter.
Compatible. Designers are expected to limit changes to
those that are either backwards or forwards compatible, or both.
Backwards compatibility. Applications
are expected to behave properly if they receive an instance document of the
"older" version of a language. Backwards
compatible changes allow applications to behave properly if they receive
an "older" version of the language.
Forwards compatibility. Applications
are expected to behave properly if they receive an instance document of the
"newer" version of a language. Forwards compatible
changes allow existing applications to behave properly if they receive
a "newer" version of the language.
Flavors. Applications are expected to behave
properly if they receive one of a set of flavors of the document type.
Big bang. Applications are expected to
abort if they see an unexpected version.
There's no single approach that's always correct. Different
application domains will choose different approaches. But by the same
token, the approaches that are available depend on other choices,
especially with respect to namespaces. This dependency makes it
imperative to plan for versioning from the start. If you don't plan
for versioning from the start, when you do decide to adopt a plan for
versioning, you may be constrained in the available approaches by decisions that you've already made.
A language goes through a common lifecycle of iterative development followed by deployment. These place in the lifecycle will affect the selection of the versioning strategy
Just as there are a number of approaches, there are a number of
strategies for implementing an approach. The internet - including MIME, markup languages, and XML languages have succesfully used various strategies, either singly or in combination. Summaries of strategies and requirements have been produced for earlier technologies and guided XML Namespaces and Schema, such as [HTML Document types] and [Web Architecture: Extensible Languages].
For any given
approach, some strategies may be more appropriate than others. Among
the strategies we find:
Must Understand. Receivers must understand all of the
elements and attributes received and are expected to abort processing
if they do not. SOAP processors must understand headers that are
explicitly identified to be mandatory.
Must Ignore. Receivers must ignore elements or
attributes that they do not understand. Sometimes the must understand
and must ignore approaches can be combined for more selective use.
SOAP processors must ignore headers they do not recognize unless the
header explicitly identifies itself as one that must be understood.
There are 2 variations of the Must Ignore strategy:
Must Ignore All This variation on must
ignore requires the receiver to ignore an element or attribute it does not
understand and, in the case of elements, all of the descendents of that element. Most
data applications, such as Web services that use SOAP header blocks or WSDL extensions, adopt this approach to
dealing with unexpected markup. For XML, the Must Ignore all rule was
first standardized in the WebDAV specification RFC 2518 [WebDAV] section 14
and later separately published as the [FlexXMLP].
Must Ignore Container. This variation on must
ignore requires the receiver to ignore an element or attribute
that it does not understand, but in the case of elements, to process
the children of that element. The Must Ignore Container practice was
described in [HTML 2.0]
Explicit Fallback. A language can provide mechanisms for
explicit fallback if the extension is not supported. [MIME] provides multipart/alternative for equivalent, and hence fallback, representations of content. [HTML 4.0] uses this approach in the NOFRAMES element. In XML, the XML Inclusions specification [XInclude] provides a fallback
element to handle the case where the putatively included resource cannot be
retreived.
Explicit Testing. A language can provide a mechanism for
explicit testing. The XSLT Specification provides a conditional logic
element and a function to test for the existence of extension functions. This allows
designers of stylesheets to deal with different receiver capabilities in an
explicit fashion.
Languages can choose a mixture of approaches. For example, XSLT provides
both an explicit fallback mechanism for some conditions and explicit testing
for others. The SOAP specification, another example, specifies Must Ignore as the default strategy and the ability to dynamically mark components as being in the Must Understand strategy.
3 Why Have a Strategy?
Different kinds of languages and different versioning strategies expose
different problems. If you don't have a strategy at all, you are effectively
choosing the "no versioning" strategy.
It's probably obvious that attempting to deploy a system that
provides no versioning mechanism is frought with peril. Putting the
burden of version "discovery" on receivers is probably
impractical in anything except a closed system.
At the other end of the spectrum is the "big bang" approach which
is also problematic.
"Big bang" is a very coarse-grained approach to
versioning. It establishes a single version identifier, either a version number or namespace name, for an entire
document.
The semantics of the "big bang" are that applications decide on the
basis of the document version whether or not they know how to process
that document. If the version isn't recognized, the entire document is
rejected.. Typically, when introducing a new version using the
big bang approach, all of the software that produces or
consumes the instance documents is updated in a sweeping overhaul in
which the entire system is brought down, the new software deployed and
the system is restarted. This big bang approach to versioning is
practical only in circumstances where there is a single controlling
authority, and even in that case, it carries with it all manner of
problems. The process can take a considerable amount of time, leaving
the system out of commission for hours if not days. This can result in
significant losses if the system is a key component of a revenue
generating business process and the cost of coordinating the system
overhaul can also be quite costly as well.
Another approach to mitigate against a complete overhaul is to run parallel versions of the system, often with proxies or gateways between them. However, this too has its costs as multiple versions of the software must be supported and maintained over time and there is the added cost of developing the proxy or gateway between the two environments.
The "big bang" approach is appropriate when the new version is
radically different from its predecessor. But in many cases, the
changes are incremental and often a receiver could, in practice, cope
with the new version. For example, it might be that there are many
messages that don't use any features of the new version or perhaps it
is appropriate to simply ignore elements that are not recognized.
For example, consider two services exchanging messages. Imagine that some
future version of the language that they are using defines a new
"priority" element. Because senders and receivers are distributed,
it may happen that an old receiver, one unprepared for a priority element,
encounters a message sent by a newer sender.
If big bang versioning is used, old systems will reject the new
message. However, if the versioning strategy instead allowed the old
receiver to simply ignore unrecognized content, it's quite possible
that other components of the system could simply adapt to the previous
behavior. In effect, the old system would ignore the priority element
and its descendents so it would "see" a message that
looks just like the old format it is expecting.
For the sender, the result would be that the request is fulfilled,
though perhaps in a more or less timely fashion than expected. In many
cases this may be better behavior than receiving an error. In
particular, senders using the new format can be written to cope with
the possibility that they will be speaking to old receivers.
If the new system needs to make sure that priority is respected,
then it can change the purchase order's name or namespace to indicate
that the new behavior is not considered backwards compatible.
What is needed is some sort of middle ground solution. An evolving
system should be designed with backwards and forwards compatibility in mind.
One approach is to use version numbers, with a goal of using "major
version" changes for incompatible developments and
"minor version" changes for compatible ones.
Unfortunately, version numbers often wind up looking very similar to
the big bang approach. Each language is given a version identifier, almost always a
number, that's incremented each time the language changes. Although
it's possible to design a system with version numbers that enables
both backward and forward compatibility, for example XSLT, typically,
a version change is treated as if that the new language is not backwards
compatible with the old language.
Some efforts, such as HTTP, try to have the best of both worlds
by allowing for extensibility (in HTTP's case, via headers) as well as
version numbers that explicitly identify when a new version is
backwards compatible with an old version.
One argument in favor of version numbers is that they allow one to
determine what is a 'new version' and what is an 'old version'. But in
practice this is not necessarily true. For example, RSS has 0.9x, 1.x,
and 2.x versions, all being actively developed in parallel. In effect
the version numbers, even though they appear to be ordered, are simply
opaque identifiers. Using version numbers does not gaurantee that
version 1+x has any particular relationship to version 1.
The self-describing and extensible nature of XML markup, and the addition of XML
Namespaces, provide a much better framework for developing
languages that can evolve.
4 Designing for the Middle Ground
Strategies on the extreme ends (none or big bang) might be
appropriate for closed systems or systems that are largely autonomous or monolithic. In
the modern world of distributed agents cooperating through Web service
interactions, the extremes pose obvious problems when messages from a new
version of a language may be sent to systems that were written for an
older version (and vice versa).
Rather than having a single global version identifier, each XML
element in a language should be allowed to version independently of
others. We propose that this be accomplished by adopting "must
ignore" and "must understand" rules.
If a language parser encounters an element or attribute that is not
recognized in a "must ignore" context, then that
component and all of its descendants are ignored. This approach allows
individual elements to be versioned without having to resort to a
big bang approach with its associated problems.
We recognize that it is not always appropriate to ignore content.
If a language parser encounters an element or attribute that is not
recognized in a "must understand" context, it must
consider that an error and react accordingly.
This finding's focus on versioning is driven by a desire to enable
loose coupling between senders and receivers of messages written using
XML based languages. Loose coupling is best achieved by increasing the
possibility for backwards-compatible and forwards-compatible
processing to occur when the XML language evolves. A number of rules
are described for versioning XML languages, making use of XML
Namespaces and W3C XML Schema constructs. The finding also includes
rules for working with languages such as SOAP that provide an
extensible container model.
4.1 An Example
Throughout this finding, we'll motivate our discussion of versioning
with an ongoing example. Suppose that you have designed a Web service for
handling purchase orders. Processing begins when a purchase order is
sent to the service. The order is processed and notification of
shipment is sent back.
Because it can take an arbitrary amount of time to process an order
before the shipped message can be sent (consider, for example, items
on back order), it's useful to make this process asynchronous. To do
this, the original sender includes a "call back" address
where the shipped message should be delivered when it is ready.
Initially, the purchase order processor acts as a receiver. But
when the shipment has been processed, it acts as a sender, delivering
a message to the callback service that was provided.
Ultimately, we'll describe the evolution of this callback service
in two ways: one that is
backwards compatible and one
that is not.
In order to be schema agnostic, we will use the examplotron [examplotron] schema to convey the semantics of our examples. Examplotron uses examples to indicate the type and uses additional attributes to refine the content model.
Ironically, given the purpose of this finding, examplotron doesn't currently support extensibility points. We are in discussion with Eric van der Vlist about adding this functionality. For the time being, we've added the [...] notation to indicate arbitrary extensibility of attributes and elements.
5 Identifying and Controlling Languages
Our main goal is to allow backwards and forwards compatible processing
as a language evolves.In order to accomplish those objectives, we
must achieve two goals:
The processor must understand the semantics of every valid message
that it receives. We must therefore define the semantics of messages
that contain new elements or attributes.
We assume that each service rejects invalid messages. Therefore,
it must be possible for our language to evolve without changing the
schema that we've defined for it. New versions of a service might be deployed with newer schemas, but we want these new services to be able to communicate with the already deployed senders and receivers that will continue to use the old schemas.
That is why forwards compatible language
changes have to be possible without changing the schema.
In order for a schema to be extensible in the way described above,
to allow new elements or attributes to be added without changing the
schema, the schema must allow extension in any namespace. This brings us to the next rule for enabling a must ignore
versioning strategy in XML languages:
Good Practice
Any Namespace: The language SHOULD provide for extension in any namespace.
It usually makes sense to allow extension in attributes as well.
Good Practice
Full Extensibility: All XML Elements that can allow attributes, ie ComplexTypes in XML Schema, SHOULD
allow any attributes and any elements in their content models.
The corollary of extensibility in any namespace, including the language's namespace, is that a namespace does not identify a single version of a language or set of names. A namespace identifies a compatible set of names.
Good Practice
Namespace identifies compatible names: The namespace name identifies names that are compatible within the same namespace name.
The section on extensibility will describe the conditions for when to change the namespace name as a result of change in the names identified.
Given that a namespace name is not for a single version of a language or set of names, it may be useful to identify the particular version. An example would be specifying in a policy statement the exact language supported by a software agent. This use of version identification could be considered each compatible "minor" version, with the namespace name identifying the incompatible versions.
Good Practice
Identify specific version with version attribute: The specific version of a set of names within a given namespace may be identified with a version attribute to differentiate between the compatible versions
This finding does discourage the use of version attributes. Namespace names provide a solution for identification in the large majority of the identification problems. Version attributes should only be used in a small minority of the cases. There is considerable danger that using version attributes to differentiate between compatible versions in a namespace will morph into differentiating between incompatible versions of a namespace and thus replacing much of the namespace functionality.
5.1 Defining an Extensible Callback
A number of examples illustrate the application of these and
subsequent rules.
<wscb:Callback xmlns:wscb="http://example.com/callback/"
xmlns:eg="http://examplotron.org/0/">
...
<wscb:callbackLocation eg:content="xsd:anyURI" eg:occurs="."/>
...
</wscb:Callback> A major motivation for using XML Namespaces is to
allow extensions to a language to be made by any party. The example above accomplishs
that goal. An extension can be defined by any new specification simply
by normative reference to the original Callback specification and a
definition for the new element or attribute content. No permission should be needed from
the authors of the specification to make such an extension.
6 Understanding Extensions
The key value of the extension strategy described above is that
existing XML documents can be extended without having to change
existing implementations. For languages that are intended to be
extensible, specifications SHOULD provide a clear processing model for
extensions.
Good Practice
Provide Processing Model: Languages MUST
provide a processing model for dealing with extensions.
Given that an existing processor cannot possibly know the intended
semantics of a component that its never seen before, only one semantic
is possible: ignore that component. We propose, therefore, that processors
"must ignore" elements and attributes they do not recognize.
For many applications, including most Web services, the most
practical rule is: must ignore.
Good Practice
Must Ignore: Receivers MUST ignore any XML
attributes or elements that they do not
recognize in a valid XML document.
This rule does not require that the elements be physically removed;
only ignored for most processing purposes. It would be reasonable, for example,
if a logging application included unrecognized elements in its log. There are cases where the elements should not be physically removed. An example is an application that forwards the content to another receiver should preserve the unknown content.
There are two broad types of languages relating to dealing with extensions. These two types are presentation or document and data oriented applications. For data oriented applications, such as Web services, the rule is:
Good Practice
Must Ignore All: The Must Ignore rule applies to unrecognized elements and their descendents.
Applications must deal carefully with the ignored elements,
especially if any of them are counted or if the application makes use
of information about their position.
Imagine that software compliant with the Example 1
Callback type
received the following Callback document:
<wscb:Callback
xmlns:wscb="http://example.com/callback/"
xmlns:ncs="http://example.com/newcallbackstuff"
ncs:foo="bar">
<wscb:callbackLocation>
http://example.com/foo/CallbackService
</wscb:callbackLocation>
<ncs:conf>
<ncs:lk3>15</ncs:lk3>
</ncs:conf>
</wscb:Callback> The receiver ignores the ncs:foo attribute and the
ncs:conf element (and its descendents, so it never even
sees ncs:lk3). With these components ignored, the request
can be processed just like an older version of the callback.
Document oriented languages need a different rule as the application will still want to present the content of an unknown element. The rule for document oriented applications is:
Good Practice
Must Ignore Container: The Must Ignore rule applies only to unrecognized elements
This retains the descendents of the ignored container element, such as for display purposes.
In order to accomodate big bang changes when they are needed, the
must ignore rule is not expected to apply to the root element. If the
document root is unrecognized, the entire message must be
rejected.
This finding outlines some general extensibility strategies. However, individual
languages will choose rules in accordance with their requirements.
7 Versioning Languages
The strategy outlined above distributes the notion of versioning
down into the messages. Changes that are compatible with the extension
mechanism do not require a namespace change.
Good Practice
Re-use Namespace Names and Element Names: If
a backwards or forwards compatible change is made to an element
definition by the owner of the element's namespace, then the old
namespace name and element names SHOULD be used in conjunction with
the extensibility model.
Imagine the callback element is extended to specify an expiration, to indicate that the callback will only be viable until a specified time..
In the example below, this is done with an expires element added to the extensibility point in the original schema:
<wscb:Callback xmlns:wscb="http://example.com/callback/">
<wscb:callbackLocation>
http://example.com/foo/CallbackService
</wscb:callbackLocation>
<wscb:expires>An absolute time in the future/wscb:expire>
</wscb:Callback> The expires element is defined in the callback namespace, but it
isn't defined in the earlier callback specification. If the callback
receiver is only aware of the earlier version of the Callback
specification and follows the must ignore rule, it will
ignore the expires element because it is not defined in the specification that
the receiver understands.
Here is an example of a schema that could be used for the new
language that would preserve backwards compatible behavior.
<wscb:Callback xmlns:wscb="http://example.com/callback/"
xmlns:eg="http://examplotron.org/0/">
...
<wscb:callbackLocation eg:content="xsd:anyURI" eg:occurs="."/>
<wscb:expires eg:content="xsd:dateTime" eg:occurs="?"/>
...
</wscb:Callback> This CallbackType with an optional expires element is
backwards compatible with earlier specification.
As you can see, the namespace name is not always required to change
when a specification evolves. It depends on the compatibility of the
actual changes.
7.1 Backwards Incompatible Changes
There are a few distinct types of backwards incompatible change:
A required information item is added.
The semantics of an existing information item are changed.
The maximum number of allowable items is reduced. This change does not guarantee incompatibility. Instance documents where the maximum number allowable is still greater than or equal to the number of occurrences will still be vaild. If the maximum number of allowable items is reduced below the previous versions minimum number, then incompatibility is guaranteed.
Imagine that the semantics of callback location change; perhaps a
conversation identifier is now required as part of the location. In this
case, the must ignore rule won't help as ignoring the conversation identifier
will result in invalid callbacks being dispatched.
Backwards incompatibility can easily be achieved by changing
the namespace name or any of the element names. For example:
<wscb:Callback xmlns:wscb="http://example.com/conversationCallback/"
xmlns:eg="http://examplotron.org/0/">
...
<wscb:callbackLocation eg:content="xsd:anyURI" eg:occurs="."/>
<wscb:conversationId eg:content="xsd:anyURI" eg:occurs="."/>
...
</wscb:Callback> Notice that the namespace name has been changed from
/callback to /conversationCallback. This new
message type will be rejected as unrecognized by older systems. Deploying this callback request is an example of a "big bang" change.
7.2 Namespace content changes
Only the owner of a namespace can change (ie. version) the
meaning of elements and attributes in that namespace.
Constraint
Only Namespace Owners Change Namespace: The namespace name owner is the only entity that is allowed to change the meaning of names in a namespace.
There is a school of thought that says that every extension should
be placed in a separate namespace; that after publication, no new
names should be added to a namespace. If you hold
that point of view then you may not feel that an extensibility element
is necessary or desirable.
Another school of thought says that the maintainers of the language
have a right to add new names to a namespace as they see fit. There are certain advantages
associated with adding new names in the same namespace.
It reduces the number of namespaces needed to describe
instances of the document. There are significant convenience
advantages to using defaulted namespaces for document creation and
manipulation.
It provides a clear separation between extensions by the
language designers and extensions by third parties.
There may be additional benefits in code generation and reuse
if single namespace or a small set of namespaces can completely describe
the language.
A namespace name owner will use the lifecycle of the namespace as one of the factors in determining whether to revise the namespace or not. Typically, the changes during development are not compatible changes. The author of namespaces that are under development will typically follow a "big bang" approach. This helps reduce the number of potentially buggy or immature implementations that are deployed. A W3C specification is a good illustrative example. It will probably change namespace names for each working draft. The Candidate Recommendation, Proposed Recommendation and Recommendation namespaces names should only be changed if compatibility is not achieved.
8 Containers
The issues of versioning and extensibility seem particularly
relevant to languages such as SOAP that are designed to be containers
for transporting a message payload.
Containers are XML elements designed specifically for holding XML
elements whose names and definitions are not known when the container language
is designed. For example, SOAP messages are containers. They have
an extensible Header element and an extensible Body element. Another
examples of a container is WSDL definitions [WSDL 1.1]. Containers are generally trivial and uninteresting without
one or more extensions.
A container extension is typically the specification of a discrete
feature. Extensions provide semantic meaning for either the container
or the contained message or both. SOAP header blocks, like the callback
example, SOAP bodies, policy statements, etc., are examples of
extension languages. In Web services, there are a few well-established
containers, so most Web service languages are container extensions.
Some standalone languages are also specification of a discrete
feature, but do not need a container. Some examples are MathML, SVG, XHTML.
A standalone language may also be a container. Further, unknown to a
standalone language author, it may be used as a container extension.
Thus even standalone languages should plan for extensions and on
being used as an extension. An example of a standalone language that
has been subsequently used as an extension is the XML Digital Signature language.
It does not allow for attribute extensibility, therefore any use of XML Signature as a SOAP
extension requires the creation of a wrapper element to accomodate the
soap:mustUnderstand and soap:role attributes.
Given adoption of the Must Ignore practice, it is often the case that the creator of an extension
wants to require that the receiver understand the extension,
over-riding the must ignore Good Practice. The most common technique is to use
a "must understand" option. This is typically a flag that
indicates that the element must be understood.
Good Practice
Provide Must Understand: Container languages
MUST provide a "must understand" model for dealing with
optionality of extension elements that override the must ignore good practice.
The must understand and must ignore good practices work together to provide a
stable processing model for containers. The [SOAP 1.2], and [WSDL 1.1] attributes and values for specifying "must understand" are
respectively: soap:mustUnderstand="1", wsdl:required="1". SOAP is probably the most common case of a
container that provides a must understand processing model. The default value for
soap:mustUnderstand is 0, which is effectively the must ignore good practice.
Constraint
Use Must Understand: When a language provides
a must understand model, extensions MUST use it when the extension is
required.
In the callback examples, the callback sender can make use of the fact that
the SOAP specification provides a must understand model. A sender can mark the callback with soap:mustUnderstand="true" to indicate that a receiver must understand the callback. This allows
the sender to insert extensions into the container and use the must
understand attribute to override the must ignore rule. Senders can
extend SOAP or their own extensions without changing namespaces, retaining compatibility with the
receiver. Obviously the receiver may be updated to handle new
extensions, but there is now a loose coupling between the language's
processing model and the extension processing model.
When dealing with non-container XML languages, there is less obvious
need for providing a must understand mechanism. If a change is made in the content of
the XML language that is not backwards compatible, then the root
element of the XML language can be changed either by changing the
element name or the namespace. In the case of standalone languages, this will probably result in receivers of the
instance document generating a fault. In extension languages, the results will be governed by whether the extension is marked with must Understand or not. In the standalone case, the extensibility model described earlier means that language could become an extension.
As XML does not allow attributes on attributes, it is very difficult to mark an extension attribute with a Must Understand attribute.
Constraint
Must Understand for elements: Container languages should provide a Must Understand model for elements and not attributes
As a result of this, an extension language designer that wants a component to be understood should model the component as an element and not an attribute.
Good Practice
Promote Must Understand: If a must understand
option is not provided inside a particular extension element, the
extension that must be understood SHOULD be promoted to the first
container that does provide a must understand option.
Imagine that an author is adding a conversation ID extension
and the conversationID element must be understood.
The conversation ID author cannot
change the callback namespace and the callback doesn't provide a
must understand model. The solution is that the conversation ID author promotes the
conversationID element so that it is a sibling of the callback, and specifies
must understand in the container. This is shown below:
<wscb:Callback
xmlns:wscb="http://example.com/callback"
xmlns:cid="http://example.com/callerID">
<wscb:callbackLocation>
http://example.com/foo/CallbackService
</wscb:callbackLocation>
</wscb:Callback>
<cid:callerID soap:mustUnderstand="1">1234567</cid:callerID> This rule should also be applied when the receiver may have
performed significant work prior to finding the extension that must be
understood and it may have to undo the performed work if it doesn't
understand the extension. Imagine if the callerID was
deep inside the callback. The receiver might perform significant work
in processing the callback. Upon finding a must understand extension
that it doesn't understand, the receiver may have to undo all the work
that it had performed. Promoting must understand elements to the
highest level minimizes the work that may have to be undone.
A container may allow multiple required extensions to be targetted by an individual receiver. It is then possible that one or more of the extensions may not be understood by the receiver. The container should anticipate this possibility and require that either all the mandatory extensions are processed by the recevier, or none. An example of this is the SOAP 1.2 specification.
Good Practice
Multiple Extensions: Containers should specify the expected behaviour of multiple extensions.
9 XML Schema
Many deployed and developing XML languages today use W3C XML Schema
to define their message types. Although other efforts, such as OASIS
RELAX NG schemas, deserve serious consideration, this section focuses
on W3C XML Schema and the challenges it introduces to the design of a
versionable language. Similar challenges are faced by designers using
other schema languages, and similar strategies can be employed to
conquer them. The following sections assume that the reader is familiar with
XML Namespaces, W3C XML Schema, and particularly W3C XML Schema's
wildcard element <xs:any>. Readers are encouraged to read some of the well-written existing XML Schema extensibility and versioning best practices, such as [XFront Schema Best Practices] and [XML.com Schema Design Patterns].
9.1 Identifying and Controlling Languages
Extensibility in XML Schema is commonly accomplished using the wildcard element, and the ##any namespace or a
combination of the ##other namespace and the ##targetnamespace in some designated "extensibility" element.
Using the callback example, our first attempt at designing an extensible schema
might look something like this:
<xs:complexType name="CallbackType">
<xs:sequence>
<xs:element name="callbackLocation" type="xs:anyURI"
minOccurs="1" maxOccurs="1"/>
<xs:any namespace="##any" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xsl:anyAttribute/>
</xs:complexType> At first, this seems to accomplish what we want: it allows a
callbackLocation followed by any number of extension elements.
But a problem arises when we want to extend this schema. Suppose, for example,
that we want to add an optional expires element. Although we can
send a expires to receivers using the old schema, we want a new schema
that allows new receivers to validate the expires element
explicitly. It appears that the following would work:
<xs:complexType name="CallbackType">
<xs:sequence>
<xs:element name="callbackLocation" type="xs:anyURI"
minOccurs="1" maxOccurs="1"/>
<xs:element name="expires" type="xs:integer"
minOccurs="0" maxOccurs="1"/>
<xs:any namespace="##any" processContents="lax"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xsl:anyAttribute/>
</xs:complexType> But that schema fragment is invalid.
There are constraints about namespace options and optional elements
that are explained later in 9.3 Determinism. In order to create
valid extension schemas that allow extension in the same namespace, we must
create a container to hold them.
This brings us to the first rule for enabling a must ignore
versioning strategy in XML languages defined by W3C XML Schema:
Good Practice
Any Namespace - XML Schema edition: The language MUST provide an
extensibility element that allows for extension in the current
namespace and a wildcard that allows for extension in another
namespace.
For extensions in the same namespace, create an extension type. For
example:
<xs:element name="extension" id="extension">
<xs:annotation>
<xs:documentation>An extension container for elements in the current namespace.
</xs:documentation>
</xs:annotation>
<xs:complexType mixed="true">
<xs:sequence minOccurs="1" maxOccurs="unbounded">
<xs:any processContents="lax" namespace="##targetnamespace"/>
</xs:sequence>
<xs:anyAttribute namespace="##any" processContents="lax"/>
</xs:complexType>
</xs:element> This example is similar to the <xs:appinfo> element
in W3C XML Schema itself, which can contain extensions.
For extensions in another namespace, use <xs:any
namespace="##other"> at appropriate points in your content
model. W3C XML Schema determinism requirements impose restrictions on
where these extensions may appear. Generally, it is easiest of the
extensions are allowed at the end of the content model.
Good Practice
Full Extensibility - XML Schema edition: All XML Elements MUST
allow any attributes and allow any elements at the end of their
content models. XML Elements MAY allow for element extensibility
elsewhere in their content models.
Consider the following definition for a SOAP header lock
for our callback example.
<s:complexType name="CallbackType">
<s:sequence>
<s:element name="callbackLocation"
type="s:anyURI"
minOccurs="1" maxOccurs="1"/>
<s:element name="Extension"
type="wscb:ExtensionType"
minOccurs="0" maxOccurs="1"/>
<s:any processContents="lax"
namespace="##other"
minOccurs="0" maxOccurs="unbounded"/>
</s:sequence>
<s:anyAttribute/>
</s:complexType>
<s:complexType name="ExtensionType">
<s:sequence>
<s:any processContents="lax"
namespace="##targetnamespace"
minOccurs="1" maxOccurs="unbounded"/>
</s:sequence>
<s:anyAttribute/>
</s:complexType> This design has the serendipitous advantage that it separates third
party extensions (in a different namespace) from compatible changes in
the same namespace. If both extensions in the same namespace and in
other namespaces are provided in the same document, there is no
confusion about ordering of the extensions. This strict ordering of
extensions guarantees that validation can occur. In particular, a node
that has the newer language can use the newer schema, and all the
binding and mapping tools that are available.
In both cases, lax validation is used to enable validation to
succeed with or without a schema for the extension elements.
Use of an Extension element for extensions in the same
namespace and namespace="##other for extensions in different
namespaces avoids determinism issues discussed later.
9.2 Versioning
The callback element with a expires using XML Schema is
<wscb:Callback xmlns:wscb="http://example.com/callback/">
<wscb:callbackLocation>
http://example.com/foo/CallbackService
</wscb:callbackLocation>
<wscb:extension>
<wscb:expires>60</wscb:expires>
</wscb:extension>
</wscb:Callback> Here is the callback with expires example in an XML Schema.
<s:complexType name="CallbackType">
<s:sequence>
<s:element name="callbackLocation" type="s:anyURI"
maxOccurs="unbounded"/>
<s:element name="extension">
<s:complexType>
<s:sequence>
<s:element name="expires" type="s:integer"
minOccurs="0" maxOccurs="unbounded"/>
<s:element name="extension" type="wscb:ExtensionType"
minOccurs="0" maxOccurs="1"/>
<s:any processContents="lax" minOccurs="0"
maxOccurs="unbounded" namespace="##other"/>
</s:sequence>
</s:complexType>
</s:element>
<s:any processContents="lax" minOccurs="0" maxOccurs="unbounded"
namespace="##other"/>
</s:sequence>
<s:anyAttribute/>
</s:complexType>
9.3 Determinism
XML DTDs and W3C XML Schema have a rule that requires schemas to
have deterministic content models. The meaning of deteriminism can
be seen in this example from the XML 1.0 specification:
"For example, the content model ((b, c) | (b, d)) is
non-deterministic, because given an initial b the XML processor cannot
know which b in the model is being matched without looking ahead to
see which element follows the b."
The addition of wildcards in W3C XML Schema (not present in XML
DTDs) leads to some schemas that we might like to express, but that
aren't allowed.
Wildcards with ##any, where minOccurs
does not equal maxOccurs, are not allowed before an
element declaration.
The element before a wildcard with ##any must have a
maxOccurs value that equals its minOccurs
value. If these are different,
then the optional occurrences could match either the element
definition or the wildcard. As a result of this rule, the minOccurs
must also be greater than zero.
Types in any namespace derived by extension that add element
definitions after a wildcard with ##any must be avoided.
Types in a different namespace derived by extension that add
element definitions after a wildcard with ##other must be
avoided. This rule and the previous are roughly equivalent for
explanation purposes: In these two cases, violating these constraints
with an instance of the added element definition could match either
the wildcard or the derived element definition. This is effectively
the first bulleted rule applied to derivation. The problems of
determinism make derivation and wildcarding almost mutually exclusive,
the exception being extension in the same namespace and wildcards with
##other.
Constraint
Be Deterministic: Use of wildcards must be deterministic.
Location of wildcards, namespace of wildcard extensions, minOccurs and
maxOccurs values are constrained, and type restriction is
controlled.
We'll look at these alternatives in more detail below.
It is worth noting that the structural limitations
introduced by W3C XML Schema's handling of determinism are a
consequence of W3C XML Schema's design and are not an inherent
limitation of schema-based structures. In RELAX NG, for example, none
of these determinism constraints apply.
9.4 Containers and XML Schema
It should be noted that W3C XML Schema does not permit validation
of containers with required or optional extensions. Effectively, W3C XML Schema
cannot specify that a particular extension is required or optional in
a wildcard element. It does have the process contents attribute that
controls validation of content, but there is no option that says a
particular extension is required. Languages such as WSDL SOAP binding extension have been
created to allow the specification of a container and required
extensions in containers like SOAP. The WSDL SOAP binding extension provides a new schema that merges the SOAP schema with the
SOAP extension schemas.
9.5 Alternative Extensibility and Versioning Techniques
There are a variety of alternative extensibility and versioning
techniques.
9.5.1 Using ##any
As shown earlier, a common design pattern is to provide an
extensibility point, not an element, allowing any namespace at the
end of a type. This is typically done with <xs:any namespace="##any">.
Determinism makes this unworkable as a complete solution. First,
the extensibility point can only occur after required elements in the
original schema, limiting the scope of extensibility in the original
case. Second, backwards compatible changes require that the added
element is optional, which means minOccurs="0".
Determinism prevents us from placing a minOccurs="0" before an
extensibility point of ##any. Thus, when adding an element at an
extensibility point, the author can make the element optional and lose
the extensibility point, or the author can make the element required
and lose backwards compatibility.
Forwards compatibility with required elements can be retained
because the sender can send the new required element and the receiver
should simply ignore it. The solution provided in this finding provides
a superior solution for extensibility near optional elements and
backwards compatibility.
9.5.2 Using ##other
Another common design pattern is to use an extensibility point
allowing other namespaces, <xs:any
namespace="##other">, for extensibility. While this option
is obviously useful for adding distributed extension and avoids
determinism problems, it does not allow backwards or forward
compatible changes. In order to add an extension element to an XML
fragment, it must be in a new and separate namespace. The option of
adding an extension that is in the same namespace is not allowed using
##other. Critically, this means that a change without changing a
namespace or adding a namespace cannot be done. The owner of the
namespace will typically change the namespace name or element names
when making changes. That means that all receivers
that are not updated will reject the messages. This effectively forces
the big bang approach.
The namespace owner could use a new namespace for the compatible
changes. This technique suffers from a number of problems. An
extension in a different namespace means that the newer schema cannot
be validated. Specifically, there is no way to take a schema with a
wildcard, such as SOAP, and then create a new Schema that constrains
the wildcard. For example, it is not possible to take the SOAP schema
and require that foo and bar elements are required to be children of
the header element. Indeed, the need for this functionality spawned
the message and part constructs in WSDL. The ordering of the
extensions cannot be controlled. It results in specifications and
namespaces that are inappropriately factored. In the callback with
expires example, a high cohesion design means that expires belongs in
the callback namespace and not a new one. Further, the re-use of the
same namespace has better tooling support. Many applications use the
schema to create the equivalent programming constructs. These tools
often work best with single namespace support for the "generated"
constructs.
To a certain degree, we've combined these two designs together to
produce a design that achieves extensibility and is compliant with W3C
XML Schema's determinism constraint. The namespace name owner can add
backwards and forwards compatible changes into the extensibility
element, and other authors can add their changes at the wildcard
location.
9.5.3 Using Type Extension
Extending languages in W3C XML Schema can also be accomplished
by the use of derivation. For extension, the new type must have all the
existing elements and attributes and may add new elements or attributes.
Consider a callback example using
<xs:any namespace="##other">
that has the conversation identifer element as an option in the
extension. Using extension, this might appear as follows:
<s:schema xmlns=http://example.com/2003/02/soap/callback/
xmlns:wscb="http://example.com/2003/02/soap/callback/">
<s:element name="CallbackExtended"
type="wsdb:CallbackExtendedType"/>
<s:complexType name="CallbackType">
<s:sequence>
<s:element name="callbackLocation" type="s:anyURI"
maxOccurs="unbounded"/>
<s:any processContents="lax" minOccurs="0"
maxOccurs="unbounded" namespace="##other"/>
</s:sequence>
<s:anyAttribute/>
</s:complexType>
<s:complexType name="CallbackExtendedType">
<s:complexContent>
<s:extension base="wscb:CallbackType">
<s:sequence>
<s:element name="conversationID" type="s:anyURI"
minOccurs="1" maxOccurs="1"/>
<s:any processContents="lax" minOccurs="0"
maxOccurs="unbounded"/>
</s:sequence>
<s:anyAttribute/>
</s:extension>
</s:complexContent>
</s:complexType>
</s:schema> And instance of the extended type would appear as:
<CallbackExtended xmlns="http://example.com/2003/02/soap/callback/">
<callbackLocation>
http://example.com/foo/CallbackService
</callbackLocation>
<conversationID>
http://example.com/convid/5
</conversationID>
</CallbackExtended> Looking at the instance, how does a receiver "know"
that the CallbackExtended element is of type
CallbackExtendedType, which is an extension of
CallbackType? It must examine the schema for the CallbackExtended
element.
In a closed environment, the new types may be retrievable and type substitution is acceptable. An example of this could be XML Query.
In an open environment, the receiver wouldn't have the schema available since the
receiver was only programmed to support the original Callback.
Dynamically retrieving schemas to figure out what has happened poses
many risks, including security and performance. This is the
fundamental difference between using <xs:any> and
W3C XML Schema extension. <xs:any> allows
extensions to be added and does not require that the new schema is
available to the older software (if processContents is
"skip" or "lax") whereas W3C XML Schema
extensibility requires the newer schema. Note also that the W3C XML
Schema extensibility model does not permit the same element name and
namespace to be be used for the newer version. This is because W3C
XML Schema rightly does not allow duplicate element name declarations.
Another important language decision is "When should wildcards
be used versus type extension?" This is a very difficult
judgment call. One rule of thumb is that type extension is for lower
level constructs in a particular namespace and wildcard element are
for higher level constructs. Higher level constructs are those that
are intended for extension by 3rd parties or those where backwards or forwards
compatibility is a goal. Care must be taken when combining wildcards
and allowing derivation. For example, the common pattern of using
##other in extension points precludes derivation in a different
namespace, such as a newer version of a specification.
9.5.4 Substitution Groups
Substitution groups are another technique for extensibility. This
is similar to type derivation, as a new type is created that can be
substituted in for an existing type. The new type is merged in to the
schema at the substitution point, and the base type is left as-is. The same trade-offs for Type extension apply for substitution groups.
9.5.5 Redefine
Insert text...
9.5.6 Comparison Summary
These comparisons demonstrate that wildcard extensibility is the only
W3C XML Schema mechanism that allows backwards-compatible and forwards-compatible
changes without updating older software, particularly in open environments. Using ##any
or ##other do not provide the ability to re-use namespaces
and introduce compatible changes. Type derivation and
substitution groups require an exchange of schemas, which
may not be appropriate in an open environment.