2 What is State
As defined by FOLDOC, state is how something is; its configuration,
attributes, condition or information content. We will use the term component
to include software and hardware "things". Virtually all components have
state, from applications to operating systems to network layers. State is
considered to be a point in some space of all possible states. A component
changes from one state to another over time when triggered by some kind of
event. The event could be a network message, a timer expiring or an
application message. Components that do not have state, that is there is no
trigger that causes a transition, are called stateless. Most interesting,
particularly personalized, components have state of some kind, which is what
allows them to provide personalized information when interacting with user
agents on the Web. This finding concerns itself primarily with the following
kinds of state:
application state, which broadly is the state of a particular
application;
resource state, which is generally the state related to a resource
identified with a URI. In the Web context, typically application state
will align with resource state, that is the state of the resources is the
state of the application. One aspect of resource state is sub-resource
state, that is resources that do not (and arguably should have been)
themselves separately identified by a URI...for example, a bank account
that is identified by a bank account number stored in a cookie, rather
than in a separate URI;
per user or per session state, which can cause a resource to
interact differently according to the user making the access or the
network connection on which the request is received;
This finding starts from the perspective that truly stateless systems are
uninteresting. Further, most systems that are advertised as stateless are
actually incorrectly characterized or they are doing state management
someplace else in the system. The real questions of system design with
respect to state is where and how the various types of state will be managed,
and who has read/write access to the state. The decisions for state
management are taken in the broader context of overall system design. This
finding will look into how state, such as authentication information and
application state, is exchanged in a Web and Web services context. It will
examine the trade-off in properties between simplicity in server design
versus simplicity in component design, and explore additional properties such
as scalability, reliability, and performance.
3 State in
applications
The state in a distributed system may exist across a large variety of
applications that comprise the system. A stereotypical Web application will
have a web browser communicating with a Web server. The Web server is the
first point of contact for the application, which could consist static HTML
pages, PHP generated pages from a mySQL database, a Java application running
in an application server communicating with a high-end SQL database, and many
more configurations. Despite many years of best efforts to insulate or
abstract application design from the underlying components, it is a reality
that the allocation of state to the components and the selection of
components are directly coupled.
3.1 Browser State
The Web browser is one half of the design of state in a Web application,
and it has specific state items that it can manage. It is important for our
analysis to point out that a client that stores data related to an
application, such as username/passwords for URIs, should be considered a
stateful application. Web browsers are stateful clients because they store
state, despite being typically mislabeled as "stateless". It is even more
useful to analyze the type of state that browsers store and manage. Typically
the web browser state is roughly related to the amount of information that
the user has typed in or configured, which has natural limits. We find that
generally the state managed by the web browser (aka web browser state) is not
what one would consider large in today's computing terms. For example, web
browsers are not storing multiple megabytes of data (like a digitized
signature) per URI. There are additional state aspects of browser
interactions that may be stored. There is a modestly popular firefox
extension that will store and allow reload of the entire browser session,
such as all the open windows. The pages being viewed is another application
specific type of state that can be stored and managed. An incomplete list of
state managed by web browsers is: cached pages; username/password per realm;
cookies; form auto-complete data; previously viewed pages (history);
currently viewed pages; home page; configuration settings such as text sizes,
colors, fonts, etc.. This is a fairly extensive list of state being
managed.
In addition to state that the application directly understands and
manages, there is state that may be managed by the browsers but that is
evaluated or interpreted at the server. A primary example of this is HTTP
cookies. The state inside a cookie, including the variation where a session
id is in the cookie, is opaque to the browser. It is the server application
that has read/write access to the state.
3.2 Server State
Probably the primary software component that manages state is a server,
from ftp to web to application server. [FOLDOC]
provides a useful and interesting definition of stateful versus stateless
servers. "A stateless server is one which treats each request as an
independent transaction, unrelated to any previous request. This simplifies
the server design because it does not need to allocate storage to deal with
conversations in progress or worry about freeing it if a client dies in
mid-transaction. A disadvantage is that it may be necessary to include more
information in each request and this extra information will need to be
interpreted by the server each time. An example of a stateless server is a
World-Wide Web server. These take in requests (URLs) which completely specify
the required document and do not require any context or memory of previous
requests. Contrast this with a traditional FTP server which conducts an
interactive session with the user. A request to the server for a file can
assume that the user has been authenticated and that the current directory
and transfer mode have been set.". This definition, while true, is very
easily open to misinterpretation. Many of the Web applications that are built
on top of a Web server are very stateful. They may have log-on sessions,
application sessions like shopping carts, etc. that all use context or memory
from previous requests. The design decision of a stateful application over a
stateless connection (aka Cookies with Session IDs or EndpointReferences with
Reference Parameters) versus a stateful application over a stateful
connection (aka FTP) is a very detailed decision, and not nearly as obvious
as it might seem.
This definition, and the subtleties contained therein, touch on the heart
of this finding, which is that design state in systems is part of a complex
task that requires detailed analysis.
Many Web and Web service applications deployed today use stateful servers
because a stateful server achieves desirable characteristics in the system.
For example, many if not most banking systems use stateful servers in order
to achieve high reliability, performance, scalability, and availability. One
of the trade-offs is touched on by that FOLDOC definition, which is that high
performance systems do not need a simpler server design and are prepared for
the costs associated.
4 State
decision factors
The decision on where to place the state in the distributed application
and how to identify the state are affected by numerous factors. Some of the
key considerations are scalability, reliability, network and application
performance, security, ease of design and promoting network effects on the
World Wide Web, I.e. leveraging and contributing to a single, global
information space
Roy Fielding argues in his REST dissertation [REST]
that stateless server has the benefits of increasing reliability,
scalability, visibility and while potentially decreasing network performance.
However, I believe the trade-offs from an application developers perspective
are somewhat different, and need to be examined from a holistic
perspective.
4.1 Ease of
Application construction
There are two primary types of designers that are relevant: the network
administrator that controls the deployment of applications and publication of
URIs, and the application developer that controls the contents of messages
including http headers. The application developer can develop the application
without affecting the URI with the state id information and so avoid a
potential conflict with the administrator.
Many, if not most, applications are built to exchange state information
that is not "identifying" information, such as session ids. This is evidenced
by the widespread use of HTTP Cookies. In the cases where these applications
are also exchanging identifying information, the application development is
simpler when the same mechanisms are used for exchanging both types.
Examining the Web example, the application developer can easily insert and
parse information in the cookie header, rather than rewriting the URI that is
sent.
In the Web services example, it is very easy to do dispatch based upon a
soap header block, which is an XML QName. The tree-like structure of XML and
use of SOAP and SOAP Header blocks means that an application developer can
use widely available tooling, such as JAX-RPC handler chains, that makes it
easy to use the XML QNames. On the converse, there are no standards available
for inserting or parsing a QName(s) into or from a URI.
It is worth explicitly noting that there is a trade-off between the
control over the URI versus other parts of the message body, and a trade-off
between the ease of updating/parsing URIs and the other parts of the message
body.
4.2 Security
Security is a primary consideration in all application design. In most
systems, the "owner" will attempt to keep as much of the information, type
data as well as instance data, as hidden as possible. The typically security
considerations are ensuring that the right people can access the right data,
and that the data cannot be altered. This usually breaks down into
authentication, authorization, encryption, and integrity. The decisions
around security are usually coupled together and dependent upon the
technologies available.
In the Web context, some of the primary technologies available are HTTP
Authentication, SSL/TLS, and Cookies.
Cookies and sessions are a good example of the interdependency of the
decisions. If a cookie is storing state, aka parameters, then there may be
less difficulty in guessing legitimate values for possible state parameters
including username/password. Malicious clients could "guess" the state values
in an effort to subvert the application's security. A solution is to have the
server sign the state information before it gives it back to the client and
verify the integrity of that signature before accepting state information
from the client. One feature of session IDs is the relative difficulty of
guessing a valid session ID. It is much easier to assign a large session ID
as an indirect reference to the state information that to sign/validate state
within each communication.
Another trade-off is which parts of the application can be signed or
encrypted. SSL has been widely deployed specifically to sign and encrypt the
HTTP body. Putting username and password in a URI is obviously a bad idea
because anything seeing the URI, like an intermediary, can see the username
and password. The same concern is true for any other information that might
be considered sensitive, such as as account numbers or personal information.
Another part of the application design is how much information is sent to the
client. A stereotypical concern is that a browser may be operated from a
Kiosk which may not be secured. Storing any information at all on the client
may be inadvisable. This may suggest a design where no information is stored
in a Cookie.
4.3
Performance and Scalability
Performance is the time to complete a given request for a given load on a
system. Scalability is the availability of necessary resources for a request
under a given load. Performance and scalability are often coupled together
into the notion of "availability". The performance/scalability trade-off is
whether the cost of acquiring the necessary resources for a request is best
served with the state on the client or on the server, and that completely
depends upon how the resources are freed up and then re-allocated. The
resources can be processes, threads, memory, cpu cycles, database
connections, network connections. Allocation and re-use of the resources
happens on a per-resources basis. For example, most applications use database
connection pooling but they typically gain the functionality from middleware
of some kind. Typically scalability is usually specified in terms of
performance under various loads on a system.
In the simplest case, it may be that not freeing up the resources for an
amount of time (aka caching) is the most scalable. Keeping the state in
memory, with a time-out optimized for typical client latency, can scale
better than release resources when the time-out is set correctly and the
resource acquisition/freeing is significant. Anecdatally, Jim Gray coined the
"five minute rule" as a historically accurate cut-off time for caching in
memory rather than persisting to disk for random access.
In other configurations, it may be that it is "cheaper" to free up
resources by responding with the session id in the response and persisting
the data to the database rather than responding with the entire state to the
client because the "cost" of transmitting to the client is more expensive
than the cost of sending to the database. Likewise, it may be "cheaper" to
reify the session by acquiring it from the database than from the client.
However, the cost of freeing up state and recovering state is based on a
variety of factors, specifically the system architecture and the connections
to the client and database, the middleware software, the database software,
and hardware/software platforms used for the system.
The optimum performance/scalability curve is flat, that is the performance
of a request does not vary with the # of requests. However, this is typically
impossible so a linear curve is the most desirable. A linear curve usually
becomes logarithmic under heavy load. The typical curve then is flat, then
linear, then logarithmic. The various solutions for performance and
scalability are simply about adjusting the curve.
TBD: slight discussion on clustering with session ids?
A goal of high end systems is to provide high performance, high
scalability, and linear decay in performance. This may be only possible with
a stateful configuration with components like a "write-through" cache. A
write through cache is where reads hit the cache, writes flow through to the
back-end system and the cache is refreshed.
TBD: elaborate a bit on stateless going to the DB vs stateful perf.
elaborate on modern load balancing/session mgmt doesn't mean state is
"pinned"
4.4 Reliability
Reliability of Stateful applications has three distinct aspects:
reliability of the hardware, reliability of the software, and reliability of
the network. The reliability of the network is not typically a factor in the
design of the application style, as it is typically assumed that the network
is unreliable. The aspect of reliability that concerns this writing is
hardware and software reliability which we will collectively call "machine"
reliability. For a given client, the two time periods of interest are during
a request and in between requests.
In a stateless application design, a machine can fail between a request
without affecting the clients view of the system. They send a request and it
is dispatched to an available machine. If a machine has crashed in between
requests, there is no disruption.
In a stateful application design, the systems can be designed to handle
failures between a request. Common techniques are duplicating the state _
RAID disks, back-up nodes _ and hardening the system _ UPS, memory checksums,
etc. For example, an application server can have a primary and backup node.
If a machine fails, then the backup node is used for subsequent requests.
Stateful and stateless application design must deal with the situation of
where a machine crashes during a request. In stateless applications,
typically the request is lost. Let us make a simplifying assumption that the
request is "atomic" and is either completed or aborted. This allows us to
avoid the problem of determining application state where the problems of
meaning of reliability in a synchronous environment arise. Many systems are
designed to handle machine failure during processing by having a stateful
"dispatcher" that has tracked the request and can replay the request to a
different machine if one fails during a request.
Related to Reliability is manageability, as systems are often managed for
reliability. For example, a component may be starting to behave erratically
and the administrator wishes to replace the component. Stateful and stateless
systems would probably be designed for this task by letting the requests
"drain" off of the system that is due for maintenance. A stateful system has
the downside that the states may be long-running and hence take longer to
"drain". Advances in application server technology provide for managing these
by supporting "transferring" state from one machine to another.
The discussions so far have not discussed "client" reliability. Web based
systems typically have a simplifying assumption that browsers are for a
single user, are unreliable, and responses must be received within about 30
seconds for good HMI design. We have made a simplifying, but erroneous
assumption that systems where the client has the state are "stateless". The
state always exists somewhere, and in many EAI and B2B systems, the web based
simplifying assumptions are not true. The system, whether it is the client or
the server or the network, must contain the state. Imagine a system where the
client keeps the state for long periods of time, it must deal with
reliability of the state information. If a machine crashes, the system can't
lose the state.
Stateful systems can deliver virtually the same reliability as stateless
systems, it is more appropriate described as a matter of cost. A stateful
system may require more costly infrastructure in the form of components
selected to achieve the same reliability. On the other hand, the difference
between the reliability for a stateless system versus a stateful system may
be small given the overall reliability desired.
TBD: Improve text to hit the point that many systems are not like the
human-centric web wrt state that is cached..
4.5 Network
Performance
TBD
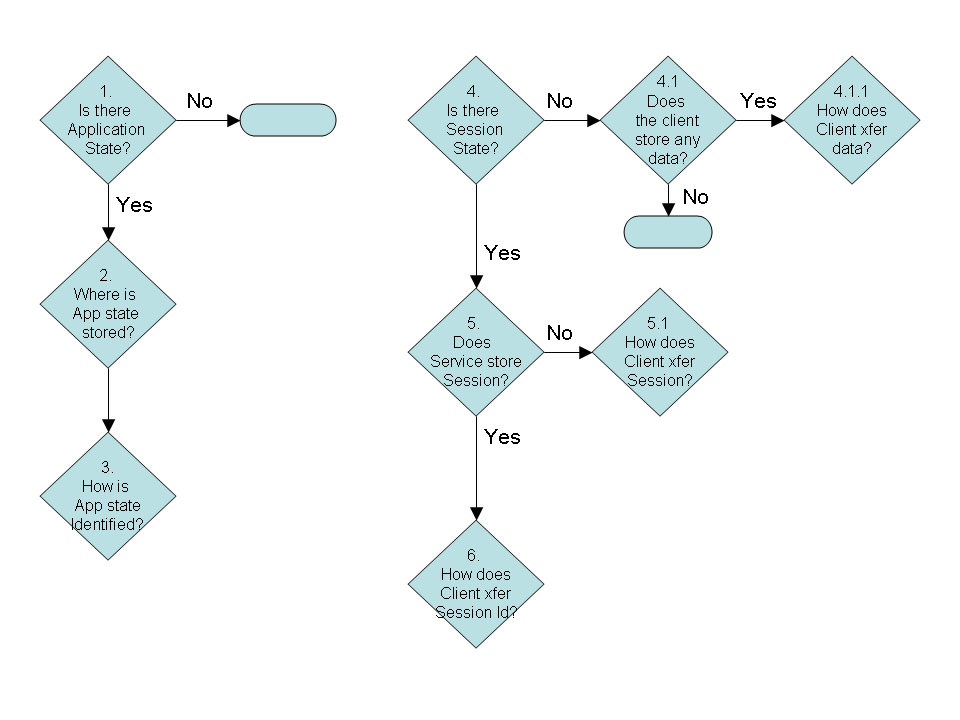
5 Decisions
There are a number of decision regarding state that are invariably made in
distributed application design. These are shown below in 2 flowcharts:
It is possible to never store the data on the client or the server.
However, applications are almost never designed for completely stateless
clients and servers. In a browser based application, it would be very
frustrating to enter username and password for every request. This is why the
browser stores username/passwords, as well as cookies. Realistically, the
choice is whether to store the data used to create the state, such as
username and password, on the client or whether there is session state, such
as "logged-in".
If the client is stateful (yes to question #4.1), then the data that is
stored in the client is sent to the service for each request. If the decision
is to store the state ( rather than data used to create the state), the next
decision (#5) is whether the state is stored on the client or the server.
Note that applications where the client stores data, beit data for recreating
state or the state itself, are typically (and erroneously) called stateless
applications, even though there is state on the client.
For Web messages, the location of the state id can only be in the URI, in
an HTTP header or in the message body. It is possible to express state in the
protocol operation or method but that is very rarely done so we will exclude
that possibility.
A number of examples will show a variety of decision combinations for Web,
XML and Web service technologies.
6 Abstract Example
This section introduces an abstract example which will be elaborated in
subsequent sections.
Dirk decides to build an online banking application. Customers can view
their consolidated accounts, an individual account, previous transactions,
and can make transfers. The site is made secure by encrypting and signing the
information and requiring a username/password to access the pages. When the
customer selects the accounts view, the banking application will ask them for
their username and password. If they have already entered their username and
password, they will not be asked for it again. The system will automatically
log the customer out if they have been idle for 10 minutes.
This is a stereotypical stateful application. It introduces an application
that involves two types of state: persistent application state for the
account and session state for logging in. The bank account application
obviously has account balance state and it is stored in the server, though
clients may have a local copy of the state. The session state may be realized
by storing state on the client or on the server. The example is considered
abstract because it is independent of the underlying technology choices, such
as HTTP, Cookies, SOAP, WS-Addressing, etc. The example will be elaborated in
HTML Browser and XML based interactions. Many applications for security
and/or regulatory reasons have a more thorough security design, such as
two-factor authentication. However, we choose to keep this simple application
as illustrative of the issues related to the design of state in
applications.
7 Stateful Resource
Identification
The identifier structure for the resources is a primary decision in state
design. In the banking application with account state, we will examine 2
different URI designs: one URI per resource or one URI for all
information.
7.1 URI per resource
The URI per resource design has a distinct URI for each of the resources,
such as user, account or transaction. The user clicks on the login, and this
redirects them to a unique URI for their account. The URI per account design,
sometimes called "deep-linking", has all the network effect advantages that
the web has to offer: the users account is bookmarkable, exchangeable,
etc.
Dirk decides to use the URI per resource design. He specifies the URI
structure for each of the resources, such as account summary and detailed
account information.
GET /useraccounts/123456789 HTTP/1.1
Host: www.fabrikam.com
GET /account/1010333010202 HTTP/1.1
Host: www.fabrikam.com
This design has security concerns as the user number and account are in
the URI. The user number and account could be encrypted in the URI, with
obvious increase in complexity. It does suffer from other potential increased
complexity as it may be easier to populate and parse the data from someplace
other than the URI, such as FORM POST or cookie data. Another problem with
selecting a URI that takes them to say 'cleared checks for my savings
account' then if the website is redesigned (a frequent event, at least on the
back end) then that URI will break. Either that or the website has to
maintain complex mapping tables to handle versioning URIs across multiple
versions of the website. Hence many websites would rather just force users to
come in through a well defined home page and then focus on making navigation
as easy as possible to get them quickly to where they want to be.
7.2 URI for all
resources
In the URI for all resources design, there is a "dispatch" URI and the
particular resource requested is encoded in the request message or headers.
For example, after logging in, the http cookie contains the user id. When the
user requests the generic page, the particular user id is sent in the cookie
data. Another example is the use of HTTP FORM POST data for the account
identifer. This has security advantages as the information can be
encrypted
GET /bankinfio HTTP/1.1
Host: www.fabrikam.com
Cookie: $Version="1"; useraccounts="123456789"
POST /bankinfio HTTP/1.1
Host: www.fabrikam.com
account="1010333010202"
8 Session State
The design of session, whether stateful or stateless, and how the
information is transmitted is another key decision.
8.1 HTTP
Authentication
Dirk now has to decide about security. He decides that the banking
application will maintain no session state on the server and the client will
send any necessary data for each request. The application has a URI for the
entry page to the banking application and a link to the account balances.
When any banking URI is requested, the username/password features of HTTP are
used, usually implemented as a pop-up window asking for username and
password.
GET /acct/123456789 HTTP/1.1
Host: www.fabrikam.com
user-pass: username:password
Note: user-pass is shown for relevence and convenience and the actual HTTP
Authorization header would be different than shown above.
There are very few web sites that are built in such a stateless server
manner, perhaps the largest is the W3C web site. Most web sites use
alternative technologies for logging in and they store the state using HTTP
cookies or using URL rewriting. The primary reasons for customized security
are ease of use concerns, particularly wanting direct control over the look
and feel of the screens including helpful tips and links to forgotten
passwords. There is some debate over whether this helps or hinders security
concerns, that is wanting greater control over the security timing out.
8.2 URL Rewriting
with session in the URL
Dirk decides that a customized security screen is needed. A new page with
the entry of username and password is inserted in the application, after the
"show item" page in the state flow. At first, Dirk was going to have the URL
contain the username and password. From a state analysis perspective, there
is no significant difference between storing a username/password per URL or a
URL that contains a username/password.
GET /acct/123456789?user=username&pwd=password HTTP/1.1
Host: www.fabrikam.com
A key difference is security, so the URL containing username/password was
rejected for obvious security reasons. Upon successful completion, the URL is
rewritten to contain the state that the user has logged on. After the
security page, any URLs in pages returned are rewritten to contain the state
and the state is encrypted to prevent tampering and guessing. Dirk has
quickly moved into a decision that the application will have session
state.
GET /acct/123456789?sessionid=5
Host: www.fabrikam.com
Alternatively, Dirk includes a session ID in the URL. If the session has
expired, the user will be redirected to the log-in page.
The URL with session id approach has a security downside because the
session id is in the URI, whereas other solutions will enable the session Id
to be more secure by having the session id in the body of the message. A
modest downside because it is unlikely that URLs with a particular users
login state need to be exchanged or bookmarked. From a modeling perspective,
the resources that would likely be identified are accounts and particular
transactions, not login state. If the user ever forwarded or bookmarked the
URL, the login state will be useless at best and confusing and inefficient at
worst. In some domains, it may be difficult for the application to have full
control over the URL and do the rewriting to include the session and it may
be difficult for the application to parse the URL to extract the state.
Stepping back a bit, the issue is that the application state (the account)
and the session state( login state) may need to be independent for a variety
of reasons.
8.3 Cookies with client-side state
HTTP Cookies offer the benefit of a well-defined place, the HTTP Cookie
header, for storing and retrieving data without rewriting the URL.
Nadia decides to change the banking application to store the application
state in a cookie. The application still has URIs for the banking application
page. The application stores the state in a cookie that is sent to the
browser upon successful completion of the page, and sent back to the service
on every request.
GET /acct/123456789 HTTP/1.1
Host: www.fabrikam.com
Cookie: $Version="1"; user="username"; pass="password"
Yet still, very few web applications are built this way. Most secured web
sites use cookies where the state is stored on the server, rather than
encapsulated in the client. The motivations are primarily about security,
particularly giving the serviced application the control over whether to keep
the state in memory or passivate to disk. Again, storing the state in a URL,
in an HTTP Cookie (which is a special HTTP header) or in an HTTP
Authentication special memory area all make the client stateful. In general
application design, there are other concerns around client-side state as the
state could get quite large so the constraints on the client storage could be
onerous, it may be difficult to serialize and so serialization to the client
could be difficult, or the network performance could be significant. Cookies
do have two modes of storage, persistent (to disk) or transient (in memory
only). Transient cookies offer somewhat more security than persistent
cookies.
8.4
Cookies with session ids
Nadia further updates the banking application to store the log-in state in
a server side component. The server-side component is identified with an id,
commonly called a session id. This session id is stored in the cookie.
GET /acct/123456789 HTTP/1.1
Host: www.fabrikam.com
Cookie: $Version="1"; sessionid="5"
In this example, the application has 2 different types of state
information that are being identified: the account balance and the session
state. By putting the account id in the URI and keeping the session id
separate, the application has achieved the network effect of re-usable URIs
for the account and separately managed transient session information.
9 XML interactions
The previous examples showed how browser based technologies support
stateful clients and session based interactions. There are also the same
issues in similar XML interactions.
9.1
URI per resource with HTTP Authentication XML example
Dirk is tasked with making the banking application available as a Web
service rather than HTML pages. He uses XML to do this. All the possibilities
shown in the previous HTML example are available for XML. For example, he
could use HTTP Authentication to return an XML document with the balance.
GET /acct/123456789 HTTP/1.1
Host: www.fabrikam.com
user-pass: username:password
returns:
<Balance acct="123456789">2000</Balance>
9.2 URI for all resources with XML for
all content
XML and HTTP POST gives Dirk the option to send XML in the HTTP Body. He
decides that the banking application is a service with an interface
containing two operations: getBalance and log-in. The first operation is a
log-in operation. If successful, it returns an XML document containing a
session ID that client should use for requesting the account information.
POST /bankinfo HTTP/1.1
Host: www.fabrikam.com
<Login>
<username>foo</username>
<password>bar</password>
</Login>
response:
<LoginResponse>
<status>OK</status>
<SessionId>5</SessionId>
</LoginResponse>
A request to the service, such as "GetBalance", might have a fragment
like:
POST /bankinfo HTTP/1.1
Host: www.fabrikam.com
<GetBalance>
<Account>123456789</Account>
<SessionId>5</SessionId>
</GetBalance>
response:
<Balance acct="123456789">2000</Balance>
We see 2 very different styles of design. The first makes full use of HTTP
as an application protocol. The client and server use and understand HTTP
fully, by using the HTTP GET operation, HTTP Authentication and a URI per
resource. The second application makes very little use of HTTP, as it uses
HTTP POST to a single URI for all operations and it has custom
authentication. This is sometimes characterized as "HTTP Tunnelling" or HTTP
as Transport.
The use of HTTP and it's characteristics, particularly it's operations,
versus HTTP as transport is a the heart of these two styles. The use of many
URIs and HTTP Get is at the heart of the Web architecture and achieving all
the benefits that can accrue (see Web arch).
The use of HTTP as Transport does offer advantages. A primary advantage is
that the login and getBalance operations are independent of HTTP. This means
that it is easier to write applications that are transport independent, that
is the messages can easily be sent over other protocols such as JMS. The WSDL
portType fragment for an account service is:
<definitions xmlns="http://schemas.xmlsoap.org/wsdl/" targetNamespace="http://example.com/account">
<portType name="AccountPortType">
<operation name="GetBalance">
<input message="tns:GetBalanceInput"
wsaw:Action="http://example.com/GetBalance"/>
<output message="tns:GetBalanceOutput"
wsaw:Action="http://example.com/Balance"/>
</operation>
<operation name="Login">
<input message="tns:LoginInput"
wsaw:Action="http://example.com/Login"/>
<output message="tns:LoginOutput"
wsaw:Action="http://example.com/LoginResponse"/>
</operation>
</portType>
</definitions>
There are no currently widely deployed description languages for the HTTP
example. Shortly, we will show a WSDL with a SOAP binding and WS-Addressing
that provides for description of the protocol independent messages. This has
the significant advantage that large numbers of operations can be
described.
Before moving to a Web service example, we show that the session Id could
be represented as an HTTP Content-Location header
GET /acct/123456789 HTTP/1.1
Host: www.fabrikam.com
user-pass: username:password
Response:
200 OK
Content-Location: http://www.fabrikam.com/acct/12345689/?sessionId=5
<LoginResponse>
<status>OK</status>
</LoginResponse>
Followed by
GET /acct/123456789?sessionId=5 HTTP/1.1
Host: www.fabrikam.com
response:
<Balance acct="123456789">2000</Balance>
This design appears to be a good middle ground. There is a "base" URI for
the account and then a new URI minted for each session id. It utilizes XML
for responses and HTTP URIs fully. However, almost no XML toolkits make this
scenario simple. There is not strong support for HTTP headers such as
Content-Location in various language toolkits.
9.3 Web service
example
Dirk is tasked with making the banking application available using SOAP
and WS-Addressing technologies in addition to XML and WSDL. The first
operation is a log-in operation. If successful, it returns a WS-Addressing
"ReplyTo" containing an EPR that client should use for requesting the account
information. The EPR contains a reference parameter that contains the session
id and a reference parameter that contains the account id.
<S:Envelope xmlns:S="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:fabrikam="http://example.com/fabrikam">
<S:Header>
...
<wsa:To>http://example.com/fabrikam/acct</wsa:To>
<wsa:Action>http://example.com/fabrikam/login</wsa:Action>
...
</S:Header>
<S:Body>
<Login>
<user>username</user>
<password>password</password>
</Login>
</S:Body>
</S:Envelope>
Returns:
<S:Envelope xmlns:S="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:fabrikam="http://example.com/fabrikam">
<S:Header>
<wsa:Action>http://example.com/fabrikam/loginResponse</wsa:Action>
<wsa:ReplyTo>
<wsa:EndpointReference
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:fabrikam=http://example.com/fabrikam>
<wsa:Address>http://example.com/fabrikam/acct</wsa:Address>
<wsa:ReferenceParameters>
<fabrikam:SessionID>5</fabrikam:SessionID>
</wsa:ReferenceParameters>
</wsa:EndpointReference>
</wsa:ReplyTo>
</S:Header>
<S:Body>
<LoginResponse>OK</LoginResponse>
</S:Body>
A request to the service, such as "GetBalance", might have a fragment
like:
<S:Envelope xmlns:S="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:fabrikam="http://example.com/fabrikam">
<S:Header>
...
<wsa:To>http://example.com/fabrikam/acct</wsa:To>
<wsa:Action>http://example.com/fabrikam/GetBalance</wsa:Action>
<fabrikam:SessionID wsa:IsReferenceParameter='true'>5</fabrikam:SessionID>
...
</S:Header>
<S:Body>
<GetBalance>
<Account>123456789</Account>
</GetBalance>
</S:Body>
</S:Envelope>
response:
<Balance acct="123456789">2000</Balance>
The WSDL for the previous is approximately
<definitions targetNamespace="http://example.com/account" ...>
...
<portType name="AccountPortType">
<operation name="GetBalance">
<input message="tns:GetBalanceInput"
wsaw:Action="http://example.com/GetBalance"/>
<output message="tns:GetBalanceOutput"
wsaw:Action="http://example.com/Balance"/>
</operation>
<operation name="Login">
<input message="tns:LoginInput"
wsaw:Action="http://example.com/Login"/>
<output message="tns:LoginOutput"
wsaw:Action="http://example.com/LoginResponse"/>
</operation>
</portType>
<binding name="AccountSoapBinding" type="tns:AccountPortType">
<soap:binding style="document" transport="http://schemas.xmlsoap.org/soap/http" />
<wsaw:UsingAddressing wsdl:required="true" />
<operation name="GetBalance">
<soap:operation soapaction="http://example.com/GetBalance" />
<input>
<soap:body use="literal" />
</input>
<output>
<soap:body use="literal" />
</output>
</operation>
<operation name="Login">
<soap:operation soapaction="http://example.com/Login" />
<input>
<soap:body use="literal" />
</input>
<output>
<soap:body use="literal" />
</output>
</operation>
</binding>
</definitions>
We see here all the pros and cons of the current Web services standards
compared to HTTP as transfer protocol. There are many vendors that have
implemented WSDL, SOAP, WS-Addressing. Thus interoperability between the
toolkits is heightened. The design time tools can interoperably use the above
WSDL to generate clients stubs and server skeletons. At runtime, clients and
servers from different vendors can interoperate.
There are downsides as well. This architecture is "off the web" and cannot
take advantage of any Web infrastructure such as browsers, caching, etc. This
is documented in [WebArch] There are many
specifications required, and they generally complicated. This can result in
incomplete and non-interoperable implementations.
9.4 EPRs "on the Web"
The WS-Addressing specifications do not provide a binding or mapping of
WS-Addressing Message Addressing Properties (MAPs), including EPRs, into an
HTTP request. Further, there does not appear to be any industry standard for
such a binding. Without such a binding, most if not all EPRs that are created
with Reference Parameters will not be available on the Web. All the example
URIs listed in the Web section could be used for application to application
communication.
9.5 Web services
authentication state
WS-Security specifies a SOAP header block for securing SOAP messages. One
form of WS-Security is the username/password, as specified in the username
token profile. Instead of implementing a custom "login" XML protocol,
WS-Security can be re-used.
<S:Envelope xmlns:S="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:wsse="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd"
xmlns:fabrikam="http://example.com/fabrikam">
<S:Header>
...
<wsa:To>http://example.com/fabrikam/acct</wsa:To>
<wsa:Action>http://example.com/fabrikam/GetBalance</wsa:Action>
<wsse:Security>
<wsse:UsernameToken>
<wsse:Username>username</wsse:Username>
<wsse:Password>password</wsse:Password>
</wsse:UsernameToken>
</wsse:Security>
...
</S:Header>
<S:Body>
<GetBalance>
<Account>123456789</Account>
</GetBalance>
</S:Body.
</S:Envelope>
This has the advantage of re-using the WS-Security mechanisms. It has the
downsides of using a fairly complicated specification when perhaps HTTP
Authentication would be simpler. WS-Security provide many more mechanisms and
functionality, but not secure sessions.
9.6 Web
services session
WS-SecureConversation specifies a security token that represents a
secureconversation. The context is negotiated prior to the application
request.
<S:Envelope xmlns:S="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:wsse="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd"
xmlns:wsc="http://schemas.xmlsoap.org/ws/2005/02/sc"
xmlns:fabrikam="http://example.com/fabrikam">
<S:Header>
...
<wsa:To>http://example.com/fabrikam/acct</wsa:To>
<wsa:Action>http://example.com/fabrikam/GetBalance</wsa:Action>
<wsse:Security>
<wsc:SecurityContextToken>
<wsc:Identifier>uuid:...</wsc:Identifier>
</wsc:SecurityContextToken>
</wsse:Security>
...
</S:Header>
<S:Body>
<GetBalance>
<Account>123456789</Account>
</GetBalance>
</S:Body.
</S:Envelope>
As of April 2006, there are few implementations of this specification. It
is progressing through an OASIS Technical Committtee. It is likely to get
wide adoption. As mentioned in the Web services and Web service security
sections, this specification may be far more than needed for an
application.