1 Preface
Of the many ways in which the Web can be extended, the provision for new URI schemes may be the most fundamental. URI schemes are often created to signal the use of new protocols for transfer of resource-related information. Embodied in such protocols are operations, such as GET, POST and DELETE in the case of HTTP, which determine the sorts of interactions that are possible with a given resource. The operations in turn determine the format and typing of information exchanged on the Web.
Precisely because so many aspects of resource naming and interaction are subject to change through introduction of URI schemes, new schemes can undermine the interoperability of the Web. [AWWW] explains why unnecessary proliferation of URI schemes must be avoided: "While Web architecture allows the definition of new schemes, introducing a new scheme is costly. Many aspects of URI processing are scheme-dependent, and a large amount of deployed software already processes URIs of well-known schemes. Introducing a new URI scheme requires the development and deployment not only of client software to handle the scheme, but also of ancillary agents such as gateways, proxies, and caches. See [RFC 2718] for other considerations and costs related to URI scheme design...Because of these costs, if a URI scheme exists that meets the needs of an application, designers should use it rather than invent one."
Conversely, the introduction of new protocols, operations, and data formats may sometimes be essential if the Web is to continue as a universal information space integrating the broadest possible range of resources. Already a wide variety of information is being shared through peer-to-peer protocols, many of which are not well integrated on the Web, and there is reason to believe that the highest quality multimedia feeds may not be best distributed and controlled through HTTP. Immersive user interfaces may require interaction protocols which are more flexible than those in in widespread use on the Web today, and so on. For such reasons, it is important to explore the tradeoffs involved in deploying new schemes, protocols and operations. This finding attempts to provide useful guidelines for the introduction and use of URI schemes and their associated protocols.
[RFC 2718] sets out guidelines and caveats for the creation of new URI schemes. This finding provides complementary information relating to the deployment of resources using such schemes, the design of protocols, the choice of operations to be supported, and the suggested behaviour of user agents. Indeed, this finding for the most part avoids restating principles already covered in [RFC 2717] and [RFC 2718]; readers are encouraged to become familiar with them before proceeding.
2 Terminology
This finding is intended to cover a broad range of information formats and protocols including client/server, peer-to-peer, streaming multimedia, multicast, etc. For convenience, the following client/server-oriented terminology is used except in cases where the extension to other protocols is unlikely to be clear:
- User agent
- A programmed entity, typically software, that uses a protocol to retrieve or update the state of a remote resource.
- Server
- A programmed entity, typically software, that maintains the state of a resource. Servers implement network protocols that support requests to retrieve (representations of) and/or to update the resource's state.
3 URI Assignment and Protocols
For schemes such as http and ftp, the association of a URI to a resource is defined in terms of the
corresponding protocol.
Thus, the resource identified by http://example.org/resource1 is by definition the
one for which representations are returned (GET) or updated (PUT) when that URI is supplied as the
HTTP Request-URI (see [RFC 2616]).
Unless otherwise stated, this finding deals only with such protocol-associated URI schemes.
Subtleties arise when such URIs are employed without deploying a server for the resource. For example, it is common to use XML namespace names based on the http scheme even when no server is providing representations for that namespace. Deploying such a server is desirable, but is not required by Web architecture. When there is no such server, the URI chosen SHOULD be consistent with eventual server deployment. So, in the case of HTTP, it is inappropriate to base a URI on a DNS name that is not registered, because the DNS name might later be assigned to an organization that would use it for a purpose inconsistent with serving representations of the resource. Similar considerations apply for other schemes and their associated protocols.
4 Gateway Proxies
In the simplest case, the protocol associated with the URI directly connects the user agent to the resource provider.
The Web also allows for gateway proxies, which convert from one protocol to another. In such cases, the server offers the resource using one protocol, but the user agent access it through another. For example, HTTP can be used as a proxy for the FTP protocol.
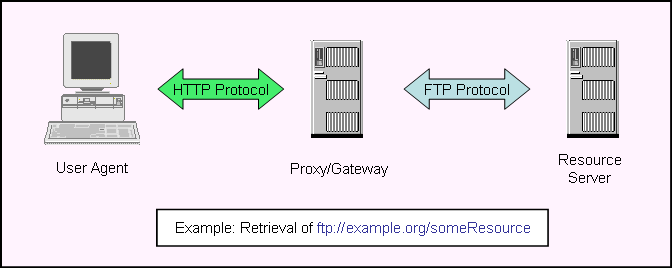
The following considerations apply to the implementation of gateway proxies:
URI references provided by the user agent MUST be translated into appropriate addresses or other resource indicators employed by the server. Note that the server protocol may but need not be Web-based, and may but need not use URI-addressing. In the example above, the FTP protocol predates the Web and does not use URIs in messages exchanged between the gateway and the resource server.
Operations requested by the user agent MUST be translated into suitable equivalents in the server protocol. In the example above, HTTP GETs presumably result in the FTP operations that open a connection, set an appropriate transfer mode (most likely binary), change to the appropriate server directory, and retrieve the appropriate file. The result of that retrieval must then be assigned a suitable MIME type and returned as an octet stream in the HTTP Response. The Web itself has no fixed standards for the degree of fidelity that is appropriate for any given gateway or pair of protocols, but the specifications for particular protocols or URI schemes may impose such constraints. For example, a gateway using HTTP as a proxy protocol must never map an HTTP GET into an unsafe operation on the resource. Gateways are not possible in cases where the mismatch between the operations supported is too great.
Similarly, the gateway is responsible for mapping the format and typing of information exchanged. Again, the Web architecture imposes no fixed standards as to the level of fidelity that is appropriate, but particular scheme and protocol specifications may. In the example above, the gateway is responsible for using heuristics or other means to assign media types to representations of FTP-based resources.
On the Web, URI names are typically used "on the wire" as the means
by which protocols identify resources to be accessed.
HTTP, for
example, uses a URI as its Request-URI.
When one such protocol is used as a proxy to another,
the two "hops" may or may not use the same URI.
When they are not the same, then there are two URI's identifying the same resource. (Strictly speaking, the two URI's name the resource and the proxy of the resource respectively, but for many practical purposes the effect is similar to having two names for the resource itself.)
[AWWW] explains the disadvantages of assigning more than one URI to a single resource.
For those reasons, protocols intended for use with gateways SHOULD
be designed to avoid
the requirement to generate such duplicate URI names.
HTTP, for example, provides for the use of non-http scheme URIs as Request-URIs; accordingly, the same URI can often be used on both "hops".
Conversely, URI duplication may be unavoidable when the gateway protocol
demands naming with a particular scheme.
| Editorial note | |
| Does this section us an appropriate mix of RFC 2119 "MUST"s and "SHOULD"s vs. more informal guidance? | |
5 Selection of Protocols by User Agents
This section discusses the means by which a user agent can select an appropriate protocol for accessing a resource.
The specification for a URI scheme determines the normative association of URIs from that scheme to resources. For protocol-based URIs, that association is typically defined in terms of the protocol (see 3 URI Assignment and Protocols). In such cases, a user agent can determine a protocol based on inspection of the URI, and in the common case where there is one protocol associated with a scheme, the scheme name directly determines the protocol. It is, for example, always acceptable for a user agent to attempt an HTTP connection to a resource named with the http scheme.
The means by which user agents determine that a gateway protocol is to be used are specific to each user agent. Using the example above, a user agent would require some configuration to indicate that ftp-scheme resources were in fact to be accessed using the HTTP protocol. This is similar to the other sorts of proxy configuration that are commonly required of Web browsers.
6 Protocol design: consistency of operations and formats (To Be Supplied)
This section has not been written. The paragraphs below are placeholders with reminders of possible topics to be covered.
To be supplied: explain that it's much easier to support new protocols in a user agent if the operations of that protocol are even generally similar to those of HTTP or other widely deployed protocols. So, a high def streaming video protocol may not support exactly an HTTP "Get", but if it supports something in the same spirit then a browser can probably provide a fairly consistent navigation experience as one goes from a web page to a movie and back.
To be supplied: similarly, if a peer-to-peer protocol supports retrieval of media typed octet streams, then browsers can use existing renderers, caches, etc. This will link to the AWWW GPN on reusing formats.
To be supplied: operations on the wire vs. operations at the endpoint. In HTTP, GET is visible both as a browser operation and on the wire. In peer to peer, you might have a very compatible operation at the browser that turned into all sorts of strange traffic on the wire. That's still a good thing to go for: if you can simulate as much of the HTTP "endpoint API" as possible, then you get a lot of browser compatiblity, even if the on the wire protocols are radically different.
7 References
- AWWW
- I.Jacobs, N. Walsh, Architecture of the World Wide Web. W3C. December, 2004. (See http://www.w3.org/TR/webarch/.)
- RFC 2119
- S. Bradner. Key words for use in RFCs to Indicate Requirement Levels. IETF. March, 1997. (See http://www.ietf.org/rfc/rfc2119.txt.)
- RFC 2717
- R. Petke, I. King Registration Procedures for URL Scheme Names. IETF. November, 1999. (See http://www.ietf.org/rfc/rfc2717.txt.)
- RFC 2616
- R. Fielding, J. Gettys, J. Mogul, H. Frystyk, P. Masinter, P. Leach, T. Berners-Lee Hypertext Transfer Protocol — HTTP/1.1. IETF. June, 1999. (See http://www.ietf.org/rfc/rfc2616.txt.)
- RFC 2717bis
- T. Hansen, T. Hardie, L. Masinter Guidelines and Registration Procedures for new URI Schemes. February, 2005. (See http://ietfreport.isoc.org/all-ids/draft-hansen-2717bis-2718bis-uri-guidelines-04.txt.)
- RFC 2718
- L. Masinter, H. Alvestrand, D. Zigmond, R. Petke Guidelines for new URL Schemes. IETF. November, 1999. (See http://www.ietf.org/rfc/rfc2718.txt.)
- RFC 3986
- T. Berners-Lee, R. Fielding, L. Masinter Uniform Resource Identifier (URI): Generic Syntax. IETF. January, 2005. (See http://www.ietf.org/rfc/rfc3986.txt.)