1 Introduction
This is an old issue, and people are tired of it. — Sandro Hawke, January 2003 [disambiguating]
In any kind of discourse it is very useful for an agent to be able to provide a definition of a term, in such a way that other agents can discover and use that definition in order to make sense of sentences that use that term, and to compose new ones.
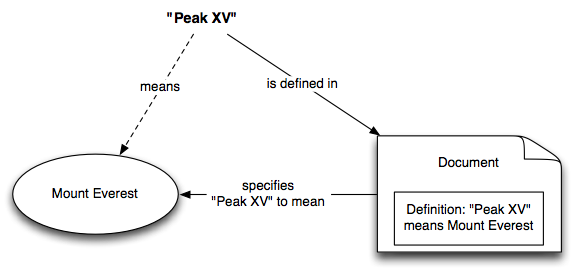
Suppose that Alice, in communication with Bob, uses the term "Peak XV" to mean Mount Everest, as in "Alice would like to climb Peak XV next summer". If Bob does not know what "Peak XV" means, he will have to find out. He might be able to ask Alice directly, although in many cases this will be impossible - Alice might be too busy, or otherwise unavailable. Lacking that option he must do some research, consulting dictionaries, encyclopedias, or search engines in the hope of obtaining the correct explanation of Alice's use of the term "Peak XV".
The essential idea is that there are one or more methods available to Bob by which he can discover bits of writing that explain what what Alice means by "Peak XV".
In this report, the terms being defined are URIs, and the bits of writing that might explain the meaning of a URI are called "definitions". URIs can be used to mean all sorts of things in many different technical contexts. Two contexts of special interest to this report are in natural language (e.g. "The W3C home page is 'http://www.w3.org/'"), and in declarative languages such as RDF and OWL.
The nature of definitions need not concern us here - many forms are familiar, including translation between languages (e.g. providing an English or Spanish term equivalent to a given term), descriptions (the term refers to an entity possessing some set of properties), explanation by example, axiomatic systems, and so on. Also not of concern here are the many ways in which meaning can fail as a result of what a definition says about the term in question, or how a term is used. Our concern is only with the method by which definitions are conveyed.
When the term in question is a URI, discovery methods include, in addition to those already mentioned, network protocols such as HTTP that involve the URI directly.
Definition discovery is not the same as Web dereference, however, since dereferencing a URI gives you information - i.e. the document, image, etc. specified by the URI - not necessarily related to defining anything. Care must be taken to avoid confusing the two operations. In theory dereference could play a role in explaining the meaning of a dereferenceable URI (see 5.6 'Hashless' URI dereferences to its definition (incompatibly)), but this is not generally done at present, since a dereferenceable URI refers to the information resource accessible via that URI, not to what that information resource defines or describes (see 7.3 Using a URI to refer to the information resource accessible via that URI).
The reason we define definition discovery methods is interoperability - so that everyone gets the same definition of each URI. We only need consensus on methods such as the ones surveyed here for URIs that are to be shared widely. If agents that use a URI in one way never use it in communication with agents that use it in another way, then it is OK for the URI to have distinct senses in the two communities, and there is no problem to be solved - each community can use the URI in its own way, and there will be no confusion.
The operative word here is "if". Isolation is fragile and means lost opportunities for synergy and unintended reuse; all the arguments in favor of a World Wide Web, which depends on the global nature of the URI vocabulary, apply here.
This report presents discovery methods in current use, reports some criticisms of them, and presents some new discovery methods that have been proposed to address the criticisms.
1.1 Glossary
This section defines terms that are used in this report. An attempt has been made to avoid gratuitous differences from the way these terms are used elsewhere, but in a few cases choice of terminology has been difficult and words with other meanings (such as "definition") are given technical definitions. These definitions are not being proposed for general adoption.
[Draft comment: All terminology choices are provisional; for most of them I am testing the waters to see how well the word works, and am prepared to change.]
- accessible via
- When a URI is dereferenceable, "the information resource accessible via a URI" (abbreviated IR(that URI), see below) is the information resource whose versions are the versions obtained by dereferencing that URI.
- definition
- A document or document part that provides information about the meaning of a URI or other kind of term. This term is not meant to be either rigorous or exclusive. The "information" could be prose, RDF, OWL, or some combination. It needn't be successful, specific, or comprehensive in defining the term in the ordinary sense of "defining". Rather, the term as used here refers to the role it plays in discovery. We might more accurately say "putative definition". [Draft note: Alan R: Is sound recording possible definition?]
- dereferenceable
- A URI is dereferenceable if it may be used with a standard access mechanism to retrieve information, or to perform some other action on an associated resource ([rfc3986] section 1.2.2). In particular, hashless http: URIs are dereferenceable if some HTTP method (or equivalent) is successful (2xx response). Some URIs belonging to some other URI schemes are also dereferenceable.
- fixed information resource
- A document, image, sound recording, or other replicable entity as encoded in an octet sequence, together with optional brief annotations, such as media type and language, intended to guide the interpretation of the content. There is no requirement that a given fixed information resource is accessible via any URI.
- hashless
- A URI is 'hashless' if it has no hash '#' sign or subsequent fragment identifier. 'Hashless URI' is synonymous with 'absolute URI' as defined in [rfc3986].
- http: URI
- A URI whose scheme (the part before the colon) is 'http' or 'https'.
- information resource
- Roughly speaking, something that is appropriate as the subject of metadata. See 7 Appendix. About information resources.
- IR(u)
- IR(u) is shorthand for the information resource accessible via URI u. For example, if 'http://example/image23' is dereferenceable, then IR('http://example/image23') is the information resource accessible via that URI.
- metadata
- Information about information, or about an information resource. In RDF, metadata might be written using vocabularies such as Dublin Core, FOAF, or CC REL.
- term
- A URI, word, name, or phrase that can serve in subject or object position in a statement. In an RDF serialization, for example, a term might be a qname, URI, or blank node label. In Turtle, a term might be any Turtle term, including one written using blank node [...] notation.
- refer
- For the purposes of this report, reference is just one way to mean. There may be other ways to mean other than to refer, but none are specified here.
- version (of an information resource)
- A fixed information resource associated with an information resource is a version of the information resource. [1]
2 Use case scenarios
Use cases need to be presented as being independent of any particular solution to be used, in order that the solution space can be explored more objectively. This leads to some frustrating vaguenesses in the following, but the vagueness is intentional and necessary.
2.1 Choosing a URI, providing a definition of the URI, using the URI
Alice wants to refer to a particular canoe being offered for sale. Alice "mints" a new URI (one that is not yet in use) with the purpose of using that URI to refer to her canoe. Alice publishes a document containing a definition of the URI, i.e. a document that would lead a reader to understand that the URI refers to the canoe.
Bob then learns of Alice's URI and uses it in a document of his own.
Subsequently Carol encounters Bob's document. Wanting to know what the URI means, she is led to Alice's published definition, which she reads. She is enlightened.
Any method for implementing this use case would need to explain: what kind of URI Alice should use (syntactic constraints); where and how should Alice should publish the definition so that it can be found; and how Carol might come to discover Alice's definition, given the URI.
2.2 Using a document as a definition by reference to its primary topic
Bob desires to refer to Chicago. He finds a Web page on the Web at 'http://example/about-chicago' (provided by, say, Alice) that consists of a description of Chicago, and wants to use it for the purpose of referring to Chicago. He chooses a URI and associates it with Alice's Web page in such a way that Bob's URI will be understood as referring to Chicago.
Carol encounters Bob's URI, is led to 'http://example/about-chicago' and thence to Alice's description of Chicago, and then somehow understands that Bob's URI is meant to refer to Chicago.
(This differs from the previous use case in that here Bob is not involved in the creation of the definition (the description of Chicago). The document about Chicago was not written with the purpose of defining Bob's URI - in fact Bob's URI doesn't even occur in it. Rather than look in the document for a definition mentioning Bob's URI, Carol must determine the topic of the document and take the topic as the meaning of Bob's URI.)
3 General definition methods in current use
This section describes how people currently implement the use cases.
3.1 Colocate definition and use
One way to lead someone encountering a URI to a definition of the URI is to make sure that the definition of the URI is propagated into in each document in which the URI occurs. This makes the definition easy to find, since anyone who encounters the URI will have in hand the definition that they need. The form of the URI in this case is arbitrary.
3.2 Link to documents containing definitions
Whenever using a URI to refer to something, provide, again in the document or message in which the occurs, a link to a document that carries a definition of the URI. This is the approach taken by OWL; the document containing the URI is related to the one from which the definition of the URI should be obtained via the owl:imports relation.[2]
The rdfs:isDefinedBy property might also be used for this purpose.
3.3 Register a URI scheme or URN namespace
Each URI scheme, e.g. mailto:, http:, ftp:, and so on, has its own URI scheme registration, accessible via a registry maintained by IANA [rfc4395]. A URI scheme registration helps to define the meaning of URIs using that scheme. For example, the registration for the data: URI scheme fully explains the meaning of every URI that uses that scheme, while the mailto: scheme registration explains that each URI refers to a particular mailbox, understood relative to the domain name system and the mailbox assignments made by each particular host.
Most URI scheme registrations, such as that for http:, only provide a partial definition, and other sources of information must be consulted in order to understand a particular URI using that scheme. For example, to understand an http: URI, one generally needs to dereference it (and even then one only knows a single version of it; see 7.3 Using a URI to refer to the information resource accessible via that URI).
To define a URI to refer to Mount Everest, Alice invents a new URI scheme, say mountain:, and publishes a registration for it via IETF and IANA that says that 'mountain:peakxv' refers to Mount Everest. Bob, on encountering 'mountain:peakxv', checks the IANA URI scheme registry (which he knows about because the registry is specified by IETF), obtains a link to Alice's registration for the 'mountain:' scheme, reads the registration, and is enlightened.
Practically speaking, this approach is very challenging due to the rigor of the review process for URI scheme registrations (see [rfc4395]). Furthermore, Web clients will not understand the new URI scheme, making the definition of the URI effectively inaccessible for most agents encountering the URI, at least until the mountain: scheme becomes as well known as the http: scheme.
URN namespaces [draft note: cite RFC 3406] work in a similar way. Each namespace has a registration document that is formally reviewed through IETF and placed on file with IANA.
3.4 Use the LSID getMetadata() method
A URN namespace for which there is a general definition method is the 'lsid' namespace.[3] URIs beginning 'urn:lsid:' are called LSIDs. LSIDs have an associated SOAP-based protocol that has separate methods for dereference (getData) and discovery (getMetadata). According to the LSID specification, an LSID for which the getData method yields nonempty content refers to a what is here called a fixed information resource, while the LSID could refer to anything at all if getData yields empty content. In the latter case the information yielded by the getMetadata method generally constitutes, or at least contains, a definition of the LSID.
3.5 'Hash URI'
With this method, the URI must be a 'hash URI', i.e. must contain a fragment identifier. The definition of the URI is placed in the document accessible via the URI that is the pre-fragment stem of the URI.
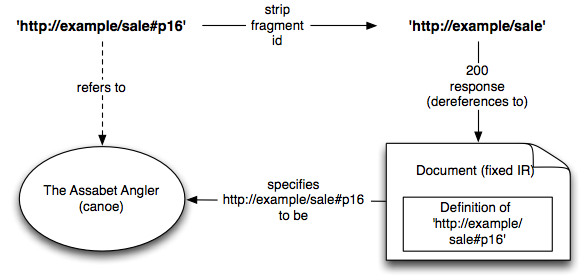
The interpretation of a URI possessing a fragment identifier, say 'http://example/sale#p16', is governed (according to [rfc3986]) by the media type of some version of the information resource accessible at its stem URI 'http://example/sale'. For RDF-enabled media types, the media type registration defers to the content of the version - that is, the version itself gets to arbitrarily define what the 'hash' URI means.[4]
3.6 'Hashless URI' with HTTP 303 See Other redirect
In this approach, one mints hashless http: URI, makes a definition of it accessible via a second URI, and then arranges for a GET request of the first URI to redirect to the second URI. The first URI then gets it meaning according to the document accessible via the second URI.
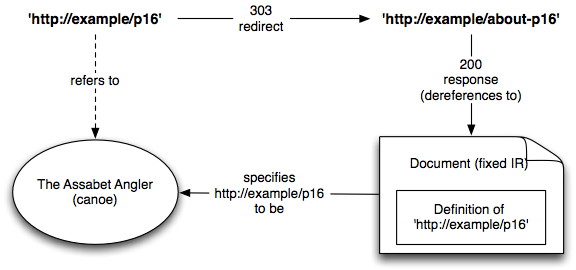
Alice chooses 'http://example/p16' as the way she will refer to a particular canoe being put up for sale. At 'http://example/about-p16' she publishes text and/or RDF that defines 'http://example/p16', explaining the URI by providing details about the canoe (make, model, length, location). For the URI 'http://example/p16', which will not be dereferenceable (since otherwise it would refer to the information resource at that URI, not the canoe), she arranges that a GET request yields a 303 redirect with a Location: header specifying 'http://example/p16' as the redirect target.
Those encountering 'http://example/p16' will attempt to dereference it, but this will fail, with a 303 redirect delivered instead. The 303 redirect indicates that the URI does not refer IR('http://example/p16'), but rather that the document at 'http://example/about-p16' provides a definition of 'http://example/p16'. [Draft note: TBD: cite HTTPbis]
Another pattern is to use 303 redirect to a document whose primary topic is the intended referent, similar to the Chicago example above. This could, in theory, lead to ambiguities, as the primary topic and the entity referred to using the URI might be different.
4 Critique of the current methods
The methods 3.1 Colocate definition and use and 3.2 Link to documents containing definitions work as far as they go, but may not be practical in all situations. 3.3 Register a URI scheme or URN namespace is not practical, and 3.4 Use the LSID getMetadata() method relies on an unregistered URN namespace and complex protocol. And when domain names are used as authority components in LSIDs, as they often are, the resulting URNs are no more "persistent" than http: URIs, leaving the advantages of LSIDs over http: URIs uncertain.
We therefore focus in this section on the two widely used definition methods, fragment identifiers and 303 redirects.
4.1 Fragment identifiers are fragile
"People forget to put it there when writing and cut and pasting URIs." (Harry) [Draft note: More information needed.]
The meaning of a hash URI "depends on how you access it, which is nuts. Its as though a word has different meanings depending on whether you read it in a book or have it read out to you." (Ian Davis) — I think he's talking about the situation where there is content negotiation and there is inconsistency between the variants. The more common problem with content negotiation is that there is no way to know ahead of time which variant has the definition at all, and thus which one to request in content negotiation.
Ian points out that RDF Concepts says: "a URI reference in an RDF graph is treated with respect to the MIME type application/rdf+xml [RDF-MIME-TYPE]. Given an RDF URI reference consisting of an absolute URI and a fragment identifier, the fragment identifer identifies the same thing that it does in an application/rdf+xml representation of the resource identified by the absolute URI component." and that this appears to conflict with webarch. [Draft note: TBD: try to figure out what is going on here.]
4.2 The common 'hash URI' pattern fails with large namespaces
When a large number of URIs are formed by combining a fixed "namespace" prefix with many suffixes using hash as a connector, there will be a single underlying document at the pre-hash URI that must provide definitions of all of the large number of URIs. This is an unacceptable performance hit for the server, the network, and the client. 'Hashless' URIs don't have this problem as the response can be specific to each URI.
[Draft note: look at Norm Walsh's 2007-02-17 post]
4.3 Hash URIs don't support REST architecture
Hash URIs don't work with HTTP PUT, POST, or DELETE methods. (Manu)
4.4 303 is difficult, sometimes impossible, to deploy
Deploying a 303 redirect requires giving the correct directive to a web server, for example adding a Redirect line to .htaccess in Apache. Unfortunately many hosting solutions do not allow this.
The Chicago use case is an extreme version of this - the entity providing access to the Chicago document (Alice) does not even care about providing URIs that refer to Chicago; it is someone having no control over how the URI dereferences (Bob) who needs a reference to Chicago.
4.5 303 leads to too many round trips
To get definitions of N URIs by redirecting through 303 responses, you need to do 2N HTTP requests.
4.6 303 makes the URI difficult to bookmark
"the user enters one URI into their browser and ends up at a different one, causing confusion when they want to reuse the URI of the toucan. Often they use the document URI by mistake." (Ian Davis)
"Redirection has in fact very confusing side effects; as we expect the semantic web to work seamlessly with the web, it is very odd that a semantic web uri cannot be copy pasted to a browser without seeing it change to something that is not the same as before." [giovanni]
5 Possible mitigations
With fragment identifiers and the 303 redirect identified as the sources of current difficulties, a number of alternative methods have been suggested to get around their problems.
5.1 Use something other than a URI
[Draft note: This section derives from JAR's TAG F2F presentation slides. The purpose of talking about this idea is mainly to remind people that the problem is one of notational engineering, not philosophy. This doesn't work very well, though, and I will probably flush this section.]
URIs are just one kind of term that might be used to refer to something. If defining a URI is too difficult or costly, then perhaps one might do without. In RDF serializations such as Turtle, for example, we have blank node notation:
[ foaf:isPrimaryTopicOf <http://example/about-chicago> ] Here we have managed to refer to Chicago without defining a new URI; we have simply referred indirectly using a URI that refers to an information resource according to a generic method (see 7.3 Using a URI to refer to the information resource accessible via that URI).
A more concise alternative is syntactic sugar:
*<http://example/about-chicago> which might be supported in a hypothetical RDF serialization as a shorthand for the previous example. (The asterisk is meant to be suggestive of indirection in the C programming language.)
5.2 'Hash URI' with fixed suffix
This idea attempts to address one reason for using 'hashless' URIs instead of fragment identifiers. Suppose you want to combine a large number of local names a, b, c, ... into a namespace. The usual solutions would be to write 'http://example/namespace#a' (a "hash namespace") or 'http://example/namespace/a' (a "hashless namespace").
In the "singleton fragid" approach one would write 'http://example/namespace/a#' (a null fragment identifier) or 'http://example/namespace/a#_', using a fixed suffix for every URI and varying the part between the namespace prefix and the suffix.
As in the 303 approach, each URI in the namespace would (or could) have its own document, providing a definition for that single URI rather than for every URI in the namespace.
The choice of fixed fragment identifier (null, "_", or something else) is largely a matter of taste.
A null fragid precludes the use of qnames to abbreviate such URIs. (In particular it would not be possible to use them as predicate names in RDF/XML.) However, SPARQL, Turtle, and RDFa are being extended to admit CURIEs that include #, making this a newly attractive option.
To address the "hash gets lost" problem we could explore heuristics to automatically replace 'http://example/p16' with 'http://example/p16#' (or 'http://example/p16#_') when needed.
5.3 'Hashless URI' with site-specific discovery rules
The network round-trip (303 redirect) to map the URI whose definition is to be discovered to the URI of the information resource that defines it can be avoided if we know a general rule that maps one kind of URI to the other, as such a rule can be applied on the client without server involvement. It is too much to hope that a single rule could work uniformly for all URIs whose definition might be sought, but an individual host may have a rule that applies for URIs at that host.
The "well known URIs" protocol gives a place where such a file containing such rules can be stored [rfc5988]. The rule might be stored in a well-known file 'definition-rule', as in 'http://example/.well-known/definition-rule'. To obtain a definition of 'http://example/p16', obtain the definition-rule file for its host. Then if the rule says to map 'http://example/{path}' to, say, 'http://example/{path}.about', a definition of 'http://example/p16' can be sought by dereferencing 'http://example/p16.about'.
When the mapping is cached, this reduces the number of round trips from two (in the 303 case) to one.
This would be a new protocol and the name and format of the definition-rule file would have to be pinned down. One option might be to use the link-template feature of the host-meta file [rfc5988].
Looking for a definition-rule file for every host that has URIs for which definitions need to be discovered would be expensive if only a few of them have such files, but with some cleverness the number of such failed requests can probably be kept small. The details would have to be worked out, but this approach could be a boon to bulk consumers of 'hashless' URI definitions.
5.4 'Hashless URI' with new HTTP request or response
To reduce the number of round trips, we might use a new HTTP method to request a definition of a URI, or the server could use a new status code to indicate that what it is returning is a definition of the request URI.
The URIQA specification [uriqa] defines MGET, a new HTTP request method. An MGET request on a URI yields a response containing a definition of that URI.
In response to GET of a URI, a server might provide a definition in a non-success response. (A successful response would mean that the URI refers to the information resource at the URI.) Possibilities for HTTP response status codes that might signal this situation: 203 Non-Authoritative Information, a new 2xx status (e.g. 209), a new 3xx status (e.g. 308), or a variety of 4xx codes. (Placing the definition in the content of a redirect response (status code 301, 302, 303, and 307) is unsatisfactory as the content would not be displayed in a Web browser.)
The Link: header or other HTTP header might play a role here. [TBD: explain and cite Web Linking and HTTPbis]
Any of these options would mean fewer round trips than following a 303 redirect. A downside is that they are all generally as difficult, or more difficult, to deploy than 303 redirects.
5.5 'Hashless' URI dereferences to its definition (compatibly)
[Draft note: We are trying to represent Ed Summers's view in this section.]
Currently we use a dereferenceable hashless URI 'http://example/p16' to refer to the information resource at that URI, IR('http://example/p16') (see 7.3 Using a URI to refer to the information resource accessible via that URI). To use an http: scheme 'hashless URI' to refer to anything else, one uses a 303 redirect. To address performance and deployment difficulties with 303 redirects, it has been suggested that the same URI be used for two purposes: to refer to the information resource at that URI, and to refer to some entity given by a definition of the URI that is carried by (a version of) the information resource itself.
Suppose that Alice wants to use the URI 'http://example/p16' to refer to a canoe. She publishes a definition containing the following at 'http://example/p16':
<http://example/p16> foo:mass 2140.
<http://example/p16> foaf:name "Assabet Angler". Bob then comes along and writes the following metadata about IR('http://example/p16') in the usual way, i.e. using the URI to refer to the information resource, based on what information is accessed via that URI:
<http://example/p16> dc:creator "Alice".
<http://example/p16> dc:title "All about the Assabet Angler".Carol encounters both bits of RDF (or either) and needs to make sense of them. Suppose she is aware that 'http://example/p16' might be used in both ways - in metadata, with the intent that the metadata is about IR('http://example/p16'); and also according to a definition of 'http://example/p16' found in IR('http://example/p16'). For each use of 'http://example/p16' she (or her software) needs to determine which sense is supposed to apply.
In general, what agents using this protocol need - both those composing statements and those deciphering them - is an agreed rule for classifying each occurrence of a URI u as referring either to the information resource IR(u) or to what the content at IR(u) describes.
There are probably many ways in which one might accomplish this; the following method is provided for illustration. Suppose that it "makes sense" or "is appropriate" for the subject of a particular property to be an information resource. For example, the subject of Dublin Core properties might be seen as "making sense" when the subject is an information resource. The judgment of "making sense" might be made according to an asserted or inferred domain constraint, or it might simply be by fiat (asserted). Call such a property a subject-IRS property. A property that is not subject-IRS would be subject-NIRS. Similarly, we would have object-IRS and object-NIRS properties. The decision of which sense is meant for a particular occurrence of a URI is then based on the subject or object classification of the property in the statement in which the URI occurs.
In the example, dc:title would be classified as subject-IRS object-NIRS, while foo:mass would be classified as subject-NIRS object-NIRS. To avoid mistakes, these classifications would have to be understood in the same way by both Bob and Carol, i.e. they would have to be part of the shared meaning of the properties in question.
This approach presents a couple of challenges.
First, not all subject or object positions of properties are easily classified as IRS vs. NIRS. For example, the object of "likes" and the subject of "is located at" are not obviously either IRS or NIRS. No matter which choice is made in these cases, meanings that required the other choice would be difficult to express - you would have to revert to a mode of expression that did not involve a 200 response (hash, 303, blank node, etc.).
Second, care must be taken to ensure that the two senses can be recovered even in the presence of inference. Especially troubling would be if equations were inferred for one sense that were unsound for the other, e.g. an incorrect identification of two information resources on the basis of an identity between the things they describe. To rule this out would require adoption of practices and conventions designed to prevent such conclusions, such as avoiding the use of functional properties and owl:sameAs in conjunction with URIs subject to dual use.
5.6 'Hashless' URI dereferences to its definition (incompatibly)
Under this proposal, a dereferenceable URI would, in some cases at least, get its meaning according to a definition found in the document to which the URI dereferences, rather than according to the IR reference rule. This approach avoids the deployment and performance difficulties of 303 redirects. Defining a URI is easy - it is the same as publishing any Web document - and access to the definition is also easy, not requiring an indirection step.
This would be an incompatible change, as tools that assume that u refers to IR(u) will misunderstand uses of u where u is meant to be defined by the definition in IR(u)'s content, and vice versa. However, most of the time, a URI does not dereference to a definition of itself. Therefore it might make sense for some of those URIs to refer to their information resources. This would maintain backward compatibility for those URIs, at least, limiting the damage incurred by the incompatible change. (Tools that uniformly assume the IR reference rule would still be incompatible, of course.)
The challenge is how to distinguish the two situations. The criterion "provides a definition of URI u" is not machine actionable as stated, both because the definition might be couched in an arbitrary language or notation, and because it is not obvious how to distinguish content that contains a definition of a particular URI from content that doesn't. But an approximation to the criterion might be made actionable, based on some combination of media type and aspects of the content. One approximation that has been proposed if as follows: If IR(u) has a version with media type 'application/rdf+xml', then take u to be defined by IR(u), otherwise take u to refer to IR(u). This rule would generate false positives (e.g. documents not containing u) and false negatives (e.g. only having a text/html version), but it illustrates the idea.
Some machine-actionable rule is desirable, since without one there is no reliable way to use any hashless dereferenceable URI u to refer to IR(u), and all currently deployed metadata would fail. There would always be the possibility that u might be understood to be defined by IR(u) instead.
Whatever rule is adopted (if any), for those URIs u whose meaning would be changed incompatibly, another way would have to be provided to refer to IR(u), so that metadata applicable to IR(u) could be written. This could be done in RDF given a standard way to write the predicate corresponding to what we've been calling 'is accessible via'. For example, the Turtle term
[ :accessibleVia "http://example/p16"^^xsd:anyURI ] could be a new way to refer to IR('http://example/p16'), which we formerly referred to in Turtle as '<http://example/p16>'. A local shorthand could be defined to the same effect:
:about-p16 :accessibleVia "http://example/p16"^^xsd:anyURI . (Note that either a 'hash' URI or a 303 URI could be used to refer to an information resource, perhaps defined in this way.)
Or the referring document could just assert that it's using the URI to refer to the IR in question:
<http://example/p16> :accessibleVia "http://example/p16"^^xsd:anyURI . which would constitute an explicit opt-in to the IR reference rule, running some interoperability risk. (This would be an instance of 3.1 Colocate definition and use.) [5]
To avoid the need for the :accessibleVia notation, some convention might be used to provide a URI (other than u) to refer to IR(u), when one is available. This could be done using a Link: HTTP response header, or via an RDF statement such as
<http://example/p16#ir> :accessibleVia "http://example/p16"^^xsd:anyURI . 6 Summary
The following table summarizes the candidate new discovery methods, evaluating each against a set of criteria, as described below.
| compatible? | robust? | easy to deploy? | min round trips | ns scales? | >1 definition? | |
| Hash | + | - | + | 1 | - | + |
| Hashless + 303 | + | + | - | 2 | + | + |
| Hash + fixed suffix | + | - | + | 1 | + | + |
| Hashless + definition-rule | + | + | ? | 1+ε | + | + |
| Hashless + new HTTP | + | + | - | 1 | + | + |
| Overload | + | + | + | 1 | + | - |
| Depends | - | + | + | 1 | + | + |
- compatible?
- Does it assign a new, incompatible definition to existing URIs?
- robust?
- Is the URI free of fragment identifiers that can get lost?
- easy to deploy?
- Can a publisher with a file-upload-only hosting solution use this method?
- min round trips
- How many network round trips are needed to find a definition, assuming (a) the definition is not cached and (b) the /.well-known/host-meta cache misses with probability ε ?
- ns scales?
- Can definition-containing document sizes be bounded as namespaces grow in size?
- >1 definition?
- Can distinct definitions give the same meaning to distinct URIs?
[Draft note: For reference, here's a similar analysis - not the same problem, but a related one - with its own matrix.]
7 Appendix. About information resources
"Information resources" figure in this story as providers of definitions, as things that one refers to (metadata subjects), and as things that are the referents of URIs. As the desire to refer to information resources using dereferenceable URIs competes with the proposal (5.6 'Hashless' URI dereferences to its definition (incompatibly)) to refer to other things using those same dereferenceable URIs, it is important to understand what needs are met by information resources, what kinds of things one says about them, and what one means by saying things about them.
7.1 Use case: Preparing and consuming metadata for a Web-accessible information resource
Bob is preparing a bibliography. He finds a report on cicadas provided by Alice at the URI 'http://example/cicada' and wishes to refer to the report for the purpose of composing metadata such as its title, author, and publication date. He selects a URI, blank node, or other term to use to refer to the report, then composes the metadata, using his term in the metadata to refer to the report. (Bob's term might be 'http://example/cicada' but could be something else, if there is the possibility that 'http://example/cicada' does not refer to Alice's document.)
Subsequently Carol encounters an entry from Bob's bibliography. Wanting to know what the subject of the entry is, she is led somehow (depending on discovery method) from Bob's term to Alice's URI, and from there to Alice's document IR('http://example/cicada'), which is the document that Bob's term refers to.
[Draft note: DB: a. What URI should Bob use to refer to the report? b. How should Carol know to dereference http://example/cicada ? c. How should Carol know that Bob's URI is intended to refer to IR('http://example/cicada')?]
7.2 Natural history of information resources
The following explains the particular theory of "information resources" assumed in this report. The theory is independent of how one refers to information resources. More elaborate theories are certainly possible, but this is all we need to assume in order to explain how they work and what they are good for.
Each information resource has one or more associated versions, where each version is a fixed information resource, consisting of fixed content (octet sequence) and additional information (media type, language) affecting the interpretation of the content. Different versions may be appropriate at different times or in different interaction contexts. No particular meaning is implied by the word "version;" the word is chosen as suggestive of its most common use.
Metadata statements such as those giving authorship, title, and topic are true or false of fixed information resources in the obvious way — they are true according to the content, its interpretation, or its provenance. Such statements also apply to arbitrary information resources in a systematic way, as follows: If a statement is true all versions of the information resource, then the statement should be taken as true of the information resource, and vice versa.
Operationally, this means that if you have knowledge of an information resource's versions, you can write metadata using the information resource as subject, and someone reading this metadata can then apply that metadata to whatever version they access.
An information resource need not be accessible via a URI, or even have any associated URI at all. An information resource might exist only inside a local file system or database, or it might be ephemeral.
7.3 Using a URI to refer to the information resource accessible via that URI
To refer to the information resource accessible via a URI when that URI is dereferenceable, one generally uses the URI itself. E.g. 'http://example/ir' refers to IR('http://example/ir'), if 'http://example/ir' is dereferenceable. One might use such a URI in a metadata statement, for example: "The creator of http://example/ir is Carol", or, expressed equivalently in Turtle,
<http://example/ir> dc:creator "Carol". If one wants to refer to an information resource, but it isn't accessible via any URI, one might choose a URI, publish the information resource's versions at that URI, and then use the URI to refer to the information resource.
An agent who encounters a URI and wants to know what the URI means can dereference it, and if the dereference is successful (HTTP 2xx status as opposed to 303 or 404 or anything else),[6] the agent can take the URI to be a reference to the information resource that is accessible via that URI.[7]
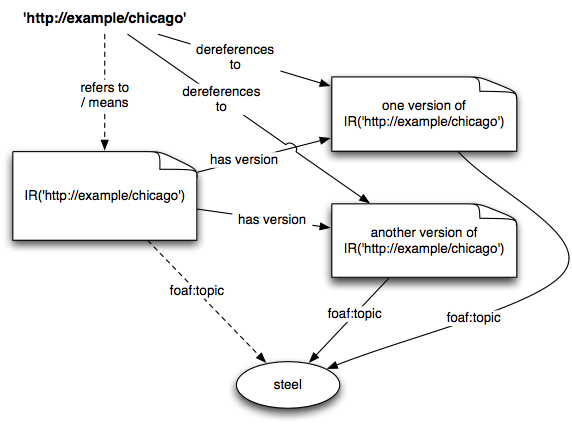
In this example, the URI 'http://example/chicago' dereferences on two different occasions to two different fixed information resources. (Perhaps the document was edited, or is available in two different languages.) These fixed IRs are versions of the information resource IR('http://example/chicago'). Steel is a topic of both versions. If steel is a topic of any version of IR('http://example/chicago'), it will also be considered a topic of IR('http://example/chicago').
Dashed lines indicate relationships that are induced by circumstances.
8 Acknowledgments
David Booth, Michael Hausenblas, Nathan Rixham, and Alan Ruttenberg contributed to the creation of this report.
9 References
- issue-14-resolved
- Roy Fielding. [httpRange-14] Resolved. Email to www-tag list, 2005. (See http://lists.w3.org/Archives/Public/www-tag/2005Jun/0039.html.)
- issue-57
- Issue 57. W3C Technical Architecture Group, 2007-2011. (See http://www.w3.org/2001/tag/group/track/issues/57.)
- rfc3986
- T. Berners-Lee, R. Fielding, L. Masinter. Uniform Resource Identifier (URI): Generic Syntax. RFC 3986, IETF, 2005. (See http://www.ietf.org/rfc/rfc3986.txt.)
- rfc4395
- T. Hansen, T. Hardie, and L. Masinter. Guidelines and Registration Procedures for New URI Schemes. RFC 4395, IETF, 2006. (See http://www.ietf.org/rfc/rfc4395.txt.)
- rfc5988
- M. Nottingham. Web linking. RFC 5988, IETF, 2010. (See http://www.ietf.org/rfc/rfc5988.txt.)
- hostmeta
- E. Hammer-Lahav. Web Host Metadata. Internet-draft, IETF, 2010. (See http://tools.ietf.org/html/draft-hammer-hostmeta-13.)
- webarch
- Ian Jacobs and Norman Walsh, editors. Architecture of the World Wide Web, Volume One. W3C Recommendation, December 2004. (See http://www.w3.org/TR/webarch/.)
- disambiguating
- Sandro Hawke. Disambiguating RDF Identifiers. W3C, January 2003. (See http://www.w3.org/2002/12/rdf-identifiers/.)
- uriqa
- Patrick Stickler. The URI Query Agent Protocol. Nokia, 2010. (See http://sw.nokia.com/uriqa/URIQA.html.)
- giovanni
- Giovanni Tumarello. http-range-14 303 issue, request for reopening the discussion. (See http://lists.w3.org/Archives/Public/www-tag/2007Jul/0034.html.)