See also: IRC log
<jar> scribe: Jonathan Rees
<jar> scribenick: jar
Noah will review priorities agreed last time
noah: After lunch: would like to get agreement to publish Ashok's draft
RESOLUTION: minutes of sept 1 http://www.w3.org/2001/tag/2011/09/01-minutes are approved
(discussion of list of 5 products listed here http://www.w3.org/2001/tag/2011/09/13-agenda#Convene )
masinter: We had a request to talk about character normalization
noah: It's on the agenda.
<DKA> Noah: I'd like a chance to update the TAG on the upcoming workshop on off-line web applications which I will be co-chairing after TPAC: http://www.w3.org/2011/web-apps-ws/ - should only need 15 minutes but also related to ACTION-544.
<DKA> Did you see my note on the workshop?
masinter: What about the XML/HTML task force?
noah: We agreed on last call to put that off until after the F2F
masinter: Fragids and mime types are convolved...?
noah: Jeni prepared a draft http://www.w3.org/2001/tag/doc/mimeTypesAndFragids-2011-08-12
jeni: I'm expecting help from Peter and Henry.
timbl: In general my feeling is disappointment at the conclusion that the inconsistencies are largely theoretical
<noah> Tim is commenting on the statement in section 2.2:
<noah> "However, the impact of these inconsistencies is largely theoretical from the standpoint of a single application."
timbl: These inconsistencies may seem OK at the beginning, but later they become a big headache.
... The article is a great analysis, but then shrugs its shoulders
<masinter> I agree. With regard to this document, I think the problem analysis is useful and helpful, but I don't think the recommendations do enough
timbl: Our mandate is to design a strong platform
... At the moment there's no guarantee of what a fragid will do
... Shoulder shrugging seems to break the architecture
jenit: I tried to make the conclusions contentious to stimulate figuring out what to do.
<masinter> There are a couple of different things that have to happen: Fix[ing] up fragment identifier references in MIME type definitions requires some of the "MIME and the web" actions. Fixing SVG fragment identifiers and XML fragment identifiers require updates to those specs. Just putting those things in a finding doesn't seem like it will affect the right specs.
<DKA> I [liked] Best Practice 3: Fragment Identifiers in Media Type Definition: Media type definitions should avoid 'must' language when describing supported fragment identifiers as in practice it is likely to be ignored. Instead, they should provide pointers to any known fragment structures that might be applied to that media type and give warnings of any contradictions between them.
masinter: Agree, like problem definition, but need stronger recs, different ones in different arenas
timbl: Don't misunderstand "finding" - findings are to the TAG as Recommendations are to the W3C. They can say that things should not be done and should be done.
masinter: Then how do findings become actions?
<Zakim> ht, you wanted to register uncertainty and plug your talk this afternoon :-)
ht: I would like to agree with Tim, but the horse is out of the barn. We need to think about why it's so hard to make this work. We've been struggling with this since XML Schema at least.
<masinter> ((I'm not entirely sure what Henry is torn about, and what horse is out of what barn))
ht: We've made progress around question of bare names in XML media types... we haven't sorted out the details, but it seems like it might work to say the same URI means different things at different levels of the stack
<masinter> A character sequence has a meaning in a context
ht: The talk this afternoon will talk about this. Nobody in philosophy of language would agree with the proposition that a character sequence has a meaning. We're making our stand at the wrong level - need to talk about the link level - how it's used
<masinter> that's why i kept on putting 'meaning' in quotes in the discussions with JAR on the mailing list
ht: We may need to back off from context-free meaning
... I've been trying to be convinced, but.
<masinter> the primary context for URIs is A@HREF, and in lieu of other disambiguation, meaning of URIs is its meaning within that context
<masinter> i think this reads on the internationalization/equality/disambiguation issues
timbl: We don't need to go into that in too much detail.
... But we can say don't use a URI to mean one thing in one place, another thing in another.
ht: We can't live with the goal of unique and determinate meaning of a URI.
<noah> http://www.w3.org/2001/tag/products/fragids.html
noah: (It was my intent that we would review the product page at start of each discussion...)
<ht> s/indeterminate/determinate/
<noah> http://www.w3.org/2001/tag/doc/mimeTypesAndFragids-2011-08-12
(Begin discussion of Best Practice 1: Canonical Fragment Identifiers)
<masinter> I don't understand Best Practice 1
<masinter> To whom is this directed?
timbl: Should indicate how it's canonical. How?
<masinter> Whose practice should change?
noah: Request that the doc have its own fragids
<noah> "Fragment structures which provide multiple ways of addressing the same secondary resource should indicate which fragment identifier is canonical and should be used for making statements about that secondary resource."
<timbl> Now I know what it means, I think I disagree, as different forms of XPointer will have different persistent qualities, which will differ from application to application.
<noah> Do we mean just "making statements about" or do we mean "as the preferred form of reference"
<JeniT> If there are several ways to point to a single fragment within a document...
<JeniT> ... that are equivalent in terms of what they point to
<masinter> is this directed at web developers? People who define fragment identifier semantics for a particular MIME type?
<JeniT> ... then it is helpful to say, when you are designing the fragment identifier scheme
<timbl> Sometimes, numeric tree address will be more stable than one based on local context
<masinter> What is a "fragment identifier scheme" ?
<JeniT> ... which one of the many fragids that point to the fragment should be generated
<JeniT> masinter, it [the Best Practice] is directed at people who define fragment identifier schemes, such as XPointer
<JeniT> masinter, or the media fragments [WG]
<masinter> Should people be defining fragment identifier schemes that aren't associated with specific media types?
ashok: What is this recommendation really telling us? In a MIME type there might be more than one way to specify a 2ary resource.
... If you just use 'should' then this BP won't do much... 'must' is better
<Yves> well, with XPointer you always have multiple ways to point to one element in a specific document
jenit: In many cases it's hard for there to be only one way. Different fragids for same thing are robust in different ways to changes in the document
... so 'must' is too strong
<masinter> and then the javascripting interface gives another generic method
<masinter> this really brings the issue clearer for me
jenit: Different advice to different levels (e.g. xpointer vs. media fragments)
timbl: The editor has to make his/her own choice. Sometimes when you're scraping the page [...] I don't see the value of promoting a canonical one
<Zakim> noah, you wanted to suggest we go through the "Best practices" proposed in the draft and to ask, do we really mean just "to make statements about"?
noah: But this is advice re writing mime type registrations, not to document producers
<JeniT> Are multiple fragment identifiers that address the same resource (eg XML element) equivalent at the semantic level?
noah: Tim's saying there are reasons to not use the canonical fragid
... E.g. for upper/lower case it would be easy to say lower case is preferred
<masinter> or when you have fragments that are not normalized unicode and different systems handle equivalence differently
<timbl> (noah, we are not talking about canonical in the sense of upper and lower case, but selecting completely different methods of identifying an element (etc).)
<Zakim> masinter, you wanted to wonder if the problem is the W3C groups that define generic systems for fragment identifiers without regard for other generic systems... so
masinter: We have at least 3 different generic systems for defining what fragids mean. XML, scripting interface, media fragments.
... mime type is being constrained 3 ways by 3 generic processing systems
<noah> Tim: I just used that as a trivial example, but I tried to make clear that I meant the general case.
yves: media fragments are in SVG
masinter: There's no advice we can give, since they're already overconstrained
<noah> I read Jeni as saying: "designate one form as canonical, for use where practical" I'm about half convinced it's worth saying.
timbl: Jeni is dealing [in BP 1] with two fragids for the same thing. I'm more concerned about one fragid for two things
<masinter> I forgot RDF/RDFa adding another generic one, so there are 4 generic fragment definition systems
<masinter> Personally I'd recommend using something other than fragment identifiers in URIs
<masinter> use markup instead
timbl: RDF. same id for two things bad idea
<Zakim> masinter, you wanted to suggest that it might be a 'best practice' to not use fragment identifiers when you can use markup
ashok: The argument was: different contexts require different styles. Why not say this in the MIME type registration?...
masinter: Fragids are a needle-eye for expressing things that might better be expressed using markup
timbl: But you can't bookmark markup
yves: Media annotation relies on use of URIs
<masinter> i think we should invent canonical markup for each of these different applications, and urge people to use markup rather than info packed into the string
yves: The problem comes when you use fragment vs. SVG view box...
<masinter> and W3C shouldn't invent any more systems for using fragment identifiers without having a markup equivalent.
<masinter> Using new data is a way in which that's been done
<masinter> and you can bookmark markup with data:
yves: [different modes of expression are robust to different kinds of change]
<Yves> to me "canonical fragment identifier" can't be defined by the media type, but by the people creating fraguris. What could be done in the media type definition is to alert about properties of "equivalent" ways of identifying secondary resources
<Yves> like robustness issues (relative to document change, like pixel-based spatial media fragment on a SVG picture that may change size, etc...)
<masinter> data:application/videofragment+xml,<video%20src=%xxhttp://uri/%xy%20start....>
<JeniT> Yves, the question for me is whether, at the semantic level, those different types of addressing "the same thing" are equivalent or not
<JeniT> Yves, and perhaps they aren't
<Yves> Jeni, exactly
noah: What's the best level at which to engage here?
Best Practice 2: Generic Fragment Structures
<Yves> they can be equivalent in many cases, but not always
<noah> "Fragment structures should be defined at levels that anticipate content negotiation. For example, the semantics of the svgView() fragment identifiers could be meaningfully applied to all image formats. Were a similar scheme developed in future, it should be defined for all images rather than a particular image format."
<JeniT> Yves, if they're *actually* equivalent, then you need to have a normalising method or comparison method to compare them eg when they're used in statements
<Zakim> masinter, you wanted to add the issue of normalization and character equality somewhere
masinter: The fragids could have the same problems with char identification as came up with CSS
<Yves> (unlike the uppercase/lowercase for bare names example that Noah pointed)
<Yves> Jeni, yes
<JeniT> Yves, :)
<masinter> look at http://tools.ietf.org/html/rfc5147 = URI Fragment Identifiers for the text/plain Media Type
<masinter> Should those fragment identifiers apply to documents that aren't text/plain ?
(Due to technical difficulties Dan and Jeni dropped off of the conference call. They rejoined later.)
<masinter> Ashok, putting markup in the query parameters doesn't help at all. The problem is that an unversioned, untyped, unsniffable data structure in the fragment
<masinter> Maybe if the generic fragment identifier systems were sniffable
masinter: Ashok was saying you could encode markup attributes as cgi query parameters...
... When you look at a fragid, you have to apply many heuristics to determine which meaning was meant
... The generic systems aren't designed with nonoverlapping syntaxes
noah: I'm tempted to rule non-URI syntaxes out of order.
masinter: It's legitimate to point out that there are some applications that don't need to use fragids
... And even when they're used, it would be good to have a non-uri syntax defined for expressing same thing
... Fragids aren't sniffable. There is no magic number.
timbl: We've got this web built on usefulness of URIs... so I'm also tempted to rule it out of order
<noah> The reason for, potentially, ruling out of order, is that this whole effort is framed as trying to make the URI-based approaches work better.
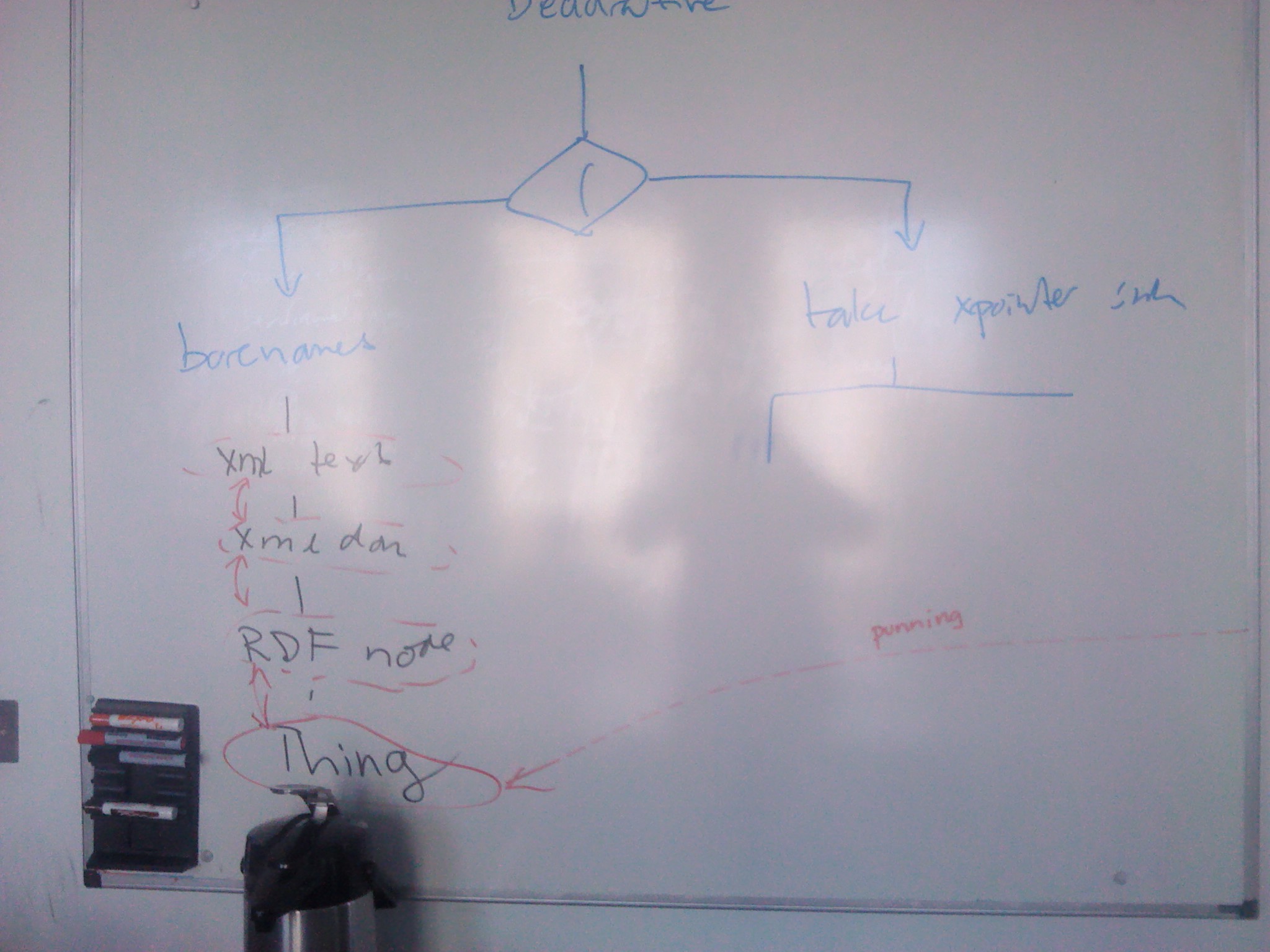
timbl: (drawing on board choice between barename and xpointer)
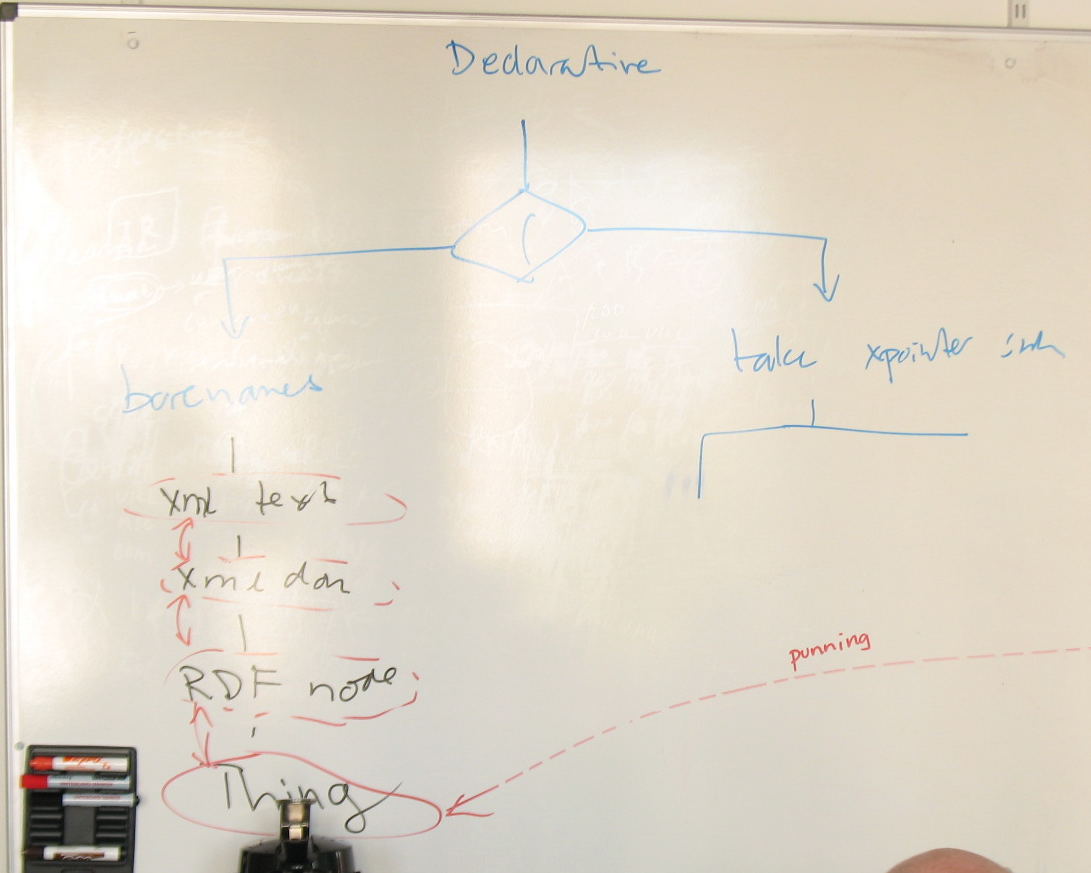
masinter: But that's not what people have implemented. The script gets first whack at it
noah: So people have ignored the specs. The media type reg should say how fragids identify
... So what scripts do is an implementation detail
ashok: Also passing args to functions
<masinter> Every specification should have an applicability statement which defines the scope of when the specification should be used, and even identify other ways of accomplishing applications which are inappropriate
<masinter> it's perfectly appropriate for us to limit the domain of applicability for fragment identifiers to those use cases which really NEED to use fragement identifiers, and to urge those who don't need to pack everything into an ascii string to do so
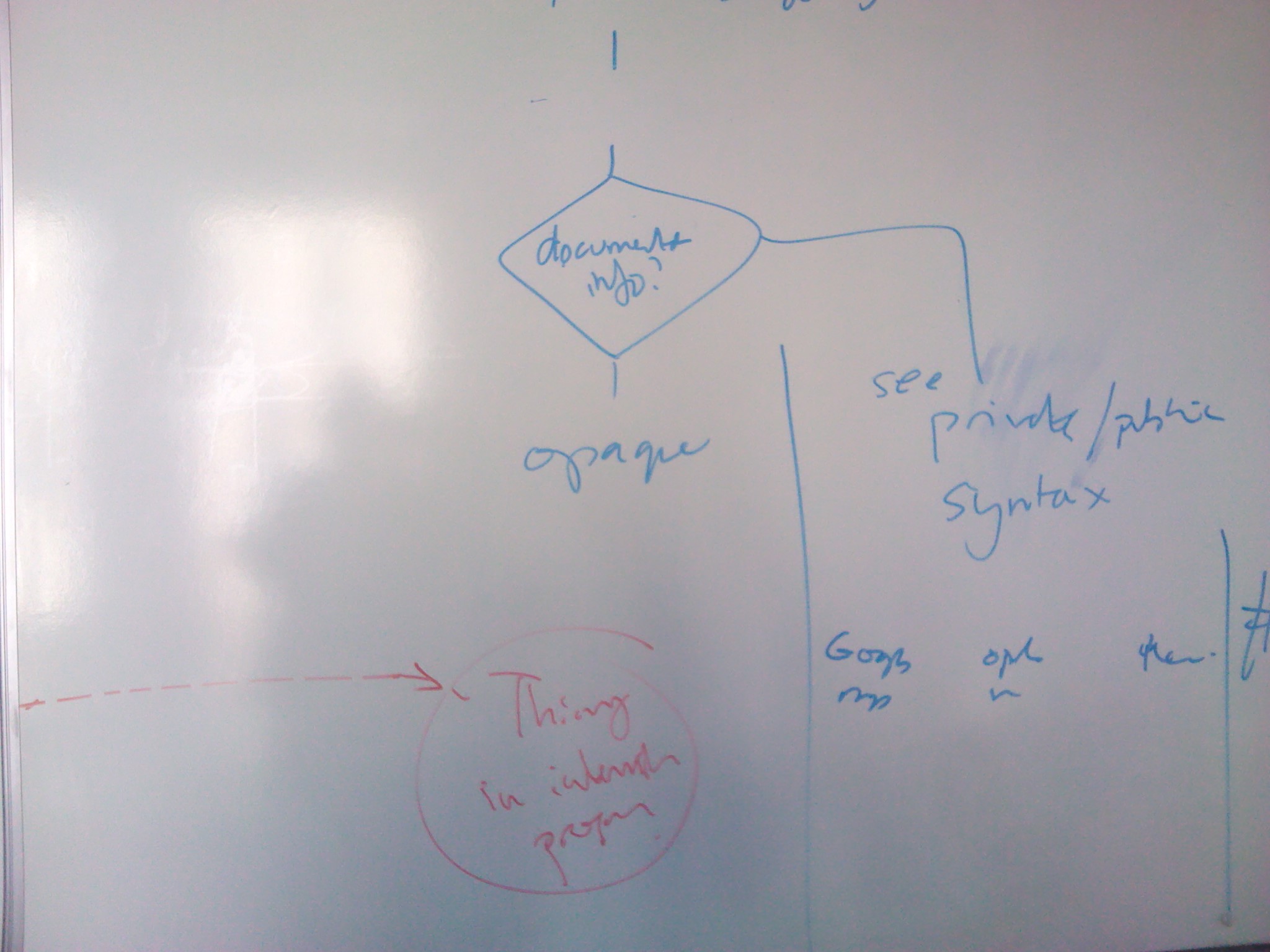
timbl: We have a rule of opaqueness for URIs. When there's downloaded code, the client shouldn't interpret without out of band agreement
noah: The javascript is like an HTML form... code coming from the server that knows how to build URIs
<masinter> "Best Practice: Generic systems for fragment identifiers should use and reserve unique initial strings which disambiguate which generic system is being used"
<Zakim> noah, you wanted to question whether mechanisms other than URIs are in order for this discussion.
<noah> Tim doesn't want to go into this, but I think this is quite parallel to the Javascript case: http://www.w3.org/2001/tag/doc/metaDataInURI-31.html#forms
<Zakim> ht_home, you wanted to offer "_when_ they are used to identify parts of document...."
ht: Maybe change the language a little bit. The semantics of a fragid *that point into a document of a certain media type* are... and other fragid uses are constrained in some other way?
noah: Say, when javascript uses fragids in a certain way, it must conform to ... [scribe mangled]
<masinter> RDF, media fragments, xpointer, scripting, XML IDs.... are there others?
<masinter> Maybe this is the reason for the ! in #!
<Yves> #! was indeed to avoid conflict
<masinter> so we should make #! a 'best practice'?
<ht_home> Done, I think
<masinter> "!" is the unique signature that should be used for all scripting?
<masinter> code should only ambush fragments that start with "!" ?
timbl: The browser history state is a sequence of values of address bar.
noah: No it's not. Sometimes I go forward and back and the address bar doesn't change.
timbl: Those things have alternate URIs that aren't being shown.
... Is there any reason you want to constrain them in the address bar case?
noah: I might copy them to email. But if I can't get to them, I don't care if there's a fragid that breaks media type rules.
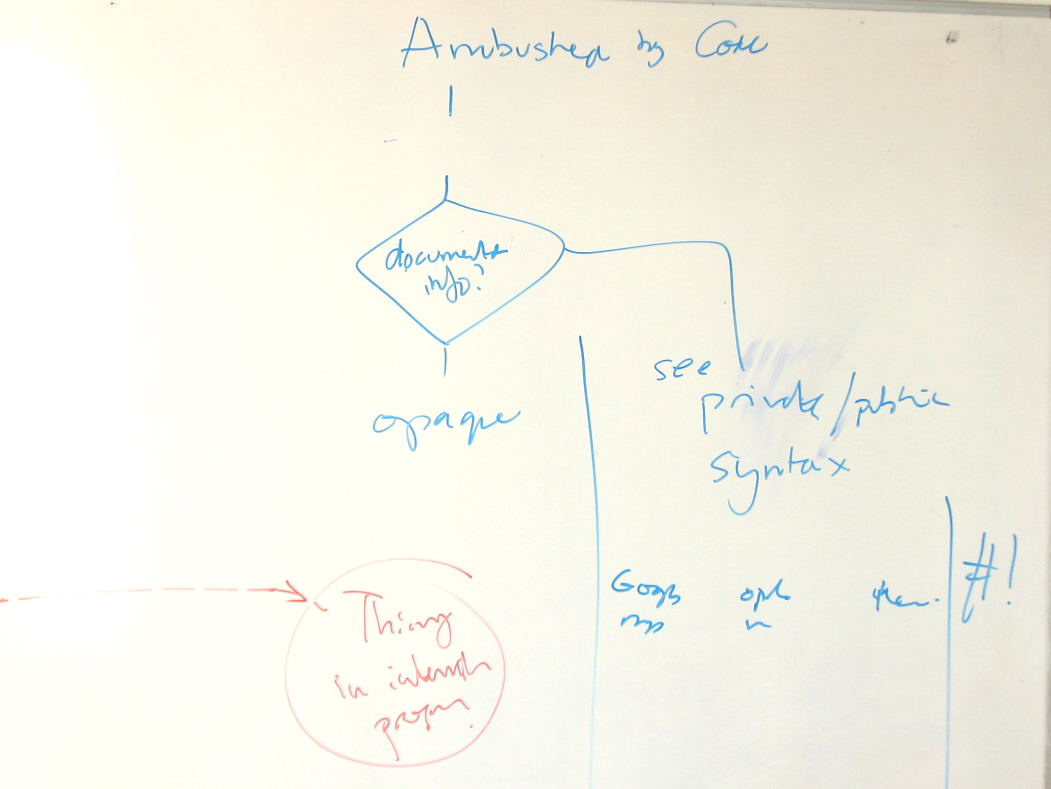
timbl: You [Larry] are being ambushed by code architecture, there's a different architecture for that (Tim draws at whiteboard)

ht: That's what I was trying to say
timbl: There are two architectures. One is declarative, the other is ambushed-by-code. They have little to do with one another.
ht: So if the URI does escape into the world, we won't know which arch applies, so won't know what it means...
noah: To me the javascript most of the time should be an implementation detail
timbl: Think of the fragid as being defined by two things. The media type, and a javascript bit
... There's all this punning going on. There's the Thing that the URI identifies, and then there's the RDF node, the XML DOM, the XML text
noah: So what does the media type reg say?
ht: The URI spec should mention that this other architecture exists
... I imagine: That I use the fragid in a URI that I send an HTTP request for (i.e. outside scripting context)
(question of putting the hair in MIME type, vs. in URI RFC)
timbl: For me a format spec isn't complete until it meets IETF media type reg requirements
<masinter> I think we could reasonably have a 'guidelines for defining fragment identifier semantics for media types' and then ask that the media type registration document to point to the guidelines, since this is long
<masinter> and that some media types are 'scriptable' and dispatch the fragments to the script
<JeniT> I think the scripting thing is a distraction
<timbl> really?
<JeniT> I think if we ignore scripting, we still have problems, which are more fundamental
<JeniT> and more important to fix
<masinter> Jeni -- i think scripting issue is separable... important, a 'distraction' from the main point
<timbl> I think we can't ignore scripting, but yes, for the non-script case we should spec that
<masinter> but still needs to be fixed
noah: Media type reg should tell me what the fragid means. Full stop. Fix the html media type reg, that's an anomaly.
<timbl> JeniT, in the room I have the scripting case on a separate whiteboard
<Yves> I agree, the use of js (or scripting in general) already breaks what is in the definition of static media types. Processing the fragment is not a bigger surprise than that
masinter: How about a separate document, guidelines for writing fragment id specs for mime type registrations, and then the appropriate RFCs can reference that
<ht_home> Low-quality photos of whiteboard at http://www.w3.org/2001/tag/2011/09/timbl_whiteboard_declarative.jpg http://www.w3.org/2001/tag/2011/09/timbl_whiteboard_ambushed_by_code.jpg
<noah> Scribe -- please move links to these into the transcript of this morning's fragid session: http://www.w3.org/2001/tag/2011/09/Whiteboard1.jpg and http://www.w3.org/2001/tag/2011/09/Whiteboard2.jpg
<noah> ACTION-543?
<trackbot> ACTION-543 -- Jeni Tennison to propose addition to MIME/Web draft to discuss sem-web use of fragids not grounded in media type -- due 2011-06-28 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/543
<noah> ACTION-567?
<trackbot> ACTION-567 -- Jeni Tennison to draft a document describing problems around fragids and ways things should be changed -- due 2011-06-28 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/567
<noah> ACTION-509?
<trackbot> ACTION-509 -- Jonathan Rees to communicate with RDFa WG regarding documenting the fragid / media type issue -- due 2011-09-15 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/509
<noah> JAR: I sent an email on 509, but have not yet received the feedback I need http://lists.w3.org/Archives/Public/www-tag/2011Sep/0014.html
<masinter> Generic fragment identifier methods should propose a unique string to disambiguate them from other generic fragment identifier methods
<noah> close ACTION-567
<trackbot> ACTION-567 Draft a document describing problems around fragids and ways things should be changed closed
<noah> action-543?
<trackbot> ACTION-543 -- Jeni Tennison to propose addition to MIME/Web draft to discuss sem-web use of fragids not grounded in media type -- due 2011-06-28 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/543
<noah> reassigning ACTION-543 to Peter
<noah> ACTION plinss with Henry produce partial revision of fragment id finding Due 2011-10-18
<trackbot> Created ACTION-594 - With Henry produce partial revision of fragment id finding Due 2011-10-18 [on Peter Linss - due 2011-09-20].
(break)
Product page = http://www.w3.org/2001/tag/products/mimeweb.html
masinter: Not proposing a change of direction. Rather followon in multiple avenues.
... (a) [see product page] is the 'happiana' discussion. How the community including W3C about how things get registered. There's a history of W3C media type registrations not happening. There is disagreement in the HTML WG on whether to use an IANA registry. Etc.
... Mark N and others are discussing. Things that look hard have been confusing to non-insiders. Some think overhead of expert review is too high.
... anyone have questions about process of getting things registered?
<Yves> https://www.ietf.org/mailman/listinfo/happiana
ht: Last time I reviewed this, it didn't sound like IETF thought there was a process problem. Just that there were failures to execute.
masinter: I understood this differently. There's a core process that gets things into registries, and then peripheral processes that feed into this core. The core has not been the problem.
... The distinction between provisional and permanent has to do with registries being gatekeepers when they shouldn't have been.
ht: So there is some receptivity to the process being reviewed?
masinter: Everyone agrees there's some problem somewhere. The disagreement is over where. IANA is doing its job, the problem is elsewhere.
... What seems to be missing is the widespread use of unregistered values, when a registry exists?
... There should be an impetus from somewhere to get these values registered. Whose job is it?
yves: There is a provision in the new registry scheme for non-"owner" to submit registrations.
... This is a bit controversial.
masinter: application/msword was registered so that Paul Lindner could use it in gopher
... Possibility of 3rd parties to register & add information (e.g. suggest expanding fragid specification) maybe should be part of process
... Should W3C take on the job of registering all the media types and URI schemes that are in use?
ht: Just a way to jumpstart the process
yves: Not useful unless we're talking about something very widely used
ashok: I spent some time on standards for cloud computing... each entity in the model has a different media type. Good idea? Problem? The stuff will be used.
masinter: There's work going on to improve process, there's a wiki about process, but still a gap between what's being considered and what I'd like to see
... that was (a).
Discussion of (b) from http://www.w3.org/2001/tag/products/mimeweb.html
masinter: (b) update media type reg BP http://tools.ietf.org/html/draft-freed-media-type-regs
... If we had a fragid specification document, this could reference it
... there's another document, one that deprecates the use of x- in experimental protocols
<Yves> http://tools.ietf.org/html/draft-saintandre-xdash-considered-harmful-01
masinter: If we want to have something to say about registrations, it would be best to update the RFC
Discussion of (c)
masinter: (c) Sniffing. http://tools.ietf.org/html/draft-ietf-websec-mime-sniff proposes to say how one should sniff. HTML make normative reference to this. Also ...
... Mime and the web responds to this. I have volunteered to produce an alternate document. Meeting with Tobias next week to go over this.
... it's a security issue.
<Yves> (supercedes https://tools.ietf.org/html/draft-abarth-mime-sniff-06 )
masinter: Trying to understand the scope [of the sniffing draft]. The abstract only talks about misconfigured HTTP servers. But then there's a reference to web app packaging...
... We have a TAG finding on authoritative metadata. This document specifically prescribes overriding authoritative metadata.
... This document is all or nothing. But actually browsers sniff differently in different contexts.
... It's probably better to fix the sniffing document than generate another critique
... I'd rather not have an inconsistency between a TAG finding and recommendations.
... maybe update the finding
(e)
masinter: (e) We'll probably need to update the W3C guidelines.
... So the product page maybe should prescribe not a single big document, but rather a set of documents and document updates
... (Call to see interest in these activities among TAG members)
noah: Where's the biggest bang for the buck?
timbl: The low road is HTML5 attitude: This is how it actually works. If everyone did [continued to do] things like this we'd have predictability.
... High road: This is the protocol, here are its benefits. If you don't want to use it, you don't get the benefits.
... I feel the TAG should probably spend more time on the high road. It's less crowded.
... Different functions
plinss: We need a path from the low road to the high road
masinter: The current sniffing document says what to do in all cases.
... I propose organizing by situation, and making sniffing optional in each situation.
... There was an opt-in proposal from MS - "I really mean this"
... Sniffing is what I most would like help with
... No distinction is made between no MIME type and MIME type in bad syntax
noah: Are we too late on this?
masinter: This is in the purview of the IETF web security WG [?]
<masinter> http://www.w3.org/TR/widgets/ makes normative reference to this [the sniffing draft]
<masinter> 9.1.11 Rule for Identifying the Media Type of a File
jar: Are we talking 5 products? How does Noah want to organize?
noah: Want to provide community with a way to assess our success
... So set this product up as a set of subgoals
<masinter> step 10 of widgets: "Let content-type be the result of processing file through the [SNIFF] specification." [SNIFF] Media Type Sniffing. A. Barth and I. Hickson. IETF (Work in Progress).
masinter: I don't think I got any feedback on any of the documents
... W3C has taken a stand that registries should be avoided, yet we keep on coming up with things that need to be registered. This work is central.
dka: Maybe circulate draft docs at offline apps workshop, re widgets (day after TPAC)
masinter: I think the reference can be avoided
<masinter> i think this is a 'filling the potholes' rather than a 'building new bridges' issue
jar: Would anyone be unhappy if Adam's draft progressed?
masinter: Yes
<noah> We are adjourned until 13:30 Edinburgh time.
(Adjourn for lunch)
<Yves> Scribe: Yves Lafon
<Yves> Scribenick: Yves
LM: W3C may put energy in registering all media types and the TAG may recommend that W3C do so.
also pushing things so that servers won't be released with improper media-type/filext association, the situation that led to mime sniffing
a Community Group of server vendors might work for that
<jar> No one would every want to take responsibility for changing a client from accepting of invalid to nonaccepting of invalid. [So closing holes will be nearly impossible.]
Noah: The issue is that we need to have an intuition [about whether] people who care about the issue will participate in such work or not
LM: nothing there is uncontroversial
... no community is against changing the default configurations of servers
<noah> YL: If you have a server, and the default changes, it does create headaches for people. Even if it's uncontroversial, it will be hard to find people to do the work.
Noah: the issue is to show value in doing work on this.
Tim: validators are a good way to help people do the right thing
Noah: do you have leverage with big ISPs so that they can make it easy for their users to use the right media types
jar: how about doing a hall of shame?
<jar> http://www.fred.net/tds/leftdna/
<noah> YL: There is an HTTP validator from Mark Nottingham
<noah> YL: Open source...you can create extensions
<noah> YL: One could imagine one to check content type matches.
YL: the difficult part is finding out real errors from willfull configuration that may look like "errors" per sniffing (so figuring out errors or warnings)
LM: best is to be realistic about what the TAG can do.
<masinter> "declare success and move on" -- write a document/note saying what we did, what needs to be done, and just move on
<masinter> lots of things W3C could do, but the TAG isn't going to do any of them
<Ashok> There is a Web Testing Activity proposal: > Web Testing Interest Group Charter > http://www.w3.org/2011/05/testing-ig-charter
DKA: people are reluctant to engage in things that might trigger pushback
LM: there is no risk of pushback here
Noah: There are two issues, the state of the sniffing document, and the other is the way toward a cleaner state where sniffing is not required
LM: (See the 'let's move on' quote above)
<noah> After wrapup, we will remove Mime on Web from list of top priority products, following agreement to Larry's final report
<scribe> ACTION: masinter to create a final report on Mime and the Web due in one month [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-595 - Create a final report on Mime and the Web due in one month [on Larry Masinter - due 2011-09-20].
<noah> ACTION-472?
<trackbot> ACTION-472 -- Larry Masinter to update the mime-draft based on comments & review -- due 2011-07-30 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/472
<noah> close ACTION-472
<trackbot> ACTION-472 Update the mime-draft based on comments & review closed
<noah> ACTION-588?
<trackbot> ACTION-588 -- Noah Mendelsohn to work with Larry to update mime-web product page Due 2011-08-18 -- due 2011-09-15 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/588
<noah> ACTION-588 Due 2011-10-25
<trackbot> ACTION-588 Work with Larry to update mime-web product page Due 2011-08-18 due date now 2011-10-25
Discussion of draft http://www.w3.org/2001/tag/doc/IdentifyingApplicationState-20110910.html
Noah: the goal is to progress toward publishing a finding, and find a way to park the original document (as a Note)
LM: stepping back... It is written generically, but really targeting http: URIs, data: URIs and fragment identifiers is not discussed as it is only client-side.
(discussion about fragment being allowed in data URI or not)
<JeniT> Is the proposal to publish this as a draft finding or a final finding?
<Ashok> Final, I believe
ht: (regarding final or draft finding), we can publish this as final, or we can do a call fo review before publishing
it's up to us to decide
LM: it's the kind of document where we need community consensus
DKA: maybe there is no difference between publishing it as a finding and waiting feedback, and publish a draft and ask for feedback.
... we need to have "Proposed Finding" state
Ashok, can be done in the status section
<Ashok> Or in a covering note
<DKA> PROPOSED RESOLUTION: We publish the "Identifying Application State" document as a "proposed finding" between now and TPAC, with a fixed feedback time-frame. We bring attention to it at TPAC and encourage people to send feedback. We then collect the feedback and publish it as a finding a [month after] TPAC.
Ashok: got external comments on the previous drafts, not on this one
... there are two actions opened, we should close them and open a new one.
Noah: Do you want to publish before or after TPAC?
Ashok: the plan is to publish as soon as possible and talk about it during TPAC
RESOLUTION: The TAG will publish the "Identifying Application State" document as a "proposed finding" by 30 Sept. 2011, and will solicit feedback to be due by 15 November. We will bring attention to the draft at TPAC and encourage people to send feedback. Unless major concerns are raised, goal is to publish a final finding no later than Jan. 2012 F2F.
jar will help doing some copy editing before publication
<noah> ACTION: Jonathan to copy edit the finding on application state Due: 2011-09-21 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-596 - Copy edit the finding on application state Due: 2011-09-21 [on Jonathan Rees - due 2011-09-20].
<noah> ACTION-481?
<trackbot> ACTION-481 -- Ashok Malhotra to update client-side state document with help from Raman -- due 2011-09-10 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/481
<noah> close ACTION-481
<trackbot> ACTION-481 Update client-side state document with help from Raman closed
<noah> . ACTION: Ashok to publish a final draft for public review of the finding on Application State Due: 2011-09-30
<noah> ACTION: Ashok to publish a final draft for public review of the finding on Application State Due: 2011-09-30 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-597 - Publish a final draft for public review of the finding on Application State Due: 2011-09-30 [on Ashok Malhotra - due 2011-09-20].
<noah> ACTION-586?
<trackbot> ACTION-586 -- Ashok Malhotra to add text covering advice equivalent to "Use of AJAX implementation technology is not a sufficient excuse for failing to provide first class URI identification for documents on the Web" -- due 2011-08-11 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/586
<noah> close ACTION-586
<trackbot> ACTION-586 Add text covering advice equivalent to "Use of AJAX implementation technology is not a sufficient excuse for failing to provide first class URI identification for documents on the Web" closed
<noah> YL: Wrt to Raman's draft, we can remove the content or mark as legacy, indicating that it's superceded by the TAG finding.
<noah> YL: But...this can't happen until the TAG finding is final
<noah> ACTION: Yves to publish as a note what had been the FPWD (Raman's draft) on client side state: Due: 2011-01-15 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-598 - Publish as a note what had been the FPWD (Raman's draft) on client side state: Due: 2011-01-15 [on Yves Lafon - due 2011-09-20].
<noah> ACTION-598 Due 2012-01-15
<trackbot> ACTION-598 Publish as a note what had been the FPWD (Raman's draft) on client side state: Due: 2011-01-15 due date now 2012-01-15
<masinter> (a) follow up from our last call comments
Noah: proposal... one part of the work was on microdata/RDFa. That is now tracked outside, so we should mark last call review as done, and get action to track further development of HTML5
<masinter> (b) things that should be done for HTML.next, not HTML5
LM: we need to track the 'author' view
... there are discussions about HTML.next, rechartering etc... This could be a topic for the TAG
<noah> PROPOSED RESOLUTION: The TAG will close out the major TAG "Product" titled HTML5 Last Call Review, but will pursue ongoing related initiatives (e.g. microdata/RDFa), and will generally keep tracking HTML5 developments
RESOLUTION: The TAG will close out the major TAG "Product" titled HTML5 Last Call Review, but will pursue ongoing related initiatives (e.g. microdata/RDFa), and will generally keep tracking HTML5 developments
<noah> NM: It's worth having a general tracking action on HTML5
<noah> ACTION: Noah to close out HTML5 review product Due: 2011-10-15 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-599 - Close out HTML5 review product Due: 2011-10-15 [on Noah Mendelsohn - due 2011-09-20].
LM: do we have any comments on what needs to be done in the future of HTML?
<noah> AM: What do you mean future version?
<noah> NM: What would be called HTML6 if you were/are using version numbers
ashok: looking at issue list, we have many that are postponed, assigned to 'next release'
(discussion about HTML-XML TF and the possibility of the community doing convergence)
Noah: let's look at the first use case http://www.w3.org/2010/html-xml/snapshot/report.html#uc01
LM: not sure the two solutions allow me to use XSLT
Noah: it does as it light the path on the work to be done to do concrete integration
(discussion about the polyglot vs html5 parser of "invalid" markup)
<masinter> should the Authoring view of HTML document make documents non-conforming if they can't be turned into polyglot
<noah> ACTION-560?
<trackbot> ACTION-560 -- Henry Thompson to review HTML polyglot last call Due 2011-06-06 -- due 2011-06-02 -- OPEN
<trackbot> http://www.w3.org/2001/tag/group/track/actions/560
<noah> NM: Overtaken by events?
<noah> HT: No, I want to review it, please bump the date.
<noah> ACTION-560 Due 2011-11-30
<trackbot> ACTION-560 Review HTML polyglot last call Due 2011-06-06 due date now 2011-11-30
LM: we failed to apply comments on things that were under way, however it would be good to discuss and give input on what's next
jar: we have a collision course with research on distributed systems and what's deployed using HTML now
[Larry Masinter pastes in the text of email message from Maciej Stachowiak to HTML WG list dated 10 Aug 2011, http://lists.w3.org/Archives/Public/public-html/2011Aug/0263.html ]
<masinter> Hello Working Group,
<masinter> Now that the Last Call period is over, it's a good time to start thinking about the next steps in the evolution beyond HTML5.
<masinter> There are a few ways we can start thinking and talking more about HTML.next:
<masinter> 1) Let's start up some discussion and collection of post-HTML5 feature ideas.
<masinter> 2) Though we cannot yet publish post-HTML5 deliverables as Working Drafts, nothing stops us from creating Editor's Drafts. So current editors and anyone else who is interested are encouraged to create post-HTML5 proposed Editor's Drafts for consideration, in parallel with the versions working their way through the LC process.
<masinter> 3) To be able to publish post-HTML5 delieverables, we will have to change the charter of the Working Group. There are two possible tracks we can take:
<masinter> A) Come up with a detailed definition of the requirements, scope, and expectations for our next-generation deliverables, and cast that as a new charter.
<masinter> B) Update the current charter and give a fairly loosely defined scope for post-HTML5 deliverables.
<masinter> Option A is much more clear about the next phase of our work, which is helpful in some ways, but it may require longer discussion to be clear about the scope. Option B likely requires less careful wording and negotiation. There is some interest in completing rechartering by the time of TPAC 2011. To achieve that, we'd have to have a draft charter ready in 3-5 weeks. We have W3C staff members who can help with the drafting.
<masinter> The Chairs welcome discussion of any or all of these topics. This will also be a discussion item at this week's telecon.
<masinter> Regards,
<masinter> Maciej
<masinter> my question is whether the TAG wants to/should participate in that process
Tim: The issue is that if we decide what should be next, it could end up like XHTML2
ht: it is evolutionary, it gathers more functionality, the browser becomes the platform. But the browser was not originally designed to transform itself in an OS.
<jar> "it wasn't meant to do X" ...
<jar> dka: web runtimes as alternative clients (widgets)
<jar> dka: enormous pushback on widgets
DKA: the intent of widget was packaging web application, install them _as real applications_, and it's widely deployed. There was a lot of pushback as it was seen as destroying the web
<noah> It's widely deployed? I thought he said widely "vilified"
he said both
<DKA> I said that Adobe Air was widely deployed - and that this was a good example of a Web Runtime environment (though a proprietary one). The idea of W3C Widgets was to standardise the approach to packaging up apps for such a runtime environment.
Tim: There was a set of competitive languages, and javascript won. This direction got some momentum. For web application, many things were missing, like giving access to the web (see CORS). Packaging is not really an issue, the main one is about master files
... using all the pieces we currently have and create a few more steps, we can really go further
<Zakim> masinter, you wanted to propose a way forward
<Zakim> DKA, you wanted to suggest we step through "Section 5: Recommended Best Practices"?
DKA: native apps vs the web... when talking about widgets.. people were complaining that it was not the web (even if using web techniques) because it was not running in the browser
... one issue is the possibility to address 'web runtime'.
... There is a need for a version of widget that is really part of the web
... and it may converge with an upgraded version of appcache
<noah> AM: Things run in the browser, right?
<timbl> dka: The app runs inside a webkit instance, but not a browser
<timbl> ... it is a web runtime, not a browser
<noah> DKA: No, not in the story I told. Something like Webkit, yes, but browser typically not.
<timbl> tim: It has the DOIM [DOM] and many browser-like things
<timbl> Ashok: Suppose we don't use JS?
ht: I said that we don't need a meeting to discuss about the browser evolving. A meeting is good for radical changes, but not sure it's needed
noah: there is a group of people who will work on what's next, it may or may not go through radical changes, but the question is "should we engage in that process" be it monitoring, doing charter change, give small or bigger input etc...
<Zakim> jar, you wanted to wonder about how predictable the trajectory ought to be
LM: in august, Maciej sent a note about the rechartering. So it's about the TAG having an input on the charter or not
DKA: the workshop on offline web application may lead to such input
<masinter> http://lists.w3.org/Archives/Public/public-html/2011Aug/0263.html
<noah> NM: Can anyone get involved in HTML next tracking
<noah> NM: Can you report to the TAG on it
http://www.w3.org/2011/web-apps-ws/
<noah> DKA: Yes, I think I could. Relates closely to the workshop.
<noah> DKA: Workshop scope is narrower.
<masinter> What I said was that web-apps-ws is orthogonal to HTML.next
<masinter> web-apps could be done entirely with SVG and XML and not HTML anywhere
<noah> ACTION: Appelquist to report to TAG on goals, scope and progress to date for HTML.next work Due: 2011-10-18 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-600 - Report to TAG on goals, scope and progress to date for HTML.next work Due: 2011-10-18 [on Daniel Appelquist - due 2011-09-20].
<noah> ACTION: Noah to document in product pages wrapup of HTML5 last call work, leading to HTML next review Due: 2011-10-11 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-601 - Document in product pages wrapup of HTML5 last call work, leading to HTML next review Due: 2011-10-11 [on Noah Mendelsohn - due 2011-09-20].
Tim, Peter, DKA, ht, Noah, Larry should be at TPAC
Everybody is expected at the January F2F
The proposed plan for the April TAG meeting seems ok with everybody, so almost ready for confirmation (need Jeni's input to finalize)
<noah> ACTION-565
<noah> ACTION-565?
<trackbot> ACTION-565 -- Noah Mendelsohn to talk to Bernard about possible IAB/TAG co-location -- due 2011-08-16 -- PENDINGREVIEW
<trackbot> http://www.w3.org/2001/tag/group/track/actions/565
<noah> close ACTION-565
<trackbot> ACTION-565 Talk to Bernard about possible IAB/TAG co-location closed
<noah> ACTION: Noah to work with IETF liaisons to propose possible TAG participation in IETF paris Due: 2011-10-10 [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-602 - Work with IETF liaisons to propose possible TAG participation in IETF paris Due: 2011-10-10 [on Noah Mendelsohn - due 2011-09-20].
formal liaisons are Thomas Roessler and Philippe Le Hegaret, and Mark Nottingham
<DKA> This is the workshop on the future of offline webapps: http://www.w3.org/2011/web-apps-ws/ - set for 5th of November in Redwood City.
<noah> ACTION: Noah to mention to Ian to document level of TAG commitment in nomination info [recorded in http://www.w3.org/2011/09/13-tagmem-irc]
<trackbot> Created ACTION-603 - Mention to Ian to document level of TAG commitment in nomination info [on Noah Mendelsohn - due 2011-09-20].
<noah> NM: Should app cache vs. app packaging be on the headsup list for Jeff?
<noah> DKA: Yes.
<noah> NM: OK, please remind me.
{kind=link}
{kind=link}
{kind=link}
{kind=link}