SW: Would it be better to stick with the plan to have a telcon with Aria tomorrow, or maybe on the 13th of March?
TVR: I would prefer to wait, and encourage Tim to send an email to Michael Cooper clarifying his position, which will make the later discussion more productive.
TBL: That's OK with me.
SW: I will tell Al Gilman that this is what we suggest doing.
<ht_vancouver> http://lists.w3.org/Archives/Member/tag/2008Feb/att-0101/persistence.html
HT: I would like to discuss http://lists.w3.org/Archives/Member/tag/2008Feb/att-0101/persistence.html . I'm sorry it took so long for me to prepare this.
SW: Could you give background for our new members, please?
HT: This goes back at least 2-3 years.
JR: Actually, the issue is older than that.
HT: Despite the lines in WebArch that say "use http-scheme URIs for everything", there's quite a bit of energy behind using new URI schemes, e.g. in the Library Science community, and other contexts where persistent URIs are a big concern, and also in lots of other places. The Government of New Zealand is using new URN subspaces e.g. for identifying namespaces. A new and widely publicized proposal for a new URI scheme called XRI also drew attention to this. We had a request for the TAG to look at this. Dave Orchard and I did early drafts. The feedback was: this will only convinced those who are already convinced. There also was useful discussion with the community that was proposing lsid as a new URI scheme. I pointed them to John Kunze's work on the ark scheme, which uses http.
<DanC_lap> http://dot.ucop.edu/home/jak/cv.html John A. Kunze
HT: It seemed that the XRI work stopped short of full Oasis Recommendation-like status (can't remember what Oasis calls that). XRI was redesigned to shift focus away from persistent identifiers and toward providing names for things and individuals, much as you'd need for RDF. There is a relative XRI =henryt that is defined as equivalent to xri://=henryt
DO: These are not really URIs; they don't meet the syntactic constraints.
HT: Well, they're like IRIs. Those aren't URIs either until you escape them, and then they can be. Turns out they are publishing new drafts, labelled 2.0, which are nearing what we would call "last call" status. We the TAG noticed these late, and sent some last minute questions. I have some reason to believe they are preparing a response to us. They also appear to be working on some new drafts.
AM: What is the problem they are trying to solve?
HT: I've been trying to understand that.
Scribe thinks the draft in question is probably: http://docs.oasis-open.org/xri/2.0/specs/cd02/xri-resolution-V2.0-cd-02.html
HT: Note that Dave and I have more or less split the TAG draft. I've worked on some parts; he's worked on others.
DO: Ashok asks a good question. I think reasons include 1) persistence of resolution to a resource and 2) guarantee that the identifier is persistently assigned over time
AM: Does that mean that an XRI designating, say, the current director of W3C couldn't eventually resolve to Tim's successor?
NM: No, I >think< the concern is that someone doesn't grab your XRI if, say, someone else grabs what you thought was your DNS registration.
<Stuart> https://2idi.com/register/create_account offers individual i-name registrations for $12 per year.
HT: IANA has some procedures that I, Henry, can go through if I'm unhappy with what people are doing with, say, DNS HenryThompson.name. They may have that goal too, but last I looked, the exact escalation mechanism was listed as TBD.
<Stuart> http://2idi.com/register
DO: They have acknowledged that there is resolution of say example.foo.com, which is in some sense resolved by asking foo.com what example.foo.com is, and then doing similar things with paths. They seem not to like the split between DNS (.) resolution vs path (/) resolution in URIs. XRI's can more uniformly use (/).
HT: I'll get to that later. My document, which we're about to discuss, is all about delegation. I've come to believe that's the substantive issue.
SW: Last I looked, if I want =skw, I have to pay $12 year. Not clear to me what happens next year if I don't pay.
TBL: Doesn't seem functionally different from the DNS story.
HT: Yes, I'd like to move on to discussing the draft TAG finding, which really isn't best seen as a critique of XRIs. I think there are general concerns of the communities that desire the two persistence properties we've discussed (persistent mapping to representations, and also a uniform mechanism for naming and accessing metadata). I'm not going to discuss the latter, in part because the TAG is ramping up discussion of that under ISSUE-57, httpRedirections-57. Still, we won't have a complete answer to the concerned communities until we figure out the metadata bit. There are two issues relating to persistence. 1: domain names aren't owned, they're leased. Still, it's the only universally available lookup mechanisms.
JR: On the Internet.
DC: There are also things like Freenode, which is a P2P system.
HT: OK, so by the way, we are talking about naming system for the Web, and retrieval is fundamental to what we're discussing. I believe that Ray Dennenberg, by contrast, specficially wants a system for which retrieval is known NOT to be possible. I'm not discussing that now.
TBL: Libraries have the interesting characteristic that in many cases, only 10% of materials put into the libary are ever checked out.
JR: But, do you know in advance which 10%?
HT: Nobody ever expects the network effect :-) Pretty much all of these schemes are a combination of lookup and hierarchy, and with the possible exception of Freenode, most of the ones we see use DNS as the lookup bootstrap. IANA has very fundamentally sound reasons for leasing not selling. It's not clear to me there's a way around that.
TBL: Can you elaborate?
HT: No. I should say, I haven't studied it enough to fully justify what I've said, but it's my intuition.
<DanC_lap> "Full domain ownership" -- https://www.gandi.net/domain/buy/search/
HT: I think it's important that we tackle this for the foundational domains of the Web itself. I think we need a holding company that has a legal right to inherit names that others fail to keep.
TBL: The legal contracts are tied to to the top level domains, like ".org". I'd like to start a TAG discussion, sometime, of what the requirements would be. That's not a general solution.
NM: What did you mean by foundational. Is ibm.com in it?
HT: Could be a false assumption, but I'm assuming there's a category difference for the organizations that have on the Web documents that are not only on the Web, but constitutional of what the Web is.
TBL: We need a name for those.
NM: So, you're worried that if iana.org gets taken, then the list of registered scheme names can get hijacked?
TBL: I think the role of MIT libraries, the Louvre etc. in the social system of maintaining the archives of the world's technical material, e.g. Microsoft Vista manuals, is an important piece of this puzzle.
JR: Important yes, but different.
HT: I agree.
(Scribe is falling behind Tim, a bit)
TBL: Having the manuals is important.
HT: Having the manuals isn't the issue, but having them at the same URI is. That said, I don't want to have this discussion today. I have other things I want to discuss in this agenda slot. I'm focussing on communities that want naming conventions with persistence characteristics that meet their needs. That includes Life Science Identifiers (LSID), references to scholarly papers, etc. They are all nervous about, and have some bad experiences with, the single point of failure that's involved in the DNS lookup step.
JR: Well, I think they're wrong about that concern.
HT: You can certainly get fault tolerance in the moment with failover to multiple machines. The deeper problems are the social ones. The owner of a name may, for various reasons, stop providing access to representations of resources for which they have been responsible. Delegation is the name for the answer in general, but I'm exploring two flavors of solution.
... 1) Centralzation: put all your eggs in one basket and watch that basket. Everyone agrees there will be one domain name. The group will work really hard to make sure resolution works in perpetuity. There is still a nonzero possibility of trouble with the single point of failure. There may also be quite complex contractual frameworks required to ensure that the expectations are properly agreed to. Another concern I've heard is that there's a loss of "branding", in that you lose the opportunity to
"advertise" another organization in the DNS part of the URI string.
... 2) Delegation as Replication: two or more lookups are done, before you get to the hierarchy part. "If just one of us survives, we're OK". Consider an ARK example. Each URI references one of the DNS names, e.g. http://adfdasf.lib.berkeley.edu/ark://inf.ed.ac.eu/ If either Berkeley.edu or the other site survives, the resolution works. You could use ark.org
NM: To be architecturally sound, don't you need to start with http://ark.org as the prefix. Otherwise, what happens if I manage to register berkeley.edu to myself?
TBL: Not an issue, Berekely.edu won't be stolen.
NM: But I thought the whole point of this complexity to deal with the case where it WAS stolen?
HT: Noah's right, I think. Note that this deals with the branding concerns, at least in some ways. WebArch says "A URI owner SHOULD NOT associate arbitrarily different URIs with the same resource." BUT, I don't think swapping out the DNS names in this scheme is really arbitrary. So, doesn't violate WebArch.
TBL: You'll sort of wind up with a new protocol built on top of HTTP. Not totally bad, but a tradeoff.
HT: Yes.
TBL: Don't John at Berkeley and others share a responsibility for agreeing on serving the data?
HT: No, not for serving the data. Only for preserving the stability of the name mappings.
NW: What have we gained? If University of Edinburgh goes out of business, I buy their DNS name, and serve bad content. How does this scheme help?
HT: Policies under which control is taken away are hard to formulate.
NM: I understand how Norm can set up his challenge, I don't know how a client will pick Norm's content vs. the intended.
HT: You still need replication of representations.
NM: Berkeley and Edinburgh are not symmetric. Edinburgh is a data server. If it gets taken over, then the core managers (Berekeley) agree that Edinburgh isn't trustworthy and route around it.
<DaveO> I *think* that Tim's point is that the 2nd level name can evolve and can transition to a new organization..
HT: Regarding Noah's challenge about Berkeley.edu, in this example being hijacked, the only thing I can see to say is that the clients may know to try some of the others that have joined with Berkeley in maintaining these. You can also put a hash code in the URI. That's the only way to ensure that "that which is named" doesn't change. Point 3. Centralize naming, distributed storage.
DC: like purl.org.
HT: Yes, I think so.
TBL: I think the Akamai approach is interesting. You hash URIs onto a ring that runs 0-1, into which the servers have arranged themselves. If that server doesn't have, you go around to the next one. You're just guessing, with very high probability, where you'll find a server for a representation. You can go straight to the data.
<Zakim> DanC_lap, you wanted to point out that gandi.net sells (not rents) domain names
DC: Going back to selling vs. renting, gandi.net offers to sell you not rent.
NM: Do they have to "rent" at the next level up?
HT: No, I think the next level up just brokers.
TBL: I'm more and more convinced that we need a top level domain for doing buying vs. renting right.
<DanC_lap> (there's a .museum tld; I wonder if it meets timbl's requirements)
NM: Socially, I expect that people would finding calling it "museum" would be confusing, even if it otherwise was entirely suitable.
<DanC_lap> (see http://about.museum/ )
HT: I agree with everything Tim said except the bit about needing a top-level domain.
TVR: Where does that leave us as the TAG in terms of what we can actually do?
<timbl_> See http://www.w3.org/DesignIssues/PersistentDomains
SW: The previous draft of our finding seemed pretty hard over on "use http URIs". You were going to reconsider in doing this draft. Where are we now?
HT: I'd like to take this note and use it as a new beginning to reframe the finding. I'd like to reframe the substance of the finding as "here are the tradeoffs". I think we still can say, with modest cost that we identify, such as escaping requirements and round trips: "http can be used for all of this"
<jar> Need a URI analog of http://www.nature.org/aboutus/leadership/art15495.html
HT: The subtext is that the costs of using http for doing these things are typically low enough, and the benefits are great enough, that we can recommend it.
DO: Do you think you are addressing the need that the XRI folks have expressed? It's the same as the reason the WAF group is doing their things. It can be in an HTTP header or in a processing instruction. I think the XRI folks want to have the recursion through the path controlled by the creator of the document.
HT: That's a social contract saying that the people at xri.org will respond to GETs by interpreting documents of that structure.
DO: It's other organizations too.
HT: Yes, it starts at xri.org. It's a social contract, but I'm not convinced the URI needs to start with an xri: URI scheme to make that practical. I'll have to think about how to clarify that what you do at each stage of the lookup process, you have have the control you want in the places you want it.
SW: Are you saying your action's done?
<timbl_> TimBL: Proposed that a new TLD is necessary.
HT: No, I didn't do a draft finding.
SW: And when you do a draft we'll get it back on our agenda.
<timbl_> Timbl: the social contracs around the current TLDs are source of te current anxieties which give rise to these new systems like XRI.
TBL: I would like to ask that the next version of the document will include how you would do it, and perhaps in yet another section how I would do it?
HT: If you mean addressing the domain name persistence question, I think that's a different issue.
TBL: I thought that to meet the goals of the paper, you have to discuss the social and other issues around top level domains.
HT: We need to discuss offline.
TVR: How can we as TAG influence domain name persistence?
TBL: We can.
TBL: We can propose all kinds of things. The TAG has status and influence regarding things like this.
<timbl_> TimBL: The TAG could propose a new TLD and the cration of a new organization to run it.
SW: BREAK
HT: This draft was influenced by Tim's note on the Interpretation of XML Documents http://www.w3.org/DesignIssues/XML which points out that the recursive interpretation of XML documents is the natural one. Seems to offer a way into addressing semantics of documents with more than one namespace. The finding winds up focussing on the question of "what's the default processing model". Is there any sequence of steps that applications should as a matter of course perform before consuming XML documents. Later, we framed this as "If an author takes responsibility for the information in an XML document, what is she/he taking responsibility for." Consider, e.g. the case of a document I send you with XInclude statements in it. Am I communicating the raw infoset, with the include element itself, or is it better on balance to say that I'm taking responsibility for the document that results. When the inclusion is perform! ed?
TVR: What about processing instructions asking for XSLT transforms?
HT: Known to be an open question.
<ht_vancouver> http://www.w3.org/2001/tag/doc/elabInfoset-20071127/elabInfoset.xml#definition
HT: The ones we prioritized as likely highest were XInclude, Signature checking, and Encryption.
<Stuart> http://www.w3.org/2001/tag/doc/elabInfoset/
HT: We are discussing http://www.w3.org/2001/tag/doc/elabInfoset-20071127/
TVR: How deep do you go on nested inclusion?
NW: Xinclude says you must go all the way down.
TBL: Doesn't seem right. I you should say "the document means this", not "processors must do this".
NW: I think the spec is a bit more careful about this. XInclude speaks of a synthesized infoset. I think it may do it quite declaratively.
TBL: These specifications shouldn't say what processors do when there's an error. They should declare the interpretation of legal documents.
NM: Yes.
HT: This document defines a general notion of an elaboration signal. Also defined is a general notion of quotation.
TBL: Tim has previously commented that quotation should be tied to particular XML vocabularies, not at the document level. (scribe isn't sure why this appears to have Tim speaking of himself in the 3rd person -- probably a mistake in scribing, but there is no better record of what was said)
HT: Section 4.1 in this draft attempts to address this objection by saying that individual parts of documents can signal this individually.
NM: The first sentence in 4.1 parses ambiguously. In particular, it can be read as implying that "documents are in namespaces".
HT: Not my intention. I'll fix it.
SW: Can we move past the history to the draft that's on the table?
HT: Yes, I will. Note that section 6 hasn't caught up with the rest of the document.
TVR: What if for whatever reason I start with a simple document not using namespaces? If I later Xinclude it in a document that uses namespaces, does it inherit the container namespace?
NW: No. It stays not in a namespace.
NM: I'd suggest perhaps factoring the mention of namespaces and why this finding will generally most useful with markup that's namespace-qualified, but then just referring to things like "quoting elements".
<Stuart> Hmmmm.... I am vex'ed really by the globally scoped/locally scoped nature of qualified element names... ie. the significance even of a qualified element name (say it's content model) *can* vary by structural position in a document - cf SCUDs for assiging URI for element and attribute names.
TBL: Yes, and sometime I would like to find a way to discuss the idea we mentioned yesterday, of establishing default prefixes based on media type. Is there a lot of XML being used out there that's not using namespaces?
NW: A lot of the messages being passed for RESTful APIs aren't using namespaces.
NM: OK, that convinces me a bit more that factoring the mention of namespaces might be a good thing. These folks doing RESTful messages might still find the finding helpful in clarifying quoting elements, etc., even if those are not qualified.
TBL: Yes. When things aren't qualified, the semantics have to be grounded in prior agreements, and that applies to things like quoting too.
<DaveO> DBO: I can't remember seeing SOAP messages with bodies that don't have a namespace.
HT: If you're elaborating an infoset, what counts as quotation depends on where you are in the tree. SOAP may be an example. A SOAP intermediary needs to not elaborate the quoting, endpoint does.
TBL: That's a complicated way of looking at it. The message >has< one semantic. Maybe or maybe not one bit of software or another bothers to get at all that semantics by doing the expansion.
<DaveO> DBO:
<DaveO> DBO: Also, WS-I Basic Profile requires a namespace in soap body:
<DaveO> DBO: R1014 The children of the soap:Body element in a MESSAGE MUST be namespace qualified.
<Norm> Wow. I had no idea.
<Norm> Not unreasonble at all.
HT: I think we need to allow for different answers in different consumers.
TBL: Strongly disagree.
NM: I'm on the fence. Imagine a message. Some headers are encrypted with a key that's for document management software. That software never sees the document decrypted, just the control headers plus an encrypted blob. Tim as the ultimate receiver sees the opposite; his softwrae has the other keys, so never sees the management headers, just the body.
TVR: (scribe got behind something about multipart) I like Tim's answer.
<Stuart> http://www.ltg.ed.ac.uk/~ht/compositional.pdf
HT: I have tried to explore a compositional semantics of XML in the document http://www.w3.org/2001/tag/doc/elabInfoset-20071127/ . As an example, I remind you of RDF, which has a convention for embedding XML as XML, inside an RDF/XML document. This isn't infosets and elaboration yet, just the particular interpretation of XML burried in RDF/XML.
TBL: Too bad that the elaboration signal in this case is an attribute, but it still works.
HT: Yes, I just used a partial function from element names + attribute sets to consequences. It accommodates signals in attributes as well.
<DanC_lap> (oops; I didn't manage to do read this bit on composition, despite my action to do so. )
(Henry then summarizes the document)
(Henry explores the definition (15) in the document. Scribe finds it impractical to retype all of this mathematical notation on the fly).
TBL: The "exclusion" parameter seems to be too much complexity.
DO: In a financial transaction, you might want to have the same markup (encrypted credit card number) elaborated in some contexts and not others.
<Zakim> timbl_, you wanted to intosoduce the use case of query on an elabrated infoset which only slects certain things, eg credit card #
NM: Whether to try to decrypt the credit card number might depend not just on the document contents, but also on whether you are the auditing application or something else.
TBL: Imagine an XPath recursing down looking for a customer number. Never happens to trip over the credit card number. If I get to where I need the key and I don't have it, that's a bug.
DO: No, it's not a bug. Noah had it right. It depends on what Hal Lockhard calls the "situation". You may be looking at the message, and your application has to store it in the database encrypted. With a different application, you may need it plain text. That information about the situation can't by entirely found in the document. So, the elaboration will be influenced by the situation.
TBL: That's the X in the function.
HT: I'm afraid I didn't prep well enough for this. I've actually addressed this. "There is at least one flaw in this, where I said X is unlikely to be constant through the descent."
NM: Not just varying through the descent, also could be constant for a given tree traversal (I'm storing the document) vs. constant but different for a second traversal (this application always cracks open the credit card number)
TBL: I prefer to view Dave's case as lazy evaluation. There's one true semantic for the elaborated infoset, independent of whether every application chooses to get at it.
<Zakim> DaveO, you wanted to mention the "situation" is coming up elsewhere and to mention that maybe Hal can help Henry
DO: I think perhaps Hal Lockhart could be helpful.
AM: I'm thinking of standard documents that don't have these quoted things, and the situations. I'm thinking about a separate file or instruction that will tell you how to do the interpretation.
HT: A long time ago, we separated out talking about things like pipeline languages. Here, we're talking about the handful of things that apply across the board
<scribe> scribenick: ht_vancouver
NM: This relates to the self-describing web stuff. There's this context-independence invariant which a lot of the web depends on. What we're trying to do is derive some very general [elaborations] which go with _any_ application/...+xml message body Consider a google crawler that knows nothing but what it gets at the end of a URI -- where would it look for a separate 'situation' document?
<scribe> scribenick: noah
<Zakim> jar, you wanted to wonder whether an algebraic (equivalence) approach would be helpful
JR: I think you get in trouble if you talk about how things "are processed". Another approach is to talk about equivalences, e.g. between the initial document and the ones with the inclusion done. We then say do the same thing to both versions.
<timbl_> +q
<timbl_> +1
HT: I'm not sure whether that makes sense. What I'm trying to do in the pdf document is to state what the equivalences are.
JR: If I deal with both things, I should deal with them in the same way?
NM: Hmm, I'm not sure I see how to "deal with" the encrypted form of, say, an inventory list in the same way as the unencrypted form.
SW: How many people have read this
(seemed like about half of those present)
<jar> jar was suggesting a formal framework of the form: if A and B are equivalent, and if a processor handles both A and B, then it *must* handle A and B in the same way (sorry, this is online thinking, always a risk)
HT: Please give me an action to a) revise this document based on feedback and b) how to combine with the Elaborated Infoset draft finding.
SW: What might we "find" for our TAG finding?
<DanC_lap> trackbot-ng, status
ACTION Henry S. to a) revise composition.pdf to take account of suggestions from Tim & Jonathan and feedback from email and b) produce a new version of the Elaborated Infoset finding, possibly incorporating some of the PDF
<scribe> ACTION: Henry S. to a) revise composition.pdf to take account of suggestions from Tim & Jonathan and feedback from email and b) produce a new version of the Elaborated Infoset finding, possibly incorporating some of the PDF
<trackbot-ng> Created ACTION-113 - S. to a) revise composition.pdf to take account of suggestions from Tim & Jonathan and feedback from email and b) produce a new version of the Elaborated Infoset finding, possibly incorporating some of the PDF [on Henry S. Thompson - due 2008-03-05].
****ADJOURNED FOR LUNCH****
Collection of comments http://www.w3.org/2001/tag/2008/02/CommentsOnSelfDescribingWeb.html
<Norm> scribenick: Norm
<DaveO> I made comments in June in http://www.w3.org/2001/tag/2007/06/01-minutes
DaveO: I wanted to see some microformats in here. Both done right with the profile URI and then a discussion of how it's often not used correctly.
... The theory is that the microformats are grounded in URI space and can be self-describing, I think that many of them are, in fact, not, and many implementations also are not.
... We should point out the theory as well as the practice.
Noah: I did see the comment in June. I think you can look at microformats in two ways.
<Stuart> topic http://www.w3.org/2001/tag/2008/02/26-agenda#selfDescribingWeb
Noah: One, where short names are used in data values. I did try to tell that story.
... My question is, is there enough value in microformats to add it. It's hot this year, but will it be relevant later.
<DanC_lap> (on microformats and URI-based extensibility: http://microformats.org/wiki/misconceptions#microformats_use_non_URI_based_extensibility )
DaveO: I think microformats may be a prominent technology that could be used in a self-describing way, but we need to give advice to encourage them to do so.
... The microformats folks aren't really pushing this.
Noah: I think there's a choice, I've been trying to avoid getting into every particular technology.
... I can see two reason to add microformats, one is that it teaches a new principle; (and Noah didn't say what two was)
TimBL: Yes, I think we should tell that story.
Raman: I agree with Tim too.
DaveO: I also had a question about the use of RDF. I think the statements about RDF are too strong.
Noah: I think you're taking that a little out of context.
<DanC_lap> (noodling... "RDF [RDF] plays an important role for creating self-describing Web data resources, and for integrating representations rendered using other technologies such as XML."
<DanC_lap> )
General agreement that the text reads as if it says that if you're interested in self describing web, you should use RDF.
TimBL: I suggest that RDF be introduced as a common data model for integrating and processing data from many sources, and as a reference model for self-describing data.
Some discussion of the intent.
<DanC_lap> ("for data, if you can turn it into RDF, you're home," timbl just said. but graphs/relations aren't well supported in ordinary programming languages. s-expression-shaped things like the XML DOM or JSON feel more like "home" to a python/javascript programmer.)
Noah: What I meant it to read as was "RDF does two things, 1) sometimes it's how you store your data and 2) even if you're using some other technology, you can still use RDF as a model.
... Everyone is happy with the last para before 4.3.1?
No objections.
Stuart: I have some levels of discomfort.
JAR: Do you have a list of negative examples in mind?
Noah: I think that microformats were in part a negative, which is why I chose Atom
JAR: Negative examples are really helpful, but I can imagine why you didn't want to put them in.
Noah: If I add microformats, should I drop Atom?
... They seem to be teaching the same things.
DaveO: I like the Atom example; keep both.
Noah: Ok
DaveO: I think the Atom one is straight-up, they did it right, the microformats one is less clear.
... so having both would be valuable.
... There's only one microformat that mentions the profile, hCard, and none of the tools that generate them actually generate the profile.
JAR: Predicates being the same as another takes you out of OWL-DL. It'd be nice to avoid that here as it doesn't seem necessary.
Noah: I'll follow-up with you offline for a little OWL tutorial.
<DanC_lap> (short version: change sameAs to equivalentProperty)
JAR: RFC 2119 only applies to specifications. Personally, I find the SHOULDs a little off-putting in the absence of some expectation-setting.
DanC: The GPNs need work.
Noah: Should I just kill 2119?
General sentiment that we've abused it in the past.
Some discussion of whether the use of SHOULD/MUST is appropriate.
Ashok: In specs, these are conformance statements.
TimBL: A protocol spec is a contract, it says if you do these things, then you'll get these invariants.
... This is a lot like a spec; I'd like to see it made more spec-like.
Noah: I don't think SHOULDs are about conformance.
... There are no MUSTs in the document.
JAR: There's a distinction that I think is missing. The way I see a spec is a little different; it's like a game; it's a set of rules. You voluntarily enter the game, and when you do you take on a bunch of obligations. The spec is saying, if you're playing this game, then you should do these things.
... That's perfectly clear. If you want to say you're playing the game, then you must do these things.
... In this document, I'm missing the first part.
Noah: Do you find this in other findings?
JAR: Yes, it's not just about this finding.
Noah: Then maybe we should come back to this in a broader context.
<timbl_> Within a given community, there is a set of standards S, If within the community, all clients understand specs from S, and all server s express themselves uniquely using members of S, then clients will understand servers. The TAG has the dulty I suspect to ennumerate S for the web at large.
<Zakim> DanC_lap, you wanted to lean toward speaking to microformats as SXSWi is coming up; if it's too ephemeral, maybe a blog item instead or in addition? and to wonder if making new
Noah: I've put a lot of time into this, some of the comments are about the content and I'm happy to work on those for as long as it takes, or drop it, JAR has made a different comment. This finding is like the others but he has concerns about it. I'd have like to hear that before the first or second draft. If we want to change the style of fidnings, let's start the next one.
<timbl_> I agree with DamC. It is missing 4.1 and a half, MIME-type based extensibility.
DanC: Most W3C technologies shouldn't aim to be in the ubiquitous set; they should aim to be in the extension set.
... The things I like are:
<DanC_lap> "... when such self-describing resources are linked together, the Web as a whole can support reliable, ad hoc discovery of information."
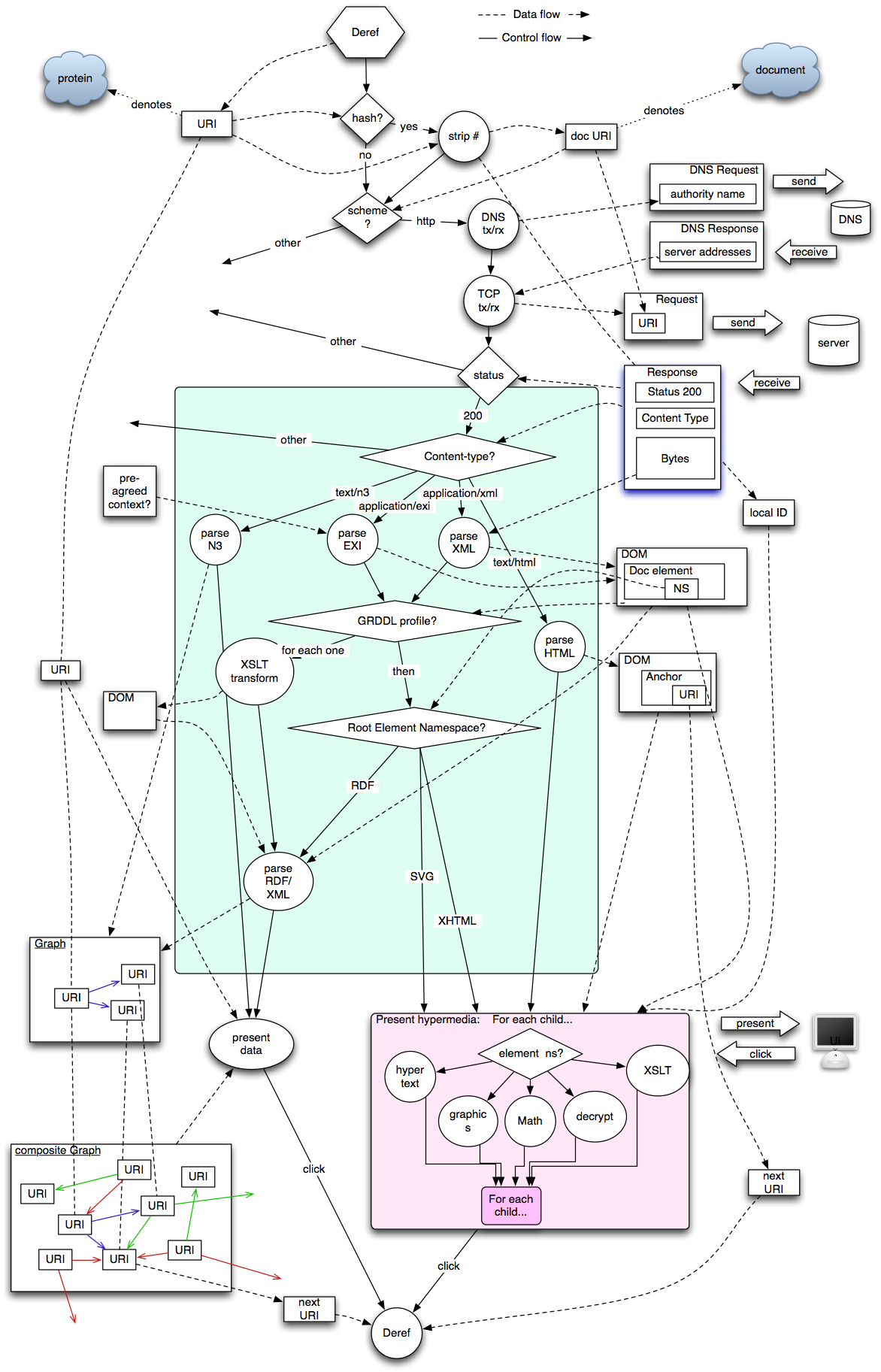
<timbl_> http://www.w3.org/DesignIssues/diagrams/arch/follow.png
DanC: GPNs not in support of a principle seem out of place to me.
<DanC_lap> self-describing resources promote reliable
<DanC_lap> [14:51] <timbl_> q?
<DanC_lap> [14:51] <Zakim> ... ad-hoc discovery of information
General agreement that a principle in this neighborhood would be a good thing.
TimBL: We could do an interoperability thing here. There was a web services event that did this.
... We could set the bar; at the moment, using my model of the set of standards, the standards which are shared are DNS, HTTP 1.1, HTML 4, RDF, GRDDL, XML.
<DanC_lap> (the list tim's giving is, to me, given in section "2 The Web's Standard Retrieval Algorithm")
TimBL: Maybe we do it separately for semantic web and presentation technologies
<DanC_lap> (GRDDL is designed to work even if not everybody groks it.)
<Zakim> timbl_, you wanted to note re RDF that it is also a standard for interoperability betwen applications
TimBL: To be compatible with this profile, for example, all semantic web technologies must implement GRDDL. We could point out that the microformats aren't in this space because they're not implemented by semantic web tools.
... You could make it a lot more like a spec this way.
<timbl_> http://www.w3.org/DesignIssues/diagrams/arch/follow.png
TimBL: In the spec, I'd like to see that diagram or one like it.
Some attempt to present both the diagram and Section 2 on the projector.
DanC: Aren't these pretty similar?
Noah: I think the diagram would be pretty frightening to a new comer.
TimBL: The green bit is basically interpreting an HTTP response.
... Well, more or less.
... The pink box is presenting hypermedia
Noah: I'm sure we could clean this up, but is it the level of detail that we want?
TimBL: I think that sections 4.* are different ways of adding stuff. And in a way, the fact that the diagram is messy, indicates how many points there are that you can try to hijack this. The sequence of the diagram lets you point out that you can hook things in where the pointy bits are.
DanC: Pointy bits? Flow?
Some discussion of the arrows on the right hand side
DanC: Ok. That's not self-evident.
Noah: I think what I'm stressing about is that I had a different reader in mind.
... I've tried to write this for users that don't need all this detail.
... The web is different than your private network because it promotes ad-hoc discovery by people who don't know each other.
... This diagram is in the same space, but for a different audience.
TimBL: The person I want to address is the one who is wondering whether to use RDF or a microformat.
DanC: With that diagram? How?
Noah: That's what I was thinking about when I wrote the text that I already got push back on.
... I'm very torn. There's a lot of good input here, but I'm not sure we're closing on this.
<timbl_> Suggest: s/Good Practice: RDFa SHOULD be used to make information conveyed in HTML self-describing./Good Practice: RDFa will be usable be used to make information conveyed in HTML self-describing when and only when RDFa is an accepted recommendatio
TimBL: I'm happy for the more rigerous version to be in the architecture of the semantic web activity.
JAR: Yes, some of this could be expressed more formally.
... This document is saying things that are different from what an ontology of HTTP document would say.
Noah: It shouldn't conflict.
TimBL: Does it?
JAR: We can talk more about what this AWWSW effort is doing, but this is more advice to people in the trenches. Ideally, the RDF also has that property, but we aren't there yet.
Noah: This is inspiring to correctness, but not rigor. It's trying to show you some principles.
<DanC_lap> (again: pointer to david booth's rules?)
<DanC_lap> (aha... http://esw.w3.org/topic/AwwswDboothsRules )
Some discussion of David Booth's rules, which we plan to discuss tomorrow morning.
JAR: Just because you have a model, that's different from giving advice or direction about what mechanisms you should use.
TimBL: The RDF rules say "these are the things that a client infers and therefore, it provides a protocol and expections at a much stronger level"
JAR: But it's not prescriptive in the same way. It allows you to deduce that good practice is such and such, but it doesn't actually say that.
DanC: It seems to me like the difference between saying "if you open that door, I'll be happy" and "would you please open that door"
<Zakim> DanC_lap, you wanted to note that GRDDL is designed to be dynamically discovered, not ubiquitously known
TimBL: The sequence in the bullets in 2, I think is important. We need something else to address in the semantic web.
... I'd like you to mention the fact that there's a crucial decision to make about whether or not something is an accepted standard. For example, right now, the jury is still out on RDFa.
<DanC_lap> (to repeat: GPNs not in support of any particular priniciple seem out of place to me)
Noah: Anyone else happy with that?
DanC: No. I think GPNs without principles are awkward.
<timbl_> Principle: A set of standards, shared betweem many readers and many writers, allow interoperability.
Noah: The good practice is that it helps you follow your nose.
<timbl_> Principle: Flexibility points in the architecture allow specifications, metadat and code to be found which allow the smooth extesion of the set of standards.
Noah: I'm happy to do whatever makes sense, but I don't want to thrash.
<DanC_lap> (I'm struggling with stuff like "the web will be a better place if you use GRDDL". I'm not sure why...)
Henry: I'd prefer a middle way, which is you should separate this document at least conceptually into two parts: one is the self-describing old-fashioned web and two is extensions into the semantic web.
Noah: That's why 4.3 is its own subsection, but clearly that's not working for you.
<timbl_> I cannot see why GRDDL deosn't have to be in hte set of standards fro it to work
Henry: All I'm saying is, the GPNs should say "GPN for the semantic web" or something like that.
Stuart: I'd be reluctant to say that without being sure that the semantic web community is behind us.
<timbl_> +1 to upgrade 4.3 as insert new 5
Henry: At the moment, I don't see any gradation and I think that would be useful for someone coming to this document to find answers about how to put information the web: this is the bare minimum, this is the sweet spot, this is the whole thing.
Ashok: Who is this for and why should they pay attention?
Noah quotes from the abstract.
<Zakim> Stuart, you wanted to mention concerns wrt to intention and GRDDL/RDFa 'mined' triples.
Broadly: language designers not web masters.
Stuart: In the GRDDL/RDFa area, I'm a little uncomfortable with "mining triples out of documents". With respect to GRDDL/RDFa, you can look at in two ways: are the triples really there because the author put them in, or are you mining them out where maybe the author didn't intend them.
Noah: I think its a non-issue; for GRDDL, you have to make it explicit.
<timbl_> The self-describing web mean s that there is one meaning for each doeumcnt, so mining and experssion MUST be the same.
It may be less clear for RDFa.
Stuart: I'm not sure I agree, you have to really understand what the transformation is going to do in order to understand the statements.
TimBL: I think documents have a context insensitive meaning. There's no difference. Because you used a standard mechanism to extract the information, the author must be held accountable for that information.
Stuart: I hear what you're saying, but I find it a hard sell.
<DanC_lap> +1 thesis is: each document has one context-free meaning (or at least: one meaning in the context of ubiquitously deployed standards)
Stuart: Especially when the GRDDL may change.
TimBL: I think that's a corner case.
Noah: Is there a good story here about the distinction between explicitly putting in a GRDDL link in and having one implicitly.
DanC: No, I don't think so.
Some discussion of how GRDDL might be found.
<timbl_> acktimbl_
<Zakim> timbl2, you wanted to suggest an opening for the new section 5
TimBL: I wanted to suggest that 4.3 should be a new section 5.
... With new introductory text.
<Zakim> DanC_lap, you wanted to put my finger on something about MIME types and media plug-ins and to note comments on RDFa test case #1
DanC: I had these vague feelings about MIME types. Section 2 is pretty standard. Section 3 says use something analagous to "use PNG instead of some new format"
... Section 4 is new stuff.
Noah: Yeah, I think may be we should drop 4.1
... It's only indirectly about self-describing.
TimBL: I think it's perfect.
... It says "don't"
DanC: I would rather that this was more ordered: if you're thinking about a new URI scheme or a new MIME type, a new MIME type; a new namespace or a new media type, a new namespace.
<DanC_lap> uri scheme costs more than new mime type; new mime type costs more than new namespace
DanC: After section 4.1, then we get into RDF and the semantic web.
... I'm wondering about flash plugins and java apps.
... When you want to extend the capability of the web and you want to publish something that doesn't fit, what people do is flash, ...
TimBL: Or they invent new attributes and then write scripts to do something with them.
DanC: there's a whole bunch of stuff about the semantic web but nothing about the hypertext web.
Noah: I thought we already talked about the hypertext web.
... The XML stuff winds up late because it was suggested that I tell the RDF/triple story first.
Some discussion of the flash case and how it boiled down to a new media type.
Noah: If follow-your-nose leads you to a new mime type, then all it means is that large numbers of users won't be able to understand the content.
... Mark Baker said don't use XML languages and I'd be grateful for advice on that point.
*** break ***
<ht_vancouver> 2001/tag/doc/nsDocuments-2007-11-13/docbook.n3
<timbl_> http://www.w3.org/2001/tag/doc/nsDocuments-2007-11-13/docbook.n3
<ht_vancouver> java -Dpellet.configuration=file:$pd\\pellet.properties -jar $pd\\lib\\pellet.jar "$@"
<timbl_> Tag findings += "CLASSPATHs considered harmfull"
Some discussion of what the model described by the nsDocument finding is. Nature keys and purposes.
TimBL reviews some of the RDF fragments in the Tabulator
Scibe fails to keep up
Henry attempts to describe the semantics of:
<http://docbook.org/ns/docbook>
purpose: validation [a nature:Object;
nature: key "http://relaxng.org/ns/structure/1.0";
... target <http://docbook.org/xml/5.0b1/rng/docbook.rng> ];
There seems no longer to be consensus that this is a good model.
<scribe> ACTION: Henry S. to find the counter example that made it necesseary to make a terniary relationship [recorded in http://www.w3.org/2008/02/27-tagmem-irc]
<trackbot-ng> Created ACTION-114 - S. to find the counter example that made it necesseary to make a terniary relationship [on Henry S. Thompson - due 2008-03-06].
<Zakim> timbl_, you wanted to agree it is wirth putting in the pattern of inventing new attributes or stye say and imoplement it in jscript in the early stages or for old browsers.
Stuart: One of the issues that led to this being a key rather than a class relation is that because the values varied so widely.
Agreed. But not the issue
Stuart: It still bugs me that the purpose arrow is the direction that it is.
Henry: Yes, and I tried to fix that.
Beginning of section 7.
Stuart: RDDL is a directory with entries in it. The nature and purpose are on the entry. Those entries are quads, with namespace, nature, purpose, and resource.
TimBL attempts to answer the question
Noah asserts that the answer was to a different question
<timbl_> 't match the picture
Noah: This goes way back, the reason we chose this structure was because the same target might be viewed with two natures.
... At least as a thought experiment, does it sit any better if we call it nature:treatAs
... I'm not trying to tell you want it is, I'm telling you you may treat it as if it was a specific thing. If you view it hthrough this prism, you will be happy.
<Zakim> DanC_lap, you wanted to ask ht to estimate cost of flipping purpose arrow
DanC: What's the cost of changing it?
Henry: High. First, it breaks the appearance of coherence with RDDL; second, it requires redoing the ontology.
<Zakim> timbl_, you wanted to worry that the N3 deosn
TimBL: The fact that purpose is class isn't clear from the diagram.
Some discussion of whether or not this helps Stuart.
TimBL: Can we agree that we'll remove the label 'purpose'?
General agreement.
<Zakim> Stuart, you wanted to disagree that flipping the arrow 'breaks' coherence with the RDDL 1.0 model.
Stuart: Henry said "it would break coherence". I disagree. You examine the RDDL 1.0 document and I think you'll find that subject of a purpose is not a namespace.
We look at 3.2 of the RDDL spec.
Henry: Yes, I agree that sentence supports your position; but the fact that it's materialized as an xlink:arcrole supports my position.
Considering:
<rddl:resource xlink:type="simple"
xlink: title="DTD for validation"
... arcrole="http://www.rddl.org/purposes#validation"
... role="http://www.isi.edu/in-notes/iana/assignments/media-types/application/xml-dtd"
... href="rddl-xhtml.dtd"
>
<h3> 7.4 Document Type Definition</h3>
<p> A DTD <a href="http://www.rddl.org/rddl-xhtml.dtd">rddl-xhtml.dtd</a> for RDDL, defined as an extension of XHTML Basic 1.0
using Modularization for XHTML</p>
</rddl:resource>
Stuart: That is the directory entry; it has an ancillary resource, and it has a nature and a purpose.
<Zakim> noah, you wanted to say I think the purpose is of the target
Noah: 3.2 says "related resources may have a purpose"
... it does not say directory entries have a purpose.
... it could be that related resources have a purpose, not directory
... or it could be that both have purpose and we're talking about different ones
... and it could be that the wording is just sloppy
... It runs backwards, but the pair that is involved is the correct pair.
TimBL discusses the task of working out what the attributes mean
<DanC_lap> TimBL: ... and so actually the arcrole (purposes#validation) plays the part of predicate ...
TimBL: We could ask the RDDL spec authors to clarify the thing that purpose applies to.
Stuart: What is the subject of that arc?
<Zakim> DanC_lap, you wanted to do a silent auction thingy
Stuart: I would assert that it's the entry.
DanC: Straw poll: ship it!
two "yes" but not from the editor
<Zakim> ht, you wanted to discuss what the subject was originally
<DanC_lap> PROPOSED: to address editorial comments, e.g. purpose label, skw's comments on rddl informal ontology capturing
Henry: I don't believe that any change to the topology of the ontology is necessary. But I'd be willing to take an editorial pass to improve the description of the way the RDDL is encoded.
<DanC_lap> PROPOSED: to address editorial comments, e.g. purpose label, skw's comments on rddl informal ontology capturing, and publish as a TAG finding
Henry: I'm in favor of that
TimBL: Yep.
noah, Norm: Yep.
DanC: Any objections?
jar, Raman abstain.
RESOLVED to do as proposed.
Noah: One interpretation of this is that Henry will do it and we'll review it again, another is that Henry will just ship it.
DanC: If it's good enough for Henry, Stuart, and Norm, then it's good enough for the reest of the TAG.
<ht_vancouver> ACTION: Henry S. to improve the presentation of the way the ontology reconstructs RDDL 'purpose', and to attempt to address skw's concern about the subject of the so-called purpose relation [recorded in http://www.w3.org/2008/02/27-tagmem-irc]
<trackbot-ng> Created ACTION-115 - S. to improve the presentation of the way the ontology reconstructs RDDL 'purpose', and to attempt to address skw's concern about the subject of the so-called purpose relation [on Henry S. Thompson - due 2008-03-06].
ADJOURNED.
{kind=link}