- Present
- Tim_Berners-Lee, Dan_Connolly, Roy_Fielding, Noah_Mendeloshn, Vincent_Quint, Ed_Rice, Henry_Thompson, Norm_Walsh, Dave_Orchard_(as_indicated_by_phone)
- Regrets
- (none)
- Chair
- Vincent Quint
- Scribe
- timbl, noah, ht, DanC, Roy, Ed, Henry, Norm

See also: IRC log 14 Jun, 15 Jun, 16 Jun
<DanC_mtg> +Norm
<DanC_mtg> Norm has arrived in Stata601
<DanC_mtg> ndw offers for Tue am
<DanC_mtg> ER for Wed PM
<scribe> scribe: timbl
Ed: Wed pm
HT: Thu am
RF: Thu pm
NM: Tue pm
Norm and Henry will duck out for a 10 minutes at 11:00 ET tomorrow.
Switch: Now we have Ed Wed am, Norm Wed pm
The minute takers should take responsibility for the end product.
Changes to scribing: Noah offers to do Tim's work, starting now
<noah> scribe: noah
<scribe> scribenick: noah
<timbl> Dan this afternoon
Date: 14 June 2005
<DanC_mtg> 31 May minutes
RESOLUTION: approve minutes of 31 May minutes at http://www.w3.org/2005/05/31-tagmem-minutes.html
VQ: Should we have another telcon on 21 June?
<timbl> Regrets for 21st.
TBL: Regrets for 21st
NM: Regrets for 21st, at W3C Schema futures meeting.
VQ: for now, the meeting is on
RESOLUTION: Vincent will chair on June 21; regrets DC, TBL, NM.
<DanC_mtg> "DC: Acked to discuss 1) RDDL, the XQuery namespaces, Schema Component Designators and abstractComponentRefs-37/WSDL"
<DanC_mtg> -- http://www.w3.org/2005/05/10-tagmem-minutes.html#item04
<timbl> When do we expect Dave to call in?
VQ: Our main goal for this meeting is to figure
out our goals and strategies leading to, say, 2006
.... propose to discuss tag directions every morning at this meeting?
DC: is all morning too much time?
NM: Rest of our time is flexible, can we just adapt.
TBL: Dave should be there, especially for discussing web services arch?
HT: Should spend at least this morning, and should do round robin.
VQ: OK, for today we'll do it all morning, then
see where we stand.
.... Is 8:30 OK for Wed & Thurs?
TBL: may not make 8:30, but start without me
NM: Suggest we start 8:30 and do issues of minor interest until Tim shows at 9.
VQ: As to rest of agenda, I've listed some other issues and findings to be considered. Got these by reviewing prev telcon minutes. I missed the one Dan wanted to raise.
<DanC_mtg> XSL/XML Query functions and operators namespace document Norman Walsh (Tuesday, 5 April)
<Norm> QT F&O Namespace document: http://www.w3.org/2005/04/xpath-functions/
DC: My concerns cross several of these. I want to review the namespace document for the XQuery stuff (http://www.w3.org/2005/04/xpath-functions/). That relates to namespaceDocument-8, abstractComponentRefs-37, and possibly some others. This is not a new issue, but relates to several existing.
HT: I would like to talk more about security issues later.
NM: Note that I sent a draft on schemeProtocols-49. See http://lists.w3.org/Archives/Public/www-tag/2005Jun/0024.html and http://lists..w3.org/Archives/Public/www-tag/2005Jun/0025.html . Read it before our discussions of that issue if you have a chance.
VQ: Current schedule is for 20-22 September in Edinburgh, Scotland
HT: We may be invited to dinner Tues night,
please let me know if any spouses are likely to attend.
.... OK, I'll assume 9 +/- 2. That uncertainty is no problem.
.... Bed crunch shouldn't be too bad then, as festival has ended.
<scribe> ACTION: Henry Thompson to send F2F logistics to Vincent for meeting page [recorded in http://www.w3.org/2005/06/14-tagmem-irc#T18-22-46]
VQ: there is an AC meeting in Montreal
.... Tech plenary will be in late Feb, early March, probably on riviera.
<ht> will do
NM: What if we do tech plenary to meet other groups, and then split difference to do late fall?
HT: Right, which puts us at the AC meeting in Montreal late November.
VQ: Dates of AC are Nov. 29 - Dec. 1 in
Montreal
.... Who will go in Montreal. Many positive responses. Dave O. says he cannot
travel that entire week.
HT: What about week before. Uh... US Thanksgiving.
DO: Proceed without me. I'll be in Edinburgh.
HT: What about Mon Tues week after XML 2005.
NW and HT: Doesn't work.
TBL: more travel this fall is tough.
<dorchard> Could do nov 29, Dec 2 TAG meeting.
NM: Tim, is there any way to line this up with the AC meeting for you?
HT: Uh...won't there be a team meeting Friday after the AC?
TBL: Actually, somewhat unclear.
Various: What about 5th and 6th December?
TBL: Where?
HT: Kansas City?
<DanC_mtg> considering 5-6 Dec... Montreal ... or Cambridge...
Various: What about Cambridge?
DO: What about straddling AC?
NW: Rather not.
VQ: What about 5&6 here?
<DanC_mtg> (yes, there's a w3c team day Fri 2 Dec. 99%odds. planning in the works)
VQ: Dave O., can you make that?
DO: scribe perceives a mumble from Dave that sounds like a yes..
RESOLUTION: We will have a TAG meeting for 2 days in Cambridge hosted by W3C 5-6 December 2005
RESOLUTION: We will have a TAG meeting in conjunction with the Feb/March 2006 Tech. Plenary in France, exact dates TBD.
VQ: I have to decide my summer vacation dates.
.... Propose not to be involved first 3 weeks of August.
We spend some time proving that for every week over the summer, at least one person is missing.
As VQ erases vacation calendar from the whiteboard, VQ requests that TAG members send email copies to him
Tim and Noah, as well as others, will miss some in July.
Proposal: we will have calls through 19th of July, then take a break with next call being 23rd of August.
From the agenda: "Should we revise the way we maintain the issues list and pending actions?"
VQ: Should I be doing more about document
management?
.... Norm is tracking errata?
NW: Right, but a bit behind. Will find time to do an errata doc soon.
VQ: OK, action is continuing.
.... We also have the public list public-webarch-comments@w3.org Mail
Archives
.... are we monitoring sufficiently?
DC & NW: yes, we are.
VQ: We also have the findings list. Noah has sent a new draft..
<Norm> NM's new finding: http://lists..w3.org/Archives/Public/www-tag/2005Jun/att-0024/schemeProtocols.html
Actually, the stable link should be: http://www.w3.org/2001/tag/doc/SchemeProtocols.html
I just fixed it. Was broken over the weekend due to messing up the checkin of png's.
Some discussion of whether to put drafts on the findings list or only approved.
DC: OK either way as long as it's clear, but I don't need unapproved there.
VQ: I'll keep them straight.
<scribe> ACTION: Vincent to add draft finding on schemeProtocols-49 to findings page (link is http://www.w3.org/2001/tag/doc/SchemeProtocols.html) [recorded in http://www.w3.org/2005/06/14-tagmem-irc#T18-22-46]
VQ: any more logistics
??: any more discussion where to put minutes?
HT: I'll let it go?
NM: I recall that there was a strong push that something stable be linkable by the time the next agenda goes out. So, we're deciding that anything stable is OK?
Various: right.
TBL: Well, uh stuff in email attachments isn't easily fixed,
Various: right, and that takes us into the discussion that we're not reopening, so we won't.
VQ: we've had various inputs from various
people on this
.... one question is, what do we plan to produce as documents?
.... that said, I propose we first discuss long term directions, then the
right documents to produce
.... First document was Noah's
NM: No, actually first was from Tim: http://lists.w3.org/Archives/Public/www-tag/2005Apr/0054.html
TBL: My feelings unchanged since writing the
note.
.... WebArch doc seems to have been effective. The form worked well.
.... let us discuss both the core findings and the rationale behind them
.... therefore, prefer to grow the scope, while working in the same general
framework and style
.... semantic web and web services seem to be the two major scopes to
consider
.... could look for other high priority issues as well, but mainly looking
for high priority ones. Probably things like httpRange-14 are best seen in
the context of the larger architectural issues.
.... somewhat tricky...in the first phase we claimed to have topic experts in
the room, that may be less true as we move into semantic web and web
services. In those cases we serve more as journalists.
.... there has been a lot of formal work done on sem web, but could be better
integrated and tied into Web arch itself.
.... on web services, the last effort at architecture, didn't gel. Some
concern that the folks who drive web services haven't put in place enough
clean architecture for us to help crystalize.
<timbl> TBL: If we were to work on WS arch, we would not be documenting retrospectively but doing design work, it seems.
<timbl> TBL: ... And it isn't design work which we should be doing.
HT: We started on web arch 10 years after the
web, sem web would be 5 years, arguably on web services it isn't; there yet.
.... we do better when there is an established body of practice. The current
experts don't always give you clean answers.
ER: But in my experience, that's exactly where we could make a contribution.
TBL: doesn't ws-i do that?
ER: does architecture follow?
DC: W3C looks better looking back.
.... we don't want to be saying "stop, or I'll say stop again"
TBL: sometimes W3C needs to do design, but not
TAG
.... TAG designs mainly at the level of doing glue to cover things that don't
line up
NM: I think our main responsibility to Sem Web and Web services should be to (a) make sure they use the core mechanisms of the Web itself appropriately and (b) in doing that, see whether they teach us more about what we need to document about the Web architecture itself.
DO: Web Services does indeed deviate from core
web architecture more than Sem Web. For example, the first versions of SOAP
didn't do HTTP Get.
.... Clearly Web Services doesn't use the RESTful mechanisms of uniform
interfaces.
.... now with WSA we see lack of use of Web Arch primarily for creating
asynchronous stateful services.
.... service will have stateful instance, and you'll want to have async
interactions with that. Client doesn't know much about state, except for need
to echo things.
.... there is very little reuse of REST
.... note that cookies are widely used on the web for stateful things. We can
learn some messages from those.
.... we've not necessarily made it easy. SOAP Response hasn't been well
adopted. Maybe if the web were more friendly to stateful interaction, WS
would have an easier time leveraging the Web.
DC: Henry asks "who are our customers"?
.... history is, we were started to answer questions about whether W3C
workgroups were or were not using Web Architecture well.
.... what we wrote is what everyone in every WG ought to know.
.... I'm not convinced we can impact the web master community.
<Zakim> timbl, you wanted to agree that Web Services are fundamentally different architecture - a remote operations architecture, not an information space architecture. These are distinct
TBL: agree with David, Web Architecture is
different architecture from REST.
.... our scope is what happens in W3C. Originally was information space, but
now there's more overlap, e.g. between web and email than there was
before.
<Zakim> noah, you wanted to say that we may need to be a bit more careful about the layering of our use of the term Web. Is the Web really only REST, or is REST just the most widely
TBL: I therefore think it's reasonable to consider WS arch if we want to because w3c does that
<scribe> scribe: ht
NM: Return to the note I wrote:
<Norm> http://lists.w3.org/Archives/Public/www-tag/2005Jun/att-0001/Priorities2005.html
NM: Remember the W3C slogan "Lead the Web to
its full potential"?
.... WebArch1 covered much of the foundations of that, the Web as it was say
5 years ago when most of the foundations were new and cool
.... Going forward we should be looking at what the web needs to achieve
continue to achieve its potential.
.... Even wrt the information space, we can see that at the moment
that new
requirements may be emerging (e.g. rise of P2P).
.... Some time ago at the tech plenary, I tried to make the case that we
would do well to think of the web in terms of layers. So, if we move beyond
HTTP to p2p, for example, then we can expect the URI layer of the web to be
used,
(the scribe takes the liberty of mentioning that the following list of layers comes from http://www.w3.org/2003/Talks/techplen-ws/w3cplenaryhowmanywebs2.htm, even though that URI wasn't mentioned until later in our discussions.)
NM: -------------------
.... 1) Names of things
.... 2) Schemes that are deployed that you can use with names (all of them)
.... 3) RESTful schemes
.... 4) Widely deployed media types
.... -------------------
.... So saying "the Web is (only) REST" is to take a significant and
potentially limiting step. Indeed, AWWW comes close to making such a leap in
talking without qualification about the exchange of representations, which is
pretty closely tied to HTTP and REST.
.... We can use the word 'Web' for a particular level of that layering, but
that has consequences: we need to get agreement on terminology for the
various layers.
.... Over time, do we really want to limit the Web's information space to
that which is best exposed in a "RESTful" manner or can we bring more of e.g.
Web Services into the information space
<Zakim> ht, you wanted to ask where "The W W W" starts and ends
<noah> scribe: noah
HT: people are confused about distinction
between Internet and Web,who invented which, etc.
.... the stuff we call the Web is what is layered on one of the protocols in
particular, I.e. HTTP
<DanC_mtg> (hmm... this lecture Henry is talking about is interesting... IEEE, IETF, W3C / ethernet, Internet, Web ... I'm very interested in how people learn about these technologies)
HT: in private discussion, Noah tried to
convince me that Web was bigger and embraced everything that could be linked
through URIs
.... reading the Arch document, doesn't tell you where not to go.
.... how should I know when I'm not on the Web and whether I think the Web
Arch doc should apply?
TBL: we found the question am I on the Web not
helpful. We did find: "is this document helpful?" to be a more useful
question.
.... I thought Noah was splitting hairs, but then I understood his peer to
peer example.
NM: I'm actually trying to draw parallel between things like P2P and Sem web. Both of them get great value from being integrated into what we know as traditional web. Each stretches the web in new directions. Sem web because it names things not connected to computers, P2P because it deals in new types of content and security.
TBL: Anyone claiming web is HTTP-only?
Noah: I thought maybe Henry.
HT: Statefulness is important. Security is important. In particular, having your identity established makes a big difference.
<timbl> Noah, http://www.w3.org/DesignIssues/diagrams/URI-space.png
<Roy> The Web has never been HTTP-only (started with FTP and Gopher, added HTTP and WAIS, ...)
HT: for example, I get something different from W3C retrievals than you do, because I'm served by the European server.
DC: why is that a problem, it's the same resource?
HT: True in principle, but in practice the system breaks; the mirroring is imperfect, and so the experience is effectively dependent on the Web's notion of one's identity.
NM: I think Henry's point is that many things in practice depend on the system knowing who you are and where you are
HT: Google, in particular, tailors results
based on partition of IP space. Cookies are another example.
.... Most commercial sites give you a very different experience according to
your cookies, and thus in a sense identities.
.... I tried to convince Google that Web would sort of survive if something
like Google disappeared. They felt it was "constitutive" of what the web
is.
<dorchard> +1 to HT's point that Google is part of the architecture from the user experience
HT: note that which URI you get redirected to from google.com depends on (your IP address? something not covered in Web Arch)
<DanC_mtg> (hmm... I could replay the whole "commonname" discussion in the TAG context, I guess, re one of HT's points about search engines)
HT: partially connected and disconnected are also important. What about push (see RIM Blackberry)
<DanC_mtg> (what does RIM do different? gee... I don't even know)
ER: are you also going toward mobile web?
HT: yes, that too.
<Zakim> DanC_mtg, you wanted to offer to project and edit an outline and to realize that the long tirade I occasionally give on how broken authentication in the web is might be relevant
DC: I had offered to edit outline, looks like
won't happen before lunch.
.... I have a document from long ago about web forms and having
authentication and a logout button using MD5. They said the would do it in
next version. Hasn't happened.
.... there are limits on who can deploy authenticated services because of
limits on number of passwords users will maintain.
.... as alternative, small sites are using clear text passwords, sometimes
with HTTP due to inability to afford compute power for doing HTTPS.
.... I think digest authentication is much better than clear text pwds.
.... Nobody can deploy new security technology.
TBL: Do browsers do it?
<Zakim> dorchard, you wanted to mention Web service "info space type" things not on the web
DO: we've drifted away from Web Services. Liked what Noah said about relationship to parallel architectures like P2P, Gnutella, BitTorrent. Some very significant architectures are being deployed that don't use Web technology. Maybe XRI as well.
<DanC_mtg> User Agent Authentication Forms Submission. Lawrence and Leach 1999
<DanC_mtg> User Agent Authentication Forms Feb 1999
DO: On Web Services side, consider WS Resource
Framework. Describes generic operations, you can get, put, etc. content of
these resources. They use WS-Notification to allow publish/subscribe for
state changes.
.... these are note computational, they are information resources. But even
in these constrained cases, they still don't use HTTP protocol fully. Don't
use HTTP GET. Still do SOAP messages over HTTP post. Want to be able to use
WSA End Point References.
.... I did a proposal at their first meeting to show how to offer these on
the web. Why not use a binding that binds down to HTTP Get? They said: good
ideas, but we're (Oasis-based team) aren't the ones to do it.
<ht> HST is intrigued by the apparent difference between tunneling and transfer. . .
DO: XMLP could do it, but that workgroup seems to be going into maintenance mode.
<DanC_mtg> describing HTTP in WSDL is kind of a cool idea, but nobody seems to be interested to do much with it.
<Zakim> noah, you wanted to say we are oversimplifying security story
<dorchard> when is the break?
<DanC_mtg> (quite, Noah, SSL is shared-key authentication, and public-key is the way to go for signature-workflow stuff)
<Zakim> DanC_mtg, you wanted to ask when lunch is
<ht> HST agrees that state and side-effect are worthy of further discussion, for sure
<Vincent> Lunch break
<Vincent> We reconvene at 1:00 pm Eastern time
NM: Tried (and largely failed) to convince Tim and others that one difference about Web Services is that more interactions are secured, and that more have state-changing effects at the resource owner. Therefore, Noah claims, the particular value that comes from GET in the web architecture is somewhat less significant. Whatever the other pros and cons of Web Services arch, it seems better targeted to these application-to-application secure scenarios.
VQ: Breaking for lunch.
VQ: let's go around and get some input from each on priorities...
ER: webarch doc is incomplete without semantic web and web services. let's spend some time on that. And let's solve httpRange-14 this week
DC: the "languages and namespaces" bullet from HT's msg seems important to me; namespaceDocument-8 and such. none of the higher level goals seems all that attractive
TimBL: ... semantic web and web services ... [missed?]
NDW: looking at the issues list, I saw 5ish that are related to URIs. Nailing that cluster seems worthwhile
RF: no particular issues to "grind"... would
like to see more "how the semantic web affects Web architecture". Would like
to see more about what Web services efforts aim to achieve. [?]
... would not want to tell them what to do, though.
NM: (1) to see that the information space continues to grow and thrive
<dorchard> rejoining...
+Stata601
<ht> dave, can you hear us?
scribe: [missed 2 and 3?]
... want to be sure there's an architecture that all the parts share
(timbl seems to be composing a table on the whiteboard)
HT: the issues of state, side-effect, and
context seem important.
... and that connects to user identity/authentication
... httpRange-14 ... I still can't see how that's orthogonal to secondary
resources.
... languages and namespaces, as DanC mentioned
... I think we owe the XML community a look at "the entity problem"
... should there be a way of doing what entities do? i.e. refer to large
complicated things with small simple names?
DO: I'd like to see the web figure out how to
give more things URIs...
... if that means dealing with stateful services, then very well...
... if that stretches "REST", then very well
... let's continue to pay attention to architecture properties, e.g.
statefulness, [missed?]
... and extensibility and versioning
VQ: not sure we need to define the architecture
of web services...
... more interested in extending/specializing the present web archtiecture in
a way that's useful for web services and semantic web...
... it's important to take into account new user interaction mechanisms
[?]... peer-to-peer, streaming... integrate those with web architecture
(I think I have a copy of the list timbl put on the whiteboard in an outliner; can send XHTML version on request)
(timbl's list has grown some arrows; no longer fits in a hierarchical outline. imagine that ;-)
(hmm... if WG members are our customers, I wonder about a WBS "what do you want the TAG to do?" survey, seeded by something like this list)
VQ: so we have a long list now... of course we
need to narrow it down...
... keep in mind that our most visible products are REC-track documents
<noah> A rather messy export of my slides on Web layering seems to be at: http://www.w3.org/2003/Talks/techplen-ws/w3cplenaryhowmanywebs2.htm
<noah> Will look for cleaner formats.
<timbl> http://www.w3.org/DesignIssues/diagrams/URI-space.png
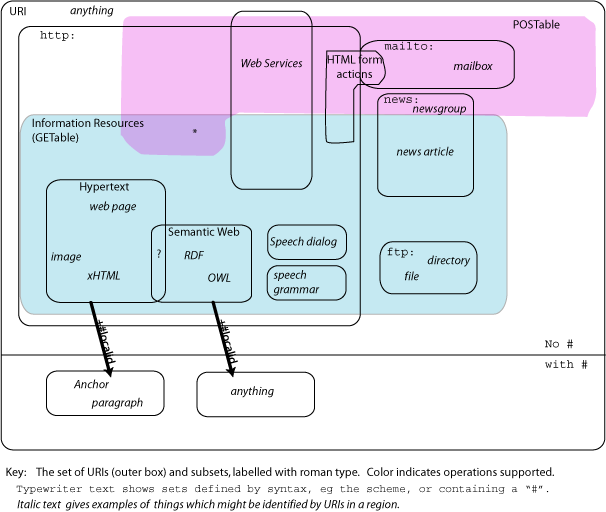
HT: re URI-space.png , I'm surprised to see the whole semantic web inside [which?]
(HT and TBL discuss httpRange-14 a bit in the context of URI-space.png )
NM: ... that's one of the reasons we should[?] talk about resources that have URIs but no GET/PUT/POST ...
DC: I'd like to remove "XML entities"
HT: then who?
NDW: XML Core
DC: +1
... how does this go beyond XML spec into web architecture?
HT: let me think about that a bit
<Norm> Dan's list has "~5 issues NDW found", for the record, I was thinking of IRIEverywhere-27, metadataInURI-31, abstractComponentRefs-37, rdfURIMeaning-39, URIGoodPractice-40, DerivedResources-43, endPointRefs-47, and URNsAndRegistries-50
NM: Ajax changes what a web page is, especially
if you do it wrong; google seems to be pretty careful...
... this "mint me a URI for the current state" design seems good...
TimBL: note IE allowed javascript to change the address bar; security issue
NM: something goes bad when content goes into executable "run the program and see what it produces" formats rather than declarative
DC: quite; the Principle of Least Power is important and underdocumented
VQ: note new work starting in Web Applications... how do we relate?
TBL: where there's a WG on something, let's let
them do it...
... but let's be sure they know about the Principle of Least Power
NM: (1) within W3C, yes, the TAG can help the Web Apps work stay declarative etc, but (2) there's stuff going on outside W3C
<ht> http://www.w3.org/DesignIssues/Principles.html for Principle of Least Power
HT: how about putting web services and semantic web under URIs? i.e. perhaps TAG's job is to say how URIs relate to those two
(DC tries it in the outliner)
DO: [missed the gist of it]
NM: misunderstandings between this group and
web services practitioners are perhaps not clarified by sticking web services
under URIs...
... one argument I've heard against using URIs is that network effects don't
apply; nobody else needs to refer to this thing, for similar reasons that we
don't routinely use URIs for "that 3rd http header field"
<dorchard> DO: much of Web and Web service development is around stateful resources that have a secondary resource identifier, which can be identified by just URIs+ frag-ids, but are also often identified by cookies or WS-A EPRs.
DO: one of the arguments I've heard for WS-Addressing endpoint references is that it works like cookies: "echo this back to me so that I can dispatch on it"
<timbl> URIpath?
DO: and dispatching based on qnames in XML trees is easier than dispatching on URIs . [?]
<timbl> DO: I wonder whether we need that URI query langauge for getting stuff out of a URI.
(in what way is it OK that they're not counting on reuse, timbl?)
DC: the cases where you don't design for reuse is generally not the Web, though, is it?
TimBL: right; this isn't the web. This is Web Services, an alternative architecture.
(scribe hears lots of endpointRefs-NN discussion, but doesn't have the energy to capture much of it until/unless it's more clearly in order)
DC: put Security 1st? we'd become very popular and unpopular... and it's at least as much QA as architecture; in many cases, the specs are there but not (well) implemented
NDW: let's not. that'll take all the energy we've got and then some
ER: [forgot/missed?]
HT: it should be in [that diagram?] but it's not. why not? [?]
TBL: ... passwords in the clear ...
HT: Rigo was quite clear that browsers don't do XML signature; if they did, the world would be a better place
TBL: with webarch v1, we didn't say "here's the web architecture; it's complete." we just elaborated on some places where mistakes had been made often, and where issues had come up a lot. and it was worth doing.
<Zakim> DanC_mtg, you wanted to note the value of diagrams
<Zakim> ht, you wanted to ask if we're confident that security will layer cleanly everywhere
HT: "if the web worked well, layering security on top would be straightforward; here are the top 6 [say] reasons why it isn't."
ER: I know lots of people that use the web *less* today because of the security issues that have come up
TBL: we haven't talked much about the impact on security of the difference between safe documents and unsafe docs, i.e. programs
HT: ... on how XSLT is turing-complete/unsafe...
<Norm> I think Henry's point was the ability of XSLT to write to local disk, not its turing completness
<ht> HST persists in believing there's a signficant difference between Denial of Service (which follows from Turing completeness) and other forms of attack with concrete/permanent consequences (e.g. writing to local disk)
TBL: dynamic HTML should have been a separate MIME type. The MIME type registration for HTML should have said "don't execute anything that looks likes a program in here"
<Zakim> DanC_mtg, you wanted to ask how whether anybody thinks they can get timbl to *not* talk about security all the time in TAG meetings 1/2 ;-)
On the assumption that httpRange-14 is done before we begin new TAG directions, httpRange-14 is removed from this list.
(I'm willing to act hopeful)
<Roy> Do we need to talk about XCAP? http://www.ietf.org/internet-drafts/draft-ietf-simple-xcap-07.txt
<ht> HST has recently started browsing apache logs, and was surprised at just how many of the entries are of the form "GET /scripts/..%c0%2f../winnt/sy
<ht> stem32/cmd.exe?/c+dir HTTP/1.0"
<Roy> rootkits for windows (looking for known IIS holes)
TBL: on versioning/extensibility, I want to make sure we get Semantic Web [part of it?] done 1st
<timbl> NM: Lots of people are up to thir necks in XML, and now need to solve the versionaing problems very desparately
<timbl> Tim: RDF has solved a set of those problems -- not all. But understanding them is important befroe we try to talk about veriosning in general.
HT: based on your suggestion, Dan, I looked up the OWL versioning support; it's very limited.
DanC: no, I mean just RDF itself solves a lot of versioning problems
<dorchard> http://www.pacificspirit.com/Authoring/Compatibility/OWLRDFExtensibility.html
<ht> Roy: That looks like yet another entry in the list which includes RFC3622 and geoprivacy and . . . -- see http://lists.w3.org/Archives/Public/www-tag/2005Mar/0081.html wrt URNsAndRegistries-50
<Roy> http://www.rtsp.org/2004/drafts/draft06/draft-ietf-mmusic-rfc2326bis-06.txt
DanC: there are these .torrent files, no bittorrent clients don't use a new URI scheme. it's a huge QA issues that it's impractical to deploy new URI schemes.
NM: right... so is it a feature that deploying new URI schemes is hard? after all, we said you should think twice before making new ones
cf schemeProtocols-49
HT: ah... this RTSP thing draft-ietf-mmusic-rfc2326bis-06.txt is interesting
RF: though it's sort of a variant of HTTP
<Roy> http://www.bittorrent.com/protocol.html
<Norm> The URI for F&O namespace document: http://www.w3.org/2005/04/xpath-functions/
the www-tag discussion started with http://lists.w3.org/Archives/Public/www-tag/2005Apr/0028.html
http://www.w3.org/2005/04/xpath-functions/#matches
http://www.w3.org/2005/04/xpath-functions/#string
DC: if we do an HTTP GET, we get text/html ,
and if we look in that spec, we'll discover that this is an anchor
... but if we look in the XQuery spec, it says that's a function.
NDW: yes.
DC: both?
NDW: yes.
<Ed> Tim: 1: THis is an achor 2: This is a Function 3: It's a function but the system gave you an anchor cos you are a person 4: Oops
<timbl> http://cgi.w3.org/cgi-bin/headers?auth=on&url=http://www.w3.org/2005/04/xpath-functions/
<ht> HST thinks pushing on the question of RDDL semantics is a useful way to go
NM: maybe this document should use a different media type... say for RDDL... so that the anchors work out. If we just use a different media type, which doesn't have much subtyping, we lose the fact that it's HTML, and some browsers don't know they can render it, etc.
<Ed> 1: this is an HTML page 2: This is a book 3: This is a book but the system gave you an HTML page because you are a browser 4 oops....
<timbl> http://www.w3.org/2001/XMLSchema.html
esp
<timbl> _____________
<rddl:resource id="xmlschema" xlink:title="XML Schema schema document" xlink:role="http://www.w3.org/2001/XMLSchema" xlink:arcrole="http://www.rddl.org/purposes#schema-validation" xlink:href="XMLSchema.xsd"> <div class="resource"> <h2>XML Schema</h2> <p>An <a href="XMLSchema.xsd">XML Schema schema document</a> for XML Schema schema documents. This corresponds to <a href="http://www.w3.org/TR/2004/PER-xmlschema-1-20040318/#normative-schemaSchema">the version published in the Proposed Edited Recommendation</a> revision of XML Schema.</p> </div> </rddl:resource>
<timbl> ________________
(hmmm... shouldn't a properly configured validator client ask for and get the variant in .xsd format to begin with?)
HT asks about http://www.w3.org/2001/XMLSchema#xmlschema
or maybe http://www.w3.org/2001/XMLSchema.html#xmlschema ; I'm not sure
<Ed> TimB: 5. This is an element (which is a repr of a function)
<Ed> Henry: 2[whose representation is [this element you just retrieved]]
<Ed> Norm: The # refers to a function
<Ed> Henry: The machine gets to an acher which is an element of the rddl name space.
<noah> Quoting from RFC 3986:
The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information. The identified secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations. A fragment identifier component is indicated by the presence of a number sign ("#") character and terminated by the end of the URI.
fragment = *( pchar / "/" / "?" )The semantics of a fragment identifier are defined by the set of representations that might result from a retrieval action on the primary resource. The fragment's format and resolution is therefore dependent on the media type [RFC2046] of a potentially retrieved representation, even though such a retrieval is only performed if the URI is dereferenced. If no such representation exists, then the semantics of the fragment are considered unknown and are effectively unconstrained. Fragment identifier semantics are independent of the URI scheme and thus cannot be redefined by scheme specifications.
<Ed> Ed thinks Noah is onto something..
<Ed> ht: because of the element, delegated by the html spec
<dorchard> je suis retourner
<ht> We'll call asap
<ht> HST wonders what the text/html media type registration actually _says_
<noah>
For documents labeled as 'text/html', [RFC2854] specified that the fragment identifier designates the correspondingly named element, these were identified by either a unique id attribute or a name attribute for some elements. For documents described with the application/xhtml+xml media type, fragment identifiers share the same syntax and semantics with other XML documents, see [XMLMIME], section 5.
rfc3236
(I can't find this bit about frag interpretation in the XHTML spec)
<noah> The above is, I think, the media type registration for application/xhtml+xml. It is by the way explaining what rfc2854 has said about text/html. I'm claiming the latter says there is a precedent for anchors sometimes referring to elements.
<Ed> level
<Ed> concept -> function
following one's nose from the IANA registry, for text/html, you get to http://www.rfc-editor.org/rfc/rfc2854.txt
<Ed> Anchor [] -> [] Hypertext
<noah> Yes Dan, and that says "For documents labeled as text/html, the fragment identifier
<noah> designates the correspondingly named element;"
<Ed> element dom ('< ... id="htm">') info set
<Ed> bits = 0011001000011011001 binary stream
section 3 Fragment Identifiers of RFC2854 says "For documents labeled as text/html, the fragment identifier designates the correspondingly named element"
<Zakim> timbl, you wanted to try Roy's model as a stack
<timbl> http://www.w3.org/2005/06/13-tag123.html
<dorchard> level->Concept->Anchor->element->Bits ?
<ht> yes
<Norm> XInclude is defined as an infoset transformation; it's at level 3
I think ...xsd#type(foo) is not to short but too long; it should be ...xsd#foo
<Zakim> DanC_mtg, you wanted to ask about crossing levels... suppose I want to make RDF statements about the hypertext document, e.g. revision control stuff ala cvs blame
hmm... isn't a type one of the components in a schema? ah... I guess not. hmm.
<ht> We have type definition schema components
<ht> anything else is sloppy talk
Hmm... when I brought this namespace doc up, I pretty much expected to go down all these holes... for a little bit, I thought we actually got somewhere. Now I'm not so sure we haven't just re-played this conversation for the N-hundredth time. I'm surely no more sure about what to *do* in the case of the XQuery F&O namespace doc.
<ht> DanC, give me a simple n3 version of a statement about Tim's car, e.g. that it is Tim's car, please
<Norm> I have at least one technical question about the F&O namespace doc too that's not at all philosophical
{ :tcar :owner :tim }.
or just { tcar owner tim}
<ht> with URIs? possible?
<ht> all three of those are URIs?
yes, they're all URI references, which stand for URIs w.r.t. the relevant base
<ht> Larry Masinter, c. 1976: "A program is not its listing"
TimBL and RF just lit up in agreement about something...
scribe: something about pointing up between levels
<Ed> are we moving to a new topic?
<Norm> Hard to tell.
<ht> "Hard cases make bad law"
<Ed> I hear versioning is going to join our discussion shortly :)
<ht> yup
<Norm> lol
(hmm... we agreed to stop at 5pm earlier.)
<dorchard> How about versioning of range-14?
<Norm> Can we ignore some _known_ 14s instead?
<dorchard> how about versionable levels of 14?
somewhat tentatively PROPOSED: to address httpRange-14 by noting a few different levels... a URI can refer to a high-level thing, and "point" to something at a lower level, e.g. an anchor or an element
<timbl> s/or an element
scribe: and to say that yes, content negotiation between .html and .rdf works
<timbl> and mixed namespace stuff works.
<ht> My stab at saying this is that there are two relations we care about: identification, which relates URIs to things (was 'resources'), and 'pointing', which relates URIs to anchors
<timbl> A URI can *identify* a thing, and also "point to" an anchor.
<timbl> "points to" is the answer to "how should I represntat this to a user who has followed a hypertext link"?
<ht> HST just wants a gloss on 'anchor' -- is it fair to say that if I have (a representation of) an information resource, and its media type, I will know what the set of possible anchors is?
oops... "refer to" was a mistake; I should have said: a URI can identify a high-level thing...
NM: let's please do continue to work on examples of these
(is http://www.w3.org/2005/06/13-tag123.html already referred to? if not, it is now)
<timbl> A subset of information resources have non-trivial anchors.
<ht> ... beyond the anchor which is the whole resource
<Norm> If ...#tcar is Tim's car and ...#tcar can be an anchor (which is part of a document) and if all documents trivially have an anchor that is the whole document, then ...ncar (no hash) is Norm's car and ...ncar has a representation.
<Norm> Yes?
<Norm> But not before dinner :-)
<ht> So is it fair to say that w/o a media type, there is only one anchor per information resource
<ht> where does that leave RDF. . .
<ht> Oh bother, said Pooh
Vincent: What do we do with this list?
- it helps us do our work
-or-
- it may also be the outline of a document we need to publish.
Vincent: This is a 12 month issues list.
Ed: Should we try and reduce the list?
TB: this should be a live document, and we should review periodically.
Noah: Pick 3-5 to start with, we may need to narrow down to 2-3.
TBL: Healthy for us to have more than one thread.
Vincent: This list is a guideline for our work, we need to go through this and set priorities. Pick a few 2,3 or 4 to work on over the next few months.
Vote was taken to prioritize list... outcome was;
top items selected were ;
1) Web applications
2) Security
3) Semantic Web
http-Range-14 is assume to remain the 'urgent' priority
<DanC_lap> Ed: lots of people have javascript turned off... maybe 18% of the visitors to HP web sites
Henry: solving issues such as Javascript interop and SVG native in browsers should also be considered.
<ht> TimBL: Why do people hold their noses wrt the DOM?
<ht> HST: Trying to do a language-independent API led to bad APIs for each of the language-specific binding
TBL: W3C as a working group could help produce a lot more tests around DOM.
W3C needs to be involved in the release of browswers in order to make this work. We havent been involved in the past.
Noah: There is a real trap in not getting in touch with our customers/vendors to find out where they're trying to take this stuff.
<Roy> E4X example: http://weblog.infoworld.com/udell/2004/09/29.html
HT: seems to me that I feel like there is an opportunity to do it another way, other than fixing java script.
HT/Dan: if we could get the browser creators to sign-up for fixing the interop problem, there would be a large benefit.
Vincent: On web applications the group doesnt exist yet and even the charter doesnt exist yet.
If we can comment on the charter and make sure it address what we feel is important.
Once the group starts we can give input on the issues with the team. Helping them start without producing something signficant ourselves (work through the wg)
Vicnent: Other topics we can do in the short-term?
Dan: Should we be involved with the web apps charter?
<Roy> http://www.cairographics.org/xr_ols2003/
<scribe> ACTION: Dan to get web applications charter and share it with the TAG for review. [recorded in http://www.w3.org/2005/06/15-tagmem-minutes.html#action01]
<ht> HST finds the E4X example underwhelming -- like XQuery, but with idiosyncratic syntax
<Roy> http://www.mozilla.org/projects/xul/
<Roy> Avalon: http://winfx.msdn.microsoft.com/library/en-us/wcp_conceptual/winfx/port_tech_wcp.asp
Noah: We need to look for things that stress web architecture
<DanC_lap> I'd like to hear from Zeldman ( http://www.zeldman.com/ ) on javascript interoperability and webapps
<ht> http://javascript.weblogsinc.com/entry/1234000893027332/
Vincent: We are also looking at moving from Procedural to declarative languages
<Roy> Haystack: http://haystack.lcs.mit.edu/
TBL: Lots of people have reversable xslt processes.
<ht> Brendan Eich on "Remixable Applications": http://javascript.weblogsinc.com/entry/1234000720046078
<ht> 'Remixable applications' turns out to mean Greasemonkey
<ht> http://greasemonkey.mozdev.org/
<Roy> Adenine: http://haystack.lcs.mit.edu/papers/sow2002-adenine.pdf
<ht> NM: Flash was less of a threat because it was typically only a part of a page, google could still get you there, but that's changing
<ht> ... We're seeing pages which are 100% flash, so nothing to get ahold off -- Avalon same deal
<Roy> TRAMP: http://www.aaronsw.com/2002/tramp
<ht> dave, we'll dial in
<dorchard> thx!
<DanC_lap> the 3 that emerged as popular were: security, Web Apps, Semantic Web
<DanC_lap> others that got some votes... Side effects, user identity, state, context
<DanC_lap> ACTION: VQ to invite Dean to a TAG teleconference [recorded in http://www.w3.org/2005/06/15-tagmem-minutes.html#action02]
<DanC_lap> timezone challenges noted
<DanC_lap> DO: note the new mailing list on web description formats; seems relevant to web apps
<DanC_lap> http://lists.w3.org/Archives/Public/public-web-http-desc/
<DanC_lap> DO: these description formats are, for example, for the Amazon search service; URI encoding conventions, etc.
<DanC_lap> (I'm kinda mystified by this; I thought WSDL was supposed to do this stuff)
<DanC_lap> NDW: our webapps discussion was more about gmail, google maps... client-side dynamic stuff
<DanC_lap> DO: hmm... the more stuff that's done in turing-complete formats, the lest you can do with declarative stuff [er... something like that]
<DanC_lap> DC: exactly. [The Principle of Least Power] I think the TAG hasn't written this down the way we should
<DanC_lap> NM: have you seen all these services layered on google maps? cheap gas and all...
<ht> Mark Nottingham's intro use cases for web description (HST still not really getting what the subject matter is . . .): http://www.mnot.net/blog/2004/06/14/desc_usecases
<DanC_lap> --- break for :15, after which resume with security
<dorchard> I've collected a list of web descriptions http://www.pacificspirit.com/Authoring/REST/
<DanC_lap> we asymtotically resume, a semi-spontaneous security discussion having broken out during the break
<Roy> RFC 2617 - HTTP Authentication: Basic and Digest Access Authentication
<DanC_lap> DC: state of the art in auth is: forms + cookies.
<DanC_lap> ... the security properties are just like HTTP basic, but the UI for HTTP basic is that crappy little dialog with (a) no trademark logo, and (b) no "if you forgot your password..." stuff
<DanC_lap> DC: digest authenticaion has better security properties, but has the UI problem
<DanC_lap> ... the 1999 submission that suggested mixing digest auth with forms is still a good idea, IMO
TBL: The virus problem is software on your pc that you didnt realize you asked for.
<DanC_lap> DC: another security issue is that with basic auth, the server doesn't store the password, but only an encrypted form of it. But with md5, it has to store the password
ht: you only want as much identification as you want/need.
<DanC_lap> RF: yes, that's a bug in the MD5 spec that, 2 months into the development, the authors said there was "too much deployment to make such a change". argh!
<ht> http://www.identityblog.com/
<DanC_lap> DC: so shared-secret auth could be a lot better
<DanC_lap> DC: then there's assymetric-key symmetric key... that's deployed for SSL certs...
ht: the security problem would get better by solving the identiy issue.
Dan: lets work hard to stamp out passwords in the clear
<ht> http://www.identityblog.com/stories/2004/12/09/thelaws.html
<DanC_lap> DC: if we could just do those 2 things, that would be good: (1) avoid passwords in the clear, (2) don't use turing-complete formats unless you have to
<Roy> http://www.securityfocus.com/infocus/1688
<Roy> http://www.securityfocus.com/infocus/1691
<DanC_lap> ... lots of brainstorming, not well-recorded ...
<timbl> Public key crypto, phishing,....
discussion: Should we update the web arch or add additional books to volumne 2.
Noah: Findings is a good way to start collecting these things, we can later determine if it rises to the level to update the arch.
Dan: See www.w3.org/DesignIssues/Principles.html
<noah> First draft of minutes from yesterday morning have been posted at: http://lists.w3.org/Archives/Public/www-tag/2005Jun/0031.html
<DanC_lap> http://www.w3.org/DesignIssues/Principles.html#PLP
<Roy> I will review PLP.
<scribe> ACTION: Roy and Norm to review http://www.w3.org/DesignIssues/Principles.html#PLP [recorded in http://www.w3.org/2005/06/15-tagmem-minutes.html#action03]
<Roy> http://ai.eecs.umich.edu/cogarch2/prop/declarative-procedural.html
<scribe> ACTION: Dan to write a report on the state of the art authentication in the web. [recorded in http://www.w3.org/2005/06/15-tagmem-minutes.html#action04]
<DanC_lap> "A Report on the Sorry State of Authentication in the Web"
Dan notes this is as much a recruiting document to help solicit input from additional experts in the area.
TBL: Need to inform users and users and those
who write browsers
... suggests TAG should make suggestions, address bar and Icon changes to
denote links/security.
... some actions in Browser should not be allowed. For example, hover over
link should show the true link at the bottom of the browser and the browser
should not allow for it to be over-ridden.
Dan: The first time the software structure cam to his mind was with MP3. Real networks and Microsoft have a little battle over who's software gets to run.
Dan the two keep over-writing the registry as to who the top of the heap is.
TBL: Registry for MIME type 1
... Bug over riding DLLs use by other people.
discssion: Microsoft issues with DLL's
<DanC_lap> (does this meeting have time to explain to me how .Net purports to address "dll hell"? it has something to do with assemblies, but I don't grok as deeply as I'd like)
TBL: Auditing. Its both a symptem of auditing
the problem as well as..
... We should put on our list, the voice browser security note.
... have the javascript security policies been reviewed? eg "a script can
only open a TCP connection to the site from whence it came"
HT: its difficult to apply style sheets to java script pages.
<DanC_lap> DC: I think browsers only run XSLT stylesheets from the same site that the document came from
<DanC_lap> TBL: so the community has bought into security-by-domain
<DanC_lap> (good question, HT, what about the grid?)
TBL: If your picking up a style sheet and it wasnt constraigned and then you referred back to a local copy but when you do an actual HHTP referance to that there is a forward.
(or an alias)
<noah> Regarding TBL's question as to whether JavaScript policies have been reviewed: I just checked with Sam Ruby, who was secretary for ECMAScript standardization effort. To has knowledge, that effort was scoped to the language only: no formal standardization of DOM, security models, etc.
Some plug-ins are trusted (like PDF) where others are less trusted because they are scripting languages which are executed locally (such as flash).
<timbl> [NEWS] Macromedia Flash Plugin Can Read Local Files
<timbl> http://www.derkeiler.com/Mailing-Lists/Securiteam/2002-08/0030.html
HT: A point for discussion. The UK funding bodies are particularly concernced about the grid, the semantic web, and the web. Are there technical architectural issues around remote servies?
Vincent: We conclude our discussion on
security. There is certainly interaction between the grid, ws and the web in
general.
... We have addressed with some success authentication/passwords and
principles of least power
<noah> A question arose before about Flash data access.
<noah> From the macromedia site: http://www.macromedia.com/cfusion/knowledgebase/index.cfm?id=tn_14213
<scribe> ACTION: Dan to draft "Dont use passwords in the clear" [recorded in http://www.w3.org/2005/06/15-tagmem-minutes.html#action05]
<noah> "For security reasons, a Macromedia Flash movie playing in a web browser is not allowed to access data that resides outside the exact web domain from which the SWF originated.
<noah> As an enhancement to Macromedia Flash Player 7, domains must be identical for data to be read. With this change a sub-domain can no longer read data from a parent domain and vice versa."
<noah> While this doesn't explicitly discuss access to local files, it leads me to believe that Flash does indeed do what one would expect: I.e. to run in a different mode when a .SWF file is launched through the web vs. when run locally. This all seems quite similar to Java.
We will save Semantic web for tomorrow
After lunch we'll address 49
break for lunch resume at 1:15
<noah> BTW: Looking back at that "Flash can read local files" report, it was clearly listed as a bug.
Outline after discussion:
Noah has produced a draft finding
<noah> http://lists.w3.org/Archives/Public/www-tag/2005Jun/0024.html
<noah> http://lists.w3.org/Archives/Public/www-tag/2005Jun/0025.html
<noah> Actual draft is at http://www.w3.org/2001/tag/doc/SchemeProtocols.html
NM: Not polished even as a first draft, but
useful for determining if it's going in the right direction
.... Motivated in part by P2P and streaming. Vague sense that the kind of
content that flows over http isn't the only kind of content that might
exist..
.... So what are the right ways to go beyond or leverage http?
.... Review can be divided into two aspects: first, is there anything that's
factually wrong?
.... Second aspect: is it beginning to tell a story that the TAG wants to
tell
DO: wonders what the motivation/problem is that this finding addresses.
NM: Impression is that for example, some P2P
protocols are integrating better into the web than others.
.... For streaming, does it make sense to have lots of new protocols, or does
it make sense to get a document with a particular media type
.... We've never really clearly said, other than looking back, what are the
guidelines for creating new protocols that you might need. And what are the
other things that you might need to know that aren't in AWWW
DC: It would suit my taste better if you'd
talked about P2P or streaming
.... right up front
NM: That's meant to be in 3rd para of the preface
HT: Section 4 maybe belongs in an appendix, but
as far as the questions you are going to answer, I don't need to know this
stuff about gateways
.... How to get an FTP URI with the HTTP protocol isn't on the shortest path
to the goal
VQ: The correspondence between the two
protocols is valuable.
.... The gateway itself isn't very interesting, but the equivalence between
the operations (or sequence of operations) may introduce the issue of
inventing new protocols when others are already available
NM: One bit of advice: consider similarity to
the operations available in other protocols
.... Because http allows you to carry an HTTP URI, you can do this gateway
without having to invent a new URI
.... Another bit of advice: ok, if you're going to build a p2p protocol, you
might want to make it easy to carry other people's URIs around
DC: Do you have anything you feel is a short summary (one or two sentences)
<Zakim> DanC_lap, you wanted to point out a few comments about misleading bits, and to express a lack of motivation. a story is traditional, by now.
NM: I think the one I just mentioned might be
one
.... last paragraph before ednote in Chapter 4
DC: "Protocols designed to be ... such URI names"
NM: And in section 3
.... The second paragraph
NM/DC disagree about the practice of 404ing namespace URIs
NM: Creating a scope in a language should be a lightweight thing to do.
DC: This paragraph is terribly misleading.
NM: I'd be happy to say the "should provide
servers" part a little more strongly
.... What is there that keeps me Noah at IBM from naming my URIs with someone
else's DNS?
.... I'm writing it down here.
DC: I think that's already covered
NM: I was trying to say that you never want to preclude someone from doing the right thing which is to actually deploy
DC: It still feels like obscure cases
NM: To me it's important to say where the rules
come from.
.... It's a deep architectural question about what it means to mint URIs that
don't have servers
DC: The part about not using someone else's DNS is in the URI Ownership section of AWWW
NM: The larger way to look at this is a way of
building things from first principles
.... Then you can look at the problems: how to get P2P on the web, what to do
with streaming media
DC: Maybe it'll work better in later drafts
.... I don't have an overall sense
RF: For me it's still backwards, you don't
select URIs based on protocols or vice-versa
.... There exist resources in the universe and there are methods of accessing
them. To a certain extent, the methods cause them to be named. One way to
achieve that is to map a URI scheme, simply an identifier, to the methods
.... A client looks up a scheme name and passes it to a handler. The handler
can then do...basically anything
NM: I'm trying to nail down what guidance we give to developers about hot to do that handler
RF: If you write the document such that it reflects the way things actually occur...
Scribe lost details
RF: You have to go from the approach of the
client: what does it do with the list of scheme names? It has a default
handler, that handler is going to perform a set of procedures for doing
operations
.... And then you look at the responsibilities of the handler at this point.
What does it have to do
NM: Where is the nature of the default defined
Some discussion here about origin servers and authoritative requests
RF: It's what the server currently represents as the representation of that resource
NM: I thought the architecture said if you
really got a 200 back from the origin server, you are authorized to say that
that was a representation of that resource
.... That it was in some sense what that URI was naming
RF: No. If I give you an ID for a social security number and you use that to get RF's tax records, does that give you my tax records or a document with current information about my taxes, ...
HT: What it gives you is an authoritative representation of that resource at that time
NM: So there's no way that I could say that
that's a representation of another resource (as opposed to the real one)
.... Not all URI schemes work that way is my impression. The UUID scheme
doesn't say a lot about authoritative representations
RF: Not all schemes are grounded in
representations (or protocols)
.... When I say there's an http information space, it doesn't depend on the
version of the http protocol
<Zakim> ht, you wanted to ask about the reality of this ftp-over-http example
HT: Is this ftp-over-http example really
important
.... Stipulate that it's all true, does it have any interest in practice
.... Are there any such gateways in the universe and are they actually
used
RF/DC: oh yeah
DC: The servers come out of the box configured to be origin servers
HT: Point me to a server that does work as a proxy server
RF: It's used in almost every large corporation
as an intranet/extranet buffer
.... The reason you can't see this from the outside world is that they have
been configured *not* to look like proxy servers
DC: Almost all the APIs have variables you can set to do this
NM: Part of the reason I brought this up was
because the architecture allows it we ought to describe it
.... But really the question is, should I give an http: scheme name to
something that's actually in bittorrent
TBL: The rules are written through the
evolution of the architecture
.... When you look at whether your going to make a bittorrent scheme or
support bittorrent with http URIs, you're making some tradeoffs
NM: I didn't mean to set down rules, I meant to explore what the tradeoffs are
DC: I wouldn't talk about one protocol fitting
in another, I'd talk about accessing representations
.... You have to motivate generality, and you've only done that about
representations
DO: I wanted to comment on defaulting. That's not written down but everyone uses it. The operation you use is also defaulted. Using http: doesn't imply doing a get.
NM: I disagree with the second
HT: It's interesting to note that linkcheck does HEADS not GETs
NM: I agree with Henry. The reason GET is a
default is because browsing is the most common thing we do. But for any of
them, we could have an application with different defaults
.... If I was handed a 'qrs:' scheme, where would I get started? The scheme
should be registered at IANA. For some of those schemes, the scheme documents
would be a lot like the document for http.
RF: Each specification defines what it knows
about the universe, it doesn't define the whole universe and then itself
.... Good practice moving forward is to separate the scheme specification and
the protocols
.... The scheme specification should point to a set of protocols (e.g., http
and https). And should also describe the set of procedures that are used to
map from identifiers in that scheme space to resources available via that
protocol or set of protocols
.... The resources "just are". These are the associated set of access
mechanisms.
<DanC_lap> (not sure they "just are")
DO: The other thing that I was going to suggest was that in the Arch Document there have often been stories. It would be good to have a story here with P2P or streaming.
<DanC_lap> +1 tell us a story, uncle Noah
<Zakim> DanC_lap, you wanted to suggest 2 or 3 things: (1) if (but *not* only if) you get a 200 on port 80, you have a representation of http://... (2) the Internet community has delegated
<timbl> Social relationships involved in the relation between a URI and a representation are of quite different for for different protocols. Eg it takes technology AND social agreement to make HTTP 200 responses definitive, but the concepts of trust are very different. The protocols used to be the master thing, until the scheme had been used for naming a lot of things -- now the protocol is secondary and can be upgraded, preserving the scheme.
TBL: You can be held accountable for http:
200's because there are social relationships behind the servers and DNS, etc.
.... It's possible that within the life of the TAG, it'll be necessary to
introduce a P2P version of http
.... But that may come with caveats
.... You may need a button on your browser that says you want the definitive
version (for your home banking)
<DanC_lap> comments on SchemeProtocols.html , transcribed from my paper copy
TBL: The trust may be very different. We'll end up morphing the trust situation in a very positive way or a very negative way.
NM: The metapoint I'm trying to raise that just
perhaps the story you just told is an important story that's not well
articulated
.... What I wanted to do in heading off into this space is to tell stories
like this
Note to scribe: what RF said above about http: and https: may not have been what he meant to say
NM drifts towards httpRange-14
<Roy> I missed it
<Zakim> ht, you wanted to parallel this with the streaming media/rtps story
HT: What Roy is calling the http: information space has the defining property that it has the DNS+hierarchy naming structure. The information space that define the http information space are about an organization of a relationship between identifiers and the resources they identify. This is completely independent of the protocol.
<DanC_lap> a suggestion: the http scheme is an agreement that there's a space of information resources, where one part of the name identifies a party, usually a domain owner, who gets to say the relationship between those names and representations that correspond to them
HT: That's an interesting perspective. What I'm
concerned about is the question, "if that's true, it's very strongly at odds
with the naive users perspective which is that http is about what we call
representations"
.... retracts that statement for the moment :-)
<DanC_lap> (re noah's question, I care in the case of representation access, but the case of operations in general is too academic; please pay one story before we spend the time to answer. 1/2 ;-)
<Zakim> DanC_lap, you wanted to ask that we go thru the bittorrent case
NM: Do people believe that the operations come with the scheme or the protocoll.
DC: That's not a small question,that's an enormous question
Answer not obvious.
DC: Let's do daap: first (Digital Audio Access Protocol)
Apparently it is *exactly* the same as http 1.1.
<DanC_lap> "The Digital Audio Access Protocol, or DAAP, is used by Apple's iTunes 4.0 digital audio player to share music across a network or the Internet. It provides capability not only to stream audio from one computer to another, but also to list the host's playlists so that they can be accessed remotely." -- http://daap.sourceforge.net/
DC: They came up with a different scheme so that they could get injected into the software deployment story
The Mac dispatches on scheme name
TBL: They forked http and added a few bits
<Roy> http://daap.sourceforge.net/docs/index.html
<DanC_lap> (I was looking at http://them.ws/post/775/what_is_daap__ )
VQ: Maybe bittorrent is a better example
DC: Anyway, daap seems like a way not to do it
.... Nice story: My kid wrote a nice story, it gets insanely popular and
automatically switches to bittorent so the load on my server only goes up a
little bit
HT: I find a URI for your kids story, I click on it, the browser waits a few seconds and says, gee this sucks, aborts that, and initiates a bittorrent request
DC: bittorrent isn't the same as gnutella, it isn't entirely peer-to-peer
DO: There's one tracker per-distributed resource
DC: I'm the guy who has to publish the seed
HT: You may have to do something and then my client has to automatically try to use bittorrent
Scribe may have missed a bit
TBL: Speculative design of a fallback system: Dan's server when it hits a certain load it automatically sends back a response that tells the client to switch to bittorrent
DC: I think Henry's design is fundamentally
better because the other way I have to satisfy a TCP request from my server
.... I'd put a .torrent file on my server that would have the address of the
tracker and some starting servers.
.... The bittorrent protocol has been upgrade to be trackerless
HT: My question is what *I* do.
<Roy> http://www.bittorrent.com/protocol.html
<noah> News article on trackerless BitTorrent: http://www.betanews.com/article/BitTorrent_Creator_Opens_Online_Search/1117065427
DC: In http, the *publisher* gets to say what the right answer is. In this other world, the social conventions are totally different. It becomes the world that gets to say what the representation is
<Ed> more general... http://www.bittorrent.com/introduction.html
<timbl> http://joi.ito.com/archives/2005/05/20/bittorrent_goes_trackerless.html
DO: A lot of people don't use google, they use
bittorrent sites that do a better job of searching bittorrent files.
.... And they provide comments
<timbl> "While it is called trackerless, in practice it makes every client a lightweight tracker. A clever protocol, based on a Kademlia distributed hash table or "DHT", allows clients to efficiently store and retrieve contact information for peers in a torrent."
<timbl> Quote was from http://www.bittorrent.com/trackerless.html
HT: We're morphing this question into a P2P version of access to the HTTP information space
ER: It does, it's just a really bad idea
Some discussion of IPR, aborted
TBL: trackerless bittorrent has a distributed
hash table in it
.... If we replace http with a not-DNS hierarchy system then we'll end up
with a different social system.
.... When you use http, you trust the publisher, when you use bittorrent, you
trust the other users running bittorrent
<timbl> But you can do a checksum or sig check on the downloaded result, and use trusted parties or trusteed links (links with keys or hashes in them)
<DanC_lap> (in the case of "file on an http server gets really popular; let's switch to bittorrent" all the clients are going to have to do a round-trip to the origin server to get the md5 and some bittorrent coordinates, unless we mix in quite a bit more stuff)
NM: One question is how do you get new modes of delivery (such as P2P) for things named with http: URIs
<ht> HST is/was trying to push on the question of the possibility of giving access to the http information space using a (collection of) transport protocols which are not HTTP or anything close to it
NM: One of the things that's likely to result from that has to do with DNS names. The social understanding of what your likely to get changes in interesting ways.
<ht> DanC+HST combine to ask: can we provide the "quite a bit more stuff" in a way which preserves the social properties of the information space
<Zakim> DanC_lap, you wanted to point out that the reason for continuing to use http: names is not just that timbl wants to Rule The World, but that preserving links is valuable to society
DC: The value of the network is the web of names. Keeping the same names preserves the value of the web.
NM: I think the reasons why we want to use http names is worth writing down
<timbl> "BitTorrent is a protocol for distributing files.. It identifies content by URL and is designed to integrate seamlessly with the web. Its advantage over plain HTTP is that when multiple downloads of the same file happen concurrently, the downloaders upload to each other, making it possible for the file source to support very large numbers of downloaders with only a modest increase in its load." -- http://www.bittorrent.com/protocol.html
VQ: Noah will incorporate comments into the
draft.
.... Should we link it as a finding in progress
General agreement
<scribe> ACTION: VQ to make a link from the findings-in-progress page
<scribe> ACTION: NM to produce a new draft
DO departs
<DanC_lap> lots of discussion... HT put a
picture up with a couple URIs... 
Representations vary over time; people can make different assertions about what a representation means
With the '#', there's a whole different architecture (involving mime types)
RF: When people use URIs, they aren't
necessarily using it in an identification relationship
.... They are using it in a "more information" relationship
.... In <a href="http://www.paris.org/Monuments/Eiffel/">Eiffel
Towe</a>, the URI is not for identification, it's a pointer to
something that gives more information about the tower.
.... Indirectly, it identifies the tower
If I replaced that with an SVG image source, a human being reading the page will reach the same conclusion (that it's the depicted real tower)
<DanC_lap> the "nobody uses http uris for anything but documents" is an "at your own risk" sort of conclusion, not one that you can turn around ala "if it's not a web page, it can't have a hashless http URI"
<Roy> http://www.httpsniffer.com/http/100304.htm
<Roy> http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.4
<Roy> 303 See Other: http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.4
<DanC_lap> (in preparation for straw poll, I'm swapping in SWBPDWG's request http://lists.w3.org/Archives/Public/www-tag/2005Mar/0101.html )
By induction, the world is used to thinking http: URIs are documents, so they must be documents
By induction, the world is used to thinking that '#' in an http: URI is a pointer into the document, so they must be pointers into the document
<Ed> my head hurts.. but I think I'm taking Tim's side on this. We need to make a clear distinction.
<DanC_lap> . http://web.resource.org/cc/Reproduction
In the picture yesterday we had two levels distinguishing "identifies" and "points to" where RDF defines "identifies" but doesn't define "points to" very well and HTTP defines "points to" but doesn't define "identifies" very well
<Ed> In semantic web its important to know if your referencing a document vs an object.
<ht> http://www.httpsniffer.com/http/100303.htm
<DanC_lap> http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3
<DanC_lap> infoRes axiom, the lesser: { ?R a http:OK200; http:about ?X } => { ?X a webarch:InformationResource }.
<DanC_lap> where an HTTP GET /path to host.example is http:about <http://host.example/path>
RF: Proposal: If an http resource responds to GET (a) with a 200 OK, then it is an information resource, (b) with 303 See Other, then it could be *any* resource, and (c) with any 4xx error, then ... ?
Seems to garner a modicum of support
NDW: I could sign off on that compromise
<dorchard> what 2xx or 3xx response codes identify non-information resources?
<DanC_lap> the common architecture position: "points to" and "denotes" agree on URIs without hashes.
<timbl> http://www.w3.org/2005/06/13-tag123.html
The proposal is that 2xx identify information resources; 3xx say "see other" so they could be anything
<DanC_lap> dorchard, a 303 response doesn't give any constraints about whether the resource is an information resource or not
<DanC_lap> ... per the RF proposal
<Roy> My proposal is that we provide advice to the community that they may mint "http" URIs for any resource provided that they follow this simple rule for the sake of removing ambiguity:
<Roy> a) If an "http" resource responds to a GET request with a 2xx response, then the resource identified by that URI is an information resource;
<Roy> b) If an "http" resource responds to a GET request with a 303 (See Other) response, then the resource identified by that URI could be any resource;
<Roy> c) If an "http" resource responds to a GET request with a 4xx (error) response, then ... ?
<Roy> This proposal enables people to name arbitrary resources using the "http" namespace without any dependence on fragment vs non-fragment URIs
<DanC_lap> (Henry, I wonder what impact this should have, if any, on the XPointer registry)
<Roy> ... and reducing ambiguity appearing on the Semantic Web by folks misusing the non-information resource's URI to identify the information content returned by redirected request
<DanC_lap> (I'd prefer myTripLog#tower , rather than myTrip#tower , to be clear that the stuff before the # is a document)
<Ed> (what if its a portal and myTripLog# is a program which generates the result you get at myTripLog#tower)
<DanC_lap> (myTripLog might be supported by a program, but it's not a program. it's a document)
<noah> Httprange-14: the issue is "TBL's argument the HTTP URIs (without "#") should be understood as referring to documents, not cars."
<DanC_lap> so RESOLVED.
Unanimity
<scribe> ACTION: RF to declare victory and move on
[see above]
<scribe> ACTION: All to send vacation info to Vincent [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action01]
<scribe> ACTION: Minute takers to get minutes to Vincent by Monday 20 July [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action02]
Norm will be chair pro tem after Vincent leaves this afternoon
VQ: Extending our work to the Semantic Web. . .
Looking for steps to make progress
TBL: Trying to identify the primary hooks we're
hanging the SW on, writing them up and connecting things to existing
WebArch
... Lots of discussion of philosophy in the SW community, some tensions
particularly with the folk from the KR and logic communities, but those
tensions have been easing
... The existing documents are not easy to work with as they stand
... We can try to pull out some principles, write some stories
... Try to explain the SW in a way that hasn't been done before -- make the
connection between SW and OFW
... For newcomers from an academic perspective, for example
<DanC_lap> Primer: Getting into RDF & Semantic Web using N3
TBL: There is a standalone, non-XML, intro to the SW -- interested to get review of this from relative newcomers
<timbl> http://www.w3.org/2000/10/swap/Primer
<scribe> ACTION: HST, VQ to review the primer [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action03]
<timbl> http://www.w3.org/2000/10/swap/doc/
TBL: Would like three reviewers for the first
page, and at least one for the whole tutorial
... It's in various forms. . .
<scribe> ACTION: TBL revise http://www.w3.org/DesignIssues/HTTP-URI.html [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action04]
TBL: Most recent SW talk has become more software engineering orientated. . .
<noah> Noah notes that http://www.w3.org/DesignIssues/HTTP-URI.html comes pretty close to bearing on the questions he (Noah) asked yesterday regarding the relationship of schemes and protocols
<timbl> http://www.w3.org/2005/Talks/0517-boit-tbl/
<timbl> Talk to bio-IT conference with some software engineering pictures
<Zakim> DanC_lap, you wanted to note 2 principles of RDF that I think our audience should know about: (1) taking "use URIs" all the way (and not stopping at qnames) for reusability (2)
DanC: Frustrated at people reinventing RDF --
at least do it well
... Given any RDF document, any subset of the triples there stand on their
own
... Adding triples never hurts
NM: Can't I add a negation of a triple -- that can't be ignorable
HST: Negation requires re-ification, I
believe
... Stopping at qnames means what?
DanC: E.g. schemas, lots of things have QNames, but knowing a QName is not enough to be able to point to something unequivocably
TBL: [diagram on whiteboard] Standards-based bus -- raw RDF, GRDDL-derived RDF, RDF queries. . .
<DanC_lap> (I suppose one could refer to " that XML Schema type whose namespace name is X and whose localname is N"... I'm not sure if that approach has been exhaustively tried)
TBL: triple-stores, RDBs exposed as XML or RDF, XMLDBs, all projecting RDF on to the bus
<DanC_lap> (norm, have you heard of ,timbl? )
TBL: Apps bit on top of the bus -- browsers,
aggregators, inference engines
... Both data sources and apps may need 'adapters' to convert to/from RDF
<Zakim> ht, you wanted to project a logic story and ask for parallels
<DanC_lap> (I've been wondering if the TAG should take a 20 minute course in model theory)
<timbl> http://www.w3.org/2005/Talks/0517-boit-tbl/#[18] and floowing slides have bits of this
<DanC_lap> HT gives a 4-slide presentation on traditional definition of a logic
<DanC_lap> TBL asks if shannon:information has been connected to frege:model-theory
<DanC_lap> HT replies with a reference to Dretske, Fred I. Knowledge and the Flow of Information. as cited from http://www.press.uchicago.edu/cgi-bin/hfs.cgi/00/14537.ctl
<DanC_lap> a nearby article nominated by google is http://www.ils.unc.edu/~losee/b5/book5.html
TBL: Example of communication as reduction in uncertainty [= entropy?] by conveying information
<scribe> ACTION: HST to recommend intro to Dretske thought [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action05]
<DanC_lap> DC asks HT whether "A Discipline Independent Definition of Information" has the relevant info; HT is unable to confirm
TBL: People working with different subsets of a
patchwork of information in an unbounded set
... Each agent can take care of the local consistency of the information it
is working with
<DanC_lap> (I think the nearest point on the TAG agenda at this point of the discussion is http://www.w3.org/2001/tag/issues.html#rdfURIMeaning-39 )
TBL: Using URIs as individuals in more than one
logic
... The logics share the RDF sentential form, but some of them diverge after
that.
NM: People are making statements (in different
logics) which all use URIs
... Sentential forms are out there, in bits of Prolog, DescriptionLogic, .. .
.
... Problem is combining these
HST: Not quite -- RDF triples are independent of all those -- they are what they are
TBL: Architectural rule: To understand a
triple, take the predicate, look it up on the web, if the result is english,
then at least you know what it means
... If you find an OWL class, your computer may be able to do things
NM: Lots of triples out there, for some subset
of them, I'll be able to reason about them in a useful way, maybe because
they are all using OWL-defined predicate
... But if some are like that, and some are defined e.g. in French, combining
them isn't going to work very well
... That's a problem in practice, but not in principle. . .
... What about the prolog approach?
DC: { :timbl :carowner :xyzzy } --- look up
:carowner, find ...[scribe coulnd't keep up]
... The unit of meaning on the web is a document
NM: In practice, then, the same triples in one document may have a different impact than the same triples divided over several documents
DC: Yes
TBL: Philosophers think they've gone beyond
this, believe they exhausted the rigid meaning approach in favour of some
kind of meaning-as-use approach
... So they think the SW story is too simple and are a bit dismissive
NM: Squishy
TBL: Semantic web is going to be very un-squishy -- if you send a particular XDI message, the tags have a very firm pre-negotiated meaning
<DanC_lap> DC: rdfURIMeaning-39 is on our issues list because... when you look up :carowner, you'll find a document that says, e.g. carowner is a property, and it's a subproperty of uniform-commercial-code:owner, etc. But what if that defining document also says "and Reagan is a great president"; does use of :carowner involve assent to that statement as well? The extreme other position is: no... I can use any URI I like to mean whatever meaning I like, irrespective of what infromation its owner publishes
TBL: In RDF, all you need is the pre-negotiated
meaning about the RDF framework, you can look up the predicates
... What we need for the arch doc is an answer to the question of what you're
committing yourself to when you send someone an RDF document
... When you chase the predicate links, you eventually converge on a small
number of meta-ontologies
... Not of course the same when you chase the subject and object URIs
... So what's a best practice in this area. . .?
VQ: Useful intro/overview of the space
... What do we do next, beyond looking at the tutorial
... Should we use the tutorial as a starting point for the architecture?
<Zakim> Norm, you wanted to suggest that what we really need are the Dirk and Nadia stories
TBL: No, I think it's not directly in the architectural direction
NDW: I regularly get pushback from e.g. people in Sun as to what the value of all this is and why it's worth the overhead -- a good Dirk&Nadia story or two is really needed to address this
NM: How much of this is really within the TAG's remit. . .
DC: Let's tell stories that connect SW to issues on our issues list
NM: SW interesting because/when it connects to
the Web as a whole -- e.g. httpRange-14
... Comfort level goes way up in that case
... How do we connect the world of logic to the world of the Web
HST: Otherwise it's not obvious how SW connects to our customers, as identified as the W3C WGs
DC: ATOM isn't our WG, but they sure need this help -- they've reinvented RDF several times!
NDW: ATOM has cut most of that loose -- they also could have done much of it with RDF, but they didn't believe it was usable in practice
TBL: The perceived problems are not just practicality, but also XML RDF syntax
HST: Not our problem, c.f. XML and entities
NM: Well, if we thought it was so important
that it was going to break the web
... then it would be our remit
VQ: Agreement that we need some stories, particularly if they make the connection
DC: Tension between the SW architecture and the
XML architecture
... How to know when to solve your problems by manipulating XML with the XML
tools, vs. using the SW arch
... There's a whole XPath-based application development worldview outthere,
with hardware accelerators and so on
HST: And Norm and I want to get the XML Processing working group going, because we think processing XML as XML is good and needs a standard
DC: So that view competes seriously with the RDF architecture
TBL: And AJAX competes also
<Norm> TBL: building XML support into your programming language competes with building RDF support into your language
DC: Is XML Proc WG going to look at XDuce and things like that?
HST: No. Document level, not lower, is way to get consensus quickly, lots of existing specs/tools at that levels
TBL: Dirk has some RDF triples, Nadia adds some, doesn't get in Dirk's way
HST: I want a story about a problem solved
... It's where the people who have problems with the perceived impracticality
of RDF processing hit the buffers
NDW: Paul and Paula example, phonebook rules
<Norm> The core of the story is that I have two address book entries for Paul and Paula because they have different work phone numbers. I use RDF inference to avoid having to duplicate the home phone numbers in each record.
TBL list from whiteboard: Stories: Versioning; Looking up predicates; Data merge; Ontology link; Inference (phonebook)
DC: NDW did View Source on his website, showing that he imported 27 different RDF sources and used them
<Norm> The URI for the data Dan is referring to is http://norman.walsh.name/knows/norman.walsh.name.rdf
DC: No way you could do that in vernacular XML w/o writing code
TAG looks at http://norman.walsh.name/knows/norman.walsh.name.rdf
scribe: which aggregates a lot of information from different sources
TBL: HST, how can you combine XML information from many namespaces
HST: Just do it, combine the docs under a common root
<timbl> DC: But then common references are not evident
DC: But you can't cross refer from one part to another
HST: Show me an example of that in Norm's doct
NDW: look at e.g. http://norman.walsh.name/1998/04/images/canaldish
NM: Purchase order example. . .
... Schemas are just a tool, to help people build systems
... Versioning work is directed at handling the common cases of language
evolution, finding what the mechanisms system builders want, [introduces
'person' example, including the addition in version N of a country code
element]
TBL: When the computer hits the unexpected code, it doesn't know what it is
NM: Schema allows some hooks via annotation, but doesn't guarantee that different parties will agree the annotation's meaning
TBL: RDF hasn't done much in the direction of required/desired/notallowed kinds of meta-information about predicates
NM: XML focus is historically on syntax, does
that ccode goes at the end of the element or the beginning
... RDF has less emphasis on ordering
NDW: RDF does versioning easily for what it does, but doesn't help much if at all with versioning XML languages
TBL: yes -- RDF versioning is much easier
<DanC_lap> NDW discovers that x can be redirected to a#b . HT asks: what if I'm looking up x#q ?
HST: I understood DC to say that RDF 'solved the versioning' problem for XML, which I think Norm was disputing, but I guess DC meant it 'dissolved' the versioning problem, that is, by moving to RDF you avoid most of XML's versioning problems
DC, TBL: the latter, pretty much
VQ: A few minutes to wrap up SW ways forward, then turn to other issues
HST would like to hear more from NDW wrt how the two applications of RDF he uses . . . by email
[break], at end of which David Orchard joins via 'phone
<Ed> http://www.w3.org/2001/tag/issues.html#namespaceDocument-8
NDW: Problems with taking RDDL forward -- some
problems encountered:
... 1) XHTML modularisation is needed to be more blessed
NDW: 2) There's a two-URI problem ;
<DanC_lap> looking back at http://www.w3.org/2005/04/05-tagmem-minutes.html#action03
NDW: 3) CMSMCQ alleges that RDDL commits some kind of tag abuse
DanC: What feedback about GRDDL/RDDL?
HST: I recall that my problem with the GRDDL idea is the necessity to run XSLT to get my schema document
DanC: you can hard-code that too
NDW: Regarding (2) above, what I meant was that in the RDDL document you have to include the same URI twice, once for humans and once for machines, which is a) tedious and b) liable to error/abuse
NM: Is that an architectural problem?
NDW: No, just not good document design -- the architectural question is introducing the level of indirection we need to get to all different kinds of things: Schema, DTD, human doc't, RELAX NG schema, ....
HST: A good-enough solution, no competitors
DC: Is status of current RDDL spec. good enough?
NDW: AC said no
NM: As written, it says it's about e.g.
namespace documents, not specifically only namespace documents
... If we were to make it a REC, we would need to specify this, yes?
NDW: Don't say 'only', just 'start there'
DC: Don't imply you should use this, just you may if you want to do the indirection
NM: So the use cases can all be namespaces, but no restriction to that
HST: So do we send RDDL to the XML Core WG ?
[all] No
DC: Start a WG
<dorchard> maybe an XG?
NDW: Schema WG
... Maybe if we asked the AC to create a WG to do this, they would agree it's
OK
NM: If we recommend a WG we get in process trouble vis a vis what we said about binary XML
[not well-minuted passage about routes to make RDDL a REC]
TBL: Wants not just the RDDL syntax, but also a semantics, i.e. a GRDDL stylesheet and an ontology for what it produces
HST: syntax is there, stylesheet is there (see http://www.rddl.org/rddl2rdf.xsl), all we need is the ontology
NM: Prefer specs not to talk about processing, if possible
<Norm> RDDL natures: http://www.rddl.org/natures/ and purposes: http://www.rddl.org/purposes/
DC: HST would you be happy if RDDL didn't have the relation you needed?
HST: Sure, The Schema WG would mint one
... The RDDL REC better allow for that
<DanC_lap> right, norm, how much of those lists should go in the REC?
NDW: Yes, I have to do that for functions for F&O
TBL: We need to look at RDFA before reaching a resolution
<Norm> I'm happy with both of those lists, in their entirety, being in the REC. And add some more if you want. Like RDF properties, I get to mint more.
<timbl> http://www.formsplayer.com/notes/rdf-a.html
DC: RDFA is the HTML WG's attempt at the general problem which RDDL is a specific instance of
<DanC_lap> (they have the same level of generality, as far as I can tell)
NM: Attributes for adding RDF to arbitrary
HTML
... Argh, uses QNames in content
TBL, HST: Sometimes that's the best solution . . .
<Norm> http://www.w3.org/MarkUp/2004/rdf-a
<DanC_lap> http://www.w3.org/TR/2005/WD-xhtml2-20050527/mod-metaAttributes.html#s_metaAttributesmodule
<DanC_lap> NDW: ew... qnames in content
TBL: Instead of rddl:resource or GRDDL, just use RDF-A, maybe?
DC: The news people use this technology, they really like the QName thing
HST: I still like the simple solution for the bounded problem
DC: What is the scope of a RDDL REC
NM: 1) Just namespace docs, just these N
properties;
... 2) Just namespace docs, these N properties for sure, more later ad
lib.
<DanC_lap> ("here's the RDDL property" hmm... the space of RDDL properties is the same as the space of RDF properties, yes?")
NM: 3) Anything about anything
<DanC_lap> (hmm... the odd thing about web architecture is perhaps that a traditional architecture allows you to determine whether a new machine is or is not an IBM360, but the #1 principle of web architecture is that there's only one web. (even though it's fractal, and there are independent webs in intranets and such, perhaps))
<ht> Break for lunch
DC: should we place namespaceDocument-8 in the "some day" pile?
NW: lots of people are deploying RDDL. It seems we should either say that is okay or that they are treading on unsafe waters.
TBL: much more inclined to pursue GRDDL than RDDL
VQ: is this something we can do in the short term?
DC: sure
<Norm> The solution that looks appealing is:
<Norm> 1. Define an ontology for this problem
<Norm> 2. Explain how rddl:purpose exposes that ontology
<Norm> 3. Write a GRDDL stylesheet with a well-known URI that literally instantiates an instance of that ontology when applied to rddl:purpose elements
<Norm> 4. So if you get a rddl 1.0 document, you can do it with GRDDL or by recognizing the URI of the stylesheet. If you get something else and apply its GRDDL and you get that ontology, you can use that too
<DanC_lap> (re part 1, the only term I know of that's used in practice is the one XSV uses to find schema documents)
VQ: there is nothing about RDF-A there ...
<Norm> ACTION: Norm to write something like this up and send it to www-tag to see if it gets popular support [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action01]
DC: step one and three apply to RDF
<DanC_lap> (VQ thought it didn't say RDF anywhere; I was clarifying that "ontology" brings in RDF)
VQ: I suggest we move on
<Norm> ACTION: VQ to update the open action list; this action subsumes Norm's outstanding action to post something about GRDDL/RDDL to the list [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action02]
<DanC_lap> http://www.w3.org/2001/tag/2005/03/action-summary.html
<DanC_lap> http://lists.w3.org/Archives/Public/www-tag/2005Apr/att-0068/April122005.html#action01
DC: [looking for example]
<timbl> One is idempotent and irreversible, the other is reversible.
TBL: mixing two different functions under a single name -- one is idempotent and the other is reversible
<DanC_lap> http://www.w3.org/TR/2005/WD-xpath-functions-20050404/#func-escape-uri
<DanC_lap> (invertible is more traditional than reversible, but close enough)
<DanC_lap> i("my file name") = "my%20file%20name"
<timbl> The reversible one takes a string and produced a path segment.
<DanC_lap> encode("my file name") = "my%20file%20name"
DC: this function allows arbitrary data to be included to produce a URI path segment
<DanC_lap> fn:escape-uri ("http://www.example.com/~bébé", false()) returns "http://www.example.com/~b%C3%A9b%C3%A9"
<timbl> uriSafe("htpp://foo/~bar") = ... %7E
<timbl> ..
<DanC_lap> critically: urisafe(urisafe(x)) = x
DC: the second example takes an entire IRI and encodes only the unsafe characters
RF: what about iri2uri?
<timbl> a2c
<DanC_lap> clean(clean(x)) = x
<ht> kool!
TBL: I propose clean
<timbl> encodeForURI(foo)
<DanC_lap> xxlify
<timbl> &ify
<DanC_lap> encode-as-uri()
RF: percent-encode and clean-uri
<timbl> percent-two-fice-ify
<Norm> percent-encode-uri presumably
TBL: what namespace are these?
all: schema functions and operators
<DanC_lap> encode-as-uripath() and clean-uri()
<DanC_lap> encode-as-uri() and clean-uri()
<DanC_lap> encode-for-uri() and clean-uri()
<timbl> encode-for-uri()
DC: who gets tell the working group? NOT IT
RF: not it
<Ed> http://www.w3.org/Bugs/Public/show_bug.cgi?id=1243
<scribe> ACTION: TimBL to respond to the XQuery WG regarding better split of function into two names [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action03]
VQ: anything else on this topic?
TBL: I see that existing bug report has been resolved... do we need a new bug report?
all: yes, a new bug report is in order
<Vincent> Dave, do you plan to join us shortly?
[break for 5 minutes]
<dorchard> yes I do.
<dorchard> I'll call in when you get back..
we are back but have not restarted yet
<Vincent> DO: then we will address XMLversioning-41 and abstractComponentRefs-37
<ht> Run against random strings ten characters long, the
<ht> grammar accepts about 0.7% of them, about 70 in 10000
<ht> trials.
<ht> Run against longer strings (30 characters), the
<ht> percentage falls somewhat: fewer than 10 in 10000
<ht> trials.
<dorchard> I do have a 10 minute appt at 2pm est 11am pst with a painter.
<dorchard> Perhaps convene once I get back?
<dorchard> very interested in 41 and 37...
<noah> On a different subject, but just so it gets into the minutes, I have updated http://www.w3.org/2001/tag/doc/SchemeProtocols.html to point to the newly published http://ietfreport.isoc.org/all-ids/draft-hansen-2717bis-2718bis-uri-guidelines-04.txt
<dorchard> back in 10..
<DanC_lap> [F&O] fn:escape-uri needs to be invertible in the true() case; take out the % exception
<ht> base URI issue is launched at http://lists.w3.org/Archives/Public/www-tag/2005Apr/0077
<timbl> _______________
<timbl> The design of escape-uri has a flaw in that it hides within one function two quite different ones. It should be split into two functions corresponding to different values of the escape-reserved flag. Possible names are as follows:
<timbl> encode-for-uri() takes any unicode string and returns a string which can be used as a path segment in a URI. This function is reversible, and NOT idempotent. (Definition of the inverse function would clearly be a good idea). Its semantics are those of your function with the second argument set to TRUE.
<timbl> clean-uri() takes a unicode string which may contain URI syntax but (like e.g. IRI) contains invalid URI characters. Without disturbing the URI punctuation, it encodes non-URI characters so that the result is a valid [part of a] URI in ascii. Its semantics are those of your function with the second argument set to FALSE.
<timbl> _____________________
<Ed> Ed +1
<DanC_lap> +1
<noah> +1
<Vincent> +1
RF: +1
<DanC_lap> so RESOLVED.
<Norm> +1
<DanC_lap> recorded as bug 1502
<timbl> http://www.w3.org/Bugs/Public/show_bug.cgi?id=1502
http://www.w3.org/2001/tag/issues.html#abstractComponentRefs-37
<DanC_lap> (re-checking pending actions http://www.w3.org/Bugs/Public/show_bug.cgi?id=1243 )
<timbl> http://lists.w3.org/Archives/Public/www-tag/2003Jun/0054.html
<DanC_lap> "HT: prepare abstractComponentRefs materials for ftf discussion (with help from DanC)"
<DanC_lap> is DONE, IMO
<ht> http://www.w3.org/TR/2005/WD-xmlschema-ref-20050329/
HT: worth noting that the above is a new draft proposing xpointer schemes for this purpose
RF: for the record, the examples in (http://www.w3.org/TR/2005/WD-xmlschema-ref-20050329/#section-example) show how ugly this can be
DC: [shows diagram showing a reference from an OWL diagram that wants to indicate the range of a function by pointing to a schema type definition, using a URI for that type as described by an xsd document]
<dorchard> back.
RF: calling now
<DanC_lap> will do...
<DanC_lap> HT: I think I'm on the same side as Dan on this, in that I think #xyz should short for a big long lhs#xpointer(...) as long as it's unambiguous, i.e. that there's only one big long xpointer() thing that has a referent
<ht> The problems the Schema WG has with this are, at least:
<ht> 1) What NS do I look in?
<DanC_lap> HT was responding to a question I asked about the case of ...people#xmlns(...people, p)xscd(p:minorAge)
<Zakim> DanC_lap, you wanted to correct myself: RDDL spec as-is is *almost* OK; it doesn't have a clear, normative mapping to RDF yet and to ask for a special-case in case the lhs, before
<ht> 2) Do I only look at simple types, or at all nameables?
<ht> 3) What is the default for mapping from left-hand-side (before the #) to schema, in which to look for the named thing
[large discussion about whether the component identifier's LHS (before the number sign) is supposed to be the schema's namespace URI or the URI of a schema document]
<Zakim> DanC_lap, you wanted to point out a relation to rdfURIMeaning-39
<DanC_lap> (hmm... HT says he has proposed a "language definition document" for composing schemas; I wonder if that's actually novel w.r.t. what's already available)
DC and TBL: the schema-URI should be the namespace URI of the schema -- the owner of that URI is responsible for maintaining the relationship between that URI and its representations (schema documents) -- some schemas will change over time and the owner knows whether they should retain the same URI or mint a new one for the new namespace [? scribe is interpreting]
DC: over time, community will only tolerate changes within the scope of the original namespace, leading to global consensus (or global change to a more stable URI)
<DanC_lap> (namespaces are *just like other resources* in this respect. when you update your essay, you can do it in-place or in a new place)
TBL: different groups place different
constraints on what content can be changed without requiring a different name
to reflect that change
... HTML makes changes with the intention of staying within the same
namespace, whereas others require each behavioral change to require a new
namespace version.
<ht> HST poses two examples: What is the name of the 'p' element in HTML4.1 strict?
<ht> What is the name of the 'output' element in XSLT 2.0?
<DanC_lap> answer: W3C hasn't minted such a name, henry
DO: How does a publisher indicate versions within a single namespace?
We concluded scheduling of next teleconference at this point.
<DanC_lap> what I want names for is: every doodad in every target namespace
NM: What do we want to name? Does it match what schema WG is trying to specify? If not, how do we go from here?
DC: why is schema any different from other documents? Front Page of the NY Times changes frequently; the U.S. Constitution changes less often.
<ht> HST: One week the type definition called 'banana' accepts integers between 3 and 18, the next week it accept dates between 2 and 22 February 1931
<Zakim> ht, you wanted to talk about a core xscd requirement
<Zakim> Norm, you wanted to push on the xhtml schema case
<ht> So I think I'm brought back to the language definition business, and it gets _much_ richer
<ht> The language 'document' has to tell me what the kinds and names of instances of the kinds are, and each version within the language has to tell you where to find the definitions of each name which they actually _do_ define
<DanC_lap> ack
<Zakim> DanC_lap, you wanted to ask if there are hints from the study of the rigid designator problem and the variable/value and the resource/representation situation, recalling
<ht> NM: Introduces the example of XPath cost of using a new namespace for every change to any element in your schema
http://www.w3.org/TR/2005/WD-xmlschema-ref-20050329/#section-example
<ht> NM, HST: We are hearing that a { namespace, localname, kind } triple is what would serve the SW's needs, even if it's not what the Schema WG needs for many of its own requirements
<DanC_lap> no, dorchard , I don't think schema components mostly have names
<DanC_lap> oops; misunderstood the question
<ht> Doesn't it matter that namespace -> schema is not 1-to-1?
<Norm> When timbl finishes or 10 minutes from now whichever comes first
NM: there are two different perspectives on naming -- one is to name the concept by way of the namespace, two is to name a component within a specific schema document
<DanC_lap> break thru xx:10
<DanC_lap> (hmm... how far did we get on http://www.w3.org/2001/tag/issues.html#rdfURIMeaning-39 )
<DanC_lap> wrong one..
<DanC_lap> ( http://www.w3.org/2001/tag/issues.html#abstractComponentRefs-37 )
NM: schema WG is currently working on the latter, whereas TAG *also* wants the conceptual name for use in things like semantic web and version-independent referencing
<DanC_lap> ACTION: HT to reflect TAG discussion on (namespacename, kind, localname) problem space, as compared to schema component naming problem space, to XML Schema WG [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action04]
DO: what happened here was that, as a result of issue 7, the group came up with a minimal provision to satisfy the TAG. There was no work on the bindings to actually use that facility.
<timbl> Safety is not just a question of how to use HTTP. It is also in general important for optimization.
<DanC_lap> (er... hang on... this came up as a last call issue from a member of the WG? did the WSD WG not understand that last call means "wg members have finished their review"?)
<Zakim> timbl, you wanted to say: Safety is not just a question of how to use HTTP. It is also in general important for optimization.
<DanC_lap> (hmm... WSDL requirements were written in 2002. I wonder if I was paying attention. http://www.w3.org/TR/ws-desc-reqs/ )
<DanC_lap> (ugh... no stories)
<DanC_lap> (ah... separate stories... http://www.w3.org/TR/ws-desc-usecases/ )
<Zakim> DanC_lap, you wanted to note that the web services that I see are things like the flickr API, and to note that I expect WSDL to be useful for such service interfaces, and ask where
<noah> Dan asked me to paraphrase discussion I just had with David O. Here goes:
<noah> Noah: does safety/get work with HTTP in WSDL.
<noah> David: yes, indeed it's a bit better than it was. Although the safety flag is now in an adjunct, the HTTP binding now respects it, and you can also explicitly set the HTTP GET method in the WSDL HTTP Binding
<noah> Noah: OK, am I right that a cost of the new decision is that you do not have a normative way of saying "use the SOAP GET binding from the SOAP rec"
http://www.pacificspirit.com/blog/2005/05/16/witw_wsdl_20_http_binding
<noah> David: not quite. The SOAP binding in WSDL does not honor the safety flag, but it does let you set the response only MEP and we think the GET WebMethod as well.
<noah> Noah: will that MEP to the specific on the wire protocol that the TAG agreed with the XMLP WG would be in the SOAP Rec.
<noah> David: yes, think so.
http://www.pacificspirit.com/Authoring/wsdl/YahooV1Search.wsdl
<DanC_lap> http://www.pacificspirit.com/Authoring/wsdl/ArtistWSDL2uriformencoding.html
<DanC_lap> so DaveO seems to be saying that my hopes are not completely unfounded.
<DanC_lap> so, dorchard , you're content with the recent decision of the WSDL WG?
<DanC_lap> hmm... <xs:element name="searchString" type="xs:string" fixed="webSearch"/>
DO: corporate users want to do REST stuff, but the tooling doesn't support it in the way that they are accustomed to building applications
<Zakim> Roy, you wanted to say: to be responsive to our original issue, they need to provide URIs that are GETable for the information made available by those services -- how they arrange
DO: two issues: 1) is the TAG okay with what the WSDL group did; 2) does the TAG see the state of the WS world going in the right direction or is there something more the TAG can do to improve things?
NM: I think 70-75% of the problem is political rather than technical -- people are saying that the issue isn't important enough to them to justify implementation. We did the right thing to look at the technical information, but I am wondering whether it is appropriate for the TAG to continue pushing them together
<noah> Actually, not quite. What I meant to say was, it's absolutely appropriate that we take effort to make sure the WS stack is a good citizen on the web and can exploit REST to the extent that's reasonable. The main role for the TAG is not to solve political and social problems, but we should certainly be supportive of community efforts to promote synergy between the WS stack and the rest of the Web.
<Zakim> DanC_lap, you wanted to observe that this is sort of an interesting soap/rest/web-services discussion, but regarding the TAG's position on the WSD WG's decision, it seems
<noah> I do think we should ask in all cases: if the technical underpinnings are adequate, and if the deployment isn't happening, then should we try to solve the problem by doing more technical work?
DO: We could considerably simplify WSDL by
making it specific to the SOAP binding and create a separate IDL for
REST-based Web
... The abstraction in WSDL causes additional steps that can be simplified
DC: I have heard some good news, but perhaps it would be useful to come up with a new use-case for WSDL and asking them to support it or declare it won't be supported by WSDL
<DanC_lap> 6.7 HTTP GET Versus POST: Which to Use? http://dev.w3.org/cvsweb/~checkout~/2002/ws/desc/wsdl20/wsdl20-primer.html?content-type=text/html;%20charset=utf-8#more-bindings
TBL: is there any open source code for making use of WSDL with GET
<DanC_lap> (hmm... offer a bounty for open-source [python?] implementation of this WSDL 2.0 GET stuff?)
NW: Any objection to telling the WSD chair that the change is okay?
[no objections]
<scribe> ACTION: DanC to communicate with Jonathan Marsh regarding TAG opinion on safety attribute change [recorded in http://www.w3.org/2005/06/16-tagmem-minutes.html#action05]
RESOLUTION: TAG thanks MIT and Vincent Quint for organizing and hosting this meeting
ADJOURNED
[NEW] ACTION: Henry Thompson to send F2F
logistics to Vincent for meeting page [recorded in http://www.w3.org/2005/06/14-tagmem-irc#T18-22-46]
[NEW] ACTION: Vincent to add draft finding
on schemeProtocols-49 to findings page (link is http://www.w3.org/2001/tag/doc/SchemeProtocols.html)
[recorded in http://www.w3.org/2005/06/14-tagmem-irc#T18-22-46]
[NEW] ACTION: Dan to get web applications
charter and share it with the TAG for review. [recorded]
[NEW] ACTION:VQ to invite Dean to a TAG
teleconference [recorded]
[NEW] ACTION: Roy and Norm to review http://www.w3.org/DesignIssues/Principles.html#PLP
[recorded]
[NEW] ACTION: Dan to write a report on the
state of the art authentication in the web. [recorded]
[NEW] ACTION: Dan to draft "Dont use
passwords in the clear" [recorded]
[NEW] ACTION: VQ to make a link from the
findings-in-progress page [recorded]
[NEW] ACTION: NM to produce a new draft [recorded]
[NEW] ACTION: RF to declare victory and
move on [recorded]
[NEW] ACTION: All to send vacation info to
Vincent [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action01]
[NEW] ACTION: Minute takers to get minutes
to Vincent by Monday 20 July [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action02]
[NEW] ACTION: HST, VQ to review the primer
[recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action03]
[NEW] ACTION: TBL revise http://www.w3.org/DesignIssues/HTTP-URI.html
[recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action04]
[NEW] ACTION: HST to recommend intro to
Dretske thought [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action05]
[NEW] ACTION: Norm to write something like
this up and send it to www-tag to see if it gets popular support [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action01]
[NEW] ACTION: VQ to update the open action
list; this action subsumes Norm's outstanding action to post something about
GRDDL/RDDL to the list [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action02]
[NEW] ACTION: TimBL to respond to the
XQuery WG regarding better split of function into two names [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action03]
[NEW] ACTION: HT to reflect TAG discussion
on (namespacename, kind, localname) problem space, as compared to schema
component naming problem space, to XML Schema WG [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action04]
[NEW] ACTION: DanC to communicate with
Jonathan Marsh regarding TAG opinion on safety attribute change [recorded
in http://www.w3.org/2005/06/16-tagmem-minutes.html#action05]
[End of minutes]
changes since call for review of Mon, 20 Jun 2005 18:40:35 +0200:
$Log: 14-16-minutes.html,v $ Revision 1.23 2005/06/24 20:55:02 connolly inline eiffel tower diagram Revision 1.22 2005/06/24 20:48:26 connolly width/height of semantic levels table Revision 1.21 2005/06/24 20:46:50 connolly blockquote style Revision 1.20 2005/06/24 20:45:32 connolly - marked up NM's quote from RFC3236 - inlined timbl's "Semantic levels" table Revision 1.19 2005/06/24 20:38:04 connolly - marked up an excerpt with blockquote/pre - moved some F+O namespace notes under the relevant item Revision 1.18 2005/06/24 20:29:11 connolly inlined 2nd/final snapshot of outline Revision 1.17 2005/06/24 20:26:07 connolly - added navbar for tue/wed/thu am/pm - moved some summer schedule stuff under the relevant item - linked HT's msg - continued inlining stuff that was projected at the meeting: URI-space.png Revision 1.16 2005/06/24 20:02:41 connolly link to call for review Revision 1.15 2005/06/24 20:01:20 connolly per NM Fri, 24 Jun 2005 15:18:01 -0400 Revision 1.14 2005/06/21 14:25:04 connolly links to context: W3C, TAG Revision 1.13 2005/06/21 14:20:22 connolly - item014 is more TAG Directions - try iframe for inlining stuff that was projected at the meeting, and not just referenced Revision 1.9 2005/06/20 17:32:40 connolly - consolidate scribe/roll items - consolidate scheduling of next telcon items - consolidate issue37 items - edit next teleconference item down to the substance of it - added changelog revision 1.8 date: 2005/06/20 17:12:15; author: connolly; state: Exp; lines: +7 -10 WSDL and safety... remove pointer to irrelevant issue ---------------------------- revision 1.7 date: 2005/06/20 16:25:54; author: vquint; state: Exp; lines: +1 -2 (vquint) Changed through Jigsaw. ----------------------------