
Health Care and Life Science (HCLS) Linked Data Guide
Editor's Draft 19 November 2012
- $Revision: 1.11 $ of $Date: 2012/12/06 20:27:07 $
- see also public-semweb-lifesci@w3.org Mail Archives
- Published W3C Technical Report version:
- Editors:
- M. Scott Marshall, MAASTRO Clinic, Maastricht, The Netherlands
- Richard D. Boyce, Department of Biomedical Informatics, University of Pittsburgh, Pittsburgh, PA, USA
- Contributors:
- Helena F. Deus, Digital Enterprise Research Institute, National University of Ireland, Galway, Ireland
- Jun Zhao, Department of Zoology, University of Oxford, Oxford, U.K.
- Egon L. Willighagen, Department of Bioinformatics - BiGCaT, Maastricht University, Maastricht, The Netherlands
- Matthias Samwald, Section for Medical Expert and Knowledge-Based Systems, Center for Medical Statistics, Informatics, and Intelligent Systems, Medical University of Vienna, Vienna, Austria; Vienna University of Technology, Vienna, Austria
- Elgar Pichler, Department of Chemistry and Chemical Biology, Northeastern University, Boston, MA, USA
- Janos Hajagos, Stony Brook University School of Medicine, Stony Brook, NY, USA
- Mikel Egaña Aranguren, School of Computer Science, Technical University of Madrid, Madrid, Spain
- Michael Miller, Institute for Systems Biology, Seattle, WA, USA
- Eric Prud’hommeaux, World Wide Web Consortium, MIT, Cambridge, MA, USA
- Michel Dumontier, Carleton University, Ottawa, Canada
- Susie Stephens, Janssen Research & Development, LLC, Radnor, PA, USA
Copyright © 2012 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
Abstract
This W3C Note summarizes emerging practices for creating and publishing health care and life sciences (HCLS) data as Linked Data in such a way that they are discoverable and usable by people, Semantic Web agents, and applications. These practices are based on the cumulative experience of the Linked Open Drug Data (LODD) task force of the W3C HCLS IG. While no single set of recommendations can address all of the heterogeneous information needs that exist within the HCLS domains, practitioners wishing to create Linked Data should find the recommendations useful for identifying the tools, techniques, and practices employed by earlier developers. In addition to clarifying available methods for producing Linked Data, the recommendations for metadata should also make the discovery and consumption of Linked Data easier. We have written this document assuming a basic level of understanding about the Semantic Web, RDF, Linked Data, and biomedical ontologies.
Status of This Document
This is an editor's draft of a document for the Semantic Web in Health Care and Life Sciences Interest Group (HCLS IG). This is a live document and is subject to change without notice. It reflects the best effort of the editors to reflect implementation experience and incorporate input from various members of the IG, but is not yet endorsed by the IG as a whole. This document is not endorsed by the W3C or its member companies.
1. Introduction
All data requires structure to provide useful information and codify specific linkages within the data. Using a graph language such as Resource Description Framework (RDF) helps to clarify the linkages within a data set by using a general mechanism that also enables the data to be connected to other sources that use the same semantic model. An appropriate semantic model for a given data set must be complemented by social protocol to establish common terms for the domain of discourse from which the data is derived. RDF exploits the World Wide Web to define and discover such terms. While the interest of data integration motivates us to use shared terms, this is sometimes in tension with legacy identifiers, as well as some social pressures (such as preserving a web site's user experience by funneling identifier resolution through that site). As in the conventional relational database world, this imposes a requirement of a "lookup table", which maps one code set to another. The development of such a table is a common task in data integration, and is challenging because it requires sufficient domain expertise to understand the meaning of the data which is often undocumented or implicit in human-readable labels.
Linked Data is a principled approach to data integration that employs ontologies, terminologies, Uniform Resource Identifiers (URIs), and RDF to connect pieces of data and optimize term re-use by ensuring that terms are backed by the Web (i.e. they can be pasted into the location bar in a browser)(LinkedData 2011). Expressing information as Linked Data shifts some of the integration burden from data consumers to publishers, which has the advantage that data publishers tend to be more knowledgeable about the intended semantics (for example, see this short video introduction to Linked Data). This is particularly relevant in the life sciences, where there is often no agreement on a unique representation of a given entity. As a result many life science entities are referred to by multiple labels and some labels refer to multiple entities. For example, a query for the Homo sapiens gene label "Alg2" in Entrez Gene (http://www.ncbi.nlm.nih.gov/gene) returns multiple results. Among them is one gene located on chromosome 5 (Entrez ID:10016) and the other on chromosome 9 (Entrez ID:85365), each with multiple aliases. An a posteriori integration would require the identification of the context in which these two genes are identified (e.g. the chromosome). If, instead, steps are taken to ensure that these two labels do not map to the same gene a priori (i.e. during data publication) then the burden of integration would be reduced.
There are several motivations to publishing Linked Data sets as indicated by the following potential use cases:
- Shareability: A data provider or publisher would like to make some existing data more openly accessible, through standard, programmatic interfaces such as SPARQL or resolvable URIs.
- Integration: A developer desires to create and maintain a list of links between different RDF data sets so that he can easily query across these datasets.
- Normalization: A computer science researcher is interested in matching and indexing an existing RDF data set using a set of common ontologies, so that the dataset can be queried using ontological terms.
- Discoverability: A bench biologist would like to be able to discover what is available in the Semantic Web related to a set of proteins, genes, or chemical components, either as published results, raw data, or tissue libraries.
- Federation: A developer desires to integrate information from distributed data sources using SPARQL.
Participants of the World Wide Web Consortium‚ Health Care and Life Sciences Interest Group (HCLS IG) have been making health care and life sciences data available as Linked Data for several years. These efforts have resulted in tremendous growth in the quantity of life sciences RDF. For example, in 2009 members of the interest group created more than 8.4 million RDF triples for a range of genomic and drug-related datasets available as Linked Data (A Jentzsch et al. 2009). More recently, members have begun enriching the LODD datasets with data spanning discovery research and drug development (Luciano et al. 2011). At the time of this writing, just one of the many publicly-available life sciences data sets (UniProt-RDF) has over five billion triples.
The interest group has found that publishing HCLS datasets as Linked Data is particularly challenging due to 1) highly heterogeneous and distributed datasets; 2) difficulty in assessing the quality of the data; and 3) privacy concerns that force data publishers to de-identify portions of their datasets (e.g. from clinical research) (H. F. Deus et al. 2011). Another challenge is to make it possible for the data consumer to discover,
evaluate, and query the data. Would-be consumers of data from the Linked Open Data cloud are confronted with these uncertainties and often resort to data warehousing because of them.
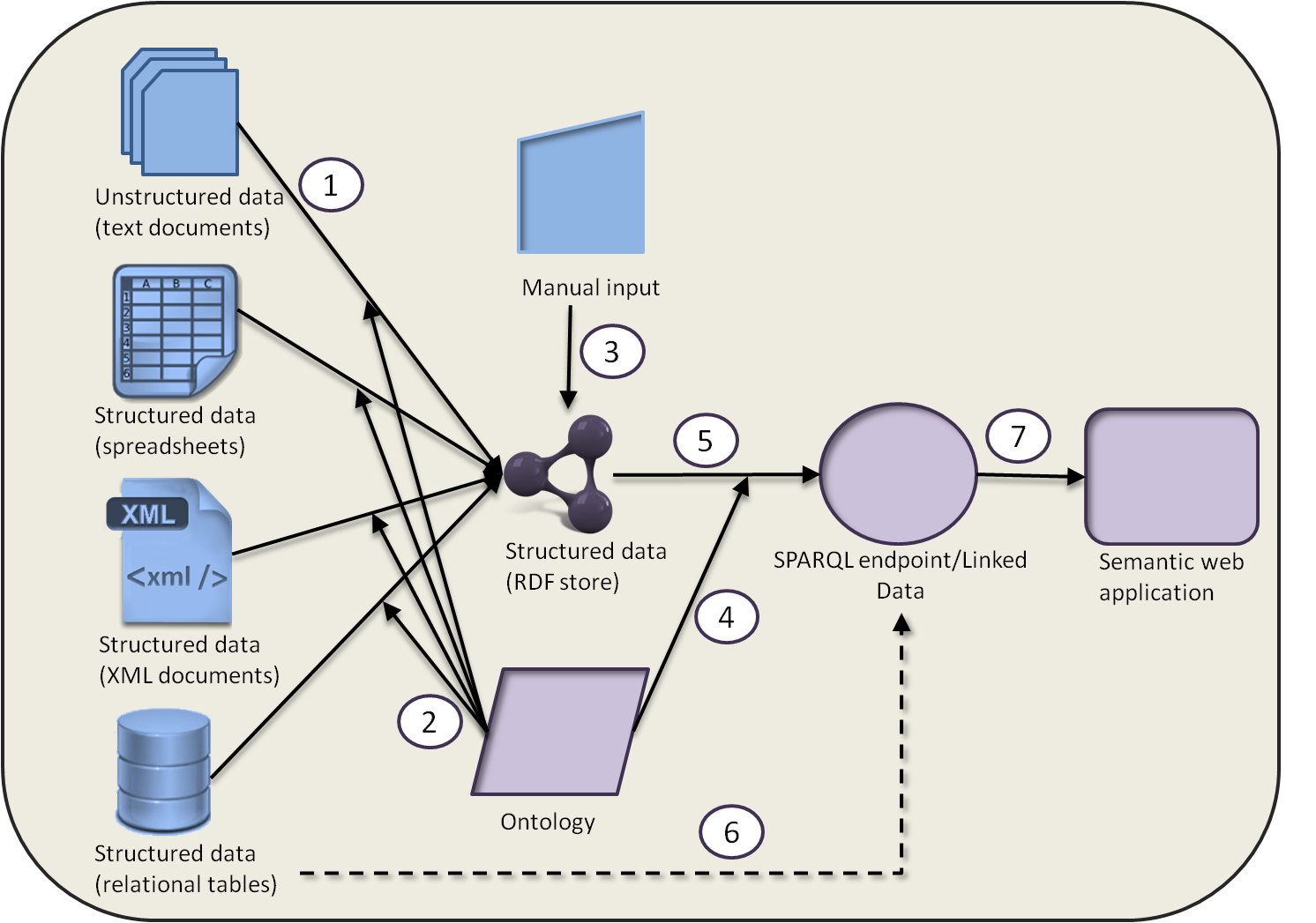
This collective experience of publishing a wide range of HCLS datasets has led to the identification of a general data workflow for mapping HCLS data to RDF and linking it with other Linked Data sources (see Figure 1). Briefly stated, the figure describes the following steps for both structured and unstructured datasets:
1. Select the data sources or portions thereof to be converted to RDF.
2. Identify persistent URLs (PURLS) for concepts in existing ontologies and create a mappping from the structured data into an RDF view.
3. Customize the mapping manually if necessary.
4. Map concepts in the new RDF mapping to concepts in other RDF data sources, relying as much as possible on ontologies.
5. Publish the RDF data through a SPARQL endpoint or as Linked Data.
6. Alternatively, if data is in a relational format, apply a Semantic Web toolkit such as SWObjects (Prud’hommeaux et al. 2010) that enables SPARQL queries over the relational schema.
7. Create Semantic Web applications using the published data.
HCLS Linked Data developers may face many challenges when creating new Linked Data resources using the above general workflow. As such, the identification of practices for addressing such challenges is a necessary step to enable integration of health care and life sciences datasets. The questions listed in Listing 1 summarize many of these challenges. The remaining sections of this document discuss a set of emerging practices currently used to address each of these questions.
Figure 1 Data flow depicting the ontology-driven mapping of structured and unstructured data into RDF format and the subsequent use of that data by a Semantic Web application via a SPARQL endpoint. See Section 1 for a description of the numbered elements.
2. Emerging practices for handling issues that a Linked Data publisher may encounter
No single set of rules would be able to address all of the heterogeneous information needs that exist within the HCLS domain. However, discussion within the HCLS IG has led to the following set of recommendations that address each of these questions:
Listing 1 - Questions that a Linked Data creator might have when creating an RDF Linked Data set
Q1. What are the tools and approaches for mapping relational databases to RDF?
Relational databases (RDBs) are the mainstay of data management and a prevalent source of data. A popular expression in the Semantic Web community is ‘leave the data where it lives’ and create an RDF view – resulting in synchronized and always up-to-date access to the source data. Many Semantic Web practitioners, including some in the pharmaceutical industry and in the HCLS IG, prefer to operate from an RDB foundation. In fact, some prefer to create a schema and import unstructured data sources into an RDB before working on the RDF rendering of that data. For this reason, key technology will be found in the area of mapping RDB to RDF (RDB2RDF).
The survey by the RDB2RDF Incubator Group (Sahoo et al. 2009) provides a review of the state-of-the-art for mapping between RDB and RDF data. Mapping the content of a RDB into RDF is an active area of research that has led to the development of new tools and approaches such as SWObjects (SWObjects 2011). Entities in life science databases often have complex relationships. The semantics of these entities and their relationships can often be expressed using existing life science ontologies. This not only promotes the reuse of existing knowledge resources but also has the potential to enhance the interoperability between different RDF datasets. Hence, for mapping life science data to RDF, one of the most important aspects is the capability of representing the domain semantics that is not explicitly defined in the relational algebra of RDBs.
The tools for RDB2RDF must be able to support customized mapping definitions. Of nine tools reviewed by Sahoo (Sahoo et al. 2009), three of them (Virtuoso (Auer et al. 2009), D2R (C. Bizer 2010) and Triplify (Auer et al. 2009)) support manual definition of the mappings, allowing users to use domain-semantics in the mapping configuration. Other tools also support the manual definition of mappings, such as ODEMapster (OntologyEngineeringGroup 2011). Practical experiences have shown that the automatic mappings generated by tools like D2R provide a welcome starting point for customization (Jun Zhao et al. 2009). Apart from customizable mapping definitions, the tools should also support the use of existing bio-ontologies in the mapping process, using services such as those hosted at NCBO’s BioPortal (NCBO 2011; Noy et al. 2009).
An important feature of RDB2RDF tools is the ability to create a ‘virtual view’, or a semantic view of the contents of a (non-RDF) source database. For example, in addition to creating an RDF version of database contents using its mappings, D2R can provide a SPARQL endpoint and a Linked Data interface (where URIs resolve to descriptive RDF) directly on top of the source non-RDF database, creating a virtual ‘view’ of databases. Such a 'semantic view' will guarantee up-to-date access to the source data, which is particularly important when the data is frequently updated with new information.
SWObjects creates semantic views by rewriting queries, from SPARQL to SQL, as well as from one RDF vocabulary to another. One of the advantages of using the relatively new SWObjects is that the mappings used to create RDF views of RDB’s are expressed using the SPARQL CONSTRUCT standard rather than a specialized, non-standardized language. In SWObjects, SPARQL CONSTRUCT statements form rules that can be chained together. This also makes it possible to pass constraints through a chain of CONSTRUCT statements that effectively rewrite a query to be more efficient and reduce the computational cost of query execution. A challenge of using SWObjects is that all queries and desired types of information must be anticipated in order to create the RDF views because any information not exposed via the SPARQL CONSTRUCT mappings that configure the SWObjects
SPARQL endpoint will be invisible to queries. Configuring such RDF views therefore requires knowledge of SPARQL, SQL, and of how the anticipated queries would translate into SQL. Ideally, this activity would be supported by an “SWObjects map editor tool” which would autocomplete graph patterns in the SPARQL Construct according to possible matches in (potential) graph SERVICE endpoints.
The user experience in terms of performance depends on many architectural and design factors, including the optimization of the back-end RDB, size and structure of the data, and the specific queries required by the application. For example, in a federation, there are potentially invisible costs such as support for entailment regimes (materialized or on-the-fly), etc. However, query rewriting alone is a linear exercise that shouldn’t add any unexpected algorithmic overhead. Developer costs in terms of maintenance, on the other hand, are more straightforward. Generating and storing RDF will require synchronization whenever either the source data model, the target RDF model, or the mapping logic between them changes. Therefore, query rewriting will generally lower developer costs that would otherwise be devoted to synchronization of code, data, and GUI.
The set of tools available for mapping relational data to RDF is rapidly expanding; please see the W3C HCLS Wiki Tools page for an expanded list.
Q2. Are some relational schemas easier to map to RDF than others and is a direct mapping better than a transformation?
An RDB schema can vary in complexity from a single table to hundreds of tables with supporting reference tables. Many HCLS databases, such the UCSC Genome Browser (Karolchik 2003), are complex and organized specifically for research and discovery. Tools that map RDB into RDF, like D2R or Virtuoso, provide an automated process to generate a mapping file (Sahoo et al. 2009), which converts every table into a class. For tables with a large number of columns this strategy can translate into a significant reduction of the initial time investment required for converting the contents of an RDB. In practice, a completely automated process is a convenient first step in publishing Linked Data, however it does not enable the fine-grained control that is needed to create RDF representations that align well with existing ontologies or related datasets. Furthermore, it is often unnecessary to convert every table into a class and wholesale conversion can create scaling problems for large table
spaces. Domain-specific enhancements during the mapping process enable a much more accurate representation of the meaning and interrelatedness of statements within and across RDBs. Furthermore, they have the potential to drastically reduce the size and complexity of the resulting RDF dataset (Byrne 2008).
RDB schemas can vary in their level of normalization as quantified by normalized forms (Date 2009). The normalization process seeks to reduce the occurrence of repeated and inconsistent data elements (NULL values) by breaking apart tables with many columns into component interlinked tables. The component tables often do not directly reflect the application needs of those seeking an RDF representation. In practice, many databases are not normalized because the overhead of working with the schema is not worth the extra reliability and space savings that may result. For Online Analytical Processing (OLAP) applications in particular, highly normalized RDB schema designs can increase the complexity of SQL to such an extent that analysis becomes impractical.
In dimensional modelling (Kimball & Ross 2002), a logical design technique for data warehouses and OLAP, data are grouped into coherent categories that are easier to understand. This makes the mapping from dimensional representations to RDF, RDF Schema, or Web Ontology Language (OWL) classes more straightforward, and enables the default automated mapping process to yield better results. Furthermore, hierarchies in the dimension tables may help to indicate RDF classes and their relationships providing a richer data set.
How much data restructuring is needed depends on the underlying RDB schema structure and data contained, as well as the intended application of the interlinked data. These issues have also been faced by designers of traditional data warehouses and their data extract, transfer, and load (ETL) processes. In this context, Linked Data publishers can learn from recommended practices for building and populating data warehouses (Kimball & Caserta 2004). We recommend that the data publisher become as versed as possible in the underlying RDB schema, data content, and “business rules” that generated the stored data so as to best understand how the data should be structured in a Linked Data representation.
Q3. How to convert non-relational information to RDF?
Even though the ideal situation is to create an RDF view or directly map information from an RDB to Linked Data, there may be a situation in which information in other formats (CSV, XML, etc.) should be transformed into RDF. The xCurator project offers an end-to-end framework to transform a semi-structured (XML) source into high-quality Linked Data (Yeganeh et al. 2011). Also for XML, Gloze (Anon 2006), which is part of Jena, uses the information available in the XML schema to convert bi-directionally between XML and RDF. CSV4RDFLOD (Timrdf 2011) can be used to transform CSV (Comma Separated Values) flat files into RDF. Google Refine (Maali & Richard Cyganiak 2011) is a general data “Cleansing” tool that works with a plethora of formats: CSV, Excel, XML, etc. The Google Refine RDF extension (Google 2011) can be used to export a Google Refine project as RDF. The set of tools available for this task is rapidly expanding, please see the W3C HCLS Tools page for an expanded list.
Q4. How should the RDF representation be mapped to global ontologies or reference terminologies?
NCBO’s BioPortal is a convenient tool which can be used to identify public ontologies that best map to the entities in biomedical and clinical data sets. BioPortal contains URIs for concepts from almost 300 biomedical ontologies and reference terminologies, including SNOMED-CT and NCI Thesaurus. Ontologies can be selected based on a number of criteria including terminological coverage of target domain, popularity (to leverage existing RDF for linking), and axiomatic richness. OntoBee is a similar resource specific to ontologies developed by the Open Biological and Biomedical Ontologies (OBO) Foundary (Xiang et al. 2011, OBO 2011). Selected terms from these ontologies can be collected in a common resource ontology (CRO) to avoid repeating class definitions for every data source (Verbeeck 2010). For classes available in public ontologies, it is recommended that the CRO be built as a comprehensive representation of a domain by importing a standard set of orthogonal ontologies using the guidelines described in MIREOT (Courtot et al. 2009).
Using a CRO offers some advantages:
- Scientists may have strong preferences for particular ontologies. When there is no general agreement about which ontology to use, one can use the definition of a proxy class in the CRO. The proxy can be linked to a number of public ontologies using URI aliases. Another advantage of the proxy approach is that in depth knowledge of the ontologies to reference by proxy is not necessary for the selection of terms for use in the RDF.
- Building a SPARQL query requires knowledge about the ontology or ontologies used during the mapping process. This information can be retrieved from the CRO.
- Using semantic wikis such as Semantic MediaWiki (Krötzsch et al. 2006), the CRO can be maintained or extended by the scientists themselves.
- Semantic MediaWiki can store its data in RDF if the “triple store connector” plug-in is installed, enabling its use as a metadata repository for data source discovery. While at the time of this writing SPARQL is not integrated, Semantic MediaWiki extensions like RDFIO can be used to make the RDF data available as SPARQL (Lampa 2010).
- Custom definitions can be included within the CRO; this is an important step as it may happen that some class definitions required for mapping the RDB schema to RDF will not be available as public ontologies.
A challenge in making data available as Linked Data is the high level of expertise necessary to understand ontologies and dialects of description logic employed by OWL. For example, understanding and using the full potential of OWL 2 can be challenging, even with ontology tools like Protégé (Knublauch et al. 2004). Fortunately, creating RDF (or an RDF view) that makes use of global ontologies does not always require comprehensive knowledge about OWL and ontologies. In the life sciences, tools such as the NCBO Annotator (Jonquet et al. 2008) can be used to automatically identify relevant concepts in existing ontologies.
Q5. How to interlink instances to other existing data sources?
A challenge that becomes increasingly relevant as Linked Data grows is the comprehensive review and identification of the data sources that may contain instances which can be linked to a converted RDF dataset. This is a necessary step for making the data “5-star” as per Tim Berners-Lee’s definition (i.e., available on the Web in a non-proprietary machine-readable format and linked to other RDF data sources) (T. Berners-Lee 2007). Creating interlinks between data often requires extensive research work on deciding and choosing a target Linked Dataset. Once a target data source is identified for linking, connections established between the two datasets will enrich both. Ways to achieve this include constructing links using a scripting language that performs string processing, using a SPARQL CONSTRUCT query if both datasets are loaded into a single triple store, or using more specialized frameworks such as Silk (Becker et al. 2011). Domain knowledge can provide more appropriate guidance on how links between datasets should be established and, in our practical experience (Jun Zhao et al. 2009), has been found to be effective for correcting automatically-created interlinks such as gene synonyms and genome locations. Structure descriptors, such as SMILES strings, and InChi identifiers may be used to establish links between datasets containing drugs and small molecules.
Q6. Does all data need to be mapped to the same ontologies in order to achieve interoperability?
No. However, the more entities and predicates there are in common between two data sets, the easier those two datasets can be integrated or "joined" in a query, without loss of information or gain in noise. The use of any ontology when mapping data is already an improvement over tags or unstructured text which often force integration to rely simply on lexical or "string" similarity. Indeed, if the same ontologies or URIs are used in different data sets, the level of effort required is much less than if the ontologies are different. But often there are domains that are represented by different organizations, for instance the multiple protein and gene databases that have existed side by side with separate funding, or separate but related domains such as drug and adverse reaction knowledge bases. In case different ontologies have been used in each data set, it is sometimes possible to use alignment information between the two ontologies in order to translate to a single mapping. This is the case in the above example where the protein and gene databases have rich cross references between them.
When mappings between ontology resources are represented in a standardized language such as SPARQL Construct (which encodes a pattern-action style rule expressed in N3), the same tools that are used to access the data and metadata can be used to execute the mappings. This approach makes post hoc data integration feasible for disparate information systems without requiring any pre-coordination of data schema or choice of controlled vocabularies because it enables dynamic remapping of queries via query rewriting. Furthermore, the query rewriting can be fully automated via the support for SPARQL Construct, which is available in the many SPARQL query engines and triple stores that are SPARQL 1.1 compliant. When the approach is implemented in a system architecture where data, metadata, and mappings are all accessible via SPARQL, it means that the choice of a given vocabulary at an endpoint is no longer critical to interoperability within the data federation. Data managers wishing to make their data accessible at a SPARQL endpoint using a set of common vocabularies (such as those selected in a data federation or consortium) can set up the mappings and a server using SWObjects (SWObjects, 2011). Data consumers who wish to access the data at a given endpoint using a set of preferred vocabularies can also create their own mappings using SWObjects, which creates a SPARQL endpoint for the resulting "RDF View" of the data. In this way, the endpoints to be integrated are then freed from schema requirements that are typically found in a data federation associated with a consortium such as EURECA. These principles have been demonstrated in a recent publication that describes post hoc data integration across several SPARQL endpoints containing microarray data (Deus et al. 2012).
Q7. How should the URIs and namespaces be determined?
Before transforming data into RDF (Figure 1, step 1) or creating an RDF view of the source data (Figure 1, step 6) one must decide on the URIs and namespaces to be used. Tim Berners-Lee has clearly outlined good practices for Linked Data (Berners-Lee 2006) and more information can be found in the Linked Data Tutorial (C. Bizer et al. 2007). Here are some of the general guidelines:
- Reusing existing URIs improves the connectivity of your data set with other data sets.
- Creating links that resolve to URIs published by others is highly recommended and necessary if the data source will be published as Linked Data.
- New URIs should be coined only if no existing URIs can be found. Use BioPortal or OntoBee for matching entities and their URIs. Besides the ‘search all ontologies’ function of BioPortal, there is also an Ontology Recommendation service (http://bioportal.bioontology.org/recommender).
- Use http://identifiers.org to find URIs for information artifacts, such as a database records and gene accession numbers.
- If you create new URIs, be sure to have control over the namespace.
- Use PURLs (Persistent URLs) where possible.
A number of projects can potentially supply URIs for the biomedical domain. The intention of the Shared Names project (SharedNames 2011) is to supply a common set of names or URIs for entities described in bioinformatics data records. SharedNames is based on a federation of PURL servers that create a vendor neutral and stable namespace for common URIs. The http://identifiers.org/ consortium is developing URIs for the HCLS domains in cooperation with prominent members of the Semantic Web community, including Bio2RDF (Belleau et al. 2008). Identifiers.org includes support for an identifier system called MIRIAM from the European Bioinformatics Institute (EBI), which has recently announced adoption of URIs.
We do not attempt here to describe all the technicalities of creating proper data URIs. Further information can be found in existing best practice documents (C. Bizer et al. 2007; Sauermann & R. Cyganiak 2011).
Q8. What should be done if there are gaps in the current ontology landscape?
The life sciences domain is very dynamic and evolving. When a particular phenomenon cannot be described in enough detail with existing ontologies, it is good practice to contact the authors of the most relevant ontology to alert them of the gap. If new terms need to be created, it is preferable to extend as much as possible an already existing ontology. When coverage of existing ontologies does not supply the necessary detail, the creation of a specialized ontology might be unavoidable. This has been done, for example, with the Experimental Factor Ontology (EFO) (EFO 2011) when the Ontology of Biomedical Investigation (OBI) (OBI 2011) could not yet supply the needed terms. Of course, when such an ontology is used, it should also be available in the public domain for those who would like access to the published RDF. In summary, if an ontology does not satisfy modelling requirements, the following procedure has been found effective (Villazón-Terrazas et al. 2011):
1) Contact the owner of target ontology.
2) Extend target ontology if (1) fails.
3) Create your own ontology if (2) fails.
The Notes API and related facilities can be used to provide comments and proposals to ontology maintainers when using WebProtege and the NCBO BioPortal (P.R. Alexander et al. 2011). Of course, to be true to Linked Data principles, be sure to add mappings to other existing ontologies if creating an ontology from scratch (Tom Heath & Christian Bizer 2011).
Q9. How should metadata and provenance be handled?
Before making data accessible either via a Linked Data interface or a SPARQL endpoint, we must consider a set of augmentations to the data in order to make it more discoverable and trustworthy. Provenance is an important type of metadata because it describes the origins and processes that led to the data set. The nature of experimental data is determined by the experimental design and conditions at the time of the experiment. Such information can be important for the analysis and interpretation of the data. In a biomedical data set, laboratory protocols, instrumentation, and handling conditions can all be relevant to some types of analysis. This information can be thought of as equivalent to the Materials and Methods section of a biomedical article, which is meant to make it possible to reproduce the results discussed in the article. The best way to express this type of information in ontological terms is an area of ongoing investigation (H. F. Deus et al. 2010).
In the context of RDF publishing, another type of metadata describes the RDF itself, including provenance information describing the processes used to produce the serialization, the versions of any ontologies used to describe the data, and an unambiguous reference to the original data. The purpose of this metadata is to supply essential information about the RDF to make it discoverable on the Web. A list of essential information about the RDF would include: label of the data set, creator(s), original publishing date, date of last issue, frequency of updates, data source, version, license, vocabularies used, and the software used in the transformation. Ideally, it would be possible to reproduce the RDF using the original data and the processes and parameters described in the provenance for the RDF. For this reason, it is preferable to use and refer to the open source software that was used in the process. Other good practices would be to refer to the SPARQL endpoint that serves the
graph and provide a representative query. Many of these practices can be supported by the VoID vocabulary (Alexander et al. 2011) and the Provenance Vocabulary (Hartig & Jun Zhao 2010). There are also standardization efforts in the W3C Provenance Interchange Working Group, with strong input from the HCLS community, which aim to provide a suite of standard recommendations and best practices, including but not limited to, the PROV Ontology (OWL 2011) and the Provenance Access and Query document (PAQ 2011). These forthcoming standards and recommendations are expected to facilitate the publication of interoperable provenance information on the Web and an agreed means for discovering, querying and accessing such information.
The ability to name a graph with a URI enables the storage of metadata statements about the graph in RDF. We recommend that such data be stored in each graph and that such information be aggregated for all graphs at the SPARQL endpoint. A promising approach from the W3C standards track is the SPARQL 1.1 Service Description (Williams 2011). Most triple stores currently supply some form of named graph (quad store) functionality and, although it has not yet been standardized by the W3C, this seems to be on track for standardization (SPARQL 2011; RDF 2011).
Q10. Under which license should I make the data available?
It is very important to annotate relevant information on the copyright and redistribution/modification rights of any Linked Data set. Without a clear disclosure of such information, many corporations and pharmaceutical companies cannot use the data because it is unclear how the data can be reused or modified. The information should be presented in the location where users are expected to interact with the data, such as on individual web pages for discrete resources, or on the SPARQL endpoint page. We think it preferable that a true Open Data license is used, such as proposed by the Panton Principles (Murray-Rust et al. 2010) and the Open Knowledge Foundation (OKF 2011), the CC0 waiver (CCO 2011), or the PDDL (ODC 2011). Data that is in the public domain (that has no copyright owner), should be labelled with the creator of that data set, as well as a clear notice about the public domain nature. For example, the Creative Common’s Public Domain Mark 1.0 can be used (PDM 2011).
In many cases the type of license is determined by the original data source. If this information is not clear, the original source should be asked to provide such information. Regardless of which license is chosen, we suggest including an RDF triple with the predicate <http://purl.org/dc/terms/license> as suggested by VoID, the URI of the published RDF graph as the subject. and, ideally, the URI to a license ontology as the object. The HCLS IG is currently investigating whether an appropriate license ontology can be made available in order to complement VoID's effort.
Q11. Does data always need to be provided as Linked Data, or is a SPARQL endpoint enough?
Although a Linked Data interface (such as that provided by D2R) is preferable, not everyone has the resources to create one. Fortunately, a SPARQL endpoint can always be made accessible through a Linked Data interface at a later time and still can serve to interconnect data sets, so long as ontological identifiers and common URIs are used.
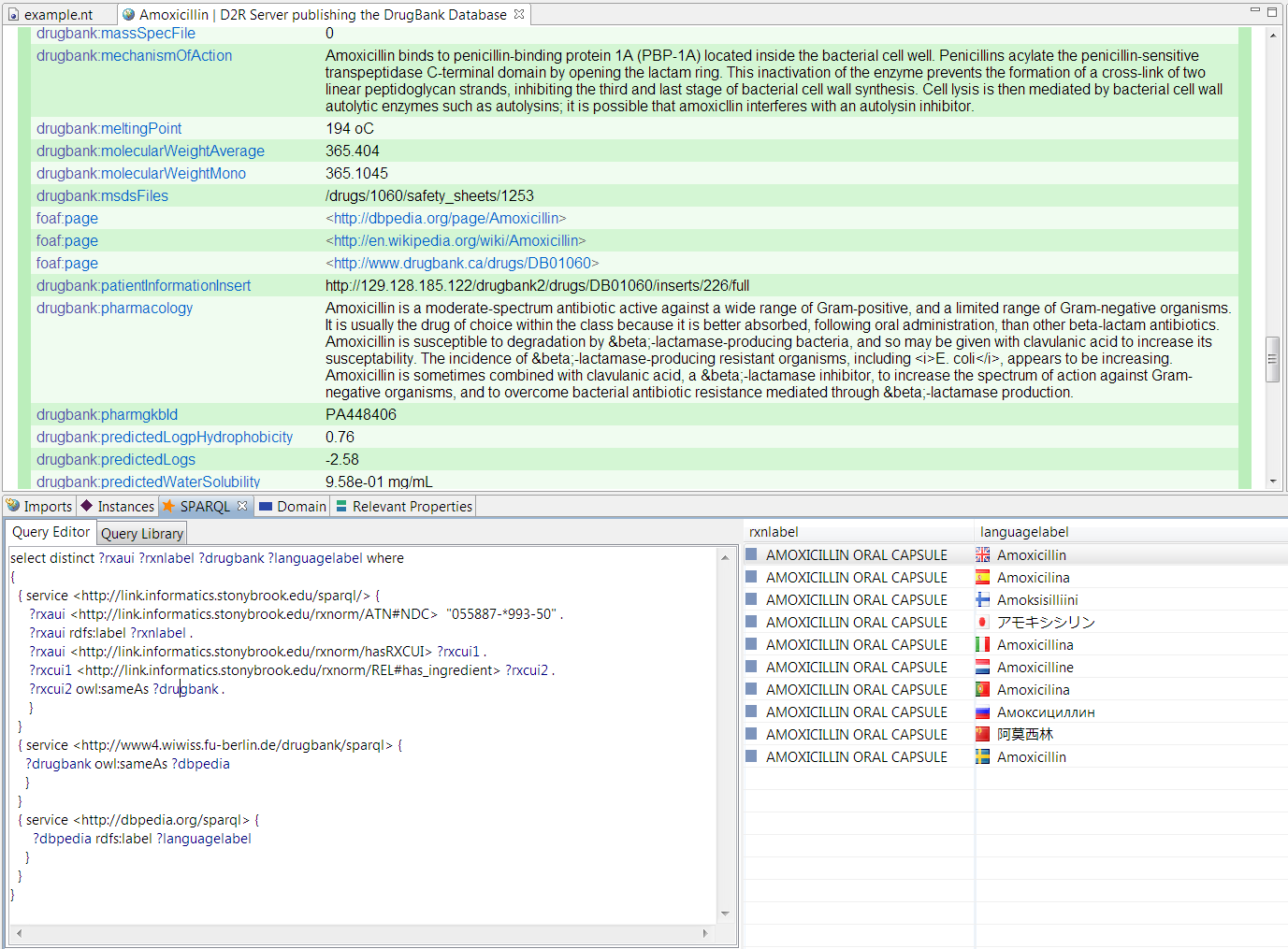
Figure 2 illustrates this point using the example of a distributed (federated) SPARQL query for the string name, in multiple languages, of a drug product that is represented by an NDC code. The query is first applied to an RDF version of the RxNorm database published as a SPARQL endpoint. Because RDF RxNorm is linked to DrugBank through the CAS registry number of its active ingredients, and DrugBank has connections to DBPedia, the query can request all language renderings of the drug product present in DBPedia; see (Christian Bizer et al. 2009) for further details. While it is not expected that the average user would write a distributed query such as that shown in Figure 2, software agents acting on a user's behalf could do so.
Figure 2 : A federated SPARQL connecting an Amoxicillin Capsule identified by the NDC code 055887-*993-50 to different language representations of the active ingredient. The screenshot from TopBraid Composer Free Edition (Versions 3.5.0) which utilizes Jena's ARQ show the results of running the federated SPARQL query. Note this query can be executed anywhere in the world where the three SPARQL endpoints can be accessed without installing any data locally on the client. Top: DrugBank provides more detailed chemical data on the active ingredient shown in the dereferencing of the URI. Different language labels are obtained from rdfs:label in DBPedia. Bottom left: source of the federated query. Bottom right: result set of executing the query. The RDF standard allows literals to be encoded in Unicode.
Q12. How can I make it easier for people and programs to find and use my published RDF?
An important part of improving the utility of the Web is by documenting the reliability and performance of information services. In the area of biomedical information services, BioCatalogue (Bhagat et al. 2010) describes and tracks the features and performance of thousands of bioinformatics services. The Comprehensive Knowledge Archive Network (CKAN) registry makes it possible to “find, share and reuse open content and data, especially in ways that are machine automatable” (CKAN 2012). The CKAN registry has its own SPARQL endpoint for machine discovery. A SPARQL Endpoints Status page has been recently initiated by an independent source (Vandenbussche 2011) that makes use of CKAN to provide an overview of reliability for the SPARQL endpoints in CKAN. Complementing this effort with descriptions of concepts, properties, and links to third party data sources may help users more easily query a new SPARQL endpoint. Additionally, a file named “sitemap.xml” can be generated in order for semantic search
engines such as Sindice to be aware of the updates of the published RDF (Richard Cyganiak & Villazón-Terrazas 2011).
Q13. What tools make use of the Linked Data once it is available?
There are a number of Linked Data browsers that enable browsing of Linked Data such as Disco (C. Bizer & Gauß 2007), Tabulator (Tabulator 2011), and Openlink ODE Browser (ODE Browser 2012). An overview of these types of browsers is available at the Linked Open Data Browser Switch web site (LOD 2011). There are also RDF crawlers such as Sindice (Sindice 2011), SWSE (SW 2011) and Swoogle (Swoogle 2011). While generic Linked Data browsers are useful for getting an overview of the raw data available on the web, they may not be practical for all end-users because the user interfaces are generally not very user-friendly and “on-the-fly” aggregation of distributed data is often slow. Fortunately, custom applications can be built that utilize SPARQL endpoints in a Service-Oriented Architecture (SOA) based on distributed vocabulary resources and Linked Data. In our experience, applications built using this approach are generally faster than applications that rely on URI / PURL resolution. Moreover, this approach
generally makes it possible to create both web applications, such as those based on AJAX libraries (Jun Zhao et al. 2009), and stand-alone applications based on the same architecture and relying on the same API (SPARQL).
Q14. Can I use automated reasoning with Linked Data?
Automated reasoning is the process by which the axioms implicit in an ontology are made explicit by a program called a reasoner. The reasoner infers the axioms that are implied by the assertions made in an ontology. For example, if A is a subclass of B and B is a subclass of C, the reasoner will infer that A is a subclass of C, since “sub class of” is a transitive relationship. Automated reasoning can be used to infer the class hierarchy of an ontology, check its consistency, perform queries against the ontology, or determine to which class an entity with certain features belongs.
Although OWL automated reasoning does not reliably scale for use in large knowledge bases, algorithms are improving continuously. For example, OWL 2 now presents three profiles (QL, RL, and EL) that optimize different kinds of reasoning. Automated Reasoning can be used in a dataset to materialize (or “insert”) inferred triples exploiting the axioms of the ontology (Jupp et al. 2011). Reasoning can also be used to check the compliance of the data against the ontology, especially with tools like Pellet ICV (Clark&Parsia 2011). Finally, some triple stores offer the possibility of exploiting OWL semantics. For example, in Virtuoso, transitivity can be used in SPARQL queries using the TRANSITIVE keyword. Moreover, OWLim offers the possibility of exploiting fragments of OWL semantics by approximating such semantics with rule sets (Stoilov 2011).
OWL reasoners are not always required. Some useful kinds of inference can be done using RDF and RDF Schema (RDFS), such as by using Simple Knowledge Organization System (SKOS) relations. In fact, in some cases, simpler kinds of reasoning can be used to create Linked Data (i.e. by inferring sameness based on being an "instanceOf" the same class rather than annotating instances with "sameAs" predicates).
In order to support automated reasoning, it is important that Linked Data creators consider carefully which entities they model as classes and instances. The discussion of what is best modeled as a class vs an instance is outside the scope of this W3C Note but is covered in resources such as (Allemang & Hendler 2008). A common practice from Linked Data developers is to describe most data as an instance of some ontological class and to use classes as values in the metadata for a graph; for example to indicate that a particular class of data is being provided in the data set.
3. Discussion
We have proposed a set of practices that authors publishing HCLS datasets as Linked Data may find useful. Here, we highlight some of the most important points:
3.1 Summary Recommendations
Create RDF views that anyone can use
- Use a mapping language to create an RDF view of the data when possible, rather than customized code.
- When possible, use vocabularies that are openly available from an authoritative server like the ones provided by OBO Foundry and the NCBO for HCLS data.
- When faced with uncertainty about the proper term from an authoritative domain ontology, use a CRO that can redirect references to proper terms until they are replaced.
- Use rdfs:label and rdfs:comment generously to provide information to user interfaces.
Publish RDF so that it can be discovered
- Publish open access data whenever possible, as well as any associated software.
- Publish a URL to the software and mappings that you used to create the RDF.
- Register your data in the CKAN data hub. If it’s biomedical, register an API to the SPARQL endpoint in BioCatalogue.
- Assign a graph URI to the RDF graph and add provenance and metadata about the graph URI to the graph itself. This practice makes it possible for visitors and crawlers to find out what is in the graph.
4. Conclusions
We have summarized a set of recommended practices for creating and publishing RDF for life sciences datasets. The set of principles and practices identified in this report have emerged from community practice and agreement rather than from a top-down approach. They reflect the state of the art in the field at the time of writing and may shift as new tools and resources are made available to the community (Noy et al. 2009). Although our suggestions to the questions that may arise during Linked Data creation (Listing 1) are oriented towards the HCLS domain, there is no reason why such practices could not be applied in other domains. For example, efforts are underway for a general source of ontologies and terminologies called the Open Ontology Repository (OORP 2011) that would be much like BioPortal, but useful for scientists and researchers outside of the HCLS domain.
5. Acknowledgements
We thank all who gave comments on the manuscript, especially Claus Stie Kallesøe and Lee Harland. We thank the participants of the Linked Open Drug Data task force and the W3C Health Care and Life Science (HCLS) Interest Group. Support for HCLS activities was provided by the World Wide Web Consortium (W3C). RB was funded by grant K12HS019461 from the Agency for Healthcare Research and Quality (AHRQ). MEA was funded by the Marie Curie Cofund programme (FP7) of the EU. The content is solely the responsibility of the authors and does not represent the official views of AHRQ.
6. References
Alexander, K. et al., 2011. Describing Linked Datasets with the VoID Vocabulary, Available at: http://www.w3.org/TR/2011/NOTE-void-20110303/ [Accessed August 11, 2011].
Alexander, P.R.,Nyulas, C., Tudorache, T., Whetzel, P.L., Noy, N.F., Musen, M.A. 2011. Semantic infrastructure to enable collaboration in ontology development. International Conference on Collaboration Technologies and Systems (CTS). May 23-27 2011. p423-430.
Allemang, D. & Hendler, J., 2008. Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL [Paperback], Morgan Kaufmann; 1 edition. Available at: http://www.amazon.com/Semantic-Web-Working-Ontologist-Effective/dp/0123735564/ref=sr_1_1?ie=UTF8&qid=1322857045&sr=8-1 [Accessed December 2, 2011].
Anon, 2006. Gloze: XML to RDF and back again. Available at: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.88.8929 [Accessed July 6, 2012].
Auer, S. et al., 2009. Triplify. In Proceedings of the 18th international conference on World wide web - WWW ’09. New York, New York, USA: ACM Press, p. 621. Available at: http://portal.acm.org/citation.cfm?id=1526709.1526793 [Accessed August 10, 2011].
Becker, C. et al., 2011. Extending SMW + with a Linked Data Integration Framework. In International Semantic Web Conference. pp. 2-5. Available at: http://www.wiwiss.fu-berlin.de/en/institute/pwo/bizer/research/publications/BeckerBizerErdmannGreaves-SMW-LDE-Poster-ISWC2010.pdf [Accessed July 6, 2012].
Belleau, F. et al., 2008. Bio2RDF: towards a mashup to build bioinformatics knowledge systems. Journal of biomedical informatics, 41(5), pp.706-16. Available at: http://dx.doi.org/10.1016/j.jbi.2008.03.004 [Accessed June 13, 2011].
Berners-Lee, T., 2007. Is your data 5*?, Available at: http://www.w3.org/DesignIssues/LinkedData.html [Accessed August 11, 2011].
Berners-Lee, Tim, 2006. Linked Data - Design issues. p.7. Available at: http://www.w3.org/DesignIssues/LinkedData.html [Accessed July 16, 2012].
Bhagat, J. et al., 2010. BioCatalogue: a universal catalogue of web services for the life sciences. Nucleic acids research, 38 Suppl(suppl_2), pp.W689-94. Available at: http://nar.oxfordjournals.org/cgi/content/abstract/38/suppl_2/W689 [Accessed July 26, 2010].
Bizer, C., 2010. D2R Map - Database to RDF Mapping Language. Available at: http://www4.wiwiss.fu-berlin.de/bizer/d2rq/ [Accessed August 10, 2011].
Bizer, C. & Gauß, T., 2007. Disco - Hyperdata Browser. Available at: http://www4.wiwiss.fu-berlin.de/bizer/ng4j/disco/ [Accessed August 11, 2011].
Bizer, C., Cyganiak, R. & Heath, T., 2007. How to publish Linked Data on the Web, Available at: http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/ [Accessed August 11, 2011].
Bizer, Christian et al., 2009. DBpedia - A crystallization point for the Web of Data. Web Semantics: Science, Services and Agents on the World Wide Web, 7(3), pp.154-165. Available at: http://dx.doi.org/10.1016/j.websem.2009.07.002 [Accessed July 20, 2011].
Byrne, K., 2008. Having Triplets – Holding Cultural Data as RDF. In M. Larson et al., eds. Proceedings of the ECDL 2008 Workshop on Information Access to Cultural Heritage, Aarhus, Denmark, September 18, 2008. Available at: http://homepages.inf.ed.ac.uk/kbyrne3/docs/iach08kfb.pdf [Accessed July 6, 2012].
CCO, 2011. CC0 Waiver. Available at: http://wiki.creativecommons.org/CC0 [Accessed August 11, 2011].
CKAN, 2011. CKAN - the Data Hub. Available at: http://ckan.net/ [Accessed August 11, 2011].
Clark&Parsia, 2011. Pellet Integrity Constraint Validator. Available at: http://clarkparsia.com/pellet/icv/ [Accessed November 14, 2011].
Courtot, M. et al., 2009. MIREOT: the Minimum Information to Reference an External Ontology Term. Available at: http://precedings.nature.com/documents/3574/version/1 [Accessed July 16, 2012].
Cyganiak, Richard & Villazón-Terrazas, B., 2011. sitemap4rdf – automatic generation of sitemap.xml files for rdf. Available at: http://lab.linkeddata.deri.ie/2010/sitemap4rdf/ [Accessed November 1, 2011].
Date, C.J., 2009. SQL and Relational Theory: How to Write Accurate SQL Code, O’Reilly Media, Inc. Available at: http://books.google.com/books?hl=en&lr=&id=406_pJtiJ6sC&pgis=1 [Accessed March 1, 2011].
Deus H.F. et al., 2012. Translating standards into practice - one Semantic Web API for Gene Expression. J Biomed Inform. Aug;45(4):782-94. Epub 2012 Mar 24. PubMed PMID: 22449719.
Deus, H.F. et al., 2011. S3QL: A distributed domain specific language for controlled semantic integration of life science data. BMC bioinformatics. Available at: http://www.biomedcentral.com/1471-2105/12/285/ [Accessed July 6, 2012].
Deus, H.F. et al., 2010. Provenance of Microarray Experiments for a Better Understanding of Experiment Results. In ISWC 2010 SWPM. Available at: http://people.csail.mit.edu/pcm/tempISWC/workshops/SWPM2010/InvitedPaper_6.pdf [Accessed July 16, 2012].
EFO, 2011. Experimental Factor Ontology. Available at: http://www.ebi.ac.uk/efo/ [Accessed August 11, 2011].
Google, 2011. rdf extension for google refine. Available at: http://lab.linkeddata.deri.ie/2010/grefine-rdf-extension/ [Accessed November 14, 2011].
Hartig, O. & Zhao, Jun, 2010. Publishing and Consuming Provenance Metadata on the Web of Linked Data D. L. McGuinness, J. R. Michaelis, & L. Moreau, eds., Berlin, Heidelberg: Springer Berlin Heidelberg. Available at: http://www.springerlink.com/content/b3k12277v736m582/ [Accessed August 11, 2011].
Heath, Tom & Bizer, Christian, 2011. Linked Data: Evolving the Web into a Global Data Space. 1st ed., Morgan & Claypool. Available at: http://www.amazon.ca/Linked-Data-Evolving-Global-Space/dp/1608454304/ [Accessed July 16, 2012].
Jentzsch, A. et al., 2009. Linking Open Drug Data. Triplification Challenge of the International Conference on Semantic Systems, pp.3-6. Available at: http://www.larkc.eu/wp-content/uploads/2008/01/2009_triplification_challenge_lodd.pdf [Accessed July 16, 2012].
Jonquet, C., Musen, Mark A & Shah, N., 2008. A System for Ontology-Based Annotation of Biomedical Data A. Bairoch, S. Cohen-Boulakia, & C. Froidevaux, eds. Medical Informatics, pp.144-152. Available at: http://www.springerlink.com/index/M88287342LP032L7.pdf [Accessed July 16, 2012].
Jupp, S. et al., 2011. Developing a kidney and urinary pathway knowledge base. Journal of biomedical semantics, 2(Suppl 2), p.S7. Available at: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=3102896&tool=pmcentrez&rendertype=abstract [Accessed July 16, 2012].
Karolchik, D., 2003. The UCSC Genome Browser Database. Nucleic Acids Research, 31(1), pp.51-54. Available at: http://www.nar.oupjournals.org/cgi/doi/10.1093/nar/gkg129 [Accessed July 16, 2012].
Kimball, R. & Caserta, J., 2004. The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning Conforming, and Delivering Data, Wiley. Available at: http://www.amazon.ca/Data-Warehouse-ETL-Toolkit-Techniques/dp/0764567578 [Accessed July 16, 2012].
Kimball, R. & Ross, M., 2002. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling I. John Wiley Sons, ed., Wiley. Available at: http://www.amazon.com/Data-Warehouse-Toolkit-Complete-Dimensional/dp/0471200247 [Accessed July 16, 2012].
Knublauch, H. et al., 2004. The Protégé OWL Plugin: An Open Development Environment for Semantic Web Applications. In S. A. McIlraith, D. Plexousakis, & F. Van Harmelen, eds. ISWC. Springer, pp. 229-243. Available at: http://www.springerlink.com/index/UWYK3RUGFQX583CP.pdf [Accessed July 16, 2012].
Krötzsch, M., Vrandečić, D. & Völkel, M., 2006. Semantic MediaWiki. In I. Cruz et al., eds. The Semantic Web - ISWC 2006. Springer Berlin / Heidelberg, pp. 935-942. Available at: http://dx.doi.org/10.1007/11926078_68 [Accessed July 16, 2012].
LOD, 2011. LOD Browser Switch. Available at: http://browse.semanticweb.org/ [Accessed August 11, 2011].
Lampa, S., 2010. Extension:RDFIO - MediaWiki. Available at: http://www.mediawiki.org/wiki/Extension:RDFIO [Accessed March 1, 2011].
LinkedData, 2011. Linked Data - Connect Distributed Data across the Web. Available at: http://linkeddata.org/ [Accessed August 31, 2011].
Luciano, J.S. et al., 2011. The Translational Medicine Ontology: Driving personalized medicine by bridging the gap from bedside to bench. In Journal of Biomedical Semantics (Bio-Ontologies 2010 Special Issue). pp. 1-4. Available at: http://www.jbiomedsem.com/content/2/S2/S1 [Accessed July 16, 2012].
Maali, F. & Cyganiak, Richard, 2011. Google-refine. Available at: http://code.google.com/p/google-refine/ [Accessed November 14, 2011].
Marshall MS, Boyce RD, Deus H, Zhao J, Willighagen E, Samwald M, Pichler E, Hajagos J, Prud’hommeaux E, and Stephens, S. Emerging practices for mapping life sciences data to RDF - a case series. Journal of Web Semantics. Special Issue: Reasoning with Context in the Semantic Web. Volume 14, July 2012, Pages 2–13. Available at: http://www.sciencedirect.com/science/article/pii/S1570826812000376 [Accessed July 16, 2012]
Murray-Rust, P. et al., 2010. Panton Principles. Available at: http://pantonprinciples.org/ [Accessed August 11, 2011].
NCBO, 2011. NCBO BioPortal. Available at: http://bioportal.bioontology.org/ [Accessed August 10, 2011].
Noy, N.F. et al., 2009. BioPortal: ontologies and integrated data resources at the click of a mouse. Nucleic acids research, 37(Web Server issue), pp.W170-3. Available at: http://nar.oxfordjournals.org/cgi/content/abstract/37/suppl_2/W170 [Accessed July 11, 2011].
OBI, 2011. OBI Ontology. Available at: http://obi-ontology.org/page/Main_Page [Accessed August 11, 2011].
OBO, 2011. The Open Biological and Biomedical Ontologies. Available at: http://www.obofoundry.org/ [Accessed September 2, 2011].
ODC, 2011. ODC Public Domain Dedication and License (PDDL). Available at: http://opendatacommons.org/licenses/pddl/ [Accessed August 11, 2011].
OKF, 2011. Open Knowledge Foundation | Promoting Open Knowledge in a Digital Age. Available at: http://okfn.org/ [Accessed August 11, 2011].
OORP, 2011. Open Ontology Repository Poster. Available at: http://kcap09.stanford.edu/share/posterDemos/164/index.html [Accessed September 1, 2011].
OWL, 2011. The PROV Ontology: Mode and Formal Semantics. Available at: http://www.w3.org/TR/prov-o/ [Accessed March 16, 2012].
PAQ, 2011. PROV-AQ: Provenance Access and Query. Available at: http://www.w3.org/TR/prov-aq [Accessed March 16, 2012].
OntologyEngineeringGroup, 2011. r2o and odemapster. Available at: http://mayor2.dia.fi.upm.es/oeg-upm/index.php/en/downloads/9-r2o-odempaster [Accessed November 14, 2011].
PDM, 2011. Public Domain Mark 1.0. Available at: http://creativecommons.org/publicdomain/mark/1.0/ [Accessed August 11, 2011].
Prud’hommeaux, E., Deus, H. & Marshall, M.S., 2010. Tutorial: Query Federation with SWObjects. In Semantic Web Applications and Tools for Life Sciences 2010. Available at: Available from Nature Precedings http://dx.doi.org/10.1038/npre.2011.5538.1 [Accessed July 16, 2012].
RDF, 2011. RDF Working Group Charter. Available at: http://www.w3.org/2010/09/rdf-wg-charter.html [Accessed August 11, 2011].
SPARQL, 2011. SPARQL Query Language Implementation Report. Available at: http://www.w3.org/2001/sw/DataAccess/impl-report-ql [Accessed August 11, 2011].
SW, 2011. Semantic Web Search Engine. Available at: http://www.swse.org/ [Accessed August 11, 2011].
SWObjects, 2011. SWObjects. Available at: http://www.w3.org/2010/Talks/0218-SWObjects-egp/#(1) [Accessed August 10, 2011].
Sahoo, S.S. et al., 2009. A Survey of Current Approaches for Mapping of Relational Databases to RDF. w3org. Available at: http://www.w3.org/2005/Incubator/rdb2rdf/RDB2RDF_SurveyReport.pdf [Accessed July 16, 2012].
Sauermann, L. & Cyganiak, R., 2011. Cool URIs for the semantic web. Available at: http://www.dfki.uni-kl.de/~sauermann/2007/01/semweburisdraft/uricrisis.pdf [Accessed August 11, 2011].
SharedNames, 2011. Shared Names. Available at: http://sharedname.org/page/Main_Page [Accessed August 11, 2011].
Sindice, 2011. Sindice - The semantic web index. Available at: http://sindice.com/ [Accessed September 1, 2011].
Stoilov, D., 2011. Primer Introduction to OWLIM - OWLIM42 - Ontotext Wiki. Available at: http://owlim.ontotext.com/display/OWLIMv42/Primer+Introduction+to+OWLIM [Accessed December 2, 2011].
Swoogle, 2011. Swoogle Semantic Web Search Engine. Available at: http://swoogle.umbc.edu/ [Accessed August 11, 2011].
Tabulator, 2011. Tabulator: Generic data browser. Available at: http://www.w3.org/2005/ajar/tab [Accessed August 11, 2011].
ODE Browser, 2012. Openlinke ODE Browser: Generic data browser. Available at: http://ode.openlinksw.com/ [Accessed December 3, 2012].
Timrdf, 2011. timrdf/csv2rdf4lod-automation - GitHub. Available at: https://github.com/timrdf/csv2rdf4lod-automation [Accessed November 14, 2011].
Vandenbussche, P.-Y., 2011. CKAN - Public SPARQL Endpoints availability. Available at: http://labs.mondeca.com/sparqlEndpointsStatus/ [Accessed August 11, 2011].
Rudi Verbeeck, Tim Schultz, Laurent Alquier and Susie Stephens, Relational to RDF mapping using D2R for translational research in
neuroscience, Bio-Ontologies Meeting, ISMB 2010 [Online] Available: https://docs.google.com/viewer?a=v&pid=sites&srcid=ZGVmYXVsdGRvbWFpbnxiaW9vbnRvbG9naWVzc2lnMjAxMHxneDoxYmE1ZWQ5ZjExNDc5NzYy [Accessed: April 12, 2012].
Villazón-Terrazas, B. et al., 2011. Methodological Guidelines for Publishing Government Linked Data. In D. Wood, ed. Linking Government Data. Springer. Available at: http://www.springer.com/computer/database+management+%26+information+retrieval/book/978-1-4614-1766-8.
Williams, G.T., 2011. SPARQL 1.1 Service Description, Available at: http://www.w3.org/TR/sparql11-service-description/ [Accessed August 11, 2011].
Z Xiang, C Mungall, A Ruttenberg, Y He. Ontobee: A linked data server and browser for ontology terms. Proceedings of the Second International Conference on Biomedical Ontology. July 28-30, 2011. Buffalo, NY, USA. https://violinet.org/docs/Ontobee_ICBO-2011_Proceeding.pdf
Yeganeh, S.H., Hassanzadeh, Oktie & Miller, R.J., 2011. Linking Semistructured Data on the Web. Interface, (WebDB). Available at: http://www.cs.toronto.edu/~oktie/papers/hhm-webdb2011.pdf [Accessed July 6, 2012]
Zhao, Jun et al., 2009. OpenFlyData: The Way to Go for Biological Data Integration. In Data Integration in the Life Sciences. pp. 47-54. Available at: http://www.springerlink.com/content/jn41378l3426j104 [Accessed July 16, 2012].