
RDFa vs RDFXML
This is a note comparing RDFa and RDF/XML in terms of features, usage, etc. - feel free to comment it or put questions inline :)
RDFa vs. RDF/XML
Index
Some History
RDF, the Semantic Web data model, needs concrete serialisations in order to be exchanged, stored, etc. The original idea was to layer RDF on top of XML beacause people thought that (already available and deployed) XML tools could be reused. Interestingly, the latest version of the Semantic Web stack does not require RDF to be used on top of XML anymore (cf. Fig. 1).
But RDF/XML (application/rdf+xml) is not the only player in town. There exists a bunch of other formats, such as N3 (text/rdf+n3), Turtle (text/rdf+n3), TriX. What have all these serialisation formats in common? Well, all of them are standalone formats, assuming that an RDF graph is serialised into a document that exists on its own. In case of RDF/XML, this document is an XML document. Each of these formats has a Internet Content Type, passed by the server, so the client knows how to parse the data.
Now, the question arises what happens in the context of the real world, where developers use APIs and environments such as PHP? The developer just writes some more PHP scripts to deliver RDF/XML, at different URIs to the HTML data. (If the HTML data is really exactly equivalent to the RDF data, then content-negotiation can be used to deliver them at the same URI, but this should be used with caution, typically only when the HTML and RDF are generated from the same data and contain exactly the same information.)
For an existing site which has pages in (X)HTML, how can they integrate or reference the RDF-based data available if they were to publish it? A number of proposal exists how to 'marry' RDF and HTML (see EmbeddingRDFinHTML or Sean's note).
Some years ago, W3C started to investigate a more 'natural' way of using RDF and (X)HTML together. The result is RDFa, RDF in attributes.
Further reading
RDF serialisations:
- rewerse project, Deliverable I4-D9a: Survey over Existing Query and Transformation Languages (cf. Appendix A)
- M. Hausenblas, W. Slany, D. Ayers. A Performance and Scalability Metric for Virtual RDF Graphs. 3rd Workshop on Scripting for the Semantic Web (SFSW07)
RDFa:
- 5 min tutorial slides (kudos to Fabien Gandon)
- RDFa Primer
- http://rdfa.info
Comparison
In Fig. 2 RDF/XML and RDFa are depcited in terms of layering on top of other technologies:
| RDF/XML |
| URI |
In the following a comparison of RDF/XML and RDFa is given.
| Issue | RDF/XML |
| Status | W3C Recommendation |
| Unicode | yes |
| URIs | yes |
| XML Namespaces | yes |
| QNames | yes |
| Spec builds on CURIEs? | no |
| Datatypes | yes |
| Standalone | yes |
| Reification | yes |
| Named Graphs | currently not, but there are discussions |
Usage
Human vs. Machine
In a Semantic Web application there are really two kinds of users around: human users and a piece of software (aka Semantic Web agent). As the Semantic Web is an extension rather than a replacement of the Web, it is important to distinguish these two users when talking about certain services, interfaces, etc. Note that human users, with the proper user interfaces, can benefit from RDF data as well as HTML docuemnts. RDFa makes a hybrid document, whose interface becomes a hybrid of the hypertext and data interfaces.
URI design and more
David Booth has put together a nice piece on URI Declaration Versus Use. And for sure we have the TAG finding regarding httpRange-14 issue.
Attempting to actually use RDF and (X)HTML representations together, one has to think about who is served (human user or SW agent) and, independently, what is served (e.g. RDF, or XHTML).
The Cool URIs for the Semantic Web Working Draft suggests options how to use RDF/XML and (X)HTML in parallel. Certain implementations exist that use (one of) these designs (cf. DBpedia). However, in the case of RDFa, the Cool URIs WD states:
The solutions described in the following apply to deployment scenarios in which the RDF data and the HTML data is served separately, such as a standalone RDF/XML document along with an HTML document. The metadata can also be embedded in HTML, using technologies such as RDFa [RDFa Primer], microformats and other documents to which the GRDDL [GRDDL] mechanisms can be applied. In those cases the RDF data is extracted from the returned HTML document.
In the case of using RDFa (or more precisely: XHTML+RDFa) one has to rethink URI design issues. Or, put as a question: Does httpRange-14 apply to the RDFa setup equally?
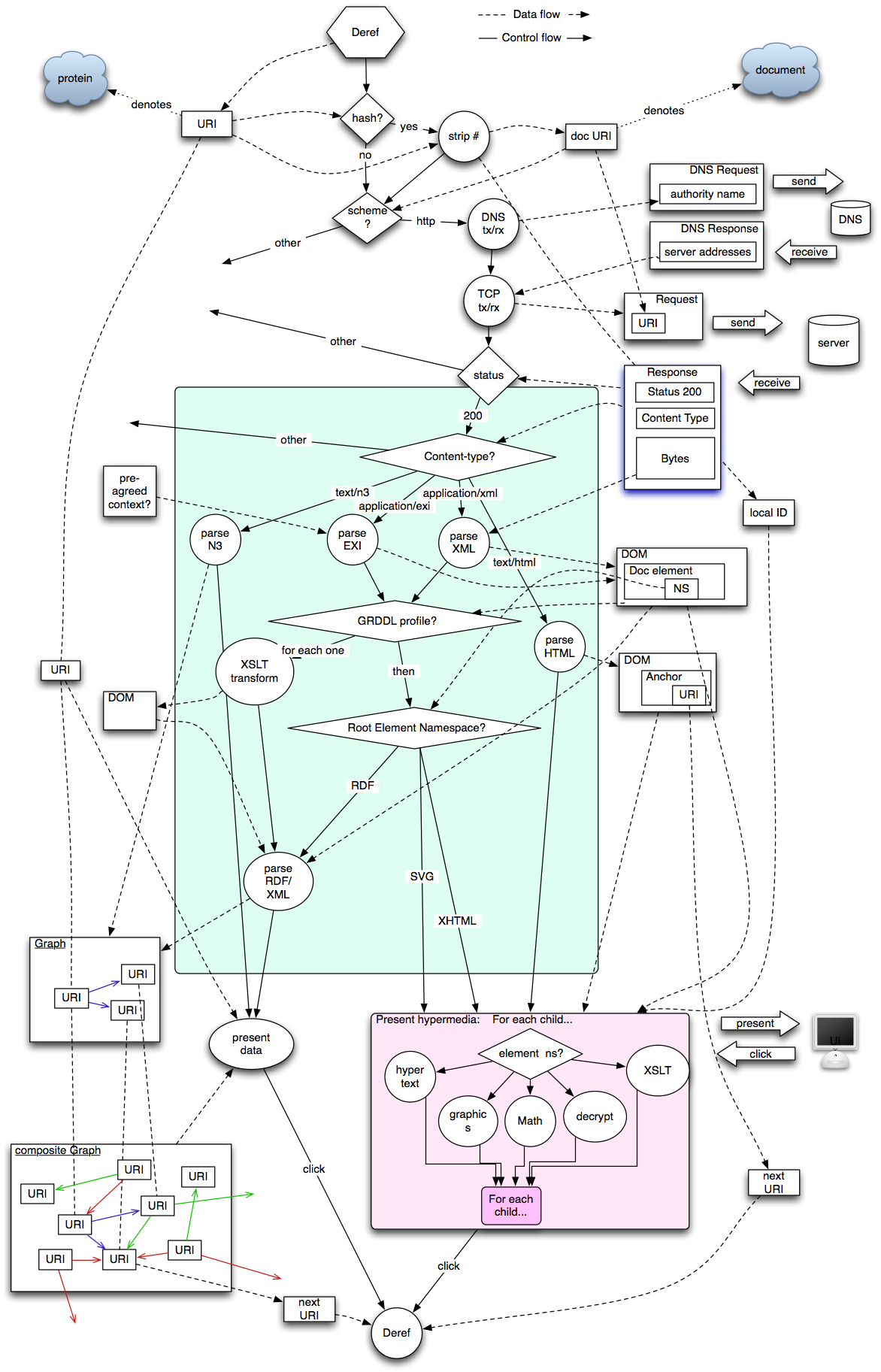
The httpRange-14 finding that HTTP URIs which return 200 identify documents applies in all these cases. The architectural question which RDFa brings up is about fragment identifiers. RDFa files define both conceptual things (People, Calendar events, etc) as well as traditional hypertext anchors. This requires browsers to be able to display either of these. This raises user interface issues, which (as of early 2008) have not been clearly resolved:
- If you represent the data as well as the hypertext, will the data be repeated, confusing the user?
- If you don't represent the data, will a user have access to the full power of data handling?
- There is a security threat if the user does not see (but agrees to) data which is not visible.
- Are there systems whcih currently assume that a localID within a hypertext document will identify an anchor? How will they cope with RDFa?
Further reading
- Levels of Abstraction: Net, Web, Graph
- Visualisation of the processes in the Web architecture
- TAG finding draft regarding The Self-Describing Web
- http://www.w3.org/2006/07/SWD/wiki/RDFa/RDFCoverage
{kind=link}
Discussion
- Mark Birbek on information resources and RDFa
- Discussion on semantic-web@w3.org in 12/2007
Changelog:
- 2009-02-01: Updated status of RDFa, updated named graphs and reification
- 2008-02-19: Replying to TimBL's comments
- 2007-12-23: TimBL comments
- 2007-12-19: init draft of this page by MichaelHausenblas