SWSF Application Scenarios
- This version:
- http://www.w3.org/submissions/2005/SUBM-SWSF-Applications-20050909/
- Latest version:
- http://www.w3.org/submissions/SWSF-Applications/
- Authors:
-
Steve Battle (Hewlett Packard)
Abraham Bernstein (University of Zurich)
Harold Boley (National Research Council of Canada)
Benjamin Grosof (Massachusetts Institute of Technology)
Michael Gruninger (NIST)
Richard Hull (Bell Labs Research, Lucent Technologies)
Michael Kifer (State University of New York at Stony Brook)
David Martin (SRI International)
Sheila McIlraith (University of Toronto)
Deborah McGuinness (Stanford University)
Jianwen Su (University of California, Santa Barbara)
Said Tabet (The RuleML Initiative)
Copyright © 2005 retained by the authors.
All Rights Reserved.
This document is available under the W3C Document License.
See the W3C Intellectual Rights Notices and Disclaimers for additional information.
This document
presents several use cases that illustrate SWSO
-- the Semantic Web Services Ontology, and
SWSL -- the Semantic Web
Services Language.
Status of this document
This document is part of a member submission, offered by
National Institute of Standards and Technology (NIST),
National Research Council of Canada,
SRI International,
Stanford University,
Toshiba Corporation,
and
University of Southampton
on behalf of themselves and the authors.
This is one of four documents
that make up the submission.
These documents define the Semantic Web Services Framework (SWSF).
This submission has been prepared by the Semantic Web Services
Language Committee of the Semantic Web Services Initiative.
The W3C Team Comment discusses this submission
in the context of W3C activities.
Public comment on this document is invited on the mailing list
public-sws-ig@w3.org
(public archive).
Announcements and current information may also be available on the SWSL Committee Web site.
By publishing this document, W3C acknowledges that
National Institute of Standards and Technology (NIST),
National Research Council of Canada,
SRI International,
Stanford University,
Toshiba Corporation,
and
University of Southampton
have made a formal submission to W3C for discussion. Publication of
this document by W3C indicates no endorsement of its content by W3C,
nor that W3C has, is, or will be allocating any resources to the
issues addressed by it. This document is not the product of a
chartered W3C group, but is published as potential input to the W3C
Process. Publication of acknowledged Member Submissions at the W3C
site is one of the benefits of W3C
Membership. Please consult the requirements associated with Member
Submissions of section
3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member
Submissions.
1 Introduction
2
Use Cases Illustrating the Conceptual Model
3
The Amazon E-commerce Service
4
Service Discovery with SWSL-Rules
5
Policy Rules for E-Commerce
6
Using Defaults in Domain-Specific Service Ontologies
7 Glossary
8 References
This document is part of the technical report of the Semantic Web
Services Language (SWSL) Committee of the Semantic Web Services
Initiative (SWSI).
The overall structure of the report is described in the document titled
Semantic Web Services Framework
Overview. The present document discusses a number of use cases that
illustrate the Semantic Web Services Ontology (SWSO), which is defined in
a separate document, and the Semantic Web
Services Language (SWSL), which is also described
separately.
Section 2 presents use cases that
illustrate various aspects of SWSO with emphasis on the
process model. Section 3 considers a particular
use case, the Amazon.com service, and shows how SWSO and SWSL can be
used to describe this
service. Section 4 focuses on
the problem of Web service discovery and shows how services, user goals,
mediators, and the discovery engine itself can be defined in SWSL-Rules,
which is a sublanguage of SWSL. Section 5
presents use cases for policy specification in e-commerce and shows
how these cases can be specified in SWSL-Rules. Finally,
Section 6 uses SWSL-Rules
to illustrate the need for
non-monotonic inheritance and overriding in domain-specific service
ontologies.
We introduce here several examples, which are useful in illustrating
selected aspects of the Process Model portion of the Conceptual Model
underlying the FLOWS Ontology.
Section 2.1
focuses on human-machine interactions, and
describes a hypothetical on-line bookseller.
The example illustrates aspects of
atomic processes, fluents, and messages.
Section 2.2
focuses on machine-machine interaction,
and illustrates
the use of channels, and the possible FLOWS-Core extensions
for Guarded Automata and Meta-Server.
Finally,
Section 2.3,
illustrates the flexibility of the
conceptual model, by showing briefly how it can be applied
to specify services coordination in a telecommunications
context.
This example focuses on a web service Acme_Book_Sales,
that provides support for the external web presence of
the hypothetical Acme book selling business.
We focus primarily on the occurrences of the Acme_Book_Sales service that
interact with end-users (modeled abstractly as service occurrences),
and mention only at a high level some aspects of the interaction
of occurrences of this service with
other services (e.g., to arrange for credit card charges and
shipping).
In the following we describe (i) three of the domain-specific
fluents manipulated by occurrences of Acme_Book_Sales,
(ii) four atomic processes used by Acme_Book_Sales,
(iii) four of the types of message that Acme_Book_Sales can send or receive,
and (iv) finally a typical process flow in
occurrences of Acme_Book_Sales.
Note that the domain-specific fluents described here might
be accessed by services operated by Acme other than
the service Acme_Book_Sales, and perhaps accessed by services operated
by enterprises other than Acme.
(E.g., a shipper might have read or read/write access on
some of these fluents.)
Likewise, the atomic processes used in the
service Acme_Book_Sales might be used in the specification
of other services (supported by Acme or other enterprises).
The description here is intended to illustrate certain
aspects of the process model of the
SWSL conceptual model, and
is not intended to provide a complete specification of the Acme_Book_Sales
service.
(In any event,
recall that SWSL can support both complete and
incomplete specifications of services.)
We focus on three domain-specific fluents:
Book_info[
ISBN => xsd#string,
Title => xsd#string,
Author => xsd#string
].
-
For each book that Acme is selling, this fluent holds a record (i,t,a)
for each author of the book,
where i is the ISBN number, t is the title, and a is the author name.
(For simplicity of exposition, this is not,
in the parlance of relational databases,
in Third Normal Form.)
Note that some books listed in Book_info
may not be in Acme's stock at a given time.
Book_inventory[
ISBN => xsd#string
warehouse_id => xsd#string,
quantity_on_hand => xsd#integer
].
-
We assume that the Acme company operates multiple warehouses,
and that copies of a given book might be available from one or
more of these warehouses.
Book_reservation[
ISBN => xsd#string,
user_id => xsd#string,
warehouse_id => xsd#string
].
-
When a user puts a book in their shopping cart,
this corresponds to a commitment by Acme that it
will actually ship the book if the user commits to the
purchase (and the payment details are successful).
To this end, Acme has to reserve a copy of the book
while the user is deciding whether to commit.
The fluent
Book_reservations is intended
to hold triples of the form (u,i,w), that will indicate that
a copy of the book with ISBN number i is
being held at warehouse w for user u.
We now overview four atomic processes used by Acme_Book_Sales. The
description here is somewhat informal and is intended to provide an
intuitive understanding, not a formal specification.
book_search[
input => book_descriptor[ISBN => xsd#string,
title => xsd#string,
authors => Person,
keywords => xsd#string],
output => book_record[ISBN => xsd#string,
title => xsd#string,
authors => xsd#string],
effect => Formula // focused on output only
].
- This process supports searches against the full catalog of books
sold by the bookseller. The input argument for this may include
precise information such as ISBN, title, author, and/or may include
more open-ended information such as key-words (in the title), partial
author names, etc. This atomic process returns a (possibly empty)
list of books that satisfy the search criteria. There are no
side-effects.
book_reserve[
input => reservation_input[user_id => xsd#integer,
ISBN => xsd#string],
output => reservation_output[warehouse => xsd#string,
expected_ship_date => xsd#date],
effect => Formula
// the effect is supposed to be: if the book is available, then
// decrement quantity of book for this warehouse,
// insert record into the "reserved" relation
// if not, then no effect
].
-
Intuitively, this process corresponds to a user putting a book
into her shopping cart.
In this case, Acme commits that it can in fact ship the book.
So it decrements the quantity of copies available from
one of the warehouses,
and puts a record into the
Book_reservations
fluent.
reservation_cancel[
input => cancellation_result[user_ID => xsd#integer, ISBN => xsd#string],
output => success_flag_type,
effect => Formula
// Intended effect:
// If the book is reserved for this user
// remove appropriate records from "reserved" relation,
// increment quantity of book for appropriate warehouse,
// set success_flag to true;
// if not set success_flag to false;
].
book_shipment[
input => ship_type[user_ID => xsb#integer,
ISBN => xsd#string], // list of ISBNs
output => xsb#integer, // confirmation_#;
effect => Formula
// Intended effect: Assuming no exceptions,
// remove appropriate records from "reserved" relation,
// (possibly, move a copy of book to loading dock);
].
-
These atomic processes deal with "clean up" concerning
reserved books.
reservation_cancel effectively cancels out the
reservation of the book, and
book_shipment records the fact that the book
should really be shipped (and might include physically moving
a copy of the book to a loading dock).
So far we have focused on how occurrences of Acme_Book_Sales
"interacts" with domain-specific fluents.
What about interaction with other services, and with humans
(which are modeled as services)?
Some of the messages that Acme_Book_Sales can send and
receive include the following.
As before, the description of argument types is
for intuitive purposes only.
book_search_request(User_ID: string, search_criteria: search_criteria_type)
-
A user can send a message of this type
to an occurrence of Acme_Book_Sales.
The single argument is an amalgam of whatever search criteria
the user has specified.
In practice we would expect this argument to be assembled
by the user interface code running on the user's web browser and
Acme's web server, based on the inputs of the user into her browser.
book_search_response(ISBN: string, title: string, list_of [author: string])
-
This message can be sent by an occurrence of Acme_Book_Sales
to a user, indicating information about
zero or more books that Acme is selling.
shopping_cart_request(user_ID: string, ISBN: string)
-
This message can be sent by a user to an occurrence of Acme_Book_Sales,
indicating that the user wants the specified book to be
put into her shopping cart.
book_availability_response(ISBN: string, title: string,
list_of [author: string], ship_date: date)
-
This message can be sent by an occurrence of Acme_Book_Sales
to a user, indicating that the indicated book is available,
and can be shipped to the user on ship_date.
Acme_Book_Sales is capable of sending and receiving several
other types of message.
This includes messages
from the user to commit to
a purchase, and to put in credit card information,
and messages back to the user to confirm various operations.
It includes messages between occurrences of Acme_Book_Sales
and banking services, and
between Acme_Book_Sales and shipping services.
Example 2.1(a): Atomic Processes and Internal Process Model.
We now briefly discuss a partial specification of
the permitted process flow of
atomic process occurrences
in interpretations of the theory
for this application domain.
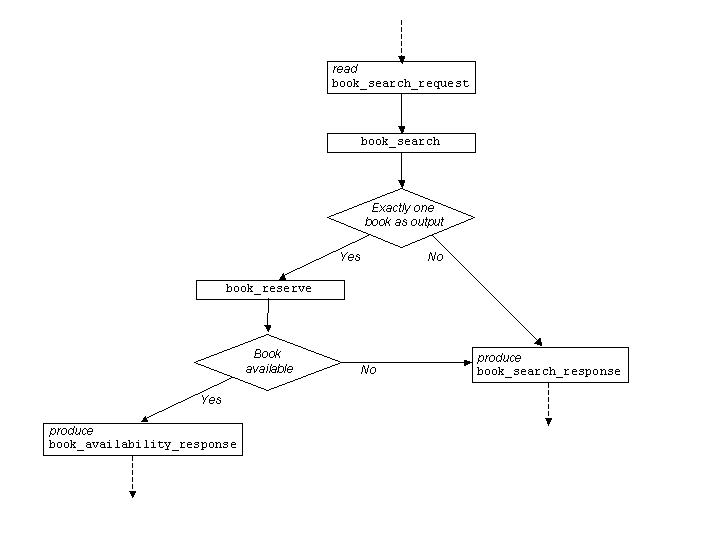
Figure 2.1
illustrates a portion of this process flow,
using a flow-chart paradigm.
In terms of a formal domain theory, this (or something equivalent)
could be specified using the Control Constructs extension of
FLOWS-Core, or by using more primitive PSL-OuterCore
predicates such as
soo_precedes.
A notable aspect of the process flow indicated in
Figure 2.1 is that
there is not necessarily a one-to-one correspondence between messages
being sent by a user and invocations of atomic processes in the
occurrence of Acme_Book_Sales. Specifically, after an Read_Message
occurrence of kind
book_search_request, there will be an occurrence in
Acme_Book_Sales of the atomic process book_search, with the
appropriate input argument. If zero or more than one books is output
from this atomic process occurrence, then there is a Produce_Message
occurrence that creates a message of type
book_search_response.
(Presumably, this is followed by an appropriate
Read_Message occurrence in the end-user.)
However, if exactly one book was returned by the
book_search occurrence,
then in the occurrence of Acme_Book_Sales
there is an occurrence of
book_reserve.
Intuitively, this is a pro-active step by
Acme_Book_Sales, in order to provide
for the user information about availability and
possible shipping date of this book.
If the book is available, then in Acme_Book_Sales
there is a Produce_Message occurrence that
produces a message of type
book_availability_response. (If the book is not available,
then in Acme_Book_Sales there would be a Produce_Message occurrence that
creates a message of type
book_search_response,
or perhaps of a different type, that includes
the fact that the book is currently unavailable.)
(We note that if the end-user has a Produce_Message occurrence
that creates a message of type
book_search_request then the response message may have one
of two kinds. We assume that the Acme web server and the user's web
browser software will present these to the user in an appropriate
manner.)
It is possible, using the knowledge pre-conditions and
conditional effects portion of the FLOWS-Core ontology,
to precisely characterize the flow of information
between atomic process occurrences in an occurrence
of the Acme_Book_Sales service.
One application of this capability would be to
support a form of de-bugging, in which one could verify that
a domain theory
for a service such as Acme_Book_Sales provides for
the flow of information needed to support a desired objective.
Another application of this capability is presented in the
next example.
Example 2.1(b): Inferring Message Production and Reads
We now consider a variation, in which the domain theory T
for Acme_Book_Sales includes two parts:
-
T1:
An explicit description of the domain-specific atomic
processes that Acme_Book_Sales can perform along with
constraints on their sequencing, relationship to domain-specific fluents, etc.
-
T2:
A family of generic constraints that state properties such as
that if an atomic process (e.g.,
book_search)
requires a certain form of input (e.g., ISBN# and/or
book title and/or ...),
and there is an occurrence of that process, then a message
holding the required information in its payload
must have been produced (e.g., the the user) and read by
some Read_Message occurrence in the occurrence of Acme_Book_Sales.
Here, the family T2 of constraints might be used
in a variety different contexts involving services
that embody many different
variations of Acme_Book_Sales.
Imagine now that we want to study the possible occurrences
satisfying the theory T1 union T2,
in which a user's goal is to buy a book with a given
ISBN#.
Suppose further that o is an occurrence of the overall
system in which the user's goal is achieved.
From the constraints in T1 one can infer properties of
o concerning the actual ordering of the domain-specific
atomic process occurrences, the input and output
values associated to those occurrences, and the values of the domain-specific
fluents.
Furthermore,
one can use T2, along with axioms from the FLOWS-Core
ontology, to infer that certain messages must have been produced
and read in o, and infer
some of the characteristics of the payloads of those messages.
Thus, assuming that
an appropriate family T2 of constraints is specified,
one can specify the full behavior of a web service
by specifying only the domain-specific atomic processes
involved that service.
In particular,
the message-handling atomic processes of the service
can be inferred, and do not have to be specified explicitly.
We now describe the Store-Warehouse-Bank example,
which
is based loosely on an example in
[Bultan03]
(see also [Hull03]).
As suggested in
Figure 2.2
below,
we assume the existence of three entities, namely
a (bricks-and-mortar) Store,
a Warehouse, and a Bank.
(Unlike the example of
Subsection 2.1,
the store here is assumed to maintain a physical inventory on premises.)
For each entity we focus on one of the several web services
that it might perform; these have the following names:
Store_inventory_maintenance
-
A "back-office" service, that attempts to ensure that
the for each item sold by the store,
the available stock at the store
remains above some threshold.
Warehouse_order_fulfillment
-
This service running at the Warehouse
responds to orders from the Store.
As part of its operation it charges
an account of the Store held at the Bank.
Bank_account_maintenance
-
This service running at the Warehouse
responds to orders from the Store.
As part of its operation it charges
an account of the Store held at the Bank.
In the following we describe, for the three services,
(a) the domain-specific fluents they can access and manipulate,
(b) the atomic domain-specific atomic processes in them, and
(c) the kinds of messages that they can create, read, and
destroy.
(FLOWS-Core does not consider parameter typing,
but we include types here as an intuitive convenience.
The use of structured values in message parameters,
and atomic process outputs, can in principle
be provided in extensions
of FLOWS-Core, such as
Relation-valued Parameters and XML-valued Parameters;
see
Section 3.7.2.)
For this example, we assume the following service-specific
fluents and relations:
Bank_accounts(account_id:int,
owner_id:int,
balance:int)- This fluent holds data on bank accounts.
It is accessed and maintained exclusively by some services associated
with the Bank (including
Bank_account_maintenance).
Store_inventory(item_id:int,
quantity:int)- This fluent holds data on inventory held by the store.
It is accessed and maintained exclusively by some services associated
with the Store (including
Store_inventory_maintenance).
Warehouse_inventory(item_id:int,
quantity:int)- This fluent holds data on inventory held by the warehouse. It is
accessed and maintained exclusively by some services associated with
the Warehouse (including
Warehouse_order_fulfillment.
(For simplicity, we assume that the Store and Warehouse use the same
numbering system.)
Goods_in_transit(shipment_id:int, shipping_date:date,
expected_delivery_date:date,
transport_content_list_id:int)- This fluent holds data on goods that are being shipped (from the
Warehouse to the Store). For this example, we assume that it can be
viewed by some services associated with the Warehouse and the Store.
(In practice, this fluent might be maintained by yet another service,
e.g., operated by an entity Shipper. In that case, services
associated with the Store and Warehouse might "read" information
in
Goods_in_transit by exchanging messages with a
service operated by Shipper.)
Transport_content_lists(transport_content_list_id:int,
item_id:int, quantity:int)- This relation holds the contents of shipments. (The approach to
modeling taken by this fluent is suggestive of how the extension
Relation-Valued Parameters on FLOWS-Core might be constructed.) It
can be accessed by the same services that can access
Good_in_transit.
Wholesale_order_content_lists(wholesale_order_id:int,
item_id:int, quantity:int)- Similar to
Transport_content_lists, this relation
holds the contents of orders (made by the Store against the
Warehouse). This fluent can be read by some services associated with
the Store and the Warehouse. (The reader may wonder why this is not
a fluent. The answer is that the association
between wholesale_order_id's and
the item_id,quantity pairs need not vary
over time -- it can be viewed as fixed for the duration of the
execution of the overall system being modeled. In particular, a
given wholesale_order_id will be used in exactly one
message payload, and so there is no need to override
the item_id,quantity pairs associated to
it.)
At least the following kinds of domain-specific
atomic processes can be
performed by the various services.
Create_account(owner_id:int,
account_id:int,
initial_balance:int)Modify_account_balance(account_id:int,
amount:int)- These have the expected semantics, and can be performed by
occurrences of
Bank_account_maintenance
(and perhaps other services associated with the Bank).
Transfer_funds(source_account_id:int,
target_bank_id:int,
target_account_id:int,
amount)-
This atomic activity is performed by occurrences of
Bank_account_maintenance
(and perhaps other services associated with the Bank).
The source account must be maintained by the Bank service
(the target might be another bank), and the source account
must have enough funds to cover the transfer.
Send_shipment_from_warehouse(shipment_id:int,
transport_content_list_id:int,
ship_date:date)-
This atomic activity is performed by occurrences
of the
Warehouse_order_fulfillment service.
It corresponds intuitively to the situation where
a physical shipment is created
by the warehouse (for the store).
The primary pre-condition is that there is enough inventory
in Warehouse_inventory;
the conditional effect is to update
Warehouse_inventory,
Goods_in_transit and Transport_contents_lists
appropriately.
In practice, occurrences of this atomic activity will occur
after a message is received from the Store, requesting
a shipment of goods.
Receive_shipment_to_store(shipment_id:int,
transport_content_list_id:int,
receive_date:date)-
This atomic activity is performed by occurrences
of the
Store_inventory_maintenance service.
It corresponds intuitively to the situation where
a physical shipment is received
by the store (from the warehouse).
One pre-condition is that there is a record in Goods_in_transit
with this shipment_id.
(Additional pre-conditions might be based on dates.)
The primary conditional effect is that the Store_inventory and
Goods_in_transit are updated appropriately.
We mention two additional atomic domain-specific activities
that are associated with the Store and Bank, respectively,
but which do not arise in the services
Store_inventory_maintenance
or Warehouse_order_fulfillment.
Sell_to_buyer(buyer_id:int,
retail_order_id:int,
price:int)-
This atomic activity
corresponds intuitively to the situation where
an individual makes a purchase at the store.
As with orders against the Warehouse,
an additional fluent
Retail_order_content_lists(retail_order_id:int,
item_id:int,
quantity:int)
can be maintained to hold the list of goods
involved in a retail order.
The pre-condition on this atomic activity
is that there is sufficient inventory at the Store,
and the conditional effect is that the
Store_inventory
is updated appropriately.
Receive_shipment_to_warehouse(shipment_id:int,
transport_content_list_id:int,
ship_date:date)-
This atomic activity
corresponds intuitively to the situation where
a physical shipment is received
by the warehouse (from a service not discussed in the example).
The conditional effect is to update
Warehouse_inventory
appropriately.
Finally, we turn to the kinds of messages that the
three services can exchange.
request_account_creation(store_id:int;
account_amount:int)- Intuitively, this message
requests establishment of an account by the Bank
for the Store in the given amount.
acknowledge_account(account_id:int,
account_balance:int)-
Intuitively, this message
acknowledges the establishment of an account by the Bank
for the Store, and provides the (newly created) account_id,
along with current balance.
account_balance_inquiry(store_id:int;
account_id:int)-
Intuitively, this message
requests the current balance of a bank account.
account_balance_report(account_id:int,
account_balance:int)-
Intuitively, this message
gives the current balance in an account.
place_order(order_id:int,
store_id:int,
wholesale_order_id:int,
bank_account_id:int,
stop_attempt_date:date)-
Intuitively, this message
places an order by the Store against the Warehouse.
It will fail if there is not sufficient inventory in
the Warehouse to fill the order.
In that case, the Store wants the Warehouse to
keep trying to fill the order until
stop_attempt_date.
(The list of things ordered is found in the fluent
Wholesale_order_contents_lists, associated with the value of
wholesale_order_id; see
Example 2.2(a)
below.)
fulfill_order_commitment(order_id:int;
shipment_id:int)-
Intuitively, this message
indicates that an order against the Warehouse will be filled,
and provides the shipment_id.
(Further information on the shipment can be obtained
from the fluents
Goods_in_transit and
Transport_contents_lists.)
reject_order(order_id:int)-
Intuitively, this message
indicates that an order against the Warehouse cannot be filled.
bill_for_goods(account_id:int;
order_id:int,
bill_amount:int,
target_bank_id:int,
target_account_id:int)-
Intuitively, this message
indicates that the Warehouse is sending a bill to
the Bank for payment from the specified account.
Here the value of
target_account_id is
intended to be a bank account of the Warehouse;
it might be maintained by the Bank highlighted in this
example or by some other bank (as indicated by the
value of target_bank_id).
payment_for_goods(account_id:int;
order_id:int,
payment_amount:int
target_account_id:int)-
Intuitively, this message
indicates that the Bank is making a payment of
the specified amount
to the Warehouse.
Example 2.2(a): Relation-valued parameters.
Using the above we can illustrate concretely
the approach described in
Subsection 3.7.2
for supporting in FLOWS-Core
parameters having the form of relations
(rather than having form essentially equivalent to
single objects or scalars).
Consider the message type place_order,
whose third argument is wholesale_order_id.
Speaking intuitively, to understand the information
conveyed by the third argument, one must
look at the relation
Wholesale_order_content_lists(wholesale_order_id,
item_id, quantity).
In particular,
a given value W for wholesale_order_id
will be associated by
Wholesale_order_content_lists
with a set of item_id,quantity
pairs; these will correspond to the set of items
(with quantities) that the Store is ordering.
In a similar manner, the output parameter
transport_content_list_id
of atomic process
Send_shipment_from_warehouse
identifies a
set of item-quantity pairs,
according to the relation
Transport_content_lists.
Example 2.2(b): Guarded Automata.
We now consider one approach to
formally specifying a representative process flow for the
activity associated with service
Warehouse_order_fulfillment.
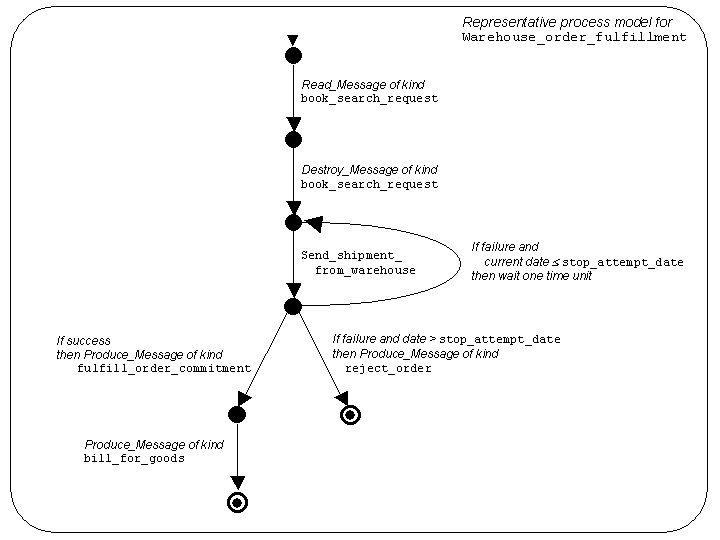
This is illustrated in
Figure 2.2,
which shows informally a Guarded Automaton
that specifies a possible behavior.
This follows the spirit of the potential
PSL extension of FLOWS-Core described in
Subsection 3.7.6.
Intuitively,
a typical flow of activity for (occurrences of) this service
could be as follows:
- At the beginning, there would be a Read_Message atomic process
occurrence of kind
place_order, followed by a
Destroy_Message occurrence (which destroys the message just read).
- An occurrence of atomic process
Send_shipment_from_warehouse is next. Note that the
automaton state reached after this occurrence has three out-edges.
These are guarded by conditions, which in this case are disjoint. (In
general, the conditions of edges from a given state of a guarded
automaton may be overlapping, which models a form of non-determinism.)
-
If this atomic process occurrence fails
(e.g., because the warehouse does not have sufficient inventory)
then the occurrence of
Warehouse_order_fulfillment
will include additional occurrences
of atomic process
Send_shipment_from_warehouse,
if the current time precedes the
stop_attempt_date specified as an argument of
the
place_order message that was initially read.
-
If there is a successful occurrence of
Send_shipment_from_warehouse,
then
there is a Produce_Message occurrence
that creates a message of type
fulfill_order_commitment (intended for the Store),
and there is a Produce_Message occurrence that
creates a message of type
bill_for_goods (intended for the Bank).
-
If there is no successful occurrence of
Send_shipment_from_warehouse, then
there is a Produce_Message occurrence that
creates a message of type
reject_order.
Can a single occurrence of Warehouse_order_fulfillment
accommodate many orders, or in other words,
can it
include many occurrences of the Read_Message
atomic process of kind
book_search_request?
As specified in
Figure 2.2,
this is not possible;
rather, a new occurrence of the service
Warehouse_order_fulfillment
will be needed for each message of
type place_order coming from the Store.
An alternative design for
Warehouse_order_fulfillment
would be to add transitions from the two
final states shown in
Figure 2.2,
which point back to the start state.
This would enable a form of sequential handling of
order requests.
A problem with this design is that it may take
a long period of time to process a single order
(in the case where there is looping
on attempts to have successful execution of
Send_shipment_from_warehouse).
The next example describes how the use of a
meta-service can enable a better design.
Example 2.2(c): Meta-Service
In
Subsection 3.7.1 above
a potential extension for FLOWS-Core is described, in
which "Servers" are used to support the orderly
creation of occurrences of a given service.
We illustrate that notion here, in the context
of the Store-Warehouse-Bank example.
In particular, we assume now that are Formal Servers
Store_server,
Warehouse_server,
and
Bank_server
associated with the Store, Warehouse, and Bank.
We assume that
server_service(Warehouse_server, Warehouse_order_fulfillment)
holds.
The fluent server_service
might also associate other services with Warehouse_server,
e.g., for making orders against manufacturing enterprises,
for managing its own bank account, etc.
Suppose now that
the service Warehouse_order_fulfillment has been
specified so that an occurrence of this service is focused
on fulfilling a single order placed by the Store (or other entities),
basically as in
Figure 2.2.
If we use Warehouse_server,
then the messages of type place_order
will be read and destroyed by Warehouse_server.
When such a message is read, then an occurrence of
service Warehouse_order_fulfillment will come
into existence.
It would be typical for this new occurrence
to start with a Read_Message occurrence,
which reads a message produced by Warehouse_server
(which might be essentially a copied version of the
place_order message.)
The new occurrence of Warehouse_order_fulfillment
could then operate as specified
in
Figure 2.2.
Example 2.2(d): Static and Dynamic Channels.
We now consider how channels might be used in the Store-Warehouse-Bank
example.
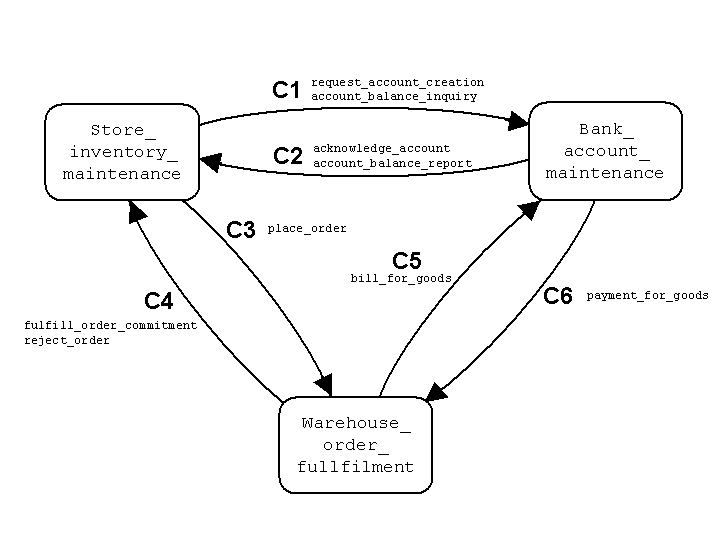
Figure 2.3,
illustrates how six pre-defined channels might
be established between the three services
(see
Subsection 3.1.5).
The figure also shows how the various message types
are assigned to the channels.
In a domain theory over FLOWS-Core, this would be achieved by
asserting constraints such as
channel_source(C5, Warehouse_order_fulfillment),
channel_target(C5, Bank_account_maintenance),
and
channel_mtype(C5, bill_for_goods).
Suppose that
constraints of this sort are specified in a domain theory,
and also that a constraint is specified stating
that all messages must be placed on a channel.
Then specification of service behavior can be simplified.
To illustrate, consider a Produce_Message atomic process
that is a subactivity of Warehouse_order_fulfillment,
and that creates messages of type bill_for_goods.
For any occurrence of this atomic process,
the message created will necessarily be placed on
channel C5.
Furthermore, only occurrences of the service
Bank_account_maintenance will be able
to read this message.
Suppose now that new Warehouses can be added to the
overall system at arbitrary times.
For example, suppose that a new service
Alternative_warehouse_order_fulfillment
becomes available at some time t.
It might be natural in this case to create new
channels C7 and C8, analogous to
C3 and C4, but connecting
Store_inventory_maintenance to
Alternative_warehouse_order_fulfillment
rather than to Warehouse_order_fulfillment.
After this, occurrences of Store_inventory_maintenance
could make orders against either warehouse.
A different approach to using the new warehouse service
Alternative_warehouse_order_fulfillment
would be to modify channel C3 by adding
Alternative_warehouse_order_fulfillment
as a new target, and
to modify channel C4 by adding
Alternative_warehouse_order_fulfillment
as a new source.
In an associated application domain theory,
the destination of place_order messages
might be non-deterministic, or might be determined
by properties of the message payload and/or relevant
fluents (e.g., the inventory at the two warehouses).
This brief example is intended to illustrate the flexibility of
the FLOWS-Core ontology.
Specifically, we illustrate how the framework can be applied in the
context of services coordination for telecommunications, a discipline
which has characteristics somewhat different than traditional
e-commerce oriented, transaction-based
web services.
A basic building block in the deployment of telecommunications
services is the notion of "session"
(e.g., in which several people are in communication, possibly
by multiple media),
and a basic concern in telecommunications is dealing with
asynchronous events (such as wireless connections dropping or
pre-pay accounts running out) that might occur at essentially
any time.
The IETF Session Initiation Protocol (SIP) provides an extensible family
of standardized protocols for initiating and maintaining
communication sessions; this operates at a fairly low
level in the network, tends to focus on a single media at
a time, and addresses a variety of details concerning
both signaling and real-time packet streams, the selection of
codecs, etc.
The 3GPP IP Multimedia Subsystem (IMS) reference architecture
provides an architectural framework and a broad family of
protocols extending core SIP, with a focus on enabling
rich, flexible, and scalable communication services.
We focus here on the use of the FLOWS-Core ontology for describing
session management and orchestration
at an even higher level, which can be realized
on top of the SIP and IMS layers.
To illustrate, we describe a simple environment
which includes 3 core services, namely,
audio_bridge,
video_server,
teleconf_manager;
and includes in essence a service corresponding
to each kind of end-user device, say,
device_1, ..., device_n.
(E.g., perhaps we could have a service device_i
for each style of cell phone currently available.)
The audio_bridge would support messages
of the sort "initiate_audio_bridge" (in-going),
"audio_bridge_initiated(bridge_id:)" (out-going),
"add_end_point(bridge_id, end_point_id)" (in-going),
"drop_end_point(bridge_id, end_point_id)" (in-going),
and "cancel_audio_bridge(bridge_id)" (in-going).
Atomic processes internal to the audio_bridge
would include things like "add_to_bridge(bridge_id, end_point_id)",
which would have the real-world effect of establishing a
real-time packet (RTP) stream between the physical bridge
server and the physical end-point.
To represent this real-world situation
a domain-specific fluent
active_audio_sessions(bridge_id, end_point_id),
can be used,
where a pair (b, e) in this fluent would indicate that
end-point e is currently connected to bridge b.
Note that a failure in the network could lead to breaking
the RTP stream, and in turn the removal of pairs from
the fluent, at essentially any (non-deterministic) time during processing.
The video_server would support similar messages
for enabling one or more end-points to connect to the server,
support atomic processes for establishing RTP streams to end-points,
and rely on a fluent
active_video_sessions(session_id, end_point_id)
analogous to active_audio_sessions.
In addition, for a given video session s, there will be
the state of the video server, which is whether it is currently
streaming a video clip, or whether an end-user has requested
fast-forward, fast-reverse, or scene-based look-up request.
Thus, the video_server can support incoming messages
of the sort "play_video(session_id, video_id)",
"fast_forward(session_id)", "fast_reverse(session_id)",
"indexed_scene_selection(session_id,index)".
Additional atomic processes in video_server
would include capabilities for
manipulating the content of those
streams.
A corresponding domain-specific fluent
video_session_status(session_id, current_video_id, play_back_state,
video_location) is used to track the status of each
video session.
(PSL is based on discrete time, so this fluent is assumed
to work with discrete time as well.)
The conference_manager can serve as a single point
of access, so that end-points can enter into multi-media multi-party
teleconferences, and take advantage of additional features not
directly available from the audio_bridge and
video_server services.
This might include mute capabilities, the establishment of
"whisper" sessions (e.g., in which a subset of the teleconference
participants temporarily drop out of the primary audio session and
create a separate, private audio session just for themselves),
the possibility that only a subset of the participants are
watching the video, an awareness of who is speaking at a given
moment (so that it can be delivered through a web portal to
end-users),
etc.
The conference_manager might also take care of
billing considerations, using messages to and from a billing
server.
In practice, the conference_manager will need
to maintain the state of all of the conferences it is managing.
One natural way to represent this would be using one
or more domain-specific fluents, which are accessible only
by occurrences of conference_manager.
We note that the process model used inside the
conference_manager might be based
on explicit support for sessions and subsessions,
rather than being based on flowchart-based constructs
as found in
[BPEL 1.1]
or
[OWL-S 1.1].
In particular, it would be natural for the internal process model
to support in essence spawning of an unbounded
number of sub-processes (sub-activity occurrences),
where each one corresponds to the
addition of one more participant into a teleconference.
This is reminiscent of the ability of many process algebras
to support process spawning, but is not supported in BPEL 1.1.
(Such unbounded spawning is supported in BPML
[BPML].)
Furthermore, it is important that the internal
model for conference_manager be able
to accommodate specifications for what should happen
if asynchronous events of various types should arise
at essentially any time.
There is evidence that it is cumbersome
to specify the treatment of such asynchronous events in
BPEL, because the BPEL constructs related to "waiting" for
asynchronous events are generally tied to scopes.
In a telecom context, the natural treatments for
several kinds of asynchronous events
cut across the scoping that is convenient to establish
in a BPEL specification.
In any case, the needed internals of
conference_manager
can be modeled accurately using
FLOWS-Core.
Finally, there are services associated with the end-points.
These will include the capability for sending messages
to the conference_manager to request a teleconference
and perhaps to request information about an ongoing teleconference (e.g.,
who is speaking now?).
Atomic processes would include the ability to start receiving or
sending an RTP stream, the initiation or
cancellation of presentation/display of audio/video
output to the end-user, and maintenance of information in connection
with the RTP streams.
The
Amazon e-commerce service
(ECS)exposes a range of capabilities including the full Amazon product catalogue.
A
freely downloadable development kit enables developers to create
value-added web-sites and services. In addition to exposing product
information through comprehensive search capabilities, Amazon offer remote
shopping cart resources that can be managed online and submitted for
check-out processing.
We use the Amazon scenario to explore the benefits that semantic
modeling of web-services can provide. We focus on the requirements
for advertising & matchmaking; contracting & negotiation; process
modeling & enactment, and express these in terms of a concrete and
straightforward challenge for semantic modeling: to assist the customer
in buying a copy of "The Description Logic Handbook" at the cheapest
price.
The terminology of the scenario is drawn from the
Web Services
Architecture document (plus extensions from [Preist04]).
Advertising and Matchmaking
We don't assume from the outset that the customer will buy the book from
Amazon. They may in fact consult many different book vendors and select
the cheapest offer. We are interested in how the customer finds the Amazon
service, and how detailed the
service description needs to be. Let us be
clear, we are not at this stage trying to describe the operational
web-service interface for which one may continue to use WSDL. Rather we aim
to describe, and advertise, the service in terms of its value proposition.
Advertising is therefore concerned with the description of this service offer and
its flip-side the service requirement. It is unreasonable to expect Amazon to
advertise their service in terms of each and every product available; they
may instead publish a generalized service offer. For example, Amazon
divide their product range into a number of offerings including Books,
Music, DVDs, etc. The service offer may simply describe Amazon as a book
vendor, assuming we have a readily available domain ontology that declares
the concept of 'Books' together with a suitable 'offering' relationship.
Another resource we have available to describe the type of service offered
by Amazon is the MIT Process handbook that classifies the
customer interaction with
Amazon.com as an
example of the 'Sell via electronic store
with posted prices' business
process.
The service offer is published in some form so that the Amazon service can
be discovered either directly by the customer, or by using some
third-party discovery service. The service requirements mirror the service
offer, though we will assume the request is more general in the way it
classifies the service but is more specific in the product detail. The
requirements will define only a service that will 'Sell' a Book with the name
'The Description Logic Handbook'. To 'Sell' is more generic
than to 'Sell via electronic store...', however the class of Books with this
specific product name is more specific than Books in general. Therefore,
even in this simple example there is no strict taxonomical relationship
between the service offer and requirements.
The function of matchmaking is to identify the relationship (if any)
between the service offer and the service request. We are primarily
interested in matches in the intersection of the service offer and
request. An additional conundrum appears when we consider the service
offer, described above, in relation to other service offers. For example,
consider an alternative offer that describes Amazon as a Music vendor. If Music
is not explicitly disjoint from Books then there are also solutions in the
intersection where Music is deemed synonymous with Books. What is the
logical justification for ranking the Books offer over the Music offer? SWSL rules may be used to define this matchmaking relationship; the
relationship between matching service offers and requirements. These rules
may be interpreted by an agent to perform service discovery. Furthermore,
the non-monotonic features of SWSL rules enable us to select the best
matches available - selecting Amazon Books over Amazon Music.
Contracting and Negotiation
The abstract nature of the service offer means that we can't
immediately see if the required book is actually for sale and at what
price. The requester must enter into direct negotiation with the service
provider agent
to fill in the gaps - to come up with the service contract. The
contract represents an
agreement between the customer and the service provider, defining
exactly the service (instance) to be provided. The contract must be
specific about the required product, for the title may not be sufficient:
for books the Amazon Standard Item Number (ASIN) provides a unique product
code equivalent to the book's ISBN.
As with service descriptions and matchmaking, the service contract
defines the content of a negotiation process. With Amazon ECS,
negotiation involves a catalogue search that returns product info
including price and availability. Only at this point do we have the raw
material for a service contract - a tangible offer. To flesh-out and and
shake-hands on the contract, the agent adds the book to the cart and
proceeds to the checkout. We assume the final go-ahead to make the
purchase is referred back to the customer. This style of negotiation
follows a very simple take-it-or-leave-it pattern, but
requires a technically non-trivial choreography that differs between services. For this reason, we require a method of
process modeling so that our agent can negotiate on the customer's behalf.
Process Modeling and Enactment
A key feature of the
Service
Oriented Architecture is its characterization of the
tasks and
actions concomitant
with the negotiation and delivery of the service. Tasks are modeled as
processes, which break down by way of composite processes into more
primitive atomic processes that represent these basic actions.
Additionally, every process is modeled in terms of its Inputs, Outputs,
Preconditions and Effects (IOPEs) which provide an epistemic account of
the impact of these actions on the knowledge-base of the agent. Through
process modeling we aim to describe the overall negotiation task which
involves actions that relate to catalogue search; remote cart management;
and checkout processing (there are also tasks
that pertain to service delivery, such as order tracking, that are not
covered in the immediate scenario). The SWSL process model expresses declarative processes constraints rather
than directly executable programs, providing additional flexibility to
agents that may use them to govern, rather than determine, their behaviour. The process model is further underpinned by a theory of the
semantics of these
tasks which captures the meaning and purpose, over and above the
mechanics, of the interaction.
For brevity we only model a subset of the Amazon ECS capabilities
required to describe the book-buying scenario. One of the basic operations available to the customer agent is to
search the product catalogue for the desired item. One of the actions
available to the requester agent is to request an
ItemSearch. This atomic process is defined below. The
search index defines the Amazon store to be searched which for the
scenario will be 'Books'. The 'title' of the book is a string as defined
above which represents all or part of the required product name. The
'items' parameter represents the search output that will include
potentially more than one matching item with pricing and availability
details. The example is described using the presentation syntax which is
a convenience notation that translates into
SWSL-FOL axioms.
aws#ItemSearch(?searchIndex,?title,?items) {
Atomic
input aws#SubscriptionId xs#string
input aws#Operation xs#string 'ItemSearch'
input aws#SearchIndex xs#string ?searchIndex
input aws#Title xs#string ?title
input aws#ResponseGroup xs#string 'Offers'
output aws#Items aws#ItemsOffered ?items
}
These examples are supported by the creation of a domain ontology that
defines the structured objects that appear in the scenario, specifically
definitions of 'ItemsOffered', using SWSL. 'ItemsOffered' is simply a
collection of 'ItemOffered' (a 'Item') each of which may have a number of
actual offers. The only property that is necessary
for an item is the ASIN. This is subclassed in ItemSearch to include
offers detailing pricing and availability information. It is also
subclassed in CartCreate to include the required quantity for each item.
prefix aws = _"http://webservices.amazon.com#".
prefix xs = _"http://www.w3.org/2001/XMLSchema#".
aws#Items [ aws#item => aws#Item ].
aws#Item [ aws#ASIN => xs#string ].
aws#ItemsOffered [ aws#item => aws#ItemOffered ] :: aws#Items.
aws#ItemOffered [ aws#offers => aws#Offers ] :: aws#Item.
aws#Offers [ aws#offer => aws#Offer ].
aws#Offer [
aws#price => aws#Price,
aws#availability => xs#string
].
aws#Price [
aws#amount => xs#positiveInteger,
aws#currencyCode => xs#string
].
The advantage of using a domain ontology is that we can work with the data indepedently
of any particular message syntax. For example, it may allow us to compare
the catalogue content with that of other online stores. We also have a
level of abstraction that is resilient to minor version changes in the
interface specification (unless there is a semantic difference).
The service grounding should identify the appropriate domain ontology and
provide enough information for a client to lift message content into this
abstract ontology.
Amazon web-services are interesting in this respect because they provide
two alternative modes of service invocation with equivalent semantics. A
Service Oriented Model utilizing SOAP over HTTP is supported, together
with a REST-compliant Resource Oriented Model.
In the last example, nothing really changes other than the
agent's knowledge of the product catalogue. Contrast this with the effect of adding the book to the cart.
Amazon provides a 'remote shopping cart' resource that is managed by the
Amazon server. Operations on the cart allow an agent to add items to a new
or existing cart; to clear and modify a cart; and to view the current
contents of a cart. The
real-world effect is the state-change of a remote shopping cart
(a new cart resource is created). Any stateful resource is
described by a fluent that reflects the way it changes in response to events.
Effects encode the changes that can be directly attributed to an
action. Preconditions describe the state of the world (i.e. not
just the knowledge of our agent) that must pertain prior to performing an
action.
We look first at adding an item to a new shopping cart with
CartCreate. We can add more than one item at a time so
the input is again a collection of items. The response includes a URL from which the contents of the cart may be
purchased. The existence of this new shopping cart is a statement of fact
about the world so this is expressed as an effect; an assertion of the
existence of the new cart with a specific cart identifier.
aws#CartCreate(?items,?url) {
Atomic
input aws#SubscriptionId xs#string
input aws#Operation xs#string 'CartCreate'
input aws#Items aws#ItemsRequested ?items
output aws#CartId xs#string ?cart
output aws#purchaseURL xs#anyURI ?url
effect aws#cart(?cart)
}
This example require additional domain classes that define 'ItemsRequested'. This is
again a subclass of 'Items' with the addition in 'ItemRequested' of the
required quantity required.
aws#ItemsRequested [ aws#item => aws#ItemRequested ] :: aws#Items.
aws#ItemRequested [ aws#quantity => xs#positiveInteger ] :: aws#Item.
The 'items' are an output
of item search and a required input to
any cart operation. We can describe this linkage of inputs to outputs as a
constraint on the relative ordering of an occurrence of a search and cart
operation. In this case we wish to describe a sequential
composition where we put the search before the cart. We describe this
composite process as a shopping activity, and just like window shopping
there is no implication that anything is actually purchased.
aws#shopping(?searchIndex,?title,?qty,?cart,?url) {
Sequence
occurrence ?o1 aws#ItemSearch(?searchIndex,?title,?items)
occurrence ?o2 aws#CartCreate(?items,?cart,?url)
?o1 soo_precedes ?o2
}
Currently, the Amazon API does not allow an agent to complete a
purchase automatically, but each shopping cart has a purchase URL that the
customer can visit to finalize the purchase.
This creates an interesting challenge for process modeling. How do we represent
these out-of-band actions that are not directly performed by the agent and
are not grounded in web-services? The effect of order submission is also
significantly different from the simple state-changes we see in shopping
carts. Adding items to a cart does not commit the buyer to
anything. However, when the buyer places a confirmed order, the seller is
then under an obligation to deliver the product (and the customer is under
obligation to pay). This is understood to be central to the buyer/seller
contract and may be described as an
obligation between the
requester and
provider. It represents a commitment to honour an agreement at all
future times (until it is discharged).
In reality, these obligations are conditional. The buyer has the right to
cancel the order at any time up until the order is actually dispatched.
Conversely, a
permission proffers the right at some future time to perform an action
(until it is withdrawn). Both obligations and permissions are described in
the web-service
policy model.
aws#purchase(?cart,?url) {
Atomic
input aws#purchaseURL xs#anyURI ?url
effect aws#commit(?cart)
}
This example illustrates the use of SWSL-Rules for Web service discovery.
The particular features of the language that this example relies on include
frame-based
representation, reification,
and nonmonotonic Lloyd-Topor extensions.
In addition, logical updates à la Transaction logic
[Bonner98] are used in the discovery
queries. Transaction Logic was mentioned in Section
3.15 as a possible extension for SWSL-Rules.
To make the example manageable, services are described only by their names
and conditional effects. To discover a service, users must represent their
goals using the goal ontology described below.
These goals are described in terms of user requests, which
represent formulas that the user wants to be true
in the after-state of the service (i.e., the state that would
result after the execution of the service).
User goals and services may be expressed in different ontologies and so
mediators are needed to translate between those ontologies.
This type of mediators is known as wgMediators [Bruijn05]. In this example, we
assume that each service advertises the mediators that can be used to talk
to this service though the attribute mediators.
Ontologies
Geographical ontology.
To begin, we assume the following simple geographic taxonomy, which is
shared by user goals and services. It defines
several regions and subregions, such
as America, USA, Europe,
Tyrol. Each region is viewed as a class of cities. For
instance, Innsbruck is a city in Tyrol
and 'Stony Brook' is a town in the New York State
(NYState).
USA::America.
Germany::Europe.
Austria::Europe.
France::Europe.
Tyrol::Austria.
NewYorkState::USA.
StonyBrook:NewYorkState.
NewYork:NewYorkState.
Innsbruck:Tyrol.
Lienz:Tyrol.
Vienna:Austria.
Bonn:Germany.
Frankfurt:Germany.
Paris:France.
Nancy:France.
Europe:Region.
America:Region.
?Reg:Region :- ?Reg1:Region and ?Reg::?Reg1.
?Loc:Location :- ?Reg:Region and ?Loc:?Reg.
To make it easier to specify what is a region and what is not, we use a rule
(the penultimate statement above) to say that a subclasses of a region are
also regions and, therefore, such subclasses do not need to be explicitly
declared as regions. The last rule simply says that any object that is a
member of a geographical region is a location.
Goal ontology.
Services write their descriptions to conform to specific
ontologies. Likewise, clients describe their goals in terms of goal
ontologies. Here we will not describe these ontologies, but rather the forms
of the inputs and outputs that the services expect to produce and the
structure of the user goals.
Furthermore, since users and service designers are unlikely to be skilled
knowledge engineers,
we assume that the inputs, the outputs, and the goals are fairly simple and
that most of the intelligence lies in the mediators.
We assume that there is one ontology for goals and two for
services. Consequently, there are two mediators: one translating between the
goal ontology and the first service ontology, and the other between the goal
ontology and the second service ontology.
The goal ontology looks as follows:
Goal[requestId *=> Request,
request *=> TravelSearchQuery,
result *=> Service
].
The classes Request and Service will be specified
explicitly by placing specific object Ids in them. The class
TravelSearchQuery consists of the following search queries:
searchTrip(?From,?To):TravelSearchQuery :-
?From:(Region or Location) and ?To:(Region or Location).
searchCitipass(?Loc):TravelSearchQuery :- ?Loc:(Region or Location).
The meaning of the query searchTrip(?X,?Y) depends on whether the
parameters are regions or just locations. For location-parameters, the query
is assumed to fetch the services that serve those locations. For
region-parameters, the query is assumed to find services that
service every location in the region that is known to the knowledge
base. For instance, searchTrip(Paris, Germany) is a request for
travel services that can sell a ticket from Paris to any city in
Germany. Similarly, searchCitipass(NewYork) is interpreted as
a search for travel services that can sell city passes for New York and
the request searchCitipass(USA) is looking for services that
can sell city passes for every location in USA.
The result attribute is provided by the ontology as a place
where the discovery mechanism is supposed to put the results.
Domain-specific service ontologies.
A service ontology is intended to represent the inputs and outputs of the
service as well as the effects of the service. Since the inputs are not
generally provided in the user goal (since the user is not expected to know
anything about such inputs), the job of translating goal queries into the
inputs to the services lies with the mediator.
Service ontology #1 is defined as follows:
// Service input
search(?requestId,?fromLocation,?toLocation):ProcessInput :-
?requestId:Request and
?fromLocation:Location and ?toLocation:Location.
search(?requestId,?city):ProcessInput :-
?requestId:Request and ?city:Location.
// Service output
ItineraryInfo::ServiceOutput.
PassInfo::ServiceOutput.
ItineraryInfo[from*=>Location, to*=>Location].
PassInfo[city*=>Location].
itinerary(?reqNumber):ItineraryInfo :- ?reqNumber:Request.
pass(?reqNumber):PassInfo :- ?reqNumber:Request.
Note that services expect locations as part of their input and they know
nothing about regions. In contrast, as we have seen, user goals can have
region-wide requests. It is one of the responsibilities of the mediators to
bridge this mismatch.
Service ontology #2 is similar to ontology #1 except that it understands
only requests for citipasses and the formats for the input and the
output are slightly different.
// Service input
discover(?requestId,?city):ProcessInput :-
?requestId:Request and ?city:Location.
// Service output
ServiceOutput[location*=>Location].
?reqNumber:ServiceOutput :- ?reqNumber:Request.
Shared core ontology for services.
In addition, we need a core ontology that is shared by everyone in order to
provide a common ground for the service infrastructure. In this example, the
core ontology is represented by a single class
Service, which is declared as follows:
prefix xsd = "http://www.w3.org/2001/XMLSchema".
Service[
name *=> xsd#string,
process *=> Process[effect(ProcessInput) *=> Formula],
mediators *=> Mediator
].
Note that the definition of the class Service belongs to the
core ontology and therefore it is shared by everybody.
The method effect represents the conditional effect of the
service. It takes an input to the service as a parameter and returns a set of
rules that specify the effects of the service for that
input. Formula is a predefined class.
The attribute mediators indicates the mediators that the
service advertises for anywho would want to talk to that service.
Note that the class ProcessInput belongs to the core ontology,
but it's extension (the set of objects that are members of that class) is
defined by domain-specific ontologies.
Examples of Concrete Services
We now present instances of concrete services.
// This service uses ontology #1, and mediator med1 bridges it to the goal ontology
serv1:Service[
name -> "Schwartz Travel, Inc.",
// Input must be a request for ticket from somewhere in Germany to somewhere
// in Austria OR a request for a city pass for a city in Tyrol
// Depending on the input, output is either an itinerary object with Id
// itinerary(requestId) or a citipass object with Id
// pass(requestId).
process ->
_#[effect(?Input) -> ${
(itinerary(?Req)[from->?From,to->?To] :-
Input = search(?Req, ?From:Germany, ?To:Austria))
and
(pass(?Req)[city->?City] :- ?Input=search(?Req,?City:Tyrol))
}],
mediators -> med1
].
// Another ontology #1 service
serv2:Service[
name -> "Mueller Travel, Inc.",
process ->
_#[effect(?Input)-> ${
itinerary(?Req)[from->?From, to->?To] :-
?Input = search(?Req,?From:(France or Germany),?To:Austria)
}],
mediators -> med1
].
// An ontology #2 service
serv3:Service[
name -> "France Citeseeing, Inc.",
process ->
_#[effect(?Input)-> ${
?Req[location->?City] :- ?Input=discover(?Req,?City:France)
}],
mediators -> med2
].
// Another ontology #2 service
serv4:Service[
name -> "Province Travel",
process ->
_#[effect(?Input)-> ${
?Req[location->?City] :-
?Input = discover(?Req,?City:France) and ?City != Paris
}],
mediators -> med2
].
User Goals
Next we show examples of user goals. Note that the value of the
attribute result is initially the empty set. When the goal is
posed to the discovery engine, this value will be changed to contain the
result of the discovery.
goal1:Goal[
requestId -> _#:Request,
request -> searchTrip(Bonn,Innsbruck),
result -> {}
].
// search for services that serve all cities in France and Austria
goal2:Goal[
requestId -> _#:Request,
request -> searchTrip(France,Austria),
result -> {}
].
goal3:Goal[
requestId -> _#:Request,
request -> searchCitipass(Frankfurt),
result -> {}
].
goal4:Goal[
requestId -> _#:Request,
request -> searchCitipass(Innsbruck),
result -> {}
].
// services that can sell citipasses for every city in France
goal5:Goal[
requestId -> _#:Request,
request -> searchCitipass(France),
result -> {}
].
Each of the two mediators, med1 and med2, consists
of several main clauses. The first clause in each mediator takes a user goal
and translates it into input (to services)
that is appropriate for the corresponding
domain-specific service ontology.
The remaining clauses define the mediator's method getResult.
This method is supposed to be invoked in the after-state of the service
execution. It takes as parameters the user goal and the service (in whose
after-state the method is invoked). Depending on the form of the goal's
request, getResult poses a query that is appropriate
for that request and the service ontology of the service. For instance, if
the request is searchCitipass(?City:Location), i.e.,
finding services that can sell citipasses for a specific location, then the
query appropriate for services that use ontology #1
is pass(?)[city->?City] and
the query for ontology #2 is ?[location->?City].
Finally, if the query yields results, the mediator constructs output that can
be used to return results to the user and this output is compliant with
our goal ontology.
Each form of the input has two cases: one assumes that the parameters are
locations (e.g., searchCitipass(?City:Location)) and the other
that they are regions (e.g., searchCitipass(?City:Region)).
Therefore, for each form of the input our mediators have two clauses.
Since ontology #2 understands only one input, med2 uses only two
clauses to define getResult. The mediator for ontology
#1, med1, needs four clauses to cover both forms of the input.
Finally, we remark that the clauses that deal with region-based requests have
to construct more sophisticated queries to be asked in the after-state of the
services. In our example, we use nonmonotonic
Lloyd-Topor extensions to simplify such queries.
// mediator for ontology #1
med1:Mediator.
med1[constructInput(?Goal)->?Input] :-
?Goal[requestId->?ReqId, request->?Query] and
if ?Query = searchTrip(?From,?To)
then ?Input = search(?ReqId,?From1,?To1)
else if ?Query = searchCitipass(?City)
then ?Input = search(?ReqId,?City1).
med1[getResult(?Goal,?Serv) -> ${?Goal[result->?Serv]}] :-
?Goal[request->searchCitipass(?City:Location)] and
pass(?)[city->?City].
med1[getResult(?Goal,?Serv) -> ${?Goal[result->?Serv]}] :-
?Goal[request->searchCitipass(?Region:Region)] and
forall ?City (?City:?Region ==> pass(?)[city->?City]).
med1[getResult(?Goal,?Serv) -> ${?Goal[result->?Serv]}] :-
?Goal[request->searchTrip(?From:Location,?To:Location)] and
itinerary(?)[from->?From, to->?To].
med1[getResult(?Goal,?Serv) -> and ?Result = ${?Goal[result->?Serv]}] :-
?Goal[request->searchTrip(?From:Region,?To:Region)] and
forall ?From,?To (?City1:?FromReg and ?City2:?ToReg
==> itinerary(?)[from->?City1, to->?City2]).
// mediator for ontology #2
med2:Mediator.
med2[constructInput(?Goal)->?Input] :-
?Goal[requestId->?ReqId, request->?Query] and
if ?Query = searchCitipass(?City)
then ?Input = discover(?ReqId,?City1).
med2[getResult(?Goal,?Serv) -> ${?Goal[result->?Serv]}] :-
?Goal[request->searchCitipass(?City:Location)] and
?[location->?City].
med2[getResult(?Goal,?Serv) -> ${?Goal[result->?Serv]}] :-
?Goal[request->searchCitipass(?Region:Region)] and
forall ?City (?City:?Region ==> ?[location->?City]).
The Discovery Engine
The final piece of the puzzle is the actual engine that performs service
discovery. It relies on the features, borrowed from
Transaction Logic [Bonner98], which
are currently not in
SWSL-Language, but are considered for future extensions. These features
include modifications to the current state of the knowledge base and
hypothetical execution of such modifications.
findService(?Goal) :-
?Serv[mediators -> ?Mediator] and
?Mediator[constructInput(?Goal) -> ?Input] and
?Serv.process[effect(?Input) -> ?Effects] and
hypothetically(
insert{?Effects} and
?Mediator[getResult(?Goal,?Serv) -> ?Result]
) and
insert{?Result}.
The findService transaction performs the
following tasks:
-
For each service instance, s, it finds the mediator
that the service advertises.
-
It then uses the mediator to construct the input for that service based
on the user goal.
-
Using the input, it computes the effects that the service guarantees to be
true in the after-state of the execution.
-
It then hypothetically does the following:
-
It inserts the effects (which are rules in this case) into the
knowledge base. This simulates the execution of the
service s and
temporarily creates the after-state of the service
execution.
-
Using the mediator, it
checks whether the user goal is true in the after-state of the
service s and then
returns the result.
-
If the above hypothetical execution fails for a particular
service, no result is returned and the subsequent insert
operation is not executed.
If the hypothetical execution succeeds, it means that the
service s matches the goal.
After the hypothetical execution, the state of the knowledge base
returns to what was before the execution of the service, but the
variable ?Result is now bound to a result, which is a
formula of the form
goal[result->s]
This is then inserted into the knowledge base. In this way, the set of
answers to the goal is built as the value of the result
attribute of the goal object.
For instance, if
?- findService(goal1).
is executed then the following will become true:
goal1[result -> {serv1,serv2}]
Similarly, executing
?- findService(goal2).
yields goal2[result -> serv2]. The third
goal, goal3, matches none of the services listed above, so only
goal3[result->{}] can be derived.
Executing
?- findService(goal4).
yields goal4[result -> serv1].
A more interesting goal is goal5, because it requests
citipasses for an entire region (France). Given the information available in
our knowledge base, only serv3 should match. Note
that serv4 does not match because it does not serve Paris,
while the goal specifies only those services that can sell citipasses for
every location in France.
The overall SWSL language and ontologies support many kinds of application
scenarios.
In this subsection, we discuss in detail how SWSL-Rules can be
used to represent several (fictional) examples of policies for e-commerce.
Some of these examples are given directly in the remainder of
this section, in full detail.
These include:
price discounting example;
refunds example;
supply chain ordering lead time example;
creditworthiness example; and
credit card transaction authorization example.
Taken together these examples include both B2C/retailing and B2B/supply-chain aspects,
in several industry domains
(books, appliances, and computer equipment manufacturing).
Each of these policies is useful for not just one but several different
kinds of tasks within an application realm.
For example, price discounting rules are useful in advertising and in
service contract specification.
Most of these detailed examples are rather brief, for the sake of
expository simplicity. However, the example dealing with authorization of
credit card transactions is
significantly longer and more realistic.
Additional examples of policy rules are available
that use the same fundamental knowledge representation as SWSL-Rules.
[Grosof2004e]
gives a long
example of e-contracting policy rules that combines rules with
ontologies and deals with exception handling / monitoring.
The [Grosof2004f] tutorial
gives a collection of use cases and examples, including those
for semantic mediation.
The SweetRules [Grosof2004f]
downloadable includes a collection of examples.
Overall,
the SWSL-Rules is especially well suited to represent available knowledge
and desired patterns of reasoning for several of the SWS tasks, including:
-
authorization policies (for security, access control, confidentiality,
privacy, and other kinds of trust);
-
contracts (partial or complete, proposed or finalized), e.g., terms and
conditions, service provisions, or surrounding business process policies;
-
monitoring of processes to recognize and handle exceptions or other
dynamic conditions (e.g., monitoring
of performance of contracts to detect and respond to violations of contract
provisions such as late delivery or non-payment);
-
advertising, discovery, and matchmaking (e.g., advertisements and
requests for quotation or requests for proposals can be regarded as partial
contract proposals);
-
semantic mediation, especially translation mappings that mediate
between different
ontologies or contexts and thus between knowledge expressed in those
different ontologies or contexts (e.g., to translate from the output
of one service to the input expected by another service); and
-
object-oriented ontologies that use default inheritance with priorities
and/or cancellation (e.g., in the manner of the Process Handbook
[Process Handbook,
Bernstein2003,
Grosof2004d]).
In particular, the capabilities of SWSL-Rules for logical nonmonotonicity
(negation-as-failure and/or Courteous prioritized conflict handling)
is used heavily in many use case scenarios for each of the above tasks
and its associated kinds of knowledge.
Next, we give an example of a set of policy rules that specify
personalized price discounting in an e-bookstore.
These rules are useful in advertising, and also as part of a contract
(proposed or final).
The policy rules specify that by default, a shopper gets no discount
(i.e., gets a zero percent discount).
However, there are some particular circumstances which do warrant
a discount. Loyal purchasers get a five percent discount.
Members of the Platinum Club get a ten percent discount.
However, customers who have been late in making payments during the last
year get no discount.
Also there is a mutex (integrity constraint) rule which specifies
that it is a contradiction to conclude two different values of the discount
percentage for the same customer, i.e., that the discount percentage
should be unique.
/* price discounting policy rules */
{ordinary}
giveDiscount(percent00,?Cust) :- shopper(?Cust).
{loyal}
giveDiscount(percent05,?Cust) :- shopper(?Cust) and loyalPurchaser(?Cust).
{platinum}
giveDiscount(percent10,?Cust) :- shopper(?Cust) and member(?Cust,platinumClub).
{slowPayer}
giveDiscount(percent00,?Cust) :- slowToPay(?Cust,last1year).
overrides(loyal,ordinary).
overrides(platinum,loyal).
overrides(platinum,ordinary).
overrides(slowPayer,loyal).
overrides(slowPayer,platinum).
!- giveDiscount(?X,?Cust) and giveDiscount(?Y,?Cust) | notEquals(?X,?Y).
/* some "case" facts about particular customers ann, cal, kim, and peg. */
shopper(ann).
shopper(cal).
loyalPurchaser(cal).
shopper(kim).
member(kim,platinumClub).
shopper(peg).
loyalPurchaser(peg).
slowToPay(peg,last1year).
The above premises (policy rules and case facts) together entail
the following conclusions about the discount percentages for the
particular customers Ann, Cal, Kim, and Peg.
/* the entailed discount percentages for the particular customers */
giveDiscount(percent00,ann).
giveDiscount(percent05,cal).
giveDiscount(percent10,kim).
giveDiscount(percent00,peg).
Next, we give a typical example of a seller's refund policy,
as a set of policy rules that specify
refunds in an e-retailer (here, of small consumer appliances)
These rules are useful in advertising, and as part of a contract
(proposed or final), and as part of contract monitoring / exception handling
(which is in turn part of contract execution).
The unconditional guarantee rule says that if the buyer returns the
purchased good for any reason, within 30 days, then the purchase
amount, minus a 10 percent restocking fee, will be refunded.
The defective guarantee rule says that if the buyer returns the purchased
good because it is defective, within 1 year, then the full purchase amount
will be refunded. A priority rule says that if both of the previous two
rules apply, then the defective guarantee rule "wins", i.e., has higher
priority. A mutex says that the refund percentage is unique per
customer return.
/* refund policy rules */
{unconditionalGuarantee}
refund(?Return,percent90) :-
return(?Return) and delay(?Return,?D) and lessThanOrEqual(?D,days30).
{defectiveGuarantee}
refund(?Return,percent100) :-
return(?Return) and reason(?Return,defective) and delay(?Return,?D) and
lessThanOrEqual(?D,years1).
overrides(defectiveGuarantee,unconditionalGuarantee).
!- refund(?Refund,percent90) and refund(?Refund,percent100).
/* some background facts (typically provided by lessThanOrEqual
being a built-in predicate */
lessThanOrEqual(days12,days30).
lessThanOrEqual(days44,years1).
lessThanOrEqual(days22,years1).
lessThanOrEqual(days22,days30).
/* some "case" facts about particular customer returns of items */
return(toaster02).
delay(toaster02,days12).
return(blender08).
delay(blender08,days44).
reason(blender08,defective).
return(radio04).
delay(radio04,days22).
reason(radio04,defective).
The above premises (policy rules, background facts, and case facts)
together entail
the following conclusions about the discount refund percentages for the
particular customer returns of the toaster, blender, and radio.
/* the entailed refund percentages for the particular customer returns */
refund(toaster02,percent90).
refund(blender08,percent100).
refund(radio04,percent100).
In B2B commerce, e.g., in supply chains (especially in manufacturing),
sellers often specify how much lead time, i.e., minimum advance notice, is
required when a buyer places or modifies a purchase order.
Next, we give an example of a part supplier vendor's (here, Samsung
supplying computer equipment) lead time policies
as a set of rules.
These rules are useful in advertising, and as part of a contract
(proposed or final), and as part of contract monitoring / exception handling
(which is in turn part of contract execution).
The first policy rule says "14 days lead time if the buyer is a preferred
customer". This might be authored by the marketing part of the seller's
organization. The second policy rule says "30 days lead time if the
ordered item is a minor part". This might be authored by the financial
accounting part of the seller's organization. The third policy rule says
"2 days lead time if: the ordered item is backlogged at the vendor
(i.e., the seller is having trouble fulfilling its overall set of existing
orders), and the order is a modification to reduce the quantity of the
item, and the buyer is a preferred customer". This might be authored by
the operations part of the seller's organization. The third rule is
given higher priority than the first rule, say, because operations'
authority (about lead time) is greater than that of marketing.
A mutex says that the lead time is unique per purchase order.
/* ordering lead time policy rules */
{leadTimeRule1}
orderModificationNotice(?Order,days14) :-
preferredCustomerOf(?Buyer,?Seller) and purchaseOrder(?Order,?Buyer,?Seller).
{leadTimeRule2}
orderModificationNotice(?Order,days30) :-
minorPart(?Order) and purchaseOrder(?Order,?Buyer,?Seller).
{leadTimeRule3}
orderModificationNotice(?Order,days2) :-
preferredCustomerOf(?Buyer,?Seller) and orderModificationType(?Order,reduce) and
orderItemIsInBacklog(?Order) and purchaseOrder(?Order,?Buyer,?Seller).
overrides(leadTimeRule3,leadTimeRule1).
!- orderModificationNotice(?Order,?X) and orderModificationNotice(?Order,?Y) | notEquals(?X,?Y).
/* some "case" facts about particular purchase orders */
purchaseOrder(po1234567,compUSA,samsung).
preferredCustomerOf(compUSA,samsung).
purchaseOrder(po5678901,microCenter,samsung).
preferredCustomerOf(microCenter,samsung).
orderModificationType(po5678901,reduce).
orderItemIsInBacklog(po5678901).
The above premises (policy rules and case facts)
together entail
the following conclusions about the ordering lead time for the
particular purchase orders po1234567 and po5678901.
/* the entailed lead times for the particular purchase orders */
orderModificationNotice(po1234567,days14).
orderModificationNotice(po5678901,days2).
Policies about authorization, including creditworthiness and other
kinds of trustworthiness to access information or perform
transactions, are often
naturally expressed in terms of necessary and sufficient conditions.
Such conditions include: credentials, e.g., credit ratings or
professional certifications; third-party recommendations; properties
of a transaction in question, e.g., its size or mode of
payment; and historical experience between the agents, e.g.,
familiarity or satisfaction.
Next, we give a simple example of policy rules of a merchant
about creditworthiness (of customers)
using a credit report service and a fraud alert service.
These rules are useful for representing authorization policies, as part of
contract negotiation, and in contract
monitoring and exception handling (e.g., if the fraud alert arrives
after contractual agreement has been reached).
The first policy rule says that, by default, the merchant deems a
requester customer to be creditworthy if the requester has a
good rating from a
particular credit report service (CreditReportsRUs, a source trusted
by the merchant).
The second policy rule says that the merchant deems a requester to
be not creditworthy if the requester has a bad rating from any
fraud alert service that is recommended as expert by a particular
security consultant (recommenderServiceD, again, a source trusted
by the merchant).
The second rule is given higher priority than the first rule.
The merchant is called "self" (as is conventional in the security policy
literature for the granting authority institution).
/* creditworthiness policy rules */
{credSelf}
honest(self,?Requester) :- creditRating(creditReportsRUs,?Requester,good).
{frauSelf}
neg honest(self,?Requester) :-
creditRating(?BlackballService,?Requester,bad) and
fraudExpert(recommenderServiceD,?BlackballService).
overrides(frauSelf,credSelf).
fraudExpert(recommenderServiceD,studentLoanAgency).
/* some "case" facts about particular requester customers */
creditRating(creditReportsRUs,sue,good).
creditRating(creditReportsRUs,joe,good).
creditRating(studentLoanAgency,joe,bad).
The above premises (policy rules and case facts)
together entail
the following conclusions about the creditworthiness of the
particular requester customers Sue and Joe.
/* the entailed creditworthiness of the particular requester customers */
honest(self,sue).
neg honest(self,joe).
Next, we give a longer and more realistic example
of authorization in e-commerce: authorization by a merchant
of credit card transactions requested by customers.
In this example, the merchant ("eSellWow") merges the
authorization policies of credit card issuer (called the "bank") with
the merchant's own additional authorization policies.
These rules are useful for specifying authorization policies, contracts,
and exception handling.
/* Some terminological abbreviations:
CVC: Card Verification Code (the three or so numbers found on the back of a credit card)
"Bank": the credit card company that is the issuer of the credit card (e.g., Mastercard)
*/
/* Predicates' meaning:
transactionRequest: a credit card transaction requested by a customer
merchant: a merchant who is established to do credit card transactions
with the credit card company
ccInGoodStanding: credit card is in good standing with the credit card company that is
the issuer of the credit card
ccInfo: credit card info about the account and its status, that is on file with the bank
authorize: the credit card transaction is authorized
transactionExpirationDateOf: customer-supplied expiration date that is part of the transaction
transactionCardholderNameOf: customer-supplied cardholder name that is part of the transaction
transactionCVCOf: customer-supplied CVC that is part of the transaction
transactionCardholderAddressOf: customer-supplied cardholder billing address
that is part of the transaction
ccFraudRating: rating of a credit card by a fraud alerting/tracking service
fraudExpert: a service is a legitimate expert in fraud alerting/tracking
fraudRecommenderFor: trusted recommender of fraud experts
customerRating: the rating of customer based on the merchant's own/other experience
Built-in predicates (used):
notEquals
lessThan
*/
/* The following group of rules are policies of the bank,
then adopted/imported as a group/module by the merchant, in this case eSellWow. */
/* bankGoodStanding: Bank says by default the transaction is authorized if the card is in
good standing */
/* expiredCard: Bank says the transaction is disallowed if the card is expired. */
/* overLimit: Bank says the transaction is disallowed if the card is above its account limit. */
/* mismatchExpirationDate: Bank says the transaction is disallowed if the expiration date from
the customer or card in the transaction does not match what's on file for the card.
However, the expiration date may not be available as part of the transaction. */
/* mismatchCVC: Bank says the transaction is disallowed if the Card Verification Code
does not match what's on file for the card.
However, note that the CVC may not be available as part of the transaction. */
/* mismatchAddress: Bank says the transaction is disallowed if customer-supplied cardholder
billing address does not match what's on file for the card.
However, the customer-supplied cardholder billing address may not be available. */
/* mismatchName: Bank says the transaction is disallowed if customer-supplied cardholder
name does not match what's on file for the card.
However, the customer-supplied cardholder billing address may not be available. */
/* The expiredCard, overLimit, mismatchExpirationDate, mismatchCVC, mismatchAddress, and
mismatchName rules all have higher priority than bankGoodStanding. */
/* The following group of rules are additional policies of the merchant eSellWow,
which it adopted/imported from a vendor and consultant when setting up its e-store website */
/* merchantRespectBank: Merchant say a transaction is disallowed if the bank does. */
/* merchantTrustBank: Merchant says, by default, that a transaction is allowed if the bank does. */
/* fraudAlert: Merchant says transaction is disallowed if a trusted fraud tracking service
rates the fraud risk as high for the card. */
/* trustTRW: Merchant relies on recommenderServiceTRW for establishing such trust. */
/* badCustomer: Merchant says transaction is disallowed if its own/other experience indicates that the
customer is a bad customer to deal with. */
/* The fraudAlert and badCustomer rules both have higher priority than merchantTrustBank. */
/* The following are additional background fact rules, known to the merchant eSellWow and the bank. */
/* eSellWow is an established merchant for mastercard and visa. */
/* The following are additional background fact rules, known to the merchant eSellWow. */
/* recommenderServiceTRW recommends fraudscreen */
{bankGoodStanding}
authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInGoodStanding(?Bank,?CreditCardNumber).
{expiredCard}
neg authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
notEquals(?ExpiredFlag,"false").
{overLimit}
neg authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
lessThan(?AccountLimit,?Amount).
{mismatchExpirationDate}
neg authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
transactionExpirationDateOf(?TransactionID,?TransactionExpirationDate) and
notEquals(?TransactionExpirationDate,?ExpirationDate).
{mismatchName}
neg authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
transactionCardholderNameOf(?TransactionID,?TransactionCardholderName) and
notEquals(?TransactionCardholderName,?CardholderName).
{mismatchCVC}
neg authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
transactionCVCOf(?TransactionID,?TransactionCVC) and notEquals(?TransactionCVC,?CVC).
{mismatchAddress}
neg authorize(?Bank,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
transactionCardholderAddressOf(?TransactionID,?TransactionCardholderAddress),
notEquals(?TransactionCardholderAddress,?CardholderAddress).
overrides(expiredCard,bankGoodStanding).
overrides(overLimit,bankGoodStanding).
overrides(mismatchExpirationDate,bankGoodStanding).
overrides(mismatchName,bankGoodStanding).
overrides(mismatchCVC,bankGoodStanding).
overrides(mismatchAddress,bankGoodStanding).
{merchantTrustBank}
authorize(?Merchant,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
authorize(?Bank,?TransactionID).
{merchantRespectBank}
neg authorize(?Merchant,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
neg authorize(?Bank,?TransactionID).
{fraudAlert}
neg authorize(?Merchant,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
fraudRecommenderFor(?Merchant,?recommenderService) and
fraudExpert(?recommenderService,?FraudFirm) and
ccFraudRiskRating(?FraudFirm,?CardholderName,high).
{badCustomer}
neg authorize(?Merchant,?TransactionID) :-
transactionRequest(?TransactionID,?Merchant,?CreditCardNumber,?Amount) and
issuer(?CreditCardNumber,?Bank) and merchant(?Merchant,?Bank) and
ccInfo(?CreditCardNumber,?Bank,?CardholderName,?AccountLimit,
?ExpiredFlag,?ExpirationDate,?CardholderAddress,?CVC) and
customerRating(?Merchant,?CardholderName,bad).
overrides(fraudAlert,merchantTrustBank).
overrides(badCustomer,merchantTrustBank).
fraudRecommenderFor(eSellWow,recommenderServiceTRW).
merchant(eSellWow,mastercard).
merchant(eSellWow,visa).
fraudExpert(recommenderServiceTRW,fraudscreen).
/* The following groups of "case" facts each specify a
particular case scenario of a requested customer transaction. */
/* Joe Goya has a card in good standing, unexpired, and
the transaction amount is below the account limit.
His customer rating is good.
Transaction expiration date, address, and CVC are unavailable, as
is fraud alert rating.
The policies thus imply that his transaction ought to be authorized
by the merchant as well as by the bank. */
/* Mary Freund has a card in good standing, unexpired, and
the transaction amount is below the account limit.
Her address matches, and her fraud report and customer rating are fine.
But the transaction CVC and address do not match the ones on file.
Thus the policies imply that the transaction on her card
ought to be disallowed by the merchant as well as the bank. */
/* Andy Lee has a card in good standing, unexpired,
and the transaction amount is under the account limit.
But his customer rating is bad.
Thus the policies imply that his transaction ought to be disallowed
by the merchant (regardless of whether the bank allows it). */
transactionRequest(trans1014,eSellWow,"999912345678",70).
issuer("999912345678",mastercard).
ccInfo("999912345678",mastercard,joeGoya,1100,"false","2007_08","43 Garden Drive, Cincinnati OH",702).
ccInGoodStanding(mastercard,"999912345678").
customerRating(eSellWow,joeGoya,good).
transactionRequest(trans2023,eSellWow,"999987654321",410).
issuer("999987654321",visa).
ccInfo("999987654321",visa,maryFreund,2400,"false","2008_02","325 Haskell Street, Seattle, WA",684).
ccInGoodStanding(visa,"999987654321").
ccFraudRiskRating(fraudscreen,maryFreund,low).
customerRating(eSellWow,maryFreund,excellent).
transactionCVCOf(trans2023,524).
transactionTransactionAddressOf(trans2023,"1493 Belair Place, Los Angeles, CA").
transactionRequest(trans3067,eSellWow,"999956781234",120).
issuer("999956781234",mastercard).
ccInfo("999956781234",mastercard,andyLee,900,"false","2006_05","1500 Seaview Boulevard, Daytona Beach, FL",837).
ccInGoodStanding(mastercard,"999956781234").
customerRating(eSellWow,andyLee,bad).
The above premises (policy rules and case facts)
together entail
the following conclusions about the authorization of the
particular requested transactions by customers Joe Goya, Mary Freund, and
Andy Lee. Notice that in the case of Andy Lee's, the merchant denies
authorization even though the bank approves it, because of the merchant's
own customer rating info and policies.
/* the entailed approval vs. denial by the bank, and by the merchant, of
authorization of the particular requested credit card transactions. */
authorize(mastercard, trans1014).
authorize(eSellWow, trans1014).
neg authorize(visa, trans2023).
neg authorize(eSellWow, trans2023).
authorize(mastercard, trans3067).
neg authorize(eSellWow, trans3067).
SWSO
is a core
service ontology and is
domain-independent.
However, it is often necessary to represent
domain-specific
ontologies.
Such ontologies might be represented in SWSL-Rules or in SWSL-FOL. An
important and frequently-used flavor of domain-specific service
ontologies uses
the object-oriented framework of the kind found in object-oriented
programming languages and in AI frame-based systems.
In such frameworks, the values of a property P
of a superclass are inherited by each of its subclasses.
These subclasses are known as the specializations
of the
parent
superclass. For example, the property P might be a data attribute or a
method definition. This inheritance has default
flavor:
explicitly specified information about the property for the subclass
overrides -- or cancels -- the inheritance. Such default inheritance
(and, by extension, such an ontology) is logically nonmonotonic and
cannot be represented in SWSL-FOL. However, it can be represented
in SWSL-Rules, which is object-oriented and includes inheritance as a
basic
feature.
To illustrate this point, we give an example of a service,
Sell Product,
which relies on
such a domain-specific service ontology.
The ontology describes a Sell Product business process
and a some of its specializations. The form and domain of this
ontology are similar to those found in the Process
Handbook [Process Handbook,
Malone99].
This kind of ontology is useful for business process modeling and
design,
and thus is useful -- along with other knowledge -- for a number of SWS
tasks, including:
In [Bernstein2003]
we introduced an example about Sell Product. The example below is
adapted from that. There we give an
approach to representing default inheritance about process ontologies
in terms of Courteous LP. Another approach to representing default
inheritance in a similar spirit is shown in [Yang02]
who use LP
with NAF but
without Courteous, instead defining special constructs
that extend the LP KR.
Below, we give an approach similar in spirit to both of the above, that
is relatively simple -- simple enough for a self contained brief
presentation here -- although lacking some of the advantages and
subtleties of the above two approaches.
Modeling the parent service
"Sell Product"
Suppose we need to design
a sales process that is used in an organization in two
ways. One version is used in a mail-order business and the other
in a retail store. First, we need to model a generic sales
process for which one can find a template in a process repository
(e.g., the Process Handbook). The "Sell product"
service consists of five subtasks: "Identify potential customers,"
"Inform potential customers," "Obtain Order," "Deliver product ," and
"Receive payment." In this example, we do not model any sequencing
dependencies between the subtasks.
One way to represent this
situation is to treat the main service as a class and its subtasks as
attributes:
SellProduct[
identifyCustomers *-> genericFindCust,
informCustomers *-> genericInformCust,
obtainOrder *-> genericGetOrder,
deliverProduct *-> genericDeliver,
receivePay *-> genericGetPay
].
Here the attribute names
represent the names of the subtasks and the values of these attributes
are the names of the actual procedures to be used to perform these
tasks. These procedures can be written in a procedural programming
language, such as Java, or even in SWSL-Rules. For instance,
?Product[genericInformCust] :-
?Product[genericFindCust -> ?Cust] and
generateFlyer(?Cust) and
informMailRoom.
Some of the formulas in the
body of the above rule could be purely declarative and be defined by
other rules in the knowledge base (e.g., genericFindCust)
while others could have side effects in the physical world (such as generateFlyer
and informMailRoom).
Such side-effectful statements are not currently part of SWSL-Rules,
but they are planned for future
extensions.
Note that the method genericFindCust
returns a set
of customers (based on some marketing criteria), and the method genericFindCust
is executed for each
such customer.
Overriding and Canceling
Inherited Features
Continuing the example, we specify the "Sell by mail order" and "Sell
in retail
store" services as subclasses of the "Sell Product" process, as shown
in Figure 6.1.
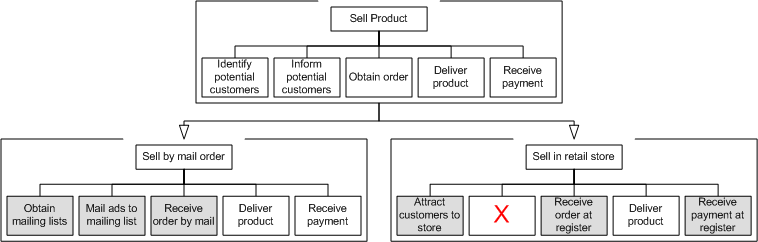
Figure 6.1: The "Sell Product"
service with
two subclasses. The grayed out subtasks are overwritten
with more specific alternatives; the subtask with the red cross is
deleted ("canceled").
This subclassing approach
has several advantages. First, it provides a simple way
of reusing the elements already defined in an object-oriented manner.
Second,
taxonomic organization of processes has been found
useful for human browsing [Malone99].
For "Sell by mail order," inheritance of three of the subtasks
of the parent service "Sell product" is
overwritten by other subtasks, and two subtasks are inherited.
For "Sell in retail store", one subtask is inherited, inheritance of
three
others is overwritten, and one subtask is "canceled" (i.e., is no
longer
defined for the subsprocess).
Since nonmonotonic inheritance
is one of the basic concepts of SWSL-Rules, modeling of the service
"Sell by mail order" is straightforward. First, we need to specify it
as a subclass of SellProduct.
Then we need to explicitly define the three overwritten subtasks and
provide new values (new procedures) for them. We do not need to mention
the two tasks that are inherited:
SellByMailOrder::SellProduct[
identifyCustomers *-> obtainMailLists,
informCustomers *-> junkmailAds,
obtainOrder *-> getOrderByMail
].
Because of the overriding in
the SellByMailOrder
subclass, the subtask informCustomers
is no longer performed using the previously defined method genericInformCust.
Instead, the method junkmailAds
is used; it could be defined in SWSL-Rules as follows:
?Product[junkmailAds] :-
?Product[obtainMailLists -> ?List] and
?List[address -> ?Addr] and
affixLabelToAd(?Addr) and
informMailRoom.
To model the "Sell in retain store" we first specify a new subclass of
the
"Sell Product" service. According to the figure, this subclass inherits
the deliverProduct
attribute, while three other attributes,
identifyCustomers,
obtainOrder,
and receivePay,
are overwritten.
This is modeled similarly to the SellByMailOrder
subclass:
SellInRetail::SellProduct[
identifyCustomers *-> attractToBrickAndMortar,
obtainOrder *-> getOrderAtRegister,
receivePay *-> getPayAtRegister
].
The more interesting case is
the cancellation of the informCustomers
attribute. One way to achieve this is to introduce a special null
subtask and use it to override inheritance of the genericInformCust
procedure. A more interesting way it to take advantage of the semantics
of multiple inheritance
in SWSL-Rules according to which conflicting multiple inheritance for
the same attribute makes the value undefined. To achieve this, we can
introduce a family of classes parameterized by the features that need
to be canceled:
FeatureTerminator(?Feature)[?Feature *-> null].
For each concrete attribute, the above statement says that the value of that
attribute in the corresponding class is null. As a special case
(when ?Feature = informCustomers), the value of the
attribute informCustomers in
class FeatureTerminator(informCustomers) is null. To cancel the
inheritance of informCustomers we now need to add the following
fact:
SellInRetail::FeatureTerminator(informCustomers).
With this statement, SellInRetail
becomes a subclass of two classes, SellProduct
and FeatureTerminator(informCustomers).
Each of these classes has an explicit definition of the attribute informCustomers,
but those definitions are in conflict. According to the semantics of
inheritance in SWSL-Rules, this makes the value of informCustomers
in class SellInRetail
undefined
and thus the inheritance of that attribute is "canceled."
Next, suppose that we need to extend the repertoire of selling services
with a third process, "Sell electronically,"
which can be executed electronically.
Figure 6.2: The "Sell Product"
service with
three subclasses; the third subclass has an exception handler.
Figure 6.2 shows that the new
process has an exception attached to the second subtask "Inform
potential customers by email" in order to addresses the issue of
unwanted email solicitations. The exception permits people to remove
themselves from the mailing list by putting their addresses on the
opt-out list.
Inheritance and overriding of
the attributes from the parent class is modeled as before:
SellElectronically::SellProduct[
identifyCustomers *-> obtainByDataMining,
informCustomers *-> informByEmail,
obtainOrder *-> getOrderByEMail
].
The method informByEmail
could be defined as follows:
?Product[informByEmail] :-
?Product[obtainByDataMining -> ?Email] and
sendEmail(?Email).
One way to incorporate the
opt-out exception to the general policy is by adding the premise naf
optOutList(?Email) to the
body of the above rule. However, this approach is not modular, since it
requires modification of the existing rules (the method informByEmail
may have already been defined). Even if it were acceptable to make this
change now, further changes to the opt-out policy might require
additional changes to the existing rules. A more scalable approach is
to express the above opt-out exception using constraints, and this is
where the mutex
primitive of the Courteous
layer of SWSL-Rules comes in:
!- sendEmail(?Email) and optOut(?Email).
This constraint says that sendEmail(?Email)
and optOut(?Email)
cannot be true together for the same individual. For people who put
their names on the opt-out list, optOut(?Email)
will be true and, therefore, sendEmail(?Email)
will be false. On the other hand, for an email address, e,
that is not found on the opt-out list, the corresponding predicate
predicate optOut(e)
will not be provable and, by negation-as-failure, optOut(e)
will be assumed false. Therefore, sending email to that address will
not be blocked.
- Activity
-
Activity.
In the formal PSL ontology, the notion of activity is a basic construct,
which corresponds intuitively to a kind of (manufacturing
or processing) activity.
In PSL, an activity may have associated
occurrences, which
correspond intuitively to individual instances or
executions of the activity.
(We note that in PSL an activity is not a class or type with
occurrences as members; rather, an activity is an object,
and occurrences are related to this object by the
binary predicate
occurrence_of.)
The occurrences of an activity may impact
fluents (which provide an abstract
representation of the "real world").
In FLOWS, with each service there is an associated
activity (called the "service activity" of that service).
The service activity may specify aspects of the internal
process flow of the service, and also aspects of the
messaging interface of that service to other services.
- Channel
-
Channel.
In FLOWS, a channel is a formal conceptual object,
which corresponds intuitively to a repository and
conduit for messages.
The FLOWS notion of channel is quite primitive,
and under various restrictions can be used to model
the form of channel or message-passing as
found in web services standards,
including WSDL, BPEL, WS-Choreography, WSMO,
and also as found in several research investigations,
including process algrebras.
- FLOWS
-
First-order
Logic Ontology for Web Services.
FLOWS, also known as SWSO-FOL,
is the first-order logic version of the Semantic Web Services Ontology.
FLOWS is an extension of the PSL-OuterCore ontology, to
incorporate the fundamental aspects of
(web and other electronic) services, including service descriptors,
the service activity, and the service grounding.
- Fluent
-
Fluent.
In FLOWS, following PSL and the situation calculii, a
fluent is a first-order logic term or predicate whose
value may vary over time.
In a first-order model of a FLOWS theory, this
being a model of PSL-OuterCore,
time is represented as a discrete linear sequence
of timees, and
fluents has a value for each time in this sequence.
- Grounding
-
Grounding.
The SWSO concepts for describing service activities,
and the instantiations
of these concepts that describe a particular service activity, are
abstract specifications, in the sense that they do not specify
the details of particular message formats, transport protocols,
and network
addresses by which a Web service is accessed. The role of
the grounding is to provide these more concrete
details.
A substantial portion of the grounding can be acheived by
mapping SWSO concepts into corresponding WSDL constructs.
(Additional grounding, e.g., of some process-related aspects
of SWSO, might be acheived using other standards, such
as BPEL.)
- Message
-
Message.
In FLOWS, a message is a formal conceptual object,
which corresponds intuitively to a single message that
is created by a service occurrence, and read by zero
or more service occurrences.
The FLOWS notion of message is quite primitive, and
under various restrictions can be used to model
the form of messages as found in web services standards,
including WSDL (1.0 and 2.0), BPEL, WS-Choreography, WSMO,
and also as found in several research investigations.
A message has a payload, which corresponds
intuitively to the body or contents of the message.
In FLOWS emphasis is placed on the knowledge that
is gained by a service occurrence when reading a message
with a given payload
(and the knowledge needed to create that message.
- Occurrence
-
Occurence (of a service).
In FLOWS, a service S has an associated FLOWS activity
A (which
generalizes the notion of PSL activity).
An occurrence of S is formally
a PSL occurrence of the activity A.
Intuitively, this occurrence corresponds to
an instance or execution (from start to finish) of the activity
A, i.e., of the process associated with
service S.
As in PSL, an occurrence has a starting time
time and an ending time.
- PSL
-
Process Specification Language.
The Process Specification Language (PSL) is a
formally axiomatized ontology
[Gruninger03a,
Gruninger03b]
that has been
standardized as ISO 18629.
PSL provides a layered, extensible ontology
for specifying properties of processes.
The most basic PSL constructs are embodied in
PSL-Core; and PSL-OuterCore incorporates
several extensions of PSL-Core that includes
several useful constructs.
(An overview of concepts in PSL
that are
relevant to FLOWS is given in
Section 6 of the
Semantic Web Services Ontology document.)
- QName
-
Qualified name.
A pair (URI, local-name). The URI represents a
namespace and local-name represents a name used in an XML
document, such as a tag name or an attribute name.
In XML, QNames are syntactically
represented as prefix:local-name, where prefix is
a macro that expands into a concrete URI.
See Namespaces
in XML for more details.
- ROWS
-
Rules Ontology for Web Services.
ROWS, also known as SWSO-Rules,
is the rules-based version of the Semantic Web Services Ontology.
ROWS is created by a relatively straight-forward,
almost faithful,
transformation of FLOWS, the First-order Logic Ontology for
Web Services.
As with FLOWS, ROWS incorporates
fundamental aspects of
(web and other electronic) services, including service descriptors,
the service activity, and the service grounding.
ROWS enables a rules-based specification of a family of
services, including both the underlying ontology and
the domain-specific aspects.
- Service
-
(Formal) Service.
In FLOWS, a service is a conceptual object, that
corresponds intuitively to a web service (or other electronically
accessible service). Through binary predicates a service
is associated with various service descriptors (a.k.a.
non-functional properties) such as Service Name, Service Author,
Service URL, etc.; an activity (in the sense of
PSL) which specifies intuitively the process model associated with the
service; and a grounding.
- Service contract
- Describes an agreement between the service requester and service
provider,
detailing requirements on a service occurrence or family of
service occurrences.
- Service descriptor
-
Service Descriptor.
This is one of several non-functional properties
associated with services.
The Service Descriptors include
Service Name, Service Author, Service Contract Information,
Service Contributor, Service Description, Service URL,
Service Identifier, Service Version, Service Release Date,
Service Language, Service Trust, Service Subject,
Service Reliability, and Service Cost.
- Service offer description
-
Describes an abstract service (i.e. not a concrete instance of the service)
provided by a service provider agent.
- Service requirement description
-
Describes an abstract service required by a service requester agent,
in the context of service discovery, service brokering, or negotiation.
- sQName
-
Serialized QName.
A serialized QName is a shorthand representation of a URI. It is
a macro that expands into a full-blown URI.
sQNames are not QNames: the former are URIs, while the latter are
pairs (URI, local-name).
Serialized QNames were originally introduced in RDF as a notation for
shortening URI representation. Unfortunately,
RDF introduced confusion by adopting the term QName for something that is
different from QNames used in XML. To add to the confusion, RDF uses
the syntax for sQNames that is identical to XML's syntax for QNames.
SWSL distinguishes between QNames and sQNames, and uses the
syntax prefix#local-name for the latter.
Such an sQName expands into a full URI by concatenating the value
of prefix with local-name.
- URI
-
Universal Resource Identifier.
A symbol used to locate resources on the Web. URIs are defined by IETF. See
Uniform Resource Identifiers
(URI): Generic Syntax for more details.
Within the IETF standards the notion of URI is an extension
and refinement of the notions of Uniform Resource Locator (URL)
and Relative Uniform Resource Locators.
- [Berardi03]
- Automatic composition of e-services that export their
behavior.
D. Berardi, D. Calvanese, G. De Giacomo, M. Lenzerini, and M. Mecella.
In Proc. 1st Int. Conf. on Service Oriented Computing (ICSOC),
volume 2910 of LNCS, pages 43--58, 2003.
- [Bernstein2000]
- How can cooperative work tools support dynamic group
processes? Bridging the specificity frontier. A. Bernstein. In
Proc. Computer Supported Cooperative Work (CSCW'2000), 2000.
- [Bernstein2002]
- Towards High-Precision Service Retrieval. A.
Bernstein, and M. Klein. In
Proc. of the first International Semantic Web Conference (ISWC'2002),
2002.
- [Bernstein2003]
- Beyond Monotonic Inheritance: Towards Semantic Web
Process Ontologies. A. Bernstein and B.N. Grosof (NB: authorship
sequence is alphabetic). Working Paper, Aug. 2003. Available at: http://ebusiness.mit.edu/bgrosof/#beyond-mon-inh-basic.
- [Bonner93]
- Database Programming in Transaction Logic. A.J.
Bonner, M. Kifer, M. Consens. Proceedings of the 4-th Intl.~Workshop on
Database Programming Languages,
C. Beeri, A. Ohori and D.E. Shasha
(eds.), 1993. In Springer-Verlag Workshops in Computing Series, Feb.
1994: 309-337.
- [Bonner98]
- A Logic for Programming Database Transactions.
A.J. Bonner, M. Kifer. Logics for Databases and Information Systems, J.
Chomicki and G. Saake (eds.). Kluwer Academic Publishers, 1998: 117-166.
- [Bruijn05]
- Web Service Modeling Ontology (WSMO).
J. de Bruijn, C. Bussler, J. Domingue,
D. Fensel, M. Hepp, M. Kifer, B. Kaenig-Ries, J. Kopecky,
R. Lara, E. Oren, A. Polleres, J. Scicluna, M. Stollberg.
DERI Technical Report.
- [BPML 1.0]
- A. Arkin.
Business Process Modeling Language.
BPMI.org, 2002
- [BPEL 1.1]
-
Business Process Execution Language for Web Services, Version 1.1
. S. Thatte, editor.
OASIS Standards Specification, May 5, 2003.
- [Bultan03]
- Conversation specification: A new approach to design and
analysis of e-service composition.
T. Bultan, X. Fu, R. Hull, and J. Su. In Proc. Int. World Wide
Web Conf. (WWW), May 2003.
- [Chang73]
- Symbolic Logic and Mechanical Theorem Proving.
C.L. Chang and R.C.T. Lee. Academic Press, 1973.
- [Chen93]
- HiLog: A Foundation for Higher-Order Logic Programming.
W. Chen, M. Kifer, D.S. Warren. Journal of Logic Programming, 15:3,
February 1993, 187-230.
- [Chimenti89]
- Towards an Open Architecture for LDL. D. Chimeti,
R. Gamboa, R. Krishnamurthy, VLDB Conference, 1989: 195-203.
- [deGiacomo00]
- ConGolog, A Concurrent Programming Language Based on the
Situation
Calculus.
G. de Giacomo, Y. Lesperance, and H. Levesque.
Artificial Intelligence, 121(1--2):109--169, 2000.
- [Fu04]
- WSAT: A Tool for Formal Analysis of Web Services.
X. Fu, T. Bultan, and J. Su. 16th International Conference on
Computer Aided Verification (CAV), July 2004.
- [Frohn94]
- Access to Objects by Path Expressions and Rules.
J. Frohn, G. Lausen, H. Uphoff. Intl. Conference on Very Large
Databases, 1994, pp. 273-284.
- [Gosling96]
- The Java language specification.Gosling, James,
Bill Joy, and Guy L. Steele. 1996. Reading, Mass.: Addison-Wesley.
- [Grosof99a]
- A Courteous Compiler From Generalized Courteous Logic
Programs To Ordinary Logic Programs. B.N. Grosof. IBM Report
included as part of documentation in the IBM CommonRules 1.0 software
toolkit and documentation, released on http://alphaworks.ibm.com. July
1999. Also available at:
http://ebusiness.mit.edu/bgrosof/#gclp-rr-99k.
- [Grosof99b]
-
A Declarative Approach to Business Rules in Contracts.
B.N. Grosof, J.K. Labrou, and H.Y. Chan.
Proceedings of the 1st ACM Conference on Electronic Commerce (EC-99).
Also available at:
http://ebusiness.mit.edu/bgrosof/#econtracts+rules-ec99.
- [Grosof99c]
-
DIPLOMAT: Compiling Prioritized Default Rules Into Ordinary
Logic Programs (Extended Abstract of Intelligent Systems Demonstration).
B.N. Grosof. IBM Research Report RC 21473, May 1999.
Extended version of 2-page refereed conference paper
appearing in Proceedings of the National Conference on
Artificial Intelligence (AAAI-99), 1999. Also available at:
http://ebusiness.mit.edu/bgrosof/#cr-ec-demo-rr-99b.
- [Grosof2003a]
- Description Logic Programs: Combining Logic Programs with
Description Logic. B.N. Grosof, I. Horrocks, R. Volz, and S.
Decker. Proceedings of the 12th International Conference on the World
Wide Web (WWW-2003). Also available at: http://ebusiness.mit.edu/bgrosof/#dlp-www2003.
- [Grosof2004a]
- Representing E-Commerce Rules Via Situated Courteous
Logic Programs in RuleML. B.N. Grosof. Electronic Commerce
Research and Applications, 3:1, 2004, 2-20. Preprint version is also
available at: http://ebusiness.mit.edu/bgrosof/#.
- [Grosof2004b]
- SweetRules: Tools for Semantic Web Rules and Ontologies,
including Translation, Inferencing, Analysis, and Authoring.
B.N. Grosof, M. Dean, S. Ganjugunte, S. Tabet, C. Neogy, and D. Kolas.
http://sweetrules.projects.semwebcentral.org. Software toolkit and
documentation. Version 2.0, Dec. 2004.
- [Grosof2004c]
- Hypermonotonic Reasoning: Unifying Nonmonotonic Logic
Programs with First Order Logic. B.N. Grosof.
http://ebusiness.mit.edu/bgrosof/#HypermonFromPPSWR04InvitedTalk.
Slides from Invited Talk at Workshop on Principles and Practice of
Semantic Web Reasoning (PPWSR04), Sep. 2004; revised Oct. 2004. Paper
in preparation.
- [Grosof2004d]
- SweetPH: Using the Process Handbook for Semantic Web
Services. B.N. Grosof and A. Bernstein.
http://ebusiness.mit.edu/bgrosof/#SweetPHSWSLF2F1204Talk. Slides
from Presentation at SWSL Meeting, Dec. 9-10, 2004. Note: Updates
the design in the 2003 Working Paper "Beyond Monotonic Inheritance:
Towards Semantic Web Process Ontologies" and describes implementation.
- [Grosof2004e]
-
SweetDeal: Representing Agent Contracts with Exceptions using
Semantic Web Rules, Ontologies, and Process Descriptions.
B.N. Grosof and T.C. Poon.
International Journal of Electronic Commerce (IJEC), 8(4):61-98, Summer 2004
Also available at:
http://ebusiness.mit.edu/bgrosof/#sweetdeal-exceptions-ijec.
- [Grosof2004f]
-
Semantic Web Rules with Ontologies, and their E-Business Applications.
B.N. Grosof and M. Dean.
Slides of Conference Tutorial (3.5-hour) at the 3rd International Semantic
Web Conference (ISWC-2004).
Available at:
http://ebusiness.mit.edu/bgrosof/#ISWC2004RulesTutorial.
- [Gruninger03a]
-
A Guide to the Ontology of the Process Specification Language.
M. Gruninger.
Handbook on Ontologies in Information Systems.
R. Studer and S. Staab (eds.). Springer Verlag, 2003.
-
[Gruninger03b]
-
Process Specification Language: Principles and Applications.
M. Gruninger and C. Menzel.
AI Magazine, 24:63-74, 2003.
- [Gruninger03c]
-
Applications of PSL to Semantic Web Services.
M. Gruninger.
Workshop on Semantic Web and Databases. Very Large Databases Conference, Berlin.
- [Hayes04]
- RDF Model Theory.
Hayes, P. W3C, February 2004.
- [Helland05]
- Data on the Outside Versus Data on the Inside.
P. Helland. Proc.
2005 Conf. on Innovative Database Research (CIDR), January,
2005.
- [Hull03]
- E-Services: A Look Behind the Curtain.
R. Hull, M. Benedikt, V. Christophides, J. Su. Proc. of the ACM
Symp. on Principles of Database Systems (PODS), San Diego, June,
2003.
- [Kifer95]
- Logical Foundations of Object-Oriented and Frame-Based
Languages, M. Kifer, G. Lausen, J. Wu. Journal of ACM, 1995, 42,
741-843.
- [Kifer04]
- A Logical Framework for Web Service Discovery, M.
Kifer, R. Lara, A. Polleres, C. Zhao. Semantic Web Services Workshop,
November 2004, Hiroshima, Japan.
- [Klein00a]
- Towards a Systematic Repository of Knowledge About
Managing Collaborative Design Conflicts. Klein, Mark.
2000. Proceedings of the Conference on Artificial Intelligence in
Design. Boston, MA, USA.
- [Klein00b]
- A Knowledge-Based Approach to Handling Exceptions in
Workflow Systems. Klein, Mark, and C. Dellarocas. 2000.
Computer Supported Cooperative Work: The Journal of Collaborative
Computing 9:399-412.
- [Lloyd87]
- Foundations of logic programming (second, extended edition).
J. W. Lloyd. Springer series in symbolic computation. Springer-Verlag,
New York, 1987.
- [Lindenstrauss97]
- Automatic Termination Analysis of Logic Programs.
N. Lindenstrauss and Y. Sagiv. International Conference on Logic
Programming (ICLP), 1997.
- [Maier81]
- Incorporating Computed Relations in Relational Databases.
D. Maier, D.S. Warren. SIGMOD Conference, 1981: 176-187.
- [Malone99]
- Tools for inventing organizations: Toward a handbook of
organizational processes. T. W. Malone, K. Crowston, J. Lee, B.
Pentland, C. Dellarocas, G. Wyner, J. Quimby, C. Osborne, A. Bernstein,
G. Herman, M. Klein, E. O'Donnell. Management Science, 45(3),
pages 425--443, 1999.
- [McIlraith01]
- Semantic Web Services.
IEEE Intelligent Systems, Special Issue on the
Semantic Web, S. McIlraith, T.Son and H. Zeng.
16(2):46--53, March/April, 2001.
- [Milner99]
- Communicating and Mobile Systems: The π-Calculus.
R. Milner. Cambridge University Press, 1999.
- [Narayanan02]
- Simulation, Verification and Automated Composition of Web
Services. S. Narayanan and S. McIlraith.
In Proceedings of the Eleventh International World Wide Web
Conference (WWW-11), May, 2002.
- [Ontobroker]
-
Ontobroker 3.8. Ontoprise, GmbH.
- [OWL Reference]
- OWL
Web Ontology Language 1.0 Reference. Mike Dean, Dan
Connolly, Frank van Harmelen, James Hendler, Ian Horrocks, Deborah L.
McGuinness, Peter F. Patel-Schneider, and Lynn Andrea Stein. W3C
Working Draft 12 November 2002. Latest version is available at http://www.w3.org/TR/owl-ref/.
- [OWL-S 1.1]
- OWL-S:
Semantic Markup for Web Services. David Martin, editor. Technical Overview
(associated with OWL-S Release 1.1).
- [Papazoglou03]
- Service-Oriented Computing: Concepts,
Characteristics and Directions.
M.P. Papazoglou.
Keynote for the 4th International Conference on Web Information
Systems Engineering (WISE 2003), December 10-12, 2003.
- [Perlis85]
- Languages with Self-Reference I: Foundations. D.
Perlis. Artificial Intelligence, 25, 1985, 301-322.
- [Preist04]
- A Conceptual Architecture for Semantic Web Services, C. Preist, 1993.
In Proceedings of Third International Semantic Web Conference, Nov. 2004:
395-409.
- [Reiter01]
- Knowledge in Action: Logical Foundations for Specifying and
Implementing Dynamical Systems.
Raymond Reiter. MIT Press. 2001
- [Scherl03]
- Knowledge, Action, and the Frame Problem.
R. B. Scherl and H. J. Levesque. Artificial Intelligence,
Vol. 144, 2003, pp. 1-39.
- [Singh04]
- Protocols for Processes: Programming in the Large for Open
Systems.
M. P. Singh, A. K. Chopra, N. V. Desai, and A. U. Mallya. Proc. of
the 19th Annual ACM Conf. on Object-Oriented Programming, Systems,
Languages, and Applications (OOPSLA), Vancouver, October 2004.
- [SWSL Requirements]
- Semantic Web Services Language Requirements.
B. Grosof, M. Gruninger, et al, editors.
White paper of the Semantic Web Services Language Committee.
- [UDDI v3.02]
-
Universal Description, Discovery and Integration (UDDI)
protocol. S. Thatte, editor.
OASIS Standards Specification, February 2005.
- [VanGelder91]
- The Well-Founded Semantics for General Logic Programs.
A. Van Gelder, K.A. Ross, J.S. Schlipf. Journal of ACM, 38:3, 1991,
620-650.
- [WSCL 1.0]
- Web Services
Conversation Language (WSCL) 1.0. A. Banerji et al. W3C Note, March 14, 2002.
- [WSDL 1.1]
-
Web Services Description
Language (WSDL) 1.1. E. Christensen, F. Curbera,
G. Meredith, and S. Weerawarana. W3C Note, March 15, 2001.
- [WSDL 2.0]
-
Web Services Description
Language (WSDL) 2.0 --
Part 1: Core Language. R. Chinnici, M. Gudgin, J.-J. Moreau, J. Schlimmer, and S. Weerawarana.
W3C Working Draft,
August 3, 2004.
- [WSDL 2.0 Primer]
-
Web Services Description
Language (WSDL) Version 2.0 --
Part 0: Primer. D. Booth, C. Liu, editors.
W3C Working Draft,
21 December 2004.
- [WS-Choreography]
- Web Services
Choreography Description Language Version 1.0. N. Kavantzas, D. Burdett, et. al., editors. W3C
Working Draft, December 17,
2004.
- [XSLT]
- XSL Transformations (XSLT) Version
1.0. J. Clark, editor. W3C
Recommendation, 16 November 1999.
- [XQuery 1.0]
- XQuery 1.0: An XML Query
Language. S. Boag, D. Chamberlin, et al, editors.
W3C Working Draft 04 April 2005.
- [Yang02]
- Well-Founded Optimism: Inheritance in Frame-Based
Knowledge Bases. G. Yang, M. Kifer. Intl. Conference on
Ontologies, DataBases, and Applications of Semantics for Large Scale
Information Systems (ODBASE), October 2002.
- [Yang03]
- Reasoning about Anonymous Resources and Meta Statements
on the Semantic Web. G. Yang, M. Kifer. Journal on Data
Semantics, Lecture Notes in Computer Science 2800, Springer Verlag,
September 2003, 69-98.
- [Yang04]
- FLORA-2 User's
Manual. G. Yang, M. Kifer, C. Zhao, V. Chowdhary. 2004.