RDF HDT (Header-Dictionary-Triples) is a binary format for publishing and exchanging RDF data at large scale. RDF HDT represents RDF in a compact manner, natively supporting splitting huge RDF graphs into several chunks. It is designed to allow high compression rates. This is achieved by organizing and representing the RDF graph in terms of two main components: Dictionary and Triples structure. The Dictionary organizes all vocabulary present in the RDF graph in a manner that permits rapid search and high levels of compression. The Triples component comprises the pure structure of the underlying graph in a compressed form. An additional and RECOMMENDED Header component includes extensible metadata describing the RDF data set and its organization. Further, the document specifies how to efficiently translate between HDT and other RDF representation formats, such as Notation 3.
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications can be found in the W3C technical reports index at http://www.w3.org/TR/.
This document is a part of the HDT Submission which comprises five documents:
- Binary RDF Representation for Publication and Exchange (HDT)
- Extending VoID for publishing HDT
- RDF Schema for HDT Header Descriptions
- Relationship of HDT to relevant other technologies
- Implementation of HDT
By publishing this document, W3C acknowledges that the Submitting Members have made a formal Submission request to W3C for discussion. Publication of this document by W3C indicates no endorsement of its content by W3C, nor that W3C has, is, or will be allocating any resources to the issues addressed by it. This document is not the product of a chartered W3C group, but is published as potential input to the W3C Process. A W3C Team Comment has been published in conjunction with this Member Submission. Publication of acknowledged Member Submissions at the W3C site is one of the benefits of W3C Membership. Please consult the requirements associated with Member Submissions of section 3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member Submissions.
Table of Contents
1. Introduction
This document defines the RDF HDT format, an RDF data-centric format which reduces verbosity in favor of machine-understandability and data management.
HDT introduces a new representation format using the skewed structure of big RDF graphs to achieve large spatial savings. It is based on two main components (as shown in Figure 1):
- Dictionary, organizes all vocabulary present in the RDF graph in a manner that avoids repetitions and permits rapid search and high levels of compression.
- Triples, comprises the pure structure of the underlying graph, avoiding noise produced by long labels, repetitions, etc.
Additionally, a RECOMMENDED Header component SHOULD include logical and physical metadata required to describe the RDF data set.
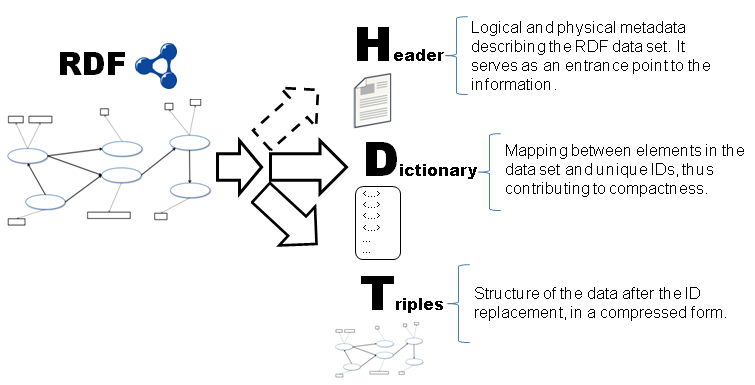 Figure 1: HDT Components: Header-Dictionary-Triples (PNG)
Figure 1: HDT Components: Header-Dictionary-Triples (PNG)
The aims of the format are:
- Compactness, use much less space, saving thus storing space and communication bandwidth and time.
- Clean Publication and exchange, separate dictionary from triples (the graph structure), includes a header with metadata about provenance and statistics about data.
- On-demand indexed accessing, permits basic data operations, accesing parts of the file without having to process all of it.
- RDF compression, improvements with respect to universal compressors.
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119]
2. Basic Concepts
[Definition:] A program module called an HDT processor, whether it is
software or hardware, is used by application programs to encode their data into HDT core data
and/or to decode HDT core data to
make the data accessible.
The former and latter aforementioned roles of HDT processors are called [Definition:]
HDT encoder and [Definition:] HDT decoder
respectfully.
[Definition:] HDT core data consists of the Dictionary and Triples information
of the HDT representation, whether it is present in a unique or several files or streams. This core data MUST be self-contained, i.e.,
it MUST contain enough information to consume the data set. Each file or stream belonging to the HDT core data
is headed by control information and followed by the [Definition:] HDT body which can be the full or part of the Dictionary component or the Triples component or both. Note that the optional Header is out of the
definition of the HDT core data, constituting a different file or stream.
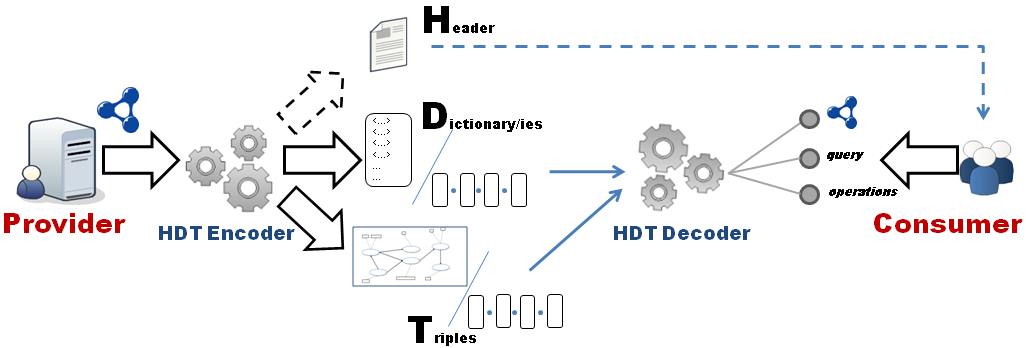 Figure 2: The process of HDT encoding/decoding (PNG)
Figure 2: The process of HDT encoding/decoding (PNG)
Figure 2 shows a typical producer/consumer case in HDT. First, the content producer makes use of an
HDT encoder in order to generate HDT from RDF content. The Header, if present, can be retrieved by the consumer in order to get metadata
about the dataset and the publication. In turn, the consumer uses an
HDT decoder to efficiently access the HDT core data. Furthermore, the
HDT decoder SHOULD provide the consumer with distinct access possibilities, such as getting the original full RDF document, querying over the data or several management operations.
3. HDT Syntax
The syntax of HDT is given by the syntax of the Dictionary codification and the Triples encoding. If the additional Header component exists,
it SHOULD follow a standard vocabulary for describing RDF data sets.
The use of an extension of VoID for publishing HDT is strongly RECOMMENDED.
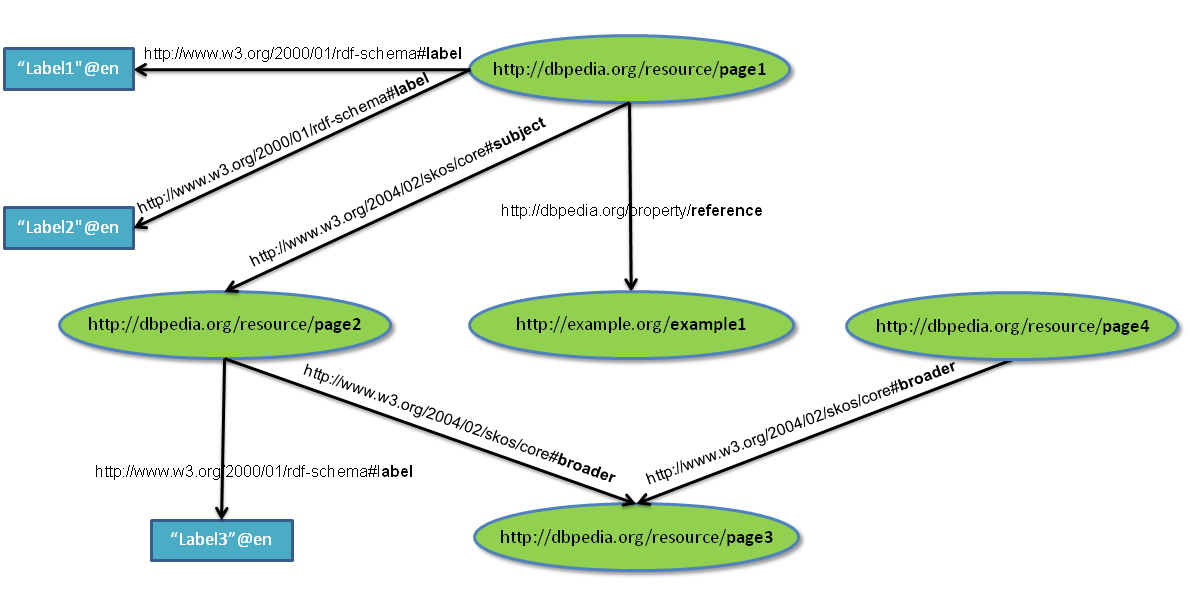 Example 1: RDF graph example of DBpedia. (PNG)
Example 1: RDF graph example of DBpedia. (PNG)
Example 1 shows a brief RDF graph example from DBpedia in which pages are described with labels, they can reference other external pages and they are categorized through other DBpedia category pages. Example 2 shows the skeleton conversion of Example 1 to RDF HDT.
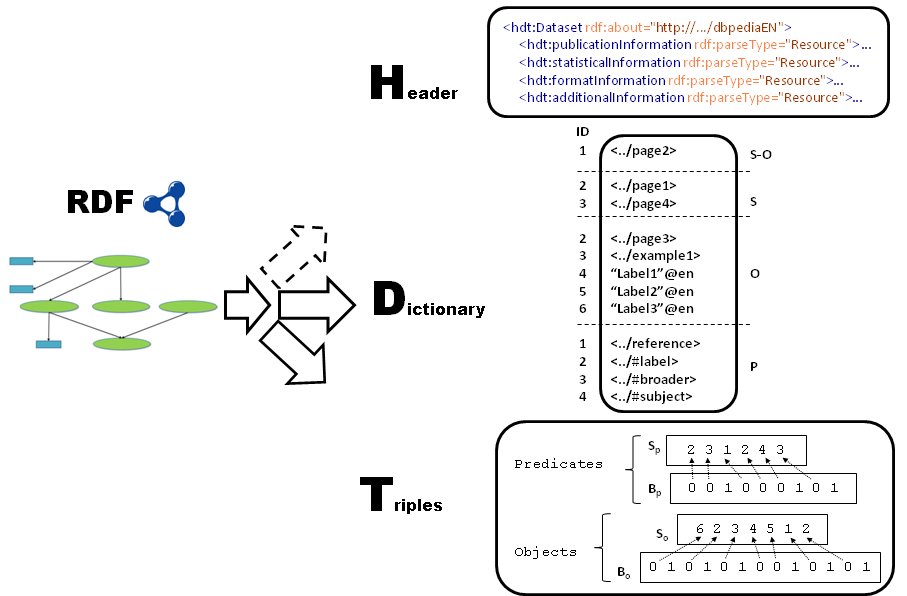 Example 2: A construction of the HDT format for the Example 1 (PNG)
Example 2: A construction of the HDT format for the Example 1 (PNG)
The Header is an optional component containing metadata about the data publication together with information to retrieve and process the
HDT core data. If the additional Header component exists, it
SHOULD be an RDF graph. This allows expressing metadata about the
data set (originally in RDF) with an RDF syntax, which can be discovered and used through well-known mechanisms, such as SPARQL Endpoints.
The use of [VoID] as the main vocabulary of the Header and/or an extension of VoID for publishing HDT are strongly RECOMMENDED.
3.2 Control Information
Each Dictionary and Triples component, as well as subparts of them in case of splitting, is headed by a sequence representing control information.
[Definition:] The Control Information can identify Dictionary and Triples components or subparts of them, distinguish HDT core data streams from text, identify the version of the HDT format being used, and specify the options used to process the HDT core data. The control information has the following structure:
The HDT Options field is optional and its presence is indicated by
the value of the presence bit that follows the HDT Component Distinguishing Bits.
If the HDT Options are present (presence bit sets to '1'), then a final reserved word "$END" MUST be added at the end of the Control Information to delimit its length.
The details of each field within the control information are described in the following sections.
3.2.1 HDT Cookie
[Definition:]
The Control Information starts with an HDT Cookie,
which is a four byte field that serves to indicate that the file or stream of which it is a part is
HDT core data.
The four byte field consists of four characters
" $ " , " H ", " D " and " T "
in that order, each represented as an ASCII octet, as follows.
This four byte sequence is particular to HDT and specific enough to distinguish HDT files and streams from a broad range of data types currently used on the Web.
3.2.2 HDT Format Version
[Definition:]
The second part of the Control Information is the HDT Format Version, which identifies the
version of the HDT format being used. The HDT format version number corresponding with this document is 1 (one).
The version is a sequence of one or more 4-bit unsigned integers. The first bit set to 1 indicates that the next 4-bits must be read. The version number is determined by summing each sequence of 4-bit unsigned integers and adding 1 (one). There are examples of versions:
| HDT Format Version |
Stands for |
| 0000
|
Version 1
|
| 0111
|
Version 8
|
| 1000 0000
|
Version 9
|
| 1000 0001
|
Version 10
|
3.2.3 HDT Component Distinguishing Bits
[Definition:]
The third part of the Control Information consists in the HDT Component Distinguishing Bits, which identify the
component or components of the HDT body that follow the Control Information.
The HDT Component Distinguishing Bits are three bits. The combination of the first two bits identifies the information below the HDT Control Information, as follows:
| HDT Component Distinguishing first and second bits |
Stands for |
| 01
|
Dictionary Component
|
| 10
|
Triples Component
|
| 11
|
both Dictionary and Triples Component
|
| 00
|
Reserved
|
The third bit set to 1 indicates that the current file or stream is a subpart of the entire component.
When both Dictionary and Triples Component, i.e.
HDT core data follow the Control Information.
3.2.4 HDT Options
[Definition:]
The fifth part of the Control Information, if present, consists in the HDT Options, which provides a mechanism
to specify the options of the encoded component or components of the HDT body. It MUST include all the required information to decode the data.
The HDT Options are represented as text with a <property>:<value>; scheme.
The presence of HDT Options is optional in the Control Information, and it is predicated on the value of the presence bit that follows the Distinguishing Bits.
When HDT Options are present, an HDT Processor MUST observe the specified options to process the HDT body. Otherwise, an HDT Processor may follow
the default values. If the Header component is present and it informs about such information, their values override the default ones. In case of conflicts, the HDT Options override the information of the Header.
The following table describes the HDT options that may be specified in the Control Information.
Below is a brief description of each option.
[Definition:]
The codification is used to identify the concrete codification scheme used to process the HDT body.
This MUST be an URI identifying the codification of the component or components indicated by the HDT Component Distinguishing Bits.
When the codification option is absent, undefined or empty, no statement is made about the codification scheme, therefore an HDT Processor SHOULD assume the codification by default of the component or components indicated by the HDT Component Distinguishing Bits, unless other information is communicated out of band.
The following table shows the URIs of the codifications by default and the section with detailed information:
| HDT Component |
Codification by default |
Details |
| Dictionary Component
|
http://purl.org/HDT/hdt#dictionaryPlain
|
Section 3.3.2
|
| Triples Component
|
http://purl.org/HDT/hdt#triplesBitmap
|
Section 3.4.3
|
| both Dictionary and Triples Component
|
http://purl.org/HDT/hdt#globalBitmap
|
Section 3.4
|
[Definition:]
The format sets up the MIME type of the HDT body. When the format option is absent, undefined or empty, an HDT Processor SHOULD assume the format by default of the component or components indicated by the HDT Component Distinguishing Bits, unless other information is communicated out of band.
The following table shows the formats by default:
| HDT Component |
Format by default |
| Dictionary Component
|
text/plain
|
| Triples Component
|
application/octetstream
|
| both Dictionary and Triples Component
|
multipart/mixed
|
[Definition:]
The user defined meta-data sets up auxiliary properties with additional control information to process the data. The syntax and semantic of the user defined properties depend on the codification of the HDT body, thus HDT Processor MUST interpret the user defined properties within the codification context.
User defined properties MUST follow the following naming conventions to prevent conflicts between different component properties:
| HDT Component involved |
Rules for naming user defined properties |
| Dictionary Component
|
Property names MUST start with one unique dollar sign('$') character followed by alphanumeric characters.
|
| Triples Component
|
Property names MUST start with two unique dollar signs ('$$') characters followed by alphanumeric characters.
|
| both Dictionary and Triples Component
|
Property names MUST start with three unique dollar signs('$$$') characters followed by alphanumeric characters.
|
3.3 Dictionary
The goal of the Dictionary is to assign a unique ID to each element in the data set. This way, the dictionary contributes to the aim of
compactness, by replacing the long repeated strings in triples by their short IDs. In fact, the assignment of IDs, named as mapping, is usually the first step in RDF indexing.
There is no restriction on the particular mapping or codification. A dictionary codification by default is given, and it
MUST be assumed by HDT Processors
when no other codification scheme is specified in the codification option or in the Header
component.
3.3.1 Dictionary Encoding
The distinction between URIs, literals and blanks, as well as string escaping, follows a similar N3 syntax:
-
URIs are delimited by angle brackets '<' and '>'. Whitespace within the angle brackets is to be ignored.
-
URIs can be absolute or relative to the base URI (defined in the user defined meta-data or in the Header component).
-
URIs can make use of prefixes (defined in the user defined meta-data or in the Header component) or predefined prefixes (described below).
-
Blanks are named with the _: namespace prefix, e.g. _:b19 represents a blank node.
-
Literals are written using double-quotes (e.g. "literal"). The """literal""" string form is used when they may contain linebreaks.
-
Literals represented numbers or booleans can be written directly corresponding to the right XML Schema Datatype: xsd:integer, xsd:double, xsd:decimal or xsd:boolean.
-
Comments are not allowed in any form.
Predefined prefixes:
| Prefix |
Stands for |
| a
|
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
|
| =
|
<http://www.w3.org/2002/07/owl#sameAs>
|
|
=>
|
<http://www.w3.org/2000/10/swap/log#implies>
|
|
<=
|
<http://www.w3.org/2000/10/swap/log#implies> but in the inverse direction
|
String escaping sequences:
| Escape Sequence |
Stands for |
| \newline
|
Ignored
|
| \\
|
Backslash (\)
|
| \'
|
Single quote (')
|
| \"
|
Double quote (")
|
| \n
|
ASCII Linefeed (LF)
|
| \r
|
ASCII Carriage Return (CR)
|
| \t
|
ASCII Horizontal Tab (TAB)
|
| \uhhhh
|
character in BMP with Unicode value U+hhhh
|
| \U00hhhhhh
|
character in plane 1-16 with Unicode value U+hhhhhh
|
3.3.2 Dictionary Codification by Default
The dictionary codification by default, referred to as http://purl.org/HDT/hdt#dictionaryPlain, MUST be assumed by HDT Processors
when no other codification scheme is specified in the codification option or in the Header
component.
Four subsets are mapped as follows (for a graph G with SG, PG, OG the different subjects, predicates and objects):
- 1. Common subject-objects (SOG) with IDs from 1 to |SOG|
- 2. Non common subjects (SG-SOG), mapped to [|SOG| +1, |SG|]
- 3. Non common objects (OG-SOG), in [|SOG|+1, |OG|]
- 4. Predicates, mapped to [1, |PG|].
Common subject-objects avoids duplicating entries in the dictionary and thus reducing the dictionary size. Furthermore, these elements are well and fast localized in the top IDs, as they conform the basis of subject-object JOINs in SPARQL. The common subject-object proportion is measured by the definition of subject-object ratio in [HDT-ISWC2010].
The physical Dictionary component consists in a list of strings matching the mapping of the four subsets, in order from (1) to (4),as shown in Example 3. A reserved '\2' character is appended to the end of
each string and each vocabulary to delimit their size.
Example 3 expands the Example 1 to show the RDF graph and the Dictionary in HDT, by default.
<http://dbpedia.org/resource/page2> \2\2 <http://dbpedia.org/resource/page1>\2 <http://dbpedia.org/resource/page4> \2\2 <http://dbpedia.org/resource/page3>\2 <http://example.org/example1> \2 "Label1"@en \2 "Label2"@en \2\2 <http://dbpedia.org/property/reference> \2 <http://www.w3.org/2000/01/rdf-schema#label> \2 <http://www.w3.org/2004/02/skos/core#broader> \2 <http://www.w3.org/2004/02/skos/core#subject> \2\2
Example 3: RDF graph and dictionary representation.
The dictionary codification by default allows to parametrize the configuration by some user defined meta-data, as follows:
| User defined property |
Use |
| $dictionaryEncoding
|
Set up the dictionary encoding. By default, utf8.
|
| $dictionarySeparator
|
Define the reserved separator character. The default value is '\2'.
|
| $dictionaryOrder
|
Describe the order inside each defined subset in the dictionary. By default there is no implicit order.
|
| $dictionaryPrefixBaseURI
|
Set up the base prefix to be used in the dictionary when parsing relative URIs.
|
|
$dictionaryPrefixLabel_1, $dictionaryPrefixLabel_2, etc.
|
Set up prefixes labels to be used in the dictionary.
|
|
$dictionaryPrefixURI_1, $dictionaryPrefixURI_2, etc.
|
Set up the corresponding URIs to the predefined prefix labels.
|
| $dictionarySequence
|
Identify the order in the sequence of all the dictionary chunks in case of splitting the dictionary in several files or streams.
|
If the dictionary is split in several files or streams, each chunk MUST be interpreted as a continuous order in the mapping sequence, following the $dictionarySequence property.
3.4 Triples
The Triples component contains the structure of the data after the ID replacement, comprising the pure structure of the underlying graph.
There is no restriction on a particular codification for the Triples component, but three types of codification are specified in this document. Example 4 shows the three given codifications within the Example 1. These possibilities are described in the next subsections. Further triple codifications MAY be established by specifying a concrete codification option or by the Header component. The codification by default MUST be interpreted as Bitmap Triples (referred to as http://purl.org/HDT/hdt#triplesBitmap) by HDT Processors.
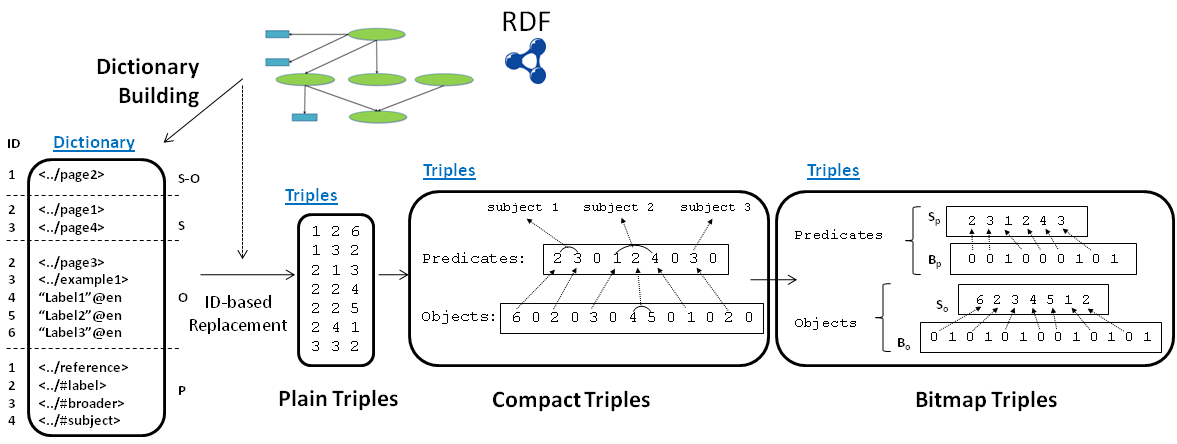 Example 4: Three possibilities of triple representations succeeding the dictionary creation for the Example 1 (PNG)
Example 4: Three possibilities of triple representations succeeding the dictionary creation for the Example 1 (PNG)
When the same file or stream comprises both the dictionary component and the triples component, then a secondary Control Information MUST be included in between the two streams, identifying the HDT Component Distinguishing Bits of each stream.
3.4.1 Plain Triples
This is the most naive approach in which only the ID substitution is performed. This option is denoted by the http://purl.org/HDT/hdt#triplesPlain codification
property.
The physical file contains three ID per triple, each of them codified with 32 bits by default. The codification allows to parametrize the configuration
by some user defined meta-data, as follows:
| User defined property |
Use |
| $$IDCodificationBits
|
The number of bits of each ID. The default value is set to 32. The value logBits must be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects, predicates or objects.
|
| $$subjectCodificationBits
|
The number of bits of the subject IDs. This element must supersede the $$IDCodificationBits if both properties coexist in the same configuration. The value logBits must be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects.
|
| $$predicateCodificationBits
|
The number of bits of the predicate IDs. This element must supersede the $$IDCodificationBits if both properties coexist in the same configuration. The value logBits must be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total predicates.
|
| $$objectCodificationBits
|
The number of bits of the object IDs. This element must supersede the $$IDCodificationBits if both properties coexist in the same configuration. The value logBits must be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total objects.
|
| $$triplesSequence
|
Identify the order in the sequence of all the triples chunks in case of splitting the triples in several files or streams.
|
If the triples are split in several files or streams, each chunk MUST be interpreted as a continuous order, following the $$triplesSequence property.
A specific number of bits for each element is available using $$subjectCodificationBits, $$predicateCodificationBits and $$objectCodificationBits. This provides flexibility
and space savings, e.g. keeping the default codification to 32 bits but specifying a $$predicateCodificationBits property, because the limited size of the predicates
allows them to be represented with fewer bits.
3.4.2 Compact Triples
This option is denoted by the http://purl.org/HDT/hdt#triplesCompact codification property, and it implies a
triple sorting by subject and the creation of predicate and object adjacency lists.
Adjacency List is a natural data structure that facilitates managing, searching, and a
good compromise of size (as compared to naive lists of tuples or triples). For example,
the set of triples:
{(s, p1, o11), ... ,(s, p1, o1n1), (s, p2, o21), ... ,(s, p1, o2n2), ... ,(s, pk, oknk )}
can be written as the adjacency list (named S-P-O Adj. List):
s → [(p1, (o11, ..., o1n1), (p2, (o21, ...,o2n2)), ... ,(pk, (oknk))].
Turtle (and hence N3) allows such generalized adjacency lists for triples. For example the set of triples {(s, p, oj)} 1≤j≤ n, can be abbreviated as (s p o1, ... ,on).
The Triples component contains a compact adjacency list representation, whose construction process is shown in Example 5.
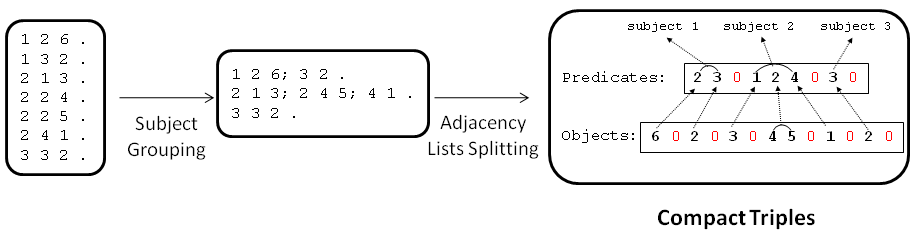 Example 5: Compact Transformation from ID-based triples. (PNG)
Example 5: Compact Transformation from ID-based triples. (PNG)
First, a subject ordered grouping is performed, that is, triples are reorganized
in an adjacency list, in sequential order of subject IDs. Due to this order, an
immediate saving can be achieved by omitting the subject representation, as we know
the first list corresponds to the first subject, the second list to the following, and so on.
Then, the representation is split into two coordinated streams of Predicates
and Objects. The first stream of Predicates corresponds to the lists of predicates
associated with subjects, maintaining the implicit grouping order.
The end of a list of predicates implies a change of subject, and must be marked with a separator, the
non-assigned zero ID. The second stream (Objects) groups the lists of objects for each
pair (s, p). These pairs are formed by the subjects (implicit and sequential), and coordinated
predicates following the order of the first stream. In this case, the end of a list
of objects (also marked in the stream with the non-assigned zero ID) implies a change of (s, p) pair, moving forward
in the first stream processing.
Thus, the compact triple representation is supported by two Streams: (1)
a predicate stream in which the predicate lists are separated by
0s (i-th list belongs to i-th subject) and (2) an object stream in which
the object lists are separated in the same way (j-th list belongs to j-th predicate in the
former predicate stream).
This format, by default, assumes an S-P-O Adj. List, being S implicitly represented and P as the key stream to access the secondary stream of objects.
Alternative representations are also possible, specifying a $$streamsOrder property in the
user defined meta-data or in the Header Component, as follows:
| $$streamsOrder property value |
Stands for |
| SPO
|
Set up the order of the streams as Subject-Property-Object Adj. Lists. This MUST be taken as the default order of the streams.
|
| SOP
|
Set up the order of the streams as Subject-Object-Property Adj. Lists.
|
| PSO
|
Set up the order of the streams as Property-Subject-Object Adj. Lists.
|
| POS
|
Set up the order of the streams as Property-Object-Subject Adj. Lists.
|
| OPS
|
Set up the order of the streams as Object-Property-Subject Adj. Lists.
|
| OSP
|
Set up the order of the streams as Object-Subject-Property Adj. Lists.
|
In every case, the first stream is implicit and then it is not represented, and the second stream acts as the key stream to access the secondary stream.
Both the key stream and the secondary stream can be defined in the same HDT body or in different files or streams.
When the HDT body only comprises one unique stream, its function
MUST be defined with the $$streamFunction property in the
user defined meta-data or in the Header Component, as follows:
| $$streamFunction property value |
Stands for |
| key
|
Identify the current stream as the key stream.
|
| secondary
|
Identify the current stream as the secondary stream.
|
Other
user defined meta-data or Header information can also be defined for the stream, as follows:
| User defined property |
Use |
| $$IDCodificationBits
|
The number of bits of each ID. The default value is set to 32. The value logBits must be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects, predicates or objects.
|
| $$triplesSequence
|
Identify the order in the sequence of all the triples chunks in case of splitting the triples in several files or streams.
|
If the triples are split in several files or streams, each chunk MUST be interpreted as a continuous order, following the $$triplesSequence property.
When the same file or stream comprises both the key stream and the secondary stream, then a secondary Control Information MUST be included in between the two streams, identifying the $$streamFunction on each stream.
3.4.3 Bitmap Triples
This format, denoted by http://purl.org/HDT/hdt#triplesBitmap, extracts the 0's out of the predicate and object streams of compact triple representation. The graph structure is indexed with two bitsequences (Bp and Bo, for predicates
and objects) in which 0-bits mark IDs in the corresponding Sp or So sequence, whereas
1-bits are used to mark the end of an adjacency list. This transformation is shown in Example 6. On the one hand, Predicates={2,3,0,1,2,4,0,3,0} evolves to the sequence Sp={2,3,1,2,4,3} and the bitsequence Bp={001000101} whereas, on the other hand, Objects= {6,0,2,0,3,0,4,5,0,1,0,2.0} is reorganized
in So={6,2,3,4,5,1,2} and Bo={0101010010101}.
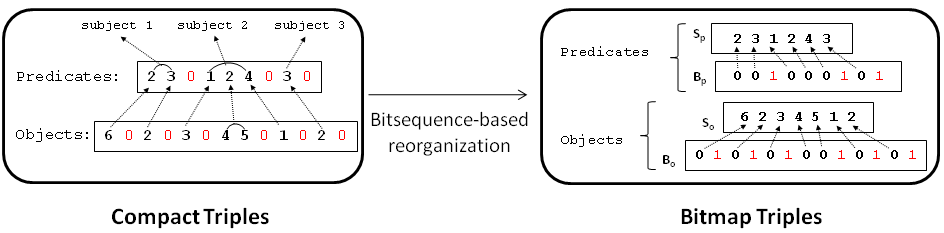 Example 6: Bitmap Transformation from Compact Streams. (PNG)
Example 6: Bitmap Transformation from Compact Streams. (PNG)
Formally, the i-th 1-bit in Bp marks the
end of the predicate adjacency list for the i-th subject (it is referred to as Pi), whereas
the length of the 0-bit sequences between two consecutive 1-bit represents the number
of predicates in the corresponding list.
In Example 6, the second 1-bit in Bp marks the
end of the predicate adjacency list for the second subject (P2). As we can see, a sequence
of three 0-bit exists in between the previous and the current 1-bit. This means
P2 contains three predicates, which are represented by the third, fourth and fifth IDs in Sp by
considering that the third, fourth and fifth 0-bit in Bp correspond to P2. Thus, P2={1,2,4}.
Data in So and Bo are related in the same way. Hence, the j-th 1-bit in Bo marks
the end of the object adjacency list for the j-th predicate. This predicate is represented
by the j-th 0-bit in Bp and it is retrieved from the j-th position of Sp.
In Example 6, the fourth 1-bit in Bo refers the end of the object adjacency list for the fourth predicate in
Sp which is related to the second subject as we have previously explained. Thus, this
adjacency list stores all objects o in triples (2,2,o) ∈ G.
This format, by default, assumes an S-P-O Adj. List, being the subject implicitly represented. Sp and Bp are the key stream and bitmap respectively in order to access the secondary stream (So) and the secondary bitmap (Bo).
Alternative representations are also possible, specifying a $$streamsOrder property in the
user defined meta-data or in the Header Component, as follows:
| $$streamsOrder property value |
Stands for |
| SPO
|
Set up the order of the streams as Subject-Property-Object Adj. Lists. This MUST be taken as the default order of the streams.
|
| SOP
|
Set up the order of the streams as Subject-Object-Property Adj. Lists.
|
| PSO
|
Set up the order of the streams as Property-Subject-Object Adj. Lists.
|
| POS
|
Set up the order of the streams as Property-Object-Subject Adj. Lists.
|
| OPS
|
Set up the order of the streams as Object-Property-Subject Adj. Lists.
|
| OSP
|
Set up the order of the streams as Object-Subject-Property Adj. Lists.
|
In every case, the first stream is implicit and then it is not represented, and the second stream acts as the key stream to access the secondary stream.
The key stream, the key bitmap, the secondary stream and the secondary bitmap can be defined in the same HDT body or in different files or streams.
When the HDT body only comprises one unique stream, its function
MUST be defined with the $$streamFunction property in the
user defined meta-data or in the Header Component, as follows:
| $$streamFunction property value |
Stands for |
| key
|
Identify the current stream as the key stream.
|
| secondary
|
Identify the current stream as the secondary stream.
|
When the HDT body only comprises one unique bitmap, its function
MUST be defined with the $$bitmapFunction property in the
user defined meta-data or in the Header Component, as follows:
| $$bitmapFunction property value |
Stands for |
| key
|
Identify the current bitmap as the key bitmap.
|
| secondary
|
Identify the current bitmap as the secondary bitmap.
|
Other
user defined meta-data or Header information can also be defined for the stream, as follows:
| User defined property |
Use |
| $$IDCodificationBits
|
The number of bits of each ID. The default value is set to 32. The value logBits must be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects, predicates or objects.
|
| $$triplesSequence
|
Identify the order in the sequence of all the triples chunks in case of splitting the triples in several files or streams.
|
Regarding bitmaps,
user defined meta-data or Header information can also define an additional property, as follows:
| User defined property |
Use |
| $$triplesSequence
|
Identify the order in the sequence of all the triples chunks in case of splitting the triples in several files or streams.
|
If the triples are split in several files or streams, each chunk MUST be interpreted as a continuous order, following the $$triplesSequence property.
When the same file or stream comprises both the key stream or bitmap and the secondary stream or bitmap, then additional Control Information MUST be included in between each stream or bitmap.
4. Identifiers For HDT
The URI identifying the HDT representation is: http://purl.org/HDT/hdt#hdt
The Vocabulary used for HDT specification is:
Namespace: http://purl.org/HDT/hdt#
Local name: hdt.
The media type of HDT is the media type of their parts. The Header SHOULD be represented in an RDF syntax. The normative format of the Header is [RDF/XML]. The Dictionary encoding and its media type MAY be specified in the Control Information or in the Header (utf8 and plain/text by default respectively). The triples encoding depends on the triple representation (See Triples), and the media type MAY be specified in the Control Information or in the Header.
6. HDT Operations Over Bitmaps Triples
Bitmaps Triples representation (See Bitmap Triples) allows for an on-demand loading strategy over the structure indexed in Bp and Bo, accessible by fast rank/select operations.
In general terms, rank/select operate over a sequence S of length n drawn from an alphabet Σ = {0,1}, as follows:
-
ranka(S,i): counts the occurrences of a symbol a ∈ {0,1} in S[1,i].
-
selecta(S,i): finds the i-th occurrence of symbol a ∈ {0,1} in S.
This problem has been solved using n + o(n) bits of space while answering the
queries in constant time ([Compact-PAT]).
Multiple operations can be defined. Algorithm 1 shows a Check&Find operation for a triple (s,p,o) over the Bitmaps Triples representation.
Algorithm 1. Check&Find operation for a triple (s,p,o).
1: begin ← select1(Bp, s-1) + 2;
2: end ← select1(Bp, s) - 1;
3: sizePs ← end - begin;
4: Ps ← retrieve(Sp, 1 + rank0(Bp, begin), sizePs );
5:
6: plist ← binary_search(Ps, p);
7: pseq ← rank0(Bp, begin) + plist;
8:
9: begin ← select1(Bo, pseq - 1) + 2;
10: end ← select1(Bo, pseq)- 1;
11: sizeOsp ← end - begin;
12: Osp ← retrieve(So, 1 + rank0(Bo, begin), sizeOsp);
13:
14: plist ← binary_search(Osp, o);
Lines 1-4 describe the steps performed to retrieve the predicate adjacency list for the subject s (Ps).
First, the size of the list is retrieved by locating its begin/end positions in Bp.
Next, the sequence of predicate IDs is obtained from Sp. This operation seeks the
position where Ps begins in Sp (by using the rank0 operation in line 4), and, next,
retrieves the sequence of sizePs predicates that composed it. Lines 6-7 describe the identification of the position (pseq) where s and p are related in Sp. The predicate p is located in Ps with a binary_search, and, next, this
local position (plist) is used to obtain its global rank in Sp. In this step, the object adjacency list for (s,p) (Osp) is ready to use, by considering that it is indexed through
the pseq-th predicate. Osp is retrieved (lines 9-12) similarly to Ps, considering Bo
and So. Finally, o is located with a binary_search on Osp.
This operation does not just find the required triple (s,p,o), but also the triples (s,p,z) ∈ G
The S-P-O Adjacency List order MUST be assumed. The algorithm MUST be modified for alternative representations S-O-P Adj. List, P-S-O, P-O-S, O-P-S Adj. List and O-S-P Adj. List.
7. HDT And SPARQL
The SPARQL Query Language for RDF can make use of some interesting features in HDT:
- Subject-object JOINs resolution can profit from the common naming in the dictionary, as the elements
are correctly and quickly localized in the top IDs.
- Algorithm 1 can response basic ASK queries of SPARQL for patterns (s,p,o), (s,?p,?o) and (s,p,?o).
- Algorithm 1 can response basic CONSTRUCT query of SPARQL for simple WHERE patterns (s,p,o), (s,?p,?o) and (s,p,?o).The resultant is a RDF HDT graph.
The S-P-O Adjacency List order MUST assumed. The response patterns vary for alternative representations S-O-P Adj. List, P-S-O, P-O-S, O-P-S Adj. List and O-S-P Adj. List.
A. References
-
[HDT-ISWC2010]
-
J.D. Fernández, M.A. Martínez-Prieto, and C. Gutierrez. Compact Representation of Large
RDF Data Sets for publishing and exchange. In ISWC 2010, LNCS 6496, pages 193-208, 2010.
-
[VoID]
-
K. Alexander, R. Cyganiak, M. Hausenblas, and J. Zhao. Describing Linked Datasets with the VoID Vocabulary. W3C Interest Group Note 03 March 2011. Available at http://www.w3.org/TR/2011/NOTE-void-20110303/.
-
[Compact-PAT]
-
D. Clark. Compact PAT trees. PhD thesis, University of Waterloo, 1996.
-
[KEYWORDS]
-
S. Bradner. Key words for use in RFCs to Indicate Requirement Levels. The Internet Society, March 1997. Available at http://www.ietf.org/rfc/rfc2119.txt.
-
[RDF/XML]
-
D. Beckett. RDF/XML Syntax Specification (Revised). W3C Recommendation 10 February 2004. Available at http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/
B. Acknowledgements (Informative)
HDT work is partially funded by MICINN (TIN2009-14009-C02-02), Millennium Institute for Cell Dynamics and Biotechnology (ICDB) (Grant ICM P05-001-F), and Fondecyt 1090565 and 1110287. Javier D. Fernández is granted by the Regional Government of Castilla y Leon (Spain) and the European Social Fund.