Bert Bos | Connected books & CSS
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

(Tree image by Amy van der Hiel, 2014)
Presented at:
Web.br 2016
São Paulo, Brazil
14 October 2016
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
![[A photo of my building]](111477-ERCIM.jpg)
W3C you know. The Brazil Office of W3C organized this conference; W3C is where HTML, CSS and many other things you use every day are made. And W3C is also where I work.
IDPF is the organization that makes the EPUB standard, which is used by most e-readers and also online for journals and other documents. Even if you haven't heard the name ‘IDPF’ you have probably encountered EPUB. And EPUB in turn is based on HTML, CSS and other W3C standards.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
Technical work is being prepared by DPub IG
Various requirements documents…
… including ‘Portable Web Publications’ (PWP)

The practical organization is currently being worked out and should be finalized in January. On the specification side, work has already been started by the DPub IG of the W3C to collect requirements on what is currently called ‘Portable Web Publications’, documents that can be read online with all the features you from Web documents, and equally well offline.
Imagine a book that you can get with a click online in a Web browser and read right there, but equally well on a USB stick and read offline. Whether you are online or offline when you read the book, or a bit of both, doesn't matter. Such a publication is easy to copy or give to somebody else. You can send it by e-mail.
But, like a Web page, it can have extra features, such as online comments/reviews, a readers forum and errata.
Of course, links to Web services won't work until you are online. Actions may be queued for later execution, for example.
The same format will also be a good basis also for paper publications, or for publications that are published in a number of different formats.
Such a Portable Web Publication should also contain all the metadata necessary for the publishing, printing and maintenance of the publication. Thus it will have a unique identifier, a copyright license, and in general enough information to allow printing to different kinds of formats (paperback, hardcover), online publishing, other electronic publishing (CD, USB stick), library lending, or automatic indexing for catalogues or bibliographic references.
The combination of efforts by W3C and IDPF should also improve accessibility of documents. Both have acquired a lot of expertise in the area. W3C has its WAI activity that provides W3C's working groups with expertise and reviews. IDPF works with the DAISY consortium and their collaboration has made EPUP3, the current version of EPUB, the basis for talking books.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

CSS originally designed for
all kinds of devices,
big or small,
with or without graphics capabilities,
relatively simple layouts,
ease of use.
→ High-level layout hints,
allows high-quality implementations,
but provides little control over them.
Only part of the capabilities is in the area of CSS, but will have to become more powerful. But wasn't CSS meant to be simple?
Originally, CSS was meant for Web pages: Web pages on all kinds of devices, big and small, with or without graphics, but typically with fairly simple layouts: basically one column with maybe some floating things on the side. CSS was designed to allow implementatons to provide good typography, but didn't provide much control for the typographers.
For example, the 'text-align' property can call for justification, but leaves it up to the implementation to choose a good method: only expanding the spaces between words, both expanding and contracting, expanding and contracting the space between letters, hyphenating words, justifying each line individually or also moving words from one line to the next in order to avoid particularly bad lines, or lines that are very expanded next to ones that are very dense, which looks bad.
In other scripts, such as the Arabic script, there are other methods to choose from, but the principle is the same: CSS only gives a high-level hint to apply justification, without saying how.
Another example is fonts: CSS from the start allowed to choose the fonts, but if a font has multiple variants for the same letter, you couldn't specify which one you wanted.
These things are slowly changing. E.g., we have many new capabilities for advanced typography in the Fonts module, hyphenation is close to being standardized, and we are working on refinements of the handling of justification and line breaking.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
You might wonder why CSS, a standard since 20 years (1996! ), only
has a fonts module since three years, and the other things aren't
even done yet. There are several reasons:
), only
has a fonts module since three years, and the other things aren't
even done yet. There are several reasons:
(explained below)
You can also ask the opposite question. If you accept that CSS is the right technology to support layout of whole books and more complex publication, then why didn't CSS get those capabilities a long time ago?
Here are some of the reasons.
Originally, I, and others with me, thought CSS was for the simple designs, the 80% case, that every Web author would be able to make. Many of the details would be handled automatically by the implementations.
CSS, we thought, would also not be our final answer. It was probably good enough for 10 years or so, just enough time to come up with an easier language, that was also better adapted to the variety of devices and languages on the Web.
Or, in fact, two languages: an easy one that everybody could use and was good enough for such things as a Web home page, a journal article, a letter, a memo, or a press release; and an advanced one for complex digital publications, such as books, newspapers, journals or technical manuals.
Indeed, a few years later, we started XSL, our advanced style sheet language, much more focused on (complex) book layout, and with better internationalization. It includes, e.g., vertical writing such as for Japanese, years before CSS started working on that.
XSL was a success in the publishing world, although not so much on the Web. But, maybe because W3C is a Web Consortium, we have trouble continuing the development of XSL, at least of the part related to layout (which is called XSL-FO). So, in January 2013, we decided to stop the WG that was working on XSL-FO version 2 (called the XPPL WG), until there would be enough W3C member organizations again for restarting it
People apparently like CSS and they want CSS to grow, rather than be replaced. With the development of XSL-FO frozen, publishers also are turning to CSS. In December, we'll celebrate 20 years of CSS, and CSS doesn't look like it has reached its top yet.
E.g., I saw a talk two weeks ago by somebody from Hachette Livres, one of the world's biggest publishers. Hachette started using CSS in 2010 and found that it worked well for novels. CSS was good enough and it simplified the production process. By now they sold more than 50 million books made with CSS, including some best-sellers with more than half a million copies. (They are also active in Brazil, maybe you even have one their books. But you probably can't see that it was made with CSS, as it should be.)
They are currently experimenting with more complex books, such as travel guides. You can already get quite far, but the CSS rules become complicated, and some things are missing. Compared to XSL-FO, CSS still has a lot of catching up to do.
Implementing good typography is also a skill that you have to learn and it is not necessarily a skill the makers of browsers have. Others have been doing it for a long time. Adobe, e.g., has products for typesetting, and they bought several companies that were doing it before them.
When we made CSS, the programmers who made browsers didn't even know about tree-structured documents. We thought CSS would be easy to implement, because all it did was assign properties to the tree and inherit them down the tree. It turned out the browser makers hadn't considered HTML as a tree and many of the early browser bugs that were mysterious to us are easy to explain once you know that.
Nowadays, every browser has a DOM, so much has improved, but there is more to do.
Originally, I also didn't think CSS would be used for styling graphical user interfaces. A GUI is a rather different thing from a document and there are specialized tools to make ‘skins’. But despite several attempts, we never succeeded in standardizing on a UI language and instead people are making do with HTML and CSS. Neither HTML nor CSS were originally designed for that, and making UIs with them is still rather clumsy, despite additions made to HTML (in particular HTML5) and CSS over the years.
Adapting CSS to use in GUIs has been the focus of a lot of work in the CSS WG, meaning there was less attention to the needs of publishing. It resulted in things like flexbox, transitions, transformations and more recently grids. Flexbox and grids especially are great for GUIs, but they don't work so well for documents. A document is a tree, and typically much more structured than a GUI, which is basically flat: a container with a bunch of controls inside. Flexbox and grid work well for the latter, but not for the former.
Despite advances in networks, the Web has been getting slower and slower. The reason is mostly that Web pages are too big, because they include too much JavaScript and overly big images and videos. Designers also include too more CSS than they need.
Browsers have been focusing a lot on improving speed. They can't reduce the size of pages, but they can improve the speed of CSS rendering. And they also postpone adding CSS features that require long computations. A CSS animation can often replace a lot of JavaScript (and give smoother animations, too), but then the CSS properties must be quick to compute.
Some of the things we need for good typography, such as better line breaking and justification, necessarily require multiple passes over the text, which would be too slow inside an animation. But we still need them for book layout.
Modern computers are fast, hundreds of times faster than when we started designing CSS, and doing a nice, typographically correct layout can easily be done in real time, i.e., as fast as you can type. In other words, for an implementation that outputs to PDF or to a printer, none of this is a problem. But it is a problem in a browser that is trying to do an animation at 60 frames a second.
How to have both good typography and fast browsers is still a matter of study. We are considering defining a ‘dynamic profile’ and a ‘static profile’ for CSS, but we aren't quite happy with that. We are still searching…
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
![[photo]](Statue_de_Gutenberg_a_Strasbourg.jpg) Statue of
Gutenberg in Strasbourg (photo: AlteRimoldi)
Statue of
Gutenberg in Strasbourg (photo: AlteRimoldi)
A small aside about innovation:
Going from manuscript to printing with lead meant compromises and the loss of some age-old tricks to make books more readable. But the advantages were worth it and slowly the new technologies caught up with the old.
Now, going from typesetting systems to CSS entails new compromises. You can currently only make simple books without a very high expectation of typographic quality, but, in this case, too, there are advantages: HTML and CSS are easy, easily reusable (which also means a faster production process) and standardized, and all those advantages together means its use also makes producing books chaper.
And if the book is in fact an e-book, and especially if you have an Internet connection, there are other advantages, too, e.g.: hyperlinks, instant updates, shared annotations (shared with others or with yourself on a different device), sound and animations (think of children's books), copy & paste, restyling (change contrast, change the font or its size, etc.).
And we have the firm intention to improve the typographic capabilities of CSS and its implementations and catch up quickly with the quality of books made before CSS…
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

Håkon and my book (3rd ed., 2005) was one of the first made with HTML+CSS
Sped up production process by a few weeks
The book Håkon and I made was one of the first made entirely in HTML and CSS, certainly the first published by Addison-Wesley. That was in 2005. In fact, AW didn't have to do much: we produced the PDF ourselves and when AW had corrections to make, we regenerated the PDF and uploaded it via FTP. But even so, it meant the production process from the moment we submitted our copy until the actual printing was shortened by a few weeks compared to the previous process, where authors provided Word or Framemaker files, or even double-spaced typewritten sheets of paper.
We used Prince, which couldn't do everything we needed, but we contacted the maker, Michael Day, and proposed some proprietary CSS properties, several of which he managed to implement. In fact, we were continually using alpha versions of Prince. What Prince couldn't implement in time, we could usually hack around.
E.g., we wanted hyphenation. There were no explicit hyphenation properties in CSS, but it was not forbidden to implement hyphenation either. However, nobody had done so yet. In fact, most implementations at the time, including nearly all browsers, couldn't even do soft hyphens correctly. It proved too hard to implement automatic hyphenation in Prince in a short time, but Michael did add correct handling of soft hyphens and we wrote a wrapper in Perl to add soft hyphens to our text (using the algorithm and patterns from TEX) just before running Prince.
(The current version of Prince does do automatic hyphenation, and CSS now has properties to control hyphenation, too. Not an official W3C standard, yet but the relevant part of the draft is quite stable.)
Prince isn't the only software that makes good PDF. There are also, e.g., AntennaHouse Formatter (does XSL, too), PDFReactor and VivlioStyle (still in beta). See Andreas Jung's Print CSS Rocks for an overview.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

(Rare) example of math in a running header
The Paged Media module has been implemented in various products since more than 10 years. It defines, among other things, a simple page template with running headers.
It defines three boxes along the top of the page that each allow simple text in a single font. That works for many books, but is no longer enough when the text needs some structure, such as in this example with some math.
Such headers are rare in practice. Even in books about math, the running headers usually don't contain formulas, or in the whole book there may be just one chapter with such a header. So in practice you can make quite a few books with the existing CSS features.
But there are types of books where running headers are much more elaborate. E.g., there are repair manuals for machines where the running headers contain complete tables.
There are proposed new properties to move whole elements, not just a text string, into the running headers, and there are some experimental implementations of those, but they are still far from being standard.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
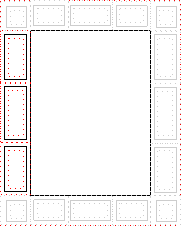
CSS so far defines a single page template, sufficient only for simple publications.
EPUB3 has a page-template module, but it is not part of CSS. The ideas from that module may be used for a standard CSS page template module, but little work has been done on it so far. E.g., should it based on the model of grids or absolute positioning? The former is easier in many cases and usually avoids having to specify numeric coordinates, but it can become complex for page layout that do not resemble a grid.
Whatever the model and the syntax, the fundamental idea is to draw a page layout entirely in the style sheet, independent of the document and its elements. The parts of the layout are thus ‘pseudo-elements’, and they can be styled, whether or not any part of the document ends up being displayed in them.
One question is if it is enough to move an element from the document into the header, i.e., the author puts an XML element (or an HTML element with some class) in the document and it is that element that becomes the running header. Complex headers often are not direct copies of something in the body of the document, so this is not such a strange idea.
It is a variant of floating or absolute positioning: an element is taken out of the normal flow and put in a special location. Except that repeats until something else is put there, Which may mean it repeats zero times.
Prince has implemented one of the proposals that does this.
Or should we have the possibility to copy an element and have it appear both in the body and in the header. The math example above is in fact an exact copy of a section heading, so the ability to make two copies of a single element makes sense, too.
The simple page template from CSS Paged Media allows for a body area and some boxes around it, but what if you want, say, running headers above your columns, or you have several regions on the page and you want each to have a running header?
It seems we need a way to define boxes that behave like running headers in the sense that every occurrence of the box repeats the same content, until some new content is provided.
And callouts are a bit like running headers, too: they take some text from the page on which they occur, and discard other candidates on the same page. Except they don't repeat.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

We have an early draft of a module that extends the 'float' property to allow floating to the top of a page or column. It allows to specify to which page or column an element should flow: the current one, or the n'th one after it.
Another way to think of this example is as a predefined grid, where the image is a fixed region that acts a bit like a running header or a callout and receives the first available image.
Various ideas for defining regions on a page are also being studied.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

There is no solution for the color inversion in any of our drafts yet (but it is possible with SVG). The overlap itself is also tricky, but a negative margin or an overflow can probably do it.
If we consider the top right article as a single region with a 'columns: 3' property, then the top-right image spans two columns. This is a reasonable extension for multicol. As an alternative, the three columns and the image can also be seen as four separate regions, three of which form a chain.
We have no way to guarantee that an element (or border) has exactly the height of the digits of a font, but if we can be reasonably sure of the font (thanks to Web fonts), it is probably OK to measure the font on server side.
Similarly, the kerning in the page header is probably a question of setting a fixed negative margin.
To fill all columns exactly to the bottom, there has to be some flexibility to exploit. The space between the paragraphs could be made stretchy (as in TEX), and the images could be cropped slightly differently. But we have no such features in any CSS draft yet.
The rules between the columns can be made in several ways: as borders on the slots ('::slot()' pseudo-element), or as narrow slots filled with a black background.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●

13th c. manuscript
Considered as a template with 6 areas (a…f):
a a a a a a . b b b b b a a . . . . . . . . . b a a . c . d . e . f . b a a . c . d . e . f . b a a . c . d . e . e . b a a . c . d . e . e . b a a . . . . . . . . . b a a a a a a . b b b b b a a a a a a . b b b b b
This manuscript is the result of adding more annotations (a and b) in the margins of a text that itself already had a main text (d and f) and annotations (c and e). That partly explains the irregular width of the columns.
In modern designs, e.g., in newspapers, columns may also be of different widths, but the wider columns are typically an exact multiple of the narrow ones. So one way to look at such a design is as a set of regular columns, except that some columns are combined into one.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
CSS cannot add every feature people ask for. (Too big, too slow, too buggy.)
Instead CSS engines will allow extensions → Houdini APIs
Extensions at all levels:
The CSS WG continues to add features to CSS, but is also working on APIs to add your own extensions. The whole CSS engine, including the parser, the cascading and inheritance process, the box building, the rendering engine and the even handlers, will be opened up so that (advanced) programmers can extend each of these parts and add new properties, new values and new kinds of graphical objects.
This way, features that have only a limited application don't have to be in the core of CSS. Instead, a WebApp developer can add them to his app, or a somebody can make a specialized browser or CSS processor by taking an existing CSS engine and extending it with specialized functions.
For e-books, e.g., this can mean that e-book readers can be based on the same engine as a browser, but with better line breaking, thanks to an extension that replaces the built-in line-breaking with better algorithms.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
Another application of Houdini might for mathematics:
Better alignment & spacing in formulas, thanks to access to
math-related font data 
Another example is mathematics. Displaying formulas well is quite complex and browser makers see it as a niche market and thus give it low priority. MathJax is a JavaScript shim that does quite a good job rendering MathML, but it is limited by the CSS box model. Imagine a new MathJax with access to the lower levels of the rendering engine, then bundle that with the rendering engine and ship it as an e-book reader. You'll have a CSS renderer that is implemented partly in C and partly in JavaScript, but that is invisble to the user. What is not invisible, however, is that you now have a rendering engine that can actually do math quite nicely.
Don't expect these results to happen quickly, though. The priority for Houdini is to speed up complex, interactive WebApps: things like fast scrolling through an animated graphic. Access to font features that CSS doesn't expose, such as those for mathematics, will happen eventually, but probably after some other APIs.
Why are these APIs called ‘Houdini APIs’? Houdini was known for two things: escaping out of boxes and debunking claims of supernatural powers. The Houdini task force likewise tries to offer developers a way to escape the CSS box model and tries to explain how a CSS engine actually works and show that it isn't magic.
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
https://www.w3.org/Talks/2016/1014-CSS-Sao-Paulo
To Lead the Web to its full potential
To Anticipate the Trends
To Increase your company value
Join W3C
https://www.w3.org/Consortium/join
or contact: Vagner Diniz or Newton Calegari
Bert Bos <bert@w3.org>
GPG fingerprint: 7744
0204 52A5 14D9 147D
2A13 2D7A E420 184B 5BA4
![]() course starting in November on
course starting in November on  !
!
![[photo: magazine page with a callout]](CRW_3246_1.jpg)
![[photo: magazine page with a callout, circled with a green pen]](CRW_3246_2.jpg)
![[photo]](Houdini_and_Lincoln.jpg)
{kind=link}
I like books, typography and CSS. That would be reason enough to talk about CSS and books. But there are signs that this particular combination of technologies is at a tipping point: still young, but no longer a niche; and on the way to becoming one of the major ways to make documents, both online and offline.
And there is also an important change underway in the way standards for digital publishing are made. W3C and IDPF announced ([en] [pt-br]) in May that they would combine into a single organization.