This document describes requirements for the layout and presentation of text in the Punjabi language, using the Gurmukhi script when they are used by Web standards and technologies, such as HTML, CSS, Mobile Web, Digital Publications, and Unicode.
Status of This Document
This section describes the status of this
document at the time of its publication. A list of current W3C
publications and the latest revision of this technical report can be found
in the W3C technical reports index at
https://www.w3.org/TR/.
This early draft has not yet been through any review process. Please do not rely on the contents.
This document describes the basic requirements layout and text support on the Web and in eBooks for the Punjabi language, using the Gurmukhi script. These requirements provide information for Web technologies such as CSS, HTML and digital publications about how to support users of the Gurmukhi script. Currently the document focuses on Gurmukhi as used for the Punjabi language. The information here is developed in conjunction with a document that summarises gaps in support on the Web for Gurmukhi.
Group Draft Notes are not endorsed by
W3C nor its Members.
This is a draft document and may be updated, replaced or obsoleted by other
documents at any time. It is inappropriate to cite this document as other
than work in progress.
The
W3C Patent
Policy
does not carry any licensing requirements or commitments on this
document.
This document provides information about the Gurmukhi script as used for the Punjabi language.
This document should contain no reference to a particular technology. For example, it should not say "CSS does/doesn't do such and such", and it should not describe how a technology, such as CSS, should implement the requirements. It is technology agnostic, so that it will be evergreen, and it simply describes how the script works. The gap analysis document is the appropriate place for all kinds of technology-specific information.
1.2 Gap analysis
This document is pointed to by a separate document, Gurmukhi Gap Analysis, which describes gaps in support for Gurmukhi on the Web, and prioritises and describes the impact of those gaps on the user.
Wherever an unsupported feature is indentified through the gap analysis process, the requirements for that feature need to be documented. Those requirements can be described here.
As gaps in support for Gurmukhi are captured, the gap is brought to the attention of the relevant spec developer or browser implementation community. The progress of such work is tracked in the Gap Analysis Pipeline.
The document Language enablement index points to this document and others, and provides a central location for developers and implementers to find information related to various scripts.
The W3C also maintains a tracking system that has links to GitHub issues in W3C repositories. There are separate links for (a) requests from developers to the user community for information about how scripts/languages work, (b) issues raised against a spec, and (c) browser bugs. For example, you can find out what information developers are currently seeking, and the resulting list can also be filtered by script.
The Gurmukhi script is an abugida, ie. consonants carry an inherent vowel sound that is overridden using vowel signs. See the table to the right for a brief overview of features for the modern Panjabi orthography.
Gurmukhi text runs left to right in horizontal lines.
Words are separated by spaces.
Gujarati uses 32 consonant letters. The repertoire can be extended by applying the nukta diacritic to 5 characters, to represent foreign sounds, particularly for words from Persian.
A final h can be indicated using the visarga, but otherwise final consonants are written using ordinary characters
Although consonant clusters are frequent, there are very few conjuncts, mostly just r and h, which are subjoined. This leads to difficulties for automatic transcription.
Consonant gemination is indicated, unusually for an Indian script, by a special diacritic that appears before the letter being lengthened.
The Punjabi orthography has an inherent vowel, and represents other vowels using vowel signs, including a pre-base vowel but no circumgraphs. All vowel signs are combining marks, and are stored after the base character. The inherent vowel is usually not pronounced at the end of a word, however there is often a ghost ᵊ.
Gurmukhi has independent vowels, one for each vowel sound, including the inherent vowel, and these are used to write all standalone vowel sounds. There are no unique shapes for independent vowels. Instead vowel signs are added to one of three consonants that are used only as vowel carriers, however Unicode provides separate code points for all the combinations and deprecates the use of 2 of the carriers.
Two diacritics are used for nasalisation, tippi and bindi, each used in different phonetic contexts.
Punjabi is a tonal language. Tones are normally indicated by the use of certain consonants, rather than diacritics
Gurmukhi has its own set of native digits, however modern text tends to use ASCII digits, depending on the context.
Punctuation is mostly western, but dandas are used for sentence and verse final punctuation.
3. Text direction
Gurmukhi is written horizontally, left to right.
4. Characters & encodings
Visually, Gurmukhi independent vowels are written using a combination of a vowel sign attached to one of three base letters. Those combinations are encoded by the Unicode Standard as single, precomposed code points, but it is also possible to analyze the letter as using a decomposed sequence of code points: a base letter followed by a vowel sign.
The precomposed characters don't decompose when normalised using NFD, nor do the decomposed sequences change under NFC. They are therefore not treated in Unicode as canonically equivalent. The Unicode Standard recommends that the precomposed characters be used.
Many fonts (such as Noto Fonts) will display a dotted circle if the content author tries to use the decomposed sequence, but not all fonts do. Content authors who created their content with a font such as Gurmukhi MN will find that their content no longer looks right when a different font is used. Furthermore, decomposed sequences won't match to precomposed characters during search or matching.
ਅ + ੈ [U+0A05 GURMUKHI LETTER A + U+0A48 GURMUKHI VOWEL SIGN AI]
ਔ [U+0A14 GURMUKHI LETTER AU]
ਅ + ੌ [U+0A05 GURMUKHI LETTER A + U+0A4C GURMUKHI VOWEL SIGN AU]
ਆ [U+0A06 GURMUKHI LETTER AA]
ਅ + ਾ [U+0A05 GURMUKHI LETTER A + U+0A3E GURMUKHI VOWEL SIGN AA]
It is unlikely that content authors will always choose the approach recommended by the Unicode Standard, so applications should be able to treat precomposed and decomposed independent vowels as the same, even though they are not canonically equivalent.
5. Glyph shaping & positioning
Gurmukhi printed text is not cursive, and the orthography has no case distinction.
5.1 Glyph joining
Within a Gurmukhi word, spacing glyphs are joined together at the top bar.
ਚਿੜੀ-ਛਿੱਕਾ ciṛī-chikkā badminton
The top bar extends across or through most spacing letters, including both consonants and vowels, but some letters create a gap in the line (while still joining at either side). Two such letters can be seen in the following example.
ਅਧਿਆਪਕ adhiāpak teacher
Letters that create these gaps include digits and the following:
ਪ ਘ ਖ ਮ ਅ ਃ
5.2 Font styling & weight
Italics and bold are not traditional features of Gurmukhi text, but they do occur in modern texts.
Oblique text tends to be used to offset blocks of text, by-lines, etc., rather than for emphasis.
Figure 1 Slanted text used to set off a paragraph.
6. Graphemes
A grapheme is a user-perceived unit of text. Text operations that use graphemes as a unit of text include line-breaking, forwards deletion, cursor movement & selection, character counts, text spacing, text insertion, justification, case conversions, and sorting. The Unicode Standard uses generalised rules to define ‘grapheme clusters’, which approximate the likely grapheme boundaries in a writing system, however they don't work well with many complex scripts.
The term orthographic syllable is not clearly defined in the Unicode Standard. In this page we define it to mean a typographic unit that includes more than one grapheme cluster. This is commonly the case for Brahmi-derived scripts, such as for Devanagari conjuncts, or Balinese stacks. Orthographic syllables do not correspond to phonetic syllables.
Although grapheme clusters alone provide good segmentation for many Gurmukhi syllables (because of the lack of conjuncts), they are not sufficient to represent typographic units for stacks. Stacks are common and must not be split apart by edit operations that visually change the text (such as letter-spacing, first-letter highlighting, and in-word line breaking). For those operations one needs to segment the text using orthographic syllables, which string grapheme clusters together with a virama.
The Gurmukhi virama (halant) is ੍ [U+0A4D GURMUKHI SIGN VIRAMA],
which has an Indic Syllabic Category of Virama.
6.1 Grapheme clusters
Base Combining_mark* ZW(N)J?
Grapheme clusters cover the combinations described just above. In these sequences, Gurmukhi combining marks used for Punjabi may include zero or more of the following types of character.
Nukta [1] (see Repertoire extension) Only one per grapheme cluster, typed and stored immediately after the base consonant.
Virama (halant) (see Consonant clusters and Vowel absence) Occurs immediately after a consonant (and optional nukta) at the beginning of a cluster. In modern Punjabi text stacks are only formed with a subjoined RA or HA, and on rare occasions VA. Other consonant clusters are simple sequences of consonant letters.
ZW(N)J is not usually found in Gurmukhi text.
The following examples show a variety of typical grapheme clusters:
Figure 2 Examples of words split into Unicode grapheme clusters.
Note how grapheme clusters segment the parts of a stack after the virama in the last 2 examples. This is not always desirable (see 6.2 Larger typographic units just below).
6.2 Larger typographic units
(Consonant Nukta? Virama)* Grapheme_cluster
Gurmukhi stacks medial RA (and sometimes VA) and HA after a syllable coda (see Consonant clusters). The stacks represent consonant clusters (but not gemination, which is indicated using a diacritic).
Grapheme clusters terminate after a sequence of marks that includes a halant, but editorial operations that change the visual appearance of the text, such as letter-spacing, first-letter highlighting, line-breaking, and justification, should never split conjunct forms apart. For this reason, an alternative way of segmenting graphemes is needed. This may not apply, however, for some other operations such as cursor movement or backwards delete.
Where stacks appear, a typographic unit contains multiple grapheme clusters. The non-final grapheme clusters all end with ੍ [U+0A4D GURMUKHI SIGN VIRAMA], and the final grapheme cluster begins with a consonant.
The following are examples. Some examples were shown in the previous section: here the stack is treated as a single typographic unit.
Figure 3 Examples of words split into orthographic syllables.
7. Structural boundaries & markers
7.1 Word boundaries
The concept of 'word' is difficult to define in any language (see What is a word?). Here, a word is a vaguely-defined, but recognisable semantic unit that is typically smaller than a phrase and may comprise one or more syllables.
Gurmukhi words are separated by spaces.
Some grammatical suffixes are also separated from their stem by a space, and in this case the two parts should not become separated.
Words are occasionally hyphenated, eg.
ਚਿੜੀ-ਛਿੱਕਾ ciṛī-chikkā badminton.
7.2 Phrase & section boundaries
Gurmukhi uses ASCII punctuation marks. Phrases are delimited by comma, semicolon, and colon. Sentences are terminated with a full stop, question mark or exclamation mark.
Sentences may also be terminated using । [U+0964 DEVANAGARI DANDA], rather than an ASCII full stop. It is often separated from the last word in the sentence by a small gap, but should not wrap alone to the beginning of the next line. The gap also doesn't grow during justification.
Figure 4 Examples of danda in use as a sentence delimiter in a newspaper report.translation
The Ambassador of Mauritius to India Mrs. Mary Claire J. Monty came to visit Sri Harmandir Sahib today. He bowed down with reverence and served for some time at Guru Ramdas Ji's Langar Hall.
7.3 Quotations
Gurmukhi texts use quotation marks around quotations. Of course, due to keyboard design, quotations may also be surrounded by ASCII double and single quote marks.
The default quote marks for Gurmukhi should be “ [U+201C LEFT DOUBLE QUOTATION MARK] at the start, and ” [U+201D RIGHT DOUBLE QUOTATION MARK] at the end.
When an additional quote is embedded within the first, the quote marks should be
‘ [U+2018 LEFT SINGLE QUOTATION MARK]
and
’ [U+2019 RIGHT SINGLE QUOTATION MARK].
7.4 Abbreviation, ellipsis & repetition
ਃ [U+0A03 GURMUKHI SIGN VISARGA] is used very occasionally in Gurmukhi. In some cases it acts like a Sanskrit visarga, producing a voiceless h sound, but in others it represents an abbreviation, in the same way the period is used in English.
However, contractions are very common in Punjabi text, and a much more common way of indicating these is to use
' [U+0027 APOSTROPHE].
A particularly common contraction is to represent ਵਿੱਚ ʋɪtt͡ʃɪ̆ in as 'ਚ.
Figure 5 Examples of abbreviated words using apostrophes.translation
ISKCON Vice President Radharaman said that the increasing incidence of attacks on Hindu temples in Australia is alarming.
8. Line & paragraph layout
8.1 Line breaking & hyphenation
By default, Gurmukhi breaks lines at inter-word spaces.
8.1.1 Line-edge rules
As in almost all writing systems, certain punctuation characters should not appear at the end or the start of a line. The Unicode line-break properties help applications decide whether a character should appear at the start or end of a line.
The following list gives examples of typical behaviours for some of the characters used in modern Gurmukhi. Context may affect the behaviour of some of these and other characters.
“ ‘ ( should not be the last character on a line.
” ’ ) . , ; ! ? । % should not begin a new line.
ੴ ☬ do not create line-break opportunities unless they are separated from other letters by space.
8.2 Text alignment & justification
Figure 6 shows lines justified by stretching the inter-word spaces.
Figure 6 Justification of Punjabi text.
Note that the space before the danda at the end of a sentence is not stretched during justification.
8.3 Baselines, line height, etc.
Gurmukhi uses the so-called 'alphabetic' baseline, which is the same as for Latin and many other scripts.
It also has a 'hanging baseline', which may be used for text alignment in things such as initial letter highlighting. The hanging baseline is based on the top bar that joins the letters.
Gurmukhi requires slightly more vertical space than Latin text. To give an approximate idea, Figure 7 compares Latin and Gurmukhi glyphs from Noto fonts. The basic Gurmukhi letters are typically slightly higher than the Latin x-height, and conjunct stacks and other diacritics extend slightly below the Latin descenders. The hanging baseline is slightly higher than the Latin x-height (Noto fonts actually have a lower top bar than many others).
Figure 7 Font metrics for Latin text compared with Gurmukhi glyphs in the Noto Serif Gurmukhi (top) and Noto Sans Gurmukhi (bottom) fonts.
Figure 8 shows similar comparisons for the Baloo Paaji 2 and Raavi fonts.
Figure 8 Latin font metrics compared with Gurmukhi glyphs in the Baloo Paaji 2 (top) and Raavi (bottom) fonts.
8.4 Counters
Counters are used to number lists, chapter headings, etc.
Patterns for using these styles in CSS can be found in Ready-made Counter Styles, and we use the names of those patterns here to refer to the various styles.
The modern Punjabi orthography uses a native numeric style and an alphabetic style.
8.4.1 Numeric counter styles
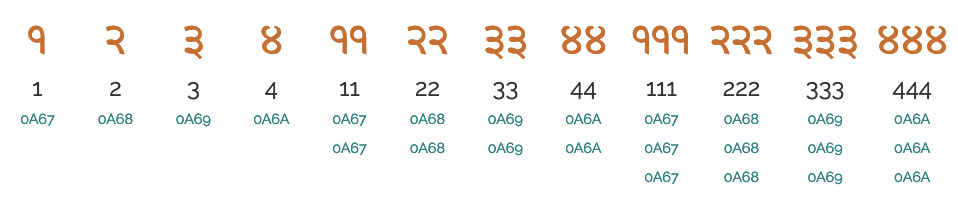
Gurmukhi uses a numeric counter style, based on the decimal model, and using the standard Gurmukhi digits, in a decimal pattern.
'੧' '੨' '੩' '੪' '੫' '੬' '੭' '੮' '੯' '੦'
Figure 9 Examples of counter values using the Gurmukhi numeric counter style.View as text
The numeric style commonly uses a full stop + space as a suffix. The alphabetic style may enclose counters in parentheses, or use a single closing parenthesis.
Examples:
Figure 11 Separators for Punjabi list counters.
8.4.4 Examples
Figure 12 Examples of alphabetic counters in Punjabi.
8.5 Styling initials
Punjabi content sometimes enlarges the first part of the first word in a paragraph, in a similar way to drop caps. Instead of enlarging just the first letter in the word, it is normal to enlarge the first orthographic syllable (see Figure 13). If the first character is the beginning of a conjunct, the whole stack should be included in the styling.
Figure 13 Enlarged syllable styling at the start of a paragraph.
In principle, the top line of the characters should align in the large text and the following first line.
A. Acknowledgements
The initial content of this document was created from parts of this page.
Special thanks to the following people who contributed information that is used in this document (contributors' names listed in in alphabetic order).