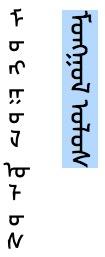Abstract
This document describes and prioritises gaps for the support of the Traditional Mongolian script (Hudum) on the Web and in eBooks. In particular, it is concerned with text layout. It checks that needed features are supported in W3C specifications, in particular HTML and CSS and those relating to digital publications. It also checks whether the features have been implemented in browsers and ereaders. This is a preliminary analysis.
Status of This Document
This section describes the status of this
document at the time of its publication. A list of current W3C
publications and the latest revision of this technical report can be found
in the W3C technical reports index at
https://www.w3.org/TR/.
This document describes and prioritises gaps for the support of Mongolian on the Web and in eBooks. In particular, it is concerned with text layout for the traditional (Hudum) script. It checks that needed features are supported in W3C specifications, in particular HTML and CSS and those relating to digital publications. It also checks whether the features have been implemented in browsers and ereaders. This document complements the document Mongolian Layout Requirements, which describes the requirements for areas where gaps appear. It is linked to from the language matrix that tracks Web support for many languages.
The editor's draft of this document is being developed by the Mongolian Layout Task Force, part of the W3C Internationalization Interest Group. It is published by the Internationalization Working Group. The end target for this document is a Working Group Note.
This document was published by the Internationalization Working Group as
a Working Draft using the
Recommendation track.
Publication as a Working Draft does not
imply endorsement by W3C and its Members.
This is a draft document and may be updated, replaced or obsoleted by other
documents at any time. It is inappropriate to cite this document as other
than work in progress.
This document was produced by a group
operating under the
W3C Patent
Policy.
W3C maintains a
public list of any patent disclosures
made in connection with the deliverables of
the group; that page also includes
instructions for disclosing a patent. An individual who has actual
knowledge of a patent which the individual believes contains
Essential Claim(s)
must disclose the information in accordance with
section 6 of the W3C Patent Policy.
This document is governed by the
2 November 2021 W3C Process Document.
1. Introduction
The W3C needs to make sure that the needs of scripts and languages around the world are built in to technologies such as HTML, CSS, SVG, etc. so that Web pages and eBooks can look and behave as people expect around the world.
This page documents difficulties people encounter when trying to use the Mongolian language with the Traditional Mongolian script on the Web.
Having identified an issue, it investigates the current status with regards to web specifications and implementations by user agents (browsers, e-readers, etc.), and attempts to prioritise the severity of the issue for web users.
A summary of this report and others can be found as part of the language matrix.
For a description of the Mongolian script see the (non-W3C) page Mongolian, which summarises aspects of the orthography and typographic features, including relevant Unicode characters and their use.
1.1 Work flow
This version of the document is a preliminary analysis
Gap analysis work usually starts with a preliminary analysis, conducted quickly by one or a small group of experts. Then a more detailed analysis is carried out, involving a wider range of experts. The detailed analysis may involve the development of tests, in order to illustrate issues and track results for browsers. The next phase is ongoing maintenance. It is expected that the resulting document will not be frozen: as gaps are fixed, this should be noted in the document. It is also possible that new gaps are noticed or arise, and they can be added to this document when that happens.
As the gap analysis develops, the requirements for features that are problematic should be described in the companion document, Mongolian Layout Requirements. Links to the appropriate part of that document should be added to this document as the material is created. Note that the requirements document should not contain any technology-specific information: all of that belongs here.
1.2 Prioritization
This document not only describes gaps, it also attempts to prioritise them in terms of the impact on the local user. The prioritisation is indicated by colour.
Key:
It is important to note that these colours do not indicate to what extent a particular features is broken. They indicate the impact of a broken or missing feature on the content author or end user.
Basic styling is the level that would be generally accepted as sufficient for most Web pages. Advanced level support would include additional features one might expect to include in ebooks or other advanced typographic formats. There may be features of a script or language that are not supported on the Web, but that are not generally regarded as necessary (usually archaic or obscure features). In this case, the feature can be described here, but the status should be marked as OK.
The decision as to what priority level is assigned to a described gap is down to the experts doing the gap analysis. It may not always be straightforward to decide. If a given section in this document refers to more than one feature that is broken, each with different impacts on Web users, the priority for the section should be the lowest denominator.
A cell can be scored as OK if the feature in question is specified in an appropriate specification, and is supported by user agents. A specification that is in CR or later and has two implementations in 'major' browsers will count. This means that the feature may not be supported in all browsers yet. (At some point in the future we may try to distinguish, visually, whether support is available in a specification but still pending in major browsers or applications.)
3. Characters and phrases
3.1 Characters & encoding
Are there any character repertoire issues preventing use of this script on the Web? Do variation selectors need attention? Are there any other encoding-related issues? See available information or check for currently needed data.
#34 Encoding model needs to be simplified
The Unicode encoding model for Mongolian is notoriously problematic. Differentiation of code points by phonetics rather than by glyph shape leads to many spelling mistakes by authors, as the glyphs for many code points or positional forms are identical.
However, more immediate problems arise due to the lack of standardisation and the current complexity surrounding the writing of alternate glyph forms, context-dependent and orthographic. This makes it impossible to create interoperable content that can be guarranteed to look the same or even accurate given the use of different fonts and text processors.
Experts from Mongolia and China are currently working with the Unicode Consortium in order to simplify and standardise the Mongolian encoding model.
3.2 Fonts
Do the standard fallback fonts used in browsers (eg. serif, sans-serif, cursive, etc.) match expectations? Are special font or OpenType features needed for this script that are not available? See available information or check for currently needed data.
#35 Lack of standardisation of variants
The lack of standardisation surrounding the outcome of using free variation selectors across fonts makes content authoring unreliable. In addition, the many rules needed to control automatic selection of appropriate glyph variants, particularly for the QA and GA letters, present a barrier to would-be font designers.
Experts from Mongolia and China are currently working with the Unicode Consortium in order to simplify and standardise the Mongolian encoding model in ways that will address this issue.
3.3 Font styles, weight, etc
This covers ways of modifying the glyphs, such as for italicisation, bolding, oblique, etc. Do italic fonts lean in the right direction? Is synthesised italicisation problematic? Are there other problems relating to bolding or italicisation - perhaps relating to generalised assumptions of applicability? See available information or check for currently needed data.
3.4 Glyph shaping and positioning
Does the script in question require additional user control features to support alterations to the position or shape of glyphs, for example adjusting the distance between the base text and diacritics, or changing the glyphs used in a systematic way? Do you need to be able to compose/decompose conjuncts, or show characters that are otherwise hidden, etc? See available information or check for currently needed data.
#35 Lack of standardisation of variants
The lack of standardisation surrounding the outcome of using free variation selectors across fonts makes content authoring unreliable. In addition, the many rules needed to control automatic selection of appropriate glyph variants, particularly for the QA and GA letters, present a barrier to would-be font designers.
Experts from Mongolia and China are currently working with the Unicode Consortium in order to simplify and standardise the Mongolian encoding model in ways that will address this issue.
3.5 Cursive text
If this script is cursive (eg. Arabic, N’Ko, Syriac, etc), are there problems or needed features related to the handling of cursive text? Do cursive links break if parts of a word are marked up or styled? Do Unicode joiner and non-joiner characters behave as expected? See available information or check for currently needed data.
3.8 Grapheme/word segmentation & selection
This is about how text is divided into graphemes, words, sentences, etc., and behaviour associated with that. Do Unicode grapheme clusters appropriately segment character units for your script? When you double- or triple-click on the text, is the expected range of characters highlighted? When you move through the text with the cursor, or backspace, etc. do you see the expected behaviour? (Some of the answers to these questions may be picker up in other sections, such as line-breaking, or initial-letter styling.) See available information or check for currently needed data.
3.9 Inline features & punctuation
Are there specific problems related to punctuation or the interaction of the text with punctuation (for example separation of punctuation from previous text, but allowing no line break between)? Are there issues related to handling of abbreviation, ellipsis, or iteration? Are there problems related to bracketing information or demarcating things such as proper nouns, etc? See available information or check for currently needed data.
3.10 Text decoration
This is about ways of marking text (see also specific sections dedicated to quotations and inline notes/annotations). Is it possible to express emphasis or highlight content as expected? Bold, italic and under-/over-lines are not always appropriate, and some scripts have their own unique ways of doing things, that are not in the Western tradition at all. Text delimiters mark certain items or sections off from the main text, such as book names in Chinese, quotations, head markers in Tibetan, etc, and often involve the use of punctuation. Is there any behaviour that isn't well supported, such as overlines for numeric digits in Syriac? Are there issues about the positioning or use of underlines? Some aspects related to the drawing of lines alongside or through text involve local typographic considerations. Do underlines need to be broken in special ways for this script? Do you need support for additional line shapes or widths? Does the distance or position of the lines relative to the text need to vary in ways that are not achievable? Are lines correctly drawn relative to vertical text? See available information or check for currently needed data.
3.12 Inline notes & annotations
The ruby spec currently specifies an initial subset of requirements for fine-tuning the typography of phonetic and semantic annotations of East Asian text, including furigana, pinyin and zhuyin fuhao systems. Is is adequate for what it sets out to do? What other controls will be needed in the future? What about other types of inline annotation, such as warichu? (For referent-type notes such as footnotes, see below.) See available information or check for currently needed data.
#41 In-page search fails on ruby-annotated text
This issue is applicable to all languages that use ruby markup (Chinese, Japanese, Mongolian, Korean).
If text is marked up for ruby, using the interleaved markup approach currently required by the HTML spec, a browser's in-page search no longer recognises the text. For example, if you search for 東京 on a page that has this markup:
<ruby><rb>東<rt>とう<rb>京<rt>きょう</ruby>
the search will fail to locate the word.
Note that a tabular arrangement of markup, such as
<ruby><rb>東<rb>京<rt>とう<rt>きょう</ruby>
would work fine but, although it is parsed correctly, this tabular markup is not displayed correctly by Blink or Webkit currently, and therefore the HTML specification has obsoleted the rb and rtc elements.
For more details, see this GitHub issue, which is being used to track this gap.
4. Lines and Paragraphs
4.1 Line breaking
Does the browser capture the rules about the way text in your script wraps when it hits the end of a line? Does line-breaking wrap whole 'words' at a time, or characters, or something else (such as syllables in Tibetan and Javanese)? What characters should not appear at the end or start of a line, and what should be done to prevent that? See available information or check for currently needed data.
See also hyphenation below.
4.2 Hyphenation
Is hyphenation used for your script, or something else? If hyphenation is used, does it work as expected? (Note, this is about line-end hyphenation when text is wrapped, rather than use of the hyphen and related characters as punctuation marks.) See available information or check for currently needed data.
#40 Browsers don't hyphenate Mongolian text
Hyphenation occurs in writing Mongolian and Todo. U+1806 MONGOLIAN TODO SOFT HYPHEN is used at the beginning of the second line to indicate resumption of a broken word. It functions like U+2010 HYPHEN, except that it appears at the _beginning_ of a line rather than at the end.
Specs:
issue Better describe the likely outcomes of hyphenation Open.
css-text Describes how to apply hyphenation. It makes no special mention of Mongolian, nor of which character to use and where.
css-text Has a hyphenate-character property which will allow users to specify the character to use for hyphenation, but it doesn't allow control of the location of the character.
Tests & results:
Webkit is unable to display traditional Mongolian script.
Interactive test, Mongolian text is hyphenated when hyphens:auto is set
Gecko and Blink fail to produce hyphenation.
Interactive test, Mongolian adds a hyphen to the start of the second line when a word is manually hyphenated with SHY
Gecko and Blink both fail. Gecko produces a long baseline extension at the bottom of the first line, which may or may not be a hyphen. Blink produces a hyphen that is horizontal and detached from the preceding text, at the end of the first line also.
i18n test suite, CSS3 Text, hyphens
General tests for hyphens support. (Results may need updating.)
Priority:
Marked as advanced, since hyphenation is optional.
4.3 Text alignment & justification
When text in a paragraph needs to have flush lines down both sides, does it follow the rules for your script? Does the script need assistance to conform to a grid pattern? Does your script allow punctuation to hang outside the text box at the start or end of a line? Where adjustments are need to make a line flush, how is that done? Do you shrink/stretch space between words and/or letters? Are word baselines stretched, as in Arabic? What about paragraph indents, or the need for logical alignment keywords, such as start/end, rather than left/right? See available information or check for currently needed data.
4.4 Letter spacing
Some scripts create emphasis or other effects by spacing out the words, letters or syllables in a word. Are there requirements for this script/language that are unsupported? (For justification related spacing, see below.) See available information or check for currently needed data.
4.5 Lists, counters, etc.
The CSS Counter Styles specification describes a limited set of simple and complex styles for counters to be used in list numbering, chapter heading numbering, etc.The rules plus more counter styles (totalling around 120 for over 30 scripts) are listed in the document Ready-made Counter Styles. Do these cover your needs? Are the details correct? Are there other aspects related to counters and lists that need to be addressed? See available information or check for currently needed data.
#36 Upright list counters not supported
This issue is applicable to Chinese, Japanese, Korean, and Mongolian.
A common way to orient counters for lists in vertical text is to have an upright number with a dot alongside it.

The expected way to achieve this in HTML would be to use the following CSS: li::marker { text-combine-upright: all; }, however this cannot be used because not all browsers support text-combine-upright applied to counters.
A workaround might be to use fullwidth characters for counters, such as ①, ②, ③ etc., but use of such a workaround requires the availability of custom built counter styles, and not all browsers currently support the CSS Counter Styles specification. So that doesn't work either.
It is a significant nuisance for content authoring to not be able to produce upright counters for lists.
For more details, see this GitHub issue, which is being used to track this gap.
4.6 Styling initials
Does the browser or ereader correctly handle special styling of the initial letter of a line or paragraph, such as for drop caps or similar? How about the size relationship between the large letter and the lines alongide? where does the large letter anchor relative to the lines alongside? is it normal to include initial quote marks in the large letter? is the large letter really a syllable? etc. Are all of these things working as expected? See available information or check for currently needed data.
5. Page & book layout
5.1 General page layout & progression
How are the main text area and ancilliary areas positioned and defined? Are there any special requirements here, such as dimensions in characters for the Japanese kihon hanmen? The book cover for scripts that are read right-to-left scripts is on the right of the spine, rather than the left. Is that provided for? When content can flow vertically and to the left or right, how do you specify the location of objects, text, etc. relative to the flow? For example, keywords 'left' and 'right' are likely to need to be reversed for pages written in English and page written in Arabic. Do tables and grid layouts work as expected? How do columns work in vertical text? Can you mix block of vertical and horizontal text correctly? Does text scroll in the expected direction? Other topics that belong here include any local requirements for things such as printer marks, tables of contents and indexes. See available information or check for currently needed data.
Are vertical form controls well supported? In right-to-left scripts, is it possible to set the base direction for a form field? Is the scroll bar on the correct side? etc. See available information or check for currently needed data.
All boxes used for form input should contain vertical text, should be rotated so that they progress down the page, and their content should progress in vertical lines from left to right. See User interaction in the requirements document. This is particularly important for Mongolian, among vertically set orthographies, because horizontal lines don't work.
Specs:
css-writing-modes-3 specifies the requirements for vertical text support, including examples of form controls rendered to match the writing mode.
Tests & results:
i18n test suite, Forms
Only Gecko vertically orients forms, but in pull-down select boxes it doesn't vertically orientate the selection options. Blink and Webkit fail to orient forms vertically at all. (The tests use Japanese text and don't check whether lines flow left to right for Mongolian.)
Here are some other tests, again in Japanese: standard syntax • proprietary syntax
Browser bug reports:
WebKit. The WebKit source has
358
359 input, textarea, keygen, select, button, meter, progress {
360 -webkit-writing-mode: horizontal-tb !important;
361 }
Priority:
This has a significant impact for creation of general web sites.