This document provides guidance to
DID method
developers, related to serialization, cryptographic primitive selection,
governance, and interoperability.
Guidance provided in this document does not necessarily reflect consensus
of the W3C DID WG, although
some members of the WG have contributed to it.
Status of This Document
This section describes the status of this
document at the time of its publication. Other documents may supersede
this document. A list of current W3C publications and the latest revision
of this technical report can be found in the
W3C technical reports index at
https://www.w3.org/TR/.
Implementers are advised to consult this guide if they are directly
involved with the W3C DID Working Group or are actively involved in
authoring a DID method.
Publication as a Working Group Note does not imply endorsement
by the W3C Membership.
This is a draft document and may be updated, replaced
or obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
This document was produced by a group
operating under the
W3C Patent
Policy.
The group does not expect this document to become a W3C Recommendation.
As well as sections marked as non-normative, all authoring guidelines, diagrams, examples, and notes in this specification are non-normative. Everything else in this specification is normative.
The key word SHOULD in this document
is to be interpreted as described in
BCP 14
[RFC2119] [RFC8174]
when, and only when, they appear in all capitals, as shown here.
See [DID-CORE] for normative requirements associated with developing
DID methods.
Avoid introducing requirements in your DID method specification that are
neither described in [DID-CORE] nor registered in the
[DID-SPEC-REGISTRIES].
Avoid constructing a new DID Method that is nearly identical to an
existing
DID Method.
There are several "families" of DID methods, including
Hyperledger
Indy, Sidetree, and
various methods that share similar smart contracts or rely on shared
content addressing technology.
Implementers are cautioned to write and regularly run integration and
interoperability tests that span these "families", in order to ensure
methods have sufficient support for open standards and real
interoperability.
The primary user-facing aspects of a DID method are its
DID Syntax and its
Verifiable Data Registry.
Together these determine most of the unique properties of a DID method,
and its privacy and security properties for comparison to other methods.
3.1 DID Syntax
This section is non-normative.
Note
See [DID-CORE] for normative requirements associated with developing
DID Syntax.
Avoid allowing users to control the structure of the DID Unique
Suffix, also referred to as the method-specific-id in the
DID Syntax ABNF. This
can be accomplished by coupling the
Create operation
canonical representation to the method-specific-id. It can
also be accomplished by leveraging sources of entropy.
Avoid vanity DIDs such as, for example,
did:example:deadbeef1f236.... The structure of the
identifier should not be relied on for anything other than collision
resistance. Be especially careful of trusting a relationship between a
DID subject and
DID controller
without relying on a cryptographically secure
verification
relationship
for authentication.
Anyone can claim a DID, but only someone who controls the associated
keys can authenticate their association with the DID.
For example did:example:xyzcorp should not be assumed to belong to
XYZ Corp.
Depending on the nature of the
VDR, publishing
type or kind might be advantageous for
decentralized discovery or mass surveillance. Implementers are not to
rely on conformance to specification text while implementing
decentralized identifiers.
The VDR is the system to which
DID method operations
such as Create, Resolve, Update, and Deactivate are applied.
Typically a globally-unique, tamper-evident, immutable log is used to
produce a verifiable data registry.
Blockchains or distributed ledgers are popular choices for building
verifiable data registries, but there are other solutions. Each yield
unique security pros and cons.
Some DID methods rely on centralized trusted service providers and
Merkle proofs to provide tamper-evident logs without the costs
associated with distributed consensus.
Some DID methods rely on multiple registries that may not be globally
available.
Few DID methods support portability across verifiable data
registries. Altering the VDR associated with a DID will almost
certainly impact Privacy and Security considerations.
Instead of designing complex DID methods with registry portability,
consider supporting multiple DID methods that have each been designed
to support disjoint security and/or privacy consideration, such as
global discoverability, offline functionality, pairwise uniqueness,
linkage to existing roots of trust such as websites, etc.
Depending on the nature of the VDR, it may be desirable to store data
other than DID documents, such as verifiable credentials,
templates or schemas for credentials, discovery metadata, or integrity-
or content-addressable identifiers for related information.
3.3 Establishing a DID
This section is non-normative.
In order to create secure DID systems, it is important to consider the
process
of establishing a Decentralized Identifier.
Establishing cryptographic assurances for the identifier from its
inception is critical to ensuring that the security of the system isn't
compromised through attacks against the creation process.
A commonly observed process for establishing a decentralized identifier
is:
Obtain entropy from a source of randomness that is as
close to actually random as possible.
Generate a first verification method from entropy.
The Create Operation will often use the first verification method
directly, or a deterministic
function thereof, such as a hash, to construct and register the DID.
Note
True randomness is hard to get. Public sources such as the
NIST
Randomness Beacon
are reliable but not appropriate for use directly as a secret key. See
the
section on Randomness for more information.
DID resolution is a function which takes a DID, and produces a DID
resolution result in a representation, most commonly
JSON.
DID resolution can be proxied through intermediaries such as
command-line
tools or HTTP servers. Because the DID document contains key
material, such intermediaries represent excellent targets for attackers,
who can use the intermediaries to tamper with verification
relationships.
Avoid tampering with a DID document that has been returned by a
DID resolver.
It is better to throw an error than to attempt to solve problems
in the underlying DID method.
Avoid transforming DID documents without the consent of the DID subject
or controller.
Whenever possible, run all software necessary to support a DID Method
yourself.
The [DID-CORE] specification describes representations. The
[DID-SPEC-REGISTRIES] supports the registration of an unbounded
number of alternative representations.
Each representation has unique pros and cons.
DID Methods are responsible for producing a DID document in the
requested representation.
DID method implementers may choose to return verification methods in
alternate formats for representations, for example, an implementer
might prefer to return verification material encoded with
publicKeyJwk for application/did+json and
publicKeyBase58 for application/did+ld+json.
Avoid allowing arbitrary unknown properties such as
__proto__
or other characters that might be used to attack JSON parsing into
application/did+json .
While application/did+json is very flexible and allows
for arbitrary JSON, implementers are cautioned to implement security
in depth.
There is no strong consensus regarding preserving data model properties
across representations.
Removing properties when converting a did document can result in an
inability to maintain
interoperability with [VC-DATA-MODEL]. See Drawbacks and Benefits.
4.1 Drawbacks
The DID document data model contains “properties” (such as id,
verificationMethod, and service), which are
defined in a way that is independent of a concrete representation. There
are a number of known representations,
including JSON and JSON-LD (defined by DID Core), and CBOR (defined by a
DID WG Note). Additional
representations
(such as XML, YAML, CBOR-LD, and others) are possible and may be defined
in the future. For each of these
representations, a combination of production and consumption rules
defines the concrete syntax of properties,
but
the semantics of properties are independent of any given representation.
In other words, in every representation
of a DID document, there is always a way to represent a service or a
verificationMethod, and their meanings
are consistent across conformant representations.
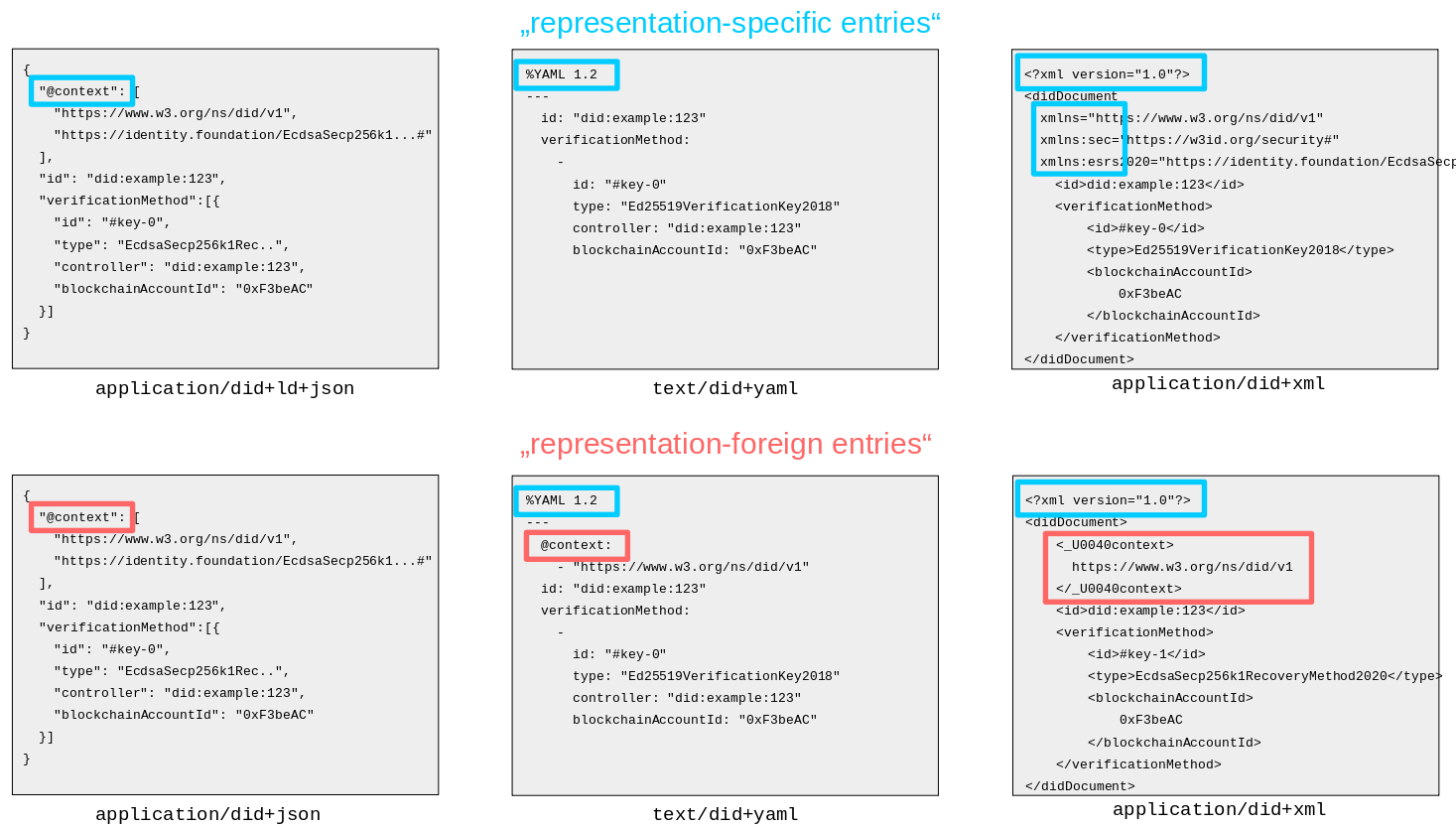
In addition to “properties”, a DID document may contain
“representation-specific entries” which may be
required by certain representations in order to fully represent the DID
document data model and its
properties. For example, the JSON-LD representation of a DID document
(with media type
application/did+ld+json) requires the
@context representation-specific entry, in order to correctly express
the semantics of properties such as
id,
verificationMethod or service within the JSON-LD representation.
This enables JSON-LD’s semantics which are
based on a decentralized, permissionless, open-world data model.
In contrast to this, the (non-LD) JSON representation (with media type
application/did+json) does not have
this semantic
capability; instead, (non-LD) JSON documents always need agreement on
semantics in some out-of-band way that is
not part of the document itself. In the case of DID documents using the
(non-LD) JSON representation, those
semantics are
typically established by the DID Spec
Registries.
Therefore,
establishing semantics of DID document properties in the (non-LD) JSON
representation does not require
the representation-specific @context entry, as is required by the
JSON-LD representation.
Similar holds true for the (non-LD) CBOR representation.
Other examples of “representation-specific entries” could be XML
namespace definitions or YAML tags, although
these particular representations have not been defined at the time of
this writing.
If an entry that is specific to one representation appears in another
representation, it can be called a
"representation-foreign entry". An example of this is an @context
entry appearing in the
application/did+json
representation.
Examples of “representation-specific entries” and
“representation-foreign entries”:
Figure 1
Representation-specific and representation-foreign entries.
4.1.1
Avoid representation-foreign entries
This section is non-normative.
It is bad practice and potentially harmful for producers to include
"representation-foreign entries" in DID
documents.
Different implementations of DID document consumers may or may not be
able to properly understand the meaning
and processing rules of representation-foreign entries. Since DIDs and
DID documents form an open ecosystem
with
many producers and consumers, a producer cannot anticipate the
behavior of a consumer with regard to
representation-foreign entries.
For example, if a producer adds an @context entry to a DID document
in the application/did+json
representation, some consumers (those that understand JSON-LD, such as
JSON-LD document loaders) may process
it
in one way, while other consumers (those that only understand plain
JSON, without any JSON-LD specific rules)
may process it in a different way.
This can lead to inconsistent behavior by consumers that cannot be
predicted by a producer.
4.1.2
Reliance on representation-foreign entries
This section is non-normative.
It is bad practice and potentially harmful for consumers to rely on
"representation-foreign entries" in DID
documents.
As a special case of the previous section, certain consumers may go as
far as relying on the presence of
representation-foreign entries. For example, an incorrectly
implemented consumer of DID documents in the
application/did+json representation may attempt to apply JSON-LD
tooling to that representation. That
tooling
is dependent on the presence of the @context representation-foreign
entry, which is not actually required
(and
in fact discouraged) to be used in the application/did+json
representation.
The result is lack of interoperability, since such consumers will
throw errors even if the returned DID
document
representation is actually conformant.
4.1.3
Security problems with representation-foreign entries
This section is non-normative.
If some implementations of DID document consumers process
representation-foreign entries, and others don’t,
then
this can lead to security holes, since the semantics of DID document
properties will not be interpreted in a
predictable way.
For example, consider the following DID document, and assume that the
JSON-LD context
https://myextensions.com/other-definitions.jsonld defines
blockchainAccountId in a way that is different
from the property
listed in the DID
Specification Registries.
Example 7: A DID document in the `application/did+json` representation with the `@context` representation-foreign entry
If this DID document is consumed as application/did+json by an
implementation that doesn't understand
JSON-LD,
it will interpret blockchainAccountId as the >property
listed in the DID
Specification Registries, and it will process it accordingly.
If the exact same DID document is consumed as application/did+json
by an implementation that understands
JSON-LD, it may interpret blockchainAccountId using the provided
JSON-LD context, and therefore process it
differently.
It is a common mistake to claim that "JSON-LD is just JSON", and to
justify injecting the @context
representation-foreign entry into a DID document in the
application/did+json representation. This claim
however is true only on the syntax level, but wrong and dangerous on
the semantic level, especially when
security-related properties are involved. In the example above,
different consumer implementations are likely
to
come to different conclusions on how the DID can be controlled.
Representation-foreign entries in DID documents should be avoided,
since they can lead to inconsistent and
unpredictable DID control decisions.
4.1.4
Conversion between Representations
This section is non-normative.
The DID document data model and the production/consumption rules of
representations have been designed to
enable
lossless conversion between representations. Conversion between
representations is achieved by executing the
consumption rules of the source representation, and then the
production rules of the target representation.
The DID Specification Registries [DID-SPEC-REGISTRIES] provide additional
information about properties as well as representation-specific
entries that help with such conversion. For
example, a DID document in the application/did+json representation
can be converted to the
application/did+ld+json representation by adding a @context
representation-specific entry during
production,
using the JSON-LD context information in the DID Specification Registries [DID-SPEC-REGISTRIES].
Conversely, a DID document in the application/did+ld+json
representation can be converted to the
application/did+json representation by removing the @context
representation-specific entry during
consumption.
Representation-foreign entries in DID documents should be avoided,
since the implications on lossless
conversion
between representations is unclear.
4.2 Benefits
Implementers are not required to support all representations.
For example, an implementation might choose to only support
application/did+json,
and choose not to support application/did+ld+json,
application/did+dag+cbor,
application/did+xml, application/did+yaml,
etc...
Implementers might prefer to use JSON or YAML representations to
implement both the
abstract data model and concrete reprepresentations.
When converting between an implementation of the abstract data model and
a
representation that is capable of preserving all properties,
all properties SHOULD be preserved.
For example, preserving @context in YAML,
allows for the document to later be used with
documentLoaders
that use
frame to perform
dereferencing.
DID Methods that support both application/did+ld+json and
application/did+json
ought to return application/did+json with an
@context, because it enables
both representations to be used with tooling and standards that support
semantics (such as [VC-DATA-MODEL]),
and because the default behavior of JSON processors is to ignore object
members that are not understood.
DID Document representations produced by an implementation ought to be
treated as immutable,
since any tampering, including adding, removing, or reordering core or
representation specific entries
might be considered malicious, since it alters the integrity of the
produced DID Document.
5. Privacy Considerations
This section is non-normative.
Decentralized Identifiers, like any other technology, can be used to
enhance privacy as well as harm privacy. This section speaks to topics
that implementers might consider when thinking about the privacy
characteristics of their software systems.
5.1
Dealing with Personal Data
This section is non-normative.
Never store personal data, even in an encrypted format, on any
verifiable data
registry backed by immutable storage.
It is the DID method implementer's responsibility to think about and
identify
the extent to which personal data may be included in a DID document.
Software should at least display a warning and ask for confirmation
before creating
or updating any properties of a DID document that depend on user
provided inputs.
A DID method specification should have a section dedicated to personal
data covering the extent to
which information published on the corresponding ledger can be updated
or deleted.
It should provide specific instructions of how to do so, if it is
possible.
Otherwise, it should clearly state that it is not possible.
A DID method should avoid "phone home" or tracking characteristics that
would
permit tracing of a user in manner not understood or authorized by the
user
by some third party.
5.2 Avoid correlation
This section is non-normative.
Avoid reusing verification methods across DID Methods.
Avoid reusing services with unique parameters across DID Methods.
Any anonymous identifier, even if it is generated randomly, can be used
to
infer sensitive information about a
DID subject
if it is reused enough times.
A DID method implementer should rotate keys and identifiers as often as
possible
to avoid correlation
5.3 Anonymity
This section is non-normative.
Consider formally modeling the privacy implications associated with
your implementation using
t-closeness or
other mechanisms.
If your DID Method supports global enumeration and indexing, consider
exposing this information publicly. You may wish to provide alerts
similar to services that watch version control systems for sensitive
information that is accidentally leaked.
5.4 Compliance
This section is non-normative.
Review any applicable local law when considering developing or
operating a decentralized identifier method.
Decentralized Identifiers are security primitives that are often used to
secure important systems. This section speaks to topics that
implementers might consider when thinking about the security
characteristics of their software systems.
Pay very close attention to the defense, cryptographic agility, and
political
acceptability of any cryptography you rely on for DID Method security.
Avoid complex or slow signature formats, especially if they are poorly
documented, or do not have an open standard with well documented test
vectors.
Avoid open source implementations that are declared a "defacto
standard", but lack open standard technical specifications.
Support for legacy cryptography systems such as
JOSE
and OpenPGP should be considered
due to their prevalence in existing systems.
6.1 Vendor Lock In
This section is non-normative.
Competition, direct substitutability, interoperability, and mutual
feature support are key to reducing the barriers to adoption of, and
increasing confidence in, your DID Method.
Avoid inventing "new features". Work with others to find a common way
to express any new features that are not unique to your DID Method.
Avoid hard coupling to specific networks, such as Bitcoin or
Hyperledger Fabric. Design your method such that it may be adapted
to support multiple ledger systems.
Transparency and openness in approaches related to security not only
lead to greater security, but promote interoprability and adoption.
6.2 Digital Signatures
This section is non-normative.
We recommend the user review
safecurves.cr.yp.to before
selecting elliptic curve types. A key note however, is that several
items on safecurves are less frequently updated.
In addition to safecurves you should always check the top level
standards
and any docs which superseed referenced standards in safecurves,
especially
FIPS 186-4 and
SP 800-56A Rev 3 when evalutating curves for use.
Avoid secp256k1, RSA, P-256, P-384 and P-521.
Avoid relying on smart contracts for complex data management. If you
must use a smart contract, keep it simple and architect a solution
that supports data migration.
6.3 Hashing Algorithms
This section is non-normative.
Avoid MD5, SHA1, and other legacy hashing algorithms with known
weaknesses
or high collision rates.
When in doubt in selection of a hashing algorithm, consult the
NIST documentation related to hash function selection,
SHA-3 as described in FIPS 202
should be strongly considered for new implementations
6.4 Randomness
This section is non-normative.
When making an implemention carefully consider how you are sourcing
random numbers. Consult
RFC 4086:
Randomness Requirements for Security
when selecting an approach to get random bits, and pay careful attention
to the platform and any underlying hardware that may be in use as multiple
attacks have been performed in the wild due to improper selection of
random values in key material and other aspects of cryptography.
6.5 Zero Knowledge Proofs
This section is non-normative.
Consider using
BBS+ Signatures
for selective disclosure and linked-secret–based JSON-LD
verifiable
credentials.
The IETF document on
Pairing Friendly Curves
should be consulted when selecting curves for usage with zero
knowledge proofs,
especially to ensure that appropriate embedding degrees are selected,
and that
the resulting equivalent bit characteristics are sufficient.
Avoid zero knowledge proofs as described in the
AnonCredDerivedCredentialv1.
This proof format is coupled to specific ledger technologies,
similar to the concept of an ethereum virtual machine smart contract
only running on EVM compatible ledgers. Ledger-specific technologies
should be avoided when designing for portable, interoperable, and
open-standards–based zero knowledge proofs.
Avoid storing credential schemas on ledgers. Many DID methods cannot
store information other than a DID Document, which reduces the direct
interoperability, substitutability, and cost effectiveness of
solutions that make use of rare or poorly supported features such as
credential schema definition storage.
6.6 Biometrics
This section is non-normative.
Avoid relying exclusively on biometrics.
Hardware-isolated keys protected by biometrics on devices may increase
the usability of DIDs.
The addition of biometrics to other techniques can aid in certain tasks
such as reauthentication.
NIST SP
800-63B
deals directly with digital identity and has several useful sections
that address appropriate language for describing biometrics usage as
well
as techniques for incorporating biometrics into an approach for solving
problems related to digital identity.
7. Future Work
Note
This section was copied from
w3c/did-imp-guide, and
adjusted based on changes made to DID
Core.
7.1 Upper Limits on DID Character Length
The current specification does not take a position on the maximum length
of a
DID.
The maximum interoperable URL length is currently about
2048 characters. QR codes can handle about 4096 characters. Clients
using DIDs
will be responsible for storing many DIDs,
and some methods would be able to externalize some of their costs
onto clients by relying on more complicated signature schemes or by
adding state into DIDs
intended for temporary use. A future
version of this specification should set reasonable limits on
DID character
length to minimize externalities.
7.2 Verifiable Timestamps
Verifiable Timestamps have significant utility for identifier
records. This is a good fit for DLTs, since
most
offer some
type of timestamp mechanism. Despite some transactional cost, they
are the among the most censorship-resistant transaction ordering
systems at the present, so they are nearly ideal for
DID document
timestamping. In some cases a DLT's
immediate timing is approximate, however their sense of "median time
past"
(see Bitcoin BIP 113)
can be precisely defined. A generic DID document timestamping
mechanism could would work across all DLTs and
might operate
via a mechanism including either individual transactions or
transaction batches. Such a generic mechanism was deemed out of scope
for this version, although it may be included in a future version of
this specification.
7.3 Verifiable Credentials
Although DIDs
and DID documents form a
foundation for
decentralized identity, they are only the first step in describing
their subjects. The rest of the descriptive power comes through
collecting and selectively using Verifiable Credentials
[VC-DATA-MODEL]. Future versions of the specification will
describe in more detail how DIDs
and DID document can
be integrated with — and help enable — the Verifiable
Credentials ecosystem.
7.4 Alternate Serializations and Graph Models
This version of the specification relies on JSON-LD and the RDF
graph model for expressing a DID document. Future
versions of
this specification might specify other semantic graph formats for a
DID document.