Does the browser or ereader correctly handle special styling of the initial letter of a line or paragraph, such as for drop caps or similar? How about the size relationship between the large letter and the lines alongide? where does the large letter anchor relative to the lines alongside? is it normal to include initial quote marks in the large letter? is the large letter really a syllable? etc. Are all of these things working as expected? See available information or check for currently needed data.
#115 Consonant clusters with a visible virama should only have the first consonant+virama highlighted
This issue is applicable to most languages that form conjuncts from consonant clusters using a visible virama.
When the start of a line contains a 2-consonant cluster that uses a visible virama, ::first-letter should highlight only the first consonant+virama. This corresponds to a grapheme cluster, as defined by Unicode.
Specs:
css-text-3 CSS uses the concept of 'typographic character unit', which defaults to a grapheme cluster. The spec doesn't provide details about the support needed for each language.
The Unicode Consortium defines grapheme clusters to, by default, stop after the first virama in a cluster.
Tests & results:
Interactive test, When ::first-letter is applied to Devanagari the browser will NOT select a 2-consonant cluster as a unit if the virama is visible
Interactive test, When ::first-letter is applied to Bengali the browser will only select the first consonant+virama in a cluster if the virama is visible
Gecko only highlights the initial character+virama. Blink, and Webkit select all clusters as a single unit, whether or not they are conjuncts or are rendered with a visible virama.
Browser bug reports:
Blink • WebKit
Priority:
This choice needs to be discussed. If a cluster is rendered as a conjunct, it should be selected as a single unit. If, instead, the virama is displayed (ie. it is not a conjunct) then only the initial part of the cluster should be selected. Since the underlying code points are identical if a cluster is displayed as a conjunct or instead with visible viramas, it's not possible to distinguish one situation from another by working with the code points. In the absence of a technical solution that examines what the font used does when rendering, this is a difficult problem to solve. This priority rating says that, in the absence of a perfect solution, it is better to select a whole non-conjunct cluster than to break a conjunct. So it is labelled advanced, rather than basic.
#94 Conjuncts are not selected as a single unit when styling initials
This issue is applicable to most languages that form conjuncts from consonant clusters using an invisible virama.
When the start of a line contains a consonant cluster that uses a conjunct (rather than visible virama), ::first-letter should highlight the whole cluster.
Consonant clusters that form conjuncts using an invisible virama between the component letters need to be selected as a unit. This doesn't work well if segmentation relies on Unicode grapheme clusters, since a conjunct with two consonants will be parsed as two grapheme clusters (the first ending after the virama, and the second starting with the second consonant and including any following vowel-signs or other combining characters).
For these situations it is necessary to tailor the segmentation algorithm, so that it recognises the whole consonant cluster plus any attached vowel-signs or combining characters as a single unit.
For examples see Typographic character units in complex scripts.
Specs:
css-text-3 CSS uses the concept of 'typographic character unit', rather than grapheme cluster, in its specs with the explanation that the cases just described go beyond the scope of the grapheme cluster concept and that implementations should provide appropriate support. The spec doesn't provide details about the support needed for each language.
The Unicode Consortium made some attempts to address this issue, but it has so far not yielded results. CLDR now flags up a few scripts for which conjuncts are common.
Tests & results:
Interactive test, When ::first-letter is applied to Devanagari the browser will select a 2-consonant conjunct as a unit
Interactive test, When ::first-letter is applied to Bengali the browser will select a conjunct as a unit, if the virama is hidden
- Gecko: ✅❌ Most of the half-form conjuncts fail (which is the large majority of all conjuncts in Devanagari), and are broken into an initial consonant with visible virama and a following consonant.
- Blink: ✅ All conjuncts are fully selected.
- Webkit: ✅ All conjuncts are fully selected.
I18n test suite, Devanagari textBrowser bug reports:
Gecko
Priority:
Keeping conjuncts together is a pretty basic requirement. Without a fix for this, authors need to manually mark up text to apply initial letter styling, but that isn't a very useful workaround.
#84 initial-letter positioning is not widely available
Having selected the correct text for highlighting, it is important to ensure proper alignment of the baseline and height of the initial letter highlight relative to the other lines of text. This doesn't work well without help from the dedicated CSS properties, initial-letters and the initial-letters-align. Unfortunately, only Safari supports the first property, and it requires the -webkit prefix, so this is still an immature feature.
Safari aligns the alphabetic baseline of the highlighted text with that on the specified number of lines. The relationship between the highlighted letters and the first line of the paragraph appears to be based on cap height, but is not clear. The requirements for that relationship are not yet really clear, despite the information in Indian Layout Requirements.
The impact here is advanced, since it is mainly needed for advanced layouts.
#67 Letter-spacing & first-letter selection must keep yo-phola with preceding independent vowels
This issue is applicable to Bengali and Assamese.
The issues Letter-spacing splits conjuncts and Conjuncts are not selected as a single unit when styling initials describe how conjuncts should not be split by letter-spacing. See those issues for more details.
This topic builds on that for some specific cases in Bengali.
There are two cases in Bengali where hasant (virama) is preceded by an independent vowel, rather than a consonant. These are:
- অ্যা [U+0985 BENGALI LETTER A + U+09CD BENGALI SIGN VIRAMA + U+09AF BENGALI LETTER YA + U+09BE BENGALI VOWEL SIGN AA], and
- এ্যা [U+098F BENGALI LETTER E + U+09CD BENGALI SIGN VIRAMA + U+09AF BENGALI LETTER YA + U+09BE BENGALI VOWEL SIGN AA]
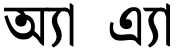


(In both cases this produces the sound æ, used for non-native words, such as 'application', 'administration' etc.)
This combination should not be split either, even though it doesn't fit the typical CvC structure of a conjunct (where 'v' is the virama).
Specs:
css-text-3 CSS uses the concept of 'typographic character unit', rather than grapheme cluster, in its specs with the explanation that the cases just described go beyond the scope of the grapheme cluster concept and that implementations should provide appropriate support. The spec doesn't provide details about the support needed for each language.
Tests & results:
Both of the following tests were run with the following pre-installed fonts:
Windows: Shonar Bangla, Arial Unicode MS, Nirmala UI, Vrinda
Mac: Bangla MN, Bangla Sangam MN, Kohinoor Bangla, Tiro Bangla, Baloo Da
Also tested with Noto Sans Bengali and Noto Serif Bengali on the Mac.
Interactive test, Bengali অ্যা and এ্যা (æ) are selected as a single grapheme by ::first-letter.
- Gecko: ✅❌ Mac: fails for Bangla MN, and Bangla Sangam MN, but passes for the other 3 fonts. Windows: works fine for all fonts.
- Blink: ❌ Mac & Windows: fails for all fonts.
- Webkit: ❌ Mac: fails for all fonts. It was not possible to apply the Noto fonts.
Note that Blink and Webkit actually handle the more usual CvC conjunct arrangement (see this test).Interactive test, Bengali অ্যা and এ্যা (æ) are treated as a single grapheme for letter-spacing.
- Gecko: ✅❌ Windows: works with all fonts. Mac: fails with Bangla MN, Bangla Sangam MN, and Baloo Da, but works with the others. Works with Noto fonts.
- Blink: ✅❌ Windows: works with all fonts. Mac: same results as for Gecko.
- Webkit: ❌ Mac: failed for all fonts. In fact, letters were all spaced individually, rather than by grapheme cluster. Could not apply Noto fonts.
Gecko, Blink, and Webkit all fail to treat the sequence as a single grapheme, despite the fact that Blink and Webkit actually handle the more usual CvC conjunct arrangement (see this test).
Browser bug reports:
Gecko • Blink • Webkit
Priority:
Keeping such sequences together is a pretty basic requirement. That said, first-letter selection and letter-spacing are not essential for content authoring, although Bengali content authors should still have equal access to these styling features as Westerners. Content authors could work around the first-letter problem by adding markup (though that's not ideal), but for letter-spacing there is no real alternative, and adding spaces between letters ruins the semantics. The priority was set to advanced.