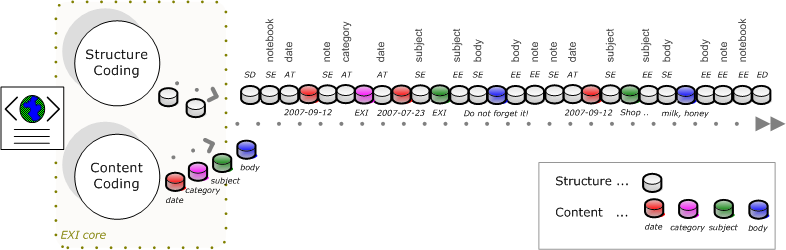
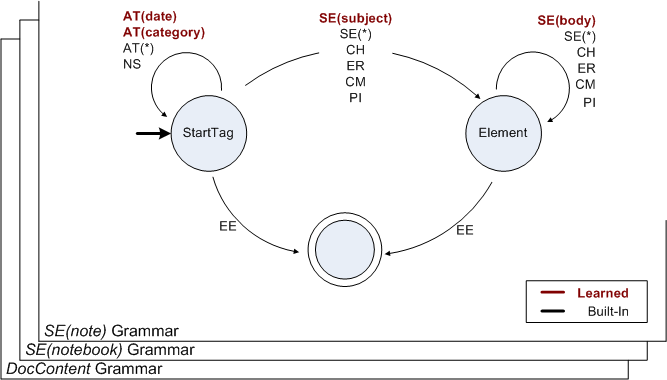
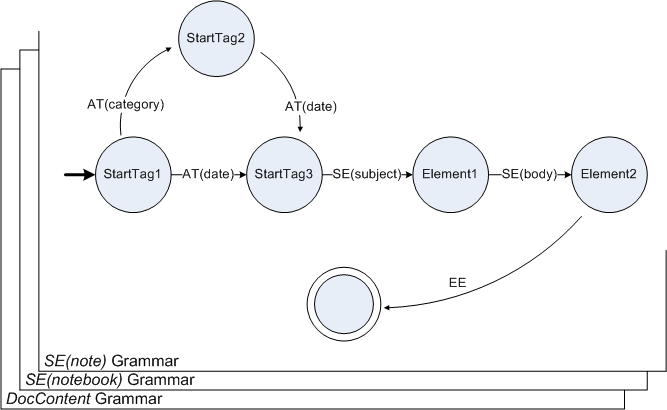
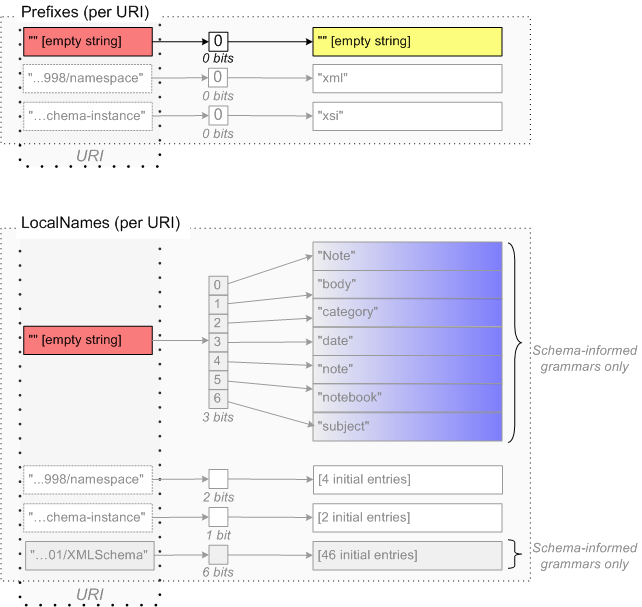
|
| 00
| SD | |
- The Document grammar is the starting point for any EXI document.
Given that there is only one possible production
SD, the associated Event Code 0 is represented in
zero bits (i.e., omitted).
- The current Document grammar moves on to the
DocContent grammar.
|
|
| 00
| SD | |
<?xml version="1.0"
encoding="UTF-8"?>
|
|
| 00
| SE | 12 "notebook"+1
|
Decode content as qname.
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
"notebook"+1 (literal local-name) Add it to local-name partition for uri "" (empty string). | Local-Names (default) |
|---|
| 0 | "notebook" |
Then,
- DocContent moves on to DocEnd and StartTagNotebook is
pushed on grammar-stack
|
| DocContent |
|---|
| SE(notebook) | DocEnd | 0 | | [Undeclared] | | 1 |
| 01
| SE | |
- DocContent moves on to DocEnd and StartTagNotebook1 is
pushed on grammar-stack
|
<notebook>
|
| StartTagNotebook |
|---|
| EE | 0.0 | | AT(*) | StartTagNotebook | 0.1 | | SE(*) | ElementNotebook | 0.2 | | CH | ElementNotebook | 0.3 |
| 00 12
| AT |
12 "date"+1 "2007-09-12"+2
|
Decode content as qname and value (String)
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
"date"+1 (literal local-name) Add it to local-name partition for uri "" (empty string). | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" |
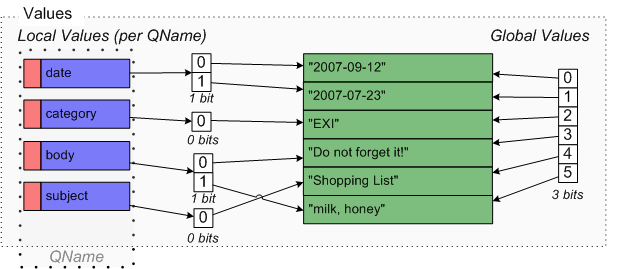
"2007-09-12"+2 (literal string value) Add it to local value partition for qname date. | Values (date) |
|---|
| 0 | "2007-09-12" |
Then,
- StartTagNotebook extended by leading AT(date)
|
| StartTagNotebook1 |
|---|
| AT(date) | StartTagNotebook2 | 0 | | SE(note) | ElementNotebook1 | 1 | | [Undeclared] | | 2 |
| 02
| AT | 01 7uint 3009 01 |
Decode content as value of Date-Time (date):
- 01 7uint (Year offset from 2000 as Integer)
- 3009 (Month*32+Day as 9-bit Unsigned Integer)
- 01 (TimeZone presence indicator as Boolean)
to reconstitute "2007-09-12".
Then,
- StartTagNotebook1 moves on to StartTagNotebook2
|
date = "2007-09-12"
|
| StartTagNotebook |
|---|
| AT(date) | StartTagNotebook | 0 | | EE | 1.0 | | AT(*) | StartTagNotebook | 1.1 | | SE(*) | ElementNotebook | 1.2 | | CH | ElementNotebook | 1.3 |
| 11 22
| SE | 12 "note"+1
|
Decode content as qname.
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
"note"+1 (literal local-name) Add it to local-name partition for uri "" (empty string). | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" | | 2 | "note" |
Then,
|
| StartTagNotebook2 |
|---|
| SE(note) | ElementNotebook1 | 0 | | [Undeclared] | | 1 |
| 01
| SE | |
- StartTagNotebook2 moves on to ElementNotebook1 and
StartTagNote1 is pushed on grammar-stack
|
<note>
|
| StartTagNote |
|---|
| EE | 0.0 | | AT(*) | StartTagNote | 0.1 | | SE(*) | ElementNote | 0.2 | | CH | ElementNote | 0.3 |
| 00 12
| AT | 12 "category"+1 "EXI"+2
|
Decode content as qname and value (String).
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
"category"+1 (literal local-name) Add it to local-name partition for uri "" (empty string). | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" | | 2 | "note" | | 3 | "category" |
"EXI"+2 (literal string value) Add it to local value partition for qname category.
Then,
|
| StartTagNote1 |
|---|
| AT(category) | StartTagNote2 | 0 | | AT(date) | StartTagNote3 | 1 | | [Undeclared] | | 2 |
| 02
| AT | "EXI"+2
|
Decode content as value (String).
"EXI"+2 (literal string value) Add it to local value partition for qname category.
Then,
- StartTagNote1 moves on to StartTagNote2
|
category="EXI"
|
| StartTagNote |
|---|
| AT(category) | StartTagNote | 0 | | EE | 1.0 | | AT(*) | StartTagNote | 1.1 | | SE(*) | ElementNote | 1.2 | | CH | ElementNote | 1.3 |
| 11 12
| AT |
12 0uint 12 "2007-07-23"+2
|
Decode content as qname and value (String).
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
0uint 12 (local-name id) | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" | | 2 | "note" |
"2007-07-23"+2 (literal string value) Add it to local value partition for qname date. | Values (date) |
|---|
| 0 | "2007-09-12" | | 1 | "2007-07-23" |
Then,
|
| StartTagNote2 |
|---|
| AT(date) | StartTagNote3 | 0 | | [Undeclared] | | 1 |
| 01
| AT | 01 7uint 2479 01 |
Decode content as value of Date-Time (date):
- 01 7uint (Year offset from 2000 as Integer)
- 2479 (Month*32+Day as 9-bit Unsigned Integer)
- 01 (TimeZone presence indicator as Boolean)
to reconstitute "2007-07-23".
Then,
- StartTagNote2 moves on to StartTagNote3
|
date="2007-07-23"
|
| StartTagNote |
|---|
| AT(date) | StartTagNote | 0 | | AT(category) | StartTagNote | 1 | | EE | 2.0 | | AT(*) | StartTagNote | 2.1 | | SE(*) | ElementNote | 2.2 | | CH | ElementNote | 2.3 |
| 22 22
| SE | 12 "subject"+1
|
Decode content as qname.
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
"subject"+1 (literal local-name) Add it to local-name partition for uri "" (empty string). | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" | | 2 | "note" | | 3 | "category" | | 4 | "subject" |
Then,
|
| StartTagNote3 |
|---|
| SE(subject) | ElementNote1 | 0 | | [Undeclared] | | 1 |
| 01
| SE | |
- StartTagNote3 moves on to ElementNote1 and
StartTagSubject1 is pushed on grammar-stack
|
<subject>
|
| StartTagSubject |
|---|
| EE | 0.0 | | AT(*) | StartTagSubject | 0.1 | | SE(*) | ElementSubject | 0.2 | | CH | ElementSubject | 0.3 |
| 00 32
| CH | 1uint 12
|
Decode content as value (String).
1uint 12 (value id in global value partition) | Global-Values |
|---|
| 0 | "2007-09-12" | | 1 | "EXI" | | 2 | "2007-07-23" |
Then,
|
| StartTagSubject1 |
|---|
| CH | ElementSubject1 | 0 | | [Undeclared] | 1 |
| 01 | CH | 1uint 00
|
Decode content as value (String).
1uint 00 (value id in global value partition)
Then,
|
EXI
|
| ElementSubject |
|---|
| EE | 0 | | SE(*) | ElementSubject | 1.0 | | CH | ElementSubject | 1.1 |
| 01
| EE | |
|
| ElementSubject1 |
|---|
| EE | 0 | | [Undeclared] | 1 |
| 01
| EE | |
|
</subject>
|
| ElementNote |
|---|
| EE | 0 | | SE(*) | ElementNote | 1.0 | | CH | ElementNote | 1.1 |
| 11 01
| SE | 12 "body"+1
|
Decode content as qname.
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
"body"+1 (literal local-name) Add it to local-name partition for uri "" (empty string). | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" | | 2 | "note" | | 3 | "category" | | 4 | "subject" | | 5 | "body" |
Then,
|
| ElementNote1 |
|---|
| SE(body) | ElementNote2 | 0 | | [Undeclared] | 1 |
| 01 | SE | |
|
<body>
|
| StartTagBody |
|---|
| EE | 0.0 | | AT(*) | StartTagBody | 0.1 | | SE(*) | ElementBody | 0.2 | | CH | ElementBody | 0.3 |
| 00 32
| CH | "Do not forget it!"+2
|
Decode content as value (String).
"Do not forget it!"+2 (literal string value) Add it to local value partition for qname body. | Values (body) |
|---|
| 0 | "Do not forget it!" |
Then,
|
| StartTagBody1 |
|---|
| CH | ElementBody1 | 0 | | [Undeclared] | 1 |
| 01 | CH | "Do not forget it!"+2
|
Decode content as value (String).
"Do not forget it!"+2 (literal string value) Add it to local value partition for qname body. | Values (body) |
|---|
| 0 | "Do not forget it!" |
Then,
|
Do not forget it!
|
| ElementBody |
|---|
| EE | 0 | | SE(*) | ElementBody | 1.0 | | CH | ElementBody | 1.1 |
| 01
| EE | |
|
| ElementBody1 |
|---|
| EE | 0 | | [Undeclared] | 1 |
| 01
| EE | |
|
</body>
|
| ElementNote |
|---|
| SE(body) | ElementNote | 0 | | EE | 1 | | SE(*) | ElementNote | 2.0 | | CH | ElementNote | 2.1 |
| 12
| EE | |
|
| ElementNote2 |
|---|
| EE | 0 | | [Undeclared] | 1 |
| 01
| EE | |
|
</note>
|
| ElementNotebook |
|---|
| EE | 0 | | SE(*) | ElementNotebook | 1.0 | | CH | ElementNotebook | 1.1 |
| 11 01
| SE | 12 0uint 23
|
Decode content as qname.
12 makes uri id 0 (i.e. 12 - 1 = 0) | URIs |
|---|
| 0 | "" [empty string] | | 1 | ".../XML/1998/namespace" | | 2 | ".../XMLSchema-instance" |
0unit 23 (local-name id) | Local-Names (default) |
|---|
| 0 | "notebook" | | 1 | "date" | | 2 | "note" | | 3 | "category" | | 4 | "subject" | | 5 | "body" |
Then,
|
| ElementNotebook1 |
|---|
| SE(note) | ElementNotebook1 | 0 | | EE | 1 | | [Undeclared] | 2 |
| 02 | SE | |
|
<note>
|
| StartTagNote |
|---|
| SE(subject) | ElementNote | 0 | | AT(date) | StartTagNote | 1 | | AT(category) | StartTagNote | 2 | | EE | 3.0 | | AT(*) | StartTagNote | 3.1 | | SE(*) | ElementNote | 3.2 | | CH | ElementNote | 3.3 |
| 12
| AT | 0uint 01
|
Decode content as value (String).
0uint 01 (value id in local value partition for qname date) | Values (date) |
|---|
| 0 | "2007-09-12" | | 1 | "2007-07-23" |
|
| StartTagNote1 |
|---|
| AT(category) | StartTagNote2 | 0 | | AT(date) | StartTagNote3 | 1 | | [Undeclared] | | 2 |
| 12
| AT | 01 7uint 3009 01 |
Decode content as value of Date-Time (date):
- 01 7uint (Year offset from 2000 as Integer)
- 3009 (Month*32+Day as 9-bit Unsigned Integer)
- 01 (TimeZone presence indicator as Boolean)
to reconstitute "2007-09-12".
Then,
- StartTagNote1 moves on to StartTagNote3
|
date="2007-09-12"
|
| StartTagNote |
|---|
| SE(subject) | ElementNote | 0 | | AT(date) | StartTagNote | 1 | | AT(category) | StartTagNote | 2 | | EE | 3.0 | | AT(*) | StartTagNote | 3.1 | | SE(*) | ElementNote | 3.2 | | CH | ElementNote | 3.3 |
| 02
| SE | |
|
| StartTagNote3 |
|---|
| SE(subject) | ElementNote1 | 0 | | [Undeclared] | | 1 |
| 01
| SE | |
- StartTagNote3 moves on to ElementNote1 and
StartTagSubject1 is pushed on grammar-stack
|
<subject>
|
| StartTagSubject |
|---|
| CH | ElementSubject | 0 | | EE | 1.0 | | AT(*) | StartTagSubject | 1.1 | | SE(*) | ElementSubject | 1.2 | | CH | ElementSubject | 1.3 |
| 01
| CH | "Shopping List"+2
|
Decode content as value (String).
"Shopping List"+2 (literal string value) Add it to local value partition for qname subject. | Values (subject) |
|---|
| 0 | "Shopping List" |
Then,
|
| StartTagSubject1 |
|---|
| CH | ElementSubject1 | 0 | | [Undeclared] | 1 |
| 01 | CH | "Shopping List"+2
|
Decode content as value (String).
"Shopping List"+2 (literal string value) Add it to local value partition for qname subject. | Values (subject) |
|---|
| 0 | "Shopping List" |
Then,
|
Shopping List
|
| ElementSubject |
|---|
| EE | 0 | | SE(*) | ElementSubject | 1.0 | | CH | ElementSubject | 1.1 |
| 01
| EE | |
|
| ElementSubject1 |
|---|
| EE | 0 | | [Undeclared] | 1 |
| 01
| EE | |
|
</subject>
|
| ElementNote |
|---|
| SE(body) | ElementNote | 0 | | EE | 1 | | SE(*) | ElementNote | 2.0 | | CH | ElementNote | 2.1 |
| 02
| SE | |
- StartTagBody is pushed on grammar-stack
|
| ElementNote1 |
|---|
| SE(body) | ElementNote2 | 0 | | [Undeclared] | 1 |
| 01 | SE | |
|
<body>
|
| StartTagBody |
|---|
| CH | ElementBody | 0 | | EE | 1.0 | | AT(*) | StartTagBody | 1.1 | | SE(*) | ElementBody | 1.2 | | CH | ElementBody | 1.3 |
| 01
| CH | "milk, honey"+2
|
Decode content as value (String).
"milk, honey"+2 (literal string value) Add it to local value partition for qname body. | Values (body) |
|---|
| 0 | "Do not forget it!" | | 1 | "milk, honey" |
Then,
|
| StartTagBody1 |
|---|
| CH | ElementBody1 | 0 | | [Undeclared] | 1 |
| 01 | CH | "milk, honey"+2
|
Decode content as value (String).
"milk, honey"+2 (literal string value) Add it to local value partition for qname body. | Values (body) |
|---|
| 0 | "Do not forget it!" | | 1 | "milk, honey" |
Then,
|
milk, honey
|
| ElementBody |
|---|
| EE | 0 | | SE(*) | ElementBody | 1.0 | | CH | ElementBody | 1.1 |
| 01
| EE | |
|
| ElementBody1 |
|---|
| EE | 0 | | [Undeclared] | 1 |
| 01
| EE | |
|
</body>
|
| ElementNote |
|---|
| SE(body) | ElementNote | 0 | | EE | 1 | | SE(*) | ElementNote | 2.0 | | CH | ElementNote | 2.1 |
| 12
| EE | |
|
| ElementNote2 |
|---|
| EE | 0 | | [Undeclared] | 1 |
| 01
| EE | |
|
</note>
|
| ElementNotebook |
|---|
| SE(note) | ElementNote | 0 | | EE | 1 | | SE(*) | ElementNote | 2.0 | | CH | ElementNote | 2.1 |
| 12
| EE | |
- ElementNotebook popped from grammar-stack
|
| ElementNotebook1 |
|---|
| SE(note) | ElementNotebook1 | 0 | | EE | 1 | | [Undeclared] | 2 |
| 12 | EE | |
|
</notebook>
|
|
| 00
| ED | | |
|
| 00
| ED | | |
EOF
|