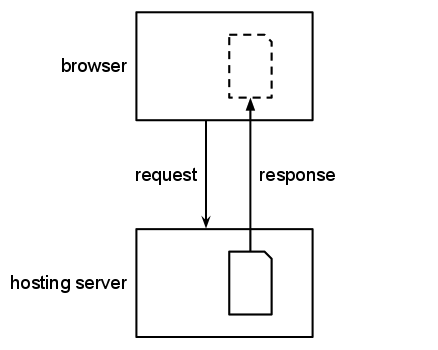
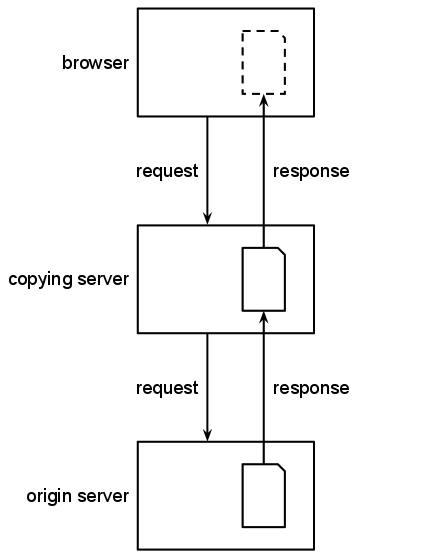
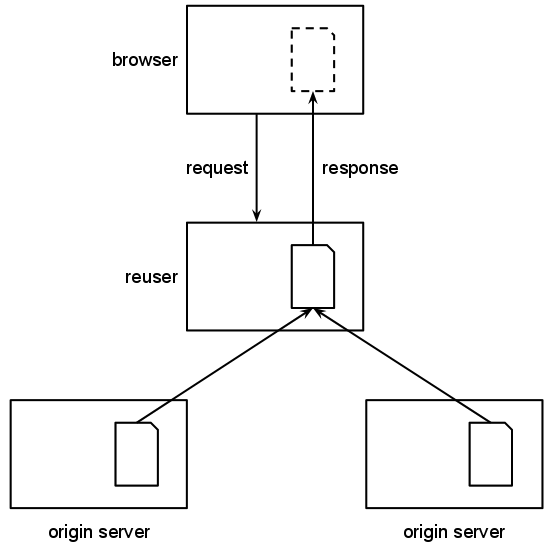
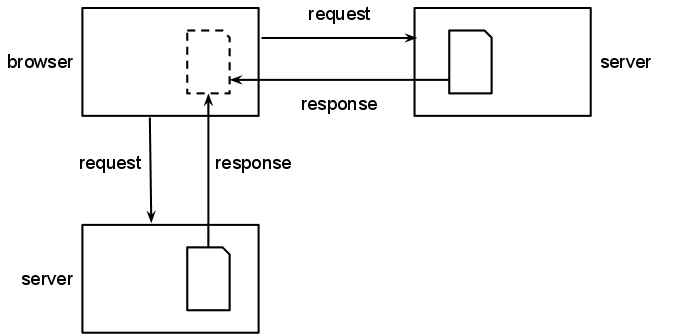
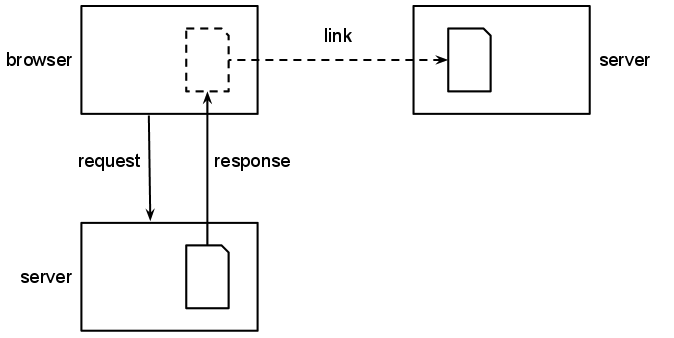
The act of viewing a web page is a complex interaction
between a user's browser and any number of web servers. Unlike
reading a book, viewing a web page involves copying the data
held on the servers onto the user's computer, if only
temporarily. Logic encoded within the page may cause more
copying to take place,
perhaps from other servers. The combined material may be displayed or otherwise
used within the original page often without the user's
explicit knowledge or consent. For an end user, it is usually
impossible to tell whether a given image or video displayed
within a page originates from the server the page comes from
or from some other location.
In addition to browsers and webservers, many other kinds of servers live on the Web.
Proxy servers and services that combine and repackage data
from other sources may also retain copies of this
material. These intermediary services may transform, translate
or rewrite some of the material that passes through them, to
enhance the user's experience of the web page or for their own
purposes.
Still other services on the web, such as search engines and
archives, make copies of content as a matter of course. This
is, in part, to facilitate the indexing necessary for their
operation, and in part to
provide value to their users and to the original
authors of the web page. These intermediaries, we argue, should be treated
differently by the law based on how much control they have over the underlying material
and how they process it.
Examples of the kind of legal questions that have arisen related to material that originates on other sites include:
2.1 Background
Many content publishers seek to
control the use of their content on the Web. In some cases,
they employ means that do not take into account the
Web's true architecture, and do not use the technical
mechanisms available to them. A few illustrative examples are
provided below.
Licenses that describe how material may be copied and
altered by others tend not to distinguish between a proxy
compressing a web page to make it load faster and someone
editing and republishing the page on their own website. To
illustrate,
the
Creative Commons Attribution-NoDerivs defines the terms
(emphasis added):
- Adaptation
- means a work based upon the Work,
or upon the Work and other pre-existing works, such as
a translation, adaptation, derivative work,
arrangement of music or other alterations of a literary or
artistic work, or phonogram or performance and includes
cinematographic adaptations or any other form in which the
Work may be recast, transformed, or adapted including in any
form recognizably derived from the original, except that a
work that constitutes a Collection will not be considered an
Adaptation for the purpose of this License. For the avoidance
of doubt, where the Work is a musical work, performance or
phonogram, the synchronization of the Work in timed-relation
with a moving image ("synching") will be considered an
Adaptation for the purpose of this
License.
- Distribute
- means to make available to the
public the original and copies of the Work
through sale or other transfer of
ownership.
- Reproduce
- means to make copies of the
Work by any means including without limitation
by sound or visual recordings and the right of fixation
and reproducing fixations of the Work, including storage
of a protected performance or phonogram in digital form
or other electronic medium.
Consider, now, the following questions:
- Does using the automatic Google Translate service
(which can be invoked automatically within Chrome) count
as an "adaptation" of a Work, given that it's a
translation, or is it only non-automated translations
that would count?
- When a document is made available on a website, the
original owner still retains their copy, it is
not transferred, so does this count as
"distribution"?
- If someone accesses a document released under this
license on the web, it has to be copied onto their
machine in order to be displayed; does this mean anyone
accessing the document "reproduces" it?
Terms and Conditions statements on websites also list
acceptable and unacceptable behavior on a site, with any
browsing on the site implicitly indicating acceptance of the
terms. These generally do not take into account the
behavior of proxies. For instance, one standard set of
Terms and Conditions includes:
You may view, download for caching purposes
only, and print pages from the website for your
own personal use, subject to the restrictions set out
below and elsewhere in these terms of use.
You must not:
(a) republish material from this website (including republication on another website);
(b) sell, rent or sub-license material from the website;
(c) show any material from the website in public;
(d) reproduce, duplicate, copy or otherwise exploit material on our website for a commercial purpose;
(e) edit or otherwise modify any material on the website; or
(f) redistribute material from this website except for content specifically and expressly made available for redistribution (such as our newsletter)
It is not possible to view material on the web without it
being downloaded onto your computer, so forbidding
downloading except for caching purposes essentially means
that people cannot view the page. In addition, many proxies
automatically transform the documents that pass through
them, for example to compress them so that they take up less
bandwidth for mobile consumption or to introduce
advertisments into pages that are accessed free of charge.
Should this be prohibited?
Limits placed on the use of a website often include
limitations on automatic indexing of the website, without
exceptions for search engines that make the website
discoverable or archives that ensure its longevity. For
example, the set of terms and conditions quoted
above goes on to say:
You must not conduct any systematic or automated data
collection activities (including without limitation
scraping, data mining, data extraction and data
harvesting) on or in relation to our website without our
express written consent.
Search engines rely on systematic data collection from
websites in order to provide users with accurate search
results, and archives do so in order to retain websites for
posterity. So, these terms and conditions, if adhered to
strictly, put the website out of the reach of search engines
and hence makes it undiscoverable; surely this is not in the
best interest of the website. Another problem is that
automated agents (webcrawlers, spiders, robots) that
gather information from the web are unable to read these
terms and conditions; the only things they understand are
the technical signals that a website provides about what is
permitted. See more on this below.
As another example, the terms and conditions
for gsig.com include:
Use of Materials: Upon your agreement to the Terms, GSI
grants you the right to view the site and to download
materials from this site for your personal, non-commercial
use. You are not authorized to use the materials for any
other purpose. If you do download or otherwise reproduce
the materials from this Site, you must reproduce all of
GSI?s proprietary markings, such as copyright and trademark
notices, in the same form and manner as the original.
...
You may not use any "deep-link", "page-scrape"?, "robot",
"spider" or any other automatic device, program, algorithm
or methodology or any similar or equivalent manual process
to access, acquire, copy or monitor any portion of the Site
or any of its content, or in any way reproduce or circumvent
the navigational structure or presentation of the Site.
It would be simpler and more effective for the site to use technical means
for controlling what webcrawlers, spiders or robots
access on the site, namely a robots.txt file
which is a set of machine processable instructions
instructing automated web agents what thay can and cannot
do. They could also exempt automated web agents from the
Terms and Conditions as discussed below.
Many sites have a linking policy that limits what links can
be made to the site from other sites. These conditions are
not backed up through relatively simple technical mechanisms
that would prevent such links from being made. For example,
the website
at quotec.co.uk has a
linking policy that includes:
Links pointing to this website should not be misleading.
Appropriate link text should be always be used.
From time to time we may update the URL structure of our
website, and unless we agree in writing otherwise, all links
should point to http://www.quotec.co.uk.
You must not use our logo to link to this website (or
otherwise) without our express written permission.
You must not link to this website using any inline linking technique.
You must not frame the content of this website or use any
similar technology in relation to the content of this
website.
Technically it is straightforward to prevent linking to pages that the website
does not want others to link to: you simply do not give these pages URLs or make the
URLs undiscoverable. This is likely to be more
effective than asking people to read and adhere to the Terms and Conditions.
Several techniques for controlling linking and inclusion are discussed in
section 6. Techniques.
Legislation that governs the possession and distribution of
unlawful material (such as child pornography, information
that is under copyright or material that is legally
suppressed through
a gag
order) needs to exempt certain types of services,
such as caching or hosting, as it would be impractical for
such services to police all the material
that passes through their servers. This does not, however, always
happen and intermediaries are often held accountable for material that
did not originate with them and have no control over.
An example of good legislation
that does exempt intermediaries the UK is
the Coroners
and Justice Act 2009 Schedule 13; from the Explanatory
Notes (emphasis added):
Paragraphs 3 to 5 of [Schedule 13] provide exemptions for
internet service providers from the offence of possession of
prohibited images of children in limited circumstances, such
as where they are acting as mere conduits for such
material or are storing it as caches or hosts.