Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
PROV Family of Specifications
This document is part of the PROV family of specifications, a set of specifications defining various aspects that are necessary to achieve the vision of inter-operable
interchange of provenance information in heterogeneous environments such as the Web. The specifications are:
- PROV-DM, the PROV data model for provenance;
- PROV-CONSTRAINTS, a set of constraints applying to the PROV data model (this document);
- PROV-N, a notation for provenance aimed at human consumption;
- PROV-O, the PROV ontology, an OWL-RL ontology allowing the mapping of PROV to RDF;
- PROV-AQ, the mechanisms for accessing and querying provenance;
- PROV-PRIMER, a primer for the PROV data model;
- PROV-SEM, a formal semantics for the PROV data model;
- PROV-XML, an XML schema for the PROV data model.
How to read the PROV Family of Specifications
- The primer is the entry point to PROV offering an introduction to the provenance model.
- The Linked Data and Semantic Web community should focus on PROV-O defining PROV classes and properties specified in an OWL-RL ontology. For further details, PROV-DM and PROV-CONSTRAINTS specify the constraints applicable to the data model, and its interpretation. PROV-SEM provides a mathematical semantics.
- The XML community should focus on PROV-XML defining an XML schema for PROV-DM. Further details can also be found in PROV-DM, PROV-CONSTRAINTS, and PROV-SEM.
- Developers seeking to retrieve or publish provenance should focus on PROV-AQ.
- Readers seeking to implement other PROV serializations
should focus on PROV-DM and PROV-CONSTRAINTS. PROV-O, PROV-N, PROV-XML offer examples of mapping to RDF, text, and XML, respectively.
First Public Working Draft
This is the first public release of the PROV-CONSTRAINTS
document. Following feedback, the Working Group has decided to
reorganize the PROV-DM document substantially, separating the data model,
from its constraints, and the notation used to illustrate it. The
PROV-CONSTRAINTS release is synchronized with the release of the PROV-DM, PROV-O,
PROV-PRIMER, and PROV-N documents.
This document was published by the Provenance Working Group as a First Public Working Draft. This document is intended to become a W3C Recommendation. If you wish to make comments regarding this document, please send them to public-prov-wg@w3.org (subscribe, archives). All feedback is welcome.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. W3C maintains a public list of any patent disclosures made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) must disclose the information in accordance with section 6 of the W3C Patent Policy.
1. Introduction
Provenance is a record that describes the people, institutions,
entities, and activities, involved in producing, influencing, or
delivering a piece of data or a thing. This document complements
the PROV-DM specification [PROV-DM] that defines a data model for
provenance on the Web.
1.1 Conventions
The key words "must", "must not", "required", "shall", "shall
not", "should", "should not", "recommended", "may", and
"optional" in this document are to be interpreted as described in
[RFC2119].
1.2 Purpose of this document
PROV-DM is a conceptual data model for provenance (realizable
using different serializations such as PROV-N, PROV-O, or PROV-XML).
However, nothing in the PROV-DM specification [PROV-DM] forces sets
of PROV
statements (or instances) to be meaningful, that is, to correspond to a consistent
history of objects and interactions. Furthermore, nothing in the
PROV-DM specification enables applications to perform inferences over
PROV instances.
This document specifies inferences over PROV instances that
applications may employ, including definitions of some provenance
statements in terms of others, and also defines a class of valid
PROV instances by specifying constraints that valid PROV instances must
satisfy. Applications should produce valid provenance and
may reject provenance that is not valid in order to increase
the usefulness of provenance and reliability of applications that
process it. section 2. Compliance with this document
summarizes the requirements for compliance with this document, which
are specified in detail in the rest of the document.
This specification lists inferences and definitions together in one
section (section 3. Inferences and Definitions), defines the
induced notion of equivalence (section 4. Equivalence), and then
considers two kinds of validity constraints (section 5. Validity Constraints): structural constraints that
prescribe properties of PROV instances that can be checked directly
by inspecting the syntax, and event ordering constraints that
require that the records in a PROV instance are consistent with a
sensible ordering of events relating the activities, entities and
agents involved. In separate sections we consider additional
constraints specific to collections and accounts (section 6. Collection Constraints and section 7. Account Constraints).
Finally, the specification includes a section (section 8. Rationale for inferences and constraints) describing the rationale
for the inferences and constraints in greater detail, particularly
background on events, attributes, the role of inference, and
accounts. A formal mathematical model that further justifies the
constraints and inferences is found in [PROV-SEM].
1.3 Audience
The audience for this document is the same as for [PROV-DM]: developers
and users who wish to create, process, share or integrate provenance
records on the (Semantic) Web. Not all PROV-compliant applications
need to check validity when processing provenance, but many
applications could benefit from the inference rules specified here.
Conversely, applications that create or transform provenance should
try to produce valid provenance, to make it more useful to other
applications.
This document assumes familiarity with [PROV-DM].
3. Inferences and Definitions
In this section, we describe inferences and definitions that may be used on
provenance data, and a notion of equivalence on PROV instances.
An inference is a rule that can be applied
to PROV instances to add new PROV statements. A definition is a rule that states that a
provenance expression is equivalent to some other expressions; thus,
defined provenance expressions can be replaced by their definitions,
and vice versa.
Inferences have the following general form:
IF hyp_1 and ... and
hyp_k THEN
there exists a_1 and ... and a_m such that conclusion_1 and ... and conclusion_n.
This means that if all of the provenance expressions matching hyp_1... hyp_k
can be found in a PROV instance, we can add all of the expressions
concl_1 ... concl_n to the instance, possibly after generating fresh
identifiers a_1,...,a_m for unknown objects. These fresh
identifiers might later be found to be equal to known identifiers;
these fresh identifiers play a similar role in PROV constraints to existential variables in logic.
TODO: Is this re-inventing blank nodes in PROV-DM, and do we want to
do this? A lot of the inferences have existentially quantified
conclusions (and there is some theory that supports this).
TODO: Make sure conjunctive reading of conclusion is clear.
Definitions have the following general form:
defined_exp holds IF AND ONLY IF
there exists a_1,..., a_m such that defining_exp_1 and ... and defining_exp_n.
This means that a provenance expression defined_exp is defined in
terms of other expressions. This can be viewed as a two-way
inference: If defined_exp
can be found in a PROV instance, we can add all of the expressions
defining_exp_1 ... defining_exp_n to the instance, possibly after generating fresh
identifiers a_1,...,a_m for unknown objects. Conversely, if there
exist identifiers a_1...a_m such that defining_exp_1
and ... and defining_exp_n hold in the instance, we can add the defined
expression def_exp. When an expression is defined in terms of
others, it is in a sense redundant; it is safe to replace it with
its definition.
3.1 Component 1: Entities and Activities
Communication between activities is defined in terms
as the existence of an underlying entity generated by one activity and used by the
other.
Given two activities identified by a1 and a2,
wasInformedBy(a2,a1)
holds IF AND ONLY IF
there is an entity with some identifier e and some sets of attribute-value pairs attrs1 and attrs2,
such that wasGeneratedBy(-,e,a1,-,attrs1) and used(-,a2,e,-,attrs2) hold.
The relationship wasInformedBy is not
transitive. Indeed, consider the following statements.
wasInformedBy(a2,a1)
wasInformedBy(a3,a2)
We cannot infer wasInformedBy(a3,a1) from these expressions. Indeed,
from
wasInformedBy(a2,a1), we know that there exists e1 such that e1 was generated by a1
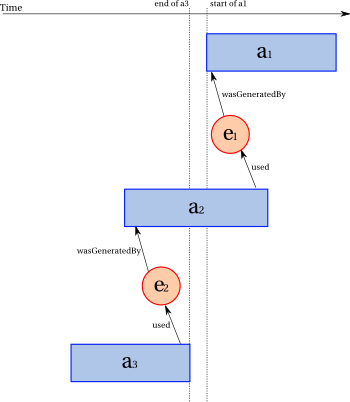
and used by a2. Likewise, from wasInformedBy(a3,a2), we know that there exists e2 such that e2 was generated by a2 and used by a3. The following illustration shows a case for which transitivity cannot hold. The
horizontal axis represents the event line. We see that e1 was generated after e2 was used. Furthermore, the illustration also shows that
a3 completes before a1. So it is impossible for a3 to have used an entity generated by a1.
Start of a2 by activity a1 is defined as follows.
Given two activities with identifiers a1 and a2,
wasStartedByActivity(a2,a1)
holds IF AND ONLY IF
there exists an entity e
such that
wasGeneratedBy(-,e,a1,-,-)
and wasStartedBy(-,a2,e,-,-) hold.
3.2 Component 2: Agents
Attribution identifies an agent as responsible for an entity. An
agent can only be responsible for an entity if it was associated with
an activity that generated the entity. If the activity, generation
and association events are not explicit in the instance, they can
be inferred.
IF
wasAttributedTo(e,ag) holds for some identifiers
e and
ag,
THEN there exists an activity with some identifier
a such that the following statements hold:
activity(a, -, -,-)
wasGeneratedBy(-,e, a, -,_)
wasAssociatedWith(-,a, ag, -, -)
Responsibility relates agents where one agent acts on behalf of
another, in the context of some activity. The supervising agent
delegates some responsibility for part of the activity to the
subordinate agent, while retaining some responsibility for the overall
activity.
@@TODO: Could this be an inference? Does it imply that
a1 is associated with all activities a2 is associated with?
3.3 Component 3: Derivations
Derivations with an explicit activity and no usage admit the
following inference:
Given an activity a, entities denoted by e1 and e2,
IF wasDerivedFrom(-,e2,e1, a, -) and wasGeneratedBy(-,e2,a,-,-) hold, THEN used(-,a,e1,-,-) also holds.
This inference is justified by the fact that the entity denoted by e2 is generated by at most one activity in a given account
(see generation-uniqueness). Hence, this activity is also the one referred to by the usage of e1.
There is some redundancy in the following discussion.
The converse inference does not hold.
From wasDerivedFrom(e2,e1) and used(a,e1,-), one cannot
derive wasGeneratedBy(e2,a,-) because identifier e1 may occur in usages performed by many activities, which may have not generated the entity denoted by e2.
Note that derivation cannot in general be inferred from the existence
of related usage and generation events. Indeed, when a generation wasGeneratedBy(g, e2, a, -, attrs2)
precedes used(u, a, e1, -, attrs1), for
some e1, e2, attrs1, attrs2, and a, one
cannot infer derivation wasDerivedFrom(e2, e1, a, g, u)
or wasDerivedFrom(e2,e1) since
e2 cannot possibly be derived from
e1, given the creation of e2 precedes the use
of e1. That is, if e1 is generated
by an activity before e2 is used, then
obviously e2 cannot have been derived from
e1. However, even if e2 happens used before e1
is generated, it is not safe to assume that e2 was derived from e1.
Derivation is not defined to be transitive. Domain-specific specializations of derivation may be defined in such a way that the transitivity property
holds.
A revision admits the following inference, linking the two entities
by a derivation, and stating them to be alternates.
Given two identifiers
e1 and
e2 identifying two entities, and an identifier
ag identifying an agent,
IF wasRevisionOf(-,e2,e1,ag) holds,
THEN the following
hold:
wasDerivedFrom(-,e2,e1,-)
alternateOf(e1,e2)
wasAttributedTo(e2,ag)
The following doesn't make sense because wasRevisionOf and
wasDerivedFrom have different types.
wasRevisionOf is a strict sub-relation
of wasDerivedFrom since two entities e2 and e1
may satisfy wasDerivedFrom(e2,e1) without being a variant of
each other.
Motivation for quotation inference
IF
wasQuotedFrom(e2,e1,ag2,ag1,attrs) holds for some identifiers
e2,
e1,
ag2,
ag1,
THEN the following hold:
wasDerivedFrom(e2,e1)
wasAttributedTo(e2,ag2)
wasAttributedTo(e1,ag1)
Traceability allows an entity to be transitively linked to another entity it is derived from, to an agent it is attributed to, or another agent having some responsibility, or a trigger of an activity that generated it.
Traceability can be inferred from existing statements, or can be asserted stating that a dependency path exists without its individual steps being expressed. This is captured
by the following inferences:
Given two identifiers
e2 and
e1 for entities,
the following statements hold:
- IF wasDerivedFrom(e2,e1,a,g2,u1) holds, for some a, g2, u1, THEN tracedTo(e2,e1) also holds.
- IF wasDerivedFrom(e2,e1) holds, THEN tracedTo(e2,e1) also
holds.
- IF wasAttributedTo(e2,ag1,aAttr) holds, THEN tracedTo(e2,ag1) also holds.
-
IF wasAttributedTo(e2,ag2,aAttr), wasGeneratedBy(-,e2,a,-,gAttr), and actedOnBehalfOf(ag2,ag1,a,rAttr) hold, for some a, ag2, ag1, aAttr, gAttr, and rAttr, THEN tracedTo(e2,ag1) also holds.
- IF wasGeneratedBy(e2,a,gAttr) and wasStartedBy(a,e1,sAttr) hold, for some a, gAttr , sAttr then tracedTo(e2,e1) holds.
- IF tracedTo(e2,e) and tracedTo(e,e1) hold for some e, THEN tracedTo(e2,e1) also holds.
We note that the inference rule traceability-inference does not
allow us to infer anything about the attributes of the related
entities, agents or events.
3.4 Component 4: Alternate Entities
TODO: There is currently no consensus what inferences on
alternate or specialization should be assumed. The following
section lists possible inferences that may or may not be adopted. Section is under review, pending ISSUE-29.
The relation alternateOf is an equivalence relation: reflexive,
transitive and symmetric.
For any entity e, we have alternateOf(e,e).
For any entities e1, e2, e3, IF alternateOf(e1,e2) and
alternateOf(e2,e3) THEN alternateOf(e1,e3).
For any entity e1, e2, IF alternateOf(e1,e2) THEN alternateOf(e2,e1).
Similarly, specialization is a strict partial order: it is irreflexive,
anti-symmetric and
transitive.
For any entity e, it is not the case that
have specializationOf(e,e).
For any
entities e1, e2,
it is not the case that
specializationOf(e1,e2)
and
specializationOf(e2,e1).
For any
entities e1, e2, e3, IF specializationOf(e1,e2)
and
specializationOf(e2,e3) THEN specializationOf(e1,e3).
Finally, if one entity specializes another, then they are also
alternates:
For any entities e1, e2, IF specializationOf(e1,e2) THEN alternateOf(e1,e2).
TODO: Possible inferences about attributes,
generation, invalidation?
The following sections are retained from an older version, and are
not consistent with the above constraints. This will be revised
once the consensus on ISSUE-29 is clearer.
3.4.1 Specialization
Specialization is neither symmetric nor anti-symmetric.
"Alice's toyota car on fifth Avenue" is a specialization of "Alice's toyota car", but the converse does not hold.
anti-symmetric counter-example???
Specialization is transitive. Indeed if specializationOf(e1,e2) holds, then there is some
common thing, say T1-2 they both refer to,
and e1 is a more specific aspect of this
thing than e2. Likewise, if specializationOf(e2,e3) holds, then there is some
common thing, say T2-3 they both refer to, and e2 is a more specific aspect of this
thing than e3. The things T1-2 and T2-3 are the
same since e2 is an aspect of both of them,
so specializationOf(e1,e3) follows since e1 and e3
are aspects fo the same thing and e1 is more specific than e3.
A specialization of "this email message" would be, for example, the "printed version on my desk", which is a specialization of "my thoughts on this email thread". So, the "printed version on my desk" is also a specialization "my thoughts on this email thread".
3.4.2 Alternate
Alternate not is reflexive. Indeed, alternate(e,e) does not hold for any arbitrary entity e since e may not be a specialization of another entity.
Alternate is symmetric. Indeed, if alternate(e1,e2) holds,
then there exists an unspecified entity e, such that
both e1 and e2 are specialization of e.
Therefore, alternate(e2,e1) also holds.
Alternate is not transitive. Indeed, if alternate(e1,e2) holds,
then there exists an unspecified entity e1-2, such that
both e1 and e2 are specialization of e1-2.
Likewise, if alternate(e2,e3) holds,
then there exists an unspecified entity e2-3, such that
both e2 and e3 are specialization of e2-3.
It does not imply that there is a common entity e1-3
that both e1 and e3 specialize.
At 6pm, the customer in a chair is a woman in a red dress, who happens to be Alice. After she leaves, another customer arrives at 7pm, a man with glasses, who happens to be Bob. Transitivity does not hold since the womanInRedDress\ is not alternate of customerInChairAt7pm.
alternate(womanInRedDress,customerInChairAt6pm)
specialization(customerInChairAt6pm,Alice)
specialization(womanInRedDress,Alice)
alternate(manWithGlasses,customerInChairAt7pm)
specialization(customerInChairAt7pm,Bob)
specialization(manWithGlasses,Bob)
alternate(customerInChairAt6pm, customerInChairAt7pm)
specialization(customerInChairAt6pm, customerInChair)
specialization(customerInChairAt7pm, customerInChair)
The above example shows that customerInChairAt6pm and customerInChairAt7pm are two alternate entities that have no overlap, while womanInRedDress and customerInChairAt6pm do overlap.
The following example illustrates another case of non-overlapping alternate entities.
Two copies of the same book, where copy A was destroyed before copy B was made.
5. Validity Constraints
This section defines a collection of constraints on PROV instances. A PROV instance is valid
if, after applying all possible inference and definition rules from
Section 2, the resulting instance
satisfies all of the constraints specified in this section.
There are two kinds of constraints:
- uniqueness constraints that say that a PROV
instance can contain at most one expression or that multiple
expressions about the same objects need to have the same values (for
example, if we describe the same generation event twice, then the
two expressions should have the same times);
- and event ordering constraints that say that it
should be possible to arrange the
events (generation, usage, invalidation, start, end) described in a
PROV instance into a partial order that corresponds to a sensible
"history" (for example, an entity should not be generated after it
is used).
The PROV data model is implicitly based on a notion of instantaneous events (or just events), that mark
transitions in the world. Events include generation, usage, or
invalidation of entities, as well as starting or ending of activities. This
notion of event is not first-class in the data model, but it is useful
for explaining its other concepts and its semantics [PROV-SEM].
Thus, events help justify inferences on provenance as well as
validity constraints indicating when provenance is self-consistent. In section 8.4 Events and Time we
discuss the motivation for instantaneous events
and their relationship to time in greater detail.
PROV-DM
identifies five kinds of instantaneous events, namely entity generation
event, entity usage event, entity invalidation event, activity start event
and activity end event. PROV-DM adopts Lamport's clock
assumptions [CLOCK] in the form of a reflexive, transitive partial order follows
(and its inverse precedes) between instantaneous events. Furthermore,
PROV-DM assumes the existence of a mapping from instantaneous events to time clocks,
though the actual mapping is not in scope of this specification.
TODO: More about what it means for constraints to be satisfied;
constraint template(s)
5.1 Uniqueness Constraints
Attribute uniqueness constraints?
We assume that the various identified objects of PROV-DM have
unique statements describing them within a PROV instance.
Given an entity identifier e, there is at
most one expression
entity(e,attrs), where attrs is some set of attribute-values.
Given an activity identifier a, there is
at most one expression
activity(a,t1,t2,attrs), where attrs is some set of attribute-values.
TODO: Same goes for all other objects:
agent, note, generation, usage, invalidation, start, end,
communication, start by, attribution, association, responsibility,
derivation, revision, quotation. We should find a
way of saying this once concisely.
We assume that an entity has exactly one generation and
invalidation event (either or both may, however, be left implicit).
So, PROV-DM allows for two distinct generations g1 and g2 referencing the same entity provided they occur
simultaneously.
This implies that the two generation events are actually the same and
caused by the same activity, though provenance may contain
several statements for the same world activity.
Given an entity denoted by e, two activities denoted by a1 and a2, two time instants t1 and t2, and two sets of attribute-value pairs attrs1 and attrs2,
IF wasGeneratedBy(id1, e, a1, t1, attrs1) and wasGeneratedBy(id2, e, a2, t2, attrs2) exist,
THEN id1=id2, a1=a2, t1=t2 and attrs1=attrs2.
Wouldn't the above constraint violate uniqueness?
Invalidation uniqueness?
A generation can be used to indicate a generation time without having to specify the involved activity. A generation time is unique, as specified by the following constraint.
Seems redundant given generation-uniqueness
Given an entity denoted by e and
two time instants t1 and t2,
IF wasGeneratedBy(e, -, t1) and wasGeneratedBy(e, -, t2) hold, THEN t1=t2.
An activity start event is the instantaneous event that marks the instant an activity starts. It allows for an optional time attribute. Activities also allow for an optional start time attribute. If both are specified, they must be the same, as expressed by the following constraint.
IF activity(a,t1,t2,-) and wasStartedBy(id,a,e,t,-), THEN t=t1.
An activity end event is the instantaneous event that marks the instant an activity ends. It allows for an optional time attribute. Activities also allow for an optional end time attribute. If both are specified, they must be the same, as expressed by the following constraint.
IF activity(a,t1,t2,-) and wasEndedBy(id,a,e,t,-), THEN t = t2.
5.2 Event Ordering Constraints
Given that provenance consists of a description of past entities
and activities, valid provenance instances must
satisfy ordering constraints between instantaneous events, which we introduce in
this section. For instance, an entity can only be used after it was
generated; hence, we say that an entity's generation event precedes any of this
entity's usage events. Should this
ordering constraint be violated, the associated generation and
usage could not be credible. The rest of this section defines
the temporal interpretation of provenance instances as a
set of instantaneous event ordering constraints.
To allow for minimalistic clock assumptions, like Lamport
[CLOCK], PROV-DM relies on a notion of relative ordering of instantaneous events,
without using physical clocks. This specification assumes that a partial order exists between instantaneous events.
Specifically, precedes is a partial
order between instantaneous events. When we say
e1 precedes e2,
this means that either the two events are equal or e1 happened before e2.
For symmetry, follows is defined as the
inverse of precedes; that is, when we say
e1 follows e2,
this means that either the two events are equal or e1 happened after e2. Both relations are partial orders, meaning
that they are reflexive, transitive, and antisymmetric.
Do we want to allow an event to
"precede" itself? Perhaps precedes should be strict.
The following discussion is unclear: what is being said here, and why?
PROV-DM also allows for time observations to be inserted in
specific provenance statements, for each of the five kinds
of instantaneous events introduced in this specification. The
presence of a time observation for a given instantaneous event fixes the
mapping of this instantaneous event to the timeline. The presence of time
information in a provenance statement instantiates the ordering constraint with
that time information. It is expected that such instantiated
constraints can help corroborate provenance information. We anticipate
that verification algorithms could be developed, though this
verification is outside the scope of this specification.
The following figure summarizes the ordering constraints in a
graphical manner. For each subfigure, an event time line points to the
right. Activities are represented by rectangles, whereas entities are
represented by circles. Usage, generation and derivation are
represented by the corresponding edges between entities and
activities. The five kinds of instantaneous events are represented by vertical
dotted lines (adjacent to the vertical sides of an activity's
rectangle, or intersecting usage and generation edges). The ordering
constraints are represented by triangles: an occurrence of a triangle between two instantaneous event vertical dotted lines represents that the event denoted by the left
line precedes the event denoted by the right line.
5.2.1 Activity constraints
In this section we discuss constraints from the perspective of
the lifetime of an activity. An activity starts, then during
its lifetime uses, generates entities and communicates with or starts
other
activities, and finally ends. The following constraints amount to
checking that all of the events associated with an activity take place
within the activity's lifetime, and the start and end events mark the
start and endpoints of its lifetime.
The existence of an activity implies that the activity start event always precedes the corresponding activity end
event. This is
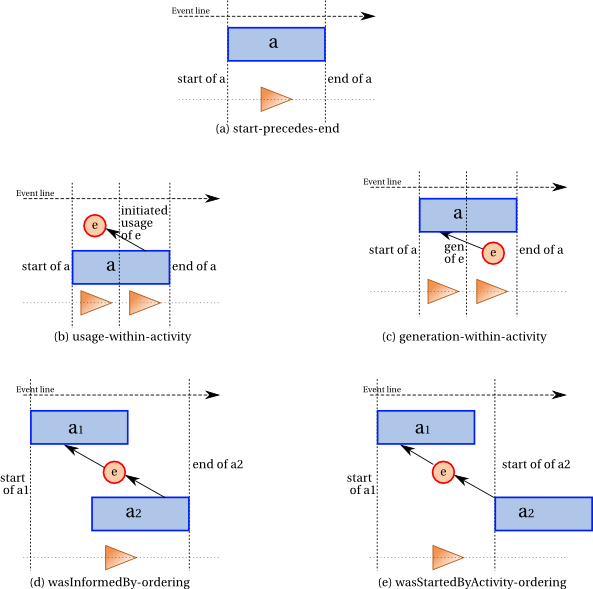
illustrated by Subfigure ordering-activity-fig (a) and expressed by constraint start-precedes-end.
IF
wasStartedBy(start,a,-,-)
and
wasEndedBy(end,a,-,-)
THEN
start
precedes
end.
A usage implies ordering of events, since the usage event had to occur during the associated activity. This is
illustrated by Subfigure ordering-activity-fig (b) and expressed by constraint usage-within-activity.
-
IF
used(use,a,e,-,-)
and
wasStartedBy(start,a,-,-)
THEN
start
precedes
use.
-
IF
used(use,a,e,-,-)
and
wasEndedBy(end,a,-,-)
THEN
use
precedes
end.
A generation implies ordering of events, since the generation event had to occur during the associated activity. This is
illustrated by Subfigure ordering-activity-fig (c) and expressed by constraint generation-within-activity.
-
IF
wasGeneratedBy(gen,a,e,-,-)
and
wasStartedBy(start,a,-,-)
THEN
start
precedes
gen.
-
IF
wasGeneratedBy(gen,a,e,-,-)
and
wasEndedBy(end,a,-,-)
THEN
gen
precedes
end.
Communication between two activities a1 and a2 also implies ordering of events, since some entity must have been generated by the former and used by the latter, which implies that the start event of a1
cannot follow the end event of a2. This is
illustrated by Subfigure ordering-activity-fig (d) and expressed by constraint wasInformedBy-ordering.
Start of a2 by activity a1 also implies ordering of events, since a1 must have been active before a2 started. This is
illustrated by Subfigure ordering-activity-fig (e) and expressed by constraint wasStartedByActivity-ordering.
IF
wasStartedByActivity(a2,a1)
and
wasStartedBy(start1,a1,-,-)
and
wasStartedBy(start2,a2,-,-)
THEN
start1
precedes
start2.
5.2.2 Entity constraints
As with activities, entities have lifetimes: they are generated, then
can be used, revised, or other entities can be derived from them, and
finally are invalidated.
Generation of an entity precedes its invalidation. (This
follows from other constraints if the entity is used, but we state it
explicitly to cover the case of an entity that is generated and
invalidated without being used.)
IF
wasGeneratedBy(gen,e,_,_)
and
wasInvalidatedBy(inv,e,-,-)
THEN
gen
precedes
inv.
A usage and a generation for a given entity implies ordering of events, since the generation event had to precede the usage event. This is
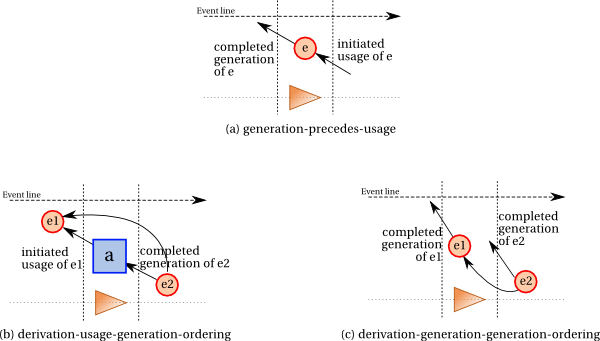
illustrated by Subfigure ordering-entity-fig (a) and expressed by constraint generation-precedes-usage.
IF
wasGeneratedBy(gen,e,_,_)
and
used(use,_,e,-)
THEN
gen
precedes
use.
All usages of an entity precede its invalidation, which is captured by constraint usage-precedes-invalidation (without any explicit graphical representation).
IF
used(use,_,e,-)
and
wasInvalidatedBy(inv,e,_,_)
THEN
use
precedes
inv.
If there is a derivation between e2 and e1, then
this means that the entity e1 had some form of influence on the entity e2; for this to be possible, some event ordering must be satisfied.
First, we consider derivations, where the activity and usage are known. In that case, the usage of e1 has to precede the generation of e2.
This is
illustrated by Subfigure ordering-entity-fig (b) and expressed by constraint derivation-usage-generation-ordering.
IF
wasDerivedFrom(d,e2,e1,a,g2,u1,-)
THEN
u1
precedes
g2.
When the usage is unknown, a similar constraint exists, except that the constraint refers to its
generation event, as
illustrated by Subfigure ordering-entity-fig (c) and expressed by constraint derivation-generation-generation-ordering.
IF
wasDerivedFrom(e2,e1,attrs)
and
wasGeneratedBy(gen1,e1,_,_)
and
wasGeneratedBy(gen2,e2,_,_)
THEN
gen1
precedes
gen2.
Note that event ordering is between generations of e1
and e2, as opposed to derivation where usage is known,
which implies ordering ordering between the usage of e1 and
generation of e2.
The entity that triggered the start of an activity must exist before the activity starts.
This is
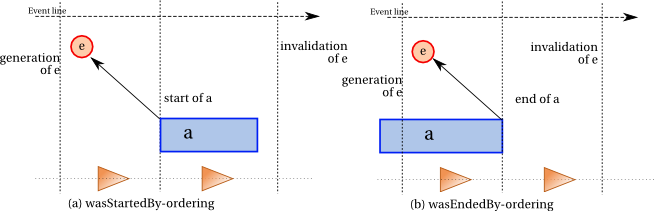
illustrated by Subfigure ordering-entity-trigger-fig (a) and expressed by constraint wasStartedBy-ordering.
-
IF
wasStartedBy(start,a,e,-)
and
wasGeneratedBy(gen,e,-,-)
THEN
gen
precedes
start.
-
IF
wasStartedBy(start,a,e,-)
and
wasInvalidatedBy(inv,e,-,-)
THEN
start
precedes
inv.
Similarly, the entity that triggered the end of an activity must exist before the activity ends, as illustrated by Subfigure ordering-entity-trigger-fig (b).
-
IF
wasEndedBy(end,a,e,-)
and
wasGeneratedBy(gen,e,-,-)
THEN
gen
precedes
end.
-
IF
wasEndedBy(end,a,e,-)
and
wasInvalidatedBy(inv,e,-,-)
THEN
end
precedes
inv.
5.2.3 Agent constraints
Like entities and activities, agents have lifetimes that follow a
familiar pattern: an agent is generated, can participate in
interactions such as starting, ending or association with an
activity, attribution, or delegation, and finally the agent is invalidated.
Further constraints associated with agents appear in Figure ordering-agents and are discussed below.
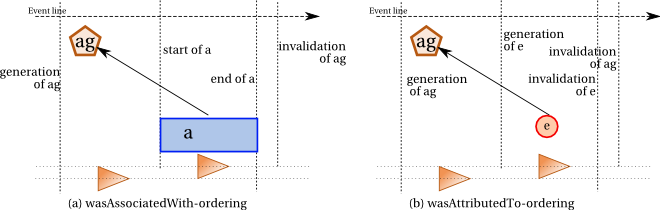
An activity that was associated with an agent must have some overlap with the agent. The agent may be generated, or may only become associated with the activity, after the activity start: so, the agent is required to exist before the activity end. Likewise, the agent may be destructed, or may terminate its association with the activity, before the activity end: hence, the agent invalidation is required to happen after the activity start.
This is
illustrated by Subfigure ordering-agents (a) and expressed by constraint wasAssociatedWith-ordering.
-
IF
wasAssociatedWith(a,ag)
and
wasStartedBy(start,a,-,-)
and
wasInvalidatedBy(inv,ag,-,-)
THEN
start
precedes
inv.
-
IF
wasAssociatedWith(a,ag)
and
wasGeneratedBy(gen,ag,-,-)
and
wasEndedBy(end,a,-,-)
THEN
gen
precedes
end.
An entity that was attributed to an agent must have some overlap
with the agent. The agent is required to exist before the entity
invalidation. Likewise, the entity generation must precede the agent destruction.
This is
illustrated by Subfigure ordering-agents (b) and expressed by constraint wasAttributedTo-ordering.
-
IF
wasAttributedTo(e,ag)
and
wasGeneratedBy(gen,e,-,-)
and
wasInvalidatedBy(inv,ag,-,-)
THEN
gen
precedes
inv.
-
IF
wasAttributedTo(e,ag)
and
wasGeneratedBy(gen,ag,-,-)
and
wasInvalidatedBy(inv,e,-,-)
THEN
gen
precedes
inv.
For responsibility, two agents need to have some overlap in their lifetime.
IF
actedOnBehalfOf(ag2,ag1)
and
wasGeneratedBy(gen,ag1,-,-)
and
wasInvalidatedBy(inv,ag2,-,-)
THEN
gen
precedes
inv.
6. Collection Constraints
Work on collections and on these constraints is deferred until after
the next working draft, so this section may not be stable.
Membership is a convenience notation, since it can be expressed in terms of an insertion into some collection. The membership definition is formalized by constraint membership-as-insertion.
memberOf(c, {(k1, v1), ...}) holds
IF AND ONLY IF there exists a collection c0, such that
derivedByInsertionFrom(c, c0, {(k1, v1), ...}).
A collection may be obtained by insertion or removal, or said to satisfy the membership relation.
To provide an interpretation of collections, PROV-DM
restricts one collection to be involved in a single derivation by insertion or removal, or to one membership relation.
PROV-DM does not provide an interpretation for statements that consist of two (or more) insertion, removal, membership relations that result in the same collection.
The following constraint ensures unique derivation.
The following constraint is unclear.
A collection must not be derived through multiple insertions, removal,
or membership relations.
Consider the following statements about three collections.
entity(c1, [prov:type="prov:Collection" %% xsd:QName])
entity(c2, [prov:type="prov:Collection" %% xsd:QName])
entity(c3, [prov:type="prov:Collection" %% xsd:QName])
derivedByInsertionFrom(c3, c1, {("k1", e1), ("k2", e2)})
derivedByInsertionFrom(c3, c2, {("k3", e3)})
There is no interpretation for such statements since c3 is derived multiple times by insertion.
As a particular case, collection c is derived multiple times from the same c1.
derivedByInsertionFrom(id1, c, c1, {("k1", e1), ("k2", e2)})
derivedByInsertionFrom(id2, c, c1, {("k3", e3), ("k4", e4)})
The interpretation of such statements is also unspecified.
To describe the insertion of the 4 key-entity pairs, one would instead write:
derivedByInsertionFrom(id1, c, c1, {("k1", e1), ("k2", e2), ("k3", e3), ("k4", e4)})
The same is true for any combination of insertions, removals, and membership relations:
The following statements
derivedByInsertionFrom(c, c1, {("k1", e1)})
derivedByRemovalFrom(c, c2, {"k2"})
have no interpretation.
Nor have the following:
derivedByInsertionFrom(c, c1, {("k1", e1)})
memberOf(c, {"k2"}).
6.1 Collection branching
It is allowed to have multiple derivations from a single root collection, as long as the resulting entities are distinct, as shown in the following example.
entity(c0, [prov:type="prov:EmptyCollection" %% xsd:QName]) // c0 is an empty collection
entity(c1, [prov:type="prov:Collection" %% xsd:QName])
entity(c2, [prov:type="prov:Collection" %% xsd:QName])
entity(c3, [prov:type="prov:Collection" %% xsd:QName])
entity(e1)
entity(e2)
entity(e3)
derivedByInsertionFrom(c1, c0, {("k1", e1)})
derivedByInsertionFrom(c2, c0, {("k2", e2)})
derivedByInsertionFrom(c3, c1, {("k3", e3)})
From this set of statements, we conclude:
c1 = { ("k1", e1) }
c2 = { ("k2", e2) }
c3 = { ("k1", e1), ("k3", e3)}
6.2 Collections and Weaker Derivation Relation
The state of a collection is only known to the extent that a chain
of derivations starting from an empty collection can be found. Since a
set of statements regarding a collection's evolution may be
incomplete, so is the reconstructed state obtained by querying those
statements. In general, all statements reflect partial knowledge regarding a sequence of data transformation events. In the particular case of collection evolution, in which some of the state changes may have been missed, the more generic derivation relation should be used to signal that some updates may have occurred, which cannot be expressed as insertions or removals. The following example illustrates this.
In the example, the state of
c2 is only partially known because the collection is constructed from partially known other collections.
entity(c0, [prov:type="prov:EmptyCollection" %% xsd:QName]) // c0 is an empty collection
entity(c1, [prov:type="prov:Collection" %% xsd:QName])
entity(c2, [prov:type="prov:Collection" %% xsd:QName])
entity(c3, [prov:type="prov:Collection" %% xsd:QName])
entity(e1)
entity(e2)
derivedByInsertionFrom(c1, c0, {("k1", e1)})
wasDerivedFrom(c2, c1)
derivedByInsertionFrom(c3, c2, {("k2", e2)})
From this set of statements, we conclude:
- c1 = { ("k1", e1) }
- c2 is somehow derived from c1, but the precise sequence of updates is unknown
- c3 includes ("k2", e2) but the earlier "gap" leaves uncertainty regarding ("k1", e1) (it may have been removed) or any other pair that may have been added as part of the derivation activities.
Do the insertion/removal derivation steps imply wasDerivedFrom,
wasVersionOf, alternateOf?
7. Account Constraints
Work on accounts has been deferred until after the next working draft,
so this section is very unstable
PROV-DM allows for multiple descriptions of entities (and in general any identifiable object) to be expressed.
Let us consider two statements about the same entity, which we have taken from two different contexts. A working draft published by the w3:Consortium:
entity(tr:WD-prov-dm-20111215, [ prov:type="pr:RecsWD" %% xsd:QName ])
The second version of a document edited by some authors:
entity(tr:WD-prov-dm-20111215, [ prov:type="document", ex:version="2" ])
Both statements are about the same entity identified by
tr:WD-prov-dm-20111215, but they contain different attributes, describing the situation or partial state of the these entities according to the context in which they occur.
Two different statements about the same entity cannot co-exist in PROV instance
as formalized in entity-unique.
In some cases, there may be a requirement for two different
statements concerning the same entity to be included in the same account. To satisfy the constraint entity-unique, we can adopt a different identifier for one of them, and relate the two statements with the alternateOf relation.
We now reconsider the same two statements of a same entity, but we change the identifier for one of them:
entity(tr:WD-prov-dm-20111215, [ prov:type="pr:RecsWD" %% xsd:QName ])
entity(ex:alternate-20111215, [ prov:type="document", ex:version="2" ])
alternateOf(tr:WD-prov-dm-20111215,ex:alternate-20111215)
Since we are not specifying ways to take the union of two accounts,
we may drop this discussion
Taking the union of two accounts is another account,
formed by the union of the statements they respectively contain. We note that the resulting union may or may not invalidate some constraints:
- Two entity statements with the same identifier but different sets of attributes exist in each PROV instance may invalidate entity-unique in the union, unless some form of statement merging or renaming (as per Example) occurs.
- Structurally well-formed
accounts are not
closed under union because the
constraint generation-uniqueness may no
longer be satisfied in the resulting union.
How to reconcile such accounts is beyond the scope of this specification.
Material transplanted from old structural well-formedness constraints section.
This example isn't very clear, since the sub-workflow-ness isn't
represented in the data. According to what was written above, we
should conclude that a0 and a2 are equal!
In the following statements, a workflow execution a0 consists of two sub-workflow executions a1 and a2.
Sub-workflow execution a2 generates entity e, so does a0.
activity(a0, [prov:type="workflow execution"])
activity(a1, [prov:type="workflow execution"])
activity(a2, [prov:type="workflow execution"])
wasInformedBy(a2,a1)
wasGeneratedBy(e,a0)
wasGeneratedBy(e,a2)
So, we have two different generations for entity e. Such an example is permitted in PROV-DM if the two activities denoted by a0 and a2 are a single thing happening in the world
but described from different perspectives.
While this example is permitted in PROV-DM, it does not make the inter-relation between activities explicit, and it mixes statements expressed from different perspectives together.
While this may acceptable in some specific applications, it becomes challenging for inter-operability. Indeed, PROV-DM does not offer any relation describing the structure of activities.
Such instances are said not to be structurally well-formed.
Structurally well-formed provenance can be obtained by partitioning the generations into different accounts. This makes it clear that these generations provide alternative
descriptions of the same real-world generation event, rather than describing two distinct generation events for the same entity. When accounts are used, the example can be encoded as follows.
The same example is now revisited, with the following statements that are structurally well-formed. Two accounts are introduced, and there is a single generation for entity e per account.
In a first account, entitled "summary", we find:
activity(a0,t1,t2,[prov:type="workflow execution"])
wasGeneratedBy(e,a0,-)
In a second account, entitled "detail", we find:
activity(a1,t1,t3,[prov:type="workflow execution"])
activity(a2,t3,t2,[prov:type="workflow execution"])
wasInformedBy(a2,a1)
wasGeneratedBy(e,a2,-)
Structurally well-formed provenance satisfies some constraints, which force the structure of statements to be exposed by means of accounts. With these constraints satisfied, further
inferences can be made about structurally well-formed statements.
The uniqueness of generations in accounts is formulated as follows.
8. Rationale for inferences and constraints
This section is non-normative.
This section collects all of the explanatory
material that I was not certain how to interpret as an unambiguous
inference or constraint. Some of these observations may need to be folded
into the explanatory text in respective sections (for example for
events,
accounts or collections).
Editing is also needed to decrease redundancy.
8.1 Entities and Attributes
When we talk about things in the world in natural language and even when we assign identifiers, we are often imprecise in ways that make it difficult to clearly and unambiguously report
provenance: a resource with a URL may be understood as referring to a report available at that URL, the version of the report available there today, the report independent of where it is
hosted over time, etc.
However, to write precise descriptions of the provenance of things
that change over time, we need ways of disambiguating which versions
of things we are talking about.
To describe the provenance of things that can change over
time, PROV-DM uses the concept of entities with fixed
attributes. From a provenance viewpoint, it is important to identify
a partial state of something, i.e. something with some aspects that
have been fixed, so that it becomes possible to express its provenance
(i.e. what caused the thing with these specific aspects). An entity
encompasses a part of a thing's history during which some of the
attributes are fixed. An entity can thus be thought of as a part of a
thing with some associated partial state.
Attributes in PROV-DM are used to fix certain aspects of entities.
An entity is a thing one wants to provide provenance for
and whose situation in the world is described by some fixed
attributes. An entity has a characterization interval,
or lifetime,
defined as the period
between its generation event
and its invalidation event.
An entity's attributes are established when the entity is
created and describe the entity's situation and (partial) state
during an entity's lifetime.
A different entity (perhaps representing a different user or
system perspective) may fix other aspects of the same thing, and its provenance
may be different. Different entities that are aspects of the same
thing are called alternate, and the PROV-DM relations of
specialization and alternate can be used to link such entities.
Different users may take different perspectives on a resource with
a URL. A provenance record might use one (or more) different
entities to talk about different perspectives, such as:
- a report available at a URL: fixes the nature of the thing, i.e. a document, and its location;
- the version of the report available there today: fixes its version number, contents, and its date;
- the report independent of where it is hosted and of its content over time: fixes the nature of the thing as a conceptual artifact.
The provenance of these three entities may differ, and may be along the following lines:
- the provenance of a report available at a URL may include: the act of publishing it and making it available at a given location, possibly under some license and access control;
- the provenance of the version of the report available there today may include: the authorship of the specific content, and reference to imported content;
- the provenance of the report independent of where it is hosted over time may include: the motivation for writing the report, the overall methodology for producing it, and the broad team
involved in it.
We do not assume that any entity is a better or worse description of
reality than any other. That is, we do not assume an absolute ground truth with
respect to which we can judge correctness or completeness of
descriptions. In fact, it is possible to describe the processing that occurred for the report to be commissioned, for
individual versions to be created, for those versions to be published at the given URL, etc., each via a different entity with attribute-value pairs that fix some aspects of the report appropriately.
Besides entities, a variety of other PROV-DM objects have
attributes, including activity, generation, usage, start, end,
communication, attribution, association, responsibility, and
derivation. Each object has an associated duration interval (which may
be a single time point), and attribute-value pairs for a given object
are expected to be descriptions that hold for the object's duration.
However, the attributes of entities have special meaning because they
are considered to be fixed aspects
of underlying, changing things. This motivates constraints on
alternateOf and specializationOf relating the attribute values of
different entities.
TODO:
Constraints on alternateOf/specializationOf for this?
TODO: Further discussion of entities moved from the old "Definitional
constraints" section. Should merge with the surrounding
discussion to avoid repetition.
An entity is a thing one wants to provide provenance for
and whose situation in the world is described by some attribute-value
pairs. An entity's attribute-value pairs are established as part of
the entity statement and their values remain unchanged for the
lifetime of the entity. An entity's attribute-value pairs are expected
to describe the entity's situation and (partial) state during an
entity's characterization interval.
If an entity's situation or state changes, this may result in its statement being invalid, because one or more attribute-value pairs no longer hold. In that case, from the PROV viewpoint, there exists a new entity, which needs to be given a distinct identifier, and associated with the attribute-value pairs that reflect its new situation or state.
Further considerations:
- In order to describe the provenance of something during an interval over which
relevant attributes of the thing are not fixed, it is required to
create multiple entities, each with its own identifier, characterization interval, and
fixed attributes, and express
dependencies between the various entities using events.
For example, if we want to describe the provenance of several
versions of a document, involving attributes such as authorship that
change over time, we need different entities for the versions linked
by appropriate generation, usage, revision, and invalidation events.
- There is no assumption that the set of attributes is complete, nor
that the attributes are independent or orthogonal of each other.
- There is no assumption that the attributes of an entity uniquely
identify it. Two different entities that are aspects of different
things can have the same attributes.
- A characterization interval may collapse into a single instant.
8.2 Activities
TODO: Further discussion of activities moved from old "Definitional
constraints and inferences" section. Edit to avoid repeating information.
An activity is delimited by its start and its end events; hence, it occurs over
an interval delimited by two instantaneous
events. However, an activity record need not mention start or end time information, because they may not be known.
An activity's attribute-value pairs are expected to describe the activity's situation during its interval, i.e. an interval between two instantaneous events, namely its start event and its end event.
Further considerations:
- An activity is not an entity.
Indeed, an entity exists in full at
any point in its lifetime, persists during this
interval, and preserves the characteristics that makes it
identifiable. In contrast, an activity is something that occurs, happens,
unfolds, or develops through time, but is typically not identifiable by
the characteristics it exhibits at any point during its duration.
This distinction is similar to the distinction between
'continuant' and 'occurrent' in logic [Logic].
8.3 Description, Assertion, and Inference
PROV-DM is a provenance data model designed to express descriptions of the world.
A file at some point during its lifecycle, which includes multiple edits by multiple people, can be described by its type, its location in the file system, a creator, and content.
The data model is designed to capture activities that happened in the past, as opposed to activities
that may or will happen.
However, this distinction is not formally enforced.
Therefore, PROV-DM descriptions are intended to be interpreted as what
has happened, as opposed to what may or will happen.
This specification does not prescribe the means by which descriptions can be arrived at; for example, descriptions can be composed on the basis of observations, reasoning, or any other means.
Sometimes, inferences about the world can be made from descriptions
conformant to the PROV-DM data model. This
specification defines some such inferences, allowing new descriptions
to be inferred from existing ones. Hence, descriptions of the world
can result either from direct assertion or from inference
by application of inference rules defined by this specification.
8.4 Events and Time
Time is critical in the context of provenance, since it can help corroborate provenance claims. For instance, if an entity is claimed to be obtained by transforming another, then the
latter must have existed before the former. If it is not the case, then there is something wrong with such a provenance claim.
Although time is critical, we should also recognize that
provenance can be used in many different contexts within individual
systems and across the Web. Different systems may use different clocks
which may not be precisely synchronized, so when provenance records
are combined by different systems, we may not be able to align the
times involved to a single global timeline. Hence, PROV-DM is
designed to minimize assumptions about time.
Hence, to talk about the constraints on valid PROV-DM data, we
refer to instantaneous events that correspond to interactions
between activities and entities.
The term "event" is commonly used in process algebra with a similar meaning. For instance, in CSP [CSP], events represent communications or interactions; they are assumed to be atomic and
instantaneous.
8.4.1 Event Ordering
The following paragraphs are unclear and need to be revised, to
address review concerns: if
we aren't saying anything about how events and time relate, and time
is the only concrete information about event ordering in PROV-DM,
then how can implementations check that event ordering constraints
are satisfied?
How the precedes partial order is implemented in practice is beyond the scope
of this specification. This specification only assumes that
each instantaneous event can be mapped to an instant in some form of
timeline. The actual mapping is not in scope of this
specification. Likewise, whether this timeline is formed of a single
global timeline or whether it consists of multiple Lamport-style
clocks is also beyond this specification. The follows and
precedes orderings of events should be consistent with the
ordering of their associated times
over these timelines.
This specification defines event ordering constraints
between instantaneous events associated with
provenance descriptions. PROV-DM data must satisfy such constraints.
PROV-DM also allows for time observations to be inserted in
specific statements, for each recognized instantaneous event introduced in this
specification. The presence of a time observation for a given instantaneous event fixes the mapping of this instantaneous event to the timeline. It can also
help with the verification of associated ordering constraints (though,
again, this verification is outside the scope of this specification).
8.4.2 Types of Events
Five kinds of instantaneous events are used
for the PROV-DM data model. The activity start and
activity end events delimit the beginning and the end
of activities, respectively. The entity usage,
entity generation, and entity
invalidation events apply to entities, and the generation and
invalidation events delimit the characterization interval of
an entity. More specifically:
An activity start event is the instantaneous event that marks the instant an activity starts.
An activity end event is the instantaneous event that marks the instant an activity ends.
An entity usage event is the instantaneous event that marks the first instant of
an entity's consumption timespan by an activity. Before this instant
the entity had not begun to be used by the activity.
An entity generation event is the instantaneous event that marks the final instant of an entity's creation timespan, after which
it is available for use. The entity did not exist before this event.
An entity invalidation event
is the instantaneous event that
marks the initial instant of the destruction, invalidation, or
cessation of an entity, after which the entity is no longer available
for use. The entity no longer exists after this event.
8.5 Account
Some of this discussion may belong in the account constraint section
as motivation, or as formal constraints/inferences. In particular,
the must, may, should statements should be clarified and put into
the normative section.
It is common for multiple provenance records to co-exist. For
instance, when emailing a file, there could be a provenance record
kept by the mail client, and another by the mail server. Such
provenance records may provide different explanations about something
happening in the world, because they are created by different parties
or observed by different witnesses. A given party could also create
multiple provenance records about an execution, to capture different
levels of details, targeted at different end-users: the programmer of
an experiment may be interested in a detailed log of execution, while
the scientists may focus more on the scientific-level description.
Given that multiple provenance records can co-exist, it is important
to have details about their origin, who they are attributed to, how
they were generated, etc. In other words, an important requirement is
to be able to express the provenance of provenance.
See ISSUE-343.
An account is an entity that contains an instance, or set
of PROV statements.
PROV-DM does not provide an actual mechanism for creating accounts, i.e. for bundling up provenance descriptions and naming them. Accounts must satisfy some properties:
- An account is a bundle of provenance descriptions whose content may change over time.
- If an account's set of statements changes over time, it should increase monotonically with time.
- A given description of e.g. an entity in a given account, in terms of its identifier and attribute-value pairs, does not change over time.
The last point is important. It indicates that within an account:
- It is always possible to add new provenance statements, e.g. stating that a given entity was used by an activity, or derived from another. This is very much an open world assumption.
- It is not permitted to add new attributes to a given entity (a
form of closed world assumption from the attributes point of view),
though it is always permitted to create a new statement describing
an entity, which is a "copy" of the original statement extended with novel attributes (cf Example merge-with-rename).
There is no construct in PROV-DM to create such bundles of
statements. Instead, it is assumed that some mechanism, outside
PROV-DM can create them. However, from a provenance viewpoint, such
accounts are things whose provenance we may want to describe. In order to be able to do so, we need to see accounts as entities, whose origin can be described using PROV-DM vocabulary. Thus, PROV-DM introduces the reserved type Account.