Abstract
CSS (Cascading Style Sheets) is a language for describing the rendering
of HTML and XML documents on screen, on paper, in speech, etc. CSS defines
aural properties that give control over rendering XML and HTML to speech.
This draft describes the text to speech properties proposed for CSS level
3, and is a re-work of the informative CSS2.1 Aural appendix [CSS21]. These are
designed for match the model described in the Speech Synthesis Markup
Language (SSML) Version 1.0 [SPEECH-SYNTHESIS].
The CSS3 Speech Module is a community effort and if you would like to
help with implementation and driving the specification forward along the
W3C Recommendation track, please contact the editors.
Status of this document
This section describes the status of this document at the time of
its publication. Other documents may supersede this document. A list of
current W3C publications and the latest revision of this technical report
can be found in the W3C technical reports
index at http://www.w3.org/TR/.
Publication as a Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
The (archived) public
mailing list www-style@w3.org (see
instructions) is preferred
for discussion of this specification. When sending e-mail, please put the
text “css3-speech” in the subject, preferably like this:
“[css3-speech] …summary of
comment…”
This document was produced by the CSS Working Group (part of
the Style Activity).
This document was produced by a group operating under the 5 February
2004 W3C Patent Policy. W3C maintains a public list of any patent disclosures made in
connection with the deliverables of the group; that page also includes
instructions for disclosing a patent. An individual who has actual
knowledge of a patent which the individual believes contains Essential
Claim(s) must disclose the information in accordance with section
6 of the W3C Patent Policy.
This document is a draft of one of the "modules" for the upcoming CSS3
specification.
This document has been developed in cooperation with the Voice Browser working group (W3C Members only).
The following issues need to be discussed and require working group
resolutions:
The CSS WG maintains an issues list for
this module.
Table of contents
1. Dependencies on other
modules
This CSS3 module depends on the following other CSS3 modules:
It has non-normative (informative) references to the following other
CSS3 modules:
2. Introduction
The speech rendering of a document, already commonly used by the blind
and print-impaired communities, combines speech synthesis and "auditory
icons". Often such aural presentation occurs by converting the document to
plain text and feeding this to a screen reader
— software or hardware that simply reads all the characters on the
screen. This results in less effective presentation than would be the case
if the document structure were retained. Style sheet properties for text
to speech may be used together with visual properties (mixed media) or as
an aural alternative to visual presentation.
Besides the obvious accessibility advantages, there are other large
markets for listening to information, including in-car use, industrial and
medical documentation systems (intranets), home entertainment, and to help
users learning to read or who have difficulty reading.
When using voice properties, the canvas consists of a two channel stereo
space and a temporal space (you can specify audio
cues before and after synthetic speech). The CSS properties also allow
authors to vary the characteristics of synthetic speech (voice type,
frequency, inflection, etc.).
Examples:
h1, h2, h3, h4, h5, h6 {
voice-family: paul;
voice-stress: moderate;
cue-before: url(ping.au)
}
p.heidi { voice-balance: left; voice-family: female }
p.peter { voice-balance: right; voice-family: male }
p.goat { voice-volume: soft }
This will direct the speech synthesizer to speak headers in a voice (a
kind of "audio font") called "paul". Before speaking the headers, a sound
sample will be played from the given URL. Paragraphs with class "heidi"
will appear to come from the left (if the sound system is capable of
stereo), and paragraphs of class "peter" from the right. Paragraphs with
class "goat" will be played softly.
Note that content creators may conditionally include CSS
properties authored specifically for user-agents with text to speech
capabilities (TTS), by specifying the "speech" media type via the
media attribute of the link element, or with the
@media at-rule, or within an @import statement
(the "aural" media type was deprecated in the informative CSS2.1 Aural
appendix [CSS21]).
When doing so, the styles authored within the scope of such conditional
statements are ignored by user-agents that do not support speech
synthesis.
3. The aural "box" model
The formatting model of CSS for aural media is based on a sequence of
sounds and silences that appear in a nested model which is related to the
visual box model; however the aural canvas is one-dimensional, monolinear.
For compatibility with the visual box model, we will call it the aural "box" model.
The element is surrounded by, in this order, ‘rest’, ‘cue’ and ‘pause’ properties -
they can be thought of as aural equivalents to ‘padding’, ‘border’ and ‘margin’ respectively.
It can be represented in the following way (including the equivalent
properties from the visual box model for clarification of relationships):
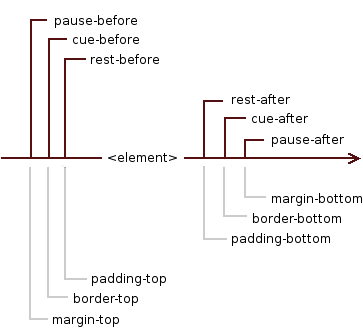
where <element> is the selected element
to which the properties from the CSS3 Speech Module apply.
Note that the ‘none’
value of the ‘display’ property (which is defined in the
CSS box model [CSS3BOX] and which applies to all
media types) influences the resolved value of the ‘speakability’
property (defined within this CSS3 module) when the ‘auto’ value is specified for ‘speakability’.
This is the only case whereby a property defined externally to this CSS3
module affects a characteristic specific to the aural dimension (i.e. has
an impact within the aural "box" model).
| Name:
| voice-volume
|
| Value:
| <non-negative number> | <percentage> | silent | x-soft |
soft | medium | loud | x-loud | inherit
|
| Initial:
| medium
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| refer to inherited value
|
| Media:
| speech
|
The ‘voice-volume’ refers to the amplitude of
the waveform output by the speech synthesiser. This may be mixed with
other audio sources, influencing the perceived loudness of synthetic
speech relative to these sources.
Values have the following meanings:
- <non-negative number>
- An integer or floating point number in the range ‘
0’ to ‘100’.
‘0’ represents silence (the
minimum level), and 100 corresponds to the maximum
level. The volume scale is linear amplitude.
- <percentage>
- Only positive values are allowed. Computed values are calculated
relative to the inherited value, and are then clipped to the range
‘
0’ to ‘100’.
Note that a leading "+" sign does not denote an increment.
For example, +50% is equivalent to 50%, so the computed value equals the
inherited value times 0.5 (divided by 2), then clipped to [0,100].
- silent, x-soft,
soft, medium, loud,
and x-loud
- A sequence of monotonically non-decreasing volume levels. The value of
‘
silent’ is mapped to
‘0’ and ‘x-loud’ is mapped to ‘100’. The mapping of other values to numerical
volume levels is implementation dependent and may vary from one speech
synthesizer to the next.
User agents should allow the level corresponding to ‘100’ to be set by the listener. No one setting is
universally applicable; suitable values depend on the equipment in use
(speakers, headphones), and the environment (in car, home theater,
library) and personal preferences.
Note that there is a difference between an element whose
‘voice-volume’ property has a value of
‘silent’, and an element whose
‘speakability’ property has the value
‘none’. The former takes up the
same time as if it had been spoken, including any pause before and after
the element, but no sound is generated (although descendants may override
the ‘voice-volume’ value and may therefore
generate audio output). The latter requires no time and is not rendered in
the aural dimension
(although descendants may override the ‘speakability’
value and may therefore generate audio output).
| Name:
| voice-balance
|
| Value:
| <number> | left | center | right | leftwards | rightwards |
inherit
|
| Initial:
| center
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| N/A
|
| Media:
| speech
|
The ‘voice-balance’ property refers to the
balance between left and right channels, and presumes a two channel
(stereo) model that is widely supported on consumer audio equipment.
Values have the following meanings:
- <number>
- An integer or floating point number between ‘
-100’ and ‘100’. For ‘-100’ only the left channel is audible. Simarly
for ‘100’ or ‘+100’ only the right channel is audible. For
‘0’ both channels have the same level,
so that the speech appears to be coming from the center.
- left
- Same as ‘
-100’.
- center
- Same as ‘
0’.
- right
- Same as ‘
100’ or ‘+100’.
- leftwards
- Moves the sound to the left, relative to the inherited ‘
voice-balance’. More precisely, subtract
20 from the inherited value and clip the resulting value to the range
‘-100’ and ‘100’.
- rightwards
- Moves the sound to the right, relative to the inherited ‘
voice-balance’. More precisely, add 20 to
the inherited value and clip the resulting value to the range
‘-100’ and ‘100’.
Many speech synthesizers only support a single channel. The ‘voice-balance’
property can then be treated as part of a post synthesis mixing step. This
is where speech is mixed with other audio sources.
| Name:
| speakability
|
| Value:
| auto | none | normal | inherit
|
| Initial:
| auto
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| N/A
|
| Media:
| speech
|
ISSUE: should the "speakability"
property be named differently ? e.g. "speaking"
This property specifies whether text will be rendered aurally.
Values have the following meanings:
- auto
- Resolves to a computed value of ‘
none’ when ‘display’ is
‘none’ (see [CSS3BOX]), otherwise resolves to
a computed value of ‘auto’ which
yields a used value of ‘normal’.
- none
- This value causes an element (including pauses, cues, rests and
actual content) to not be rendered (i.e., the element has no effect in
the aural dimension).
Note that any of the descendants of the affected element
are allowed to override this value, so they may actually take part in
the aural rendering. However, the pauses, cues, and rests of the
ancestor element remain "deactivated" in the aural dimension, and
therefore do not contribute to the collapsing of
pauses or additive behavior of adjacent rests.
- normal
- The element is rendered aurally.
Note that although the ‘none’ value of the ‘display’
property cannot be overridden by descendants of the affected element (see
[CSS3BOX]), the
‘auto’ value of ‘speakability’
can however be overridden by descendants, using either of ‘none’ or ‘normal’. In the case of ‘normal’, this would result in descendants
being rendered in the aural dimension even though they would not be
rendered on the visual canvas.
| Name:
| speak
|
| Value:
| normal | spell-out | digits | literal-punctuation | no-punctuation |
inherit
|
| Initial:
| normal
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| N/A
|
| Media:
| speech
|
This property specifies in what manner text gets rendered aurally.
Values have the following meanings:
- normal
- Uses language-dependent pronunciation rules for rendering an element
and its children. Punctuation is not to be spoken, but instead rendered
naturally as various pauses.
- spell-out
- Spells the text one letter at a time (useful for acronyms and
abbreviations). In languages where accented characters are rare, it is
permitted to drop accents in favor of alternative unaccented spellings.
As as example, in English, the word "rôle" can also be written as
"role". A conforming implementation would thus be able to spell-out
"rôle" as "R O L E".
- digits
- Speak numbers one digit at a time, for instance, "twelve" would be
spoken as "one two", and "31" as "three one".
- literal-punctuation
- Similar to ‘
normal’ value, but
punctuation such as semicolons, braces, and so on are to be spoken
literally.
- no-punctuation
- Similar to ‘
normal’ value but
punctuation is not to be spoken nor rendered as various pauses.
Speech synthesizers are knowledgeable about what is and what is not a
number. The ‘speak’ property gives authors the means to
control how the synthesizer renders the numbers it discovers in the source
text, and may be implemented as a preprocessing step before passing the
text to the speech synthesizer.
| Name:
| pause-before
|
| Value:
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
| Name:
| pause-after
|
| Value:
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
These properties specify a pause or prosodic boundary to be observed
before (or after) an element or, if any ‘cue-before’ (or ‘cue-after’) is
specified, before (or after) these.
Values have the following meanings:
- <time>
- Expresses the pause in absolute time units, as per the syntax of
"time" values in [CSS3VAL] (seconds and
milliseconds, e.g. "3s", "250ms"). Only positive values are allowed.
- none, x-weak, weak,
medium, strong, and
x-strong
- These values may be used to indicate the prosodic strength of the
break in speech output. The synthesis processor may insert a pause as
part of its implementation of the prosodic break. The value "none"
indicates that no prosodic break boundary should be output, and can be
used to inhibit a prosodic break which the processor would otherwise
produce. The other values indicate monotonically non-decreasing
(conceptually increasing) break strength between elements. "x-weak" and
"x-strong" are mnemonics for "extra weak" and "extra strong",
respectively. The stronger boundaries are typically accompanied by
pauses. The breaks between paragraphs are typically much stronger than
the breaks between words within a sentence.
| Name:
| pause
|
| Value:
| [ <‘pause-before’> || <‘pause-after’> ] | inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
The ‘pause’
property is a shorthand for setting ‘pause-before’ and ‘pause-after’. If
two values are given, the first value is ‘pause-before’
and the second is ‘pause-after’. If only one value is given,
it applies to both properties.
Examples:
h1 { pause: 20ms } /* pause-before: 20ms; pause-after: 20ms */
h2 { pause: 30ms 40ms } /* pause-before: 30ms; pause-after: 40ms */
h3 { pause-after: 10ms } /* pause-before: unspecified; pause-after: 10ms */
6.1. Collapsing pauses
The pause defines the minimum distance of the aural "box" to the aural
"boxes" before and after it. Adjacent pauses should be merged by selecting
the strongest named break or the longest absolute time interval. Thus
"strong" is selected when comparing "strong" and "weak", while "1s" is
selected when comparing "1s" and "250ms". We say that such pauses collapse. A combination of a named break and time
duration is treated additively.
The following pauses collapse:
- The ‘
pause-after’ of an aural "box" and the
‘pause-after’ of its last child, provided
the former has no ‘rest-after’ and no ‘cue-after’.
- The ‘
pause-before’ of an aural "box" and the
‘pause-before’ of its first child,
provided the former has no ‘rest-before’ and no ‘cue-before’.
- The ‘
pause-after’ of an aural "box" and the
‘pause-before’ of its next sibling.
- The ‘
pause-before’ and ‘pause-after’ of
an aural "box", if the the "box" has a ‘voice-duration’ of "0ms", no ‘rest-before’ or
‘rest-after’, no ‘cue-before’ or
‘cue-after’ and no content.
The ‘pause-after’ of an element is always
adjoining to the ‘pause-before’ of its next sibling.
The ‘pause-before’ an element is adjoining to
its first child's ‘pause-before’, if the element has no
‘cue-before’ nor ‘rest-before’.
The ‘pause-after’ of an element is adjoining to
its last child's ‘pause-after’, if the element has no
‘rest-after’ or ‘cue-after’.
An element's own pauses are adjoining if the ‘voice-duration’ property is zero, and it
has no rest, and it does not contain any content, and all of its
children's pauses (if any) are adjoining.
Note that ‘pause’ has been moved from between the
element's contents and any ‘cue’ to outside the ‘cue’. This is not
backwards compatible with the informative CSS2.1 Aural appendix [CSS21].
| Name:
| rest-before
|
| Value:
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
| Name:
| rest-after
|
| Value:
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
These properties specify a rest or prosodic boundary to be observed
before (or after) speaking an element's content.
Values have the following meanings:
- <time>
- Expresses the rest in absolute time units, as per the syntax of "time"
values in [CSS3VAL] (seconds and
milliseconds, e.g. "3s", "250ms"). Only positive values are allowed.
- none, x-weak, weak,
medium, strong, and
x-strong
- These values may be used to indicate the prosodic strength of the
break in speech output. The synthesis processor may insert a rest as part
of its implementation of the prosodic break. The value "none" indicates
that no prosodic break boundary should be output, and can be used to
inhibit a prosodic break which the processor would otherwise produce. The
other values indicate monotonically non-decreasing (conceptually
increasing) break strength between words. The stronger boundaries are
typically accompanied by rests. "x-weak" and "x-strong" are mnemonics for
"extra weak" and "extra strong", respectively.
As opposed to pause properties, the rest is
inserted between the element's content and any ‘cue-before’ or
‘cue-after’ content. Adjacent rests are
treated additively.
| Name:
| rest
|
| Value:
| [ <‘rest-before’> || <‘rest-after’> ] | inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
The ‘rest’
property is a shorthand for setting ‘rest-before’ and ‘rest-after’. If
two values are given, the first value is ‘rest-before’ and
the second is ‘rest-after’. If only one value is given,
it applies to both properties.
| Name:
| cue-before
|
| Value: |
<uri> [<percentage>] | none | inherit
|
| Initial:
| none
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| apply to inherited value for ‘voice-volume’
|
| Media:
| speech
|
| Name:
| cue-after
|
| Value: |
<uri> [<percentage>] | none | inherit
|
| Initial:
| none
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| apply to inherited value for ‘voice-volume’
|
| Media:
| speech
|
Auditory icons are another way to distinguish semantic elements. Sounds
may be played before and/or after the element to delimit it.
Values have the following meanings:
- <uri>
- The URI must designate an auditory icon resource. If the URI resolves
to something other than an audio file, such as an image, the resource
should be ignored and the property treated as if it had the value
‘
none’.
- none
- No auditory icon is specified.
- <percentage>
- Only positive values are allowed. Computed values are calculated
relative to the inherited value of the ‘
voice-volume’
property, and are then clipped to the range ‘0’ to ‘100’.
‘0’ represents silence (the
minimum level), and 100 corresponds to the maximum
level. The volume scale is linear amplitude. By basing the percentage
upon the inherited value for ‘voice-volume’, it is easy to adjust the
relative loudness of cues compared to synthetic speech for whatever
volume setting has been provided for that speech.
Note that a leading "+" sign does not denote an increment.
For example, +50% is equivalent to 50%, so the computed value equals the
inherited value times 0.5 (divided by 2), then clipped to [0,100].
Examples:
a { cue-before: url(bell.aiff); cue-after: url(dong.wav) }
h1 { cue-before: url(pop.au) 80%; cue-after: url(pop.au) 50% }
div.caution { cue-before: url(caution.wav) 130% }
| Name:
| cue
|
| Value:
| [ <‘cue-before’> || <‘cue-after’>
] | inherit
|
| Initial:
| not defined for shorthand properties
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| apply to inherited value for ‘voice-volume’
|
| Media:
| speech
|
The ‘cue’
property is a shorthand for setting ‘cue-before’ and ‘cue-after’. If two
values are given the first value is ‘cue-before’ and the second is ‘cue-after’. If
only one value is given, it applies to both properties.
The following two rules are equivalent:
h1 {cue-before: url(pop.au); cue-after: url(pop.au) }
h1 {cue: url(pop.au) }
If a user agent cannot render an auditory icon (e.g., the user's
environment does not permit it), we recommend that it produce an
alternative audio cue (e.g., popping up a warning, emitting a warning
sound, etc.)
Authors may also use content generation
techniques to insert additional auditory cues based on text instead of
audio icons.
| Name:
| voice-family
|
| Value:
| [[[<specific-voice> | [<age>? <generic-voice>]]
<non-negative number>?],]* [[<specific-voice> |
[<age>? <generic-voice>]] <non-negative number>?] |
inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| N/A
|
| Media:
| speech
|
The value is a comma-separated, prioritized list of voice family names
(compare with ‘font-family’).
Values have the following meanings:
- <specific-voice>
- Values are specific instances (e.g., Mike, comedian, mary, carlos,
"valley-girl").
- <age>
- Possible values are ‘
child’,
‘young’ and ‘old’.
- <generic-voice>
- Values are voice families. Possible values are ‘
male’, ‘female’ and ‘neutral’.
- <non-negative number>
- Indicates a preferred variant of the other voice characteristics (e.g.
"the second male child voice named ‘
Mike’"). Possible values are positive
integers, excluding zero (i.e. starting from 1). The value "1" refers to
the first of all matching voices.
Examples:
h1 { voice-family: announcer, old male }
p.part.romeo { voice-family: romeo, young male }
p.part.juliet { voice-family: juliet, female }
p.part.mercutio { voice-family: male 2 }
p.part.tybalt { voice-family: male 3 }
p.part.nurse { voice-family: child female }
Names of specific voices may be quoted, and indeed must be quoted if any
of the words that make up the name does not conform to the syntax rules
for identifiers [CSS3SYN]. Any whitespace characters
before and after the voice name are ignored. For compatibility with SSML,
whitespace characters are not permitted within voice names.
The ‘voice-family’ property is used to guide
the selection of the voice to be used for speech synthesis. The overriding
priority is to match the language specified by the xml:lang attribute as
per the XML 1.0 specification [XML10], and as inherited by nested
elements until overridden by a further xml:lang attribute.
If there is no voice available for the requested value of xml:lang, the
processor should select a voice that is closest to the requested language
(e.g. a variant or dialect of the same language). If there are multiple
such voices available, the processor should use a voice that best matches
the values provided with the ‘voice-volume’ property. It is an error if
there are no such matches.
| Name:
| voice-rate
|
| Value:
| <percentage> | x-slow | slow | medium | fast | x-fast |
inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| refer to default value
|
| Media:
| speech
|
This property controls the speaking rate. The default rate for a voice
depends on the language and dialect and on the personality of the voice.
The default rate for a voice should be such that it is experienced as a
normal speaking rate for the voice when reading aloud text. Since voices
are processor-specific, the default rate will be as well.
Values have the following meanings:
- <percentage>
- Only positive values are allowed. Computed values are calculated
relative to the default speaking rate for each voice.
Note that a leading "+" sign does not denote an increment,
for example +50% is equivalent to 50% (i.e. the computed value equals
the inherited value times 0.5, which is half the normal rate of the
voice).
- x-slow, slow,
medium, fast and
x-fast
- A sequence of monotonically non-decreasing speaking rates that are
implementation and voice specific.
| Name:
| voice-pitch
|
| Value:
| <frequency> | <percentage> | <relative-change> |
x-low | low | medium | high | x-high | inherit
|
| Initial:
| medium
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| refer to inherited value
|
| Media:
| speech
|
Specifies the average pitch (a frequency) of the speaking voice. The
average pitch of a voice depends on the ‘voice-family’.
For example, the average pitch for a standard male voice is around 120Hz,
but for a female voice, it's around 210Hz.
Values have the following meanings:
- <frequency>
- This is an absolute value that specifies the average pitch of the
speaking voice in Hertz. It must be <non-negative number> followed
by the "Hz" suffix.
- <percentage>
- Only positive values are allowed. Computed values are calculated
relative to the inherited value.
Note that a leading "+" sign does not denote an increment.
For example, +50% is equivalent to 50%, so the computed value equals the
inherited value times 0.5 (divided by 2), which is half the inherited
average pitch of the voice.
- <relative-change>
- Specifies a relative change (decrement or increment) to the inherited
value. The syntax of allowed values is a <number> (the "+" sign is
optional for positive numbers), followed by either of "Hz" (for Hertz) or
"st" (for semitones), and followed by a space character and the
"relative" keyword.
Note that the "relative" keyword is mandatory. This is in
order to disambiguate from <frequency> values which may also carry
the optional "+" sign on positive values.
- x-low, low, medium,
high, x-high
- A sequence of monotonically non-decreasing pitch levels that are
implementation and voice specific.
Examples:
h1 { voice-pitch: 250Hz; }
h1 { voice-pitch: +250Hz; } /* identical to the line above */
h2 { voice-pitch: +30Hz relative; }
h2 { voice-pitch: 30Hz relative; } /* identical to the line above */
h3 { voice-pitch: -2st relative; }
h4 { voice-pitch: -2st; } /* Illegal syntax ! ("relative" keyword is missing) */
| Name:
| voice-pitch-range
|
| Value:
| <frequency> | <percentage> | <relative-change> |
x-low | low | medium | high | x-high | inherit
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| refer to inherited value
|
| Media:
| speech
|
Specifies variation in average pitch. The perceived pitch of a human
voice is determined by the fundamental frequency and typically has a value
of 120Hz for a male voice and 210Hz for a female voice. Human languages
are spoken with varying inflection and pitch; these variations convey
additional meaning and emphasis. Thus, a highly animated voice, i.e., one
that is heavily inflected, displays a high pitch range. This property
specifies the range over which these variations occur, i.e., how much the
fundamental frequency may deviate from the average pitch.
Values have the following meanings:
- <frequency>
- This is an absolute value that specifies the average pitch range of
the speaking voice in Hertz. Low ranges produce a flat, monotonic voice.
A high range produces animated voices. It must be <non-negative
number> followed by the "Hz" suffix.
- <percentage>
- Only positive values are allowed. Computed values are calculated
relative to the inherited value.
Note that a leading "+" sign does not denote an increment.
For example, +50% is equivalent to 50%, so the computed value equals the
inherited value times 0.5 (divided by 2), which is half the inherited
average pitch range of the voice.
- <relative-change>
- Specifies a relative change (decrement or increment) to the inherited
value. The syntax of allowed values is a <number> (the "+" sign is
optional for positive numbers), followed by either of "Hz" (for Hertz) or
"st" (for semitones), and followed by a space character and the
"relative" keyword.
Note that the "relative" keyword is mandatory. This is in
order to disambiguate from <frequency> values which may also carry
the optional "+" sign on positive values.
- x-low, low, medium,
high and x-high
- A sequence of monotonically non-decreasing pitch ranges that are
implementation and language dependent.
Note that a semitone is half of a tone (a half step) on the
standard diatonic scale. A semitone doesn't correspond to a fixed value in
Hertz: instead, the ratio between two consecutive frequencies separated by
exactly one semitone is approximately 1.05946 (the actual arithmetics
involved are beyond the scope of this specification, please refer to
existing literature on that subject).
| Name:
| voice-stress
|
| Value:
| strong | moderate | none | reduced | inherit
|
| Initial:
| moderate
|
| Applies to:
| all elements
|
| Inherited:
| yes
|
| Percentages:
| N/A
|
| Media:
| speech
|
Indicates the strength of emphasis to be applied. Emphasis is indicated
using a combination of pitch change, timing changes, loudness and other
acoustic differences) that varies from one language to the next.
Values have the following meanings:
- none, moderate and
strong
- These are monotonically non-decreasing in strength, with the precise
meanings dependent on language being spoken. The value ‘
none’ inhibits the synthesizer from
emphasizing words it would normally emphasize.
- reduced
- Effectively the opposite of emphasizing a word. For example, when the
phrase "going to" is reduced it may be spoken as "gonna".
| Name:
| voice-duration
|
| Value:
| <time>
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
Allows authors to specify how long it should take to render the selected
element's content. This property takes precedence over the ‘voice-rate’
property.
Values have the following meanings:
- <time>
-
Specifies a value in seconds or milliseconds (as per the syntax of
"time" values in [CSS3VAL]) for the desired spoken
duration of the element contents, for instance, "250ms", or "3s". Only
positive numbers are allowed.
| Name:
| phonemes
|
| Value:
| <string>
|
| Initial:
| implementation dependent
|
| Applies to:
| all elements
|
| Inherited:
| no
|
| Percentages:
| N/A
|
| Media:
| speech
|
This allows authors to specify a phonetic pronunciation for the text
contained by the corresponding element.
Values have the following meanings:
- <string>
- A character string that describes a pronunciation based on the
specified ‘
@phonetic-alphabet’.
ISSUE: the ‘phonemes’ property
covers functionality that arguably doesn't belong to CSS, as it breaks the
principle of separation between content and presentation (i.e. any change
in the source text must be echoed by an corresponding change in the
content of the aural ‘phonemes’ property). The broader aspect of
pronunciation lexicons would be better addressed in the content markup.
For example, it is
proposed that formats like the W3C's own PLS standard should be
supported by the link/rel mechanism. There is a related
discussion on the public mailing-list.
11.1. @phonetic-alphabet
A phonetic alphabet is a collection of symbols that represent the
sounds of one or more human languages. The default alphabet for the
pronunciation string of the ‘phonemes’ property is the International
Phonetic Alphabet ("ipa"), corresponding to Unicode representations of the
phonetic characters developed by the International Phonetic Association
[IPA]. The phonetic alphabet can be explicitly
specified using the ‘@phonetic-alphabet’ rule.
Note that the alphabet is specified via an at-rule to avoid
problems with inappropriate cascades [CSS3CASCADE] that can occur if
the alphabet was set via a property.
Example:
@phonetic-alphabet "ipa";
#tomato { phonemes: "t\0252 m\0251 to\028a " }
This will direct the speech synthesizer to replace the default
pronunciation by the corresponding sequence of ‘phonemes’ in the
designated alphabet.
At most one ‘@phonetic-alphabet’ rule may appear in style
sheet and it must appear, when used, before any occurrence of the
‘phonemes’
property. The only valid values are the default "ipa" phonetic alphabet,
and vendor-specific strings such as "x-organization" or
"x-organization-alphabet".
12. Inserted and replaced content
Sometimes, authors will want to specify a mapping from the source text
into another string prior to the application of the regular pronunciation
rules. This may be used for uncommon abbreviations or acronyms which are
unlikely to be recognized by the synthesizer. The ‘content’
property can be used to replace one string by another. In the following
example, the abbreviation is rendered using the content of the title
attribute instead of the element's content:
Example:
abbr { content: attr(title); }
...
<abbr title="World Wide Web Consortium">W3C</abbr>
This replaces the content of the selected element by the string "World
Wide Web Consortium".
In a similar way text-to-speech strings in a document can be replaced by
a previously recorded version:
Example:
.hamlet { content: url(gielgud.wav); }
...
<div class="hamlet">
To be, or not to be: that is the question:
</div>
If the format is supported, the file is available and the UA is
configured to do so, a recording of Sir John Gielgud's declamation of the
famous monologue will be played, otherwise the UA falls back to render
the text-to-speech with its own synthesizer.
Furthermore, authors (or users in a user stylesheet) may want to add
some information to ease understanding the structure for non-visual
interaction with the document. They can do so by using the ‘::before’ and ‘::after’ pseudo-elements that will be inserted
between the element's contents and the ‘rest’:
Example:
ul::before { content: "Start list: " }
ul::after { content: "List end. " }
li::before { content: "List item: " }
This inserts the string "Start list: " before a list and the string
"List item: " before each list item; likewise the string "List end: "
inserted after the list will inform the user that the list is finished.
Different stylesheets can be used to define the level of verbosity for
additional information spoken by screen readers.
Note that detailed information can be found in the CSS3
Generated and Replaced Content Module [CSS3GENCON].
ISSUE: the speech handling of list items is
under-specified. One suggestion is to ignore list-style-type (which can
represent visual glyphs not suitable for aural processing anyway) and to
define a standard way to read list
"markers". Unfortunately this introduces a dependency on a feature
specific to CSS3-Lists. There is a related
discussion on the public mailing-list.
Appendix A — Profiles
TBD
Appendix B — Property index
| Property
| Values
| Initial
| Applies to
| Inh.
| Percentages
| Media
|
| cue
| [ <‘cue-before’> ||
<‘cue-after’> ] | inherit
| not defined for shorthand properties
| all elements
| no
| apply to inherited value for ‘voice-volume’
| speech
|
| cue-after
| <uri> [<percentage>] | none | inherit
| none
| all elements
| no
| apply to inherited value for ‘voice-volume’
| speech
|
| cue-before
| <uri> [<percentage>] | none | inherit
| none
| all elements
| no
| apply to inherited value for ‘voice-volume’
| speech
|
| pause
| [ <‘pause-before’> ||
<‘pause-after’> ] | inherit
| implementation dependent
| all elements
| no
| N/A
| speech
|
| pause-after
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
| implementation dependent
| all elements
| no
| N/A
| speech
|
| pause-before
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
| implementation dependent
| all elements
| no
| N/A
| speech
|
| phonemes
| <string>
| implementation dependent
| all elements
| no
| N/A
| speech
|
| rest
| [ <‘rest-before’> ||
<‘rest-after’> ] | inherit
| implementation dependent
| all elements
| no
| N/A
| speech
|
| rest-after
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
| implementation dependent
| all elements
| no
| N/A
| speech
|
| rest-before
| <time> | none | x-weak | weak | medium | strong | x-strong |
inherit
| implementation dependent
| all elements
| no
| N/A
| speech
|
| speak
| normal | spell-out | digits | literal-punctuation | no-punctuation |
inherit
| normal
| all elements
| yes
| N/A
| speech
|
| speakability
| auto | none | normal | inherit
| auto
| all elements
| yes
| N/A
| speech
|
| voice-balance
| <number> | left | center | right | leftwards | rightwards |
inherit
| center
| all elements
| yes
| N/A
| speech
|
| voice-duration
| <time>
| implementation dependent
| all elements
| no
| N/A
| speech
|
| voice-family
| [[[<specific-voice> | [<age>? <generic-voice>]]
<non-negative number>?],]* [[<specific-voice> |
[<age>? <generic-voice>]] <non-negative number>?] |
inherit
| implementation dependent
| all elements
| yes
| N/A
| speech
|
| voice-pitch
| <frequency> | <percentage> | <relative-change> |
x-low | low | medium | high | x-high | inherit
| medium
| all elements
| yes
| refer to inherited value
| speech
|
| voice-pitch-range
| <frequency> | <percentage> | <relative-change> |
x-low | low | medium | high | x-high | inherit
| implementation dependent
| all elements
| yes
| refer to inherited value
| speech
|
| voice-rate
| <percentage> | x-slow | slow | medium | fast | x-fast |
inherit
| implementation dependent
| all elements
| yes
| refer to default value
| speech
|
| voice-stress
| strong | moderate | none | reduced | inherit
| moderate
| all elements
| yes
| N/A
| speech
|
| voice-volume
| <non-negative number> | <percentage> | silent | x-soft |
soft | medium | loud | x-loud | inherit
| medium
| all elements
| yes
| refer to inherited value
| speech
|
The following properties are defined in other modules:
Appendix C — Index
- aural "box" model, 3.
- authoring tool, #
- collapse, 6.1.
- content, #
- cue, 8.
- cue-after, 8.
- cue-before, 8.
- display, #
- document, #
- documents, #
- <element>, 3.
- pause, 6.
- pause-after, 6.
- pause-before, 6.
- phonemes, 11.
- renderer, #
- rest, 7.
- rest-after, 7.
- rest-before, 7.
- screen reader, 2.
- speak, 5.
- speakability, 5.
- style sheet, #
- UA, #
- User Agent, #
- voice-balance, 4.
- voice-duration, 10.
- voice-family, 9.
- voice-pitch, 9.
- voice-pitch-range, 9.
- voice-rate, 9.
- voice-stress, 9.
- voice-volume, 4.
Appendix D — Definitions
Glossary
The following terms and abbreviations are used in this module.
- UA
- User Agent
-
A program that reads and/or writes CSS style sheets on behalf of a
user in either or both of these categories: programs whose purpose is to
render documents (e.g., browsers) and programs
whose purpose is to create style sheets (e.g., editors). A UA may fall
into both categories. (There are other programs that read or write style
sheets, but this module gives no rules for them.)
- document
-
A tree-structured document with elements and attributes, such as an
SGML or XML document [XML11].
- style sheet
-
A CSS
style sheet.
Conformance requirements are expressed with a combination of descriptive
assertions and RFC 2119 terminology. The key words "MUST", "MUST NOT",
"REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED",
"MAY", and "OPTIONAL" in the normative parts of this document are to be
interpreted as described in RFC 2119. However, for readability, these
words do not appear in all uppercase letters in this specification. All of
the text of this specification is normative except sections explicitly
marked as non-normative, examples, and notes. [RFC2119]
Examples in this specification are introduced with the words "for
example" or are set apart from the normative text with
class="example", like this:
This is an example of an informative example.
Informative notes begin with the word "Note" and are set apart from the
normative text with class="note", like this:
Note, this is an informative note.
Conformance to the CSS3 Speech Module is defined for three classes:
- style
sheet
- A CSS
style sheet.
- renderer
- A UA that interprets the semantics of a style sheet and renders documents that use them.
- authoring tool
- A UA that writes a style sheet.
A style sheet is conformant to the CSS3 Speech Module if all of its
declarations that use properties defined in this module have values that
are valid according to the generic CSS grammar and the individual grammars
of each property as given in this module.
A renderer is conformant to the CSS3 Speech Module if, in addition to
interpreting the style sheet as defined by the appropriate specifications,
it supports all the properties defined by CSS3 Speech Module by parsing
them correctly and rendering the document accordingly. However the
inability of a UA to correctly render a document due to limitations of the
device does not make the UA non-conformant. (For example, a UA is not
required to render color on a monochrome monitor.)
An authoring tool is conformant to CSS3 Speech Module if it writes
syntactically correct style sheets, according to the generic CSS grammar
and the individual grammars of each property in this module.
CR exit criteria
As described in the W3C process document, a Candidate
Recommendation (CR) is a specification that W3C recommends for use on
the Web. The next stage is "Recommendation" when the specification is
sufficiently implemented.
For this specification to be proposed as a W3C Recommendation, the
following conditions shall be met. There must be at least two independent,
interoperable implementations of each feature. Each feature may be
implemented by a different set of products, there is no requirement that
all features be implemented by a single product. For the purposes of this
criterion, we define the following terms:
- independent
- each implementation must be developed by a different party and cannot
share, reuse, or derive from code used by another qualifying
implementation. Sections of code that have no bearing on the
implementation of this specification are exempt from this requirement.
- interoperable
- passing the respective test case(s) in the official CSS test suite,
or, if the implementation is not a Web browser, an equivalent test. Every
relevant test in the test suite should have an equivalent test created if
such a user agent (UA) is to be used to claim interoperability. In
addition if such a UA is to be used to claim interoperability, then there
must one or more additional UAs which can also pass those equivalent
tests in the same way for the purpose of interoperability. The equivalent
tests must be made publicly available for the purposes of peer review.
- implementation
- a user agent which:
- implements the specification.
- is available to the general public. The implementation may be a
shipping product or other publicly available version (i.e., beta
version, preview release, or "nightly build"). Non-shipping product
releases must have implemented the feature(s) for a period of at least
one month in order to demonstrate stability.
- is not experimental (i.e., a version specifically designed to pass
the test suite and is not intended for normal usage going forward).
A minimum of sixth months of the CR period must have elapsed. This is to
ensure that enough time is given for any remaining major errors to be
caught.
Features will be dropped if two or more interoperable implementations
are not found by the end of the CR period.
Features may/will also be dropped if adequate/sufficient (by judgment of
CSS WG) tests have not been produced for those feature(s) by the end of
the CR period.
Appendix E — Acknowledgements
The editors would like to thank the members of the W3C Voice Browser and
Cascading Style Sheets working groups for their assistance in preparing
this new draft. Special thanks to Ellen Eide (IBM) for her detailed
comments.
Appendix F — Changes from previous draft
- Removed the "mark" property, see the Working
Group resolution
- Added the ‘
speakability’ property and removed the
‘none’ value of the ‘speak’ property, as
per this discussion
- Fixed ‘
voice-family’ grammar as per this
discussion
- The volume level of audio cues can only be set relatively to the
inherited ‘
voice-volume’ property (to avoid cues
being spoken when the main element is silent, which contradicts the
"aural box model").
- Added "HTML" to "CSS defines aural properties that give control over
rendering XML to speech" in the abstract.
- Removed unused normative links to CSS3 Modules (actually moved to
informative references), now the only dependency is CSS3 Values and
Units.
- Removed issue about the ‘
sub’
SSML element given that the CSS "content" replacement functionality
addresses the same requirement.
- Added support for semitones in pitch alterations.
- Added reference to "time" values syntax (s, ms) for ‘
voice-duration’.
- Moved "content" outside of "phonetics", as the ::before and ::after
use-cases do not relate to pronunciation rules (this is actually more
similar to audio cues, only applied with text rather than audio files)
- Added prose to explicitly support alphabet other than IPA, via the
"x-" vendor-specific prefix.
- Reworked HTML source code to work with the members-only W3C
pre-processor/generator
- Added note about the "speech" and "aural" media types.
- Harmonized all hyperlinks so that CSS properties get auto-linked by
the pre-processor
- Clarified computation rules for positive percentages with "+" prefixes
(i.e. they do not denote increments, the regular multiplicative behavior
is used).
- Fixed IPA URL reference
- Reorganized appendixes
- Fixed minor typos
Appendix G — References
Normative references
-
- [CSS3BOX]
- Bert Bos. CSS basic box
model. 9 August 2007. W3C Working Draft. (Work in progress.)
URL: http://www.w3.org/TR/2007/WD-css3-box-20070809
- [CSS3VAL]
- Håkon Wium Lie; Chris Lilley. CSS3
Values and Units. 19 September 2006. W3C Working Draft. (Work
in progress.) URL: http://www.w3.org/TR/2006/WD-css3-values-20060919
- [RFC2119]
- S. Bradner. Key
words for use in RFCs to Indicate Requirement Levels. Internet
RFC 2119. URL: http://www.ietf.org/rfc/rfc2119.txt
- [SPEECH-SYNTHESIS]
- Daniel C. Burnett; Mark R. Walker; Andrew Hunt. Speech
Synthesis Markup Language (SSML) Version 1.0. 7 September
2004. W3C Recommendation. URL: http://www.w3.org/TR/2004/REC-speech-synthesis-20040907/
- [XML10]
- C. M. Sperberg-McQueen; et al. Extensible
Markup Language (XML) 1.0 (Fifth Edition). 26 November 2008.
W3C Recommendation. URL: http://www.w3.org/TR/2008/REC-xml-20081126/
- [XML11]
- Eve Maler; et al. Extensible
Markup Language (XML) 1.1 (Second Edition). 16 August 2006.
W3C Recommendation. URL: http://www.w3.org/TR/2006/REC-xml11-20060816
- [IPA]
- International Phonetic
Association
Other references
-
- [CSS21]
- Bert Bos; et al. Cascading Style
Sheets Level 2 Revision 1 (CSS 2.1) Specification. 23
April 2009. W3C Candidate Recommendation. (Work in progress.) URL: http://www.w3.org/TR/2009/CR-CSS2-20090423
- [CSS3CASCADE]
- Håkon Wium Lie. CSS3
module: Cascading and inheritance. 15 December 2005. W3C
Working Draft. (Work in progress.) URL: http://www.w3.org/TR/2005/WD-css3-cascade-20051215
- [CSS3GENCON]
- Ian Hickson. CSS3
Generated and Replaced Content Module. 14 May 2003. W3C
Working Draft. (Work in progress.) URL: http://www.w3.org/TR/2003/WD-css3-content-20030514
- [CSS3SYN]
- L. David Baron. CSS3
module: Syntax. 13 August 2003. W3C Working Draft. (Work in
progress.) URL: http://www.w3.org/TR/2003/WD-css3-syntax-20030813