Abstract
RDFa
[
RDFA-CORE
]
enables
authors
to
publish
structured
information
that
is
both
human-
and
machine-readable.
Concepts
that
have
traditionally
been
difficult
for
machines
to
detect,
like
people,
places,
events,
music,
movies,
and
recipes,
are
now
easily
marked
up
in
Web
documents.
While
publishing
this
data
is
vital
to
the
growth
of
Linked
Data
,
using
the
information
to
improve
the
collective
utility
of
the
Web
for
humankind
is
the
true
goal.
To
accomplish
this
goal,
it
must
be
simple
for
Web
developers
to
extract
and
utilize
structured
information
from
a
Web
document.
This
document
details
such
a
mechanism;
an
RDFa
Document
Object
Model
Application
Programming
Interface
(RDFa
DOM
API)
that
allows
simple
extraction
and
usage
of
structured
information
from
a
Web
document.
Status
of
This
Document
This
section
describes
the
status
of
this
document
at
the
time
of
its
publication.
Other
documents
may
supersede
this
document.
A
list
of
current
W3C
publications
and
the
latest
revision
of
this
technical
report
can
be
found
in
the
W3C
technical
reports
index
at
http://www.w3.org/TR/.
The
following
changes
have
been
made
since
the
First
Public
Working
Draft:
-
Editorial
changes
that
renamed
this
document
to
'RDFa
API'
from
'RDFa
DOM
API'.
-
Updated
hasFeature
mechanism
per
RDFa
WG
telecon
discussion
.
-
Updated
convertType
mechanism
per
RDFa
WG
telecon
discussion
.
-
Removed
'type'
from
DataParser
interface
per
RDFa
telecon
discussion
.
-
Removed
'info'
attribute
from
IRI,
PlainLiteral,
TypedLiteral
and
RDFTriple.
'info'
attribute
only
exists
on
PropertyGroup
now.
-
Several
WebIDL
fixes
related
to
ISSUE-33
.
-
Lots
of
editorial
updates
related
to
Nathan's
feedback
.
-
Lots
of
examples
updates
-
changed
Javascript
console-based
examples
as
they
were
confusing
for
a
variety
of
different
reasons.
This
includes
almost
50%
of
the
example
code
we
had,
some
of
which
was
completely
wrong
because
the
API
has
changed
over
the
last
several
months.
Updated
to
use
comments
to
describe
what
each
statement
does,
added
colorized
comments
to
distinguish
code
more
clearly.
-
Added
type
parameter
to
createQuery
-
we
had
an
example
that
specified
a
type,
but
the
interface
definition
was
missing
the
type
parameter.
Without
this
parameter,
one
wouldn't
be
able
to
create
implementations
that
supported
things
like
SPARQL
queries.
-
Added
the
DataStoreIterator
callback
interface
as
we
had
forgotten
to
formally
define
what
the
callback
interface
looks
like
in
WebIDL.
-
Fixed
bug
in
the
getItemsBySubject
call
-
we
were
returning
a
PropertyGroupList.
That
didn't
make
any
sense
-
you
can
only
have
one
PropertyGroup
associated
with
a
subject
since
there
is
a
1-to-1
mapping
between
subjects
and
PropertyGroups.
We
also
shouldn't
have
a
getItemsBySubject
call
-
it's
getItemBySubject
-
note
the
missing
's'
in
Item.
-
Fixed
two
CSS
layout
bugs
in
ReSpec
CSS
file
used
by
RDFa
API
spec.
-
Many
updates
based
on
Ivan
Hermans
RDFa
API
review
and
feedback.
This
document
was
published
by
the
RDFa
Working
Group
as
a
First
Public
Working
Draft.
This
document
is
intended
to
become
a
W3C
Recommendation.
If
you
wish
to
make
comments
regarding
this
document,
please
send
them
to
public-rdfa-wg@w3.org
(
subscribe
,
archives
).
All
feedback
is
welcome.
Publication
as
a
Working
Draft
does
not
imply
endorsement
by
the
W3C
Membership.
This
is
a
draft
document
and
may
be
updated,
replaced
or
obsoleted
by
other
documents
at
any
time.
It
is
inappropriate
to
cite
this
document
as
other
than
work
in
progress.
This
document
was
produced
by
a
group
operating
under
the
5
February
2004
W3C
Patent
Policy
.
W3C
maintains
a
public
list
of
any
patent
disclosures
made
in
connection
with
the
deliverables
of
the
group;
that
page
also
includes
instructions
for
disclosing
a
patent.
An
individual
who
has
actual
knowledge
of
a
patent
which
the
individual
believes
contains
Essential
Claim(s)
must
disclose
the
information
in
accordance
with
section
6
of
the
W3C
Patent
Policy
.
1.
Introduction
This
section
is
non-normative.
RDFa
provides
a
means
to
attach
properties
to
elements
in
XML
and
HTML
documents.
Since
the
purpose
of
these
additional
properties
is
to
provide
information
about
real-world
items,
such
as
people,
films,
companies,
events,
and
so
on,
properties
are
grouped
into
objects
called
Property
Groups.
PropertyGroup
s.
The
RDFa
DOM
API
provides
a
set
of
interfaces
that
make
it
easy
to
manipulate
DOM
objects
that
contain
information
that
is
also
part
of
a
Property
Group.
PropertyGroup
.
This
specification
defines
these
interfaces.
A
document
that
contains
RDFa
effectively
provides
two
data
layers.
The
first
layer
is
the
information
about
the
document
itself,
such
as
the
relationship
between
the
elements,
the
value
of
its
attributes,
the
origin
of
the
document,
and
so
on,
and
this
information
is
usually
provided
by
the
Document
Object
Model,
or
DOM
[
DOM-LEVEL-1
].
The
second
data
layer
comprises
information
provided
by
embedded
metadata,
such
as
company
names,
film
titles,
ratings,
and
so
on,
and
this
is
usually
provided
by
RDFa
[
RDFA-CORE
],
Microformats
[
MICROFORMATS
],
DC-HTML,
GRDDL,
or
Microdata.
Whilst
this
embedded
information
could
be
accessed
via
the
usual
DOM
interfaces
--
for
example,
by
iterating
through
child
elements
and
checking
attribute
values
--
the
potentially
complex
interrelationships
between
the
data
mean
that
it
is
more
efficient
for
developers
if
they
have
access
to
the
data
after
it
has
been
interpreted.
For
example,
a
document
may
contain
the
name
of
a
person
in
one
section
and
the
phone
number
of
the
same
person
in
another;
whilst
the
basic
DOM
interfaces
provide
access
to
these
two
pieces
of
information
through
normal
navigation,
it
is
more
convenient
for
authors
to
have
these
two
pieces
of
information
available
in
one
property
collection,
reflecting
the
final
Property
Group.
PropertyGroup
.
All
of
this
is
achieved
through
the
RDFa
DOM
API.
There
are
many
scenarios
in
which
the
RDFa
DOM
API
can
be
used
to
extract
information
from
a
Web
document.
The
following
sections
describe
a
few
of
these
scenarios.
1.1
Importing
Data
Amy
has
enriched
her
band's
web-site
to
include
Google
Rich
Snippets
event
information.
Google
Rich
Snippets
are
used
to
mark
up
information
for
the
search
engine
to
use
when
displaying
enhanced
search
results.
Amy
also
uses
some
JavaScript
ECMAScript
code
that
she
found
on
the
web
that
automatically
extracts
the
event
information
from
a
page
and
adds
an
entry
into
a
personal
calendar.
Brian
finds
Amy's
web-site
through
Google
and
opens
the
band's
page.
He
decides
that
he
wants
to
go
to
the
next
concert.
Brian
is
able
to
add
the
details
to
his
calendar
by
clicking
on
the
link
that
is
automatically
generated
by
the
Javascript
ECMAScript
tool.
The
Javascript
ECMAScript
extracts
the
RDFa
from
the
web
page
and
places
the
event
into
Brian's
personal
calendaring
software
-
Google
Calendar.
<div prefix="v: http://rdf.data-vocabulary.org/#" typeof="v:Event">
<div prefix="v: http://rdf.data-vocabulary.org/#" typeof="v:Event">
<a rel="v:url" href="http://amyandtheredfoxies.example.com/events"
property="v:summary">Tour Info: Amy And The Red Foxies</a>
<span rel="v:location">
<a typeof="v:Organization" rel="v:url" href="http://www.kammgarn.de/" property="v:name">Kammgarn</a>
</span>
<div rel="v:photo"><img src="foxies.jpg"/></div>
<span property="v:description">Hey K-Town, Amy And The Red Foxies will rock Kammgarn in October.</span>
<span property="v:summary">Hey K-Town, Amy And The Red Foxies will rock Kammgarn in October.</span>
When:
<span property="v:startDate" content="2009-10-15T19:00">15. Oct., 7:00 pm</span>-
<span property="v:endDate" content="2009-10-15T21:00">9:00 pm</span>
</span>
Category: <span property="v:eventType">concert</span>
</div>
1.2
Enhanced
Browser
Interfaces
Dave
is
writing
a
browser
plugin
that
filters
product
offers
in
a
web
page
and
displays
an
icon
to
buy
the
product
or
save
it
to
a
public
wishlist.
The
plugin
searches
for
any
mention
of
product
names,
thumbnails,
and
offered
prices.
The
information
is
listed
in
the
URL
bar
as
an
icon,
and
upon
clicking
the
icon,
displayed
in
a
sidebar
in
the
browser.
He
can
then
add
each
item
to
a
list
that
is
managed
by
the
browser
plugin
and
published
on
a
wishlist
website.
<div prefix="rdfs: http://www.w3.org/2000/01/rdf-schema#
<div prefix="rdfs: http://www.w3.org/2000/01/rdf-schema#
foaf: http://xmlns.com/foaf/0.1/
gr: http://purl.org/goodrelations/v1#
xsd: http://www.w3.org/2001/XMLSchema#">
xsd: http://www.w3.org/2001/XMLSchema#" xml:lang="en">
<div about="#offering" typeof="gr:Offering">
<div property="rdfs:label" content="Harry Potter and the Deathly Hallows" xml:lang="en"></div>
<div property="rdfs:comment" content="In this final, seventh installment of the Harry Potter series, J.K. Rowling
<div rel="foaf:page" resource="http://www.amazon.com/Harry-Potter-Deathly-Hallows-Book/dp/0545139708"></div>
<div property="rdfs:label">Harry Potter and the Deathly Hallows</div>
<div property="rdfs:comment">In this final, seventh installment of the Harry Potter series, J.K. Rowling
unveils in spectactular fashion the answers to the many questions that have been so eagerly
awaited. The spellbinding, richly woven narrative, which plunges, twists and turns at a
breathtaking pace, confirms the author as a mistress of storytelling, whose books will be read,
reread and read again." xml:lang="en"></div>
<div rel="foaf:depiction" resource="http://ecx.images-amazon.com/images/I/51ynI7I-qnL._SL500_AA300_.jpg"></div>
reread and read again.</div>
<div rel="foaf:depiction">
<img src="http://ecx.images-amazon.com/images/I/51ynI7I-qnL._SL500_AA300_.jpg" />
</div>
<div rel="gr:hasBusinessFunction" resource="http://purl.org/goodrelations/v1#Sell"></div>
<div rel="gr:hasPriceSpecification">
<div typeof="gr:UnitPriceSpecification">
<div property="gr:hasCurrency" content="USD" datatype="xsd:string"></div>
<div property="gr:hasCurrencyValue" content="7.49" datatype="xsd:float"></div>
</div>
<div rel="gr:hasPriceSpecification">Buy for
<span typeof="gr:UnitPriceSpecification">
<span property="gr:hasCurrency" content="USD" datatype="xsd:string">$</span>
<span property="gr:hasCurrencyValue" datatype="xsd:float">7.49</span>
</span>
</div> Pay via:
<span rel="gr:acceptedPaymentMethods" resource="http://purl.org/goodrelations/v1#PayPal">PayPal</span>
<span rel="gr:acceptedPaymentMethods" resource="http://purl.org/goodrelations/v1#MasterCard">MasterCard</span>
</div>
<div rel="gr:acceptedPaymentMethods" resource="http://purl.org/goodrelations/v1#PayPal"></div>
<div rel="gr:acceptedPaymentMethods" resource="http://purl.org/goodrelations/v1#MasterCard"></div>
<div rel="foaf:page" resource="http://www.amazon.com/Harry-Potter-Deathly-Hallows-Book/dp/0545139708"></div>
</div>
</div>
1.3
Data-based
Web
Page
Modification
Dale
has
a
site
that
contains
a
number
of
images,
showcasing
his
photography.
He
has
already
used
RDFa
to
add
licensing
information
about
the
images
to
his
pages,
following
the
instructions
provided
by
Creative
Commons.
Dale
would
like
to
display
the
correct
Creative
Commons
icons
for
each
image
so
that
people
will
be
able
to
quickly
determine
which
licenses
apply
to
each
image.
<div prefix="cc: http://creativecommons.org/ns#">
<div prefix="cc: http://creativecommons.org/ns#">
<img src="http://dale.example.com/images/image1.png"
rel="cc:license"
resource="http://creativecommons.org/licenses/by/3.0/us/"/>
<a
href="http://dale.example.com" property="cc:attributionName"
<a href="http://dale.example.com" property="cc:attributionName"
rel="cc:attributionURL">Dale</a>
</div>
1.4
Automatic
Summaries
Mary
is
responsible
for
keeping
the
projects
section
of
her
company's
home
page
up-to-date.
She
wants
to
display
info-boxes
that
summarize
details
about
the
members
associated
with
each
project.
The
information
should
appear
when
hovering
the
mouse
over
the
link
to
each
member's
homepage.
Since
each
member's
homepage
is
annotated
with
RDFa,
Mary
writes
a
script
that
requests
the
page's
content
and
extracts
necessary
information
via
the
RDFa
DOM
API.
<div prefix="dc: http://purl.org/dc/terms/ foaf: http://xmlns.com/foaf/0.1/" >
<span about="#me" property="foaf:name" content="Bob">My<span> interests are:
<ol about="#me" typeof="foaf:Person">
<li rel="foaf:interests"><a href="facebook" rel="tag" property="dc:title">facebook</a></li>
<li rel="foaf:interests"><a href="opengraph" rel="tag" property="dc:title">opengraph</a></li>
<li rel="foaf:interests"><a href="semanticweb" rel="tag" property="dc:title">semanticweb</a></li>
<div prefix="dc: http://purl.org/dc/terms/ foaf: http://xmlns.com/foaf/0.1/">
<div about="#me" property="foaf:name" content="Bob">My<span> interests are:
<ol about="#me" typeof="foaf:Person">
<li rel="foaf:interests">
<a href="facebook" rel="tag" property="dc:title">facebook</a>
</li>
<li rel="foaf:interests">
<a href="opengraph" rel="tag" property="dc:title">opengraph</a>
</li>
<li rel="foaf:interests">
<a href="semanticweb" rel="tag" property="dc:title">semanticweb</a>
</li>
</ol>
<p>
Please follow me on
<span about="#me" rel="foaf:account">
<a href="http://twitter.com/bob" typeof="foaf:term_OnlineAccount" property="foaf:accountName">http://twitter.com/bob</a>.
<p>Please follow me on Twitter:
<span about="#me" rel="foaf:account">
@<a typeof="foaf:OnlineAccount" property="foaf:accountName"
href="http://twitter.com/bob">bob</a>.
</span>
</p>
</div>
1.5
Data
Visualization
Richard
has
created
a
site
that
lists
his
favourite
restaurants
and
their
locations.
He
doesn't
want
to
generate
code
specific
to
the
various
mapping
services
on
the
Web.
Instead
of
creating
specific
markup
for
Yahoo
Maps,
Google
Maps,
MapQuest,
and
Google
Earth,
he
instead
adds
address
information
via
RDFa
to
each
restaurant
entry.
This
enables
him
to
build
on
top
of
the
structured
data
in
the
page
as
well
as
letting
visitors
to
the
site
use
the
same
data
to
create
innovative
new
applications
based
on
the
address
information
in
the
page.
<div prefix="vc: http://www.w3.org/2006/vcard/ns# foaf: http://xmlns.com/foaf/0.1/" typeof="vc:VCard">
<span property="vc:fn">Wong Kei</span>
<span property="vc:street-address">41-43 Wardour Street</span>
<span>
<span property="vc:locality">London</span>, <span property="vc:country-name">United Kingdom</span>
</span>
<span property="vc:tel">020 74373071</span>
<div prefix="vc: http://www.w3.org/2006/vcard/ns# foaf: http://xmlns.com/foaf/0.1/" typeof="vc:VCard">
<span property="vc:fn">Wong Kei</span>
<span property="vc:street-address">41-43 Wardour Street</span>
<span property="vc:locality">London</span>, <span property="vc:country-name">United Kingdom</span>
<span property="vc:tel">020 74373071</span>
</div>
1.6
Linked
Data
Mashups
Marie
is
a
chemist,
researching
the
effects
of
ethanol
on
the
spatial
orientation
of
animals.
She
writes
about
her
research
on
her
blog
and
often
makes
references
to
chemical
compounds.
She
would
like
any
reference
to
these
compounds
to
automatically
have
a
picture
of
the
compound's
structure
shown
as
a
tooltip,
and
a
link
to
the
compound's
entry
on
the
National
Center
for
Biotechnology
Information
[NCBI]
Web
site.
Similarly,
she
would
like
visitors
to
be
able
to
visualize
the
chemical
compound
in
the
page
using
a
new
HTML5
canvas
widget
she
has
found
on
the
web
that
combines
data
from
different
chemistry
websites.
<div prefix="dbp: http://dbpedia.org/ontology/ fb: http://rdf.freebase.com/rdf/" >
<div prefix="dbp: http://dbpedia.org/ontology/ fb: http://rdf.freebase.com/rdf/" >
My latest study about the effects of
<span about="[fb:en.ethanol]"
typeof="[dbp:ChemicalCompound]"
property="[fb:chemistry.chemical_compound.pubchem_id]"
content="702">ethanol</span> on mice's spatial orientation show that ...
</div>
2.
Design
Considerations
This
section
is
non-normative.
RDFa
1.0
[
RDFA-SYNTAX
]
has
seen
substantial
growth
since
it
became
an
official
W3C
Recommendation
in
October
2008.
It
has
seen
wide
adoption
among
search
companies,
e-commerce
sites,
governments,
and
content
management
systems.
There
are
numerous
interoperable
implementations
and
growth
is
expected
to
continue
to
rise
with
the
latest
releases
of
RDFa
1.1
[
RDFA-CORE
],
XHTML+RDFa
1.1
[
XHTML-RDFA
],
and
HTML+RDFa
1.1
[
HTML-RDFA
].
In
an
effort
to
ensure
that
Web
applications
are
able
to
fully
utilize
RDFa,
this
specification
outlines
an
API
and
a
set
of
interfaces
that
extract
RDF
Triples
from
Web
documents
or
other
document
formats
that
utilize
RDFa.
The
RDFa
DOM
API
is
designed
with
maximum
code
expressiveness
and
ease
of
use
in
mind.
Furthermore,
a
deep
understanding
of
RDF
and
RDFa
is
not
necessary
in
order
to
extract
and
utilize
the
structured
data
embedded
in
RDFa
documents.
Since
there
are
many
Web
browsers
and
programming
environments
for
the
Web,
the
rapid
adoption
of
RDFa
requires
an
interoperable
API
that
Web
document
designers
can
count
on
being
available
in
all
Web
browsers.
The
RDFa
DOM
API
provides
a
uniform
and
developer-friendly
interface
for
extracting
RDFa
from
Web
documents.
Since
most
browser-based
applications
and
browser
extensions
that
utilize
Web
documents
are
written
in
JavaScript
ECMAScript
[
ECMA-262
],
the
implementation
of
the
RDFa
DOM
API
is
primarily
concerned
with
ensuring
that
concepts
covered
in
this
document
are
easily
utilized
in
JavaScript.
ECMAScript.
While
JavaScript
ECMAScript
is
of
primary
concern,
the
RDFa
DOM
API
specification
is
language
independent
and
is
designed
such
that
DOM
tool
developers
may
implement
it
in
many
of
the
other
common
Web
programming
languages
such
as
Python,
Java,
Perl,
and
Ruby.
Objects
that
are
defined
by
the
RDFA
DOM
API
are
designed
to
work
as
seamlessly
as
possible
with
language-native
types,
operators,
and
program
flow
constructs.
2.1
Goals
The
design
goals
that
drove
the
creation
of
the
APIs
that
are
described
in
this
document
are:
-
Ease
of
Use
and
Expressiveness
-
While
this
should
be
a
design
goal
for
all
APIs,
special
care
is
taken
to
ensure
that
developers
can
accomplish
common
tasks
using
a
minimal
amount
of
code.
While
execution
speed
is
always
an
important
factor
to
consider,
it
is
secondary
to
minimizing
the
amount
of
work
a
developer
must
perform
to
extract
and
use
data
contained
in
the
document.
-
Modularity
and
Pluggability
-
Each
part
of
the
API
is
modular
and
pluggable,
meaning
that
data
storage,
parsers
and
query
modules
may
be
replaced
by
other
developer-defined
mechanisms
as
long
as
the
interfaces
listed
in
this
document
are
supported.
-
DOM
Orthogonality
-
Interfaces
defined
on
the
Document
should
match
programming
paradigms
that
are
familiar
to
developers.
For
example,
if
one
were
to
attempt
to
retrieve
Element
Nodes
by
Subject,
the
name
of
the
method
should
be
document.getElementsBySubject()
,
which
mirrors
the
document.getElementsById()
functionality
that
is
a
part
of
[
DOM-LEVEL-1
].
-
Support
for
Non-RDFa
Parsers
-
Other
languages
that
store
data
in
the
DOM
are
considered
as
first-class
languages
when
it
comes
to
extraction
and
support
via
the
RDFa
DOM
API.
Mechanisms
like
DC-HTML,
eRDF,
Microformats,
and
Microdata
can
be
used
to
express
structured
data
in
DOM-based
languages.
It
is
a
goal
of
this
DOM
API
to
ensure
that
information
expressed
in
these
languages
can
be
extracted,
using
a
developer-defined
parser,
and
stored
in
the
Data
Store.
-
Low-level
Access
and
the
Freedom
to
Tinker
-
Providing
an
abstract
API,
while
simpler,
may
not
produce
the
kind
of
innovation
that
the
semantics
community
would
like
to
see.
It
is
important
to
give
developers
access
to
the
entire
RDFa
DOM
API
stack
in
order
to
ensure
that
each
layer
of
the
stack
can
be
improved
independently
of
a
standards
body.
-
A
Modular
RDF
API
-
The
RDFa
Working
Group
understood
that
in
order
to
provide
an
RDFa
API
that
an
RDF
API
would
have
to
be
created.
This
specification
details
a
low-level
RDF
API
as
well
as
a
higher-level
RDFa
API.
While
it
is
not
certain
how
many
developers
would
require
a
stand-alone
RDF
API,
the
hope
is
that
those
that
require
one
will
be
able
to
re-use
the
RDF
API
defined
in
this
specification.
This
specification
is
an
attempt
to
unify
RDF
APIs
much
like
POSIX
unified
the
mechanisms
used
to
access
operating
system
services
across
all
vendors.
-
Native
Language
Constructs
-
Data
is
exposed
and
processed
in
a
way
that
is
natural
for
Javascript
ECMAScript
and
many
other
Web
programming
languages
like
Python,
Ruby
and
even
C++.
For
example,
Property
Groups
can
be
exposed
as
native
objects
or
dynamically
accessible,
associative
arrays.
Data
Stores
can
be
iterated
over
by
providing
an
anonymous
function
or
function
pointer.
By
ensuring
that
programming
language
constructs
are
considered
in
the
design
of
the
API,
we
ensure
that
the
API
won't
fight
the
language
and
thus,
the
developer.
-
Macros
and
Templates
-
Some
of
the
mechanisms
that
underpin
RDF
are
difficult
to
use
in
everyday
programming.
For
example,
having
to
type
out
an
entire
URI
is
not
only
laborious
for
a
programmer,
but
also
error
prone
and
overly-verbose.
RDFa
Core
[
RDFA-CORE
]
introduces
the
concept
of
a
Compact
URI
Expression,
or
CURIE.
This
API
builds
on
the
CURIE
concept
and
allows
IRIs
to
be
expressed
as
CURIEs.
The
API
should
also
provide
short-cuts
that
reduce
the
amount
of
code
that
has
to
be
repeated.
Property
Group
Templates
are
one
example
of
reducing
repetitive
code
writing
as
it
can
be
stored
in
a
single
variable
and
re-used
for
objects.
2.2
Concept
Diagram
The
following
diagram
describes
the
relationship
between
all
concepts
discussed
in
this
document.
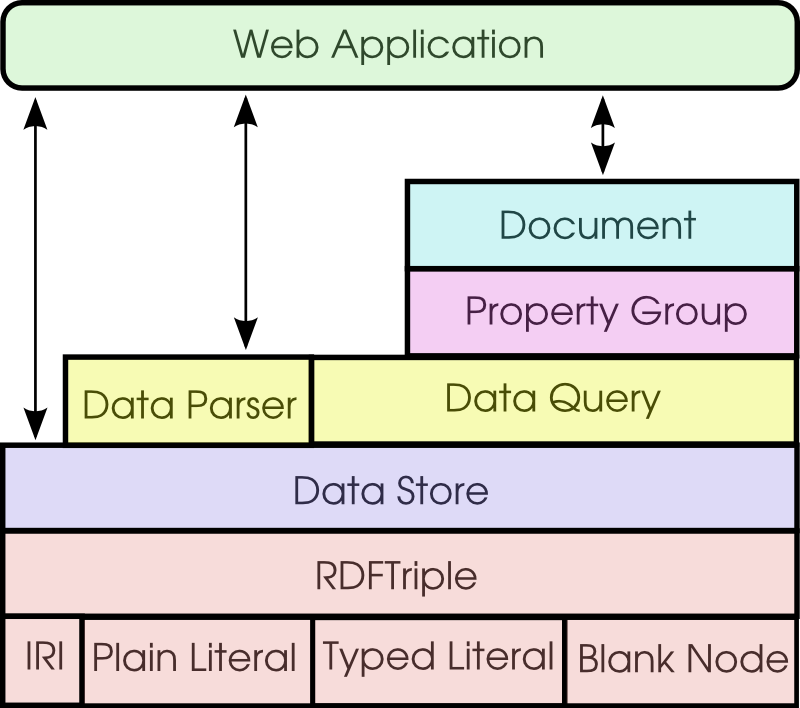
Diagram
of
RDFa
DOM
API
Concepts
The
lowest
layer
of
the
API
defines
the
basic
structures
that
are
used
to
store
information;
IRI,
Plain
Literal,
Typed
Literal,
Blank
Node
IRI
,
PlainLiteral
,
TypedLiteral
,
BlankNode
and
finally
the
RDF
Triple.
RDFTriple
.
The
next
layer
of
the
API,
the
Data
Store,
DataStore
,
supports
the
storage
of
information.
The
Data
Parser
DataParser
and
Data
Query
DataQuery
interfaces
directly
interact
with
the
Data
Store.
DataStore
.
The
Data
Parser
DataParser
is
used
to
extract
information
from
the
Document
and
store
the
result
in
a
Data
Store.
DataStore
.
The
Data
Query
DataQuery
interface
is
used
to
extract
different
views
of
data
from
the
Data
Store.
DataStore
.
The
Property
Group
PropertyGroup
is
an
abstract,
easily
manipulable
view
of
this
information
for
developers.
While
Property
Group
PropertyGroup
objects
can
address
most
use
cases,
a
developer
also
has
access
to
the
information
in
the
Data
Store
DataStore
at
a
basic
level.
Access
to
the
raw
data
allows
developers
to
create
new
views
and
ways
of
directly
manipulating
the
data
in
a
Data
Store.
DataStore
.
The
highest
layer
to
the
API
is
the
Document
object
and
is
what
most
web
developers
will
use
to
retrieve
Property
Groups
PropertyGroup
s
created
from
data
stored
in
the
document.
4.
The
Interfaces
Specification
The
following
section
contains
all
of
the
interfaces
that
developers
are
expected
to
implement.
implement
as
well
as
implementation
guidance.
4.2
The
RDF
Interfaces
RDFa
is
a
syntax
for
expressing
the
RDF
Data
Model
[
RDF-CONCEPTS
]
in
Web
documents.
The
RDFa
DOM
API
is
designed
to
extract
the
RDF
Data
Model
from
Web
documents.
The
following
RDF
Resources
are
utilized
in
this
specification:
Plain
Literals
,
Typed
Literals
,
PlainLiteral
s,
TypedLiteral
s,
IRI
References
(as
defined
in
[
IRI
])
and
Blank
Nodes
.
BlankNode
s.
The
interfaces
for
each
of
these
RDF
Resources
are
detailed
in
this
section.
The
types
as
exposed
by
the
RDFa
DOM
API
conform
to
the
same
data
and
comparison
restrictions
as
specified
in
the
RDF
concepts
specification
[
RDF-CONCEPTS
]
and
the
[
IRI
]
specification.
Each
RDF
interface
provides
access
to
both
the
extracted
RDFa
value
and
the
DOM
Node
from
which
the
value
was
extracted.
This
allows
developers
to
extract
and
use
RDF
triples
from
a
host
language
and
also
manipulate
the
DOM
based
on
the
associated
DOM
Node.
For
example,
an
agent
could
highlight
all
strings
that
are
marked
up
as
foaf:name
properties
in
a
Web
document.
The
basic
RDF
Resource
types
used
in
the
RDFa
DOM
API
are:
-
IRI
Reference
—
A
reference
to
a
resource
as
defined
in
International
Resource
Identifier
[
IRI
].
Example:
http://www.w3.org/2001/XMLSchema#string
.
-
Plain
Literal
PlainLiteral
—
A
string
value
with
optional
information
about
the
language
of
its
content.
Example:
"Harry
Potter
and
the
Half-Blood
Prince"@en
is
a
plain
literal
expressed
in
the
English
language.
-
Typed
Literal
—
A
typed
string
value
with
information
about
the
datatype
of
its
content.
Example:
"7"^^xsd:integer
is
a
typed
literal
with
a
value
of
type
xsd:integer
.
-
Blank
Node
—
A
blank
node
is
a
reference
to
a
resource
that
does
not
have
a
corresponding
IRI.
Examples
of
Blank
Nodes
BlankNode
s
include
_:me
,
and
_:42
.
-
RDF
Triple
—
Triples
are
the
basic
data
structure
utilized
by
RDF
to
express
logical
statements.
An
RDF
triple
is
a
3-item
ordered
set
consisting
of
a
subject
,
a
predicate
property
,
and
an
object
.
Example:
<http://example.org/hp>
rdfs:label
"Harry
Potter"
.
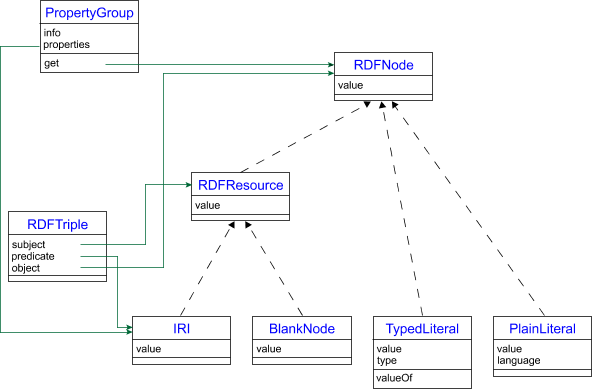
Diagram
of
RDF
Classes,
Attributes,
Methods
and
linkages.
An
RDFa
DOM
API
implementer
must
provide
the
basic
types
as
described
in
this
specification.
An
implementer
may
provide
additional
types
and/or
a
deeper
type
or
class
hierarchy
that
includes
these
basic
types.
4.1.1
4.2.1
IRI
References
RDFNode
and
RDFResource
An
IRI
Reference
in
RDFNode
is
an
anything
that
can
be
an
object
of
an
RDFTriple
.
It
is
also
the
RDFa
DOM
API
points
to
a
resource
base
class
of
PlainLiteral
,
and
is
further
defined
in
[
IRI
].
TypedLiteral
.
Constructor(in DOMString value),
Constructor(in DOMString value, in Node origin),
Stringifies=value]
interface {
[NoInterfaceObject]
interface RDFNode {
readonly attribute stringifier DOMString value;
};
Attributes
-
origin
value
of
type
Node
stringifier
DOMString
,
readonly
-
The
node
value
of
an
RDFNode
is
either
a
literal's
lexical
value
or
a
lexical
identifier
of
an
IRI
or
BlankNode
.
Note
that
specifies
the
IRI's
value
in
attribute
is
marked
with
a
stringifier
decorator.
In
[
WEBIDL
],
this
means
that
the
RDFa
markup.
value
is
used
as
the
return
value
if
toString()
is
called
on
an
object
that
inherits
from
this
type.
The
stringifier
can
be
overridden
by
the
re-specification
of
the
toString()
method
on
a
subclass
of
this
type.
No
exceptions.
An
RDFResource
is
an
anything
that
can
be
a
subject
of
an
RDFTriple
.
[NoInterfaceObject]
interface RDFResource : RDFNode {
readonly attribute stringifier DOMString value;
};
Attributes
-
value
of
type
stringifier
DOMString
,
readonly
-
The
lexical
representation
value
of
the
an
RDFResource
is
either
a
string
that
represents
an
IRI
reference.
or
an
identifier
of
a
BlankNode
.
No
exceptions.
4.2.2
IRI
References
An
IRI
Reference
in
the
RDFa
API
points
to
a
resource
and
is
further
defined
in
[
IRI
].
[NoInterfaceObject]
interface IRI : RDFResource {
};
4.1.2
4.2.3
RDF
Literals
An
RDF
Literal
is
an
RDF
Resource
that
represents
lexical
values
in
RDFa
data.
The
two
RDF
Literals
provided
via
the
RDFa
DOM
API
are
PlainLiterals
PlainLiteral
s
and
TypedLiterals.
TypedLiteral
s.
For
a
given
RDF
Literal
,
either
language
or
type
information
can
be
provided.
If
the
type
is
set,
the
RDF
Literal
is
a
Typed
Literal
.
If
a
type
is
not
set,
it
is
a
Plain
Literal
.
PlainLiteral
.
-
PlainLiteral
-
RDF
Literals
that
may
contain
language
information
about
the
given
text.
The
language
is
specified
as
a
text
string
as
specified
in
[
BCP47
]
(e.g.,
'en'
,
'fr'
,
'de'
).
-
TypedLiteral
-
RDF
Literals
that
contain
type
information
about
the
given
text.
The
type
is
always
specified
in
the
form
of
an
IRI
Reference
(e.g.,
http://www.w3.org/2001/XMLSchema#DateTime
).
Plain
Literals
PlainLiterals
PlainLiterals
PlainLiteral
s
have
a
string
value
and
may
specify
a
language.
The
RDFa
Working
Group
is
considering
whether
plain
literals
should
express
literal
values
as
UTF-8,
or
whether
the
encoding
of
the
source
document
should
be
used
instead.
This
section
assumes
that
the
encoding
from
the
source
document
should
be
used.
Constructor(in DOMString value),
Constructor(in DOMString value, in DOMString language),
Constructor(in DOMString value, in DOMString language, in Node origin),
Stringifies=value]
interface {
[NoInterfaceObject]
interface PlainLiteral : RDFNode {
readonly attribute stringifier DOMString value; readonly attribute DOMString language;
};
Attributes
-
language
of
type
DOMString
,
readonly
-
A
two
character
language
string
as
defined
in
[
BCP47
],
normalized
to
lowercase.
No
exceptions.
origin
of
type
Node
,
readonly
The
first
node
in
the
DOM
tree
that
is
associated
with
this
PlainLiteral.
No
exceptions.
-
value
of
type
stringifier
DOMString
,
readonly
-
The
lexical
value
of
the
literal
encoded
in
the
character
encoding
of
the
source
document.
The
value
is
extracted
from
an
RDFa
document
using
the
algorithm
defined
in
the
RDFa
Core
Specification
[
RDFA-CORE
],
Section
7.5:
Sequence
,
Step
11.
No
exceptions.
Typed
Literals
A
TypedLiteral
has
a
string
value
and
a
datatype
specified
as
an
IRI
Reference
.
TypedLiterals
TypedLiteral
s
can
be
converted
into
native
language
datatypes
of
the
implementing
programming
language
by
registering
a
Typed
Literal
Converter
as
defined
later
in
the
specification.
The
datatype's
IRI
reference
specifies
the
datatype
of
the
text
value,
e.g.,
xsd:DataTime
or
xsd:boolean
.
The
RDFa
DOM
API
provides
a
method
to
explicitly
convert
TypedLiteral
values
to
native
datatypes
supported
by
the
host
programming
language.
Developers
may
write
their
own
Typed
Literal
Converters
in
order
to
convert
an
RDFLiteral
into
a
native
language
type.
The
converters
are
registered
by
using
the
registerTypeConversion()
method.
Default
TypedLiteral
converters
must
be
supported
by
the
RDFa
DOM
API
implementation
for
the
following
XML
Schema
datatypes
:
-
xsd:string
-
xsd:boolean
-
xsd:float
-
xsd:double
-
xsd:boolean
-
xsd:integer
-
xsd:long
-
xsd:date
-
xsd:time
-
xsd:dateTime
Constructor(in DOMString value, in IRI type),
Constructor(in DOMString value, in IRI type, in Node origin),
Stringifies=value]
interface {
[NoInterfaceObject]
interface TypedLiteral : RDFNode {
readonly attribute stringifier DOMString value; readonly attribute IRI type; any valueOf ();
};
Attributes
origin
of
type
Node
,
readonly
The
first
node
in
the
DOM
tree
that
is
associated
with
this
TypedLiteral.
No
exceptions.
-
type
of
type
IRI
,
readonly
-
A
datatype
identified
by
an
IRI
reference
No
exceptions.
-
value
of
type
stringifier
DOMString
,
readonly
-
The
lexical
value
of
the
literal
encoded
in
the
character
encoding
of
the
source
document.
The
value
is
extracted
from
an
RDFa
document
using
the
algorithm
defined
in
the
RDFa
Core
Specification
[
RDFA-CORE
],
Section
7.5:
Sequence
,
Step
11.
No
exceptions.
Methods
-
valueOf
-
Returns
a
native
language
representation
of
this
literal.
The
type
conversion
should
be
performed
by
translating
the
value
of
the
literal
using
the
IRI
reference
of
the
datatype
to
the
closest
native
datatype
in
the
programming
language.
No
parameters.
No
exceptions.
4.1.3
4.2.4
Blank
Nodes
A
BlankNode
is
an
RDF
resource
that
does
not
have
a
corresponding
IRI
reference,
as
defined
in
[
RDF-CONCEPTS
].
The
value
of
a
BlankNode
is
not
required
to
be
the
same
for
identical
documents
that
are
parsed
at
different
times.
The
purpose
of
a
BlankNode
is
to
ensure
that
RDF
Resources
in
the
same
document
can
be
compared
for
equivalence
by
ID.
The
reasoning
behind
how
we
stringify
BlankNodes
BlankNode
s
should
be
explained
in
more
detail.
BlankNodes
BlankNode
s
are
stringified
by
concatenating
"_:"
to
BlankNode.value
BlankNode
.value
]
interface {
[NoInterfaceObject]
interface BlankNode : RDFResource {
readonly attribute stringifier DOMString value;
};
Attributes
-
value
of
type
stringifier
DOMString
,
readonly
-
The
temporary
identifier
of
the
BlankNode.
BlankNode
.
The
value
must
not
be
relied
upon
in
any
way
between
two
separate
RDFa
processing
runs
of
the
same
document.
No
exceptions.
Developers
and
authors
must
not
assume
that
the
value
of
a
Blank
Node
BlankNode
will
remain
the
same
between
two
processing
runs.
Blank
Node
BlankNode
values
are
only
valid
for
the
most
recent
processing
run
on
the
document.
Blank
Nodes
BlankNode
s
values
will
often
be
generated
differently
by
different
RDFa
Processors.
4.1.4
4.2.5
RDF
Triples
The
RDFTriple
interface
represents
an
RDF
triple
as
specified
in
[
RDF-CONCEPTS
].
RDFTriple
can
be
used
by
referring
to
properties,
such
as
subject
,
predicate
property
,
and
object
.
RDFTriple
can
also
be
used
by
referring
to
pre-defined
indexes.
The
stringification
of
RDFTriple
results
in
an
N-Triples-based
representation
as
defined
in
[
N3
RDF-TESTCASES
].
Constructor(in IRI subject, in IRI predicate, in IRI object),
Constructor(in IRI subject, in IRI predicate, in PlainLiteral object),
Constructor(in IRI subject, in IRI predicate, in TypedLiteral object),
Constructor(in IRI subject, in IRI predicate, in BlankNode object),
Constructor(in BlankNode subject, in IRI predicate, in IRI object),
Constructor(in BlankNode subject, in IRI predicate, in PlainLiteral object),
Constructor(in BlankNode subject, in IRI predicate, in TypedLiteral object),
Constructor(in BlankNode subject, in IRI predicate, in BlankNode object),
Stringifies, Null=Null]
[NoInterfaceObject, Null=Null]
interface RDFTriple {
const unsigned long size = 3;
readonly attribute RDFResource subject;
readonly attribute IRI property;
readonly attribute RDFNode object;
getter RDFNode get (in unsigned long index);
stringifier DOMString toString ();
};
Attributes
-
object
of
type
Object
RDFNode
,
readonly
-
The
object
associated
with
the
RDFTriple.
RDFTriple
.
No
exceptions.
-
predicate
property
of
type
Object
IRI
,
readonly
-
The
predicate
property
associated
with
the
RDFTriple.
RDFTriple
.
No
exceptions.
-
subject
of
type
Object
RDFResource
,
readonly
-
The
subject
associated
with
the
RDFTriple.
RDFTriple
.
No
exceptions.
Methods
get
-
An
index
method
to
access
subject,
predicate,
and
object
with
indices
from
zero
to
two,
respectively.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|---|
|
index
|
unsigned
long
|
✘
|
✘
| |
No
exceptions.
toString
-
Converts
this
triple
into
a
string
in
N-Triples
notation.
No
parameters.
No
exceptions.
4.2
4.3
The
Structured
Linked
Data
Interfaces
A
number
of
convenience
objects
and
methods
are
provided
by
the
RDFa
DOM
API
to
help
developers
manipulate
RDF
Resources
more
easily
when
writing
Web
applications.
The
basic
RDF
interface
types
described
earlier
in
this
document
are
utilized
by
the
following
Structured
Data
Interfaces:
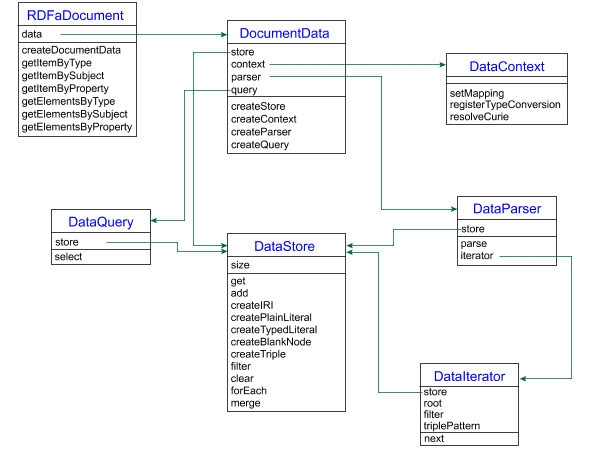
Diagram
of
Linked
Data
Classes,
Attributes,
Methods
and
linkages.
4.2.1
4.3.1
Data
Context
Processing
RDF
data
involves
the
frequent
use
of
unwieldy
IRI
references
and
frequent
type
conversion.
The
DataContext
interface
is
provided
in
order
to
simplify
contextual
operations
such
as
shortening
IRIs
and
converting
RDF
data
into
native
language
datatypes.
It
is
assumed
that
this
interface
is
created
and
available
before
a
document
is
parsed
for
RDFa
data.
For
example,
while
operating
within
a
Browser
Context,
it
is
assumed
that
the
following
lines
of
code
are
executed
before
a
developer
has
access
to
the
RDFa
DOM
API
methods
on
the
document
object:
document.data.context = new DataContext();
document.data.context = new DataContext();
document.data.context.setMapping("rdf", "http://www.w3.org/1999/02/22-rdf-syntax-ns#");
document.data.context.setMapping("xsd",
"http://www.w3.org/2001/XMLSchema-datatypes#");
In
general,
when
a
CURIE
is
resolved
by
the
RDFa
API
or
a
TypedLiteral
is
converted
to
a
native
language
type,
the
current
DataContext
stored
in
the
DocumentData
object
must
be
used
to
perform
the
action.
This
is
to
ensure
that
there
is
only
one
active
DataContext
in
use
by
the
RDFa
API
at
any
given
time.
The
default
DataContext
stored
in
the
DocumentData
object
may
be
changed
at
runtime.
All
of
the
code
that
sets
up
the
default
type
converters
for
Browser
Contexts
that
use
Javascript
ECMAScript
should
probably
be
in
the
code
snippet
above.
The
following
interface
allows
IRI
mappings
to
be
easily
created
and
used
by
Web
Developers
at
run-time.
It
also
allows
for
conversion
of
RDF
data
into
native
language
datatypes.
{
interface DataContext {
void setMapping (in DOMString prefix, in DOMString iri);
void registerTypeConversion (in DOMString iri, in TypedLiteralConverter converter);
IRI resolveCurie (in DOMString curie);
any convertType (in DOMString value, in optional DOMString inputType, in optional DOMString modifier);
};
Methods
-
convertType
-
Returns
the
native
language
value
of
the
passed
literal
value
as
a
language-native
type.
If
the
given
value
cannot
be
converted,
the
given
value
must
be
returned.
The
return
value
upon
conversion
failure
is
being
actively
discussed
in
the
RDFa
WG.
There
are
proposals
to
raise
exceptions
upon
conversion
failure,
proposals
to
return
tuples
containing
conversion
success/failure
and
the
converted
value,
as
well
as
other
mechanisms
that
would
allow
the
signalling
of
a
conversion
failure
from
the
method
to
calling
code.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|---|
|
value
|
DOMString
|
✘
|
✘
|
The
value
to
convert
that
is
associated
with
the
TypedLiteral
. |
|
inputType
|
DOMString
|
✘
|
✔
|
The
input
type
for
the
TypedLiteral
passed
as
a
string.
For
example,
xsd:string
or
xsd:integer
. |
|
modifier
|
DOMString
|
✘
|
✔
|
The
developer-supplied
modifier
for
the
conversion.
The
string
is
a
free-form,
string
that
is
used
by
the
TypedLiteralConverter
that
is
associated
with
the
inputType
.
The
RDFa
Working
Group
is
still
discussing
whether
or
not
having
a
modifier
is
a
good
idea
as
90%
of
use
cases
will
never
use
it
and
the
remaining
use
cases
could
provide
the
functionality
with
an
external
switch
to
the
conversion
function.
|
No
exceptions.
-
registerTypeConversion
-
Registers
a
type
converter
from
given
IRI
datatype
to
a
native
language
dataype
in
the
current
programming
language.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
iri
|
DOMString
|
✘
|
✘
|
A
string
specifying
the
IRI
datatype.
The
string
may
be
a
CURIE.
For
example:
http://www.w3.org/2001/XMLSchema-datatypes#integer
or
xsd:integer
.
|
|
converter
|
TypedLiteralConverter
|
✘
|
✘
|
A
function
that
converts
Converts
the
TypedLiteral's
TypedLiteral
's
value
into
a
native
language
datatype
in
the
current
programming
language.
|
No
exceptions.
-
resolveCurie
-
Resolves
a
given
CURIE.
If
successful,
returns
an
IRI
or
Null
if
the
CURIE
could
not
be
resolved.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|---|
|
curie
|
DOMString
|
✘
|
✘
|
The
CURIE
that
is
to
be
resolved
into
an
IRI.
|
No
exceptions.
-
setMapping
-
Registers
a
mapping
from
a
prefix
to
an
IRI
.
The
given
IRI
must
be
a
full
IRI.
For
example,
if
a
developer
wants
to
specify
the
foaf
IRI
mapping,
they
would
call
setMapping("foaf",
"http://xmlns.com/foaf/0.1/")
.
Calling
the
setMapping()
method
with
a
prefix
value
that
does
not
exist
results
in
the
creation
of
a
new
mapping.
Calling
the
method
with
a
null
IRI
value
will
remove
the
mapping.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
prefix
|
DOMString
|
✘
|
✘
|
The
prefix
to
put
into
the
mapping
as
the
key.
(e.g.,
foaf
)
|
|
iri
|
DOMString
|
✘
|
✘
|
The
IRI
reference
to
place
into
the
mapping
as
the
mapped
value
of
the
given
prefix.
(e.g.,
"http://xmlns.com/foaf/0.1/")
|
No
exceptions.
Easy
IRI
Mapping
All
methods
that
accept
CURIEs
as
arguments
in
the
RDFa
API
must
use
the
algorithm
specified
in
RDFa
Core,
Section
7.4:
CURIE
and
URI
Processing
[
RDFA-CORE
]
for
TERMorCURIEorURI
.
The
prefix
and
term
mappings
are
provided
by
the
current
document.data.context
instance.
The
following
examples
demonstrate
how
mappings
are
created
and
used
via
the
RDFa
API.
// Create a new mapping for the Friend-of-a-Friend vocabulary
document.data.context.setMapping("foaf", "http://xmlns.com/foaf/0.1/");
// The new mapping is automatically used when CURIEs are expanded to IRIs,// the following statement will return all the people in the document
var people = document.getItemsByType("foaf:Person");
// The following statement will result in the exact same list of PropertyGroups// as returned by the previous getItemsByType() call. Note that the only// difference is that this call uses a full IRI, while the call above uses a// CURIE
var
people2
=
document.getItemsByType("http://xmlns.com/foaf/0.1/Person");
In
the
example
above,
the
CURIE
"
foaf:Person
"
is
expanded
to
an
IRI
with
the
value
"
http://xmlns.com/foaf/0.1/Person
"
in
the
getItemsByType
method.
IRI
mappings
for
all
terms
in
the
following
vocabularies
must
be
included:
rdf
and
xsd
.
Automatic
Type
Conversion
TypedLiteralConverter
is
a
callable
interface
that
transforms
the
value
of
a
TypedLiteral
into
a
native
language
type
in
the
current
programming
language.
The
type
IRI
of
the
TypedLiteral
is
used
to
determine
the
best
mapping
to
the
native
language
type.
Specifing
Typed
Literal
Converters
]
A
TypedLiteralConverter
may
be
implemented
as
a
class,
or
as
a
language-native
callback
in
languages
like
ECMAScript.
[NoInterfaceObject Callback]
interface TypedLiteralConverter {
any convert (in DOMString value, in optional IRI inputType, in optional DOMString modifier);
};
Methods
-
convertType
convert
-
Returns
the
native
language
value
of
the
passed
literal
value
as
a
language-native
type.
If
the
given
value
cannot
be
converted,
the
given
value
must
be
returned.
The
return
value
upon
conversion
failure
is
being
actively
discussed
in
the
RDFa
WG.
There
are
proposals
to
raise
exceptions
upon
conversion
failure,
proposals
to
return
tuples
containing
conversion
success/failure
and
the
converted
value,
as
well
as
other
mechanisms
that
would
allow
the
signalling
of
a
conversion
failure
from
the
method
to
calling
code.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
value
|
DOMString
|
✘
|
✘
|
The
value
to
convert
that
is
associated
with
the
RDFTypedLiteral.
TypedLiteral
. |
|
inputType
|
IRI
|
✘
|
✔
|
The
input
type
for
the
TypedLiteral
passed
as
an
IRI
.
For
example,
http://www.w3.org/2001/XMLSchema#string
or
http://www.w3.org/2001/XMLSchema#integer
. |
|
modifier
|
DOMString
|
✘
|
✔
|
A
developer-specified
modifier
used
during
the
conversion.
The
string
is
a
free-form
string
that
is
used
by
the
developer-specified
convert()
method.
|
No
exceptions.
Examples
IRI
mappings
for
all
terms
in
the
The
following
vocabularies
must
be
included:
rdf
example
demonstrates
how
a
developer
could
register
and
xsd
.
Easy
IRI
Mapping
All
methods
that
accept
CURIEs
as
arguments
in
the
RDFa
DOM
API
must
use
the
algorithm
specified
in
RDFa
Core,
Section
7.4:
CURIE
and
URI
Processing
[
RDFA-CORE
]
for
TERMorCURIEorURI
.
The
prefix
and
term
mappings
are
provided
by
the
current
a
document.data.context
TypedLiteralConverter
instance.
.
Example
// Register a new type converter for the "xsd:boolean" type
document.data.context.registerTypeConversion("xsd:boolean", function(value) {return new Boolean(value);});
// Create a new TypedLiteral of type "xsd:boolean" with a string value of "1"
var literal = document.data.store.createTypedLiteral("1", "xsd:boolean");
This
section
// Convert the literal to a string
var lstr = literal.toString();
var lvalue = literal.value;
// At this point, lstr and lvalue will both be "1"// Get the language-native value of the literal
var lnvalue = literal.valueOf();
// At this point, the language-native value of the lnvalue variable will
//
be
a
Boolean
type
whose
value
is
non-normative.
'true'.
The
following
examples
demonstrate
example
demonstrates
how
mappings
are
created
to
create
and
used
via
the
RDFa
DOM
API.
// create new IRI mapping
document.data.context.setMapping("foaf", "http://xmlns.com/foaf/0.1/");
pass
a
// The new IRI mapping is automatically used when CURIEs are expanded to IRIs
var
people
=
document.getItemsByType("foaf:Person");
In
the
example
above,
the
CURIE
"
foaf:Person
"
is
expanded
to
an
IRI
with
the
value
"
http://xmlns.com/foaf/0.1/Person
TypedLiteralConverter
"
function
in
the
getItemsByType
method.
ECMAScript:
Example
var converter = function (value) { return new String(value) };
document.data.context.registerTypeConverter("xsd:string",
converter);
A
This
section
is
non-normative.
TypedLiteralConverter
The
following
example
demonstrates
how
a
developer
could
register
and
use
can
also
specify
a
TypedLiteralConverter.
target
type
for
the
converter
so
that
one
converter
can
be
used
for
multiple
types:
>> document.data.context.registerTypeConversion('xsd:boolean', function(value) {return new Boolean(value);});
>> var literal = document.data.store.createTypedLiteral('1', 'xsd:boolean');
>> print(literal.toString());
1
>> print(literal.value);
1
>> print(literal.valueOf());
true
var converter = function(value, inputType, modifier)
{
if(inputType == "http://www.w3.org/2001/XMLSchema#integer")
{
// if the input type is xsd:integer, convert to an ECMAScript integer
return parseInt(value);
}
else if(modifier == "caps")
{
// if the modifier is "caps" convert to a string and uppercase the // return value
return new String(value).toUpperCase();
}
else
{
// in all other cases, convert to a string
return new String(value);
}
};
// register the converter
document.data.context.registerTypeConverter("xsd:string", converter);
document.data.context.registerTypeConverter("xsd:integer", converter);
// Use the developer-defined TypedLiteralConverter to resolve the value to// a language-native type. In this example, airport codes are commonly// upper-cased values, so specify that the conversion should be capitalized.
var airportCode = document.data.context.convertType("wac", "xsd:string", "caps");
//
At
this
point,
the
value
of
airportCode
should
be
"WAC"
4.2.2
4.3.2
Data
Store
The
DataStore
is
a
set
of
RDFTriple
objects.
It
provides
a
basic
getter
as
well
as
an
indexed
getter
for
retrieving
individual
items
from
the
store.
The
Data
Store
DataStore
can
be
used
to
create
primitive
types
as
well
as
store
collections
of
them
in
the
form
of
RDFTriples.
RDFTriple
s.
The
forEach
method
is
not
properly
defined
in
WebIDL
-
need
to
get
input
from
the
WebApps
Working
Group
on
how
best
to
author
this
interface.
{
[NoInterfaceObject]
interface DataStore {
readonly attribute unsigned long size;
]
getter RDFTriple get (in unsigned long index);
boolean add (in RDFTriple triple);
IRI createIRI (in DOMString iri, in optional Node node);
PlainLiteral createPlainLiteral (in DOMString value, in optional DOMString? language);
TypedLiteral createTypedLiteral (in DOMString value, in DOMString type);
BlankNode createBlankNode (in optional DOMString name);
RDFTriple createTriple (in RDFResource subject, in IRI property, in RDFNode object);
[Null=Null]
DataStore filter (in optional Object? pattern, in optional Element? element, in optional RDFTripleFilter filter);
void clear ();
void forEach (in DataStoreIterator iterator);
boolean merge (in DataStore store);
};
Attributes
-
size
of
type
unsigned
long
,
readonly
-
A
non-negative
integer
that
specifies
the
size,
in
RDFTriples,
RDFTriple
s,
of
the
store.
No
exceptions.
Methods
-
add
-
Adds
an
RDFTriple
to
the
Data
Store.
DataStore
.
Returns
True
if
the
RDFTriple
was
added
to
the
store
successfully.
Adding
an
RDFTriple
that
already
exists
in
the
DataStore
must
return
True
and
must
not
store
two
duplicate
triples
in
the
DataStore
.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
triple
|
RDFTriple
|
✘
|
✘
|
The
triple
to
add
to
the
Data
Store.
DataStore
.
|
No
exceptions.
-
clear
-
Clears
all
data
from
the
store.
No
parameters.
No
exceptions.
-
createBlankNode
-
Creates
a
Blank
Node
BlankNode
given
an
optional
name
value.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
name
|
DOMString
|
✘
|
✔
|
The
name
of
the
Blank
Node,
BlankNode
,
which
will
be
used
when
Stringifying
the
Blank
Node.
BlankNode
.
|
No
exceptions.
-
createIRI
-
Creates
an
IRI
given
a
value
and
an
optional
Node.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
iri
|
DOMString
|
✘
|
✘
|
The
IRI
reference's
lexical
value.
|
|
node
|
Node
|
✘
|
✔
|
An
optional
DOM
Node
to
associate
with
the
IRI.
|
No
exceptions.
-
createPlainLiteral
-
Creates
a
Plain
Literal
PlainLiteral
given
a
value,
an
optional
language
value
and
an
optional
DOM
origin
Node.
language.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
value
|
DOMString
|
✘
|
✘
|
The
value
of
the
IRI.
The
value
can
be
either
a
full
IRI
or
PlainLiteral
,
which
is
usually
a
CURIE.
human-readable
string.
|
|
language
|
DOMString
|
✔
|
✔
|
The
language
that
is
associated
with
the
Plain
Literal
PlainLiteral
encoded
according
to
the
rules
outlined
in
[
BCP47
].
origin
Node
✘
✔
The
DOM
Node
that
should
be
associated
with
the
Plain
Literal
].
|
No
exceptions.
-
createTriple
-
Creates
an
RDF
Triple
RDFTriple
given
a
subject,
predicate
property
and
object.
If
any
incoming
value
does
not
match
the
requirements
listed
below,
a
Null
value
must
be
returned
by
this
method.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
subject
|
Object
RDFResource
|
✘
|
✘
|
The
subject
value
of
the
RDF
Triple.
RDFTriple
.
The
value
must
be
either
an
IRI
or
a
BlankNode.
BlankNode
.
|
predicate
property
|
Object
IRI
|
✘
|
✘
|
The
predicate
property
value
of
the
RDF
Triple.
RDFTriple
.
|
|
object
|
Object
RDFNode
|
✘
|
✘
|
The
object
value
of
the
RDF
Triple.
RDFTriple
.
The
value
must
be
an
IRI,
PlainLiteral,
TypedLiteral,
IRI
,
PlainLiteral
,
TypedLiteral
,
or
BlankNode.
BlankNode
.
|
No
exceptions.
-
createTypedLiteral
-
Creates
a
Typed
Literal
TypedLiteral
given
a
value,
a
type
value
and
an
optional
associated
DOM
Node.
a
type.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
value
|
DOMString
|
✘
|
✘
|
The
value
of
the
Typed
Literal.
TypedLiteral
.
|
|
type
|
DOMString
|
✘
|
✘
|
The
IRI
type
of
the
Typed
Literal.
TypedLiteral
.
The
argument
can
either
be
a
full
IRI
or
a
CURIE.
|
origin
Node
✘
✔
The
DOM
Node
to
associate
with
the
Typed
Literal.
No
exceptions.
-
filter
-
Returns
an
DataStore,
DataStore
,
which
consists
of
zero
or
more
RDFTriple
objects.
The
RDFa
Working
Group
is
debating
whether
the
return
value
of
the
filter
method
should
be
a
DataStore
or
a
Sequence
of
RDFTriple
s.
DataStores
allow
much
higher-level
functions
to
be
carried
out
versus
a
simple
Sequence
of
RDFTriple
s.
However,
DataStore
s
may
be
very
memory
intensive
to
construct
and
manage.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
subject
pattern
|
Object
|
✔
|
✘
✔
|
The
subject
A
filter
pattern
that
determines
which
triples
to
select
from
the
DataStore
.
The
filter
pattern
is
provided
to
make
it
easy
to
perform
complex
filtering
on
subject,
property
and
object
by
providing
a
very
flexible
data
container
to
convey
selection
information.
The
implementation
of
the
pattern
parameter
is
designed
to
be
easily
implemented
by
data
dictionaries
or
associative
arrays,
but
should
be
done
in
a
way
that
is
natural
to
the
implementation
language.
To
ensure
a
similar
programming
environment,
the
variables
to
convey
subject,
property
and
object
parameters
should
use
keys
or
variables
named
"subject",
"property"
and
"object",
respectively.
The
subject
parameter
is
used
to
filter
RDFTriple
objects.
Values
can
be
of
type
IRI,
BlankNode,
DOMString,
IRI
,
or
Null.
BlankNode
.
If
a
DOMString
is
supplied,
the
API
must
convert
the
value
into
an
IRI
or
BlankNode
before
comparison
is
performed.
If
the
subject
is
a
non-Null
value,
specified,
the
RDFTriple
must
not
be
placed
in
the
final
output
Array
unless
the
given
subject
matches
the
RDFTriple's
RDFTriple
's
subject.
If
a
subject
parameter
is
set
to
Null,
not
specified,
the
filter
function
must
not
reject
any
triple
based
on
the
subject.
predicate
subject
unless
specified
by
the
IRI
✔
✔
RDFTripleFilter
.
The
predicate
filter
pattern
which
property
parameter
is
used
to
filter
RDFTriple
objects.
Values
can
be
of
type
IRI
DOMString
or
Null.
IRI
.
If
a
DOMString
is
supplied,
the
predicate
API
must
convert
the
value
into
an
IRI
before
comparison
is
a
non-Null
value,
performed.
If
the
property
is
specified,
the
RDFTriple
must
not
be
placed
in
the
final
output
Array
unless
the
given
predicate
property
matches
the
RDFTriple's
predicate.
RDFTriple
's
property.
If
predicate
a
property
parameter
is
set
to
Null,
not
specified,
the
filter
function
must
not
reject
any
triple
based
on
the
predicate.
object
property
unless
specified
by
the
Object
✔
✔
RDFTripleFilter
.
The
object
filter
pattern
which
parameter
is
used
to
filter
RDFTriple
objects.
Values
can
be
of
type
IRI,
TypedLiteral,
PlainLiteral,
BlankNode,
DOMString,
BlankNode
,
PlainLiteral
,
TypedLiteral
or
Null.
IRI
.
If
a
DOMString
is
supplied,
the
API
must
convert
the
value
into
a
PlainLiteral
before
comparison
is
performed.
If
the
object
is
a
non-Null
value,
specified,
the
RDFTriple
must
not
be
placed
in
the
final
output
Array
unless
the
given
object
matches
the
RDFTriple's
RDFTriple
's
object.
If
an
object
parameter
is
set
to
Null,
not
specified,
the
filter
function
must
not
reject
any
triple
based
on
object.
the
object
unless
specified
by
the
RDFTripleFilter
.
|
|
element
|
Node
Element
|
✔
|
✔
|
The
parent
DOM
Node
Element
where
filtering
should
start.
The
implementation
must
only
consider
RDF
triples
on
the
current
DOM
Node
Element
and
its
children.
|
|
filter
|
RDFTripleFilter
|
✘
|
✔
|
A
user
defined
function,
returning
a
true
or
false
value,
that
determines
whether
or
not
an
RDFTriple
should
be
added
to
the
final
Array.
|
No
exceptions.
-
forEach
-
Calls
the
given
callback
for
each
item
in
the
Data
Store.
DataStore
.
While
the
forEach()
method
is
intended
to
provide
a
functional
mechanism
for
iterating
through
a
DataStore
,
it
has
been
questioned
whether
the
interface
would
be
useful
for
developers
since
there
is
already
a
procedural
array-index-based
iteration
mechanism
built
into
a
DataStore.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
callback
iterator
|
function
DataStoreIterator
|
✘
|
✘
|
A
function
that
takes
the
following
arguments:
index,
subject,
predicate,
property,
object.
The
function
is
called
for
each
item
in
the
Data
Store.
DataStore
.
|
No
exceptions.
-
get
-
Returns
the
RDFTriple
object
at
the
given
index
in
the
list.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
index
|
unsigned
long
|
✘
|
✘
|
The
index
of
the
RDFTriple
in
the
list
to
retrieve.
The
value
must
be
a
positive
integer
value
greater
than
or
equal
to
zero
and
less
than
DataStore::length.
DataStore
::length.
|
No
exceptions.
merge
-
Merges
all
triples
in
an
external
DataStore
into
this
DataStore
.
Duplicate
triples
must
not
be
inserted
into
the
same
data
store.
Returns
True
if
all
triples
were
merged
into
the
store
successfully.
No
exceptions.
The
DataStoreIterator
interface
is
used
by
the
forEach()
method
on
the
DataStore
when
processing
all
of
the
triples
in
a
DataStore
.
[NoInterfaceObject, Callback, Null=Null]
interface DataStoreIterator {
void process (in int index, in RDFResource subject, in IRI property, in RDFNode object);
};
Methods
process
-
A
callable
function
that
takes
an
array
index,
subject,
property,
and
object
as
arguments
and
processes
each
based
on
a
developer-supplied
algorithm.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|---|
|
index
|
int
|
✘
|
✘
|
The
offset
into
the
DataStore
that
contains
the
current
RDFTriple
being
processed.
|
|
subject
|
RDFResource
|
✘
|
✘
|
The
subject
of
the
RDFTriple
being
processed.
|
|
property
|
IRI
|
✘
|
✘
|
The
property
associated
with
the
RDFTriple
being
processed.
|
|
object
|
RDFNode
|
✘
|
✘
|
The
object
associated
with
the
RDFTriple
being
processed.
|
No
exceptions.
4.2.3
4.3.3
Data
Parser
The
Data
Parser
DataParser
is
capable
of
processing
a
DOM
Node
Element
and
placing
the
parsing
results
into
a
Data
Store.
DataStore
.
While
this
section
specifies
how
one
would
parse
RDFa
data
and
place
it
into
a
Data
Store,
DataStore
,
the
interface
is
also
intended
to
support
the
parsing
and
storage
of
various
Microformats,
eRDF,
GRDDL,
DC-HTML,
and
Microdata.
Web
developers
that
would
like
to
write
customer
parsers
may
should
extend
this
interface.
{
[NoInterfaceObject]
interface DataParser {
attribute DataStore store;
[Null=Null]
DataIterator iterate (in optional Object? pattern, in optional Element? element, in optional RDFTripleFilter filter);
boolean parse (in Element domElement);
};
Attributes
-
store
of
type
DataStore
-
The
DataStore
that
is
associated
with
the
DataParser.
DataParser
.
The
results
of
each
parsing
run
will
be
placed
into
the
store.
No
exceptions.
Methods
-
iterate
-
Returns
an
DataIterator,
DataIterator
,
which
is
capable
of
iterating
through
a
set
of
RDF
triples,
one
RDFTriple
at
a
time.
The
DataIterator
is
most
useful
in
small
memory
footprint
environments,
or
in
documents
that
contain
a
very
large
number
of
triples.
It
has
been
noted
that
having
an
stream-based
mechanism
of
processing
triples
via
the
iterate()
method,
and
a
process-and-store-based
mechanism
for
storing
triples
via
the
parse()
method
on
the
same
interface
is
confusing.
Each
mechanism
provides
an
alternate
way
of
processing
triples
in
a
document.
In
the
future,
iterate()
and
parse()
may
be
separated
out
into
two
distinct
interfaces.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
subject
pattern
|
Object
|
✔
|
✘
✔
|
The
subject
A
filter
pattern
that
determines
which
triples
to
select
from
the
DataStore
.
The
filter
pattern
is
provided
to
make
it
easy
to
perform
complex
filtering
on
subject,
property
and
object
by
providing
a
very
flexible
data
container
to
convey
selection
information.
The
implementation
of
the
pattern
parameter
is
designed
to
be
easily
implemented
by
data
dictionaries
or
associative
arrays,
but
should
be
done
in
a
way
that
is
natural
to
the
implementation
language.
To
ensure
a
similar
programming
environment,
the
variables
to
convey
subject,
property
and
object
parameters
should
use
keys
or
variables
named
"subject",
"property"
and
"object",
respectively.
The
subject
parameter
is
used
to
filter
RDFTriple
objects.
Values
can
be
of
type
IRI,
BlankNode,
DOMString,
IRI
,
or
Null.
BlankNode
.
If
a
DOMString
is
supplied,
the
API
must
convert
the
value
into
an
IRI
or
BlankNode
before
comparison
is
performed.
If
the
subject
is
a
non-Null
value,
specified,
the
RDFTriple
must
not
be
output
via
placed
in
the
DataIterator
final
output
Array
unless
the
given
subject
matches
the
RDFTriple's
RDFTriple
's
subject.
An
IRI
value
must
be
either
a
full
IRI
or
a
CURIE.
If
a
subject
parameter
is
set
to
Null,
not
specified,
the
filter
function
must
not
reject
any
triple
based
on
the
subject.
predicate
subject
unless
specified
by
the
DOMString
✔
✔
RDFTripleFilter
.
The
predicate
filter
pattern
which
property
parameter
is
used
to
filter
RDFTriple
objects.
Values
can
be
of
type
IRI
DOMString
or
Null.
IRI
.
If
a
DOMString
is
supplied,
the
predicate
API
must
convert
the
value
into
an
IRI
before
comparison
is
a
non-Null
value,
performed.
If
the
property
is
specified,
the
RDFTriple
must
not
be
output
via
placed
in
the
DataIterator
final
output
Array
unless
the
given
predicate
property
matches
the
RDFTriple's
predicate.
An
IRI
value
must
be
either
a
full
IRI
or
a
CURIE.
RDFTriple
's
property.
If
predicate
a
property
parameter
is
set
to
Null,
not
specified,
the
filter
function
must
not
reject
any
triple
based
on
the
predicate.
object
property
unless
specified
by
the
Object
✔
✔
RDFTripleFilter
.
The
object
filter
pattern
which
parameter
is
used
to
filter
RDFTriple
objects.
Values
can
be
of
type
IRI,
TypedLiteral,
PlainLiteral,
BlankNode,
DOMString,
BlankNode
,
PlainLiteral
,
TypedLiteral
or
Null.
IRI
.
If
a
DOMString
is
supplied,
the
API
must
convert
the
value
into
a
PlainLiteral
before
comparison
is
performed.
If
the
object
is
a
non-Null
value,
specified,
the
RDFTriple
must
not
be
output
via
placed
in
the
DataIterator
final
output
Array
unless
the
given
object
matches
the
RDFTriple's
RDFTriple
's
object.
An
IRI
value
must
be
either
a
full
IRI
or
a
CURIE.
If
an
object
parameter
is
set
to
Null,
not
specified,
the
filter
function
must
not
reject
any
triple
based
on
object.
the
object
unless
specified
by
the
RDFTripleFilter
.
|
|
element
|
Node
Element
|
✔
|
✔
|
The
parent
DOM
Node
Element
where
filtering
should
start.
The
implementation
must
only
consider
RDF
Triples
triples
on
the
current
DOM
Node
Element
and
its
children.
|
|
filter
|
RDFTripleFilter
|
✘
|
✔
|
A
user
defined
function,
returning
a
true
or
false
value,
that
determines
whether
or
not
an
RDFTriple
should
be
output
via
added
to
the
DataIterator.
final
Array.
|
No
exceptions.
-
parse
-
Parses
starting
at
the
given
DOM
Element
and
populates
the
store
with
the
information
that
is
discovered.
If
a
starting
element
isn't
specified,
or
the
value
of
the
starting
element
is
Null,
then
the
document
object
must
be
used
as
the
starting
element.
Even
though
a
specific
DOM
Element
can
be
specified
to
start
the
process
of
placing
RDFTriples
RDFTriple
s
into
the
DataStore,
DataStore
,
the
entire
document
must
be
processed
by
an
RDFa
Processor
due
to
context
that
may
affect
the
generation
of
a
set
of
triples.
Specifying
the
DOM
Element
is
useful
when
a
subset
of
the
document
data
is
to
be
stored
in
the
Data
Store.
DataStore
.
There
are
two
ways
to
approach
this
mechanism.
The
first
is
to
only
parse
the
sub-tree,
ignoring
the
context
of
the
greater
document.
The
second
is
to
parse
the
entire
document,
but
only
store
triples
that
are
a
part
of
the
sub-tree.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
domElement
|
Element
|
✘
|
✘
|
The
DOM
Element
that
should
trigger
triple
generation.
|
No
exceptions.
4.2.4
4.3.4
Data
Iterator
The
DataIterator
interface
will
almost
certainly
see
large
may
undergo
changes
in
the
next
version
of
the
RDFa
API
specification.
Implementers
are
warned
to
not
implement
the
interface
and
wait
for
the
next
revision
of
this
specification.
The
DataIterator
iterates
through
a
DOM
subtree
and
returns
RDFTriples
RDFTriple
s
that
match
a
filter
function
or
triple
pattern.
A
DOM
Node
Element
can
be
specified
so
that
only
triples
contained
in
the
Node
Element
and
its
children
will
be
a
part
of
the
iteration.
The
DataIterator
is
provided
in
order
to
allow
implementers
to
provide
a
less
memory
intensive
implementation
for
processing
triples
in
very
large
documents.
A
DataIterator
is
created
by
calling
the
document.data.parser.iterate()
method.
{
[NoInterfaceObject]
interface DataIterator {
attribute DataStore store;
readonly attribute Element root;
readonly attribute RDFTripleFilter filter;
readonly attribute RDFTriple triplePattern;
RDFTriple next ();
};
Attributes
-
filter
of
type
RDFTripleFilter
,
readonly
-
The
RDFTripleFilter
is
a
function
that
is
provided
by
developers
to
filter
RDFTriples
RDFTriple
s
in
a
subtree.
No
exceptions.
-
root
of
type
Node
Element
,
readonly
-
The
DOM
Node
Element
that
was
used
as
the
starting
point
for
extracting
RDFTriples.
RDFTriple
s.
No
exceptions.
-
store
of
type
DataStore
-
The
DataStore
that
is
associated
with
the
DataIterator.
DataIterator
.
No
exceptions.
-
triplePattern
of
type
RDFTriple
,
readonly
-
An
RDF
triple
pattern
is
a
set
of
filter
parameters
that
can
be
passed
to
an
RDFTripleFilter
to
match
particular
triple
patterns.
No
exceptions.
Methods
-
next
-
Returns
the
next
RDFTriple
object
that
is
found
in
the
DOM
subtree
or
NULL
if
no
more
RDFTriples
RDFTriple
s
match
the
filtering
criteria.
No
parameters.
No
exceptions.
4.2.5
4.3.5
Property
Group
The
PropertyGroup
interface
provides
a
view
on
a
particular
subject
contained
in
the
Data
Store.
DataStore
.
The
PropertyGroup
aggregates
the
RDFTriples
RDFTriple
s
as
a
single
language-native
object
in
order
to
provide
a
more
natural
programming
primitive
for
developers.
PropertyGroup
attributes
can
be
accessed
in
the
following
ways
in
Javascript:
ECMAScript:
// creates a PropertyGroup for the given subject
var person = document.getItemsBySubject("#bob");
// Retrieves a PropertyGroup for the given subject - since the IRI is
// fragment-relative, the document's IRI is used as the base IRI.
var person = document.getItemBySubject("#bob");
// Access the property group attribute via complete IRI
var name = person.get("http://xmlns.com/foaf/0.1/name");
// Access the PropertyGroup's name attribute via an IRI
var name1 = person.get("http://xmlns.com/foaf/0.1/name");
// Access the PropertyGroup's name attribute via a CURIE
var name2 = person.get("foaf:name");
//
At
this
point
name1
and
name2
are
equivalent
// Access the property group attribute via CURIE
var
name
=
person.get("foaf:name");
{
[NoInterfaceObject]
interface PropertyGroup {
attribute Object info; attribute IRI[] properties; Sequence get (in DOMString property);
};
Attributes
-
origin
info
of
type
Element
Object
-
A
developer-specific
info
object
to
associate
with
the
PropertyGroup
.
The
DOM
info
object
must
provide
a
property-based
accessor
mechanism
for
languages
that
support
it,
such
as
ECMAScript.
For
DOM-based
environments,
the
Element
that
originated
the
PropertyGroup
must
be
specified
in
a
property
called
source
in
the
first
type
definition
for
this
PropertyGroup.
info
attribute.
No
exceptions.
-
properties
of
type
array
of
Sequence[IRI]
IRI
-
A
list
of
all
attributes
that
are
available
via
this
PropertyGroup.
PropertyGroup
.
No
exceptions.
Methods
-
get
-
Returns
a
sequence
of
IRIs,
BlankNodes,
PlainLiterals,
BlankNode
s,
PlainLiteral
s,
and/or
TypedLiterals
TypedLiteral
s
in
the
projection
that
have
a
predicate
property
IRI
that
is
equivalent
to
the
given
value.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
predicate
property
|
DOMString
|
✘
|
✘
|
A
stringified
IRI
representing
a
predicate
property
whose
values
are
to
be
retrieved
from
the
PropertyGroup.
PropertyGroup
.
For
example,
using
a
predicate
property
of
http://xmlns.com/foaf/0.1/name
will
return
a
sequence
of
values
that
represent
FOAF
names
in
the
PropertyGroup.
PropertyGroup
.
The
given
predicate
property
may
also
be
a
CURIE.
|
No
exceptions.
The
Origin
Source
Pointer
document.getItemsByType()
returns
a
list
of
Property
Groups
that
match
the
query.
By
default
there
The
RDFa
Working
Group
is
always
a
property
called
origin
on
currently
discussing
the
Property
Group
and
all
best
mechanism
to
enable
access
to
the
DOMNode
that
contains
a
particular
subject,
predicate
or
object.
While
there
have
been
several
mechanisms
that
have
been
proposed,
none
of
its
properties,
which
refers
back
them
are
easy
or
straighforward
to
an
element
use.
This
mechanism
will
be
modified
heavily
in
the
source
document.
The
origin
property
allows
programmers
to
manipulate
DOM
objects
based
on
next
version
of
the
embedded
metadata
that
they
refer
to.
For
example,
document
in
order
to
set
allow
easier
access
to
the
DOMNode
associated
with
a
thin
blue
border
on
each
Person
,
we
could
do
this:
particular
piece
of
structured
data:
var people = document.getItemsByType("foaf:Person");
var people = document.getItemsByType("foaf:Person");
for (var i = 0; i < people.length; i++) {
people[i].origin.style.border = "1px solid blue";
people[i].info("foaf:name", "source")[0].style.border = "1px solid blue";
}
Property
Group
Templates
A
query
can
be
used
to
retrieve
not
only
basic
Property
Groups,
PropertyGroup
s,
but
can
also
specify
how
Property
Groups
PropertyGroup
s
are
built
by
utilizing
Property
Group
PropertyGroup
Templates.
There
has
been
a
complaint
that
this
section
comes
from
out
of
nowhere.
The
purpose
of
this
section
is
to
describe
that
PropertyGroups
can
be
mapped
to
native
language
objects
to
ease
development.
We
may
need
to
elaborate
more
on
this
at
this
point
in
the
document
to
help
integrate
this
section
with
the
flow
of
the
document.
For
example,
assume
our
source
document
contains
the
following
event,
marked
up
using
the
Google
Rich
Snippet
Event
format
(example
taken
from
the
Rich
Snippet
tutorial,
and
slightly
modified):
<div vocab="http://rdf.data-vocabulary.org/#" typeof="Event">
<a href="http://www.example.com/events/spinaltap" rel="v:url"
property="summary">Spinal Tap</a>
<img src="spinal_tap.jpg" rel="v:photo" />
<span property="description">After their highly-publicized search for a new drummer,
Spinal Tap kicks off their latest comeback tour with a San Francisco show. </span>
When:
<span property="startDate" content="20091015T1900Z">Oct 15, 7:00PM</span>—
<span property="endDate" content="20091015T2100Z">9:00PM</span>
<div prefix="v: http://rdf.data-vocabulary.org/#" typeof="v:Event">
<a rel="v:url" href="http://amyandtheredfoxies.example.com/events"
property="v:summary">Tour Info: Amy And The Red Foxies</a>
<span rel="v:location">
<a typeof="v:Organization" rel="v:url" href="http://www.kammgarn.de/" property="v:name">Kammgarn</a>
</span>
<div rel="v:photo"><img src="foxies.jpg"/></div>
<span property="v:summary">Hey K-Town, Amy And The Red Foxies will rock Kammgarn in October.</span>
When:
<span property="v:startDate" content="20091015T19:00">15. Oct., 7:00 pm</span>-
<span property="v:endDate" content="20091015T21:00">9:00 pm</span>
</span>
Category: <span property="v:eventType">concert</span>
</div>
To
query
for
all
Event
Property
Groups
PropertyGroup
s
we
know
that
we
can
do
this:
var
ar
=
query.select({
"rdf:type":
"http://rdf.data-vocabulary.org/#Event"
});
However,
to
build
a
special
PropertyGroup
that
contains
the
summary,
start
date
and
end
date,
we
need
only
do
this:
var events = query.select({ "rdf:type": "http://rdf.data-vocabulary.org/#Event" },
var events = query.select({ "rdf:type": "http://rdf.data-vocabulary.org/#Event" },
{"rdf:type" : "type", "v:summary": "summary",
"v:startDate":
"start",
"v:endDate":
"end"}
);
The
second
parameter
is
a
PropertyGroup
Property
Group
Template.
Each
key-value
pair
specifies
an
IRI
to
map
to
an
attribute
in
the
resulting
PropertyGroup
object.
Exposing
the
embedded
data
in
each
Property
Group
PropertyGroup
makes
it
easy
to
create
an
HTML
anchor
that
will
allow
users
to
add
the
event
to
their
Google
Calendar,
as
follows:
var anchor, button, i, pg;
var anchor, button, i, pg;
for (i = 0; i < events.length; i++) {
// Get the Property Group:
pg = events[i];
// Get the PropertyGroup
var event = events[i];
// Create the anchor
// Create the anchor
anchor = document.createElement("a");
// Point to Google Calendar
// Point to Google Calendar
anchor.href = "http://www.google.com/calendar/event?action=TEMPLATE"
+ "&text=" + pg.summary + "&dates=" + pg.start + "/" + pg.end;
+ "&text=" + event.summary + "&dates=" + event.start + "/" + event.end;
// Add the button
// Add the button
button = document.createElement("img");
button.src = "http://www.google.com/calendar/images/ext/gc_button6.gif";
anchor.appendChild(button);
// Add the link and button to the DOM object
pg.origin.appendChild(anchor);
// Add the link and button to the DOM object
// NOTE: The next call will likely change in the next version of the RDF
// API specification as it is too difficult to use for most developers.
event.info("rdf:type", "source")[0].appendChild(anchor);
}
The
result
will
be
that
the
event
has
an
HTML
a
element
at
the
end
(and
any
Event
on
the
page
will
follow
this
pattern):
<div vocab="http://rdf.data-vocabulary.org/#" typeof="Event">
<div vocab="http://rdf.data-vocabulary.org/#" typeof="Event">
.
.
.
<a href="http://www.google.com/calendar/event?action=TEMPLATE&text=Spinal+Tap&dates=20091015T1900Z/20091015T2100Z">
<a href="http://www.google.com/calendar/event?action=TEMPLATE& →
text=Hey+K-Town,+Amy+And+The+Red+Foxies+will+rock+Kammgarn+in+October.&dates=20091015T1900Z/20091015T2100Z">
<img src="http://www.google.com/calendar/images/ext/gc_button6.gif" />
</a>
</div>
For
more
detailed
information
about
queries
see
the
Data
Query
DataQuery
interface.
4.2.6
4.3.6
Data
Query
The
Data
Query
DataQuery
interface
provides
a
means
to
query
a
Data
Store.
DataStore
.
While
this
interface
provides
a
simple
mechanism
for
querying
a
Data
Store
DataStore
for
RDFa,
it
is
expected
that
developers
will
implement
other
query
interfaces
that
conform
to
this
Data
Query
DataQuery
interface
for
languages
like
SPARQL
or
other
Domain
Specific
Language.
{
[NoInterfaceObject]
interface DataQuery {
attribute DataStore store;
Sequence select (in Object? query, in optional Object template);
};
Methods
-
select
-
Generates
a
sequence
of
Property
Groups
PropertyGroup
s
that
matches
the
given
selection
criteria.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
query
|
Object
|
✔
|
✘
|
An
associative
array
containing
predicates
properties
as
keys
and
objects
to
match
as
values.
If
the
query
is
null,
every
item
in
the
Data
Store
DataStore
that
the
query
is
associated
with
must
returned.
|
|
template
|
Object
|
✘
|
✔
|
A
template
describing
the
attributes
to
create
in
each
Property
Group
PropertyGroup
that
is
returned.
The
template
is
an
associative
array
containing
predicates
properties
as
keys
and
attribute
names
that
should
be
created
in
the
returned
PropertyGroup
as
values.
|
No
exceptions.
4.3
4.4
The
Document
Interface
The
RDFa
DOM
API
is
designed
to
provide
a
small,
powerful
set
of
interfaces
that
a
developer
may
use
to
retrieve
RDF
triples
from
a
Web
document.
The
core
interfaces
were
described
in
the
previous
two
sections.
This
section
focuses
on
the
final
RDFa
API
that
most
developers
will
utilize
to
generate
the
objects
that
are
described
in
the
RDF
Interfaces
and
the
Structured
Data
Interfaces
sections.
The
following
API
is
provided
by
this
specification:
-
Document
Interface
Extensions
—
A
set
of
extensions
to
the
Document
interface
to
help
developers
manage
structured
data
in
Web
documents.
-
Document
Data
—
The
abstract
container
object
for
managing
structured
data
in
a
Document.
4.3.1
4.4.1
Document
Interface
Extensions
The
following
section
describes
all
of
the
extensions
that
are
necessary
to
enable
manipulation
of
structured
data
within
a
Web
Document.
{
[Supplemental, NoInterfaceObject]
interface RDFaDocument {
readonly attribute DocumentData data; DocumentData createDocumentData (); Sequence getItemsByType (in DOMString type); PropertyGroup getItemBySubject (in DOMString subject); Sequence getItemsByProperty (in DOMString property, in DOMString value); NodeList getElementsByType (in DOMString type); NodeList getElementsBySubject (in DOMString subject); NodeList getElementsByProperty (in DOMString property, in DOMString value);
};
Attributes
-
data
of
type
DocumentData
,
readonly
-
The
DocumentData
interface
is
useful
for
extracting
and
storing
data
that
is
associated
with
the
Document.
No
exceptions.
Methods
-
createDocumentData
-
Creates
a
DocumentData
object
and
returns
it.
The
object
that
is
returned
must
have
the
store
,
context
,
parser
and
query
attributes
initialized
to
sensible
defaults
that
would
allow
the
immediate
extraction
of
RDFa
data
from
the
current
document
by
calling
DocumentData
.parser.parse(document)
No
parameters.
No
exceptions.
-
getElementsByProperty
-
Retrieves
a
list
of
Nodes
objects
based
on
the
value
of
a
given
property.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
property
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
an
IRI-based
property.
The
string
can
either
be
a
full
IRI
or
a
CURIE.
If
the
string
is
a
CURIE,
the
DataContext
will
be
used
to
resolve
the
value.
|
|
value
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
the
value
to
match
against.
|
No
exceptions.
-
getElementsBySubject
-
Retrieves
a
NodeList
consisting
of
Nodes
that
have
explicitly
specified
the
given
subject.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
subject
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
an
IRI-based
subject.
The
string
can
either
be
a
full
IRI
or
a
CURIE.
If
the
string
is
a
CURIE,
the
DataContext
will
be
used
to
resolve
the
value.
|
No
exceptions.
-
getElementsByType
-
Retrieves
a
list
of
Nodes
based
on
the
object
type
of
the
data
that
they
specify.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
type
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
an
rdf:type
to
select
against.
|
No
exceptions.
-
getItemBySubject
-
Retrieves
a
PropertyGroup
object
based
on
its
subject.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
subject
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
an
IRI-based
subject.
The
string
can
either
be
a
full
IRI
or
a
CURIE.
If
the
string
is
a
CURIE,
the
DataContext
will
be
used
to
resolve
the
value.
|
No
exceptions.
-
getItemsByProperty
-
Retrieves
a
list
of
PropertyGroup
objects
based
on
the
values
of
a
property.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
property
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
an
IRI-based
property.
The
string
can
either
be
a
full
IRI
or
a
CURIE.
If
the
string
is
a
CURIE,
the
DataContext
will
be
used
to
resolve
the
value.
|
|
value
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
the
value
to
match
against.
|
No
exceptions.
-
getItemsByType
-
Retrieves
a
list
of
PropertyGroup
objects
based
on
their
rdf:type
property.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
type
|
DOMString
|
✘
|
✘
|
A
DOMString
representing
an
rdf:type
to
select
against.
|
No
exceptions.
Document
implements
RDFaDocument
;
4.4.2
DOMImplementation
Extensions
If
the
RDFa
API
is
implemented
in
a
DOM
environment
and
a
DOMImplementation
interface
is
provided,
the
following
additional
requirements
for
the
hasFeature()
method
must
be
met:
interface DOMImplementation { boolean hasFeature (in DOMString feature, in DOMString version);
};
Methods
-
hasFeature
-
Checks
to
see
whether
or
not
the
document
object
DOM
implementation
has
exposed
all
of
the
mandatory
RDFa
DOM
API
feature.
features
specified
in
this
specification.
An
implementation
that
supports
all
of
the
mandatory
features
in
this
specification
must
return
true
for
a
feature
string
of
"
RDFaAPI
"
and
a
version
string
of
"
1.1
".
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
feature
|
DOMString
|
✘
|
✘
|
The
feature
string
to
use
when
checking
to
see
if
the
Document
interface
has
DOM
environment
exposes
all
of
the
RDFa
DOM
API
interfaces.
This
value
should
be
"
attributes
and
methods.
|
|
version
|
rdfa
1.1
DOMString
".
|
✘
|
✘
|
The
version
string
to
use
when
checking
to
see
if
the
DOM
environment
exposes
all
of
the
RDFa
API
attributes
and
methods.
|
No
exceptions.
4.3.2
4.4.3
Document
Data
The
DocumentData
interface
is
used
to
create
structured-data
related
context,
storage,
parsing
and
query
objects.
{
interface DocumentData {
attribute DataStore store;
attribute DataContext context;
attribute DataParser parser;
attribute DataQuery query;
DataContext createContext ();
DataStore createStore (in optional DOMString type);
DataParser createParser (in DOMString type, in DataStore store);
DataQuery createQuery (in DOMString type, in DataStore store);
};
Methods
-
createContext
-
Creates
a
DataContext
and
returns
it.
No
parameters.
No
exceptions.
-
createParser
-
Creates
a
DataParser
of
the
given
type
and
returns
it.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
type
|
DOMString
|
✘
|
✘
|
The
type
of
DataParser
to
create.
For
example:
A
value
of
"
rdfa
".
"
must
be
accepted
for
all
conforming
implementations
of
this
specification.
|
|
store
|
DataStore
|
✘
|
✘
|
The
DataStore
to
associate
with
the
DataParser.
DataParser
.
|
No
exceptions.
-
createQuery
-
Creates
a
DataQuery
for
the
given
store.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
type
|
DOMString
|
✘
|
✘
|
The
type
of
query
to
create
for
the
given
store.
A
value
of
"
rdfa
"
must
be
accepted
for
all
conforming
implementations
of
this
specification.
Implementations
may
provide
alternative
query
interfaces,
such
as
SPARQL,
SQL,
HQL,
GQL,
or
other
query
languages
to
enable
innovative
new
ways
of
querying
the
underlying
storage
mechanism.
|
|
store
|
DataStore
|
✘
|
✘
|
The
DataStore
to
associate
with
the
DataQuery.
DataQuery
.
|
No
exceptions.
-
createStore
-
Creates
a
DataStore
of
the
given
type
and
returns
it.
If
the
type
is
not
specified,
a
DataStore
must
be
created
and
returned.
Alternatively,
developers
may
provide
other
DataStore
implementations
such
as
persisted
triple
stores,
quad
stores,
distributed
graph
stores
and
other
more
advanced
storage
mechanisms.
The
type
determines
the
underlying
DataStore
that
will
be
created.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
type
|
DOMString
|
✘
|
✘
✔
|
The
type
of
DataStore
to
create.
A
value
of
"triple"
must
be
accepted
for
all
conforming
implementations
of
this
specification.
If
the
type
is
omitted,
a
value
of
"triple"
must
be
assumed.
|
No
exceptions.
4.3.3
4.4.4
Pattern
Filters
An
important
goal
of
the
RDFa
DOM
API
is
to
help
Web
developers
filter
the
set
of
RDF
triples
in
a
document
down
to
only
the
ones
that
interest
them.
This
section
covers
pattern-based
filters.
Pattern
filters
trigger
off
of
one
or
more
of
the
subject,
predicate,
property,
or
object
properties
in
RDF
triples.
This
section
also
introduces
the
interfaces
for
the
other
filter
types.
Function
Filters
Filter
criteria
may
also
be
defined
by
the
developer
as
a
filter
function.
The
RDFTripleFilter
is
a
callable
function
that
determines
whether
an
RDFTriple
should
be
included
in
the
set
of
output
triples.
]
[NoInterfaceObject, Callback, Null=Null]
interface RDFTripleFilter {
boolean match (in RDFTriple triple);
};
Methods
-
match
-
A
callable
function
that
returns
true
if
the
input
RDFTriple
should
be
included
in
the
output
set,
or
false
if
the
input
RDFTriple
should
be
rejected
from
the
output
set.
|
Parameter
|
Type
|
Nullable
|
Optional
|
Description
|
|
triple
|
RDFTriple
|
✘
|
✘
|
The
triple
to
test
against
the
filter.
|
No
exceptions.
5.
The
Initialization
Process
The
RDFa
DOM
API
must
be
initialized
before
the
Web
developer
has
access
to
any
of
the
methods
that
are
defined
in
this
specification.
To
initialize
the
API
environment
in
a
Browser-based
environment,
an
implementor
must
do
the
following:
-
create
a
default
Store
object,
which
will
hold
information
obtained
from
parsing;
-
create
a
defaul
Parser
object,
passing
it
a
pointer
to
a
store;
-
initiate
parsing,
to
extract
information
from
some
object
--
usually
a
DOM
object
--
and
place
it
into
the
store;
-
create
a
default
Query
object
which
can
be
used
to
interrogate
the
information
placed
in
the
store;
Some
platforms
may
merge
one
or
more
of
these
steps
as
a
convenience
to
developers.
For
example,
a
browser
that
supports
this
API
may
carry
out
the
first
four
steps
when
a
document
loads,
and
then
expose
a
Query
interface
to
allow
developers
to
access
the
Property
Groups.
PropertyGroup
s.
Some
approaches
to
this
will
be
discussed
in
the
next
section,
but
before
we
look
at
those,
we'll
give
a
brief
overview
of
how
each
of
these
phases
would
normally
be
accomplished.
5.1
Creating
the
Data
Store
To
create
a
store
the
createStore
method
is
called:
document.data.store
=
document.data.createStore();
The
store
object
created
supports
the
Store
interfaces
providing
methods
to
add
metadata
to
the
store.
These
methods
are
used
during
parsing
to
populate
the
store
but
they
can
also
be
used
directly
to
add
additional
information.
Examples
of
this
are
shown
later.
5.2
Creating
the
Data
Parser
Once
a
store
has
been
created,
the
implementor
should
create
a
default
parser:
document.data.parser
=
document.data.createParser("rdfa",
store);
Note
that
an
implementation
may
support
many
types
of
parser,
so
the
specific
parser
required
needs
to
be
specified.
For
example,
an
implementation
may
also
support
a
Microformats
hCard
parser:
var
parser
=
document.data.createParser("hCard",
store);
Implementations
may
also
support
different
versions
of
a
parser,
for
example:
var parser = document.data.createParser("rdfa1.0", store);
var parser1 = document.data.createParser("rdfa1.0", store);
var
parser
parser2
=
document.data.createParser("rdfa1.1",
store);
Probably
should
have
a
URI
to
identify
parsers
rather
than
a
string,
since
not
only
are
there
many
different
Microformats,
but
also,
people
may
end
up
wanting
to
add
parsers
for
RDF/XML,
different
varieties
of
JSON,
and
so
on.
However,
if
we
treat
the
parameter
here
as
a
CURIE,
then
we
can
avoid
having
long
strings.
If
we
do
that,
then
the
version
number
would
need
to
be
elided
with
the
language
type:
"rdfa1.0",
"rdfa1.1",
and
so
on.
5.3
Parsing
the
DOM
Once
we
have
a
parser,
we
can
use
it
to
extract
information
from
sources
that
contain
embedded
data.
In
the
following
example
we
extract
data
from
the
Document
object:
parser.parse(
document
);
Since
the
parser
is
connected
to
a
store,
the
Property
Groups
PropertyGroup
s
obtained
from
processing
the
document
are
now
available
in
the
variable
document.data.store
.
A
store
can
be
used
more
than
once
for
parsing.
For
example,
if
we
wanted
to
apply
an
hCard
Microformat
parser
to
the
same
document,
and
put
the
extracted
data
into
the
same
store,
we
could
do
this:
var store = document.data.createStore();
var store = document.data.createStore();
document.data.createParser("rdfa", store).parse();
document.data.createParser("hCard",
store).parse();
The
store
will
now
contain
Property
Groups
PropertyGroup
s
from
the
RDFa
parsing,
as
well
as
Property
Groups
PropertyGroup
s
from
the
hCard
parsing.
(If
If
the
developer
wishes
to
reuse
the
store
but
clear
it
first,
then
the
Store.clear()
clear()
method
on
the
DataStore
interface
can
be
used.)
used.
Diagram:
Show
the
connection
between
a
Property
Group
PropertyGroup
and
the
DOM.
5.4
Creating
the
Data
Query
Query
objects
are
used
to
interrogate
stores
and
obtain
a
list
of
DOM
objects
that
are
linked
to
Property
Groups.
PropertyGroup
s.
Since
there
are
a
number
of
languages
and
techniques
that
can
be
used
to
express
queries,
we
need
to
specify
the
type
of
query
object
that
we'd
like:
var
query
=
document.data.createQuery("rdfa",
store);