5.1.1 UA mapped byte ranges
| Editorial note | |
|
This section is ready to implement.
|
As described in section 3.2 Resolving URI fragments within the user agent, the most optimal case is a user agent that knows how to map media fragments to byte ranges. This is the case typically where a user agent has already downloaded those parts of a media resource that allow it to do or guess the mapping, e.g. headers or a resource, or an index of a resource.
In this case, the HTTP exchanges are exactly the same as for any other Web resource where byte ranges are requested RFC 2616.
How the UA retrieves the byte ranges is dependent on the media type of the media resource.
We here show examples with only one byte range retrieval per time range, which may
in practice turn into several such retrieval actions necessary to acquire the correct
time range.
Here are the three principle cases a media fragment enabled UA and a media Server will encounter:
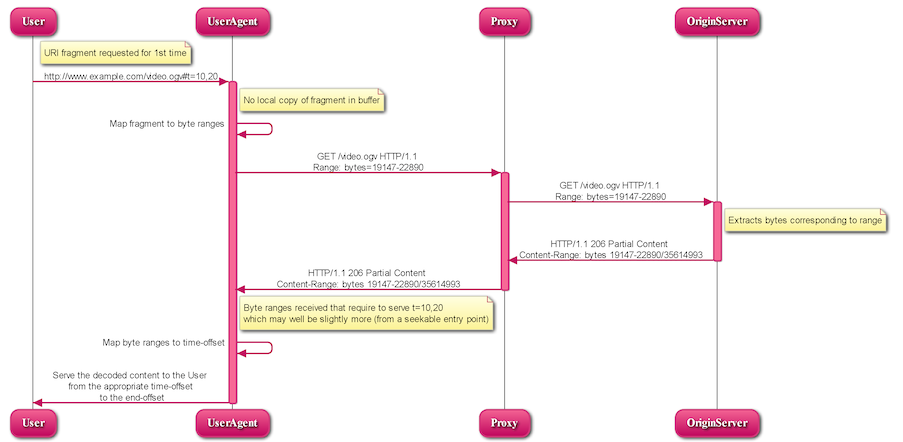
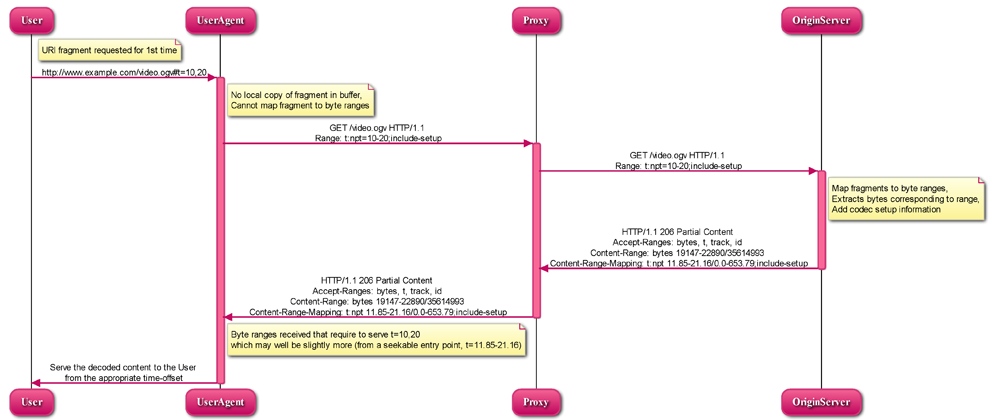
5.1.1.1 UA requests URI fragment for the first time
A user requests a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its buffer - not in this case. But it knows how to map the fragment to byte ranges: 19147 - 22890. So, it requests these byte ranges from the server:
The server extracts the bytes corresponding to the requested range and replies in a 206 HTTP response:
Assuming the UA has received the byte ranges that it requires to serve t=10,20, which may well be slightly more, it will serve the decoded content to the User from the appropriate time offset. Otherwise it may keep requesting byte ranges to retrieve the required time segments.
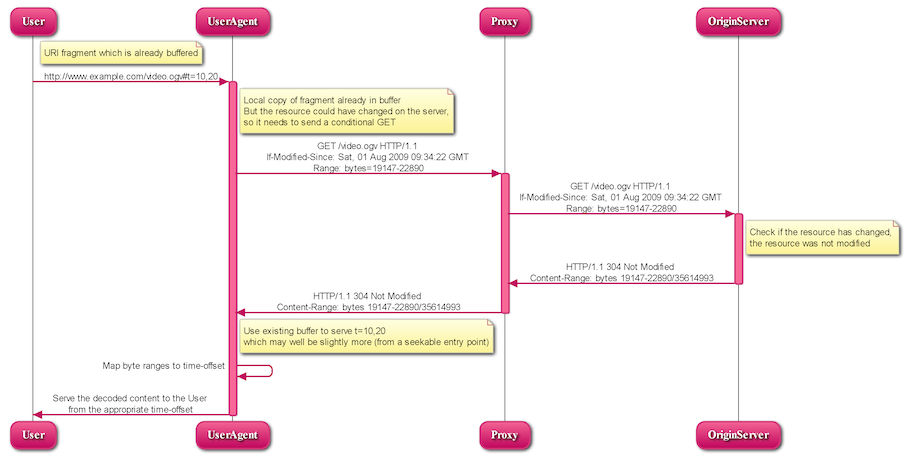
5.1.1.2 UA requests URI fragment it already has buffered
A user requests a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its buffer - it is in this case. But the resource could have changed on the server, so it needs to send a conditional GET. It knows the byte ranges: 19147 - 22890. So, it requests these byte ranges from the server under condition of it having changed:
The server checks if the resource has changed by checking the date - in this case, the resource was not modified. So, the server replies with a 304 HTTP response. (Note that a If-Range header cannot be used, because if the entity has changed, the entire resource would be sent.)
So, the UA serves the decoded resource to the User our of its existing buffer.
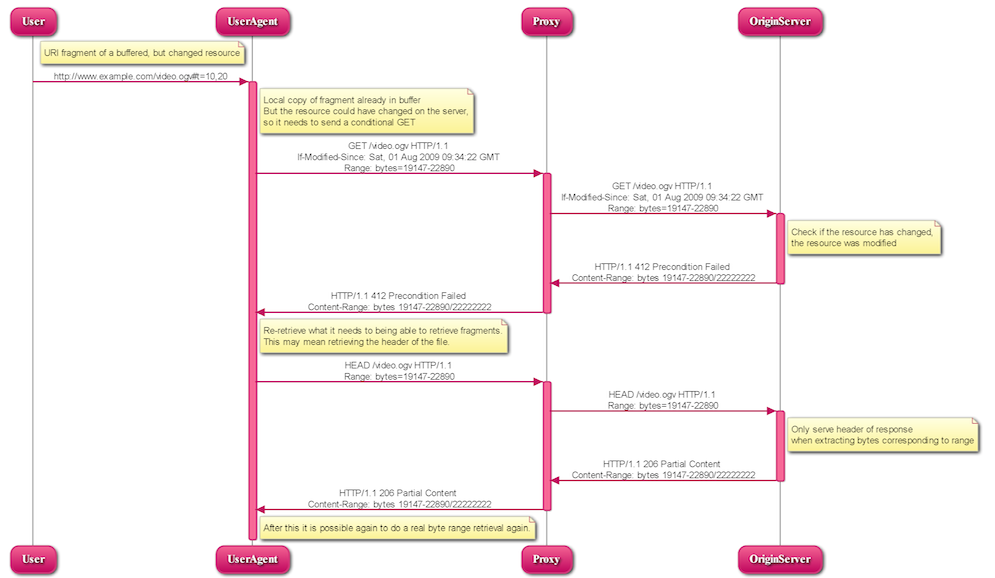
5.1.1.3 UA requests URI fragment of a changed resource
A user requests a media fragment URI and the UA sends the exact same GET request as described in the previous subsection.
This time, the server checks if the resource has changed by checking the date and it has been modified. Since the byte mapping may not be correct any longer, the server can only tell the UA that the resource has changed and leave all further actions to the UA. So, it sends a 412 HTTP response:
So, the UA can only assume the resource has changed and re-retrieve what it needs to get back to being able to retrieve fragments. For most resources this may mean retrieving the header of the file. After this it is possible again to do a byte range retrieval.
5.1.2 Server mapped byte ranges
As described in section 3.3 Resolving URI fragments with server help, some User Agents cannot
undertake the fragment-to-byte mapping themselves, because the mapping is not obvious.
This typically applies to media formats where the setup of the decoding pipeline does
not imply knowledge of how to map fragments to byte ranges, e.g. Ogg without OggIndex.
Thus, the User Agent would be capable of decoding a continuous resource, but would not
know which bytes to request for a media fragment.
In this case, the User Agent could either guess what byte ranges it has to retrieve
and the retrieval action would follow the previous case. Or it could hope that the server
provides a special service, which would allow it to retrieve the byte ranges with a simple
request of the media fragment ranges. Thus, the HTTP request of the User Agent will include
a request for the fragment hoping that the server can do the byte range mapping and send
back the appropriate byte ranges. This is realized by introducing new dimensions for the
HTTP Range header, next to the byte dimension.
The specification for all new Range Request Header dimensions is given through the following
ABNF as an extension to the HTTP Range Request Header definition (see
http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.35.2):
Range = "Range" ":" ranges-specifier
ranges-specifier = byte-ranges-specifier | fragment-specifier
;
; note that ranges-specifier is extended from RFC 2616
; to cover alternate fragment range specifiers
;
fragment-specifier = "include-setup" | fragment-range *( "," fragment-range )
[ ";" "include-setup" ]
fragment-range = time-ranges-specifier | track-ranges-specifier | name-ranges-specifier
;
; note that this doesn't capture the restriction to one fragment dimension occurring
; maximally once only in the fragment-specifier definition.
;
time-ranges-specifier = npttimeoption / smptetimeoption / clocktimeoption
npttimeoption = pfxdeftimeformat "=" npt-sec "-" [ npt-sec ]
smptetimeoption = pfxsmpteformat "=" frametime "-" [ frametime ]
clocktimeoption = pfxclockformat "=" datetime "-" [ datetime ]
track-ranges-specifier = trackprefix "=" trackparam *( ";" trackparam )
name-ranges-specifier = nameprefix "=" nameparam
This specification is meant to be analogous to the one in URIs, but it is a bit stricter.
The time unit is not optional. For instance, it can be "npt", "smpte", "smpte-25",
"smpte-30", "smpte-30-drop" or "clock" for temporal. Where "ntp" is used for a temporal
range, only specification in seconds is possible. Where "clocktime" is used for a temporal
range, only "datetime" is possible and "walltime" is fully specified in HHMMSS with
fraction and full timezone. Indeed, all optional elements in the URI specification
basically become required in the Range header.
There is an optional 'include-setup' flag on the fragment range specifier - this
flag signals to the server whether delivery of the decoder setup information (i.e.
typically file header information) is also required as part of the reply to this
request. This can help avoid an extra roundtrip where a Media Fragment URI is, e.g.
directly typed into a Web browser.
If there were multiple track parameters provided in the media fragment URI, they are all
aggregated together here in a single track ranges specifier, where the track names are
separated by semi-colon. Note that if a track name did include a semi-colon in the media
fragment URI, it is now percent escaped.
Note that the specification does not foresee a Range dimension for spatial media
fragments since they are typically resolved and interpreted by the User Agent (i.e.,
spatial fragment extraction is not performed on server-side) for the following
reasons:
spatial media fragments are typically not expressible in terms of byte ranges.
Spatial fragment extraction would thus require transcoding operations resulting
in new resources rather than fragments of the original media resource. As described
in section 3 URI fragment and URI query, spatial fragment extraction is in this
case better represented by URI queries.
When a User Agent receives an extracted spatial media fragment, it is not trivial
to visualize the context of this fragment (see also section
7.1 Clients Displaying Media Fragments).
More specifically, spatial context requires a meaningful background, which will not
be available at the User Agent when the spatial fragment is extracted by the
server.
| Editorial note: Davy | |
|
Special attention should be paid for named fragments and more specifically when a
named fragment represents a spatial fragment. We should clearly describe 1. what
named fragments are and 2. how they are resolved.
|
Next to the introduction of new dimensions for the HTTP Range request header, we also
introduce a new HTTP response header, called Content-Range-Mapping, which provides the
mapping of the retrieved byte range to the original Range request, which was not in
bytes. It serves two purposes:
It Indicates the actual mapped range in terms of fragment dimensions. This is
necessary since the server might not be able to provide a byte range mapping that
corresponds exactly to the requested range. Therefore, the User Agent needs to be
aware of this variance.
It provides context information regarding the parent resource in case the Range
request contained a temporal dimension. More specifically, the header contains the
start and end time of the parent resource. This way, the User Agent is able to
understand and visualize the temporal context of the media fragment.
The specification for the Content-Range-Mapping header is based on the specification
of the Content-Range header
(see http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.16)
and is shown below. Note that the Content-Range-Mapping header adds in case of the
temporal dimension the instance start and end in terms of seconds after a slash
"/" character in analogy to the Content-Range header. Also, we introduce an extension
to the Accept-Ranges header
(see http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.5).
Content-Range-Mapping = "Content-Range-Mapping" ":" '{'
( content-range-mapping-spec [ ";" def-include-setup ] ) / def-include-setup
'}' '=' '{'
byte-content-range-mapping-spec '}'
def-include-setup = %x69.6E.63.6C.75.64.65.2D.73.65.74.75.70 ; "include-setup"
byte-range-mapping-spec = bytes-unit SP
byte-range-resp-spec *( "," byte-range-resp-spec ) "/"
( instance-length / "*" )
content-range-mapping-spec = time-mapping-spec | track-mapping-spec | name-mapping-spec
time-mapping-spec = timeprefix ":" time-mapping-options
time-mapping-options = npt-mapping-option / smpte-mapping-option / clock-mapping-option
npt-mapping-option = deftimeformat SP npt-sec "-" npt-sec "/"
[ npt-sec ] "-" [ npt-sec ]
smpte-mapping-option = smpteformat SP frametime "-" frametime "/"
[ frametime ] "-" [ frametime ]
clock-mapping-option = clockformat SP datetime "-" datetime "/"
[ datetime ] "-" [ datetime ]
track-mapping-spec = trackprefix SP trackparam *( ";" trackparam )
name-mapping-spec = nameprefix SP nameparam
Accept-Ranges = "Accept-Ranges" ":" acceptable-ranges
acceptable-ranges = 1#range-unit *( "," 1#range-unit )| "none"
;
; note this does not represent the restriction that range-units can only appear once at most
;
range-unit = bytes-unit | other-range-unit
bytes-unit = "bytes"
other-range-unit = token | timeprefix | trackprefix | nameprefix
Three cases can be distinguished when a User Agent needs assistance by a server to
perform the byte range mapping. In the next subsections, we'll go through the protocol
exchange action step by step.
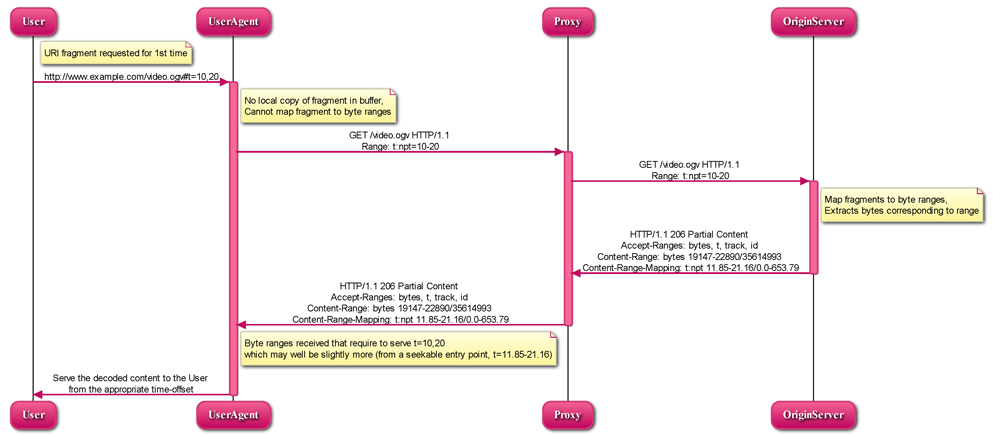
5.1.2.1 Server mapped byte ranges with corresponding binary data
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its
buffer. If it is, we revert back to the processing described in sections
5.1.1.2 UA requests URI fragment it already has buffered
and 5.1.1.3 UA requests URI fragment of a changed resource, since the UA already
knows the mapping to byte ranges. If the requested fragment is not available in
its buffer, the UA sends an HTTP request to the server, including a Range header
with temporal dimension. The request is shown below:
If the server does not understand a Range header, it MUST ignore the header field
that includes that range-set. This is in sync to the HTTP RFC RFC 2616.
This means that where a server does not support media fragments, the complete resource
will be delivered. It also means that we can combine both, byte range and fragment range
headers in one request, since the server will only react to the Range header
it understands.
Assuming the server can map the given Range to one or more byte ranges, it will
reply with these in a 206 HTTP response. Where multiple byte ranges are required to
satisfy the Range request, these are transmitted as a multipart message-body. The
media type for this purpose is called "multipart/byteranges". This is in sync with
the HTTP RFC RFC 2616.
Here is the reply to the example above, assuming a single byte range is sufficient:
Note the presence of the new reply header called Content-Range-Mapping, which provides
the mapping of the retrieved byte range to the original Content-Range request, which
was not in bytes. As we return both, byte and temporal ranges, the UA and any
intermediate caching proxy is enabled to map byte positions with time offsets and fall
back to byte range request where the fragment is re-requested. Also note that through
the extended list in the Accept-Ranges it is possible to identify which fragment
schemes a server supports.
In the case where a media fragment results in a multipart message-body, the
Content-Range headers will be spread throughout the binary data ranges, but the
Content-Range-Mapping of the media fragment will only be with the main header.
Note that requesting track fragments typically result in multipart message-bodies,
on condition that the parent resource is characterized by interleaved tracks. For
example:
Note that a caching proxy that does not understand a Range header must not cache
"206 Partial Content" responses as per HTTP RFC RFC 2616. Thus, the
new Range requests won't be cached by legacy Web proxies.
5.1.2.2 Server mapped byte ranges with corresponding binary data and codec setup data
When the User Agent needs help from the server to setup the initial decoding pipeline
(i.e., the User Agent has no codec setup information at its disposal), the User Agent
can request, next to the bytes corresponding to the requested fragment, the bytes
necessary to setup its decoder. This is possible by adding the 'include-setup' flag to
the Range header, as illustrated below:
Analogous to section 5.1.2.1 Server mapped byte ranges with corresponding binary data, the
server can map the given Range to one or more byte ranges, it will reply with these in
a 206 HTTP response. Additionally, the server adds the bytes corresponding with the
requested setup information to the response. Since this setup information usually
appears in front of a media resource, the response typically results in a multipart
message-body. The response is shown below:
Note that the Content-Range-Mapping header indicates that the codec setup information
is included in the response. In this example, the response consists of two parts of byte
ranges: the first part corresponds to the setup information, the second part corresponds
to the requested fragment.
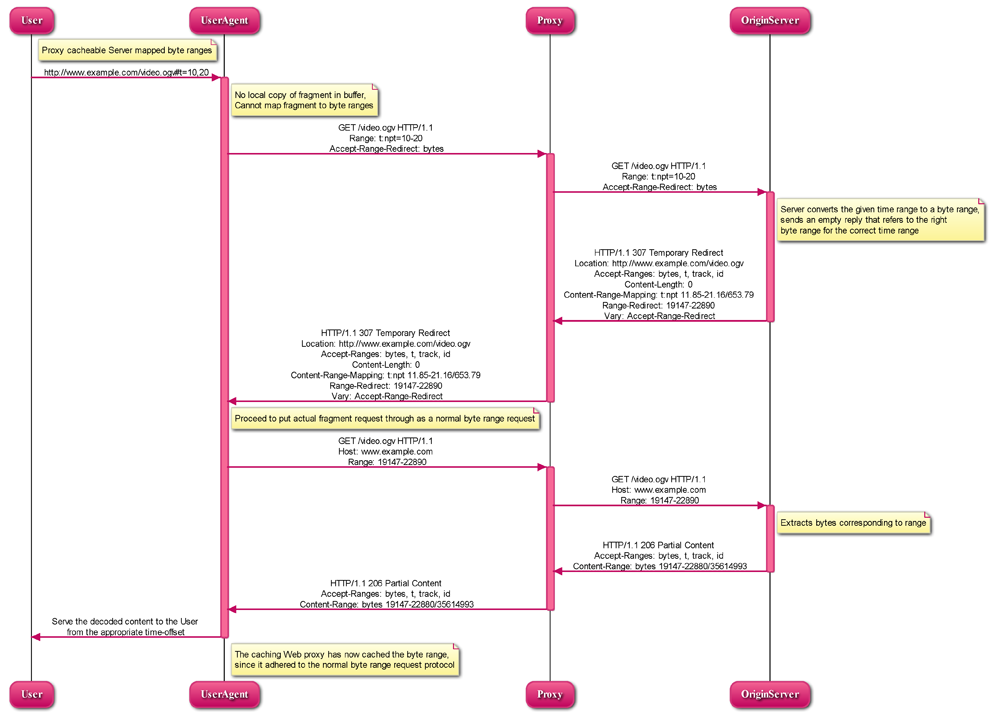
5.1.2.3 Proxy cacheable server mapped byte ranges
As described in section 3.4 Resolving URI fragments in a proxy cacheable manner, the server mapped byte
ranges approach can be extended to play with existing caching Web proxy infrastructure.
This is important, since video is a huge bandwidth eater in the current Internet and
falling back to using existing Web proxy infrastructure is important, particularly
since progressive download and direct access mechanisms for video rely heavily on this
functionality. Over time, the proxy infrastructure will learn how to cache media
fragment URIs directly as described in the previous section and then will not require
this extra effort.
To enable media-fragment-URI-supporting UAs to make their retrieval cacheable, we
introduce some extra HTTP headers, which will help tell the server and the proxy what
to do. There is an Accept-Range-Redirect request header which signals to the server
that only a redirect to the correct byte ranges is necessary and the result should be
delivered in the Range-Redirect header.
The ABNF for these additional two HTTP headers is given as follows:
Accept-Range-Redirect = "Accept-Range-Redirect" ":" bytes-unit
Range-Redirect = "Range-Redirect" ":" byte-range-resp-spec *( "," byte-range-resp-spec )
Let's play it through on an example. A user requests a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#t=10,20
The UA has to check if a local copy of the requested fragment is available in its
buffer. In our case here, it is not. If it was, we would revert back to the processing
described in sections 5.1.1.2 UA requests URI fragment it already has buffered and
5.1.1.3 UA requests URI fragment of a changed resource, since the UA already knows the
mapping to byte ranges. The UA issues a HTTP GET request with the fragment and
requesting to retrieve just the mapping to byte ranges:
The server converts the given time range to a byte range and sends an empty reply
that refers the UA to the right byte range for the correct time range.
Note that codec setup information can also be requested in combination with the
Accept-Range-Redirect header, which can be realized by adding the 'include-setup'
flag to the Range request header.
The UA proceeds to put the actual fragment request through as a normal byte range
request as in section 5.1.1.1 UA requests URI fragment for the first time:
The Origin Server puts the data together and sends it to the UA:
The UA decodes the data and displays it from the requested offset. The caching Web
proxy in the middle has now cached the byte range, since it adhered to the normal byte
range request protocol. All existing caching proxies will work with this. New caching
Web proxies may learn to interpret media fragments natively, so won't require the extra
packet exchange described in this section.
5.1.3 Server triggered redirect
When a server decides not to serve the requested media fragment in terms of byte ranges (i.e., serving the requested media fragment as specified in section 5.1.2 Server mapped byte ranges), it can redirect the UA to a representation of this fragment (for instance by transforming the media fragment URI into a media fragment query, as specified in section 5.2 Protocol for URI query Resolution in HTTP). This is particularly useful in cases where too many byte ranges would need to e extracted to satisfy the range request.
A user requests a media fragment URI using a URI fragment:
User → UA (1):
http://www.example.com/video.ogv#track=video1
Subsequently, the UA requests the media fragment from the server using the Range header:
The server decides not to serve the requested media fragment in terms of byte ranges (for instance, because the track media fragment results in too many byte ranges). The server redirects the UA to an alternate representation. For example, the URI fragment can be transformed into a URI query. Further, a Link header is added stating that the redirected location is a fragment of the originally requested resource.
| Editorial note: Davy | |
|
We need to register the 'fragment' Link Relation Web Linking.
|
Finally, the UA follows the redirect, which in this case corresponds to the process specified in section 5.2 Protocol for URI query Resolution in HTTP.
The server can also decide to combine a redirect and a media fragment URI:
User → UA (1):
http://www.example.com/video.ogv#track=video1&t=10,20
The UA requests the media fragment to the server using the Range header:
The server decides not to serve the requested media fragment in terms of byte ranges and redirects the UA to an alternate representation. However, in this case, the server decides to handle the track fragment through a URI query and the temporal fragment through a URI fragment:
Finally, the UA follows the redirect, which in this case corresponds to the process specified in section 5.2 Protocol for URI query Resolution in HTTP for the track fragment, combined with the process specified in section 5.1.2 Server mapped byte ranges for the temporal fragment.