This is revision 1.2852.
a elementStatus: Last call for comments
hreftargetpingrelmediahreflangtypeinterface HTMLAnchorElement : HTMLElement {
stringifier attribute DOMString href;
attribute DOMString target;
attribute DOMString ping;
attribute DOMString rel;
readonly attribute DOMTokenList relList;
attribute DOMString media;
attribute DOMString hreflang;
attribute DOMString type;
// URL decomposition attributes
attribute DOMString protocol;
attribute DOMString host;
attribute DOMString hostname;
attribute DOMString port;
attribute DOMString pathname;
attribute DOMString search;
attribute DOMString hash;
};
If the a element has an href attribute, then it
represents a hyperlink (a hypertext
anchor).
If the a element has no href attribute, then the element
represents a placeholder for where a link might
otherwise have been placed, if it had been relevant.
The target, ping, rel, media, hreflang, and type attributes must be omitted
if the href attribute is
not present.
If a site uses a consistent navigation tool bar on every page,
then the link that would normally link to the page itself could be
marked up using an a element:
<nav> <ul> <li> <a href="/">Home</a> </li> <li> <a href="/news">News</a> </li> <li> <a>Examples</a> </li> <li> <a href="/legal">Legal</a> </li> </ul> </nav>
Interactive user agents should allow users to follow hyperlinks created using
the a element. The href, target and ping attributes decide how the
link is followed. The rel,
media, hreflang, and type attributes may be used to
indicate to the user the likely nature of the target resource before
the user follows the link.
The activation behavior of a elements
that represent hyperlinks is to run
the following steps:
If the DOMActivate
event in question is not trusted (i.e. a click() method call was the reason for the
event being dispatched), and the a element's target attribute is such that
applying the rules for choosing a browsing context given a
browsing context name, using the value of the target attribute as the
browsing context name, would result in there not being a chosen
browsing context, then raise an INVALID_ACCESS_ERR
exception and abort these steps.
If the target of the click
event is an img element with an ismap attribute specified, then
server-side image map processing must be performed, as follows:
DOMActivate
event was dispatched as the result of a real
pointing-device-triggered click
event on the img element, then let x be the distance in CSS pixels from the left edge
of the image's left border, if it has one, or the left edge of
the image otherwise, to the location of the click, and let y be the distance in CSS pixels from the top edge
of the image's top border, if it has one, or the top edge of the
image otherwise, to the location of the click. Otherwise, let
x and y be zero.Finally, the user agent must follow the hyperlink defined by the
a element. If the steps above defined a hyperlink
suffix, then take that into account when following the
hyperlink.
The DOM attributes href, ping, target, rel, media, hreflang, and type, must
reflect the respective content attributes of the same
name.
The DOM attribute relList must
reflect the rel
content attribute.
The a element also supports the complement of
URL decomposition attributes, protocol, host, port, hostname, pathname, search, and hash. These must follow the
rules given for URL decomposition attributes, with the input being the result of resolving the element's href attribute relative to the
element, if there is such an attribute and resolving it is
successful, or the empty string otherwise; and the common setter action being the
same as setting the element's href attribute to the new output
value.
The a element may be wrapped around entire
paragraphs, lists, tables, and so forth, even entire sections, so
long as there is no interactive content within (e.g. buttons or
other links). This example shows how this can be used to make an
entire advertising block into a link:
<aside class="advertising"> <h1>Advertising</h1> <a href="http://ad.example.com/?adid=1929&pubid=1422"> <section> <h1>Mellblomatic 9000!</h1> <p>Turn all your widgets into mellbloms!</p> <p>Only $9.99 plus shipping and handling.</p> </section> </a> <a href="http://ad.example.com/?adid=375&pubid=1422"> <section> <h1>The Mellblom Browser</h1> <p>Web browsing at the speed of light.</p> <p>No other browser goes faster!</p> </section> </a> </aside>
em elementStatus: Implemented and widely deployed
HTMLElement.The em element represents stress
emphasis of its contents.
The level of emphasis that a particular piece of content has is
given by its number of ancestor em elements.
The placement of emphasis changes the meaning of the sentence. The element thus forms an integral part of the content. The precise way in which emphasis is used in this way depends on the language.
These examples show how changing the emphasis changes the meaning. First, a general statement of fact, with no emphasis:
<p>Cats are cute animals.</p>
By emphasizing the first word, the statement implies that the kind of animal under discussion is in question (maybe someone is asserting that dogs are cute):
<p><em>Cats</em> are cute animals.</p>
Moving the emphasis to the verb, one highlights that the truth of the entire sentence is in question (maybe someone is saying cats are not cute):
<p>Cats <em>are</em> cute animals.</p>
By moving it to the adjective, the exact nature of the cats is reasserted (maybe someone suggested cats were mean animals):
<p>Cats are <em>cute</em> animals.</p>
Similarly, if someone asserted that cats were vegetables, someone correcting this might emphasize the last word:
<p>Cats are cute <em>animals</em>.</p>
By emphasizing the entire sentence, it becomes clear that the speaker is fighting hard to get the point across. This kind of emphasis also typically affects the punctuation, hence the exclamation mark here.
<p><em>Cats are cute animals!</em></p>
Anger mixed with emphasizing the cuteness could lead to markup such as:
<p><em>Cats are <em>cute</em> animals!</em></p>
The em element isn't a generic "italics"
element. Sometimes, text is intended to stand out from the rest of
the paragraph, as if it was in a different mood or voice. For this,
the i element is more appropriate.
The em element also isn't intended to convey
importance; for that purpose, the strong element is
more appropriate.
strong elementStatus: Implemented and widely deployed
HTMLElement.The strong element represents strong
importance for its contents.
The relative level of importance of a piece of content is given
by its number of ancestor strong elements; each
strong element increases the importance of its
contents.
Changing the importance of a piece of text with the
strong element does not change the meaning of the
sentence.
Here is an example of a warning notice in a game, with the various parts marked up according to how important they are:
<p><strong>Warning.</strong> This dungeon is dangerous. <strong>Avoid the ducks.</strong> Take any gold you find. <strong><strong>Do not take any of the diamonds</strong>, they are explosive and <strong>will destroy anything within ten meters.</strong></strong> You have been warned.</p>
small elementStatus: Last call for comments
HTMLElement.The small element represents side
comments such as small print.
Small print typically features disclaimers, caveats, legal restrictions, or copyrights. Small print is also sometimes used for attribution, or for satisfying licensing requirements.
The small element does not
"de-emphasize" or lower the importance of text emphasized by the
em element or marked as important with the
strong element.
The small element should not be used for extended
spans of text, such as multiple paragraphs, lists, or sections of
text. It is only intended for short runs of text. The text of a page
listing terms of use, for instance, would not be a suitable
candidate for the small element: in such a case, the
text is not a side comment, it is the main content of the page.
In this example the footer contains contact information and a copyright notice.
<footer> <address> For more details, contact <a href="mailto:js@example.com">John Smith</a>. </address> <p><small>© copyright 2038 Example Corp.</small></p> </footer>
In this second example, the small element is used
for a side comment in an article.
<p>Example Corp today announced record profits for the second quarter <small>(Full Disclosure: Foo News is a subsidiary of Example Corp)</small>, leading to speculation about a third quarter merger with Demo Group.</p>
This is distinct from a sidebar, which might be multiple paragraphs long and is removed from the main flow of text. In the following example, we see a sidebar from the same article. This sidebar also has small print, indicating the source of the information in the sidebar.
<aside> <h1>Example Corp</h1> <p>This company mostly creates small software and Web sites.</p> <p>The Example Corp company mission is "To provide entertainment and news on a sample basis".</p> <p><small>Information obtained from <a href="http://example.com/about.html">example.com</a> home page.</small></p> </aside>
In this last example, the small element is marked
as being important small print.
<p><strong><small>Continued use of this service will result in a kiss.</small></strong></p>
cite elementStatus: Implemented and widely deployed
HTMLElement.The cite element represents the title
of a work (e.g.
a book,
a paper,
an essay,
a poem,
a score,
a song,
a script,
a film,
a TV show,
a game,
a sculpture,
a painting,
a theatre production,
a play,
an opera,
a musical,
an exhibition,
a legal case report,
etc). This can be a work that is being quoted or
referenced in detail (i.e. a citation), or it can just be a work
that is mentioned in passing.
A person's name is not the title of a work — even if people
call that person a piece of work — and the element must
therefore not be used to mark up people's names. (In some cases, the
b element might be appropriate for names; e.g. in a
gossip article where the names of famous people are keywords
rendered with a different style to draw attention to them. In other
cases, if an element is really needed, the
span element can be used.)
A ship is similarly not a work, and the element must not be used
to mark up ship names (the i element can be used for
that purpose).
This next example shows a typical use of the cite
element:
<p>My favorite book is <cite>The Reality Dysfunction</cite> by Peter F. Hamilton. My favorite comic is <cite>Pearls Before Swine</cite> by Stephan Pastis. My favorite track is <cite>Jive Samba</cite> by the Cannonball Adderley Sextet.</p>
This is correct usage:
<p>According to the Wikipedia article <cite>HTML</cite>, as it stood in mid-February 2008, leaving attribute values unquoted is unsafe. This is obviously an over-simplification.</p>
The following, however, is incorrect usage, as the
cite element here is containing far more than the
title of the work:
<!-- do not copy this example, it is an example of bad usage! --> <p>According to <cite>the Wikipedia article on HTML</cite>, as it stood in mid-February 2008, leaving attribute values unquoted is unsafe. This is obviously an over-simplification.</p>
The cite element is obviously a key part of any
citation in a bibliography, but it is only used to mark the
title:
<p><cite>Universal Declaration of Human Rights</cite>, United Nations, December 1948. Adopted by General Assembly resolution 217 A (III).</p>
A citation is not a quote (for
which the q element is appropriate).
This is incorrect usage, because cite is not for
quotes:
<p><cite>This is wrong!</cite>, said Ian.</p>
This is also incorrect usage, because a person is not a work:
<p><q>This is still wrong!</q>, said <cite>Ian</cite>.</p>
The correct usage does not use a cite element:
<p><q>This is correct</q>, said Ian.</p>
As mentioned above, the b element might be relevant
for marking names as being keywords in certain kinds of
documents:
<p>And then <b>Ian</b> said <q>this might be right, in a gossip column, maybe!</q>.</p>
q elementStatus: Working draft. ISSUE-48 (UA-q-quotes) blocks progress to Last Call
citeq element uses the HTMLQuoteElement interface.
The q element represents some phrasing content quoted from another
source.
Quotation punctuation (such as quotation marks) must not appear
immediately before, after, or inside q elements; they
will be inserted into the rendering by the user agent.
Content inside a q element must be quoted from
another source, whose address, if it has one, should be cited in the
cite attribute. The
source may be fictional, as when quoting characters in a novel or
screenplay.
If the cite attribute is
present, it must be a valid URL. To obtain the
corresponding citation link, the value of the attribute must be
resolved relative to the
element. User agents should allow users to follow such citation
links.
The q element must not be used in place of quotation
marks that do not represent quotes; for example, it is inappropriate
to use the q element for marking up sarcastic
statements.
The use of q elements to mark up quotations is
entirely optional; using explicit quotation punctuation without
q elements is just as correct.
Here is a simple example of the use of the q
element:
<p>The man said <q>Things that are impossible just take longer</q>. I disagreed with him.</p>
Here is an example with both an explicit citation link in the
q element, and an explicit citation outside:
<p>The W3C page <cite>About W3C</cite> says the W3C's mission is <q cite="http://www.w3.org/Consortium/">To lead the World Wide Web to its full potential by developing protocols and guidelines that ensure long-term growth for the Web</q>. I disagree with this mission.</p>
In the following example, the quotation itself contains a quotation:
<p>In <cite>Example One</cite>, he writes <q>The man said <q>Things that are impossible just take longer</q>. I disagreed with him</q>. Well, I disagree even more!</p>
In the following example, quotation marks are used instead of
the q element:
<p>His best argument was ❝I disagree❞, which I thought was laughable.</p>
In the following example, there is no quote — the
quotation marks are used to name a word. Use of the q
element in this case would be inappropriate.
<p>The word "ineffable" could have been used to describe the disaster resulting from the campaign's mismanagement.</p>
dfn elementStatus: Last call for comments
dfn elements.title attribute has special semantics on this element.HTMLElement.The dfn element represents the defining
instance of a term. The paragraph,
description list group, or section that is the nearest
ancestor of the dfn element must also contain the
definition(s) for the term given
by the dfn element.
Defining term: If the dfn element has a
title attribute, then
the exact value of that attribute is the term being defined.
Otherwise, if it contains exactly one element child node and no
child text nodes, and that child
element is an abbr element with a title attribute, then the exact value
of that attribute is the term being defined. Otherwise, it
is the exact textContent of the dfn
element that gives the term being defined.
If the title attribute of the
dfn element is present, then it must contain only the
term being defined.
The title attribute
of ancestor elements does not affect dfn elements.
An a element that links to a dfn
element represents an instance of the term defined by the
dfn element.
In the following fragment, the term "GDO" is first defined in the first paragraph, then used in the second.
<p>The <dfn><abbr title="Garage Door Opener">GDO</abbr></dfn> is a device that allows off-world teams to open the iris.</p> <!-- ... later in the document: --> <p>Teal'c activated his <abbr title="Garage Door Opener">GDO</abbr> and so Hammond ordered the iris to be opened.</p>
With the addition of an a element, the reference
can be made explicit:
<p>The <dfn id=gdo><abbr title="Garage Door Opener">GDO</abbr></dfn> is a device that allows off-world teams to open the iris.</p> <!-- ... later in the document: --> <p>Teal'c activated his <a href=#gdo><abbr title="Garage Door Opener">GDO</abbr></a> and so Hammond ordered the iris to be opened.</p>
abbr elementStatus: Implemented and widely deployed
title attribute has special semantics on this element.HTMLElement.The abbr element represents an
abbreviation or acronym, optionally with its expansion. The title attribute may be
used to provide an expansion of the abbreviation. The attribute, if
specified, must contain an expansion of the abbreviation, and
nothing else.
The paragraph below contains an abbreviation marked up with the
abbr element. This paragraph defines the term "Web Hypertext Application Technology
Working Group".
<p>The <dfn id=whatwg><abbr title="Web Hypertext Application Technology Working Group">WHATWG</abbr></dfn> is a loose unofficial collaboration of Web browser manufacturers and interested parties who wish to develop new technologies designed to allow authors to write and deploy Applications over the World Wide Web.</p>
An alternative way to write this would be:
<p>The <dfn id=whatwg>Web Hypertext Application Technology Working Group</dfn> (<abbr title="Web Hypertext Application Technology Working Group">WHATWG</abbr>) is a loose unofficial collaboration of Web browser manufacturers and interested parties who wish to develop new technologies designed to allow authors to write and deploy Applications over the World Wide Web.</p>
This paragraph has two abbreviations. Notice how only one is
defined; the other, with no expansion associated with it, does not
use the abbr element.
<p>The <abbr title="Web Hypertext Application Technology Working Group">WHATWG</abbr> started working on HTML 5 in 2004.</p>
This paragraph links an abbreviation to its definition.
<p>The <a href="#whatwg"><abbr title="Web Hypertext Application Technology Working Group">WHATWG</abbr></a> community does not have much representation from Asia.</p>
This paragraph marks up an abbreviation without giving an expansion, possibly as a hook to apply styles for abbreviations (e.g. smallcaps).
<p>Philip` and Dashiva both denied that they were going to get the issue counts from past revisions of the specification to backfill the <abbr>WHATWG</abbr> issue graph.</p>
If an abbreviation is pluralized, the expansion's grammatical number (plural vs singular) must match the grammatical number of the contents of the element.
Here the plural is outside the element, so the expansion is in the singular:
<p>Two <abbr title="Working Group">WG</abbr>s worked on this specification: the <abbr>WHATWG</abbr> and the <abbr>HTMLWG</abbr>.</p>
Here the plural is inside the element, so the expansion is in the plural:
<p>Two <abbr title="Working Groups">WGs</abbr> worked on this specification: the <abbr>WHATWG</abbr> and the <abbr>HTMLWG</abbr>.</p>
Abbreviations do not have to be marked up using this element. It is expected to be useful in the following cases:
abbr element with a title attribute is an alternative to
including the expansion inline (e.g. in parentheses).abbr element with a title attribute or include the expansion
inline in the text the first time the abbreviation is used.abbr element
can be used without a title
attribute.Providing an expansion in a title attribute once will not necessarily
cause other abbr elements in the same document with the
same contents but without a title
attribute to behave as if they had the same expansion. Every
abbr element is independent.
code elementStatus: Implemented and widely deployed
HTMLElement.The code element represents a fragment
of computer code. This could be an XML element name, a filename, a
computer program, or any other string that a computer would
recognize.
Although there is no formal way to indicate the language of
computer code being marked up, authors who wish to mark
code elements with the language used, e.g. so that
syntax highlighting scripts can use the right rules, may do so by
adding a class prefixed with "language-" to
the element.
The following example shows how the element can be used in a paragraph to mark up element names and computer code, including punctuation.
<p>The <code>code</code> element represents a fragment of computer code.</p> <p>When you call the <code>activate()</code> method on the <code>robotSnowman</code> object, the eyes glow.</p> <p>The example below uses the <code>begin</code> keyword to indicate the start of a statement block. It is paired with an <code>end</code> keyword, which is followed by the <code>.</code> punctuation character (full stop) to indicate the end of the program.</p>
The following example shows how a block of code could be marked
up using the pre and code elements.
<pre><code class="language-pascal">var i: Integer; begin i := 1; end.</code></pre>
A class is used in that example to indicate the language used.
See the pre element for more details.
var elementStatus: Implemented and widely deployed
HTMLElement.The var element represents a
variable. This could be an actual variable in a mathematical
expression or programming context, or it could just be a term used
as a placeholder in prose.
In the paragraph below, the letter "n" is being used as a variable in prose:
<p>If there are <var>n</var> pipes leading to the ice cream factory then I expect at <em>least</em> <var>n</var> flavors of ice cream to be available for purchase!</p>
For mathematics, in particular for anything beyond the simplest
of expressions, MathML is more appropriate. However, the
var element can still be used to refer to specific
variables that are then mentioned in MathML expressions.
In this example, an equation is shown, with a legend that
references the variables in the equation. The expression itself is
marked up with MathML, but the variables are mentioned in the
figure's legend using var.
<figure> <math> <mi>a</mi> <mo>=</mo> <msqrt> <msup><mi>b</mi><mn>2</mn></msup> <mi>+</mi> <msup><mi>c</mi><mn>2</mn></msup> </msqrt> </math> <legend> Using Pythagoras' theorem to solve for the hypotenuse <var>a</var> of a triangle with sides <var>b</var> and <var>c</var> </legend> </figure>
samp elementStatus: Implemented and widely deployed
HTMLElement.The samp element represents (sample)
output from a program or computing system.
See the pre and kbd
elements for more details.
This example shows the samp element being used
inline:
<p>The computer said <samp>Too much cheese in tray two</samp> but I didn't know what that meant.</p>
This second example shows a block of sample output. Nested
samp and kbd elements allow for the
styling of specific elements of the sample output using a
style sheet.
<pre><samp><span class="prompt">jdoe@mowmow:~$</span> <kbd>ssh demo.example.com</kbd> Last login: Tue Apr 12 09:10:17 2005 from mowmow.example.com on pts/1 Linux demo 2.6.10-grsec+gg3+e+fhs6b+nfs+gr0501+++p3+c4a+gr2b-reslog-v6.189 #1 SMP Tue Feb 1 11:22:36 PST 2005 i686 unknown <span class="prompt">jdoe@demo:~$</span> <span class="cursor">_</span></samp></pre>
kbd elementStatus: Implemented and widely deployed
HTMLElement.The kbd element represents user input
(typically keyboard input, although it may also be used to represent
other input, such as voice commands).
When the kbd element is nested inside a
samp element, it represents the input as it was echoed
by the system.
When the kbd element contains a
samp element, it represents input based on system
output, for example invoking a menu item.
When the kbd element is nested inside another
kbd element, it represents an actual key or other
single unit of input as appropriate for the input mechanism.
Here the kbd element is used to indicate keys to press:
<p>To make George eat an apple, press <kbd><kbd>Shift</kbd>+<kbd>F3</kbd></kbd></p>
In this second example, the user is told to pick a particular
menu item. The outer kbd element marks up a block of
input, with the inner kbd elements representing each
individual step of the input, and the samp elements
inside them indicating that the steps are input based on something
being displayed by the system, in this case menu labels:
<p>To make George eat an apple, select
<kbd><kbd><samp>File</samp></kbd>|<kbd><samp>Eat Apple...</samp></kbd></kbd>
</p>
Such precision isn't necessary; the following is equally fine:
<p>To make George eat an apple, select <kbd>File | Eat Apple...</kbd></p>
sub and sup elementsStatus: Implemented and widely deployed
HTMLElement.The sup element represents a
superscript and the sub element represents
a subscript.
These elements must be used only to mark up typographical
conventions with specific meanings, not for typographical
presentation for presentation's sake. For example, it would be
inappropriate for the sub and sup elements
to be used in the name of the LaTeX document preparation system. In
general, authors should use these elements only if the
absence of those elements would change the meaning of the
content.
In certain languages, superscripts are part of the typographical conventions for some abbreviations.
<p>The most beautiful women are <span lang="fr"><abbr>M<sup>lle</sup></abbr> Gwendoline</span> and <span lang="fr"><abbr>M<sup>me</sup></abbr> Denise</span>.</p>
The sub element can be used inside a
var element, for variables that have subscripts.
Here, the sub element is used to represents the
subscript that identifies the variable in a family of
variables:
<p>The coordinate of the <var>i</var>th point is (<var>x<sub><var>i</var></sub></var>, <var>y<sub><var>i</var></sub></var>). For example, the 10th point has coordinate (<var>x<sub>10</sub></var>, <var>y<sub>10</sub></var>).</p>
Mathematical expressions often use subscripts and superscripts.
Authors are encouraged to use MathML for marking up mathematics, but
authors may opt to use sub and sup if
detailed mathematical markup is not desired. [MATHML]
<var>E</var>=<var>m</var><var>c</var><sup>2</sup>
f(<var>x</var>, <var>n</var>) = log<sub>4</sub><var>x</var><sup><var>n</var></sup>
i elementStatus: Implemented and widely deployed
HTMLElement.The i element represents a span of text
in an alternate voice or mood, or otherwise offset from the normal
prose, such as a taxonomic designation, a technical term, an
idiomatic phrase from another language, a thought, a ship name, or
some other prose whose typical typographic presentation is
italicized.
Terms in languages different from the main text should be
annotated with lang attributes (or,
in XML, lang
attributes in the XML namespace).
The examples below show uses of the i element:
<p>The <i class="taxonomy">Felis silvestris catus</i> is cute.</p> <p>The term <i>prose content</i> is defined above.</p> <p>There is a certain <i lang="fr">je ne sais quoi</i> in the air.</p>
In the following example, a dream sequence is marked up using
i elements.
<p>Raymond tried to sleep.</p> <p><i>The ship sailed away on Thursday</i>, he dreamt. <i>The ship had many people aboard, including a beautiful princess called Carey. He watched her, day-in, day-out, hoping she would notice him, but she never did.</i></p> <p><i>Finally one night he picked up the courage to speak with her—</i></p> <p>Raymond woke with a start as the fire alarm rang out.</p>
Authors are encouraged to use the class attribute on the i
element to identify why the element is being used, so that if the
style of a particular use (e.g. dream sequences as opposed to
taxonomic terms) is to be changed at a later date, the author
doesn't have to go through the entire document (or series of related
documents) annotating each use. Similarly, authors are encouraged to
consider whether other elements might be more applicable than the
i element, for instance the em element for
marking up stress emphasis, or the dfn element to mark
up the defining instance of a term.
Style sheets can be used to format i
elements, just like any other element can be restyled. Thus, it is
not the case that content in i elements will
necessarily be italicized.
b elementStatus: Implemented and widely deployed
HTMLElement.The b element represents a span of text
to be stylistically offset from the normal prose without conveying
any extra importance, such as key words in a document abstract,
product names in a review, or other spans of text whose typical
typographic presentation is boldened.
The following example shows a use of the b element
to highlight key words without marking them up as important:
<p>The <b>frobonitor</b> and <b>barbinator</b> components are fried.</p>
In the following example, objects in a text adventure are
highlighted as being special by use of the b
element.
<p>You enter a small room. Your <b>sword</b> glows brighter. A <b>rat</b> scurries past the corner wall.</p>
Another case where the b element is appropriate is
in marking up the lede (or lead) sentence or paragraph. The
following example shows how a BBC
article about kittens adopting a rabbit as their own could be
marked up:
<article> <h2>Kittens 'adopted' by pet rabbit</h2> <p><b>Six abandoned kittens have found an unexpected new mother figure — a pet rabbit.</b></p> <p>Veterinary nurse Melanie Humble took the three-week-old kittens to her Aberdeen home.</p> [...]
The b element should be used as a last resort when
no other element is more appropriate. In particular, headings should
use the h1 to h6 elements, stress emphasis
should use the em element, importance should be denoted
with the strong element, and text marked or highlighted
should use the mark element.
The following would be incorrect usage:
<p><b>WARNING!</b> Do not frob the barbinator!</p>
In the previous example, the correct element to use would have
been strong, not b.
Style sheets can be used to format b
elements, just like any other element can be restyled. Thus, it is
not the case that content in b elements will
necessarily be boldened.
mark elementStatus: Working draft
HTMLElement.The mark element represents a run of
text in one document marked or highlighted for reference purposes,
due to its relevance in another context. When used in a quotation or
other block of text referred to from the prose, it indicates a
highlight that was not originally present but which has been added
to bring the reader's attention to a part of the text that might not
have been considered important by the original author when the block
was originally written, but which is now under previously unexpected
scrutiny. When used in the main prose of a document, it indicates a
part of the document that has been highlighted due to its likely
relevance to the user's current activity.
This example shows how the mark element can be used
to bring attention to a particular part of a quotation:
<p lang="en-US">Consider the following quote:</p> <blockquote lang="en-GB"> <p>Look around and you will find, no-one's really <mark>colour</mark> blind.</p> </blockquote> <p lang="en-US">As we can tell from the <em>spelling</em> of the word, the person writing this quote is clearly not American.</p>
Another example of the mark element is highlighting
parts of a document that are matching some search string. If
someone looked at a document, and the server knew that the user was
searching for the word "kitten", then the server might return the
document with one paragraph modified as follows:
<p>I also have some <mark>kitten</mark>s who are visiting me these days. They're really cute. I think they like my garden! Maybe I should adopt a <mark>kitten</mark>.</p>
In the following snippet, a paragraph of text refers to a specific part of a code fragment.
<p>The highlighted part below is where the error lies:</p> <pre><code>var i: Integer; begin i := <mark>1.1</mark>; end.</code></pre>
This is another example showing the use of mark to
highlight a part of quoted text that was originally not
emphasized. In this example, common typographic conventions have
led the author to explicitly style mark elements in
quotes to render in italics.
<article>
<style>
blockquote mark, q mark {
font: inherit; font-style: italic;
text-decoration: none;
background: transparent; color: inherit;
}
.bubble em {
font: inherit; font-size: larger;
text-decoration: underline;
}
</style>
<h1>She knew</h1>
<p>Did you notice the subtle joke in the joke on panel 4?</p>
<blockquote>
<p class="bubble">I didn't <em>want</em> to believe. <mark>Of course
on some level I realized it was a known-plaintext attack.</mark> But I
couldn't admit it until I saw for myself.</p>
</blockquote>
<p>(Emphasis mine.) I thought that was great. It's so pedantic, yet it
explains everything neatly.</p>
</article>
Note, incidentally, the distinction between the em
element in this example, which is part of the original text being
quoted, and the mark element, which is highlighting a
part for comment.
The following example shows the difference between denoting the
importance of a span of text (strong) as
opposed to denoting the relevance of a span of text
(mark). It is an extract from a textbook, where the
extract has had the parts relevant to the exam highlighted. The
safety warnings, important though they may be, are apparently not
relevant to the exam.
<h3>Wormhole Physics Introduction</h3> <p><mark>A wormhole in normal conditions can be held open for a maximum of just under 39 minutes.</mark> Conditions that can increase the time include a powerful energy source coupled to one or both of the gates connecting the wormhole, and a large gravity well (such as a black hole).</p> <p><mark>Momentum is preserved across the wormhole. Electromagnetic radiation can travel in both directions through a wormhole, but matter cannot.</mark></p> <p>When a wormhole is created, a vortex normally forms. <strong>Warning: The vortex caused by the wormhole opening will annihilate anything in its path.</strong> Vortexes can be avoided when using sufficiently advanced dialing technology.</p> <p><mark>An obstruction in a gate will prevent it from accepting a wormhole connection.</mark></p>
progress elementStatus: Working draft
valuemaxinterface HTMLProgressElement : HTMLElement {
attribute float value;
attribute float max;
readonly attribute float position;
};
The progress element represents the
completion progress of a task. The progress is either indeterminate,
indicating that progress is being made but that it is not clear how
much more work remains to be done before the task is complete
(e.g. because the task is waiting for a remote host to respond), or
the progress is a number in the range zero to a maximum, giving the
fraction of work that has so far been completed.
There are two attributes that determine the current task completion represented by the element.
The value
attribute specifies how much of the task has been completed, and the
max attribute
specifies how much work the task requires in total. The units are
arbitrary and not specified.
Instead of using the attributes, authors are recommended to include the current value and the maximum value inline as text inside the element.
Here is a snippet of a Web application that shows the progress of some automated task:
<section>
<h2>Task Progress</h2>
<p>Progress: <progress><span id="p">0</span>%</progress></p>
<script>
var progressBar = document.getElementById('p');
function updateProgress(newValue) {
progressBar.textContent = newValue;
}
</script>
</section>
(The updateProgress() method in this example would
be called by some other code on the page to update the actual
progress bar as the task progressed.)
Author requirements: The max and value attributes, when present,
must have values that are valid floating point numbers. The max attribute, if present, must
have a value greater than zero. The value attribute, if present, must
have a value equal to or greater than zero, and less than or equal
to the value of the max
attribute, if present, or 1, otherwise.
The progress element is the wrong
element to use for something that is just a gauge, as opposed to
task progress. For instance, indicating disk space usage using
progress would be inappropriate. Instead, the
meter element is available for such use cases.
User agent requirements: User agents must parse
the max and value attributes' values
according to the rules for parsing floating point number
values.
If the value attribute
is omitted, then user agents must also parse the
textContent of the progress element in
question using the steps for finding one or two numbers of a
ratio in a string. These steps will return nothing, one
number, one number with a denominator punctuation character, or two
numbers.
Using the results of this processing, user agents must determine whether the progress bar is an indeterminate progress bar, or whether it is a determinate progress bar, and in the latter case, what its current and maximum values are, all as follows:
max attribute is
omitted, and the value is
omitted, and the results of parsing the textContent
was nothing, then the progress bar is an indeterminate progress
bar. Abort these steps.max attribute is
included, then, if a value could be parsed out of it, then the
maximum value is that value.max
attribute is absent but the value attribute is present, or,
if the max attribute is
present but no value could be parsed from it, then the maximum is
1.textContent contained one number with an associated
denominator punctuation character, then the maximum value is the
value associated with that denominator punctuation
character; otherwise, if the textContent
contained two numbers, the maximum value is the higher of the two
values; otherwise, the maximum value is 1.value attribute
is present on the element and a value could be parsed out of it,
that value is the current value of the progress bar. Otherwise, if
the attribute is present but no value could be parsed from it, the
current value is zero.value
attribute is absent and the max attribute is present, then, if
the textContent was parsed and found to contain just
one number, with no associated denominator punctuation character,
then the current value is that number. Otherwise, if the value attribute is absent and
the max attribute is present
then the current value is zero.textContent of the element.UA requirements for showing the progress bar:
When representing a progress element to the user, the
UA should indicate whether it is a determinate or indeterminate
progress bar, and in the former case, should indicate the relative
position of the current value relative to the maximum value.
The max and value DOM attributes
must reflect the respective content attributes of the
same name. When the relevant content attributes are absent, the DOM
attributes must return zero. The value parsed from the
textContent never affects the DOM values.
positionFor a determinate progress bar (one with known current and maximum values), returns the result of dividing the current value by the maximum value.
For an indeterminate progress bar, returns −1.
If the progress bar is an indeterminate progress bar, then the
position DOM
attribute must return −1. Otherwise, it must return the result of
dividing the current value by the maximum value.
meter elementStatus: Working draft
valueminlowhighmaxoptimuminterface HTMLMeterElement : HTMLElement {
attribute float value;
attribute float min;
attribute float max;
attribute float low;
attribute float high;
attribute float optimum;
};
The meter element represents a scalar
measurement within a known range, or a fractional value; for example
disk usage, the relevance of a query result, or the fraction of a
voting population to have selected a particular candidate.
This is also known as a gauge.
The meter element should not be used to
indicate progress (as in a progress bar). For that role, HTML
provides a separate progress element.
The meter element also does not
represent a scalar value of arbitrary range — for example, it
would be wrong to use this to report a weight, or height, unless
there is a known maximum value.
There are six attributes that determine the semantics of the gauge represented by the element.
The min attribute
specifies the lower bound of the range, and the max attribute specifies
the upper bound. The value attribute
specifies the value to have the gauge indicate as the "measured"
value.
The other three attributes can be used to segment the gauge's
range into "low", "medium", and "high" parts, and to indicate which
part of the gauge is the "optimum" part. The low attribute specifies
the range that is considered to be the "low" part, and the high attribute specifies
the range that is considered to be the "high" part. The optimum attribute
gives the position that is "optimum"; if that is higher than the
"high" value then this indicates that the higher the value, the
better; if it's lower than the "low" mark then it indicates that
lower values are better, and naturally if it is in between then it
indicates that neither high nor low values are good.
Authoring requirements: The recommended way of giving the value is to include it as contents of the element, either as two numbers (the higher number represents the maximum, the other number the current value, and the minimum is assumed to be zero), or as a percentage or similar (using one of the characters such as "%"), or as a fraction. However, it is also possible to use the attributes to specify these values.
One of the following conditions, along with all the requirements that are listed with that condition, must be met:
value, min, and max attributes are all omittedIf specified, the low,
high, and optimum attributes must have
values greater than or equal to zero and less than or equal to the
bigger of the two numbers in the contents of the element.
If both the low and high attributes are specified, then
the low attribute's value must
be less than or equal to the value of the high attribute.
value, min, and max attributes are all omittedIf specified, the low,
high, and optimum attributes must have
values greater than or equal to zero and less than or equal to the
value associated with the denominator punctuation
character.
If both the low and high attributes are specified, then
the low attribute's value must
be less than or equal to the value of the high attribute.
value attribute is
omittedvalue attribute is
specifiedIf the min attribute
attribute is specified, then the minimum is
that attribute's value; otherwise, it is 0.
If the max attribute
attribute is specified, then the maximum is
that attribute's value; otherwise, it is 1.
If there is exactly one number in the contents of the element,
then value is that number; otherwise, value is the value of the value attribute.
The following inequalities must hold, as applicable:
low ≤ maximum (if low is specified)high ≤ maximum (if high is specified)optimum ≤ maximum (if optimum is specified)If both the low and high attributes are specified, then
the low attribute's value must
be less than or equal to the value of the high attribute.
For the purposes of these requirements, a number is a sequence of characters in the range U+0030 DIGIT ZERO (0) to U+0039 DIGIT NINE (9), optionally including with a single U+002E FULL STOP character (.), and separated from other numbers by at least one character that isn't any of those; interpreted as a base ten number.
The value, min, low, high, max, and optimum attributes, when present,
must have values that are valid floating point numbers.
If no minimum or maximum is specified, then the range is assumed to be 0..1, and the value thus has to be within that range.
The following examples all represent a measurement of three quarters (of the maximum of whatever is being measured):
<meter>75%</meter> <meter>750‰</meter> <meter>3/4</meter> <meter>6 blocks used (out of 8 total)</meter> <meter>max: 100; current: 75</meter> <meter><object data="graph75.png">0.75</object></meter> <meter min="0" max="100" value="75"></meter>
The following example is incorrect use of the element, because it doesn't give a range (and since the default maximum is 1, both of the gauges would end up looking maxed out):
<p>The grapefruit pie had a radius of <meter>12cm</meter> and a height of <meter>2cm</meter>.</p> <!-- BAD! -->
Instead, one would either not include the meter element, or use the meter element with a defined range to give the dimensions in context compared to other pies:
<p>The grapefruit pie had a radius of 12cm and a height of 2cm.</p> <dl> <dt>Radius: <dd> <meter min=0 max=20 value=12>12cm</meter> <dt>Height: <dd> <meter min=0 max=10 value=2>2cm</meter> </dl>
There is no explicit way to specify units in the
meter element, but the units may be specified in the
title attribute in free-form text.
The example above could be extended to mention the units:
<dl> <dt>Radius: <dd> <meter min=0 max=20 value=12 title="centimeters">12cm</meter> <dt>Height: <dd> <meter min=0 max=10 value=2 title="centimeters">2cm</meter> </dl>
User agent requirements: User agents must parse
the min, max, value, low, high, and optimum attributes using the
rules for parsing floating point number values.
If the value attribute has
been omitted, the user agent must also process the
textContent of the element according to the steps
for finding one or two numbers of a ratio in a string. These
steps will return nothing, one number, one number with a denominator
punctuation character, or two numbers.
User agents must then use all these numbers to obtain values for six points on the gauge, as follows. (The order in which these are evaluated is important, as some of the values refer to earlier ones.)
If the min attribute is
specified and a value could be parsed out of it, then the minimum
value is that value. Otherwise, the minimum value is zero.
If the max attribute is
specified and a value could be parsed out of it, the maximum
value is that value.
Otherwise, if the max
attribute is specified but no value could be parsed out of it, or
if it was not specified, but either or both of the min or value attributes were
specified, then the maximum value is 1.
Otherwise, none of the max,
min, and value attributes were
specified. If the result of processing the
textContent of the element was either nothing or just
one number with no denominator punctuation character, then the
maximum value is 1; if the result was one number but it had an
associated denominator punctuation character, then the maximum
value is the value associated with that denominator
punctuation character; and finally, if there were two
numbers parsed out of the textContent, then the
maximum is the higher of those two numbers.
If the above machinations result in a maximum value less than the minimum value, then the maximum value is actually the same as the minimum value.
If the value attribute is
specified and a value could be parsed out of it, then that value
is the actual value.
If the value attribute is
not specified but the max
attribute is specified and the result of processing the
textContent of the element was one number with no
associated denominator punctuation character, then that number is
the actual value.
If neither of the value
and max attributes are
specified, then, if the result of processing the
textContent of the element was one number (with or
without an associated denominator punctuation character), then
that is the actual value, and if the result of processing the
textContent of the element was two numbers, then the
actual value is the lower of the two numbers found.
Otherwise, if none of the above apply, the actual value is zero.
If the above procedure results in an actual value less than the minimum value, then the actual value is actually the same as the minimum value.
If, on the other hand, the result is an actual value greater than the maximum value, then the actual value is the maximum value.
If the low attribute is
specified and a value could be parsed out of it, then the low
boundary is that value. Otherwise, the low boundary is the same as
the minimum value.
If the low boundary is then less than the minimum value, then the low boundary is actually the same as the minimum value. Similarly, if the low boundary is greater than the maximum value, then it is actually the maximum value instead.
If the high attribute is
specified and a value could be parsed out of it, then the high
boundary is that value. Otherwise, the high boundary is the same
as the maximum value.
If the high boundary is then less than the low boundary, then the high boundary is actually the same as the low boundary. Similarly, if the high boundary is greater than the maximum value, then it is actually the maximum value instead.
If the optimum
attribute is specified and a value could be parsed out of it, then
the optimum point is that value. Otherwise, the optimum point is
the midpoint between the minimum value and the maximum value.
If the optimum point is then less than the minimum value, then the optimum point is actually the same as the minimum value. Similarly, if the optimum point is greater than the maximum value, then it is actually the maximum value instead.
All of which will result in the following inequalities all being true:
UA requirements for regions of the gauge: If the optimum point is equal to the low boundary or the high boundary, or anywhere in between them, then the region between the low and high boundaries of the gauge must be treated as the optimum region, and the low and high parts, if any, must be treated as suboptimal. Otherwise, if the optimum point is less than the low boundary, then the region between the minimum value and the low boundary must be treated as the optimum region, the region between the low boundary and the high boundary must be treated as a suboptimal region, and the region between the high boundary and the maximum value must be treated as an even less good region. Finally, if the optimum point is higher than the high boundary, then the situation is reversed; the region between the high boundary and the maximum value must be treated as the optimum region, the region between the high boundary and the low boundary must be treated as a suboptimal region, and the remaining region between the low boundary and the minimum value must be treated as an even less good region.
UA requirements for showing the gauge: When
representing a meter element to the user, the UA should
indicate the relative position of the actual value to the minimum
and maximum values, and the relationship between the actual value
and the three regions of the gauge.
The following markup:
<h3>Suggested groups</h3>
<menu type="toolbar">
<a href="?cmd=hsg" onclick="hideSuggestedGroups()">Hide suggested groups</a>
</menu>
<ul>
<li>
<p><a href="/group/comp.infosystems.www.authoring.stylesheets/view">comp.infosystems.www.authoring.stylesheets</a> -
<a href="/group/comp.infosystems.www.authoring.stylesheets/subscribe">join</a></p>
<p>Group description: <strong>Layout/presentation on the WWW.</strong></p>
<p><meter value="0.5">Moderate activity,</meter> Usenet, 618 subscribers</p>
</li>
<li>
<p><a href="/group/netscape.public.mozilla.xpinstall/view">netscape.public.mozilla.xpinstall</a> -
<a href="/group/netscape.public.mozilla.xpinstall/subscribe">join</a></p>
<p>Group description: <strong>Mozilla XPInstall discussion.</strong></p>
<p><meter value="0.25">Low activity,</meter> Usenet, 22 subscribers</p>
</li>
<li>
<p><a href="/group/mozilla.dev.general/view">mozilla.dev.general</a> -
<a href="/group/mozilla.dev.general/subscribe">join</a></p>
<p><meter value="0.25">Low activity,</meter> Usenet, 66 subscribers</p>
</li>
</ul>
Might be rendered as follows:
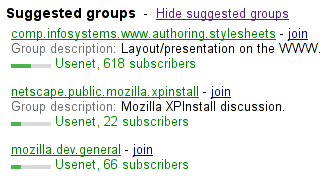
User agents may combine the value of the title attribute and the other attributes
to provide context-sensitive help or inline text detailing the
actual values.
For example, the following snippet:
<meter min=0 max=60 value=23.2 title=seconds></meter>
...might cause the user agent to display a gauge with a tooltip saying "Value: 23.2 out of 60." on one line and "seconds" on a second line.
The min, max, value, low, high, and optimum DOM attributes
must reflect the respective content attributes of the
same name. When the relevant content attributes are absent, the DOM
attributes must return zero. The value parsed from the
textContent never affects the DOM values.
time elementStatus: Working draft
datetimeinterface HTMLTimeElement : HTMLElement {
attribute DOMString dateTime;
readonly attribute Date date;
readonly attribute Date time;
readonly attribute Date timezone;
};
The time element represents either a
time on a 24 hour clock, or a precise date in the proleptic
Gregorian calendar, optionally with a time and a time zone. [GREGORIAN]
This element is intended as a way to encode modern dates and times in a machine-readable way so that user agents can offer to add them to the user's calendar. For example, adding birthday reminders or scheduling events.
The time element is not intended for encoding times
for which a precise date or time cannot be established. For
example, it would be inappropriate for encoding times like "one
millisecond after the big bang", "the early part of the Jurassic
period", or "a winter around 250 BCE".
For dates before the introduction of the Gregorian calendar,
authors are encouraged to not use the time element, or
else to be very careful about converting dates and times from the
period to the Gregorian calendar. This is complicated by the manner
in which the Gregorian calendar was phased in, which occurred at
different times in different countries, ranging from partway
through the 16th century all the way to early in the 20th.
The datetime
attribute, if present, must contain a valid date or time
string that identifies the date or time being specified.
If the datetime attribute
is not present, then the date or time must be specified in the
content of the element, such that the element's
textContent is a valid date or time string in
content, and the date, if any, must be expressed using the
Gregorian calendar.
If the datetime attribute
is present, then the element may be empty, in which case the user
agent should convey the attribute's value to the user when rendering
the element.
The time element can be used to encode dates, for
example in Microformats. The following shows a hypothetical way of
encoding an event using a variant on hCalendar that uses the
time element:
<div class="vevent"> <a class="url" href="http://www.web2con.com/">http://www.web2con.com/</a> <span class="summary">Web 2.0 Conference</span>: <time class="dtstart" datetime="2007-10-05">October 5</time> - <time class="dtend" datetime="2007-10-20">19</time>, at the <span class="location">Argent Hotel, San Francisco, CA</span> </div>
The time element is not necessary for encoding
dates or times. In the following snippet, the time is encoded using
time, so that it can be restyled (e.g. using XBL2) to
match local conventions, while the year is not marked up at all,
since marking it up would not be particularly useful.
<p>I usually have a snack at <time>16:00</time>.</p> <p>I've liked model trains since at least 1983.</p>
Using a styling technology that supports restyling times, the first paragraph from the above snippet could be rendered as follows:
I usually have a snack at 4pm.
Or it could be rendered as follows:
I usually have a snack at 16h00.
The dateTime DOM
attribute must reflect the datetime content attribute.
User agents, to obtain the date, time, and time zone represented by a
time element, must follow these steps:
datetime
attribute is present, then use the rules to parse a date or
time string with the flag in attribute from the value
of that attribute, and let the result be result.textContent, and let the result be result.dateReturns a Date object representing the date
component of the element's value, at midnight in the UTC
time zone.
Returns null if there is no date.
timeReturns a Date object representing the time
component of the element's value, on 1970-01-01 in the UTC
time zone.
Returns null if there is no time.
timezoneReturns a Date object representing the time
corresponding to 1970-01-01 00:00 UTC in the time zone given by the
element's value.
Returns null if there is no time zone.
The date DOM
attribute must return null if the date is unknown, and otherwise must
return the time corresponding to midnight UTC (i.e. the first
second) of the given date.
The time DOM attribute
must return null if the time is
unknown, and otherwise must return the time corresponding to the
given time of 1970-01-01, with
the time zone UTC.
The timezone DOM
attribute must return null if the time zone is unknown, and otherwise
must return the time corresponding to 1970-01-01 00:00 UTC in the
given time zone, with the
time zone set to UTC (i.e. the time corresponding to 1970-01-01 at
00:00 UTC plus the offset corresponding to the time zone).
In the following snippet:
<p>Our first date was <time datetime="2006-09-23">a Saturday</time>.</p>
...the time element's date attribute would have the value
1,158,969,600,000ms, and the time
and timezone attributes would
return null.
In the following snippet:
<p>We stopped talking at <time datetime="2006-09-24T05:00-07:00">5am the next morning</time>.</p>
...the time element's date attribute would have the value
1,159,056,000,000ms, the time
attribute would have the value 18,000,000ms, and the timezone attribute would return
−25,200,000ms. To obtain the actual time, the three attributes can
be added together, obtaining 1,159,048,800,000, which is the
specified date and time in UTC.
Finally, in the following snippet:
<p>Many people get up at <time>08:00</time>.</p>
...the time element's date attribute would have the value null,
the time attribute would have the
value 28,800,000ms, and the timezone attribute would return
null.
ruby elementStatus: Working draft
rt element, or an rp element, an rt element, and another rp element.HTMLElement.The ruby element allows one or more spans of
phrasing content to be marked with ruby annotations. Ruby
annotations are short runs of text presented alongside base text,
primarily used in East Asian typography as a guide for
pronunciation or to include other annotations. In Japanese, this
form of typography is also known as furigana.
A ruby element represents the spans of
phrasing content it contains, ignoring all the child rt
and rp elements and their descendants. Those spans of
phrasing content have associated annotations created using the
rt element.
In this example, each ideograph in the Japanese text 漢字 is annotated with its kanji reading.
...
<ruby>
漢 <rt> かん </rt>
字 <rt> じ </rt>
</ruby>
...
This might be rendered as:

In this example, each ideograph in the traditional Chinese text 漢字 is annotated with its bopomofo reading.
<ruby>
漢 <rt> ㄏㄢˋ </rt>
字 <rt> ㄗˋ </rt>
</ruby>
This might be rendered as:

In this example, each ideograph in the simplified Chinese text 汉字 is annotated with its pinyin reading.
...
<ruby>
汉 <rt> hàn </rt>
字 <rt> zì </rt>
</ruby>
...
This might be rendered as:

rt elementStatus: Working draft
ruby element.HTMLElement.The rt element marks the ruby text component of a
ruby annotation.
An rt element that is a child of
a ruby element represents an
annotation (given by its children) for the zero or more nodes of
phrasing content that immediately precedes it in the
ruby element, ignoring rp elements.
rp elementStatus: Working draft
ruby element, either immediately before or immediately after an rt element.HTMLElement.The rp element can be used to provide parentheses
around a ruby text component of a ruby annotation, to be shown by
user agents that don't support ruby annotations.
An rp element that is a child of
a ruby element represents
nothing and its contents must be
ignored. An rp element whose
parent element is not a ruby element
represents its children.
The example above, in which each ideograph in the text 漢字 is annotated with its
kanji reading, could be expanded to use rp so that in
legacy user agents the readings are in parentheses:
...
<ruby>
漢 <rp>(</rp><rt>かん</rt><rp>)</rp>
字 <rp>(</rp><rt>じ</rt><rp>)</rp>
</ruby>
...
In conforming user agents the rendering would be as above, but in user agents that do not support ruby, the rendering would be:
... 漢 (かん) 字 (じ) ...
bdo elementStatus: Implemented and widely deployed
dir global attribute has special semantics on this element.HTMLElement.The bdo element represents explicit
text directionality formatting control for its children. It allows
authors to override the Unicode bidi algorithm by explicitly
specifying a direction override. [BIDI]
Authors must specify the dir
attribute on this element, with the value ltr to
specify a left-to-right override and with the value rtl
to specify a right-to-left override.
If the element has the dir
attribute set to the exact value ltr, then for the
purposes of the bidi algorithm, the user agent must act as if there
was a U+202D LEFT-TO-RIGHT OVERRIDE character at the start of the
element, and a U+202C POP DIRECTIONAL FORMATTING at the end of the
element.
If the element has the dir
attribute set to the exact value rtl, then for the
purposes of the bidi algorithm, the user agent must act as if there
was a U+202E RIGHT-TO-LEFT OVERRIDE character at the start of the
element, and a U+202C POP DIRECTIONAL FORMATTING at the end of the
element.
The requirements on handling the bdo element for the
bidi algorithm may be implemented indirectly through the style
layer. For example, an HTML+CSS user agent should implement these
requirements by implementing the CSS 'unicode-bidi' property. [CSS]
span elementStatus: Implemented and widely deployed
interface HTMLSpanElement : HTMLElement {};
The span element doesn't mean anything on its own,
but can be useful when used together with other attributes,
e.g. class, lang, or dir. It represents its
children.
This section is non-normative.
| Element | Purpose | Example |
|---|---|---|
a
| Hyperlinks | Visit my <a href="drinks.html">drinks</a> page. |
em
| Stress emphasis | I must say I <em>adore</em> lemonade. |
strong
| Importance | This tea is <strong>very hot</strong>. |
small
| Side comments | These grapes are made into wine. <small>Alcohol is addictive.</small> |
cite
| Titles of works | The case <cite>Hugo v. Danielle</cite> is relevant here. |
q
| Quotations | The judge said <q>You can drink water from the fish tank</q> but advised against it. |
dfn
| Defining instance | The term <dfn>organic food</dfn> refers to food produced without synthetic chemicals. |
abbr
| Abbreviations | Organic food in Ireland is certified by the <abbr title="Irish Organic Farmers and Growers Association">IOFGA</abbr>. |
code
| Computer code | The <code>fruitdb</code> program can be used for tracking fruit production. |
var
| Variables | If there are <var>n</var> fruit in the bowl, at least <var>n</var>÷2 will be ripe. |
samp
| Computer output | The computer said <samp>Unknown error -3</samp>. |
kbd
| Computer input | Hit <kbd>F1</kbd> to continue. |
sub
| Subscripts | Water is H<sub>2</sub>O. |
sup
| Superscripts | The Hydrogen in heavy water is usually <sup>2</sup>H. |
i
| Alternative voice | Lemonade consists primarily of <i>Citrus limon</i>. |
b
| Keywords | Take a <b>lemon</b> and squeeze it with a <b>juicer</b>. |
mark
| Highlight | Elderflower cordial, with one <mark>part</mark> cordial to ten <mark>part</mark>s water, stands a<mark>part</mark> from the rest. |
progress
| Progress bar | Copying: <progress>75%</progress> |
meter
| Gauge | Disk space remaining: <meter>75%<meter> |
time
| Date and/or time | Published <time>2009-10-21</time>. |
ruby, rt, rp
| Ruby annotations | <ruby> OJ <rp>(<rt>Orange Juice<rp>)</ruby> |
bdo
| Text directionality formatting | The proposal is to write English, but in reverse order. "Juice" would become "<bdo dir=rtl>Juice</bdo>" |
span
| Other | In French we call it <span lang="fr">sirop de sureau</span>. |
HTML does not have a dedicated mechanism for marking up footnotes. Here are the recommended alternatives.
For short inline annotations, the title attribute should be used.
In this example, two parts of a dialog are annotated.
<dialog> <dt>Customer <dd>Hello! I wish to register a complaint. Hello. Miss? <dt>Shopkeeper <dd><span title="Colloquial pronunciation of 'What do you'" >Watcha</span> mean, miss? <dt>Customer <dd>Uh, I'm sorry, I have a cold. I wish to make a complaint. <dt>Shopkeeper <dd>Sorry, <span title="This is, of course, a lie.">we're closing for lunch</span>. </dialog>
For longer annotations, the a element should be
used, pointing to an element later in the document. The convention
is that the contents of the link be a number in square brackets.
In this example, a footnote in the dialog links to a paragraph below the dialog. The paragraph then reciprocally links back to the dialog, allowing the user to return to the location of the footnote.
<dialog> <dt>Announcer <dd>Number 16: The <i>hand</i>. <dt>Interviewer <dd>Good evening. I have with me in the studio tonight Mr Norman St John Polevaulter, who for the past few years has been contradicting people. Mr Polevaulter, why <em>do</em> you contradict people? <dt>Norman <dd>I don't. <a href="#fn1" id="r1">[1]</a> <dt>Interviewer <dd>You told me you did! </dialog> <section> <p id="fn1"><a href="#r1">[1]</a> This is, naturally, a lie, but paradoxically if it were true he could not say so without contradicting the interviewer and thus making it false.</p> </section>
For side notes, longer annotations that apply to entire sections
of the text rather than just specific words or sentences, the
aside element should be used.
In this example, a sidebar is given after a dialog, giving some context to the dialog.
<dialog> <dt>Customer <dd>I will not buy this record, it is scratched. <dt>Shopkeeper <dd>I'm sorry? <dt>Customer <dd>I will not buy this record, it is scratched. <dt>Shopkeeper <dd>No no no, this's'a tobacconist's. </dialog> <aside> <p>In 1970, the British Empire lay in ruins, and foreign nationalists frequented the streets — many of them Hungarians (not the streets — the foreign nationals). Sadly, Alexander Yalt has been publishing incompetently-written phrase books. </aside>
For figures or tables, footnotes can be included in the relevant
legend or caption element, or in
surrounding prose.
In this example, a table has cells with footnotes
that are given in prose. A figure element is used to
give a single legend to the combination of the table and its
footnotes.
<figure> <legend>Table 1. Alternative activities for knights.</legend> <table> <tr> <th> Activity <th> Location <th> Cost <tr> <td> Dance <td> Wherever possible <td> £0<sup><a href="#fn1">1</a></sup> <tr> <td> Routines, chorus scenes<sup><a href="#fn2">2</a></sup> <td> Undisclosed <td> Undisclosed <tr> <td> Dining<sup><a href="#fn3">3</a></sup> <td> Camelot <td> Cost of ham, jam, and spam<sup><a href="#fn4">4</a></sup> </table> <p id="fn1">1. Assumed.</p> <p id="fn2">2. Footwork impeccable.</p> <p id="fn3">3. Quality described as "well".</p> <p id="fn4">4. A lot.</p> </figure>
The ins and del elements represent
edits to the document.
ins elementStatus: Implemented and widely deployed
citedatetimeHTMLModElement interface.The ins element represents an addition
to the document.
The following represents the addition of a single paragraph:
<aside> <ins> <p> I like fruit. </p> </ins> </aside>
As does this, because everything in the aside
element here counts as phrasing content and therefore
there is just one paragraph:
<aside> <ins> Apples are <em>tasty</em>. </ins> <ins> So are pears. </ins> </aside>
ins elements should not cross implied paragraph boundaries.
The following example represents the addition of two paragraphs,
the second of which was inserted in two parts. The first
ins element in this example thus crosses a paragraph
boundary, which is considered poor form.
<aside> <ins datetime="2005-03-16T00:00Z"> <p> I like fruit. </p> Apples are <em>tasty</em>. </ins> <ins datetime="2007-12-19T00:00Z"> So are pears. </ins> </aside>
Here is a better way of marking this up. It uses more elements, but none of the elements cross implied paragraph boundaries.
<aside> <ins datetime="2005-03-16T00:00Z"> <p> I like fruit. </p> </ins> <ins datetime="2005-03-16T00:00Z"> Apples are <em>tasty</em>. </ins> <ins datetime="2007-12-19T00:00Z"> So are pears. </ins> </aside>
del elementStatus: Implemented and widely deployed
citedatetimeHTMLModElement interface.The del element represents a removal
from the document.
del elements should not cross implied paragraph boundaries.
ins and del elementsThe cite attribute
may be used to specify the address of a document that explains the
change. When that document is long, for instance the minutes of a
meeting, authors are encouraged to include a fragment identifier
pointing to the specific part of that document that discusses the
change.
If the cite attribute is
present, it must be a valid URL that explains the
change. To obtain the corresponding citation
link, the value of the attribute must be resolved relative to the element. User agents should
allow users to follow such citation links.
The datetime
attribute may be used to specify the time and date of the change.
If present, the datetime
attribute must be a valid global date and time string
value.
User agents must parse the datetime attribute according to the
parse a global date and time string algorithm. If that
doesn't return a time, then the modification has no associated
timestamp (the value is non-conforming; it is not a valid
global date and time string). Otherwise, the modification is
marked as having been made at the given datetime. User agents should
use the associated time-zone information to determine which time zone
to present the given datetime in.
The ins and del elements must implement the HTMLModElement
interface:
interface HTMLModElement : HTMLElement {
attribute DOMString cite;
attribute DOMString dateTime;
};The cite DOM
attribute must reflect the element's cite content attribute. The dateTime DOM attribute
must reflect the element's datetime content attribute.
Since the ins and del elements do not
affect paragraphing, it is possible,
in some cases where paragraphs are implied (without explicit p
elements), for an ins or del element to
span both an entire paragraph or other non-phrasing
content elements and part of another paragraph.
For example:
<section> <ins> <p> This is a paragraph that was inserted. </p> This is another paragraph whose first sentence was inserted at the same time as the paragraph above. </ins> This is a second sentence, which was there all along. </section>
By only wrapping some paragraphs in p elements, one
can even get the end of one paragraph, a whole second paragraph,
and the start of a third paragraph to be covered by the same
ins or del element (though this is very
confusing, and not considered good practice):
<section> This is the first paragraph. <ins>This sentence was inserted. <p>This second paragraph was inserted.</p> This sentence was inserted too.</ins> This is the third paragraph in this example. </section>
However, due to the way implied
paragraphs are defined, it is not possible to mark up the
end of one paragraph and the start of the very next one using the
same ins or del element. You instead have
to use one (or two) p element(s) and two
ins or del elements:
For example:
<section> <p>This is the first paragraph. <del>This sentence was deleted.</del></p> <p><del>This sentence was deleted too.</del> That sentence needed a separate <del> element.</p> </section>
Partly because of the confusion described above, authors are
strongly recommended to always mark up all paragraphs with the
p element, and to not have any ins or
del elements that cross across any implied paragraphs.
The content models of the ol and ul
elements do not allow ins and del elements
as children. Lists always represent all their items, including items
that would otherwise have been marked as deleted.
To indicate that an item is inserted or deleted, an
ins or del element can be wrapped around
the contents of the li element. To indicate that an
item has been replaced by another, a single li element
can have one or more del elements followed by one or
more ins elements.
In the following example, a list that started empty had items added and removed from it over time. The bits in the example that have been emphasized show the parts that are the "current" state of the list. The list item numbers don't take into account the edits, though.
<h1>Stop-ship bugs</h1> <ol> <li><ins datetime="2008-02-12T15:20Z">Bug 225: Rain detector doesn't work in snow</ins></li> <li><del datetime="2008-03-01T20:22Z"><ins datetime="2008-02-14T12:02Z">Bug 228: Water buffer overflows in April</ins></del></li> <li><ins datetime="2008-02-16T13:50Z">Bug 230: Water heater doesn't use renewable fuels</ins></li> <li><del datetime="2008-02-20T21:15Z"><ins datetime="2008-02-16T14:25Z">Bug 232: Carbon dioxide emissions detected after startup</ins></del></li> </ol>
In the following example, a list that started with just fruit was replaced by a list with just colors.
<h1>List of <del>fruits</del><ins>colors</ins></h1> <ul> <li><del>Lime</del><ins>Green</ins></li> <li><del>Apple</del></li> <li>Orange</li> <li><del>Pear</del></li> <li><ins>Teal</ins></li> <li><del>Lemon</del><ins>Yellow</ins></li> <li>Olive</li> <li><ins>Purple</ins> </ul>
figure elementStatus: Working draft
legend element followed by flow content.legend element.HTMLElement.The figure element represents some
flow content, optionally with a caption, that is
self-contained and is typically referenced as a single unit from the
main flow of the document.
The element can thus be used to annotate illustrations, diagrams, photos, code listings, etc, that are referred to from the main content of the document, but that could, without affecting the flow of the document, be moved away from that primary content, e.g. to the side of the page, to dedicated pages, or to an appendix.
The first legend element child of the element, if
any, represents the caption of the figure element's
contents. If there is no child legend element, then
there is no caption.
The remainder of the element's contents, if any, represents the content.
This example shows the figure element to mark up a
code listing.
<p>In <a href="#l4">listing 4</a> we see the primary core interface
API declaration.</p>
<figure id="l4">
<legend>Listing 4. The primary core interface API declaration.</legend>
<pre><code>interface PrimaryCore {
boolean verifyDataLine();
void sendData(in sequence<byte> data);
void initSelfDestruct();
}</code></pre>
</figure>
<p>The API is designed to use UTF-8.</p>
Here we see a figure element to mark up a
photo.
<figure>
<img src="bubbles-work.jpeg"
alt="Bubbles, sitting in his office chair, works on his
latest project intently.">
<legend>Bubbles at work</legend>
</figure>
In this example, we see an image that is not a figure, as well as an image and a video that are.
<h2>Malinko's comics</h2> <p>This case centered on some sort of "intellectual property" infringement related to a comic (see Exhibit A). The suit started after a trailer ending with these words:</p> <img src="promblem-packed-action.png" alt="ROUGH COPY! Promblem-Packed Action!"> <p>...was aired. A lawyer, armed with a Bigger Notebook, launched a preemptive strike using snowballs. A complete copy of the trailer is included with Exhibit B.</p> <figure> <img src="ex-a.png" alt="Two squiggles on a dirty piece of paper."> <legend>Exhibit A. The alleged <cite>rough copy</cite> comic.</legend> </figure> <figure> <video src="ex-b.mov"></video> <legend>Exhibit B. The <code>Rough Copy</cite> trailer.</legend> </figure> <p>The case was resolved out of court.</p>
Here, a part of a poem is marked up using
figure.
<figure> <p>'Twas brillig, and the slithy toves<br> Did gyre and gimble in the wabe;<br> All mimsy were the borogoves,<br> And the mome raths outgrabe.</p> <legend><cite>Jabberwocky</cite> (first verse). Lewis Carroll, 1832-98</legend> </figure>
In this example, which could be part of a much larger work discussing a castle, the figure has three images in it.
<figure>
<img src="castle1423.jpeg" title="Etching. Anonymous, ca. 1423."
alt="The castle has one tower, and a tall wall around it.">
<img src="castle1858.jpeg" title="Oil-based paint on canvas. Maria Towle, 1858."
alt="The castle now has two towers and two walls.">
<img src="castle1999.jpeg" title="Film photograph. Peter Jankle, 1999."
alt="The castle lies in ruins, the original tower all that remains in one piece.">
<legend>The castle through the ages: 1423, 1858, and 1999 respectively.</legend>
</figure>
img elementStatus: Last call for comments. ISSUE-66 (image-analysis) and ISSUE-30 (longdesc) block progress to Last Call
usemap attribute: Interactive content.altsrcusemapismapwidthheight[NamedConstructor=Image(),
NamedConstructor=Image(in unsigned long width),
NamedConstructor=Image(in unsigned long width, in unsigned long height)]
interface HTMLImageElement : HTMLElement {
attribute DOMString alt;
attribute DOMString src;
attribute DOMString useMap;
attribute boolean isMap;
attribute unsigned long width;
attribute unsigned long height;
readonly attribute boolean complete;
};
An img element represents an image.
The image given by the src attribute is the
embedded content, and the value of the alt attribute is the
img element's fallback content.
The src attribute must be
present, and must contain a valid URL referencing a
non-interactive, optionally animated, image resource that is neither
paged nor scripted. If the base URI of the element is the
same as the document's address, then the src attribute's value must not be the
empty string.
Images can thus be static bitmaps (e.g. PNGs, GIFs, JPEGs), single-page vector documents (single-page PDFs, XML files with an SVG root element), animated bitmaps (APNGs, animated GIFs), animated vector graphics (XML files with an SVG root element that use declarative SMIL animation), and so forth. However, this also precludes SVG files with script, multipage PDF files, interactive MNG files, HTML documents, plain text documents, and so forth.
The requirements on the alt
attribute's value are described in the next
section.
The img must not be used as a layout tool. In
particular, img elements should not be used to display
transparent images, as they rarely convey meaning and rarely add
anything useful to the document.
Unless the user agent cannot support images, or its support for
images has been disabled, or the user agent only fetches elements on
demand, or the element's src
attribute has a value that is an ignored self-reference,
then, when an img is created with a src attribute, and whenever the src attribute is set subsequently, the
user agent must resolve the value
of that attribute, relative to the element, and if that is
successful must then fetch that resource.
The src attribute's value is an
ignored self-reference if its value is the empty string, and
the base URI of the element is the same as the
document's address.
Fetching the image must delay the load event of the element's document until the task that is queued by the networking task source once the resource has been fetched (defined below) has been run.
This, unfortunately, can be used to perform a rudimentary port scan of the user's local network (especially in conjunction with scripting, though scripting isn't actually necessary to carry out such an attack). User agents may implement cross-origin access control policies that mitigate this attack.
If the image is in a supported image type and its dimensions are known, then the image is said to be available (this affects exactly what the element represents, as defined below). This can be true even before the image is completely downloaded, if the user agent supports incremental rendering of images; in such cases, each task that is queued by the networking task source while the image is being fetched must update the presentation of the image appropriately. It can also stop being true, e.g. if the user agent finds, after obtaining the image's dimensions, that the image data is actually fatally corrupted.
If the image was not fetched (e.g. because the UA's image support
is disabled, or because the src
attribute's value is an ignored self-reference), or if the
conditions in the previous paragraph are not met, then the image is
not available.
An image might be available in one view but not
another. For instance, a Document could be rendered by
a screen reader providing a speech synthesis view of the output of a
Web browser using the screen media. In this case, the image would be
available in the Web browser's screen
view, but not available in the
screen reader's view.
Whether the image is fetched successfully or not (e.g. whether the response code was a 2xx code or equivalent) must be ignored when determining the image's type and whether it is a valid image.
This allows servers to return images with error responses, and have them displayed.
The user agents should apply the image sniffing rules to determine the type of the image, with the image's associated Content-Type headers giving the official type. If these rules are not applied, then the type of the image must be the type given by the image's associated Content-Type headers.
User agents must not support non-image resources with the
img element (e.g. XML files whose root element is an
HTML element). User agents must not run executable code
(e.g. scripts) embedded in the image resource. User agents must only
display the first page of a multipage resource (e.g. a PDF
file). User agents must not allow the resource to act in an
interactive fashion, but should honor any animation in the
resource.
This specification does not specify which image types are to be supported.
The task that is queued by the networking task source once the resource has been fetched, must act as appropriate given the following alternatives:
load at the img
element (this happens after complete starts returning
true).error on the
img element.The task source for these tasks is the DOM manipulation task source.
What an img element represents depends on the src attribute and the alt attribute.
src attribute is set
and the alt attribute is set to
the empty stringThe image is either decorative or supplemental to the rest of the content, redundant with some other information in the document.
If the image is available and the
user agent is configured to display that image, then the element
represents the image specified by the src attribute.
Otherwise, the element represents nothing, and may be omitted completely from the rendering. User agents may provide the user with a notification that an image is present but has been omitted from the rendering.
src attribute is set
and the alt attribute is set to a
value that isn't emptyThe image is a key part of the content; the alt attribute gives a textual
equivalent or replacement for the image.
If the image is available and the
user agent is configured to display that image, then the element
represents the image specified by the src attribute.
Otherwise, the element represents the text given
by the alt attribute. User
agents may provide the user with a notification that an image is
present but has been omitted from the rendering.
src attribute is set
and the alt attribute is notThe image might be a key part of the content, and there is no textual equivalent of the image available.
In a conforming document, the absence of the alt attribute indicates that the image
is a key part of the content but that a textual replacement for
the image was not available when the image was generated.
If the image is available, the
element represents the image specified by the src attribute.
If the image is not available or if the user agent is not configured to display the image, then the user agent should display some sort of indicator that there is an image that is not being rendered, and may, if requested by the user, or if so configured, or when required to provide contextual information in response to navigation, provide caption information for the image, derived as follows:
If the image has a title
attribute whose value is not the empty string, then the value of
that attribute is the caption information; abort these
steps.
If the image is the child of a figure element
that has a child legend element, then the contents
of the first such legend element are the caption
information; abort these steps.
Run the algorithm to create the outline for the document.
If the img element did not end up associated
with a heading in the outline, or if there are any other images
that are lacking an alt
attribute and that are associated with the same heading in the
outline as the img element in question, then there
is no caption information; abort these steps.
The caption information is the heading with which the image is associated according to the outline.
src attribute is not
set and either the alt attribute
is set to the empty string or the alt attribute is not set at allThe element represents nothing.
The element represents the text given by the alt attribute.
The alt attribute does not
represent advisory information. User agents must not present the
contents of the alt attribute in
the same way as content of the title
attribute.
User agents may always provide the user with the option to display any image, or to prevent any image from being displayed. User agents may also apply image analysis heuristics to help the user make sense of the image when the user is unable to make direct use of the image, e.g. due to a visual disability or because they are using a text terminal with no graphics capabilities.
The contents of img elements, if any, are
ignored for the purposes of rendering.
The usemap attribute,
if present, can indicate that the image has an associated
image map.
The ismap
attribute, when used on an element that is a descendant of an
a element with an href attribute, indicates by its
presence that the element provides access to a server-side image
map. This affects how events are handled on the corresponding
a element.
The ismap attribute is a
boolean attribute. The attribute must not be specified
on an element that does not have an ancestor a element
with an href attribute.
The img element supports dimension
attributes.
The DOM attributes alt, src, useMap, and isMap each must
reflect the respective content attributes of the same
name.
width [ = value ]height [ = value ]These attributes return the actual rendered dimensions of the image, or zero if the dimensions are not known.
They can be set, to change the corresponding content attributes.
completeReturns true if the image has been downloaded, decoded, and found to be valid; otherwise, returns false.
Image( [ width [, height ] ] )Returns a new img element, with the width and height attributes set to the values
passed in the relevant arguments, if applicable.
The DOM attributes width and height must return the
rendered width and height of the image, in CSS pixels, if the image
is being rendered, and is being rendered to a visual medium; or else
the intrinsic width and height of the image, in CSS pixels, if the
image is available but not being
rendered to a visual medium; or else 0, if the image is not available or its dimensions are not
known. [CSS]
On setting, they must act as if they reflected the respective content attributes of the same name.
The DOM attribute complete must return
true if the user agent has fetched the image specified in the src attribute, and it is in a supported
image type (i.e. it was decoded without fatal errors), even if the
final task queued by the
networking task source for the fetching of the image resource has not yet been
processed. Otherwise, the attribute must return false.
The value of complete can thus change while a
script is executing.
Three constructors are provided for creating
HTMLImageElement objects (in addition to the factory
methods from DOM Core such as createElement()): Image(), Image(width), and Image(width, height). When invoked as constructors,
these must return a new HTMLImageElement object (a new
img element). If the width argument
is present, the new object's width content attribute must be set to
width. If the height
argument is also present, the new object's height content attribute must be set
to height.
A single image can have different appropriate alternative text depending on the context.
In each of the following cases, the same image is used, yet the
alt text is different each
time. The image is the coat of arms of the Canton Geneva in
Switzerland.
Here it is used as a supplementary icon:
<p>I lived in <img src="carouge.svg" alt=""> Carouge.</p>
Here it is used as an icon representing the town:
<p>Home town: <img src="carouge.svg" alt="Carouge"></p>
Here it is used as part of a text on the town:
<p>Carouge has a coat of arms.</p> <p><img src="carouge.svg" alt="The coat of arms depicts a lion, sitting in front of a tree."></p> <p>It is used as decoration all over the town.</p>
Here it is used as a way to support a similar text where the description is given as well as, instead of as an alternative to, the image:
<p>Carouge has a coat of arms.</p> <p><img src="carouge.svg" alt=""></p> <p>The coat of arms depicts a lion, sitting in front of a tree. It is used as decoration all over the town.</p>
Here it is used as part of a story:
<p>He picked up the folder and a piece of paper fell out.</p> <p><img src="carouge.svg" alt="Shaped like a shield, the paper had a red background, a green tree, and a yellow lion with its tongue hanging out and whose tail was shaped like an S."></p> <p>He stared at the folder. S! The answer he had been looking for all this time was simply the letter S! How had he not seen that before? It all came together now. The phone call where Hector had referred to a lion's tail, the time Marco had stuck his tongue out...</p>
Here it is not known at the time of publication what the image
will be, only that it will be a coat of arms of some kind, and thus
no replacement text can be provided, and instead only a brief
caption for the image is provided, in the title attribute:
<p>The last user to have uploaded a coat of arms uploaded this one:</p> <p><img src="last-uploaded-coat-of-arms.cgi" title="User-uploaded coat of arms."></p>
Ideally, the author would find a way to provide real replacement text even in this case, e.g. by asking the previous user. Not providing replacement text makes the document more difficult to use for people who are unable to view images, e.g. blind users, or users or very low-bandwidth connections or who pay by the byte, or users who are forced to use a text-only Web browser.
Here are some more examples showing the same picture used in different contexts, with different appropriate alternate texts each time.
<article> <h1>My cats</h1> <h2>Fluffy</h2> <p>Fluffy is my favorite.</p> <img src="fluffy.jpg" alt="She likes playing with a ball of yarn."> <p>She's just too cute.</p> <h2>Miles</h2> <p>My other cat, Miles just eats and sleeps.</p> </article>
<article> <h1>Photography</h1> <h2>Shooting moving targets indoors</h2> <p>The trick here is to know how to anticipate; to know at what speed and what distance the subject will pass by.</p> <img src="fluffy.jpg" alt="A cat flying by, chasing a ball of yarn, can be photographed quite nicely using this technique."> <h2>Nature by night</h2> <p>To achieve this, you'll need either an extremely sensitive film, or immense flash lights.</p> </article>
<article> <h1>About me</h1> <h2>My pets</h2> <p>I've got a cat named Fluffy and a dog named Miles.</p> <img src="fluffy.jpg" alt="Fluffy, my cat, tends to keep itself busy."> <p>My dog Miles and I like go on long walks together.</p> <h2>music</h2> <p>After our walks, having emptied my mind, I like listening to Bach.</p> </article>
<article> <h1>Fluffy and the Yarn</h1> <p>Fluffy was a cat who liked to play with yarn. He also liked to jump.</p> <aside><img src="fluffy.jpg" alt="" title="Fluffy"></aside> <p>He would play in the morning, he would play in the evening.</p> </article>
Status: Controversial Working Draft. ISSUE-31 (missing-alt) blocks progress to Last Call
The requirements for the alt
attribute depend on what the image is intended to represent, as
described in the following sections.
When an a element that is a hyperlink,
or a button element, has no textual content but
contains one or more images, the alt attributes must contain text that
together convey the purpose of the link or button.
In this example, a user is asked to pick his preferred color from a list of three. Each color is given by an image, but for users who have configured their user agent not to display images, the color names are used instead:
<h1>Pick your color</h1> <ul> <li><a href="green.html"><img src="green.jpeg" alt="Green"></a></li> <li><a href="blue.html"><img src="blue.jpeg" alt="Blue"></a></li> <li><a href="red.html"><img src="red.jpeg" alt="Red"></a></li> </ul>
In this example, each button has a set of images to indicate the kind of color output desired by the user. The first image is used in each case to give the alternative text.
<button name="rgb"><img src="red" alt="RGB"><img src="green" alt=""><img src="blue" alt=""></button> <button name="cmyk"><img src="cyan" alt="CMYK"><img src="magenta" alt=""><img src="yellow" alt=""><img src="black" alt=""></button>
Since each image represents one part of the text, it could also be written like this:
<button name="rgb"><img src="red" alt="R"><img src="green" alt="G"><img src="blue" alt="B"></button> <button name="cmyk"><img src="cyan" alt="C"><img src="magenta" alt="M"><img src="yellow" alt="Y"><img src="black" alt="K"></button>
However, with other alternative text, this might not work, and putting all the alternative text into one image in each case might make more sense:
<button name="rgb"><img src="red" alt="sRGB profile"><img src="green" alt=""><img src="blue" alt=""></button> <button name="cmyk"><img src="cyan" alt="CMYK profile"><img src="magenta" alt=""><img src="yellow" alt=""><img src="black" alt=""></button>
Sometimes something can be more clearly stated in graphical
form, for example as a flowchart, a diagram, a graph, or a simple
map showing directions. In such cases, an image can be given using
the img element, but the lesser textual version must
still be given, so that users who are unable to view the image
(e.g. because they have a very slow connection, or because they
are using a text-only browser, or because they are listening to
the page being read out by a hands-free automobile voice Web
browser, or simply because they are blind) are still able to
understand the message being conveyed.
The text must be given in the alt attribute, and must convey the
same message as the image specified in the src attribute.
It is important to realize that the alternative text is a replacement for the image, not a description of the image.
In the following example we have a flowchart in image
form, with text in the alt
attribute rephrasing the flowchart in prose form:
<p>In the common case, the data handled by the tokenization stage comes from the network, but it can also come from script.</p> <p><img src="images/parsing-model-overview.png" alt="The network passes data to the Tokenizer stage, which passes data to the Tree Construction stage. From there, data goes to both the DOM and to Script Execution. Script Execution is linked to the DOM, and, using document.write(), passes data to the Tokenizer."></p>
Here's another example, showing a good solution and a bad solution to the problem of including an image in a description.
First, here's the good solution. This sample shows how the alternative text should just be what you would have put in the prose if the image had never existed.
<!-- This is the correct way to do things. --> <p> You are standing in an open field west of a house. <img src="house.jpeg" alt="The house is white, with a boarded front door."> There is a small mailbox here. </p>
Second, here's the bad solution. In this incorrect way of doing things, the alternative text is simply a description of the image, instead of a textual replacement for the image. It's bad because when the image isn't shown, the text doesn't flow as well as in the first example.
<!-- This is the wrong way to do things. --> <p> You are standing in an open field west of a house. <img src="house.jpeg" alt="A white house, with a boarded front door."> There is a small mailbox here. </p>
Text such as "Photo of white house with boarded door" would be
equally bad alternative text (though it could be suitable for the
title attribute or in the
legend element of a figure with this
image).
A document can contain information in iconic form. The icon is intended to help users of visual browsers to recognize features at a glance.
In some cases, the icon is supplemental to a text label
conveying the same meaning. In those cases, the alt attribute must be present but must
be empty.
Here the icons are next to text that conveys the same meaning,
so they have an empty alt
attribute:
<nav> <p><a href="/help/"><img src="/icons/help.png" alt=""> Help</a></p> <p><a href="/configure/"><img src="/icons/configuration.png" alt=""> Configuration Tools</a></p> </nav>
In other cases, the icon has no text next to it describing what
it means; the icon is supposed to be self-explanatory. In those
cases, an equivalent textual label must be given in the alt attribute.
Here, posts on a news site are labeled with an icon indicating their topic.
<body> <article> <header> <h1>Ratatouille wins <i>Best Movie of the Year</i> award</h1> <p><img src="movies.png" alt="Movies"></p> </header> <p>Pixar has won yet another <i>Best Movie of the Year</i> award, making this its 8th win in the last 12 years.</p> </article> <article> <header> <h1>Latest TWiT episode is online</h1> <p><img src="podcasts.png" alt="Podcasts"></p> </header> <p>The latest TWiT episode has been posted, in which we hear several tech news stories as well as learning much more about the iPhone. This week, the panelists compare how reflective their iPhones' Apple logos are.</p> </article> </body>
Many pages include logos, insignia, flags, or emblems, which stand for a particular entity such as a company, organization, project, band, software package, country, or some such.
If the logo is being used to represent the entity, e.g. as a page
heading, the alt attribute must
contain the name of the entity being represented by the logo. The
alt attribute must not
contain text like the word "logo", as it is not the fact that it is
a logo that is being conveyed, it's the entity itself.
If the logo is being used next to the name of the entity that
it represents, then the logo is supplemental, and its alt attribute must instead be
empty.
If the logo is merely used as decorative material (as branding, or, for example, as a side image in an article that mentions the entity to which the logo belongs), then the entry below on purely decorative images applies. If the logo is actually being discussed, then it is being used as a phrase or paragraph (the description of the logo) with an alternative graphical representation (the logo itself), and the first entry above applies.
In the following snippets, all four of the above cases are present. First, we see a logo used to represent a company:
<h1><img src="XYZ.gif" alt="The XYZ company"></h1>
Next, we see a paragraph which uses a logo right next to the company name, and so doesn't have any alternative text:
<article> <h2>News</h2> <p>We have recently been looking at buying the <img src="alpha.gif" alt=""> ΑΒΓ company, a small Greek company specializing in our type of product.</p>
In this third snippet, we have a logo being used in an aside, as part of the larger article discussing the acquisition:
<aside><p><img src="alpha-large.gif" alt=""></p></aside> <p>The ΑΒΓ company has had a good quarter, and our pie chart studies of their accounts suggest a much bigger blue slice than its green and orange slices, which is always a good sign.</p> </article>
Finally, we have an opinion piece talking about a logo, and the logo is therefore described in detail in the alternative text.
<p>Consider for a moment their logo:</p> <p><img src="/images/logo" alt="It consists of a green circle with a green question mark centered inside it."></p> <p>How unoriginal can you get? I mean, oooooh, a question mark, how <em>revolutionary</em>, how utterly <em>ground-breaking</em>, I'm sure everyone will rush to adopt those specifications now! They could at least have tried for some sort of, I don't know, sequence of rounded squares with varying shades of green and bold white outlines, at least that would look good on the cover of a blue book.</p>
This example shows how the alternative text should be written such that if the image isn't available, and the text is used instead, the text flows seamlessly into the surrounding text, as if the image had never been there in the first place.
Sometimes, an image just consists of text, and the purpose of the image is not to highlight the actual typographic effects used to render the text, but just to convey the text itself.
In such cases, the alt
attribute must be present but must consist of the same text as
written in the image itself.
Consider a graphic containing the text "Earth Day", but with the letters all decorated with flowers and plants. If the text is merely being used as a heading, to spice up the page for graphical users, then the correct alternative text is just the same text "Earth Day", and no mention need be made of the decorations:
<h1><img src="earthdayheading.png" alt="Earth Day"></h1>
In many cases, the image is actually just supplementary, and
its presence merely reinforces the surrounding text. In these
cases, the alt attribute must be
present but its value must be the empty string.
In general, an image falls into this category if removing the image doesn't make the page any less useful, but including the image makes it a lot easier for users of visual browsers to understand the concept.
A flowchart that repeats the previous paragraph in graphical form:
<p>The network passes data to the Tokenizer stage, which passes data to the Tree Construction stage. From there, data goes to both the DOM and to Script Execution. Script Execution is linked to the DOM, and, using document.write(), passes data to the Tokenizer.</p> <p><img src="images/parsing-model-overview.png" alt=""></p>
In these cases, it would be wrong to include alternative text
that consists of just a caption. If a caption is to be included,
then either the title attribute can
be used, or the figure and legend
elements can be used. In the latter case, the image would in fact
be a phrase or paragraph with an alternative graphical
representation, and would thus require alternative text.
<!-- Using the title="" attribute -->
<p>The network passes data to the Tokenizer stage, which
passes data to the Tree Construction stage. From there, data goes
to both the DOM and to Script Execution. Script Execution is
linked to the DOM, and, using document.write(), passes data to
the Tokenizer.</p>
<p><img src="images/parsing-model-overview.png" alt=""
title="Flowchart representation of the parsing model."></p>
<!-- Using <figure> and <legend> --> <p>The network passes data to the Tokenizer stage, which passes data to the Tree Construction stage. From there, data goes to both the DOM and to Script Execution. Script Execution is linked to the DOM, and, using document.write(), passes data to the Tokenizer.</p> <figure> <img src="images/parsing-model-overview.png" alt="The Network leads to the Tokenizer, which leads to the Tree Construction. The Tree Construction leads to two items. The first is Script Execution, which leads via document.write() back to the Tokenizer. The second item from which Tree Construction leads is the DOM. The DOM is related to the Script Execution."> <legend>Flowchart representation of the parsing model.</legend> </figure>
<!-- This is WRONG. Do not do this. Instead, do what the above examples do. -->
<p>The network passes data to the Tokenizer stage, which
passes data to the Tree Construction stage. From there, data goes
to both the DOM and to Script Execution. Script Execution is
linked to the DOM, and, using document.write(), passes data to
the Tokenizer.</p>
<p><img src="images/parsing-model-overview.png"
alt="Flowchart representation of the parsing model."></p>
<!-- Never put the image's caption in the alt="" attribute! -->
A graph that repeats the previous paragraph in graphical form:
<p>According to a study covering several billion pages, about 62% of documents on the Web in 2007 triggered the Quirks rendering mode of Web browsers, about 30% triggered the Almost Standards mode, and about 9% triggered the Standards mode.</p> <p><img src="rendering-mode-pie-chart.png" alt=""></p>
In general, if an image is decorative but isn't especially page-specific, for example an image that forms part of a site-wide design scheme, the image should be specified in the site's CSS, not in the markup of the document.
However, a decorative image that isn't discussed by the
surrounding text still has some relevance can be included in a page
using the img element. Such images are decorative, but
still form part of the content. In these cases, the alt attribute must be present but its
value must be the empty string.
Examples where the image is purely decorative despite being relevant would include things like a photo of the Black Rock City landscape in a blog post about an event at Burning Man, or an image of a painting inspired by a poem, on a page reciting that poem. The following snippet shows an example of the latter case (only the first verse is included in this snippet):
<h1>The Lady of Shalott</h1> <p><img src="shalott.jpeg" alt=""></p> <p>On either side the river lie<br> Long fields of barley and of rye,<br> That clothe the wold and meet the sky;<br> And through the field the road run by<br> To many-tower'd Camelot;<br> And up and down the people go,<br> Gazing where the lilies blow<br> Round an island there below,<br> The island of Shalott.</p>
When a picture has been sliced into smaller image files that are
then displayed together to form the complete picture again, one of
the images must have its alt
attribute set as per the relevant rules that would be appropriate
for the picture as a whole, and then all the remaining images must
have their alt attribute set to
the empty string.
In the following example, a picture representing a company logo for XYZ Corp has been split into two pieces, the first containing the letters "XYZ" and the second with the word "Corp". The alternative text ("XYZ Corp") is all in the first image.
<h1><img src="logo1.png" alt="XYZ Corp"><img src="logo2.png" alt=""></h1>
In the following example, a rating is shown as three filled stars and two empty stars. While the alternative text could have been "★★★☆☆", the author has instead decided to more helpfully give the rating in the form "3 out of 5". That is the alternative text of the first image, and the rest have blank alternative text.
<p>Rating: <meter max=5 value=3><img src="1" alt="3 out of 5" ><img src="1" alt=""><img src="1" alt=""><img src="0" alt="" ><img src="0" alt=""></meter></p>
Generally, image maps should be used instead of slicing an image for links.
However, if an image is indeed sliced and any of the components
of the sliced picture are the sole contents of links, then one image
per link must have alternative text in its alt attribute representing the purpose
of the link.
In the following example, a picture representing the flying spaghetti monster emblem, with each of the left noodly appendages and the right noodly appendages in different images, so that the user can pick the left side or the right side in an adventure.
<h1>The Church</h1> <p>You come across a flying spaghetti monster. Which side of His Noodliness do you wish to reach out for?</p> <p><a href="?go=left" ><img src="fsm-left.png" alt="Left side. "></a ><img src="fsm-middle.png" alt="" ><a href="?go=right"><img src="fsm-right.png" alt="Right side."></a></p>
In some cases, the image is a critical part of the content. This could be the case, for instance, on a page that is part of a photo gallery. The image is the whole point of the page containing it.
How to provide alternative text for an image that is a key part of the content depends on the image's provenance.
When it is possible for detailed alternative text to be
provided, for example if the image is part of a series of
screenshots in a magazine review, or part of a comic strip, or is
a photograph in a blog entry about that photograph, text that can
serve as a substitute for the image must be given as the contents
of the alt attribute.
A screenshot in a gallery of screenshots for a new OS, with some alternative text:
<figure>
<img src="KDE%20Light%20desktop.png"
alt="The desktop is blue, with icons along the left hand side in
two columns, reading System, Home, K-Mail, etc. A window is
open showing that menus wrap to a second line if they
cannot fit in the window. The window has a list of icons
along the top, with an address bar below it, a list of
icons for tabs along the left edge, a status bar on the
bottom, and two panes in the middle. The desktop has a bar
at the bottom of the screen with a few buttons, a pager, a
list of open applications, and a clock.">
<legend>Screenshot of a KDE desktop.</legend>
</figure>
A graph in a financial report:
<img src="sales.gif"
title="Sales graph"
alt="From 1998 to 2005, sales increased by the following percentages
with each year: 624%, 75%, 138%, 40%, 35%, 9%, 21%">
Note that "sales graph" would be inadequate alternative text for a sales graph. Text that would be a good caption is not generally suitable as replacement text.
In certain cases, the nature of the image might be such that providing thorough alternative text is impractical. For example, the image could be indistinct, or could be a complex fractal, or could be a detailed topographical map.
In these cases, the alt
attribute must contain some suitable alternative text, but it may
be somewhat brief.
Sometimes there simply is no text that can do justice to an image. For example, there is little that can be said to usefully describe a Rorschach inkblot test. However, a description, even if brief, is still better than nothing:
<figure> <img src="/commons/a/a7/Rorschach1.jpg" alt="A shape with left-right symmetry with indistinct edges, with a small gap in the center, two larger gaps offset slightly from the center, with two similar gaps under them. The outline is wider in the top half than the bottom half, with the sides extending upwards higher than the center, and the center extending below the sides."> <legend>A black outline of the first of the ten cards in the Rorschach inkblot test.</legend> </figure>
Note that the following would be a very bad use of alternative text:
<!-- This example is wrong. Do not copy it. --> <figure> <img src="/commons/a/a7/Rorschach1.jpg" alt="A black outline of the first of the ten cards in the Rorschach inkblot test."> <legend>A black outline of the first of the ten cards in the Rorschach inkblot test.</legend> </figure>
Including the caption in the alternative text like this isn't useful because it effectively duplicates the caption for users who don't have images, taunting them twice yet not helping them any more than if they had only read or heard the caption once.
Another example of an image that defies full description is a fractal, which, by definition, is infinite in complexity.
The following example shows one possible way of providing alternative text for the full view of an image of the Mandelbrot set.
<img src="ms1.jpeg" alt="The Mandelbrot set appears as a cardioid with its cusp on the real axis in the positive direction, with a smaller bulb aligned along the same center line, touching it in the negative direction, and with these two shapes being surrounded by smaller bulbs of various sizes.">
In some unfortunate cases, there might be no alternative text available at all, either because the image is obtained in some automated fashion without any associated alternative text (e.g. a Webcam), or because the page is being generated by a script using user-provided images where the user did not provide suitable or usable alternative text (e.g. photograph sharing sites), or because the author does not himself know what the images represent (e.g. a blind photographer sharing an image on his blog).
In such cases, the alt
attribute's value may be omitted, but one of the following
conditions must be met as well:
title attribute is
present and has a non-empty value.img element is in a figure
element that contains a legend element that contains
content other than inter-element whitespace.img element is part of the only
paragraph directly in its section, and is the only
img element without an alt attribute in its section, and its
section has an associated
heading.Such cases are to be kept to an absolute
minimum. If there is even the slightest possibility of the author
having the ability to provide real alternative text, then it would
not be acceptable to omit the alt
attribute.
A photo on a photo-sharing site, if the site received the image with no metadata other than the caption:
<figure> <img src="1100670787_6a7c664aef.jpg"> <legend>Bubbles traveled everywhere with us.</legend> </figure>
It could also be marked up like this:
<article> <h1>Bubbles traveled everywhere with us.</h1> <img src="1100670787_6a7c664aef.jpg"> </article>
In either case, though, it would be better if a detailed description of the important parts of the image obtained from the user and included on the page.
A blind user's blog in which a photo taken by the user is shown. Initially, the user might not have any idea what the photo he took shows:
<article> <h1>I took a photo</h1> <p>I went out today and took a photo!</p> <figure> <img src="photo2.jpeg"> <legend>A photograph taken blindly from my front porch.</legend> </figure> </article>
Eventually though, the user might obtain a description of the image from his friends and could then include alternative text:
<article> <h1>I took a photo</h1> <p>I went out today and took a photo!</p> <figure> <img src="photo2.jpeg" alt="The photograph shows my hummingbird feeder hanging from the edge of my roof. It is half full, but there are no birds around. In the background, out-of-focus trees fill the shot. The feeder is made of wood with a metal grate, and it contains peanuts. The edge of the roof is wooden too, and is painted white with light blue streaks."> <legend>A photograph taken blindly from my front porch.</legend> </figure> </article>
Sometimes the entire point of the image is that a textual
description is not available, and the user is to provide the
description. For instance, the point of a CAPTCHA image is to see
if the user can literally read the graphic. Here is one way to
mark up a CAPTCHA (note the title
attribute):
<p><label>What does this image say? <img src="captcha.cgi?id=8934" title="CAPTCHA"> <input type=text name=captcha></label> (If you cannot see the image, you can use an <a href="?audio">audio</a> test instead.)</p>
Another example would be software that displays images and asks for alternative text precisely for the purpose of then writing a page with correct alternative text. Such a page could have a table of images, like this:
<table> <thead> <tr> <th> Image <th> Description <tbody> <tr> <td> <img src="2421.png" title="Image 640 by 100, filename 'banner.gif'"> <td> <input name="alt2421"> <tr> <td> <img src="2422.png" title="Image 200 by 480, filename 'ad3.gif'"> <td> <input name="alt2422"> </table>
Notice that even in this example, as much useful information
as possible is still included in the title attribute.
Since some users cannot use images at all
(e.g. because they have a very slow connection, or because they
are using a text-only browser, or because they are listening to
the page being read out by a hands-free automobile voice Web
browser, or simply because they are blind), the alt attribute is only allowed to be
omitted rather than being provided with replacement text when no
alternative text is available and none can be made available, as
in the above examples. Lack of effort from the part of the author
is not an acceptable reason for omitting the alt attribute.
Generally authors should avoid using img elements
for purposes other than showing images.
If an img element is being used for purposes other
than showing an image, e.g. as part of a service to count page
views, then the alt attribute must
be the empty string.
In such cases, the width and
height attributes should both
be set to zero.
This section does not apply to documents that are publicly accessible, or whose target audience is not necessarily personally known to the author, such as documents on a Web site, e-mails sent to public mailing lists, or software documentation.
When an image is included in a private communication (such as an
HTML e-mail) aimed at a specific person who is known to be able to
view images, the alt attribute may
be omitted. However, even in such cases it is strongly recommended
that alternative text be included (as appropriate according to the
kind of image involved, as described in the above entries), so that
the e-mail is still usable should the user use a mail client that
does not support images, or should the document be forwarded on to
other users whose abilities might not include easily seeing
images.
The most general rule to consider when writing alternative text
is the following: the intent is that replacing every image
with the text of its alt attribute
not change the meaning of the page.
So, in general, alternative text can be written by considering what one would have written had one not been able to include the image.
A corollary to this is that the alt attribute's value should never
contain text that could be considered the image's caption,
title, or legend. It is supposed to contain
replacement text that could be used by users instead of the
image; it is not meant to supplement the image. The title attribute can be used for
supplemental information.
One way to think of alternative text is to think about how you would read the page containing the image to someone over the phone, without mentioning that there is an image present. Whatever you say instead of the image is typically a good start for writing the alternative text.
Markup generators (such as WYSIWYG authoring tools) should, wherever possible, obtain alternative text from their users. However, it is recognized that in many cases, this will not be possible.
For images that are the sole contents of links, markup generators should examine the link target to determine the title of the target, or the URL of the target, and use information obtained in this manner as the alternative text.
As a last resort, implementors should either set the alt attribute to the empty string, under
the assumption that the image is a purely decorative image that
doesn't add any information but is still specific to the surrounding
content, or omit the alt attribute
altogether, under the assumption that the image is a key part of the
content.
Markup generators should generally avoid using the image's own file name as the alternative text.
Conformance checkers must report the lack of an alt attribute as an error unless the
conditions listed above for images whose
contents are not known or they have been configured to assume
that the document is an e-mail or document intended for a specific
person who is known to be able to view images.
iframe elementStatus: Working draft
srcnamesandboxseamlesswidthheightinterface HTMLIFrameElement : HTMLElement {
attribute DOMString src;
attribute DOMString name;
attribute DOMString sandbox;
attribute boolean seamless;
attribute DOMString width;
attribute DOMString height;
readonly attribute Document contentDocument;
readonly attribute WindowProxy contentWindow;
};
The iframe element represents a
nested browsing context.
The src attribute
gives the address of a page that the nested browsing
context is to contain. The attribute, if present, must be a
valid URL. When the browsing context
is created, if the attribute is present, the user agent must resolve the value of that attribute,
relative to the element, and if that is successful, must then
navigate the element's browsing context to the
resulting absolute URL, with replacement
enabled, and with the iframe element's
document's browsing context as the source
browsing context. If the user navigates away from this page, the
iframe's corresponding WindowProxy object
will proxy new Window objects for new
Document objects, but the src attribute will not
change.
Whenever the src attribute
is set, the user agent must resolve the value of that attribute, relative to the
element, and if that is successful, the nested browsing
context must be navigated to
the resulting absolute URL, with the
iframe element's document's browsing
context as the source browsing context.
If the src attribute is not
set when the element is created, or if its value cannot be resolved, the browsing context will
remain at the initial about:blank page.
The name
attribute, if present, must be a valid browsing context
name. The given value is used to name the nested
browsing context. When the browsing
context is created, if the attribute is present, the browsing
context name must be set to the value of this attribute;
otherwise, the browsing context name must be set to the
empty string.
Whenever the name attribute
is set, the nested browsing context's name must be changed to the new
value. If the attribute is removed, the browsing context
name must be set to the empty string.
When content loads in an iframe, after any load events are fired within the content
itself, the user agent must fire a simple event called
load at the iframe
element. When content fails to load (e.g. due to a network error),
then the user agent must fire a simple event called
error at the element instead.
When there is an active parser in the
iframe, and when anything in the iframe is
delaying the load event of
the iframe's browsing context's
active document, the iframe must
delay the load event of its document.
If, during the handling of the load event, the browsing
context in the iframe is again navigated, that will further delay the
load event.
The sandbox
attribute, when specified, enables a set of extra restrictions on
any content hosted by the iframe. Its value must be an
unordered set of unique space-separated tokens. The
allowed values are allow-same-origin,
allow-forms,
and allow-scripts. When
the attribute is set, the content is treated as being from a unique
origin, forms and scripts are disabled, links are
prevented from targeting other browsing contexts, and plugins are disabled. The
allow-same-origin
token allows the content to be treated as being from the same origin
instead of forcing it into a unique origin, and the allow-forms and allow-scripts
tokens re-enable forms and scripts respectively (though scripts are
still prevented from creating popups).
While the sandbox
attribute is specified, the iframe element's
nested browsing context, and all the browsing contexts
nested within it
(either directly or indirectly through other nested browsing
contexts) must have the following flags set:
This flag prevents content from navigating browsing contexts other than the sandboxed browsing context itself (or browsing contexts further nested inside it).
This flag also prevents content
from creating new auxiliary browsing contexts, e.g. using the
target attribute or the
window.open() method.
This flag prevents content from instantiating plugins, whether using the embed element, the object element,
the applet
element, or through navigation of a nested
browsing context.
sandbox attribute's
value, when split on
spaces, is found to have the allow-same-origin
keyword setThis flag forces content into a unique origin for the purposes of the same-origin policy.
This flag also prevents script from
reading the document.cookie DOM
attribute.
The allow-same-origin
attribute is intended for two cases.
First, it can be used to allow content from the same site to be sandboxed to disable scripting, while still allowing access to the DOM of the sandboxed content.
Second, it can be used to embed content from a third-party site, sandboxed to prevent that site from opening popup windows, etc, without preventing the embedded page from communicating back to its originating site, using the database APIs to store data, etc.
This flag only takes effect when the
nested browsing context of the iframe is
navigated.
sandbox attribute's
value, when split on
spaces, is found to have the allow-forms
keyword setThis flag blocks form submission.
sandbox attribute's
value, when split on
spaces, is found to have the allow-scripts
keyword setThis flag blocks script execution.
If the sandbox attribute is
dynamically added after the iframe has loaded a page,
scripts already compiled by that page (whether in
script elements, or in event handler
attributes, or elsewhere) will continue to run. Only
new scripts will be prevented from executing by this
flag.
These flags must not be set unless the conditions listed above define them as being set.
In this example, some completely-unknown, potentially hostile, user-provided HTML content is embedded in a page. Because it is sandboxed, it is treated by the user agent as being from a unique origin, despite the content being served from the same site. Thus it is affected by all the normal cross-site restrictions. In addition, the embedded page has scripting disabled, plugins disabled, forms disabled, and it cannot navigate any frames or windows other than itself (or any frames or windows it itself embeds).
<p>We're not scared of you! Here is your content, unedited:</p> <iframe sandbox src="getusercontent.cgi?id=12193"></iframe>
Note that cookies are still sent to the server in the getusercontent.cgi request, though they are not
visible in the document.cookie DOM
attribute.
In this example, a gadget from another site is embedded. The gadget has scripting and forms enabled, and the origin sandbox restrictions are lifted, allowing the gadget to communicate with its originating server. The sandbox is still useful, however, as it disables plugins and popups, thus reducing the risk of the user being exposed to malware and other annoyances.
<iframe sandbox="allow-same-origin allow-forms allow-scripts"
src="http://maps.example.com/embedded.html"></iframe>
The seamless
attribute is a boolean attribute. When specified, it indicates that
the iframe element's browsing context is
to be rendered in a manner that makes it appear to be part of the
containing document (seamlessly included in the parent
document). Specifically, when the attribute is
set on an element and while the browsing context's
active document has the same origin as the
iframe element's document, or the browsing
context's active document's address has the same
origin as the iframe element's document, the
following requirements apply:
The user agent must set the seamless browsing context flag to true for that browsing context. This will cause links to open in the parent browsing context.
In a CSS-supporting user agent: the user agent must add all
the style sheets that apply to the iframe element to
the cascade of the active document of the
iframe element's nested browsing context,
at the appropriate cascade levels, before any style sheets
specified by the document itself.
In a CSS-supporting user agent: the user agent must, for the
purpose of CSS property inheritance only, treat the root element of
the active document of the iframe
element's nested browsing context as being a child of
the iframe element. (Thus inherited properties on the
root element of the document in the iframe will
inherit the computed values of those properties on the
iframe element instead of taking their initial
values.)
In visual media, in a CSS-supporting user agent: the user agent
should set the intrinsic width of the iframe to the
width that the element would have if it was a non-replaced
block-level element with 'width: auto'.
In visual media, in a CSS-supporting user agent: the user
agent should set the intrinsic height of the iframe to
the height of the bounding box around the content rendered in the
iframe at its current width (as given in the previous
bullet point), as it would be if the scrolling position was such
that the top of the viewport for the content rendered in the
iframe was aligned with the origin of that content's
canvas.
In visual media, in a CSS-supporting user agent: the user agent
must force the height of the initial containing block of the
active document of the nested browsing
context of the iframe to zero.
This is intended to get around the otherwise circular dependency of percentage dimensions that depend on the height of the containing block, thus affecting the height of the document's bounding box, thus affecting the height of the viewport, thus affecting the size of the initial containing block.
In speech media, the user agent should render the nested browsing context without announcing that it is a separate document.
User agents should, in general, act as if the active
document of the iframe's nested browsing
context was part of the document that the
iframe is in.
For example if the user agent supports listing all the links in a document, links in "seamlessly" nested documents would be included in that list without being significantly distinguished from links in the document itself.
If the attribute is not specified, or if the origin conditions listed above are not met, then the user agent should render the nested browsing context in a manner that is clearly distinguishable as a separate browsing context, and the seamless browsing context flag must be set to false for that browsing context.
It is important that user agents recheck the
above conditions whenever the active document of the
nested browsing context of the iframe
changes, such that the seamless browsing context flag
gets unset if the nested browsing context is navigated to another origin.
The attribute can be set or removed dynamically, with the rendering updating in tandem.
In this example, the site's navigation is embedded using a
client-side include using an iframe. Any links in the
iframe will, in new user agents, be automatically
opened in the iframe's parent browsing context; for
legacy user agents, the site could also include a base
element with a target
attribute with the value _parent. Similarly,
in new user agents the styles of the parent page will be
automatically applied to the contents of the frame, but to support
legacy user agents authors might wish to include the styles
explicitly.
<nav><iframe seamless src="nav.include.html"></iframe></nav>
The iframe element supports dimension
attributes for cases where the embedded content has specific
dimensions (e.g. ad units have well-defined dimensions).
An iframe element never has fallback
content, as it will always create a nested browsing
context, regardless of whether the specified initial contents
are successfully used.
Descendants of iframe elements represent
nothing. (In legacy user agents that do not support
iframe elements, the contents would be parsed as markup
that could act as fallback content.)
When used in HTML documents, the allowed content
model of iframe elements is text, except that invoking
the HTML fragment parsing algorithm with the
iframe element as the context
element and the text contents as the input must
result in a list of nodes that are all phrasing
content, with no parse
errors having occurred, with no script elements
being anywhere in the list or as descendants of elements in the
list, and with all the elements in the list (including their
descendants) being themselves conforming.
The iframe element must be empty in XML
documents.
The HTML parser treats markup inside
iframe elements as text.
The DOM attributes src, name, sandbox, and seamless must
reflect the respective content attributes of the same
name.
The contentDocument
DOM attribute must return the Document object of the
active document of the iframe element's
nested browsing context.
The contentWindow
DOM attribute must return the WindowProxy object of the
iframe element's nested browsing
context.
embed elementStatus: Working draft
srctypewidthheightinterface HTMLEmbedElement : HTMLElement {
attribute DOMString src;
attribute DOMString type;
attribute DOMString width;
attribute DOMString height;
};
Depending on the type of content instantiated by the
embed element, the node may also support other
interfaces.
The embed element represents an
integration point for an external (typically non-HTML) application
or interactive content.
The src attribute
gives the address of the resource being embedded. The attribute, if
present, must contain a valid URL.
The type
attribute, if present, gives the MIME type of the plugin to
instantiate. The value must be a valid MIME type,
optionally with parameters. If both the type attribute and the src attribute are present, then the
type attribute must specify the
same type as the explicit Content-Type
metadata of the resource given by the src attribute.
When the element is created with neither a src attribute nor a type attribute, and when attributes
are removed such that neither attribute is present on the element
anymore, and when the element has a media element
ancestor, and when the element has an ancestor object
element that is not showing its fallback
content, any plugins instantiated for the element must be
removed, and the embed element represents nothing.
When the sandboxed plugins browsing
context flag is set on the browsing context for
which the embed element's document is the active
document, then the user agent must render the
embed element in a manner that conveys that the
plugin was disabled. The user agent may offer the user
the option to override the sandbox and instantiate the
plugin anyway; if the user invokes such an option, the
user agent must act as if the sandboxed plugins browsing
context flag was not set for the purposes of this
element.
Plugins are disabled in sandboxed browsing contexts because they might not honor the restrictions imposed by the sandbox (e.g. they might allow scripting even when scripting in the sandbox is disabled). User agents should convey the danger of overriding the sandbox to the user if an option to do so is provided.
When the element is created with a src attribute, and whenever the src attribute is subsequently set, and
whenever the type attribute is
set or removed while the element has a src attribute, if the element is not
in a sandboxed browsing context, not a descendant of a media
element, and not a descendant of an object
element that is not showing its fallback content, the
user agent must resolve the value
of the attribute, relative to the element, and if that is
successful, should fetch the resulting absolute
URL. The task that is queued by the networking task
source once the resource has been fetched must find and instantiate an
appropriate plugin based on the content's type, and hand that
plugin the content of the resource, replacing any
previously instantiated plugin for the element.
Fetching the resource must delay the load event of the element's document.
The type of the content being embedded is defined as follows:
If the element has a type attribute, and that attribute's
value is a type that a plugin supports, then the value
of the type attribute is the
content's type.
Otherwise, if the <path> component of the URL of the specified resource (after any redirects) matches a pattern that a plugin supports, then the content's type is the type that that plugin can handle.
For example, a plugin might say that it can
handle resources with <path>
components that end with the four character string ".swf".
Otherwise, if the specified resource has explicit Content-Type metadata, then that is the content's type.
Otherwise, the content has no type and there can be no appropriate plugin for it.
Whether the resource is fetched successfully or not (e.g. whether the response code was a 2xx code or equivalent) must be ignored when determining the resource's type and when handing the resource to the plugin.
This allows servers to return data for plugins even with error responses (e.g. HTTP 500 Internal Server Error codes can still contain plugin data).
When the element is created with a type attribute and no src attribute, and whenever the type attribute is subsequently set,
so long as no src attribute is
set, and whenever the src
attribute is removed when the element has a type attribute, if the element is not
in a sandboxed browsing context, user agents should find and
instantiate an appropriate plugin based on the value of
the type attribute.
Any (namespace-less) attribute may be specified on the
embed element, so long as its name is
XML-compatible and contains no characters in the range
U+0041 .. U+005A (LATIN CAPITAL LETTER A LATIN CAPITAL LETTER
Z).
All attributes in HTML documents get lowercased automatically, so the restriction on uppercase letters doesn't affect such documents.
The user agent should pass the names and values of all the
attributes of the embed element that have no namespace
to the plugin used, when it is instantiated.
If the plugin instantiated for the
embed element supports a scriptable interface, the
HTMLEmbedElement object representing the element should
expose that interface while the element is instantiated.
The embed element has no fallback
content. If the user agent can't find a suitable plugin, then
the user agent must use a default plugin. (This default could be as
simple as saying "Unsupported Format".)
The embed element supports dimension
attributes.
The DOM attributes src and type each must
reflect the respective content attributes of the same
name.
object elementStatus: Working draft
usemap attribute: Interactive content.param elements, then, transparent.datatypenameusemapformwidthheightinterface HTMLObjectElement : HTMLElement {
attribute DOMString data;
attribute DOMString type;
attribute DOMString name;
attribute DOMString useMap;
readonly attribute HTMLFormElement form;
attribute DOMString width;
attribute DOMString height;
readonly attribute Document contentDocument;
readonly attribute WindowProxy contentWindow;
};
Depending on the type of content instantiated by the
object element, the node also supports other
interfaces.
The object element can represent an external
resource, which, depending on the type of the resource, will either
be treated as an image, as a nested browsing context,
or as an external resource to be processed by a
plugin.
The data
attribute, if present, specifies the address of the resource. If
present, the attribute must be a valid URL.
The type
attribute, if present, specifies the type of the resource. If
present, the attribute must be a valid MIME type,
optionally with parameters.
One or both of the data and
type attributes must be
present.
The name
attribute, if present, must be a valid browsing context
name. The given value is used to name the nested
browsing context, if applicable.
When the element is created, and subsequently whenever the classid attribute changes or is
removed, or, if the classid
attribute is not present, whenever the data attribute changes or is
removed, or, if neither classid attribute nor the data attribute are present, whenever
the type attribute changes or
is removed, the user agent must run the following steps to determine
what the object element represents:
If the element has an ancestor media element, or
has an ancestor object element that is not
showing its fallback content, then jump to the last
step in the overall set of steps (fallback).
If the classid
attribute is present, and has a value that isn't the empty string,
then: if the user agent can find a plugin suitable
according to the value of the classid attribute, and plugins aren't being sandboxed,
then that plugin should be
used, and the value of the data attribute, if any, should be
passed to the plugin. If no suitable
plugin can be found, or if the plugin
reports an error, jump to the last step in the overall set of
steps (fallback).
If the data attribute
is present, then:
If the type
attribute is present and its value is not a type that the user
agent supports, and is not a type that the user agent can find a
plugin for, then the user agent may jump to the last
step in the overall set of steps (fallback) without fetching the
content to examine its real type.
Resolve the
URL specified by the data attribute, relative to the
element.
If that is successful, fetch the resulting absolute URL.
Fetching the resource must delay the load event of the element's document until the task that is queued by the networking task source once the resource has been fetched (defined next) has been run.
If the resource is not yet available (e.g. because the resource was not available in the cache, so that loading the resource required making a request over the network), then jump to the last step in the overall set of steps (fallback). The task that is queued by the networking task source once the resource is available must restart this algorithm from this step. Resources can load incrementally; user agents may opt to consider a resource "available" whenever enough data has been obtained to begin processing the resource.
If the load failed (e.g. the URL could not be
resolved, there was an HTTP
404 error, there was a DNS error), fire a simple
event called error at the
element, then jump to the last step in the overall set of steps
(fallback).
Determine the resource type, as follows:
Let the resource type be unknown.
If the resource has associated Content-Type metadata, then let the resource type be the type specified in the resource's Content-Type metadata.
If the resource type is unknown or
"application/octet-stream" and there is
a type attribute present
on the object element, then change the resource type to instead be the type specified
in that type
attribute.
Otherwise, if the resource type is
"application/octet-stream" but there is
no type attribute on the
object element, then change the resource type to be unknown, so that the
sniffing rules in the next step are invoked.
If the resource type is still unknown, then change the resource type to instead be the sniffed type of the resource.
Handle the content as given by the first of the following cases that matches:
The user agent should use that plugin and pass the content of the resource to that plugin. If the plugin reports an error, then jump to the last step in the overall set of steps (fallback).
image/"The object element must be associated with a
nested browsing context, if it does not already
have one. The element's nested browsing context
must then be navigated to the
given resource, with replacement enabled, and
with the object element's document's
browsing context as the source browsing
context. (The data attribute of the
object element doesn't get updated if the
browsing context gets further navigated to other
locations.)
The object element represents the
nested browsing context.
If the name attribute
is present, the browsing context name must be set
to the value of this attribute; otherwise, the browsing
context name must be set to the empty string.
It's possible that the navigation of the browsing context will actually obtain the resource from a different application cache. Even if the resource is then found to have a different type, it is still used as part of a nested browsing context; this algorithm doesn't restart with the new resource.
image/", and support for images has not been
disabledApply the image sniffing rules to determine the type of the image.
The object element represents the
specified image. The image is not a nested browsing
context.
If the image cannot be rendered, e.g. because it is malformed or in an unsupported format, jump to the last step in the overall set of steps (fallback).
The given resource type is not supported. Jump to the last step in the overall set of steps (fallback).
The element's contents are not part of what the
object element represents.
Once the resource is completely loaded, queue a
task to fire a simple event called load at the element.
The task source for this task is the DOM manipulation task source.
If the data attribute
is absent but the type
attribute is present, plugins
aren't being sandboxed, and the user agent can find a plugin
suitable according to the value of the type attribute, then that plugin
should be used. If no suitable plugin
can be found, or if the plugin reports an error, jump to the next
step (fallback).
(Fallback.) The object element
represents the element's children, ignoring any
leading param element children. This is the element's
fallback content.
When the algorithm above instantiates a
plugin, the user agent should pass the names and values
of all the attributes on the element, and all the names and
values of parameters
given by param elements that are children of the
object element, in tree order, to the
plugin used. If the plugin supports a
scriptable interface, the HTMLObjectElement object
representing the element should expose that interface. The
object element represents the
plugin. The plugin is not a nested
browsing context.
If the sandboxed plugins browsing
context flag is set on the browsing context for
which the object element's document is the active
document, then the steps above must always act as if they had
failed to find a plugin, even if one would otherwise have been
used.
Due to the algorithm above, the contents of object
elements act as fallback content, used only when
referenced resources can't be shown (e.g. because it returned a 404
error). This allows multiple object elements to be
nested inside each other, targeting multiple user agents with
different capabilities, with the user agent picking the first one it
supports.
Whenever the name attribute
is set, if the object element has a nested
browsing context, its name must be changed to the new value. If the attribute
is removed, if the object element has a browsing
context, the browsing context name must be set
to the empty string.
The usemap attribute,
if present while the object element represents an
image, can indicate that the object has an associated image
map. The attribute must be ignored if the
object element doesn't represent an image.
The form attribute is used to
explicitly associate the object element with its
form owner.
Constraint validation: object
elements are always barred from constraint
validation.
The object element supports dimension
attributes.
The DOM attributes data, type, name, and useMap each must
reflect the respective content attributes of the same
name.
The contentDocument
DOM attribute must return the Document object of the
active document of the object element's
nested browsing context, if it has one; otherwise, it
must return null.
The contentWindow
DOM attribute must return the WindowProxy object of the
object element's nested browsing context,
if it has one; otherwise, it must return null.
In the following example, a Java applet is embedded in a page
using the object element. (Generally speaking, it is
better to avoid using applets like these and instead use native
JavaScript and HTML to provide the functionality, since that way
the application will work on all Web browsers without requiring a
third-party plugin. Many devices, especially embedded devices, do
not support third-party technologies like Java.)
<figure> <object type="application/x-java-applet"> <param name="code" value="MyJavaClass"> <p>You do not have Java available, or it is disabled.</p> </object> <legend>My Java Clock</legend> </figure>
In this example, an HTML page is embedded in another using the
object element.
<figure> <object data="clock.html"></object> <legend>My HTML Clock</legend> </figure>
param elementStatus: Implemented and widely deployed
object element, before any flow content.namevalueinterface HTMLParamElement : HTMLElement {
attribute DOMString name;
attribute DOMString value;
};
The param element defines parameters for plugins
invoked by object elements. It does not represent anything on its own.
The name
attribute gives the name of the parameter.
The value
attribute gives the value of the parameter.
Both attributes must be present. They may have any value.
{kind=link}