VoID is an RDF Schema vocabulary for expressing metadata about RDF data sets, a mechanism for publishers to report their data, and an entrance point for consumers
to discover and retrieve data sets.
This document is a detailed guide to extend the VoID vocabulary for the particularities of binary RDF in HDT format, improving the publishing and exchanging RDF data at large scale.
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications can be found in the W3C technical reports index at http://www.w3.org/TR/.
This document is a part of the HDT Submission which comprises five documents:
- Binary RDF Representation for Publication and Exchange (HDT)
- Extending VoID for publishing HDT
- RDF Schema for HDT Header Descriptions
- Relationship of HDT to relevant other technologies
- Implementation of HDT
By publishing this document, W3C acknowledges that the Submitting Members have made a formal Submission request to W3C for discussion. Publication of this document by W3C indicates no endorsement of its content by W3C, nor that W3C has, is, or will be allocating any resources to the issues addressed by it. This document is not the product of a chartered W3C group, but is published as potential input to the W3C Process. A W3C Team Comment has been published in conjunction with this Member Submission. Publication of acknowledged Member Submissions at the W3C site is one of the benefits of W3C Membership. Please consult the requirements associated with Member Submissions of section 3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member Submissions.
Table of Contents
1. Introduction
RDF HDT is an RDF data-centric format which reduces verbosity in favor of machine-understandability and data management. It is based on two main components:
- Dictionary, organizes all vocabulary present in the RDF graph in a manner that avoids repetitions and permits rapid search and high levels of compression.
- Triples, comprises the pure structure of the underlying graph, avoiding noise produced by long labels, repetitions, etc.
This document is focused on describing a extension of VoID vocabulary to describe the third additional HDT Component, the Header, which SHOULD include logical and physical metadata required to describe the RDF data set.
The added features can be summarized as follows:
- Cleaner Publication and exchange, it allows to identify and structure different types of metadata and hence make a cleaner publication.
- Binary format specification, both Dictionary and Triples configuration can be further described.
The keywords "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119]
The proposed extension assumes that the Header is an RDF graph. The triples of this graph SHOULD
contain metadata about a publication together with the information required to retrieve and process the represented RDF graph in a machine processable format.
Additionally it MAY contain additional metadata not related to these processes.
In this proposal, the Header of the HDT is described in RDF as an hdt:Dataset element, which is a subclass of void:Dataset (rdfs:subClassOf property). Thus, the Header can make use of VoID properties to describe the HDT data set and further extend the metada.
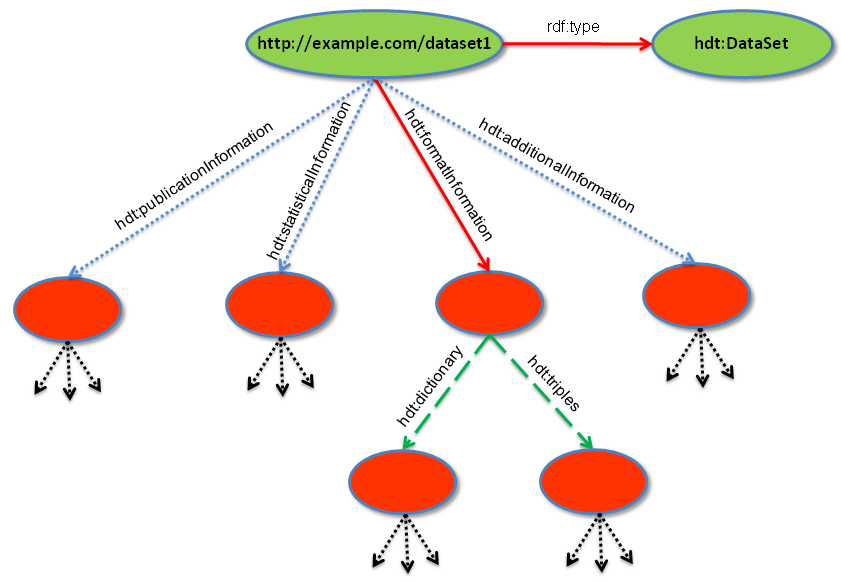 Figure 2: The structure of the proposed Header of HDT (PNG)
Figure 2: The structure of the proposed Header of HDT (PNG)
The structure of the proposed Header is represented in Figure 2. A Header MUST describe at least one resource hdt:Dataset, which is a subclass of void:Dataset (rdfs:subClassOf property). This resource SHOULD be described by at most four top-level statements (containers), leading to intermediate blank nodes which contain the four types of metadata information, which is described in the next subsections. Exactly one format metadata description MUST be present in order to retrieve the data set, and hdt:dictionary and hdt:triples definition (or subproperties of them) are REQUIRED.
Example 1 shows an RDF/XML Header example. Blank nodes have been omitted with rdf:parseType="Resource" feature ([RDF/XML], section 2.11).
It groups the statements about the publication act, i.e. the process of making RDF data publicly available for several purposes and users.
I addition to VoID properties, e.g. void:sparqlEndpoint, the use of well-known vocabularies is highly recommended, such as Dublin Core for basic metada or the [WAIVER] vocabulary for rights.
Publishers include statistical statements about the data which can provide a fast
overview of the data set complexity as well as serving for the final application (e.g. in visualization and summary). VoID property set includes statistics such as
the number of RDF triples of the data set, or the number of described entities.
[RDFStats] histograms or semantic statistics with SDMX [SDMX-SCOVO] can also be included.
In Example 1, void:statItem is used in conjunction with SCOVO.
It groups the statements specifying the concrete Dictionary and Triples component representation as well as their
physical location. For clarification, the format subproperties are described in
the Dictionary and Triples sections.
This metadata MUST be present in order to retrieve the data set, and it is REQUIRED to contain an hdt:dictionary and hdt:triples definition (or subproperties of them), as shown in Figure 2.
It contains all the further information a publisher wants to provide, e.g. annotations, or a signature as in Example 1.
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:hdt="http://purl.org/HDT/hdt#"
xmlns:dc="http://purl.org/dc/terms/"
xmlns:void="http://rdfs.org/ns/void#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:scovo="http://purl.org/NET/scovo#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:swp="http://www.w3.org/2004/03/trix/swp-2/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#">
<hdt:Dataset rdf:about="http://example.org/ex/DBpediaEN"> <!-- MUST -->
<hdt:publicationInformation rdf:parseType="Resource"> <!-- SHOULD -->
<void:dataDump rdf:resource="http://example.org/ex/DBpediaEN.rdf"/> <!-- this is the URI of the HDT Header -->
<dc:title>DBpediaEN</dc:title>
<dc:publisher>
<foaf:Organization>
<foaf:homepage rdf:resource="http://example.org/theCompany"/>
</foaf:Organization>
</dc:publisher>
<dc:issued>2010-10-01</dc:issued>
<dc:source rdf:resource="http://downloads.dbpedia.org/3.5.1/en/"/>
<dc:license rdf:resource="http://www.gnu.org/copyleft/fdl.html"/>
</hdt:publicationInformation>
<hdt:statisticalInformation rdf:parseType="Resource"> <!-- SHOULD -->
<void:statItem rdf:parseType="Resource">
<scovo:dimension rdf:resource="void:numberOfTriples"/>
<rdf:value>7</rdf:value>
</void:statItem>
</hdt:statisticalInformation>
<hdt:formatInformation rdf:parseType="Resource"> <!-- MUST -->
<hdt:dictionary rdf:parseType="Resource"> <!-- REQUIRED -->
<hdt:fileLocation rdf:resource="http://example.org/ex/DBpediaEN.dic"/>
<dc:format>application/x-gzip</dc:format>
<hdt:dictionarySeparator>\2</hdt:dictionarySeparator>
<hdt:dictionaryOrder rdf:resource="hdt:alphabetical_order"/>
<hdt:dictionaryEncoding>utf8</hdt:dictionaryEncoding>
<hdt:dictionaryNamespaces rdf:parseType="Resource">
<hdt:namespace rdf:parseType="Resource">
<hdt:prefixLabel>wiki</hdt:prefixLabel>
<hdt:prefixURI>http://en.wikipedia.org/wiki/
wikipedia#
</hdt:prefixURI>
</hdt:namespace>
</hdt:dictionaryNamespaces>
</hdt:dictionary>
<hdt:triplesBitmap rdf:parseType="Resource"> <!-- REQUIRED -->
<hdt:predicateStream rdf:parseType="Resource">
<hdt:fileLocation rdf:resource="http://example.org/ex/DBpediaEN.t3_p"/>
<dc:format>application/octet-stream</dc:format>
<hdt:IDCodification>32</hdt:IDCodification>
</hdt:predicateStream>
<hdt:objectStream rdf:parseType="Resource">
<hdt:fileLocation rdf:resource="http://example.org/ex/DBpediaEN.t3_o"/>
<hdt:IDCodification>32</hdt:IDCodification>
</hdt:objectStream>
<hdt:predicateBitmap rdf:parseType="Resource">
<hdt:fileLocation rdf:resource="http://example.org/ex/DBpediaEN.t3_pb"/>
</hdt:predicateBitmap>
<hdt:objectBitmap rdf:parseType="Resource">
<hdt:fileLocation rdf:resource="http://example.org/ex/DBpediaEN.t3_ob"/>
</hdt:objectBitmap>
</hdt:triplesBitmap>
</hdt:formatInformation>
<hdt:additionalInformation rdf:parseType="Resource"> <!-- SHOULD -->
<swp:signatureMethod rdf:resource="swp:JjcC14N-md5-xor-rsa"/>
<swp:signature rdf:datatype="xsd:base64Binary">AZ8QWE...</swp:signature>
</hdt:additionalInformation>
</hdt:Dataset>
</rdf:RDF>
3. Dictionary Configuration
The goal of the Dictionary component of HDT is to assign a unique ID to each element in the data set contributing to compactness. There is no restriction on the particular mapping or implementation, but a dictionary codification by default (section 3.3.2) is given. This MUST be assumed if hdt:dictionary is defined inside the hdt:formatInformation property of the Header. The dictionary implementation MAY be changed by specifying a new subproperty of hdt:dictionary
The dictionary concrete configuration is set up inside the hdt:dictionary property (or subproperties of it). A configuration example is shown in Example 1.
| Property |
Use |
| hdt:fileLocation
|
Set up the URI location of the dictionary. This property MUST be specified.
|
| dc:format
|
Set up the format of the dictionary. The use of MYME types is highly recommended. The default value is set to plain/text.
|
| hdt:dictionarySeparator
|
The reserved separator character. The default value is '\2'.
|
| hdt:dictionaryOrder
|
The order inside each defined subset in the dictionary. By default there is no implicit order.
|
| hdt:dictionaryEncoding
|
The dictionary encoding. By default, utf8.
|
| hdt:dictionaryNamespaces
|
The prefixes to be used in the dictionary. Each namespace (hdt:namespace) has an hdt:prefixURI and hdt:prefixLabel. The reserved 'base' label prefix can be defined to serve as the base URI when parsing relative URIs.
|
When hdt:dictionary is defined, the presence of several hdt:fileLocation properties (dictionary chunks)
MUST be included inside a list of properties and interpreted as a continuous order in the mapping sequence.
Note than a different interpretation MAY be given within another dictionary implementation.
4. Triples Configuration
The Triples component contains the structure of the data after the ID replacement. It is described inside the hdt:triples property (or subproperties) of the Header.
There is no restriction on the particular implementation, but three implementations are considered as subproperties of hdt:triples. These possibilities are described in the HDT specification (section 3.4). Further triple implementations MAY be established by specifying a new subproperty of hdt:triples. The implementation by default MUST be interpreted as Bitmap Triples.
4.1 Plain TriplesConfiguration
This is the most naive approach (supported for completeness) in which only the ID substitution is performed. This option is denoted by the hdt:triplesPlain property
in the Header.
The physical file contains three ID per triple, each of them codified with the number of bits given in the triples configuration.
| Property |
Use |
| hdt:fileLocation
|
Set up the URI location of the triples. This property MUST be specified.
|
| dc:format
|
Set up the format encoding of the triples. The use of MYME types is highly recommended. The default value is set to application/octetstream.
|
| hdt:IDCodification
|
The number of bits of each ID. The default value is set to 32. The value hdt:logBits MUST be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects, predicates or objects.
|
| hdt:subjectCodification
|
The number of bits of the subject IDs. This element MUST supersede the hdt:IDCodification if both properties coexist in the same configuration. The value hdt:logBits MUST be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects.
|
| hdt:predicateCodification
|
The number of bits of the predicate IDs. This element MUST supersede the hdt:IDCodification if both properties coexist in the same configuration. The value hdt:logBits MUST be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total predicates.
|
| hdt:objectCodification
|
The number of bits of the object IDs. This element MUST supersede the hdt:IDCodification if both properties coexist in the same configuration. The value hdt:logBits MUST be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total objects.
|
When hdt:triplesPlain is defined, the presence of several hdt:fileLocation properties (triples chunks) MUST be included inside a list of properties and interpreted as a continuous order.
A specific codification for each element is available using hdt:subjectCodification, hdt:predicateCodification and hdt:objectCodification. This provides flexibility and space savings, e.g. keeping the default codification to 32 bits but specifying an hdt:predicateCodification, because the limited size of the predicates allows them to be represented with fewer bits.
4.2 Compact Triples Configuration
This option is denoted by the hdt:triplesCompact property in the Header, and implies a
triple sorting by subject and the creation of predicate and object adjacency lists.
Both predicateStream and objectStream MUST be defined inside the hdt:triplesCompact property of the Header.
This format, by default, assume an S-P-O Adj. List, being S implicitly represented and P as the key stream to access object stream. Alternative representations are also possible, i.e., S-O-P Adj. List, P-S-O, P-O-S, O-P-S Adj. List and O-S-P Adj. List. If one of these alternative representations is taken, this MUST be specified in the Header through streamsOrder. Consequently, a specification of subjectStream in the Header MAY be needed in some Adj. List representation.
For each hdt:objectStream, hdt:predicateStream (and hdt:subjectStream if the Adj. List order is changed), there exists configuration properties:
| Property |
Use |
| hdt:fileLocation
|
Set up the URI location of the stream. This property MUST be specified.
|
| dc:format
|
Set up the format encoding of the stream. The use of MYME types is highly recommended. The default value is set to application/octetstream.
|
| hdt:IDCodification
|
The number of bits of each ID. The default value is set to 32. The value hdt:logBits) MUST be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects, predicates or objects (depend on the considered stream).
|
When hdt:triplesCompact is defined, the presence of several hdt:fileLocation properties (streams chunks)
MUST be included inside a list of properties and interpreted as a continuous order.
4.3 Bitmap Triples Configuration
This format, denoted by hdt:triplesBitmap in the Header, extracts the 0's out of the predicate and object streams of compact triple representation. The graph structure is indexed with two bitsequences (Bp and Bo, for predicates
and objects) in which 0-bits mark IDs in the corresponding Sp or So sequence, whereas
1-bits are used to mark the end of an adjacency list.
Both Sp and So streams, through hdt:predicateStream and hdt:objectStream, MUST be defined inside the hdt:triplesBitmap property of the Header.
Bitmaps, Bp and Bo, MUST be specified with hdt:predicateBitmap and hdt:objectBitmap.
This format, by default, assume a S-P-O Adj. List, being S implicitly represented and P as the key stream to access object stream. Alternative representations are also possible, i.e., S-O-P Adj. List, P-S-O, P-O-S, O-P-S Adj. List and O-S-P Adj. List. If one of this alternative representation is taken, this MUST be specified in the Header through streamsOrder. Consequently, a specification of subjectStream and subjectBitmapin the Header MAY be needed in some Adj. List representation.
For each hdt:objectStream, hdt:predicateStream (and hdt:subjectStream if the Adj. List order is changed), there exists configuration properties:
| Property |
Use |
| hdt:fileLocation
|
Set up the URI location of the stream. This property MUST be specified.
|
| dc:format
|
Set up the format encoding of the stream. The use of MYME types is highly recommended. The default value is set to application/octetstream.
|
| hdt:IDCodification
|
The number of bits of each ID. The default value is set to 32. The value hdt:logBits) MUST be interpreted as follows: each ID is encoded with log(n) bits, n being the number of total subjects, predicates or objects (depend on the considered stream).
|
When hdt:triplesBitmap is defined, the presence of several
hdt:fileLocation properties (streams chunks) MUST be included inside a list of properties and
interpreted as a continuous order.
For each hdt:predicateBitmap, hdt:objectBitmap (and hdt:subjectBitmap if the Adj. List order is changed), there exists configuration properties:
| Property |
Use |
| hdt:fileLocation
|
Set up the URI location of the bitmap. This property MUST be specified.
|
| dc:format
|
Set up the format encoding of the bitmap. The use of MYME types is highly recommended. The default value is set to application/octetstream.
|
When hdt:triplesBitmap is defined, the presence of several
hdt:fileLocation properties (bitmap chunks) MUST be included inside a list of properties and
interpreted as a continuous order.
5. Identifiers For HDT
The URI identifying the HDT representation is: http://purl.org/HDT/hdt#hdt
The Vocabulary used for HDT specification is:
Namespace: http://purl.org/HDT/hdt#
Local name: hdt.
A. References
-
[VoID]
-
K. Alexander, R. Cyganiak, M. Hausenblas, and J. Zhao. Describing Linked Datasets with the VoID Vocabulary. W3C Interest Group Note 03 March 2011. Available at http://www.w3.org/TR/2011/NOTE-void-20110303/.
-
[SDMX-SCOVO]
-
D. Ayers, L. Feigenbaum, M. Hausenblas, T. Heath, W. Halb, Y. Raimond. The Statistical Core Vocabulary (SCOVO). Available at http://vocab.deri.ie/scovo.
-
[RDFStats]
-
A. Langegger and W. Woss. Rdfstats - an extensible rdf statistics generator and library. In
Workshop on Database and Expert Systems Application, pages 79-83, 2009.
-
[KEYWORDS]
-
S. Bradner. Key words for use in RFCs to Indicate Requirement Levels. The Internet Society, March 1997. Available at http://www.ietf.org/rfc/rfc2119.txt.
-
[RDF/XML]
-
D. Beckett. RDF/XML Syntax Specification (Revised). W3C Recommendation 10 February 2004. Available at http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/
-
[WAIVER]
-
I. Davis. WAIVER: A vocabulary for waivers of rights. 6 July 2009. Available at http://vocab.org/waiver/terms/
B. Acknowledgements (Informative)
HDT work is partially funded by MICINN (TIN2009-14009-C02-02), Millennium Institute for Cell Dynamics and Biotechnology (ICDB) (Grant ICM P05-001-F), and Fondecyt 1090565 and 1110287. Javier D. Fernández is granted by the Regional Government of Castilla y Leon (Spain) and the European Social Fund.