Tutorial on Semantic Web Technologies
$Date: 2010/04/14 17:36:38 $
Ivan Herman, W3C
Introduction
Towards a Semantic Web
The current Web represents information using
natural language (English, Hungarian, Chinese,…)
graphics, multimedia, page layout
Humans can process this easily
can deduce facts from partial information
can create mental associations
are used to various sensory information
(well, sort of… people with disabilities may have serious problems on the Web with rich media!)
Towards a Semantic Web
Tasks often require to combine data on the Web:
hotel and travel information may come from different sites
searches in different digital libraries
etc.
Again, humans combine these information easily
even if different terminologies are used!
However…
However: machines are ignorant!
partial information is unusable
difficult to make sense from, e.g., an image
drawing analogies automatically is difficult
difficult to combine information
is <foo:creator> same as <bar:author>?
how to combine different XML hierarchies?
…
Example: Searching
The best-known example…
Google et al. are great, but there are too many false or missing hits
e.g., if you search in for “yacht racing”, the America’s Cup will be way down in the ranking order
adding (maybe application specific) descriptions to resources should improve this
Example: Digital Libraries
It is a bit like the search example
It means catalogs on the Web
librarians have known how to do that for centuries
goal is to have this on the Web, World-wide
extend it to multimedia data, too
But it is more: software agents should also be librarians!
help you in finding the right publications
Example: Automatic Airline Reservation
Your automatic airline reservation
knows about your preferences
builds up knowledge base using your past
can combine the local knowledge with remote services:
airline preferences
dietary requirements
calendaring
etc
It communicates with remote information (i.e., on the Web!)
(M. Dertouzos: The Unfinished Revolution)
Example: Data(base) Integration
Databases are very different in structure, in content
Lots of applications require managing several databases
after company mergers
combination of administrative data for e-Government
biochemical, genetic, pharmaceutical research
etc.
Most of these data are now on the Web (though not necessarily public yet)
The semantics of the data(bases) should be known (how this semantics is mapped on internal structures is immaterial)
Example: Semantics of Web Services
Web services technology is great
But if services are ubiquitous, searching issue comes up, for example:
“find me the best differential equation solver”
“check if it can be combined with the XYZ plotter service”
It is necessary to characterize the service
not only in terms of input and output parameters…
…but also in terms of its semantics
Introductory Example
We will use a simplistic example to introduce the main Semantic Web concepts
We take, as an example area, data integration
The Rough Structure of Data Integration
Map the various data onto an abstract data representation
make the data independent of its internal representation…
Merge the resulting representations
Start making queries on the whole!
queries that could not have been done on the individual data sets
A Simplifed Bookstore Data (Dataset “A”)
ID
Author
Title
Publisher
Year
ISBN 0-00-651409-X
id_xyz
The Glass Palace
id_qpr
2000
ID
Name
Home page
id_xyz
Amitav Ghosh
http://www.amitavghosh.com/
ID
Publisher Name
City
id_qpr
Harper Collins
London
1st Step: Export Your Data as a Set of Relations
Some Notes on the Exporting the Data
Relations form a graph
the nodes refer to the “real” data or contain some literal
how the graph is represented in machine is immaterial for now
Data export does not necessarily mean physical conversion of the data
relations can be generated on-the-fly at query time
via SQL “bridges”
scraping HTML pages
extracting data from Excel sheets
etc.
One can export part of the data
Another Bookstore Data (dataset “F”)
ID
Titre
Auteur
Traducteur
Original
ISBN 2020386682
Le Palais des miroirs
i_abc
i_qrs
ISBN 0-00-651409-X
ID
Nom
i_abc
Amitav Ghosh
i_qrs
Christiane Besse
2nd Step: Export Your Second Set of Data
3rd Step: Start Merging Your Data
3rd Step: Start Merging Your Data (cont.)
3rd Step: Merge Identical Resources
Start Making Queries…
User of data “F” can now ask queries like:
« donnes-moi le titre de l’original »
(ie: “give me the title of the original”)
This information is not in the dataset “F”…
…but can be automatically retrieved by merging with dataset “A”!
However, More Can Be Achieved…
We “feel” that a:author and f:auteur should be the same
But an automatic merge doest not know that!
Let us add some extra information to the merged data:
a:author same as f:auteurboth identify a “Person”:
a term that a community may have already defined:
a “Person” is uniquely identified by his/her name and, say, homepage or email
it can be used as a “category” for certain type of resources
3rd Step Revisited: Use the Extra Knowledge
Start Making Richer Queries!
User of dataset “F” can now query:
« donnes-moi la page d’accueil de l’auteur de l’original »
(ie, “give me the home page of the original’s author”)
The data is not in dataset “F”…
…but was made available by:
merging datasets “A” and “F”
adding three simple extra statements as an extra knowledge
using existing terminologies as part of that extra knoweledge
Combine With Different Datasets
Using, e.g., the “Person”, the dataset can be combined with other sources
For example, data in Wikipedia can be extracted using simple (e.g., XSLT) tools
there is an active development to add some simple semantic “tag” to wikipedia entries
we tacitly presuppose their existence in our example…
Merge with Wikipedia Data
Is That Surprising?
Maybe but, in fact, no…
What happened via automatic means is done all the time, every day by the users of the Web!
The difference: a bit of extra rigor (e.g., naming the relationships) is necessary so that machines could do this, too
What Did We Do?
We combined different datasets
all may be of different origin somewhere on the web
all may have different formats (mysql, excel sheet, XHTML, etc)
all may have different names for relations (e.g., multilingual)
We could combine the data because some URI-s were identical (the ISBN-s in this case)
We could add some simple additional knowledge, also using common terminologies that a community has produced
As a result, new relations could be found and retrieved
It Could Become Even More Powerful
The added extra knowledge could be much more complex to the merged datasets
e.g., a full classification of various type of library data, types of books (literature or not, fiction, poetry, etc)
geographical information
information on inventories, prices
etc.
This is where ontologies , extra rules , etc, may come in
Even more powerful queries can be asked as a result
What did we do? (cont)
The Abstraction Pays Off Because…
… the graph representation is independent on the exact structures in, say, a relational database
… a change in local database schemas, XHTML structures, etc, do not affect the whole, only the “export” step
… new data, new connections can be added seamlessly, regardless of the structure of other data sources
So Where is the Semantic Web?
The Semantic Web provides technologies to make such integration possible!
(hopefully you get a full picture at the end of the tutorial…)
Basic RDF
RDF Triples
Let us begin to formalize what we did!
we “connected” the data…
but a simple connection is not enough… it should be named somehow
hence the RDF Triples: a labelled connection between two resources
RDF Triples (cont.)
An RDF Triple (s,p,o) is such that:
“s”, “p” are URI-s, ie, resources on the Web; “o” is a URI or a literal
conceptually: “p” connects , or relates the “s” and ”o”
note that we use URI-s for naming: i.e., we can use http://www.example.org/original
here is the complete triple:
(<http://…isbn…6682>, <http://…/original>, <http://…isbn…409X>)
RDF is a general model for such triples (with machine readable formats like RDF/XML, Turtle, n3, RXR, …)… and that’s it! (simple, isn't it?
RDF Triples (cont.)
RDF Triples are also referred to as “triplets” , or “statement”
The s, p, o resources are also referred to as “subject” , “predicate” , ”object” , or “subject” , ”property” , ”object”
Resources can use any URI; e.g., it can denote an element within an XML file on the Web, not only a “full” resource, e.g.:
http://www.example.org/file.xml#xpointer(id('home'))
http://www.example.org/file.html#home
RDF Triples form a directed, labelled graph (best way to think about them!)
A Simple RDF Example (in RDF/XML)
<rdf:Description rdf:about="http://…/isbn/2020386682">
<f:titre xml:lang="fr">Le palais des mirroirs</f:titre>
<f:original rdf:resource="http://…/isbn/000651409X"/>
</rdf:Description>
(Note: namespaces are used to simplify the URI-s)
A Simple RDF Example (in Turtle)
<http://…/isbn/2020386682>
f:titre "Le palais des mirroirs"@fr;
f:original <http://…/isbn/000651409X>.
URI-s Play a Fundamental Role
URI-s made the merge possible
Anybody can create (meta)data on any resource on the Web
e.g., the same XHTML file could be annotated through other terms
semantics is added to existing Web resources via URI-s
URI-s make it possible to link (via properties) data with one another
URI-s ground RDF into the Web
information can be retrieved using existing tools
this makes the “Semantic Web”, well… “Semantic Web ”
RDF/XML Principles
Encode nodes and edges as XML elements or with literals:
«Element for http://…/isbn/2020386682»
«Element for original»
«Element for http://…/isbn/000651409X»
«/Element for original»
«/Element for http://…/isbn/2020386682»
«Element for http://…/isbn/2020386682»
«Element for titre»
Le palais des mirroirs
«/Element for titre»
«/Element for http://…/isbn/2020386682»
RDF/XML Principles (cont)
Encode the resources (i.e., the nodes):
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="http://…/isbn/2020386682">
«Element for f:original»
<rdf:Description rdf:about="http://…/isbn/000651409X"/>
«/Element for f:original»
</rdf:Description>
<rdf:RDF>
RDF/XML Principles (cont)
Encode the property (i.e., edge) in its own namespace:
<rdf:RDF
xmlns:f="http://www.editeur.fr"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="http://…/isbn/2020386682">
<f:original>
<rdf:Description rdf:about="http://…/isbn/000651409X"/>
</f:original>
</rdf:Description>
<rdf:RDF>
Examples of RDF/XML “Simplifications”
Object references can be put into attributes
Several properties on the same resource
<rdf:Description rdf:about="http://…/isbn/2020386682">
<f:original rdf:resource="http://…/isbn/000651409X"/>
<f:titre>Chart</axsvg:graphicsType xml:lang="fr">
Le palais des mirroirs
</f:titre>
</rdf:Description>
“Internal” Nodes
Consider the following statement:
“the publisher is a «thing» that has a name and an address”
Until now, nodes were identified with a URI. But…
…what is the URI of «thing»?
One Solution: Define Extra URI-s
Give an id with rdf:ID (essentially, defining a URI)
<rdf:Description rdf:about="http://…/isbn/000651409X">
<a:publisher rdf:resource="#Thing" />
</rdf:Description>
<rdf:Description rdf:ID="Thing" >
<a:p_name>HarpersCollins</a:p_name>
<a:city>HarpersCollins</a:city>
</rdf:Description>
Defines a fragment identifier within the RDF file
Identical to the id in HTML, SVG, … (i.e., it can be referred to with regular URI-s from the outside)
Note: this is an RDF/XML feature, not part of the RDF model!
Turtle has something similar, too
Blank Nodes
Use an internal identifier
<rdf:Description rdf:about="http://…/isbn/000651409X">
<a:publisher rdf:nodeID="A234" />
</rdf:Description>
<rdf:Description rdf:nodeID="A234" >
<a:p_name>HarpersCollins</a:p_name>
<a:city>HarpersCollins</a:city>
</rdf:Description>
<http://…/isbn/2020386682> a:publisher _:A234 .
_:A234 a:p_name "HarpersCollins".
A234 is invisible from outside the file (it is not a “real” URI! ); it is an internal identifier for a resource
Blank Nodes: the System Can Also Do It
Let the system create a nodeID internally (you do not
really care about the name…)
<rdf:Description rdf:about="http://…/isbn/000651409X">
<a:publisher>
<rdf:Description>
<a:p_name>HarpersCollins</a:p_name>
…
</rdf:Description>
</a:publisherA>
</rdf:Description>
Same in Turtle
<http://…/isbn/000651409X> a:publisher [
a:p_name "HarpersCollins";
…
].
Blank Nodes: Some More Remarks
Blank nodes require attention when merging
blanks nodes with identical nodeID-s in different graphs are different
the implementation must be be careful with its naming schemes when merging
From a logic point of view, blank nodes represent an “existential” statement (“there is a resource such that…”)
RDF in Programming Practice
For example, using Java+Jena (HP’s Bristol Lab):
a “Model” object is created
the RDF file is parsed and results stored in the Model
the Model offers methods to retrieve:
triples
(property,object) pairs for a specific subject
(subject,property) pairs for specific object
etc.
the rest is conventional programming…
Similar tools exist in Python, PHP, etc. (see later)
Jena Example
// create a model
Model model=new ModelMem();
Resource subject=model.createResource("URI_of_Subject")
// 'in' refers to the input file
model.read(new InputStreamReader(in));
StmtIterator iter=model.listStatements(subject,null,null);
while(iter.hasNext()) {
st = iter.next();
p = st.getProperty();
o = st.getObject();
do_something(p,o);
}
Merge in Practice
Environments merge graphs automatically
e.g., in Jena, the Model can load several files
the load merges the new statements automatically
RDFSchemas
Need for RDF Schemas
This is the simple form of our “extra knowledge”:
define the terms we can use
what restrictions apply
what extra relationships are there?
This is where RDF Schemas come in
officially: “RDF Vocabulary Description Language”; the term “Schema” is retained for historical reasons…
Classes, Resources, …
Think of well known in traditional ontologies:
use the term “novel”
“every novel is a fiction”
“«The Glass Palace» is a novel”
etc.
RDFS defines resources and classes :
everything in RDF is a “resource”
“classes” are also resources, but…
…they are also a collection of possible resources (i.e., “individuals”)
Classes, Resources, … (cont.)
Relationships are defined among classes/resources:
“typing”: an individual belongs to a specific class (“«The Glass Palace» is a novel”)
to be more precise: “«isbn:000651409X» is a novel”
“subclassing”: instance of one is also the instance of the other (“every novel is a fiction”)
RDFS formalizes these notions in RDF
Classes, Resources in RDF(S)
RDFS defines rdfs:Resource, rdfs:Class as nodes; rdf:type, rdfs:subClassOf as properties
(these are all special URI-s, we just use the namespace abbreviation)
Schema Example in RDF/XML
The schema part (“application’s data types”):
<rdf:Description rdf:ID="Novel">
<rdf:type rdf:resource= "http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
The RDF data on a specific novel (“using the type”):
<rdf:Description rdf:about="http://…/isbn/000651409X">
<rdf:type rdf:resource="http://…/bookSchema.rdf#Novel"/>
</rdf:Description>
In traditional knowledge representation this separation is often referred to as: “Terminological axioms” and “Assertions”
An Aside: Typed Nodes in RDF/XML
A frequent simplification rule: instead of:
<rdf:Description rdf:about="http://...">
<rdf:type rdf:resource="http://..../something#ClassName>
...
</rdf:Description>
<yourNameSpace:ClassName rdf:about="http://...">
...
</yourNameSpace:ClassName>
<a:Novel rdf:about="http://…/isbn/000651409X">
...
</a:Novel>
Further Remarks on Types
A resource may belong to several classes
rdf:type is just a property…
“«The Glass Palace» is a novel, but «The Glass Palace» is also an «inventory item»…”
i.e., it is not like a datatype!
The type information may be very important for applications
e.g., it may be used for a categorization of possible nodes
probably the most frequently used rdf predicate…
(remember the “Person” in our example?)
Inferred Properties
(<http://…/isbn/000651409X> rdf:type #Fiction)
is not in the original RDF data…
…but can be inferred from the RDFS rules
Better RDF environments return that triplet, too
Inference: Let Us Be Formal…
The RDF Semantics document has a list of (44) entailment rules :
“if such and such triplets are in the graph, add this and this triplet”
do that recursively until the graph does not change
this can be done in polynomial time for a specific graph
The relevant rule for our example:
If:
uuu rdfs:subClassOf xxx .
vvv rdf:type uuu .
Then add:
vvv rdf:type xxx .
Whether those extra triplets are physically added to the graph, or deduced when needed is an implementation issue
Properties
Property is a special class (rdf:Property)
properties are also resources identified by URI-s
Properties are constrained by their range and domain
i.e., what individuals can serve as object and subject
There is also a possibility for a “sub-property”
all resources bound by the “sub” are also bound by the other
Properties (cont.)
Properties are also resources (named via URI–s)…
So properties of properties can be expressed as… RDF properties
this twists your mind a bit, but you can get used to it
For example, (P rdfs:range C) means:
P is a property
C is a class instance
when using P, the “object” must be an individual in C
this is an RDF statement with subject P, object C, and property rdfs:range
Property Specification Example
Property Specification Serialized
In XML/RDF:
<rdfs:Property rdf:ID="title">
<rdf:domain rdf:resource="#Fiction"/>
<rdf:range rdf:resource="http://...#Literal"/>
</rdfs:Property>
In Turtle:
:title
rdf:type rdf:Property;
rdf:domain :Fiction;
rdf:range rdfs:Literal.
Literals
Literals may have a data type
floats, integers, booleans, etc, defined in XML Schemas
one can also define complex structures and restrictions via regular expressions, …
full XML fragments
(Natural) language can also be specified (via xml:lang)
XML Literals in RDF/XML
XML Literals
makes it possible to “include” XML vocabularies into RDF:
<rdf:Description rdf:about="#Path">
<axsvg:algorithmUsed rdf:parseType="Literal" >
<math xmlns="...">
<apply>
<laplacian/>
<ci>f</ci>
</apply>
</math>
</axsvg:algorithmUsed>
</rdf:Description/>
A Bit of RDFS Can Take You Far…
Remember the power of merge?
We could have used, in our example:
f:auteur is a subproperty of a:author and vice versa
(although we will see other ways to do that…)
Of course, in some cases, more complex knowledge is necessary are necessary (see later…)
Some Predefined Classes (Collections, Containers)
Predefined Classes and Properties
RDF(S) has some predefined classes and properties
They are not new “concepts” in the RDF Model, just resources with an agreed semantics
Examples:
collections (a.k.a. lists)
containers: sequence, bag, alternatives
reification
rdfs:comment, rdf:seeAlso, rdf:value
Collections (Lists)
We could have the following statement:
“The book inventory is a «thing» that consists of <http://…/isbn/000651409X>, <http://…/isbn/000XXXX>, …”
But we also want to express the constituents in this order
Using blank nodes is not enough
Collections (Lists) (cont.)
Familiar structure for Lisp programmers…
The Same in RDF/XML and Turtle
<rdf:Description rdf:about="#Inventory">
<a:consistsOf rdf:parseType="Collection" >
<rdf:Description rdf:about="http://.../isbn/000651409X"/>
<rdf:Description rdf:about="http://.../isbn/XXXX"/>
<rdf:Description rdf:about="http://.../isbn/YYYY"/>
</axsvg:consistsOf>
</rdf:Description>
:Inventory axsvg:consistsOf (<http://.../isbn/000651409X> <http://.../isbn/XXXX> …).
Sequences
Use the predefined:
RDF class Seq
RDF properties rdf:_1, rdf:_2, …
The agreed semantics is of a sequential containment
Sequences Serialized
In RDF/XML
<rdf:Description rdf:about="#Inventory">
<a:consistsOf>
<rdf:Description>
<rdf:type rdf:resource="http:...rdf-syntax-ns#Seq">
<rdf:_1 rdf:resource="http://.../isbn/000651409X>
...
</rdf:Description>
</a:consistsOf>
</rdf:Description/>
In Turtle
#Inventory
a:consistsOf [
rdf:type <http:...rdf-syntax-ns#Seq>;
rdf:_1 <http://.../isbn/000651409X>;
...
].
Sequences (simplified RDF/XML)
<rdf:Description rdf:about="#Inventory">
<a:consistsOf>
<rdf:Seq>
<rdf:li rdf:resource="http://.../isbn/000651409X">
...
</rdf:Seq>
</a:consistsOf>
</rdf:Description/>
Other Containers
rdf:Bag
a general bag, no particular semantics attached
rdf:Alt
attached semantics: only one of the constituents is “valid”
RDF Data Access, a.k.a. Query (SPARQL)
Querying RDF Graphs/Repositories
StmtIterator iter=model.listStatements(subject,null,null);
while(iter.hasNext()) {
st = iter.next();
p = st.getProperty(); o = st.getObject();
do_something(p,o);
In practice, more complex queries into the RDF data are necessary
something like: “give me the (a,b) pair of resources, for which there is an x such that (x parent a) and (b brother x) holds” (ie, return the uncles)
these rules may become quite complex
Queries become very important for distributed RDF data!
This is the goal of SPARQL (Query Language for RDF)
Analyze the Jena Example
StmtIterator iter=model.listStatements(subject,null,null);
while(iter.hasNext()) {
st = iter.next();
p = st.getProperty(); o = st.getObject();
do_something(p,o);
The (subject,?p,?o) is a pattern for what we are looking for (with ?p and ?o as “unknowns”)
General: Graph Patterns
The fundamental idea: generalize the approach to graph patterns :
the pattern contains unbound symbols
by binding the symbols (if possible), subgraphs of the RDF graph are selected
if there is such a selection, the query returns the bound resources
SPARQL
is based on similar systems that already existed in some environments
is a programming language-independent query language
Our Jena Example in SPARQL
SELECT ?p ?o
WHERE {subject ?p ?o}
The triplets in WHERE define the graph pattern, with ?p and ?o “unbound” symbols
The query returns a list of matching p,o pairs
Simple SPARQL Example
SELECT ?isbn ?price ?currency # note: not ?x!
WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency. }
Returns: [[<..49X>,33,£], [<..49X>,50,€], [<..6682>,60,€], [<..6682>,78,$]]
Pattern Constraints
SELECT ?isbn ?price ?currency
WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.
FILTER(?currency == €) }
Returns: [ [<..49X>,50,€], [<..6682>,60,€]]
SPARQL defines a base set of operators and functions
Optional Pattern
SELECT ?isbn ?price ?currency ?wiki
WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.
OPTIONAL ?wiki w:isbn ?isbn. }
Returns: [[<..49X>,33,£,<…Palace>], … , [<..6682>,78,$, ]]
Other SPARQL Features
Limit the number of returned results; remove duplicates, sort them, …
Specify several data sources (via URI-s) within the query (essentially, a merge!)
Construct a graph combining a separate pattern and the query
results
Use datatypes and/or language tags when matching a pattern
SPARQL is quite mature already
recommendation expected 3rd Q of 2007
there are a number of implementations
already
SPARQL Usage in Practice
Locally , i.e., bound to a programming environments like JenaRemotely , e.g., over the network or into a database
separate documents define the protocol and the result format
There are already a number of applications, demos, etc.,
Remote Query/Reply Example
GET /qps?&query=SELECT+:…+WHERE:+… HTTP/1.1
User-Agent: my-sparql-client/0.0
Host: my.example
HTTP/1.1 200 OK
Server: my-sparql-server/0.0
Content-Type: application/sparql-results+xml
<?xml version="1.0" encoding="UTF-8"?>
<sparql xmlns="http://www.w3.org/2005/sparql-results#>
<head>
<variable name="a"/>
...
</head>
<results>
<result ordered="false" distinct="false">
<binding name="a"><uri>http:…</uri></binding>
...
</result>
<result> ... </result>
</results>
</sparql>
Get to RDF(S) Data
Simplest: Write your own RDF Data…
The simplest aproach: write your own RDF data in your preferred syntax…
You may add RDF to XML directly (in its own namespace); e.g., in SVG:
<svg ...>
...
<metadata>
<rdf:RDF xmlns:rdf="http://../rdf-syntax-ns#">
...
</rdf:RDF>
</metadata>
...
</svg>
However: this does not scale!
RDF/XML with XHTML
XHTML is still based on DTD-s
RDF within XHTML’s header does not validate…
Currently, people use
link/meta in the header (using conventions instead of namespaces in metas)
put RDF in a comment (e.g., Creative Commons)
RDF Can Also Be Extracted/Generated
Use intelligent “scrapers” or “wrappers” to extract a structure (hence RDF) from a Web page…
using conventions in, e.g., class names or meta elements
… and then generate RDF automatically (e.g., via an XSLT script)
This is similar to what “microformat” do (without referring to RDF, though)
they may not extract RDF but use the data directly instead in Web 2.0 applications, but the application is not all that different
other applications may extract it to yield RDF (e.g., RSS1.0)
Formalizing the Scraper Approach: GRDDL
GRDDL
formalizes the scraper approach. For example:
<html xmlns="http://www.w3.org/1999/">
<head profile="http://www.w3.org/2003/g/data-view">
<title>Some Document</title>
<link rel="transformation" href="http:…/dc-extract.xsl"/>
<meta name="DC.Subject" content="Some subject"/>
...
</head>
...
<span class="date">2006-01-02</span>
...
</html>
yields, by running the file through
dc-extract.xsl
<rdf:Description rdf:about="…">
<dc:subject>Some subject</dc:subject>
<dc:date>2006-01-02</dc:date>
</rdf:Description>
GRDDL (cont)
The user has to provide dc-extract.xsl and use its conventions (making use of the corresponding meta-s, class id-s, etc…)
… but, by using the profile attribute, a client is instructed to find and run the transformation processor automatically
There is a mechanism for XML in general
a transformation can also be defined on an XML schema level
A “bridge” to “microformats”
Recommendation planned in the summer of 2007
Another Upcoming Solution: RDFa
RDFa extends (X)HTML a bit by:
defining general attributes to add metadata to any elements (a bit like the class in microformats, but via dedicated properties)
provides an almost complete “serialization” of RDF in XHTML
the same mechanism can also be used for general XML content
RDFa (cont.)
<div about="http://uri.to.newsitem">
<span property="dc:date">March 23, 2004</span>
<span property="dc:title">Rollers hit casino for £1.3m</span>
By <span property="dc:creator">Steve Bird</span>. See
<a href="http://www.a.b.c/d.avi" rel="dcmtype:MovingImage">
also video footage</a>…
</div>
yields, by running the file through a processor:
<http://uri.to.newsitem>
dc:date "March 23, 2004";
dc:title "Rollers hit casino for £1.3m;
dc:creator "Steve Bird";
dcmtype:MovingImage <http://www.a.b.c/d.avi>.
RDFa (cont.)
It is a bit like the microformats approach but with more rigor and fully generic
makes it easy to mix different vocabularies, which is not that easy with microformats
It can easily be combined with GRDDL
RDFa and GRDDL
Both solutions aim at “binding” existing structural data with RDF
GRDDL “brings” structured data to RDF
RDFa “brings” RDF to structured data (HTML)
The same URI may be interpreted as
a web page to be displayed by a browser
as RDF data to be integrated
(compare to a credit card: a human can read its number and owner; a card reader can access to its data)
Bridge to Relational Databases
Most of the data are stored in relational databases
“RDFying” them is an impossible task
“Bridges” are being defined:
a layer between RDF and the database
RDB tables are “mapped” to RDF graphs on the fly
in some cases the mapping is generic (columns represent properties, cells are, e.g., literals or references to other tables via blank nodes)…
… in other cases separate mapping files define the details
This is a very important source of RDF data
SPARQL As a Unifying Force
RDF(S) in Practice
Small Practical Issues
RDF/XML files have a registered Mime type:
Recommended extension: .rdf
RDF/XML has its Problems
RDF/XML was developed in the “prehistory” of XML
e.g., even namespaces did not exist!
Coordination was not perfect, leading to problems
the syntax cannot be checked with XML DTD-s
XML Schemas are also a problem
encoding is verbose and complex (simplifications lead to confusions…)
but there is too much legacy code
Don’t be influenced (and set back…) by the XML format
the important point is the model, XML is just syntax
other “serialization” methods may come to the fore
We have seen Jena
// create a model
Model model=new ModelMem();
Resource subject=model.createResource("URI_of_Subject")
// 'in' refers to the input file
model.read(new InputStreamReader(in));
StmtIterator iter=model.listStatements(subject,null,null);
while(iter.hasNext()) {
st = iter.next();
p = st.getProperty();
o = st.getObject();
do_something(p,o);
}
Jena (cont)
But Jena is much more; it has
a large number of classes/methods
adding triplets to a graph, serialize it
comparing full RDF graphs
manage typed literals
etc.
an “RDFS Reasoner”
a full SPARQL implementation
a layer (Joseki) to create a triple database
and more…
Probably the most widely used RDF environment in Java today
Ontologies (OWL)
Ontologies
RDFS is useful, but does not solve all the possible requirements
Complex applications may want more possibilities:
can a program reason about some terms? E.g.:
“if «Person» resources «A» and «B» have the same «foaf:email» property, then «A» and «B» are identical”
if somebody else defines a set of terms: are they the same?
construct classes, not just name themrestrict a property range when used for a specific class
disjointness or equivalence of classes
etc.
Ontologies (cont.)
There is a need to support ontologies on the Semantic Web:
“defines the concepts and relationships used to describe and represent an area of knowledge”
We need Web Ontology Languages
RDFS can be considered as a simple ontology language
OWL gives a much more complex set of possibilities
Languages should be a compromise between
rich semantics for meaningful applications
feasibility, implementability
W3C’s Ontology Language (OWL)
A layer on top of RDFS with additional possibilities
Outcome of various projects:
SHOE project: an early attempt to add semantics to HTML
DAML-ONT (a DARPA project) and OIL (an EU project)
an attempt to merge the two: DAML+OIL
the latter was submitted to W3C
lots of coordination with the core RDF work
recommendation since early 2004
It was a long road…
Lots of requirements, influences on OWL
research results on knowledge representation, model theory
the RDF/RDFS view of the world (triplets, syntactical issues, …), with OWL as a layer on top of RDF/RDFS
needs of the Web in general
balance between expressibility and implementability
You can read about it in a paper of Horrocks, Patel-Schneider, and van Harmelen…
The result: OWL is now the most used KR language…
Why “OWL” and not “WOL”?
Some urban legends…
e.g., reference to Owl from Winie the Pooh, who misspelled his name as “WOL”
A reference to an AI project at MIT of the mid 70’s by Bill Martin, called “One World Language”…
an early attempt for a KR language and associated ontology, intended to be a universal language for encoding meaning for computers
“Why not be inconsistent in at least one aspect of a language which is all about consistency” (Guus Schreiber)
Classes in OWL
In RDFS, you can subclass existing classes… that’s all
In OWL, you can construct classes from existing ones:
enumerate its content
through intersection, union, complement
through property restrictions
To do so, OWL introduces its own Class and Thing to differentiate the classes from individuals
OWL Classes can be “Enumerated”
The OWL solution, where possible content is explicitly listed:
Same Serialized
<owl:Class rdf:ID="Currency">
<owl:oneOf rdf:parseType="Collection">
<owl:Thing rdf:ID="£"/>
<owl:Thing rdf:ID="€"/>
<owl:Thing rdf:ID="$"/>
…
</owl:oneOf>
</owl:Class>
:£ rdf:type owl:Thing.
:€ rdf:type owl:Thing.
:$ rdf:type owl:Thing.
:Currency
rdf:type owl:Class;
owl:oneOf (:€ :£ :$).
The class consists of exactly of those individuals
Union of Classes
Essentially, like a set-theoretical union:
Same Serialized
<owl:Class rdf:ID="Literature">
<owl:unionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Novel"/>
<owl:Class rdf:about="#Short_Story"/>
<owl:Class rdf:about="#Poetry"/>
…
</owl:unionOf>
</owl:Class>
:Novel rdf:type owl:Class.
:Short_Story rdf:type owl:Class.
:Poetry rdf:type owl:Class.
:Literature rdf:type owlClass;
owl:unionOf (:Novel :Short_Story :Poetry).
Other possibilities: complementOf, intersectionOf
Property Restrictions
(Sub)classes created by restricting the property values on that class
For example, “a listed price is a price which is in either €, £, or $” means:
the value of “p:currency” when applied to a resource on listed price must take one of those values…
in other cases it can also take the value of ¥, i.e., it is not the same as range!
…thereby define the class of “listed price”
Property Restrictions in OWL
Restriction may be by:
value constraints (i.e., further restrictions on the range)
all values must be from a class (like the price example)
some value must be from a class
cardinality constraints
(i.e., how many times the property can be used on an instance?)
minimum cardinality
maximum cardinality
exact cardinality
Property Restriction Example
“the value of “p:currency” when applied to a resource on listed price must take one of those values…”:
Restrictions Formally
Defines a blank node of type owl:Restriction with a
reference to the property that is constrained
definition of the constraint itself
One can, e.g., subclass from this node
Same Serialized
<owl:Class rdf:ID="Listed_Price">
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="http://…#currency"/>
<owl:allValuesFrom rdf:resource="#Currency">
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
:Listed_Price rdf:type owl:Class;
rdfs:subClassOf [
rdf:type owl:Restriction;
owl:onProperty <http://…#currency>;
owl:allValuesFrom :Currency.
].
“allValuesFrom” could be replaced by “someValuesFrom”, “cardinality”, “minCardinality”, or “maxCardinality”
Property Characterization
In OWL, one can characterize the behavior of properties (symmetric, transitive, functional, inverse functional…)
OWL also separates data properties
“datatype property” means that its range are typed literals
Characterization Example
“foaf:email” is inverse functional
Same Serialized
<owl:DatatypeProperty rdf:ID="email">
<rdf:type rdf:resource="...../#InverseFunctionalProperty"/>
</owl:DatatypeProperty>
:email
rdf:type owl:DatatypeProperty;
rdf:type owl:InverseFunctionalProperty.
Similar characterization possibilities:
“FunctionalProperty”,
“TransitiveProperty”, “SymmetricProperty”
OWL: Additional Requirements
Ontologies may be extremely large:
their management requires special care
they may consist of several modules
come from different places and must be integrated
Ontologies are on the Web . That means
applications may use several, different ontologies, or…
… same ontologies but in different languages
equivalence of, and relations among terms become an issue
Term Equivalence/Relations
For classes:
owl:equivalentClass: two classes have the same individuals
owl:disjointWith: no individuals in common
For properties:
owl:equivalentProperty
remember the a:author vs. f:auteur?
owl:inverseOf: inverse relationship
For individuals:
owl:sameAs: two URI refer to the same individual (e.g., concept)
owl:differentFrom: negation of owl:sameAs
Example: Connecting to French
Versioning, Annotation
Special class owl:Ontology with special properties:
owl:imports, owl:versionInfo, owl:priorVersion
owl:backwardCompatibleWith, owl:incompatibleWith
rdfs:label, rdfs:comment can also be used
One instance of such class is expected in an ontology file
Deprecation control:
owl:DeprecatedClass, owl:DeprecatedProperty types
OWL and Logic
OWL expresses a subset of First Order Logic
it has a “structure” (class hierarchies, properties, datatypes…), and “axioms” can be stated within that structure only
OWL can be mapped to FOL to describe “traditional” ontology concepts … but it is not a full logic system per se!
Inference based on OWL is within this framework only
When you see OWL for the first time, it easy to expect too much…
However: Ontologies are Hard!
A full ontology-based application is a very complex system
Hard to implement, may be heavy to run…
… and not all applications may need it!
Three layers of OWL are defined: Lite, DL, and Full
decreasing level of complexity and expressiveness
“Full” is the whole thing
“DL (Description Logic)” restricts Full in some respects
“Lite” restricts DL even more
OWL Full
No constraints on the various constructs
owl:Class is equivalent to rdfs:Class
owl:Thing is equivalent to rdfs:Resource
This means that:
Class can also be an individual (it is possible to talk about class of classes, etc.)
one can make statements on RDFS constructs (e.g., declare rdf:type to be functional…)
etc.
A real superset of RDFS
But: an OWL Full ontology may be undecidable!
Example for a Possible Problem (in OWL Full)
:A rdf:type owl:Class;
owl:equivalenClass [
rdf:type owl:Restriction;
owl:onProperty rdf:type;
owl:allValuesFrom :B.
].
:B rdf:type owl:Class;
owl:complementOf :A.
:c rdf:type owl:Thing; rdf:type :A.
if c is of type A then it must be in B, but then it is in the complement of A, ie, it is not of type A…
OWL Description Logic (DL)
Goal: maximal subset of OWL Full against which current research can assure that a decidable reasoning procedure is realizable
Class, Thing, ObjectProperty,
DatatypePropery are strictly separated : a class
cannot be an individual of another class
object properties’ values must usually be an owl:Thing (except, e.g., for rdf:type)
No mixture of owl:Class and rdfs:Class in definitions (essentially: use OWL concepts only!)
No statements on RDFS resources
No characterization of datatype properties possible
…
OWL Lite
Goal: provide a minimal useful subset, easily implemented
All of DL’s restrictions, plus some more:
class construction can be done only through intersection or property constraints
cardinality restriction with 0 and 1 only
…
Simple class hierarchies can be built
Property constraints and characterizations can be used
Note on OWL layers
OWL Layers were defined to reflect compromises:
expressibility vs. implementability
Some application just need to express and interchange terms (with possible scruffiness): OWL Full is fine
they may build application specific reasoning instead of using a general one
Some applications need rigor; then OWL DL/Lite might be the good choice
Research may lead to new decidable subsets of OWL
see, e.g., H.J. ter Horst’s paper at ISWC2004 or in the Journal of Web Semantics (October 2005)
“Description Logic”
The term refers to an area in knowledge representation
a special type of “structured” First Order Logic (logic with safety guards…)
formalism based on “concepts” (i.e., classes), “roles” (i.e., properties), and “individuals”
based on model theoretic semantics (like RDF, RDFS, and OWL!)
There are several variants of Description Logic
i.e., OWL DL and Lite are embodiments of distinct Description Logics
for connoisseurs: OWL DL ≈
SHOIN (D ), OWL Lite ≈
SHIF (D )
some major differences: usage of URI-s , reference to XML Schema datatypes, version control, built-in annotation…
“Description Logic” (cont.)
Traditional DL has its own terminology:
named objects or concepts ⇔ definition of classes, relationships among classes
roles ⇔ properties
(terminological) axioms ⇔ subclass and subproperty relationships
facts or assertions ⇔ statements on individuals (owl:Thing-s)
There is also a compact mathematical notation for axioms, assertions, etc:
Literature ≣ Novel ⊔ Short_Story ⊔ Poetry
Listed_Price ⊑ ∀currency.Currencies
You may see these in papers, books…
OWL-DL “Abstract Syntax”
There is also a non-XML based notation for OWL DL (and OWL Lite) defined by W3C (also used in the formal specification of OWL DL)
currently only RDF/XML format is widely implemented, but AS → RDF/XML converters exist (i.e., it may become more widespread in future)
it makes writing ontologies with DL restrictions easier…
Class(Novel)
Class(Short_Story)
Class(Poetry)
Class(Literature) (
unionOf(Novel Poetry Short_Story …)
)
Ontology Development
The hard work is to create the ontologies
requires a good knowledge of the area to be described
some communities have good expertise already (e.g., librarians)
OWL is just a tool to formalize ontologies
Large scale ontologies are often developed in a community process
Ontologies should be shared and reused
can be via the simple namespace mechanisms…
…or via explicit inclusions
Applications can also be developed with very small ontologies, though
Ontology Examples
International country list
example for an OWL Lite ontology
There are also some large ontologies in the public:
eClassOwl : eBusiness ontology for products and services, 75,000 classes and 5,500 properties
the Gene Ontology : to describe gene and gene product attributes in any organism
UniProt : protein sequence and annotation data, hundreds of millions of triples(!)
Simple Knowledge Organization System (SKOS)
Simple Knowledge Organization System
Goal: porting (“Webifying”) thesauri: representing and sharing classifications, glossaries, thesauri, etc, as developed in the “Print World”. For example:
The system must be simple to allow for a quick port of traditional data (done by “traditional” people…)
This is where SKOS comes in (still a draft, though…)
Example: Entries in a Glossary (1)
“Assertion”
“(i) Any expression which is claimed to be true. (ii) The act of claiming something to be true.”
“Class”
“A general concept, category or classification. Something used primarily to classify or categorize other things.”
“Resource”
“(i) An entity; anything in the universe. (ii) As a class name: the class of everything; the most inclusive category possible.”
(from the RDF Semantics Glossary)
Example: Entries in a Glossary (2)
Example: Taxonomy (1)
Illustrates “broader” and “narrower”
General
SemWeb
(From MortenF’s weblog categories. Note that the categorization is arbitrary!)
Example: Thesaurus (1)
Term
Economic cooperation
Used For
Economic co-operation
Broader terms
Economic policy
Narrower terms
Economic integration, European economic cooperation, …
Related terms
Interdependence
Scope Note
Includes cooperative measures in banking, trade, …
(from UK Archival Thesaurus)
SKOS Core Overview
Classes and Predicates:
Basic description (Concept, ConceptScheme, …)
Labelling (prefLabel, altLabel, prefSymbol, altSymbol …)
Documentation (definition, scopeNote, changeNote, …)
Semantic relations (broader, narrower, related)
Subject indexing (subject, isSubjectOf, …)
Grouping (Collection, OrderedCollection, …)
Subject Indicator (subjectIndicator)
Some simple inference rules (a bit like the RDFS inference rules) to define some semantics
Why Having SKOS and OWL?
OWL’s precision not always necessary or even appropriate
“OWL a sledge hammer / SKOS a nutcracker”, or “OWL a Harley / SKOS a bike”
complement each other, can be used in combination to optimize cost/benefit
Role of SKOS is
to bring the worlds of library classification and Web technology together
to be simple and undemanding enough in terms of cost and required expertise
A typical example: the Glossary of project of W3C stores all terms in SKOS (and extracted from W3C documents),
FAO’s Agrovoc thesaurus in SKOS format, Nasa’s taxonomy
Rules
Rules
OWL-DL and OWL-Lite are based on Description Logic; there are things that DL cannot express
a well known examples is Horn rules (eg, the “uncle” relationship):
(P1 ∧ P2 ∧ …) → C e.g.: for any «X», «Y» and «Z»: “if «Y» is a
parent of «X», and «Z» is a brother of «Y» then «Z» is the
uncle of «X»”
there are a number of attempts to combined these: RuleML ,
SWRL ,
cwm, …
There is also an increasing number of rule-based system that want to interchange rules
a new type of data (potentially) on the Web to be interchanged…
Hence the ongoing work on Rules at W3C (still at its early phase!)
Some Typical Use Cases
Negotiate eBusiness contracts across platforms: supply vendor-neutral representation of your business rules so that others may find you
Describe privacy requirements and policies, and let clients “merge” those (e.g., when paying with a credit card)
Medical decision support, combining rules on diagnoses, drug prescription conditions, etc,
Extend RDFS (or OWL) with rule-based statements (e.g., the uncle example)
In the Real World…
Rule based systems can be very different
different rule semantics (based on various type of model theories, on proof systems, etc)
production rule systems, with procedural references, state transitions, etc
RIF “core”: Only Partial Interchange
Specification of the “core” is the first step
It also forms a logic language to be used, eg, with OWL, RDF, XML data, …
RIF “Variants”
Possible variants: F-logic, production rules, fuzzy logic systems, …; none of these have been finalized yet
What Have We achieved?
Remember the integration example?
Same With What We Learnt
What is Coming?
Beyond Rules: Trust
Can I trust a (meta)data on the Web?
is the author the one who claims he/she is, can I check his/her credentials?
can I trust the inference engine?
etc.
There are issues to solve, e.g.,
how to “name” a full graph
protocols and policies to encode/sign full or partial graphs (blank nodes may be a problem to achieve uniqueness)
how to “express” trust? (e.g., trust in context)
It is on the “future” stack of W3C and the SW Community …
Other Issues…
Improve the inference algorithms and implementations, scalability, reasoning with OWL Full
Better modularization (import or refer to part of ontologies)
Ontology management on the Web
Extensions of RDF and/or OWL (based on experience and theoretical advances)
allowing Blank Nodes as properties; allowing literals as subjects;
extensions of OWL-DL (“OWL 1.1”), e.g., ”qualified cardinality restrictions” (i.e., “class instance must have two black cats”) or disjoint properties
named graphs
“Sub OWL Lite” ontology level for some applications (RDFS++, OWL Feather, pD*,…)
Temporal, spatial, fuzzy, probablistic, etc, reasoning
…
Available Documents, Tools
Available Specifications: Primers, Guides
“Core” Vocabularies
A number of public “core” vocabularies evolve to be used by applications, e.g.:
Dublin Core : about information resources, digital libraries, with extensions for rights, permissions, digital right management
FOAF : about people and their organizations
DOAP : on the descriptions of software projects
Music Ontology : on the description of CDs, music tracks, …
SIOC : Semantically-Interlinked Online Communities
vCard in RDF
…
They share the underlying RDF model (provides mechanisms for extensibility, sharing, …)
Some Books
J. Davies, D. Fensel, F. van Harmelen: Towards the Semantic Web (2002)
S. Powers: Practical RDF (2003)
F. Baader, D. Calvanese, D. McGuinness, D. Nardi, P. Patel-Schneider: The Description Logic Handbook (2003)
G. Antoniu, F. van Harmelen: Semantic Web Primer (2004)
A. Gómez-Pérez, M. Fernández-López, O. Corcho: Ontological Engineering (2004)
…
See the separate Wiki page collecting books
SWBP Working Group Documents
Further Information (cont)
Some Application Examples
Semantic Web ≠ an academic research only!
SW has indeed a strong foundation in research results
But remember:
(1) the Web was born at CERN…
(2) …was first picked up by high energy physicists…
(3) …then by academia at large…
(4) …then by small businesses and start-ups…
(5) “big business” came only later!
network effect kicked in early…
Semantic Web is now at #4, and moving to #5!
May start with small communities
The needs of a deployment application area:
have serious problem or opportunity
have the intellectual interest to pick up new things
have motivation to fix the problem
its data connects to other application areas
have an influence as a showcase for others
The high energy physics community played this role for the Web in the 90’s
Some RDF deployment areas
Library metadata
Defense
Life sciences
Problem to solve?
single-domain integration
yes, serious data integration needs
yes, connections among genetics, proteomics, clinical trials,
regulatory, …
Willingness to adopt?
yes: OCLC push and Dublin Core Initiative(*)
yes: funded early DAML (OWL) work
yes: intellectual level high, much modeling done already.
Motivation
light
strong
very strong
Links to
other library data
phone calls records, etc
chemistry, regulatory, medical, etc
Showcase?
limited
not at all
yes, model for other industries.
(*) note that the Dublin Core Initiative’s work go way beyond digital libraries these days
Some RDF deployment areas (cont)
These are just examples
Others are coming to the fore: eGovernment, energy sector (oil industry), financial services, …
Health care and life science sector is now very active
also at W3C, in the form of an Interest Group
The “corporate” landscape is moving
Some of the names of active participants in W3C SW related groups: ILOG, HP, Agfa, SRI International, Fair Isaac Corp., Oracle, Boeing, IBM, Chevron, Siemens, Nokia, Merck, Pfizer, AstraZeneca, Sun, Citigroup, …
“Corporate Semantic Web” listed as major technology by
Gartner in 2006
The Semantic Technology Conference series also attract lots of participants
speakers in 2006: from IBM, Cisco, BellSouth, GE, Walt Disney, Nokia, Oracle, …
not all referring to Semantic Web (eg, RDF, OWL, …) but semantics in general
but they might come around!
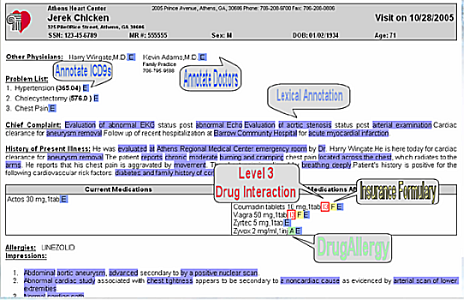
Applications are not always very complex…
Eg: simple semantic annotations of patients’ data greatly enhances communications among doctors
What is needed: some simple ontologies, an RDFa/microformat type editing environment
Simple but powerful!
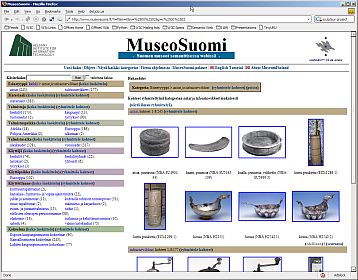
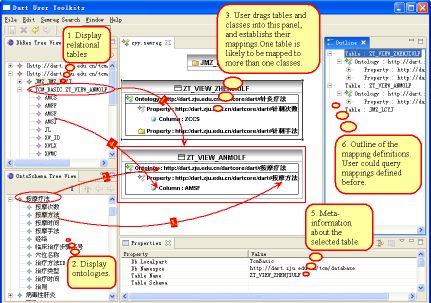
Data Integration R&D
Pfizer, NASA ,
MITRE Corp., Elsevier , EU Projects like Sculpteur and
Artiste , national projects like
MuseoSuomi ,
UN FAO’s MeteoBroker,
DartGrid from Zhe Jiang University, …
A general question: can I access your (RDF) data directly?
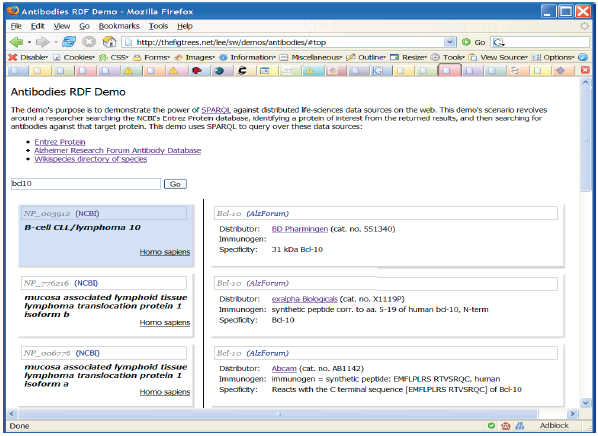
Example: antibodies demo
Scenario: find the known antibodies for a protein in a specific species
Combine (“scrape”…) three different data sources
Use SPARQL as an integration tool (see also demo online )
Example: ontology controlled annotation
Portals
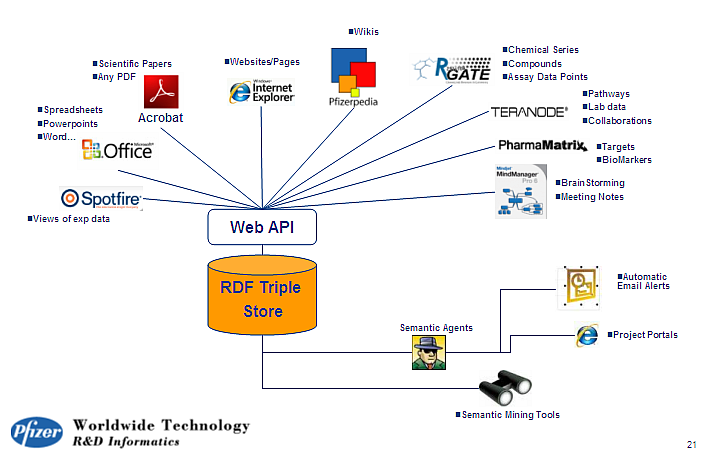
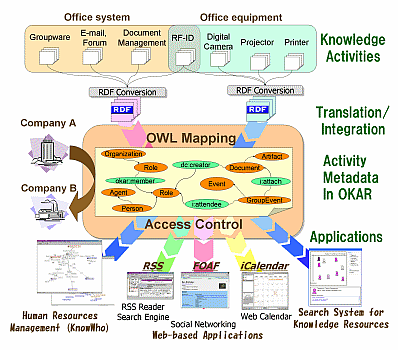
OKAR Fujitsu's and Ricoh's OKAR
Management of office information, projects, personal skills, calendars, …
e.g., “find me a person with a specific skill”
Still an R&D project
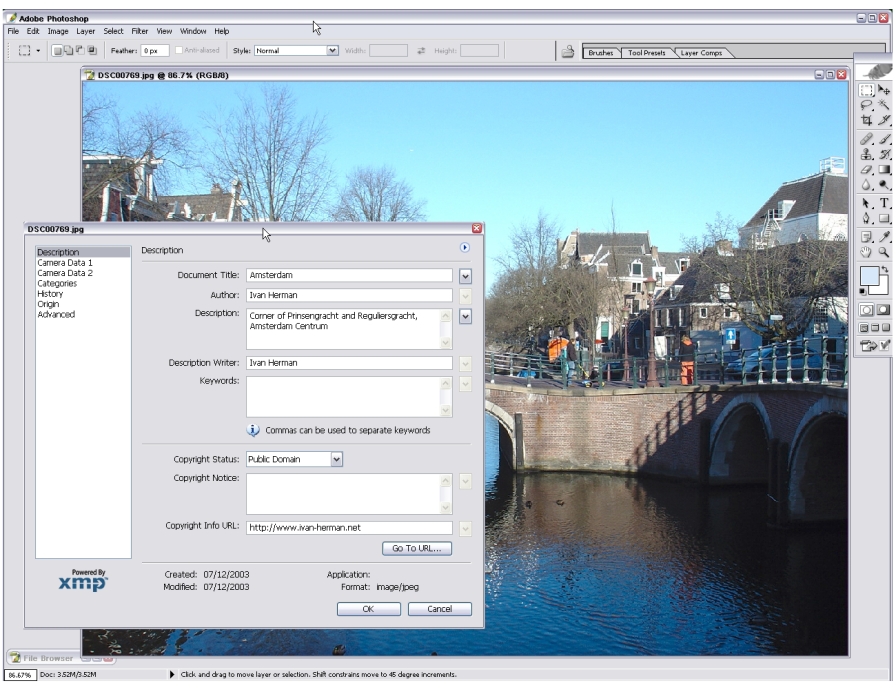
Adobe's XMP
Adobe’s tool to add RDF-based metadata to most of their file formats
used for more effective organization
supported in Adobe Creative Suite
support from 30+ major asset management vendors, with separate XMP conferences; will be used in Windows Vista
The tool is available for all!
Improved Search via Ontology: GoPubMed
Improved search on top of pubmed.org
search results are ranked using the specialized ontologies
extra search terms are generated and terms are highlighted
Importance of domain specific ontologies for search improvement
Creative Commons
To express rights of digital content on the Web
legal constraints referred to in RDF, added to pages
There are specialized browsers, browser plugins
More than 1,000,000 users worldwide (!)
without knowing that they use RDF…
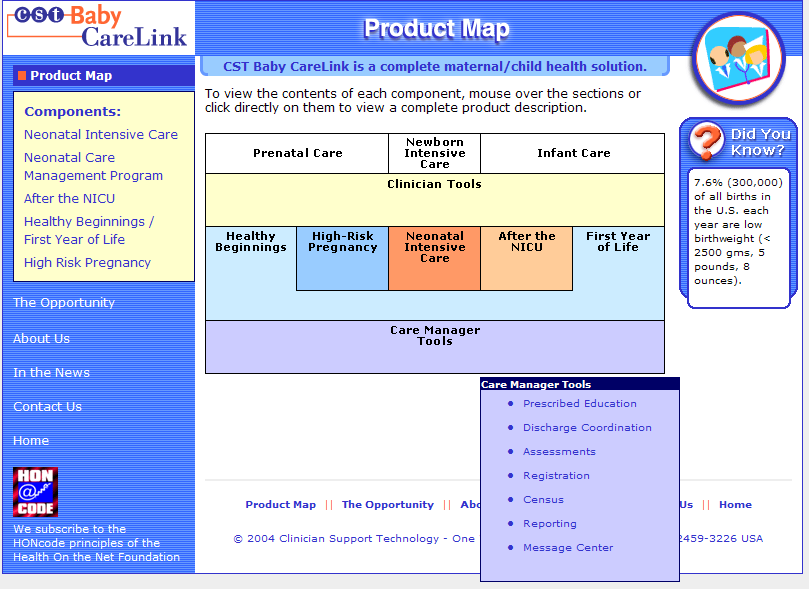
Baby CareLink
Center of information for the treatment of premature babies
Provides an OWL service as a Web Service
combines disparate vocabularies like medical, insurance, etc
users can ask complex questions and add new entries to ontologies
Example for the synergy of Web Services and the Semantic Web!
Other Application Areas Come to the Fore
Knowledge management
Business intelligence
Linking virtual communities
Management of multimedia data (e.g., video and image depositories)
Content adaptation and labeling (e.g., for mobile usage)
etc
Thank you for your attention!
These slides are publicly available on:
http://www.w3.org/People/Ivan/CorePresentations/RDFTutorial/
in XHTML and PDF formats; the XHTML version has active links that you can follow
 )
)
 !)
!) :
it is the usual picture of software tools, nothing special any more!
:
it is the usual picture of software tools, nothing special any more!