 This section describes the design and implementation of the
multi-threaded, interruptable I/O HTTP
Client as it is implemented in the
World-Wide Web Library of Common Code. The section is an extension
to the description of the HTTP Client
and is divided into the following sections:
This section describes the design and implementation of the
multi-threaded, interruptable I/O HTTP
Client as it is implemented in the
World-Wide Web Library of Common Code. The section is an extension
to the description of the HTTP Client
and is divided into the following sections:
A multi-process environment requires an extensive support from the underlying operating system. Unix is the classic platform that provides this functionality. The Unix system call "fork" generates a new child process that is an exact copy of the parent but in another address space as illustrated in the figure.
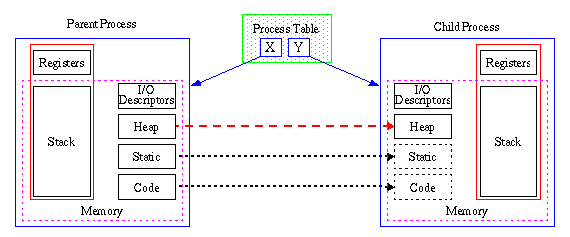
The static parts like the code segment and the static memory can be shared between the two processes and does not require a copy of the memory. Often a technique called copy-on-write is used when creating the heap and stack of the child. The kernel marks the regions in memory as read-only and only when either of the processes accesses the memory with a write request, the particular page is copied. Finally all open file descriptors and socket descriptors are copied so that the child can continue any operation including I/O from the same state as the parent.
The process of forking a child process is not unique for Unix, but the exact behavior is often quite platform dependent. Under VMS, "fork" is an extremely resource expensive procedure that in practice is unusable for fast program execution. Due to extensive security regulations in VMS, every process has a large set of environment variables that has to be initialized at the creation of the process. Furthermore, a process is created in an initial state independent of the parent process, so synchronization of the state of the parent and child process has to be established before the child is ready to execute the request.
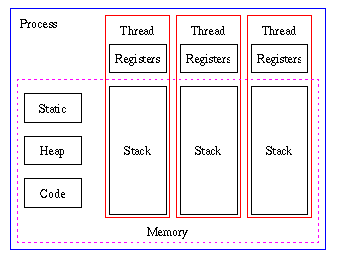
Threads provide another technique for obtaining an environment with a multiple set of execution points. A thread is a smaller unit compared to a process in that it is a single, sequential flow of control within a process. As mentioned above, when creating a new process much of the environment does never change and can therefore be reused. Threads takes the full consequence of this and creates an environment with multiple execution points within the same process. Hence threads provide a more lightweight solution than process forking and this is a part of the reason for their implementation in the Library of Common Code.
Platform Independent Implementation
The major concern in the design has been to make an implementation
that is as platform independent as possible. This means that it has
not been possible to use traditional thread packages like DECthreads
which contain a code library with a complete set of thread handling
routines and a consistent user interface. IEEE has publicized the
POSIX standard 1003.4 for multi-threaded programming but even this
will eventually limit the portability of the code so that it will not
be usable on small platforms like PCs.
Instead the multi-threaded functionality of the HTTP client has been designed to be used in a single-processor, single-threaded, environment as illustrated in the figure.
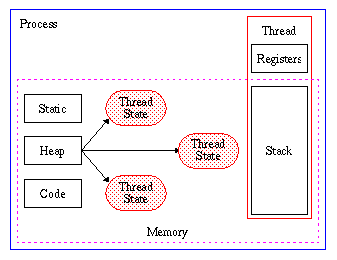
The difference between this technique and "traditional" threads as illustrated above is that all information about a thread is stored in a data object which lives throughout the lifetime of the thread. This implies that the following rules must be kept regarding memory management:
As no automatic or global variables are available in this implementation model every thread has to be state dependent and must contain all necessary information in a separate data object. In order to make a homogeneous interface to the HTRequest structure the new protocol specific data structure HTNetInfo has been defined.
The definition of this data object is highly object oriented as every protocol module in practice can define a sub class of the HTNetInfo structure in order
to add information necessary for completing a thread. Again this is all done
in plain C in order to maintain a high degree of portability.
Control Flow
A consequence of having multiple threads in the library is that the
control flow changes to be an event driven flow where any action is
initiated by an event either caused by the user or the network
interface. However, as the current implementation of multiple threads
is valid for HTTP access only, the data flow of the library has
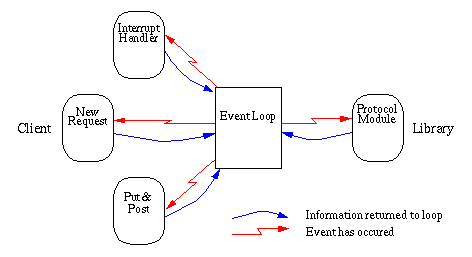
basically been preserved, see the general control flow diagram.
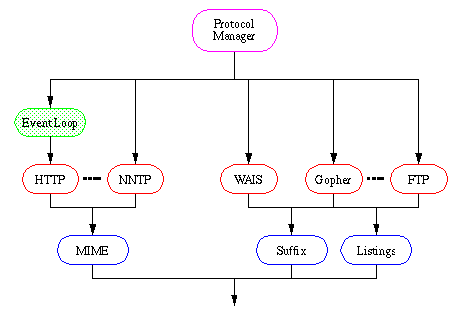
All other access schemes but HTTP protocol still use blocking I/O and the user will not notice any difference from the current implementation. The result of this is that full multi-threaded functionality is enabled only if the client uses consecutive HTTP requests even though the FTP and Gopher clients now also are implemented as state machines and in principle can use the same approach.
When a request is initiated having another access scheme than HTTP, e.g. FTP, the multi-threaded functionality partly stops as the new request gets served using blocking I/O. It is currently for the client to decide whether a new non-HTTP request can be activated when one or more HTTP request are already active. It is strongly recommended for the active mode that the client awaits the return from the HTTP event-loop, i.e., that no more HTTP requests are active or pending.
For the HTTP access, however, a socket event loop has been introduced. This might as indicated in the Introduction either be implemented by the client or the library. When other protocol modules than the HTTP client are fully implemented as multi-threaded clients they can be moved down under the event loop just like the HTTP client.
The event loop is designed using event driven call back functions. When used in active mode, the only events recognized are from a given set of file descriptors including standard input (often specified as file descriptor 0). As indicated in the figure, the event loop handles two kinds of call back functions: the ones that are internal library functions such as the loading function in the protocol modules, and the ones that require an action taken by the client application.
Henrik
Frystyk, frystyk@info.cern.ch, July 1994