Henrik
Frystyk, July 1994
 Implementation of the HTTP Client
Implementation of the HTTP Client
 This document describes the current implementation of the HTTP
Protocol as from version 3.0 (unreleased, August 1994) of the Library
of Common Code (see
current version number). The HTTP client is based on the HTTP 1.0
specification but is backwards compatible with the 0.9 version. The
major difference between the implementation before version 3.0 is that
this version is a state machine based on the state diagram illustrated
below. The advantage of this approach will become obvious in the
section on Multi Threaded Clients even
though the HTTP protocol is stateless by nature.
This document describes the current implementation of the HTTP
Protocol as from version 3.0 (unreleased, August 1994) of the Library
of Common Code (see
current version number). The HTTP client is based on the HTTP 1.0
specification but is backwards compatible with the 0.9 version. The
major difference between the implementation before version 3.0 is that
this version is a state machine based on the state diagram illustrated
below. The advantage of this approach will become obvious in the
section on Multi Threaded Clients even
though the HTTP protocol is stateless by nature.
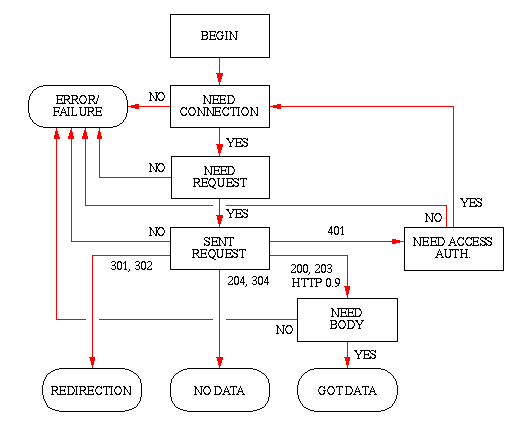
The individual states and the transitions between them are explained
in the following sections. Note the difference in notation between the
client (client side application built un top of the library)
and HTTP Client that is the protocol module in the library.
- BEGIN State
- This state is the idle state or initial state where the HTTP
client awaits a new request passed from the client. If the user at
this point has typed in a userid and a passwd for
access authorization the HTTP client also prepares the
Authorization header.
- NEED_CONNECTION State
- The HTTP client is now ready for setting up a connection to the
remote host. The connection is always initiated by a connect
system call. In order to minimize the access to the Domain Name Server, all host names to
previous visited hosts no matter of the
access schemes used) are stored in a local host cache. The cache
handles multi-homed hosts in a special way in that it measures the
time it takes to actually make a connection to one of the
IP-addresses. This time is stored together with the specific
IP-address and the hostname in the cache and on the next connection to
the same host the IP-address with the fastest connect time is chosen.
- NEED_REQUEST State
- The HTTP
Request is what the client sends to the remote HTTP server just after the
establishment of the connection. The request consists of a HTTP header line, a
set of MIME Headers, and possibly a data
object to be posted to the server. The header line has the following format:
<METHOD> <URI> <HTTP-VERSION> CRLF
Current methods supported in the clients are
- GET
- This is for requesting a URI or for specifying a
text search. Text searches are initiated by placing a "?" in the URI.
- HEAD
- The HEAD method is equivalent to GET in the sense that it is
requesting a URI at the remote server. The difference is that the
server only returns the HTTP headers but no data object. This is used
for updating cache information, getting information on the size of the
data object (or body) etc.
In the section on Put and Post the
implementation of the client interface to the library is described.
However, the actual implementation of
PUT and POST
in the HTTP protocol is yet to be specified. The reason is that the
current specification is limited and does not allow the HTTP protocol
to be a superset of existent Internet
Presentation Protocols.
The HTTP headers are as mentioned a set of MIME headers even though they are
not all officially accepted by the MIME specifications. The HTTP client
supports the following headers:
- Accept:
- The current implementation uses one accept line for each
MIME-type supported by the client. For advanced clients this means
that the "Accept: " sequence is repeated 20-30 times which gives a
overhead of 200-300 bytes per request (including the CRLF telnet
EOL-sequence). This should be changed so that either a comma separated
list is transmitted instead or only the MIME content types without any
subtypes.
-
Referer:
- If any parent anchor is known to the requested URI this is send
in the referer field. This is to let the server know what link has led
to the current request. Nothing is sent if the parent anchor is
unknown or does not exist.
- From:
- The full email address is sent along the request. It is meant as
an informative service to the recipient and can be changed to any
value the user wishes to sign the request with. As it is possible to
manipulate the email address, this field can not be used for any
security verification or precaution.
- User-Agent:
- The user agent is by many clients currently generated in a
somewhat verbose format. The goal is to make this field machine
readable so it can be used on the server side to perform individual
actions as a function of the client version. As a side effect it can
also be used for statistics etc.
- Authorization:
- The authorization header as introduced in the NEED_CONNECTION state.
- SENT_REQUEST State
- When the request is sent the client waits until a response is given from
the server or the connection is timed out in case or an error situation. As
the client does not know whereas the remote server is a HTTP 0.9 server or a
HTTP 1.0 it must look at the first part of the response to figure out what
version of HTTP is returned. The reason is that the HTTP protocol 0.9 does not
contain a HTTP header line in the response. It simply starts to send the
requested data object as soon as the GET request is handled. Future versions
of the HTTP protocol will all contain a header line with the protocol version
like the MIME protocol.
- NEED_ACCESS_AUTHORIZATION State
- If a 401
Unauthorized status code is returned the client asks the user for
a user id and a password, see also the
Access Authorization Scheme. The connection is closed before the
user is asked for the userid and password so any new request initiated
upon a 401
status code causes a new connection to be established.
- REDIRECTION State
- The remote server returns a redirection status
code if the URI has either been moved temporaryly or permanent to another
location, possibly on another HTTP server or any other server supported by the
WWW-model. The HTTP Client supports both a temporaryly and a permanent redirection code returned from the server:
-
301 Moved
- The load procedure is recursively called on a 301 redirection
code. The new URI is parsed back to the user as information via the
Error and Information module, and a new request generated. The new
request can be of any access
scheme accepted in a URI. An upper limit of redirections has been
defined (default to 10) in order to avoid infinite loops.
- 302
Found
- The functionality is the same as for a 301 Moved return status. A
clever client can use the returned URI to change the document in which
the URI originates so that the URI points to the new location.
-
- NO_DATA State
- When a return code indicates that no data object or resource
follows the HTTP headers the HTTP client can terminate the request and
pass control back to the client.
- NEED_BODY State
- If a body is included in the response from the server, the client
must prepare to read the data from the network and direct it to the
destination set up by the client. This is done by setting up a stream stack with the required
conversions.
- GOT_DATA State
- When the data object has been parsed through the stream stack,
the HTTP client terminates the request and handles control back to the
client.
- ERROR or FAILURE State
- If at any point in the request handling a fatal error occurs the
request is aborted and the connection closed. All information about
the error is parsed back to the client via the
Error and Information Module. As the HTTP protocol is stateless,
all errors are fatal between the server and the client. If the
erroneous request is to be repeated, the request starts in the initial state.
Henrik
Frystyk, frystyk@info.cern.ch, July 1994