 This document is an overview of the World-Wide Web software developed at
CERN. The development of the
World-Wide Web code was started by Tim
Berners-Lee in 1990. Ever since the code has been subject for
changes due to modifications in the architectural model, additions of
new features etc. The code is freely available as public
domain software with a very mild Copyright
statement.
This document is an overview of the World-Wide Web software developed at
CERN. The development of the
World-Wide Web code was started by Tim
Berners-Lee in 1990. Ever since the code has been subject for
changes due to modifications in the architectural model, additions of
new features etc. The code is freely available as public
domain software with a very mild Copyright
statement. During the last two years more and more World-Wide Web applications have become available from a large amount of software providers on almost every platform connected to the Internet. Many of them are based on the same architectural model as the CERN software but with additional functionality and increased performance. Most of the software is characterized by being freely available as public domain for educational institutions and other non-profit organizations whereas commercial companies must pay a fee for using them.
The CERN World-Wide Web software is written in plain C and is especially designed to be used on a large set of different platforms. It has often been discussed if the CERN code or especially the Common Code Library should be rewritten in ANSI C using the IEEE Std 1003.1-1990 standard (commonly referred to as POSIX.1), but eventually this will limit the portability on many platforms currently supported. A newly started collaboration between WWW software providers will expand this portability to also include MS-DOS and MacIntosh so that the most popular platforms are covered from large computers down to PCs. The document describes the following software product maintained at CERN:
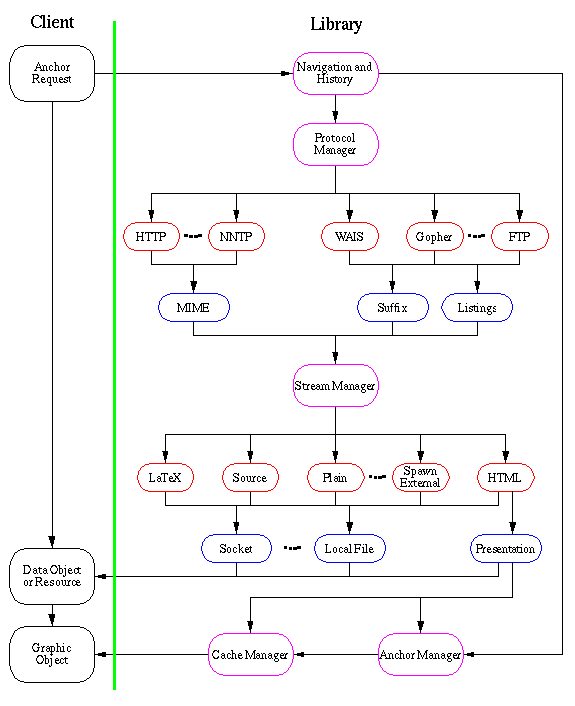
The flow of the library shows that all network communication and data object
parsing is handled internally. Only the presentation to the user is left to
the client as this is a very platform dependent task. The main elements in the
figure are explained in the following sections. A more specific description of
the implementation of the library is given in
Internals and Programmer's guide
Graphic Object
A graphic object is a displayable entity handled and maintained by the client.
It is built from the data contained in a server response upon a successful
request initiated by the client. The object can either be build directly from
the data, e.g, if the data object returned is a HTML document, or it can be
generated from a format converter within the library. The latter could be the
generation of a HTML object from a FTP directory listing (7-bit ASCII).
Graphic objects are in general necessarily coded differently on different window systems. The graphic object is responsible for displaying itself, catching mouse clicks, and calling the navigation object in order to follow links. Often the more common term "document" is used to describe the logical entity which a graphics object represents and displays.
For the moment, a graphic object is created and maintained in the client side of the library and the client itself. However, it would be possible to extend the definition of a graphic object to also describe a data object being transferred from the server to the client using the HTTP protocol. The client can then use meta information given in the graphic object to display the raw data in the representation desired or available in the client.

An anchor can be the source of zero, one, or many links . It has one "main" link for the (common) case in which it is the source for one link. When posting a data object to, e.g, a NNTP News Group or using the POST method in the HTTP Protocol it is common to have more than one recipient for the data object to be posted. The list of recipients are all in the "link list" of the anchor, this is explained in a later section on Put and Post
An anchor may be the destination of zero, one, or many links. The anchor module stores all links known by the program, and so in fact manages a copy of a small part of the Web.
Cache Manager
This is a local cache module specifically for WWW Clients. It is used to save
data objects once they have been down loaded from the Internet. The CERN Proxy server has its own cache manager to handle a
large scale cache that can serve hundreds of clients with documents once they
have been received form the remote host. The client cache is made for clients
not using a proxy cache or having a very slow link but a large local temporary
storage.
Protocol Manager
The Protocol Manager is invoked by the client in order to access a
document. Each protocol module is responsible for extracting
information from a local file or remote server using a particular
protocol. Depending on the protocol, the protocol module either builds
a graphic object (e.g. hypertext) itself, or it passes a socket
descriptor to the format manager for parsing by one of the parser
modules. As mentioned in the Graphic Object
section it can also perform a conversion of the raw data returned
from the remote server into, e.g. a HTML object.
Stream Manager
Streams are unidirectional objects which accept characters, strings,
and blocks of data to be written to them. The Stream Manager handles a
generic representation of a stream class so that the interface is
always the same for all types of different input and output streams to
the manager.
Streams can be thought of as like files open for write. The stream-based architecture allows the software to be event-driven in the sense that when input arrives, it is put into a stream, and any necessary actions then cascade off that.
Stream might be cascaded so that one stream writes into into another stream after having performed some processing on the data. An output stream is often referred to as the "target" or "sink" stream.
The elements and entities in the stream are referred to by numbers, rather than strings. The DTD contains the mapping between element names and numbers, so each structured stream when created is associated with the DTD which it using. Any instance of a structured stream has a related DTD which gives the rules and element and entity names for events on the structured stream. The only DTD which is currently in the library is an extended version of a HTML DTD version 1.0.
The SGML parser uses a DTD to output to a structured stream from a stream of SGML. A hypertext editor will output to a structured stream when writing out a document. Many protocol modules output to a structures stream when generating their data structures.
Format Conversion and Stream Stacks
Often it is desired to perform a format conversion between the entry
point and the output point of the stream. As illustrated in the Figure of the library the stream manager is the
node between the input format given by the protocol modules and the
desired output format specified by the client. Though, often it is
desirable to perform more than one data conversion on a data object.
Therefore, the stream manager is designed as a stream stack where
several streams can be cascaded, each one performing a part of the
total data conversion.
The Line Mode Browser
The CERN
Line Mode Browser is a character based World-Wide Web Browser. It
is developed for use on dumb terminals and as a test tool for the CERN Common Code Library. It can be run in
interactive mode, non-interactive mode, as a
proxy client and a set of other run modes that all are explained
in
Command Line Options. Even though it is not often used as a
World-Wide Web browser, the possibility of executing it in the
background or from a batchjob makes it a useful tool. Furthermore it
gives a variety of possibilities for data format conversion, filtering
etc.
The easist way to get an idea of what the Line Mode Browser is all
about is actually to try directly from The info server at CERN. No userid
or password is needed.
The HTTP Server
CERN
httpd is a generic hypertext server which can be used as a regular
HTTP server. The allocated port for HTTP connections is TCP port 80,
but the server can be put up to listen on any other TCP port (above
1024 if not running as root). The CERN server includes features such
as
Access Authentication,
Clickable Images etc.
The Proxy Server
The CERN server also has the possibility of running as a proxy
server. A proxy is a special HTTP server that typically runs on a
firewall machine. The proxy waits for a request from inside the
firewall, forwards the request to the remote server outside the
firewall, reads the response and then sends it back to the client. Kevin
Altis, Ari
Luotonen and Lou
Montulli have been the principle designers behind the current
proxy standard as is illustrated in the following figure:
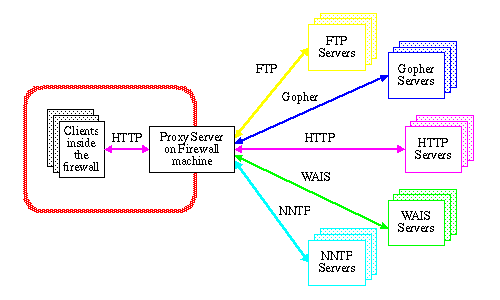
As seen from the figure, all communication between the client inside the firewall and the Proxy server is done using HTTP. This makes the client application much more effective as it can concentrate on the user interface and not on the Internet interface including presentation protocol clients etc.
In the usual case, the same proxy is used by all the clients within a given subnet. This gives another advantage of using a proxy server as it is possible for the proxy to do efficient caching of documents that are requested by a number of clients. The ability to cache documents also makes proxies attractive to groups of clients not inside a firewall as it cuts down the network traffic costs to remote hosts.
The CERN server had gateway features for a long time provided by Tim Berners-Lee, but this has recently been extended to support all the methods in the HTTP protocol used by WWW clients. Clients don't lose any functionality by going through a proxy, except special processing they may have done for non-native Web protocols such as Gopher and FTP.
Henrik
Frystyk, frystyk@info.cern.ch, July 1994