
Bidi in social media
Bidi in social media
This page checks how Facebook and Twitter manage with various bidi scenarios using plain text.
I pasted the text into my own accounts and show the results as pictures. Apart from the fact that Firefox supports RLI/LRI..PDI and other browsers don't, i don't think i would have seen different results if i had a different platform (certainly changing the language preference for the browser didn't seem to make any difference), but if anyone knows differently, please let me know.
Facebook appears to use first-strong character detection to establish the overall base direction for a comment. Twitter, however, seems to ignore the first strong character and guage the direction from the relative number of characters in a RTL vs LTR script. This is problematic when, for example, a long quotation in English follows a short intro in Arabic/Hebrew.
Note that simple paragraphs consisting only of RTL characters should work fine. Paragraphs that start with an appropriate first strong character and have an embedded phrase in the opposite direction should also work fine as long as there are no punctuation marks, numbers, or further nesting involved, and as long as the ratio of RTL vs LTR characters is appropriate for Twitter.
The first three tests look at how the default base direction is set for the whole, single paragraph tweet.
The remaining tests use inline controls to change the base direction inline.
Of course, a major issue with using Unicode control characters is that many keyboards don't support them. Another issue is that users think they are a pain to use and try to avoid them. It seems from the results that Twitter is rather allergic to them also.
The actual strings used in the test are included below. Be sure to pick up all characters on a line if using cut&paste, since there are frequently invisible characters at the start or end of the line. Note that the visual order of characters in these actual strings is not what you'd see under "Should look like". This is because, for this page, we haven't used the markup that would be needed to establish the appropriate base direction for those strings. The actual order of characters in memory is correct.
Test, paragraph direction: LTR phrase with Arabic trail
Text (no controls):
Arabic: لإيصال الشبكة المعلوماتية إلىأقصى إمكانياتها.
Should look like:
![]()
Result:
Twitter FAIL.

Facebook OK.

Test, paragraph direction: RTL phrase with Latin trail
Text (no controls):
الانجليزية: Making the World Wide Web worldwide.
Should look like:
![]()
Result:
Twitter FAIL.

Facebook OK.

Test, paragraph level: RTL phrase starting with LTR phrase
Text with no controls:
HTML היא שפת סימון.
Text with control codes:
HTML היא שפת סימון.
Control code added was RLM at very start of text.
Should look like:
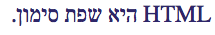
Result:
Twitter SUCCESS. But only because there are more Hebrew words than English. If you change the ratio, it won't work.

Facebook FAIL.
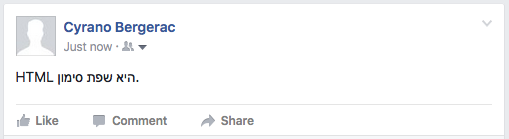
In both Twitter and Facebook, the RLM produces the right effect while typing the content into the create area, but appears to be stripped from the text before display.
Test, paragraph direction: LTR phrase starting with embedded RTL phrase
Text with no controls:
'نشاط التدويل، W3C' is how you say 'i18n Activity, W3C' in Arabic
Text with control codes:
'نشاط التدويل، W3C' is how you say 'i18n Activity, W3C' in Arabic
Control code added was LRM at very start of text. The Arabic phrase was surrounded by RLE..PDF (ie. everything inside the left set of quote marks).
Should look like:
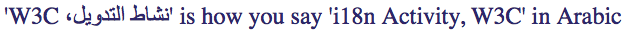
Result:
Twitter SUCCESS. But only because there are more English words than Arabic. If you change the ratio, it won't work.
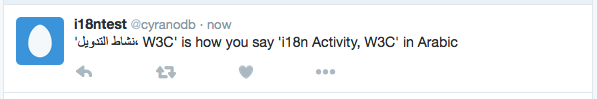
Facebook FAIL.
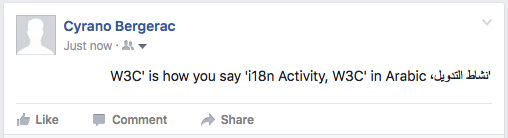
In both Twitter and Facebook, the LRM produces the right effect while typing the content into the create area, but appears to be stripped from the text before display.
Test, paragraph level: Multiple lines/paragraphs
Text (no controls)
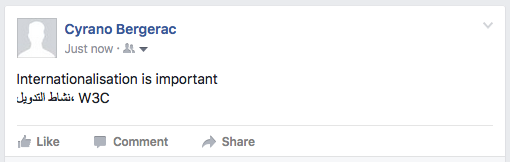
Internationalisation is important!
نشاط التدويل، W3C
Should look like:

Result:
Twitter FAIL. The key point here is that the W3C doesn't appear to the left of the arabic text. Whether the text should be to the right side is arguable, but the fact that the W3C (and the comma) is misplaced, shows that the base direction is not being determined on a paragraph by paragraph basis.

Facebook FAIL. For the same reasons. Note that when typing in the content, the rendering was as you'd expect (ie. in the browser form field), but Facebook failed to render the same way when the comment was sent.
Test, inline: double-embedded changes in direction
Text with no controls:
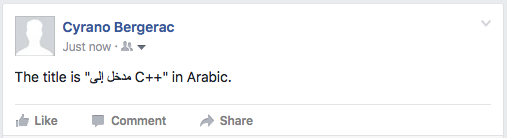
The title is "مدخل إلى C++" in Arabic.
Text with control codes:
The title is "مدخل إلى C++" in Arabic.
The title is "مدخل إلى C++" in Arabic.
The first string puts RLE..PDF around the Arabic phrase, and LRE..PDF around the C++ (embedding).
The second string does the same, but with RLI and LRI (isolation).
Should look like:

Result:
Twitter FAIL for RLE/LRE. Twitter actually stripped out the embedding control characters when i pasted the text into the input field.

Facebook FAIL for RLE/LRE. Facebook showed the embedded text as expected in the input field, but failed to display the published comment in the same way.
Twitter OK for RLI/LRI.

Facebook OK for RLI/LRI.
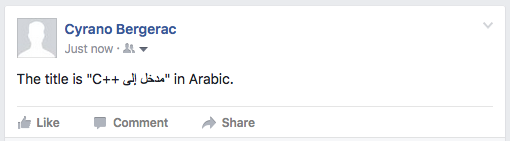
However, this this works on Firefox, which supports RLI/LRI, but not on Chrome.
The above results imply that Twitter looks for RLE/LRE/PDF and intentionally removes them from the input field.
Test, inline: RTL text followed by a number that is part of the LTR text
Text with no controls:
We find the phrase 'פעילות הבינאום' 5 times on the page.
Text with control codes:
We find the phrase 'פעילות הבינאום' 5 times on the page.
We find the phrase 'פעילות הבינאום' 5 times on the page.
In first string, control code used was LRM just before the 5.
In second, the Hebrew text was surrounded by RLI..PDI. (RLE..PDF is not useful here.)
Should look like:
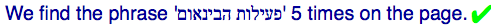
Result:
Twitter FAIL for LRM. Twitter actually stripped out the embedding control characters when i pasted the text into the input field.

Facebook FAIL for LRM. Facebook showed the embedded text as expected in the input field, but failed to display the published comment in the same way.
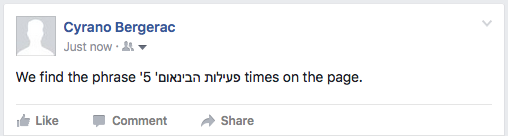
Twitter OK for isolation.

Facebook OK for isolation.
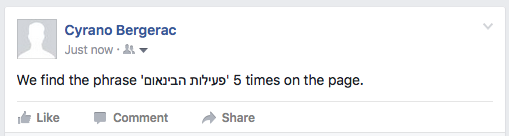
However, this works on Firefox, which supports RLI/LRI, but not on Chrome.
The above results imply that Twitter looks for LRM and intentionally removes it from the input field.
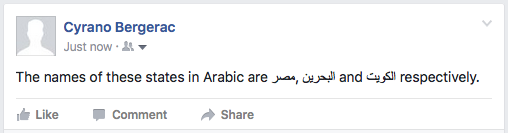
Test, inline: sequential opposite-direction phrases
Text with no controls:
The names of these states in Arabic are مصر, البحرين and الكويت respectively.
Text with control codes:
The names of these states in Arabic are مصر, البحرين and الكويت respectively.
The names of these states in Arabic are مصر, البحرين and الكويت respectively.
The first string puts LRM just after the first Arabic word.
The second wraps each Arabic word in RLI..PDI (RLE..PDF is not effective here).
Should look like:

Result:
Twitter FAIL for LRM. Twitter actually stripped out the LRM control character when i pasted the text into the input field.

Facebook FAIL for LRM. Facebook showed the embedded text as expected in the input field, but failed to display the published comment in the same way.
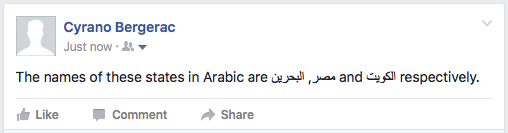
Twitter OK for isolation.

Facebook OK for isolation.
However, this works on Firefox, which supports RLI/LRI, but not on Chrome.
The above results imply that Twitter looks for LRM and intentionally removes it from the input field.
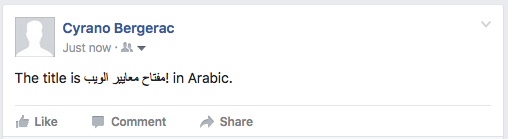
Test, inline: placement of punctuation for embedded opposite direction text
Text with no controls:
The title is مفتاح معايير الويب! in Arabic.
Text with control codes:
The title is مفتاح معايير الويب! in Arabic.
The title is مفتاح معايير الويب! in Arabic.
The first string surrounds the Arabic phrase with RLE..PDF, the second with RLI..PDI.
Should look like:

Result:
Twitter FAIL for embedding. Twitter applies a RTL base direction to the tweet because of the proportion of text that is in Arabic script.

Facebook FAIL for embedding, although it looked ok in the input box.
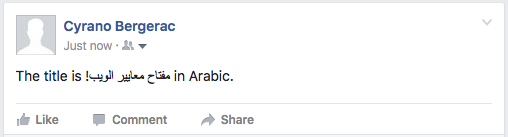
Twitter FAIL for isolation. The exclamation mark is in the right place relative to the Arabic text because the overall base direction for the paragraph is set to RTL (which is why the period appears on the left). The different order of directional runs from the embedded case arises because the RLI..PDI sequence is treated as a neutral character, rather than as a strong RTL character per an RLE..PDF sequence. (That's what Unicode requires.)

Facebook OK for isolation.
However, this works on Firefox, which supports RLI/LRI, but not on Chrome.
Test, inline: RTL text followed by a MAC address
Text with no controls:
כתובת 01:02:aa:4a:bb:06
Text with control codes:
כתובת 01:02:aa:4a:bb:06
כתובת 01:02:aa:4a:bb:06
The first string with controls uses LRM immediately before the MAC address. The second surrounds the MAC address with RLI..PDI (RLE..PDF is not effective for this problem).
Should look like:
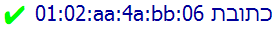
Result:
Twitter FAIL for LRM. Twitter applies a LTR base direction to the tweet because of the proportion of text that is in Latin script, and also fails to apply the LRM, leaving the initial numbers of the MAC address to bind to the Hebrew text.

Facebook FAIL for LRM, although it looked ok in the input box.
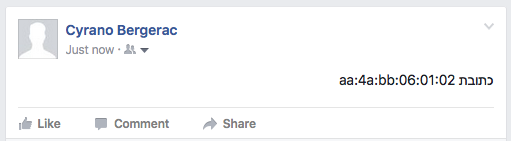
Twitter FAIL for isolation because it incorrectly applied a LTR base direction to the tweet as a whole.

Facebook OK for isolation.
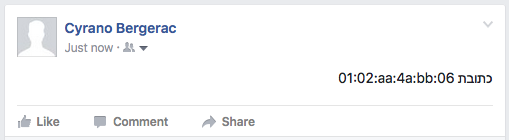
However, this works on Firefox, which supports RLI/LRI, but not on Chrome.