
Introduction to Chunks and Rules
See also:
- Introduction to Cognitive AI, originally presented to AIOTI WG03 subgroup on semantic interoperability
- Emergence of the Sentient Web and the revolutionary impact of Cognitive AI, as presented to the Open Geospatial Consortium TCM
- Cognitive agents, chunks and rules, originally presented as an invited keynote for the Gatekeeper project kickoff meeting
Companies are looking to digital transformation to become more efficient, more flexible and more nimble in respect to changing business needs. Paper forms, spreadsheets and traditional tabular databases are the legacy that is the weighing businesses down. Knowledge about the meaning of the data is locked inside people’s heads, partially described in specification documents that are often out of date, or buried inside application code that no one really knows how to update.
The future will emphasise digital integration vertically, horizontally, and temporally throughout the product life cycle, featuring decentralised information systems and machine interpretable metadata. Graphs are key to achieving this together with rules and highly scalable graph algorithms capable of handling massive datasets. Cognitive agents that blend symbolic and sub-symbolic (statistical) techniques represents the next stage in the evolution of AI, drawing upon decades of progress in Cognitive Psychology and Cognitive Neuroscience. This is important for addressing everyday situations involving uncertainty, incompleteness, inconsistency and the likely presence of errors, where traditional approaches based purely upon logical deduction struggle to be effective.
This page explores ideas for a simple way to express graphs and rules that operate on them, in conjunction with highly scalable graph algorithms, suitable for handling big data. The approach is designed with the aim of facilitating machine learning for vocabularies and rules, given that manual development will become impractical and excessively expensive as the number of vocabularies and their size scales up and up, and information systems require agility to track ever changing business needs. With that in mind, both declarative and procedural knowledge are represented in the same way to facilitate manipulation of rules as data. A series of demos are under development as proof of concept.
Cognitive AI is inspired by the organisation of the mammalian brain where the cortex is the convoluted outer part, connected via white tissue to a number of regions on the inside. In humans, the cortex is estimated to have around twenty billion neurons as compared to seventy billion neurons for the cerebellum. Different parts of the cortex are specialised to different functions, and functionally, the cortex can be compared to a set of cognitive databases. The following diagram illustrates a high level model of the brain in which the main modules are connected to multiple cognitive databases, in a manner that can be likened to a blackboard architecture. For more details see the March 2020 presentation on the Sentient Web to the OGC Future Directions Session
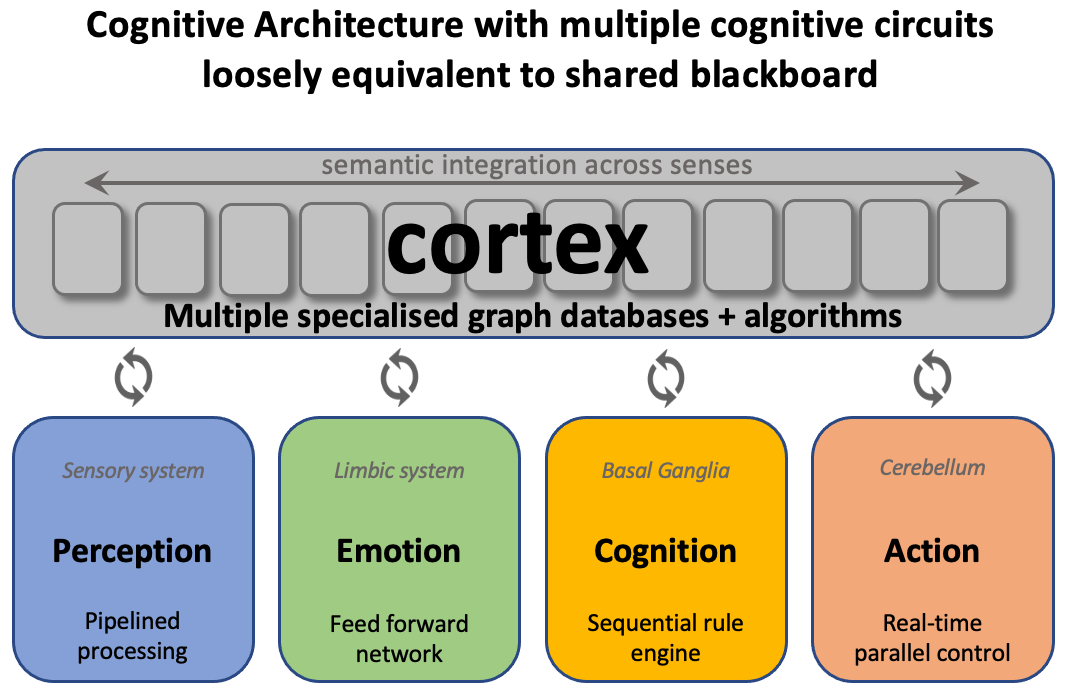
The following diagram zooms in on cognition and the role of the basal ganglia as a sequential rule engine:
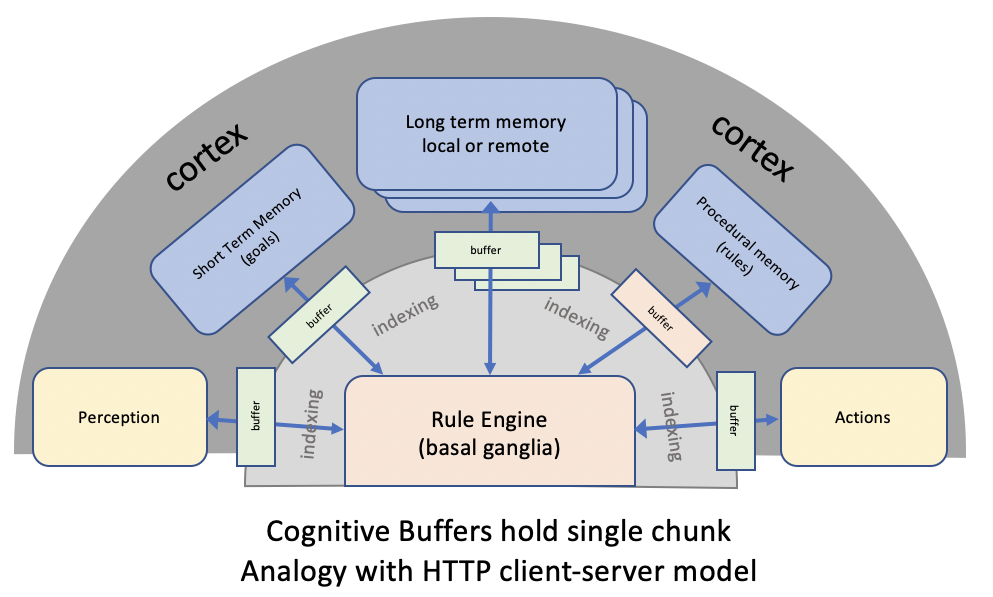
Module buffers are related to Baars’ global workspace theory (GWT) where attention acts as as a spotlight of awareness moving across a vast space of unconscious (i.e. hidden) processes. The brain is richly connected locally, and weakly remotely. The buffers correspond to the constrained communication capacity for such long range communication. This also provides an explanation of heavily folded structure of the cortex, see: Groden et al. (2019).
Chunk is a term from Cognitive Psychology, and is defined by Wikipedia as follows:
A chunk is a collection of basic familiar units that have been grouped together and stored in a person's memory. These chunks are able to be retrieved more easily due to their coherent familiarity.
See also Chunking mechanisms in human learning, by Gobet et al., who say:
Researchers in cognitive science have established chunking as one of the key mechanisms of human cognition, and have shown how chunks link the external environment and internal cognitive processes.
In the brain, chunks are signalled as concurrent stochastic spiking patterns across bundles of nerve fibres. You can think of this in terms of vectors in noisy spaces with a large number of dimensions. The set of name/value pairs in a chunk is represented by the projection of the vector onto orthogonal axes. Chunks can be represented as a vector sum over the circular convolution of the vectors representing each property's name and value. The value of a given property can be recovered to a good approximation from the chunk's vector using circular convolution with the involution of the vector for the property's name. For more details, see Eliasmith's work on concepts as semantic pointers.
For this work, a chunk is modelled as a concept with a set of properties. Each chunk has a type and an identifier. Chunk property values are either booleans, numbers, names, string literals enclosed in double quote marks, or a list thereof. Here are some examples:
friend f34 {
name Joan
}
friend {
name Jenny
likes f34
}
Where friend is a chunk type, and f34 is an optional chunk identifier. If the chunk identifier is not provided it will be assigned automatically. The second chunk above links to the first via its chunk identifier. Links are a subclass of chunk, for which the chunk type is the link relationship (aka predicate), and the link is described by the chunk properties subject and object. Links can be expressed in a compact format, e.g.
dog @kindof mammal cat @kindof mammal
This is equivalent to:
@kindof {
@subject dog
@object mammal
}
@kindof {
@subject cat
@object mammal
}
The chunk syntax avoids the need for punctuation with the exception of comma separated lists for property values. A semicolon or a newline is required after each property value, except before the closing bracket. You are otherwise free to use whitespace between tokens as you so desire.
Chunks can be used with ISO 8601 date-time strings as a data type, e.g.
company c28 {
name "Acme Inc"
ceo e1
}
employee e1 {
name "Amy Peters"
born 1984-03-01
started 2008-01-20
}
where the date-time values are interpreted as chunk identifiers for the associated fields, e.g.
iso8601 1984-03-01 {
year 1984
month 3
day 1
}
iso8601 2011-10-05T14:48:00.000Z {
year 2011
month 10
day 5
hour 14
minute 48
second 0
zone UTC
}
Human language terms can be expressed as a chunk with properties that declare the Unicode string literal, the language (ISO 639 codes) and base directionality (rtl or ltr), e.g.
text {
value "جمل"
lang ar
dir rtl
}
Relation to Property Graphs
There is an obvious similarity to labeled property graphs. These consist of nodes connected by labeled directed edges, which are referred to as relationships. Both nodes and relationships may have properties represented by key/value pairs. In the current work, both nodes and relationships are modelled as chunks, with chunk properties used for key/value pairs.
One difference from the Property Graph databases is that they generally provide query/update languages, but not rule languages. Applications are written using conventional programming languages that interact with Property Graphs via the corresponding query/update APIs. By contrast, this work on chunks seeks to support machine learning of vocabularies and rulesets, changing the role of developers into that of teachers who instruct and assess the capabilities of systems, and monitor their performance. This will be increasingly important as the number and size of vocabularies scale up and up, along with the challenge of mapping data between different vocabularies, so that manual development becomes increasingly impractical. The effectiveness of vocabularies and rulesets can be assessed through application to a curated set of test cases, with the ability for developers to add new cases as needed.
Goal directed production rules
The architecture is inspired by ACT-R, a popular cognitive architecture that has been successfully used to describe a broad range of human behaviour in Cognitive Science experiments, e.g. mental arithmetic and driving a car. There are several modules, each of which is associated with a graph. The facts module contains declarative facts, whilst the goal module contains goals.
Following ACT-R, we distinguish declarative knowledge expressed as chunks from procedural knowledge expressed as rules. Rules consist of conditions and actions. Conditions match the current contents of module buffers. Actions can directly update the buffers, or can do so indirectly, by sending messages to the module to invoke graph algorithms, such as graph queries and updates, or to carry out operations, e.g. instructing a robot to move its arm. When the algorithm or operation is complete, a response can be sent back to update the module's buffer. This in turn can trigger further rules as needed.
Rules are expressed as a set of chunks, e.g.
rule r1 {
@condition g1
@action a1, a2, a3
}
count g1 {
@module goal
start ?num
state start
}
count a1 {
@module goal
state counting
}
increment a2 {
@module facts
@do recall
first ?num
}
increment a3 {
@module output
value ?num
}
It is easier to use the following syntax which avoids the need to provide the chunk IDs, e.g. the preceding rule becomes:
count {@module goal; start ?num; state start} =>
count {@module goal; state counting},
increment {@module facts; @do recall; first ?num},
increment {@module output; value ?num}
This takes the form of one or more comma separated condition chunks, followed by the => operator, followed by one or more comma separated action chunks. Here is another example:
space {belt ?belt} => action {@do addItem; belt ?belt}
The rule language attaches special meaning to terms beginning with "@", for instance, @condition is used to name the chunk identifiers for the rule's conditions, and likewise, @action is used to name the chunk identifiers for the rule's actions. Rule variables begin with "?" and provide a means to bind data between conditions and actions.
Each condition and action identifies which module it relates to, defaulting to the goal module. Conditions act on buffers rather than on the modules. Each module has a single buffer that may contain a single chunk. In the above example, g1 is a condition chunk that matches the chunk in the goal buffer, which must have the same chunk type (in this case count). The start property is used to bind the ?num variable, while the state property is expected to have the value start.
The a1 chunk is an action and updates the chunk in the goal buffer to have the value counting for the state property. The other properties for the buffered chunk remain unchanged. The a2 chunk sends a request to the facts module to recall a chunk with type increment and a matching value for the property first. The @do directive instructs the rule engine which graph algorithm or operation to execute. The default is to update the buffered chunk for that module.
Module buffers contain copies of chunks. Updating the buffer thus has no effect on the module's graph. The @recall operator copies a matching chunk from the graph to the buffer, whilst @remember copies the chunk in the buffer to the graph. If there is an existing chunk with the same ID, this operation will overwrite those properties with values from the buffer, whilst leaving the others intact. If the chunk in the buffer lacks an ID, a match is performed on the properties to select a matching chunk in the graph to update. If none exists, a new chunk will be created.
The process of matching a buffered chunk to chunks in the graph as part of the @recall and @remember operations is stochastic, and depends on the expected utility of the chunks as determined by prior knowledge and past experience, see the later section on stochastic recall.
Badly designed rulesets have the potential for infinite loops. This is addressed by abandoning tasks that take considerably longer than expected, see task management and attention.
The rule language is a little cumbersome for manual editing. That could be addressed with a higher level rule language that compiles into chunks, but it wouldn't be appropriate for machine generated rules. Vocabularies and rule sets that have been generated through machine learning are likely to be harder to understand for humans, since the terms they use will have been machine generated, e.g. an identifier like "_:386314". This isn't expected to be a problem in practice, as people will be able to use natural language (or a controlled subset) to interact with cognitive agents, where a lexicon maps the human terms to the terms used internally.
Additional features
The rule language is expected to evolve further in the course of work on new demonstrators. This section describe some additional features and the expected direction for future extensions.
The @distinct property can be used in conditions to test that its values are not all the same. A related idea, also borrowed from ACT-R, is to be able to declare that the value in a variable must be different from the given property value, e.g.
goal g3 {
@module goal
state counting
start ?num
end !num
}
i.e. this requires that the start and end properties in the goal chunk have different values. This is a redundant feature given @distinct. If it is kept, it might possibly make sense to change the syntax to say !?num.
Additional features will be added as needed for new use cases. One example is where we want to match a chunk only if one or more named properties are not defined for that chunk. For this we can use @undefined which takes one or more property names. Another example is where we want a unique match for a property value rather than just requiring that the value in the condition is one of the values in the candidate chunk's property. To ensure a unique match you include @unique with one or more property names. More specifically, this ensures that the match will fail if the chunk's property value is a list that has items that aren't present in the value for condition's property, or if it has single value that is different from the value in the condition.
Sometimes it may be necessary to test whether a variable holds a boolean, number, name, string literal or a list thereof. This suggests the need for properties like @boolean, @number, @integer and so forth. Further consideration is needed for string literals. In principle, human language descriptions could be expressed using a chunk with properties for the string literal, its language tag and its base direction. Complex string operations would seem to be beyond the scope of a simple rule language, and something that could be better handled via invoking operations implemented by a module.
By default, actions specify chunks with the same type as the action chunk, however, sometimes you will want to query for an instance given its super type. For example, given these facts:
penguin @kindof bird eagle @kindof bird ...
and a rule action like:
* a3 {
@module facts
@do recall
@isa bird
}
Then the action could, in principle, load the following chunk to the facts buffer:
penguin p6 {
name pingou
}
This follows since pingou is a penguin, and a penguin is a kind of bird. The * acts as a wild card that matches any type. The @kindof property can be similarly used in actions to query subclasses of a given class in a taxonomy. Actions can request a given chunk using its chunk identifier with @id. This can also be used in conditions to bind a variable to the chunk identifier, and likewise, you can use @type to bind a variable to the chunk's type. The following condition matches any chunk in the facts buffer and binds ?id to the chunk's identifier and ?type to the chunks's type.
* a3 {
@module facts
@id ?id
@type ?type
}
Very occasionally, you may find a need to undefine a property for a module's buffer to ensure this rule no longer matches the buffer. For this, you place @undefine with a comma separated list of the names of the properties you want to undefine in an action for that rule. If you want to clear the buffer altogether, use @do clear. To pop the buffer use @do pop. This is only relevant when a module buffer needs to queue events to avoid the buffer being overwritten before an event has been handled. The JavaScript chunks library supports a priority queue with the API module.pushBuffer(chunk) where the priority is given in chunk.priority as an integer in the range 1 to 10 where 10 is the highest priority, and 1 is the lowest. The default is 5.
The current approach allows you to either state the expected value for a property, or to use a variable to match any value. A further possibility is when you want to constrain the match to a value from a given set. This could be addressed by referencing a range definition in subsidiary chunk, e.g. a rule could include the following:
t-shirt c1 {
@module facts
@range c2
}
range c2 {
property colour
values red, green, blue, white, black
}
which would match a chunk in the facts buffer with the type t-shirt and a colour property that is one of red, green, blue, white, or black. This could be extended to support numeric ranges, and for defining range values as separate chunks with relative ordering. This further points to the potential for supporting fuzzy reasoning. For instance, a temperature could be classified as cold, warm or hot. As the temperature is raised, it starts by being cold, but rather than suddenly being classified as warm, there is a smooth transition, with decreasing probability that the temperature is cold and increasing probability of being warm. The probability then flattens out until the smooth transition from warm to hot. For more details see the wikipedia article on fuzzy logic.

There is a need for flexible handling of properties that have a list of values. This requires further consideration. Some possible requirements include: testing if the list contains a given item, a means to iterate through the list, a means to add and remove list items, set operations on lists, e.g. union and intersection, counting the number of items in a list, a means to sort lists, and to remove any duplicates. Once again, many of these operations could be handled via graph algorithms associated with a module, rather than being built into the rule language.
Support for numbers
People and animals have an innate ability to handle numbers, e.g. to know if something is in reach of your hand, or whether a gap is small enough to jump over. This suggests the need for simple numerical operations, e.g. comparisons, such as @lteq which would be used with two variables to test that the value of the first is less than or equal to the value of the second. Limited support for comparison and adjustment of numerical values is needed for modelling emotional states. Operations on numerical values is also needed for spatial and temporal reasoning, and points to the potential for specialised processing with a graph algorithm invoked by rule actions. In other words, the rule language should remain simple, with more complex operations handled by the modules.
Stochastic recall
The real world is frustratingly uncertain, incomplete and inconsistent. Logic alone is not up to the challenge and needs to be combined with emotion and intuition. More explicitly, we need to blend symbolic and statistical approaches. This will allow us to create agents that learn and reason based upon prior knowledge and past experience. We can build upon insights from research on human memory and progress in neuroscience. In the late nineteenth century, Hermann Ebbinghaus pioneered the study of memory, and is well known for the forgetting curve and the spacing effect, otherwise known as the decay theory of memory.
He showed that the ability to recall information drops off exponentially without practice, with the sharpest decline in the first twenty minutes and leveling off after about a day. The learning curve describes how fast people learn information. The sharpest increase occurs after the first try, and successive repetitions have gradually less effect. In addition, the improvement in retention is more effective when the repetitions are spaced out (the so called spacing effect). One possible explanation is that our attention focuses on novel stimuli, so that less attention is given to closely repeated stimuli.
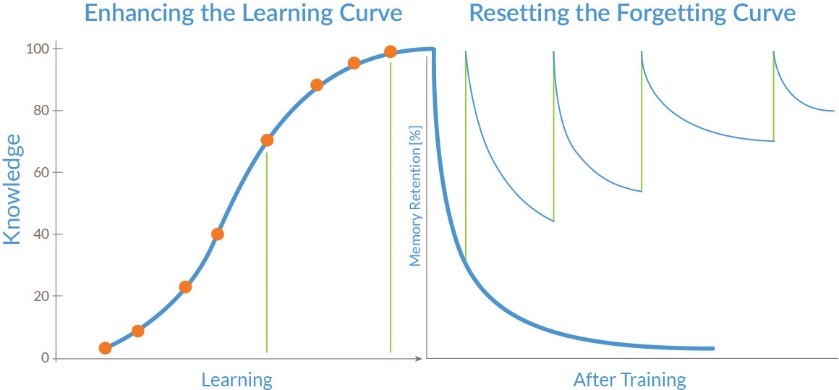
With thanks to Sean Murphy, PharmaCertify
ACT-R embodies the forgetting curve with a relatively complex model for the probability of chunk recall, and the time taken to do so, see: Said et al. The following describes a simplification that is more amenable to efficient computation in cognitive databases. The aim is to ensure that the probability of successfully retrieving a chunk from memory depends on the expected utility based upon prior knowledge and past experience.
Each chunk is associated with a numeric activation level that decays exponentially over time, and which is boosted on every recall or update by an amount that drops off when the time interval is less than a given threshold. Chunk retrieval is subject to a minimum threshold for the activity level. A noise source ensures that occasionally chunks with lower activity levels will be picked over chunks with high activity levels. This can be implemented by associating each chunk with a timestamp and the logarithmic value of activity level.
Spreading activation models how related memories boost each other. Activation is spread evenly through links between chunks, so that the more links there are from a given chunk, the weaker its effect will be on linked chunks. This process is repeated recursively until a given cut off threshold.
In 1932, John McGeoch suggested that decay theory should be replaced by interference theory, in particular, proactive interference is where older memories interfere with the recall of newer memories, and retroactive interference is where newer memories interfere with the recall of older memories. In this view, the Ebbinghaus forgetting curve is a consequence of interference from other memories.
Decay theory would suggest that old memories become unretrievable. However, it is common to be able to retrieve old memories given the appropriate cues, provided those memories were formed strongly, e.g. an important event in your life. This suggests that practical cognitive databases should emphasise interference theory over decay theory. One possibility would be to introduce persistent strengths as accretions from a history of changing activation levels. A question for further study is whether persistence should be associated with chunks or the links between them (i.e. chunk properties that name other chunks).
Another perspective is that of Bayesian statistics and information theory, e.g. how much new information is provided by a given presentation of a stimulus. One challenge is that this can lead to the need to store large numbers of parameters, and suffer from sparse statistics. Practical solutions may be feasible that approximate Bayesian statistics as the number of observations grows. Do we need to deal with timestamps for chunks, or can we just rely on spreading activation to strengthen or weaken links between chunks without the need for timestamps?
The rule language provides a means to invoke graph algorithms in a request/response pattern that updates the module's buffer with a single chunk. The simplest case is using a name that uniquely identifies a chunk. In this case, the chunk's strength determines the probability of successful recall. More generally, chunks can be recalled matching a given type and property values. Here, the best matching chunk is returned, subject to some uncertainty. In this case, we want to ensure that on average the chunk returned is the one that best matches prior knowledge and past experience.
This is influenced by the initial chunk strength, how often it has been recalled or updated, and the activation it has received from related chunks via property values naming that chunk. Just because a chunk was useful in the past is no guarantee that it will be useful in the future if the circumstances change. This means that we should place greater weight on more recent activity. Further work is needed to explore and evaluate different ways to achieve that. One approach is outlined above (decay theory). Another approach would be to use a rolling average for the frequency that the chunk is reinforced compared to other chunks.
A further point for consideration is the relationship to processing of emotions. Declarative memories are more vividly remembered if they are associated with emotions with high valence and/or high arousal. The brain's system for storing and retrieving emotional and declarative memories operates in parallel, and are brought together under conscious control, see the Papez circuit, also known as the limbic system.
Scripting API
This section describes the scripting API exposed by the JavaScript library for chunks and rules, as used in the online demos. The starting point is to create a graph from a text string containing the source of the chunks that make up the graph. The following code creates two graphs: one for facts from "facts.chk", and another for rules from "rules.chk".
let facts, rules;
fetch("facts.chk")
.then((response) => response.text())
.then(function (source) {
facts = new ChunkGraph(source);
fetch("rules.chk")
.then((response) => response.text())
.then(function (source) {
rules = new ChunkGraph(source);
});
});
Here are some operations you perform on a graph:
new ChunkGraph(source)- Create a new graph from a text string containing the chunks and links.
graph.chunks[id]- Find a chunk given its id.
graph.types[type]- Find the list of chunks with a given type.
graph.forall(kind, handler, context)- Apply a function to all chunks whose type has the
kindofrelationship to the givenkind. This applies recursively to chains ofkindofrelationships. The handler is a function that is passed the chunk and thecontext. graph.get(type, values)- Recall a chunk with a given type, and matching values as denoted by a JavaScript object with a set of named properties. Note that this is stochastic and returns the 'best' chunk when there are multiple matches.
graph.put(type, values, id)graph.delete(type, values, id)graph.parse(source)graph.add(chunk)graph.remove(chunk)Here are some operations you perform on a chunk:
new Chunk(type, id)- Create a new chunk for a given type and id. The id is optional and will be assigned automatically when the chunk is added to a graph if not supplied.
new Link(subject, predicate, object)- Create a new Link as a subclass of chunk where the chunk type is given by the predicate. The chunk id will be assigned automatically when the Link is added to a graph.
chunk.id- Access the chunk's id.
chunk.type- Access the chunk's type.
chunk.properties[name]- Access a chunk property value given the property's name.
chunk.setValue(name, value)- Overwrite the value of a named property
chunk.addValue(name, value)- Add a value for named property. An array is used only if the property value has multiple values.
chunk.removeValue(name)- Remove a value from the named property - this is the inverse of
addValue. chunk.hasValue(name, value)- Returns true or false according to whether the named property contains the given value, i.e. the property is either that value or it is a list, one of whose items is that value. If the property is undefined for this chunk, then the return value is false.
chunk.toString()- Returns a pretty printed version of the chunk.
The following describes the API for rule engines:
new RuleEngine()- Create a new rule engine.
engine.addModule(name, graph[, backend])Registers a new local module with its name, graph and an optional backend for graph algorithms.
The backend is declared as an object whose property values are functions that implement the algorithm identified by the property's name. The algorithm's name can then used with
@doin rule actions for this module. The action is passed a single argument that is an object whose property values are the bindings for the variables identified by the object's property names.The backend functions can be used to override the default actions for recall, remember and update. Note that "rules" and "goals" are required modules. The rules module is used to hold procedural knowledge as a set of rules. By default, the "goals" module is initialised to an empty graph. A separate method is envisaged for adding remote modules.
engine.getModule(name)- Return the module created by calling
engine.addModule. engine.start(rules, facts[, initial_goal])- A convenience function to set the rules and facts modules, along with an optional initial chunk, that is provided as a chunk, i.e. as source text. Note:
rulesis a graph containing the rules that define procedural knowledge, andfactsis a graph containing a set of chunks that define declarative knowledge. The goal is not used until you call engine.next(). engine.next()- Find and execute the next matching rule.
engine.setGoal(source)- Parse the source for a chunk and load it into the goal module's buffer.
engine.setBuffer(name, source)- Parse the source for a chunk and add it to the named module's graph, then load it into the module's buffer.
engine.setBuffer(name, chunk)- Load the chunk into the named module's buffer.
engine.getBuffer(name)- Return the chunk in the named module's buffer.
engine.addListener(listener)- Register a listener function that will be called when any of the module buffers are updated. The listener is passed a single argument identifying the module by name.
Short term vs working memory
Working memory is used here for the module buffers which are restricted to a single chunk. Short term memory is more flexible and provides a means to hold multiple chunks of short term interest. A possible approach would be to provide a short term memory module analogous to the brain's hippocampus, and to provide a means for queries on long term memory modules (analogous to the cortex) to place results into the short term memory module.
When trying to remember all instances of some class, it is easy to remember the most common instances, but the others will be much harder. If the instances form a sequence, then given one instance, it is relatively easy to remember the following one, for example, successive letters in the alphabet. When recalling all kinds of birds, the results could be mapped into a sequence of chunks, that rules could iterate over by following the reference from one chunk in the sequence to the next. In a sufficiently large database, search will be limited to what is most useful based on prior knowledge and past experience. This can be implemented in terms of ACT-R's stochastic recall, based upon a combination of dynamic activation levels and persistent strengths.
It will also be interesting to consider other kinds of queries, e.g. automata based upon graph traversal or simple patterns inspired by SPARQL. Those demos use RDF, but could easily be adapted to use chunks, for instance, @shape could be used to reference a chunk that is the starting node in an automata defining a shape constraint, analogous to SHACL and ShEx. The results of such queries would be a set of chunks that could be placed in the short term module. This fits well with an architecture that provides a local module for short term memory together with access to remote long term memory modules. The ability to retrieve multiple chunks in a single remote query provides for better performance compared to having to retrieve chunks one by one.
Whilst graphs of concepts and relationships are very flexible, other kinds of representations are relevant to visual and aural perception, recollection and reasoning. When you think of something in your mind's eye, say a red rose, you have an image of it and its scent, as well as the sound of the word "rose". Imagining a tree in a strong autumn wind, you can see it bending in the gusts, with the damp leaves flying. Concepts can be easier to remember given associations with multiple senses of perception, e.g. a visual image plus the sequence of syllables that make up the sound of its name. When you see something briefly, the image of it lingers for a while, but rapidly fades away. Sounds linger a little longer. Concentrating on the image, or replaying/rehearsing the sound in your mind's ear can help keep it a little longer. This relates to the mechanisms by which sensory input is buffered in working memory. Our ability to manipulate such information is limited, e.g. to rotate an image in our minds eye.
The work described in this document focuses on graphs, rules and their manipulation. This doesn't preclude spatial reasoning altogether, e.g. a network of roads can be modelled as a graph of paths and points, and spatially indexed based upon the latitude and longitude of the points. Search algorithms can then traverse this network to find the shortest routes between any two points. Likewise, graphs can be used to represent the sounds of words in terms of sequences of symbols denoting phonemes. A cognitive agent could include specialised modules that implement additional representations, and provide the means for rules to act on them as necessary for specific skills, as well as to provide links between the different kinds of representations.
Reasoning from multiple contexts
Search may often need to be conducted relative to a given context rather than across the database as a whole. The ability to define and search from within such contexts is important when it comes to counterfactual reasoning, causal reasoning, and reasoning involving multiple perspectives. Contexts are also of value in respect to implementing a theory of mind:
According to wikpedia, theory of mind is the ability to attribute mental states — beliefs, intents, desires, emotions, knowledge, etc. — to oneself, and to others, and to understand that others have beliefs, desires, intentions, and perspectives that are different from one's own.
The proposed solution is to provide a means to group chunks into a set by adding a context property to the chunk object model. This would allow for the context itself to be defined as a chunk. The context chunk can link to a parent context to define a chain of contexts. Rules conditions and actions would refer to the context chunk via @context. This would allow rules to match a specific context, and likewise, to update chunks in a specific context.
The root context is everyday declarative knowledge, e.g. elephant is a kind of mammal, and turquoise is a colour. A context might be created for what-if reasoning, for describing the beliefs attributed to some person or agent, for lessons in which some things are deemed to hold true in the context of a lesson, and for a story about some fictional world, e.g. magic exists in the world of Harry Potter novels, but pretty much everthing thing else is the same as in our world.
Nested contexts may be used, e.g. for describing the personal beliefs of the people in a given story. Knowledge described in a given context will often override or supplement knowledge in a parent context. Another use case is where you are considering different possible events leading up to a particular outcome, e.g. when trying to explain a fault in some machinery. This may necessitate a tree of chained contexts.
A question to be decided is what syntax to use in the chunk serialisation format to indicate that one or more chunks belong to a given context. The simplest idea would be to declare the context as a regular property of other chunks, analogous to kindof, see above. Another idea is to allow the context identifier immediately after the chunk identifier and just before the curly brackets enclosing the chunk's properties. A further possibility would be to allow @context followed by the context's chunk identifier then curly brackets enclosing chunks belonging to that context. This is the same syntax as for a single chunk, except that the brackets would enclose a set of chunks rather than a set of properties.
The Semantic Web focuses on logical deduction with ontologies characterised by formal semantics. This work, by contrast, focuses on graph traversal and manipulation, adopting the philosophy of relativism in which views are relative to differences in perception and consideration. There is no universal, objective truth according to relativism; rather each point of view has its own truth. Protagoras is reported to have said to Socrates:
What is true for you is true for you, and what is true for me is true for me.
This doesn't mean that all perspectives should be considered equal, but rather should be seen in the context of other knowledge, moreover, what people say isn't necessarily what they consider to be true, but what they want others to believe.
Causal Reasoning and asking why?
According to Barbara Spellman and David Mandel:
Causal reasoning is an important universal human capacity that is useful in explanation, learning, prediction, and control. Causal judgments may rely on the integration of covariation information, pre-existing knowledge about plausible causal mechanisms, and counterfactual reasoning.
Causal reasoning allows you to make predictions and decisions based upon an understanding of cause and effect. A starting point is to look at correlations across a sequence of observations. For instance, looking at the correlation between smoking and lung cancer, using counts for smokers with and without lung cancer, and counts for non-smokers with and without lung cancer.
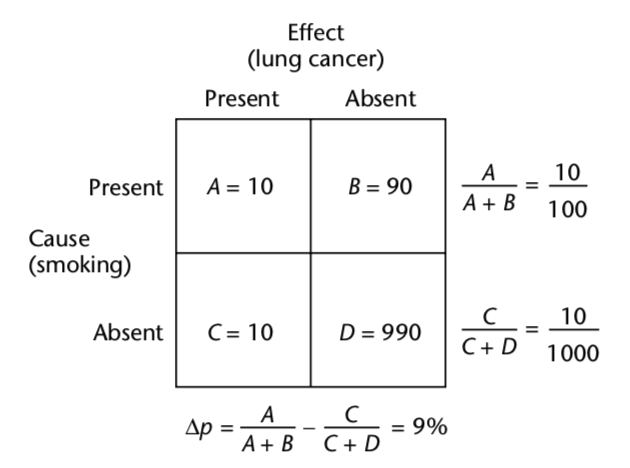
With thanks to Barbara Spellman and David Mandel
This computes the proportion of times the effect occurs when the suspected cause is present, minus the proportion of times it occurs when the suspected cause is absent. Statistical significance is defined as the likelihood that a relationship between two or more variables is caused by something other than chance. The larger the number of samples in the experiment, the smaller the observed difference in proportions needs to be in order to be considered statistically significant. However, statistical significance doesn't by itself prove a causal relationship. For instance, ice cream sales may have a statistically significant correlation with crime rates, but further study reveals a common cause - a heat wave.
To understand and gain control, we seek plausible explanations as to why things happen. Sometimes there could be more than one possible explanation, necessitating reasoning about which is the most likely for any given event. We could perhaps re-examine the statistics having widened our search to include data for the weather as well as for ice cream sales and crime rates. A plausible explanation involves a mechanism, e.g. high temperatures increase the likelihood of people getting angry and committing a crime. Simpler explanations are generally preferred to more complex ones. Newer techniques include bivariate causal discovery, see Anish Dhir and Ciaran M. Lee, and can be applied across multiple overlapping datasets to identify likely causal chains based upon membership of Markov equivalence classes.
A cognitive agent could look for statistically significant correlations when an event is deemed similar to previous ones, and then look for plausible explanations. However, what happens if you don't have a large number of events to analyse? Humans from an early age pay more attention to events which don't follow the pattern seen in previous events. One possible approach is to seek explanations by considering a range of potential causes. This can be modelled as counterfactual reasoning where something is assumed to have taken place for the purpose of analysis, but is not considered to be true in general. The previous section describes one way to represent this in terms of chunk contexts.
Knowledge of causal relationships can also be exploited when it comes to planning how to achieve a particular outcome. Actions can be modelled as having pre-conditions before they can be applied, and post conditions that hold after they have been applied. As is the case for counterfactual reasoning, plans are a kind of what-if reasoning rather than reflecting the state of the world. As such they could be constructed in a chunk context created for the purpose. Plans often make use of previous experience as a guide to how to break problems down into manageable pieces. This has implications for episodic memory.
In conclusion, cognitive agents need an innate curiosity that directs attention to finding explanations for events, starting with a means to relate a current event to previous ones. The reasoning processes will depend upon the means to construct contexts for chunks which are assumed to be true within the context of the reasoning process, rather being general facts about the world. Episodic memory needs to support recall of past events based upon similarities with the current event. It would be interesting to look at graph algorithms that can be used to offload the processing needed for computing statistically significant correlations. Such an approach would be essential for handling big data.
Episodic memory and reasoning with analogies
Episodic memory involves memories of events and awareness of past experience. An event may be considered as a single thing, or as something that is spread out in time with an appreciable duration, and memories of what happened at different stages, e.g. a birthday party, where you remember greeting people, opening presents, a birthday meal and so forth. Events can be recalled as part of a linear sequence, e.g. all the things I did yesterday, or via a relationship to other things, e.g. my 21st birthday, or via something that reminds you of that event, such as a place or a feeling.
Episodic memory is key to learning declarative knowledge from experience. The challenge is how to recognise that a current event resembles a previous one based upon its properties and relationships to other chunks. Humans are good at learning taxonomic classifications from the statistics of sequences of examples. This also relates to solving problems by seeking analogies with problems you have dealt with in the past. This involves mapping one problem to another through finding similarities, see, e.g. Gentner and Markman '97, and Gentner '83.
An open question is how to lay down episodic memories as a side effect of goal-directed rule execution, e.g. as a sequential record of goals in a structure reflecting task management and attention. The strength of memories is influenced by the expectation of reward, or the avoidance of a penalty, in other words, the strength of memories is related to emotions. Studies of episodic memory suggests several stages: encoding, storing and retrieval.
Episodic memories are reinforced by repeated recall, and are also subject to false memories where reasoning processes fill in the gaps in memories based upon what is likely or desirable according to everyday experience. Daniel Schacter, for instance, suggests that false memories form partly because our brains are constructive — they create narratives about our future, which might lead to related memory errors about our past.
This is expanded upon by Conway and Loveday in an article on autobiographical and episodic memory that concludes that all memories are mental constructions, and to some degree false and that the main role of memories lies in generating personal meanings, that allow us to make sense of the world and operate on it adaptively. Memories are, perhaps, most important in supporting a wide range social interactions where coherence is predominant and correspondence often less central. The highlights are:
- Memories are mental constructions.
- Memories represent short time slices derived from experience.
- Memories contain inferences and details not derived from memory of an experience.
- All memories are to varying degrees false.
- Memories ground personal meanings and beliefs.
The above points to opportunities for modelling autobiographical and episodic memory in cognitive agents as a constructive process that supports self-awareness in addition to learning from experience.
Compiling rules from declarative representations
The @compile property can be used with a chunk identifier to compile a set of chunks into a rule. This is needed as the use of @ terms in goals and rules interferes with retrieving or storing chunks involving these terms. The compilation process maps to these terms when copying chunks to the rule module. The default mapping simply inserts an @ character before the name, e.g. mapping do to @do. If the application needs to use the reserved terms for other purposes, you can reference your own map to the standard terms by using @map to reference a chunk with the map, e.g. if you wanted to use m instead of module, and diff instead of distinct:
@map {
m module
diff distinct
}
Note that for compile, @source identifies the module for the chunk referenced by @compile. In principle, there could be an @uncompile property which takes a chunk identifier for a rule in the rule module, and puts the mapped rule chunks into the module referenced by @source, and at the same time, placing the corresponding rule chunk into that module's buffer. This would provide an opportunity for inspection over procedural knowledge. Further work is needed to check whether this capability is really needed. See below for a brief discussion of the potential for declarative reasoning over rules as part of the process of learning how to address new tasks.
Issue: perhaps we should use @module instead of @source given that the rule module is implicit, on the assumption that there is only one rule module.
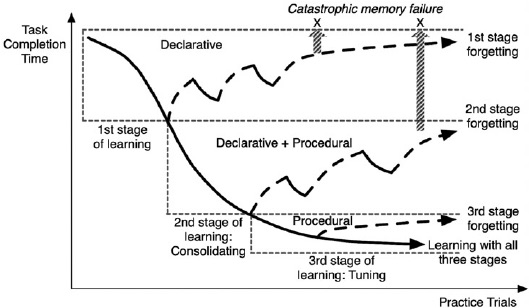
The following figure illustrates the theory of skill retention, with three stages of learning and forgetting, from Kim et al, 2013
Task management and Attention
The sequential nature of rule execution necessitates a means for switching attention between different tasks according to the current priorities, including high priority interrupts. Moreover, complex tasks will often need to be broken down into simpler sub-tasks that need to be managed in the face of competing demands. The focus of attention is also important in respect to directing processing within input modules, e.g. for an autonomous vehicle, the need to focus visual attention on road signs or pedestrians in the field of view ahead of the vehicle.
To make machine learning practical, rules need to be grouped into sets that are designed for specific tasks. A given task might involve a start rule, one or more progress rules, and at least one stop rule. For each task, there is likely to be multiple goal states. This brings a number of challenges: the relationship between a task and a sub-task, how to manage competing tasks, including time critical ones, and the relationship between tasks and machine learning.
In respect to switching between tasks, one idea is to wait for the current task to stop, and then to search for another task. Another idea is to abandon the current task when it is necessary to switch to a high priority task that requires urgent attention. Lengthy tasks could be broken up into smaller sub-tasks, allowing for pausing to consider what to do next at the completion point for individual sub-tasks. That presumes a means for suspending and resuming high level tasks.
One idea is to set the goal buffer to an idle chunk that triggers rules that look for currently pending tasks. In principle, pending tasks could be held as chunks in the goal module, having been put there when a task is proposed or suspended. This is related to the requirements for episodic memory for recording and reasoning over past experience, and to the role of the hippocampus for a relatively detailed short term memory.
A related challenge is indexing of rules for efficient selection as the number of rules scales up and up. The baseline is indexing based upon chunk type and chunk id. Further indexes could be constructed dynamically based upon the observed patterns of access, e.g. by determining that a given property is key to rule selection. Is there a way to implement a discrimination network to speed up rule selection?
One idea is to focus on conditions with literal values as a first stage, and to treat variable bindings as a second stage in the filtering process. This is then followed by a process for selecting the highest ranked rule, and then executing its actions. Rule conditions match the current state of the module buffers, and there are only a handful of such buffers. Efficient selection is thus much much easier than if rules were to directly match the state of all of the graph databases.
More sophisticated cognitive agents will be able to pause to reflect on their priorities and how well they are doing in respect to higher level goals. This includes models of self and others in the context of social interaction. How well is the agent doing relative to its expectations? What are some other ways it could proceed? This involves a means to switch attention between higher level reflective tasks and lower level tasks. Attention could also be diverted when encountering novel situations in order to understand and learn from the new experience. Both cases are related to models of attention based upon emotional responses, see the later section on Emotions and Social Interaction.
- Performance
- Proficiency in a skill or concept. This corresponds to compiled knowledge, e.g. rulesets, with limited flexibility.
- Cognition
- Understanding of a skill or concept. This involves declarative models that can be used for greater flexibility. Practise leads to increased proficiency.
- Metacognition
- Reflection on cognition, e.g. how well am I doing, is there a better way, am I missing something? Associated with secondary emotions, e.g. anxiety about not being able to achieve one's goals in a given situation.
Focusing input on features of interest
When you are driving, your visual attention prioritises features of interest relevant to driving. This involves a reinforcement learning process, as is apparent when driving in another country for the first time, when it is common at first to feel bewildered by the apparent visual clutter distracting you from the task in hand. The cognitive effort soon drops off as you learn what to focus on, and what to ignore.
This can be modelled in terms of a means to signal the current task to the input modules along with a means to consciously direct attention to specific features when needed, e.g. to read the information on a road traffic sign, having noticed a sign in the field of view. In addition, there needs to be a means to signal success and failure as a basis for reinforcement learning within the input modules. The input modules can be implemented using multi-layer artificial neural networks.
Deep learning algorithms learn to classify images after being presented with very large numbers of labelled images. However, the resulting classifiers are easily fooled with the addition of spatial noise that humans don't even notice. Moreover, humans can learn to classify images after seeing just a few examples. This makes it clear that human brains operate in very different ways compared to current deep learning systems.
More recent work has focused on explainability, e.g. Deep Learning for Interpretable Image Recognition which recognises different kinds of birds using an artificial neural network to identify features that vary from one species to another. However, this is still a long way from human abilities.
We are able to learn salient visual features that are invariant over time, and independent of the lighting conditions, spatial noise, presentation angle, and distance. Our ability to recognise entities, e.g. trees, cats and pandas, further involves learning hierarchical structures, e.g. many animals have a head, a body, fours legs and a tail. We can perform such recognition both spatially and temporally, e.g. to recognise a pattern of behaviour such as a running cat, and a cat that is about to jump on a mouse.
New approaches to perceptual processing are likely to involve evolutionary techniques that are applied to progressively richer environments to develop the means to identify such salient features and their statistical role in respect to higher level classifications of entities and behaviours. Some related research includes the work by Jeff Hawkins on hierarchical temporal memory, and the work by Helmut Linde on invariant representations.
This also relates to Baars' global workspace theory (GWT), which says that for sensory information to become conscious, three conditions must be met:
First, the information must be represented by networks of sensory neurons, such as those in the primary visual cortex at the rear of the brain, that process incoming visual signals. Second, this representation must last long enough to gain access to (“come to the attention of”) a second stage of processing, distributed across the brain's cortex, and especially involving the prefrontal cortex, which is believed to be a major center for associating multiple kinds of information. Third and finally, this combination of bottom-up information propagation and top-down amplification through attention must “ignite” to create a state of reverberating, coherent activity among many different brain centers. That, according to the model, is what we experience as consciousness.
From: Richard Robinson (2009) "Exploring the “Global Workspace” of Consciousness".
Delegated control for actions
Reaching out to grasp an object involves a complex coordinated activity in regards to perception and actuation. The intent for such an action is delegated to a separate system that runs in parallel to the cognitive rule engine. In the brain, this is implemented by the cerebellum, which can be likened to an air traffic controller interpreting data from the sensory cortex and sending control signals to the motor cortex to orchestrate a large array of muscles.
Conscious thought is needed for new tasks, but through repetition, the effort is considerably lessened as the task becomes a subconscious activity through procedural learning in the cerebellum, motor and sensory cortex. This can be emulated using reinforcement learning across a hierarchical arrangement of real-time control systems that execute concurrently. This will be explored in future demonstrators, using automata that generate smooth control signals as piecewise approximations to continuous functions.
The following diagram provides more details for the cortical circuitry for consciousness (on the left) and motor control (on the right). The cerebellum dynamically regulates movement using connections to the sensory systems, the spinal cord, and other parts of the brain.
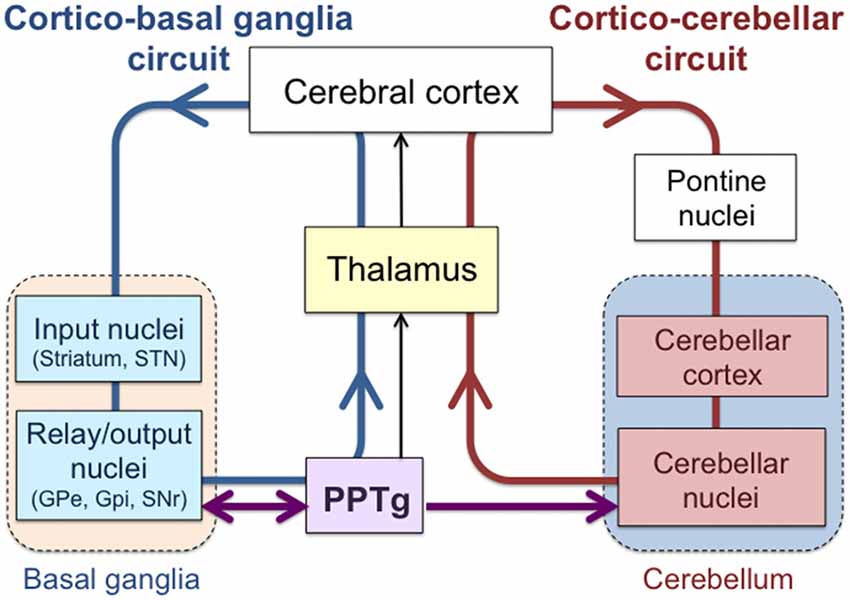
With thanks to Fumika Mori et al.
Machine learning
Machine learning of declarative knowledge can be done fully supervised, semisupervised or unsupervised. In the fully supervised approach a training set is marked up with the desired results, and the learning is evaluated against a test set. For unsupervised learning, the cognitive agent uses metrics to look for statistical regularities and learn for itself by building and assessing models. Semisupervised learning is a hybrid approach in which a human expert can guide the agent when it comes to what ideas it follows up. Prior knowledge is key to learning from a relatively small set of examples. There are many algorithms to take advantage of. Humans are especially good at paying particular attention when things aren't as expected, as a basis for continuous learning, see the later section on the brain as a prediction machine.
Reinforcement learning
Machine learning of rule sets is possible using heuristics to propose new rules, together with a means to adapt the perceived utility of rules based upon their performance at executing tasks. In reinforcement learning a reward or penalty is computed when a task either succeeds or fails. The reward/penalty is then propagated backwards in time along the chain of rules that were used to get to that point. The reward/penalty is discounted so that it has less effect the further back in time you get from the point when the task was found to have succeeded or failed. The reward/penalty could itself be related to the length of the rule chain, i.e. how long the task is expected to complete, as well as to the perceived importance of the task.
Rules could be used to determine when a task has successfully completed or when it has failed. In addition, the rule engine could decide to abandon tasks that were taking much longer than expected based upon past experience. One idea is for the rule engine to record the sequence of rule execution, and to perform the back propagation process along this sequence. It is unclear how the brain could support that in practice. Another idea just requires the rule engine to keep track of the last rule executed prior to the current rule. In this approach, the perceived utility of each rule is propagated to the immediately preceding rule. Task repetition will then ensure that reward/penalty eventually propagates back all the way to the first rule in the chain, yielding accurate estimates for rule utilities.
Work with ACT-R has identified some heuristics for proposing new rules, e.g. merging successive rules when practical. Further study is needed to better understand the process by which the heuristics are selected and applied. There is a potential analogy with evolutionary algorithms with mutation and swap operations on genetic code. Left to itself, this could require a vast number of task repetitions to achieve effective task performance. This can be speeded up by hierarchically decomposing tasks into sub-tasks, along with the means to apply reinforcement learning to estimate the utility of particular tasks, and to exploit previously learned tasks and strategies for task decomposition. This is sometimes referred to as hierarchical reinforcement learning.
This could be speeded up by learning from experience which approaches are more likely to work in a given context. That involves case based reasoning that looks for similarities and differences with other tasks. This process could be carried out by first creating a representation of the rules in declarative memory, and interpreting these and then modifying the representation as needed. The rules would be compiled to procedural memory as they stabilised, offering significant speed up in so doing. Alternatively, it may be simpler to allow for inspection and annotation of rules held in the rule module, using the mapping mechanism described earlier in this document.
The role of prior knowledge in speeding reinforcement learning has been investigated by Dubey et al., 2018 in respect to video games. They demonstrated that masking visual cues such as ladders, frowning faces and fire symbols caused a drastic degradation in human learning speed from around one minute to over twenty minutes as different kinds of priors were removed. By contrast the best performing machine learning algorithm took the equivalent of 37 hours of continuous play.
The rule engine identifies which rules match the current buffer states, and then picks the rule with the highest perceived utility. This process is stochastic, so that lower ranked rules will occasionally be picked over high ranking rules. This can be associated with a temperature parameter, where the higher the temperature, the more likely the rule engine will propose new rules or pick a lower ranked rule. When starting to learn a new task the temperature can be set high. The temperature is subsequently lowered when the task completes successfully, and raised when it doesn't. Over time this allows the system to explore the problem space and to find effective solutions. This requires a means to represent tasks as chunks, along with the temperature parameter.
Learning through imagining doing something can help when there is a significant risk or cost for doing it for real. This involves causal reasoning based upon prior knowledge and past experience. Imagining can be done in a context created for the purpose, see reasoning from multiple contexts. Imagination can help to avoid unfortunate outcomes, e.g. by choosing to move a glass away from the edge of a table in order to reduce the risk of it being accidentally knocked off, and smashing into myriad sharp fragments on the floor below, with the risk of someone being cut and the nuisance for having to clear it up.
One think to remark on is that in the brain, the basal ganglia have direct and indirect paths for outgoing connections to the cortex. One set is excitory and the other inhibitory. What insights does this provide for machine learning, and for queries for database modules?
Emotions and Social Interaction
Looking further out, a computational model of feelings and emotions may be appropriate to guide attention and decision making. This is also relevant to human computer collaboration, making the difference between being warm, caring and fun to work with versus cold and uncaring. This is where ideas developed in sociology are likely to be very relevant. At a higher level, involving reflective thinking, cognitive agents could be designed to apply ethical principles in compliance with future legislation, and held to higher standards than human citizens.
Our feelings and emotions are a function of the cortico-limbic system. Emotions play an important evolutionary role in respect to the survival of a species. At the most basic level, pain directs organisms to take immediate action to remove themselves from a cause of physical harm, e.g. burns from fire, damage from thorns or biting predators. Emotions are also at play in respect to fear of predators, interest in prey, courtship, mating and care of eggs and offspring. This can be seen as a computational process relating to the anticipated future reward or penalty for the outcome of particular behaviours, as well as to the observed difference between the expected and actual reward or penalty for a given behaviour.
Many species live in social groups, e.g. social insects such as ants, bees and termites, schooling fish, meerkats, wolves, elephants, apes and humans, to name just a few. Human social interaction is complex, and it can be argued that the evolutionary benefits of different behaviours is reflected in the wide range of emotions we can experience. Our ability to function effectively as members of a social group depends on our ability to construct workable models of other people and ourselves. We thus need to be proficient at interpreting other people's feelings as well as communicating our own. In addition, we frequently imitate what we see, smiling and laughing when people we are interacting with do so, which helps to strengthen social bonds.
Basic emotions are those that have a genetic basis for our survival. However, humans are distinct from other species in the sophistication of our languages, which have resulted in cultural evolution that takes place on a much shorter timescale than genetic evolution. Agriculture and industrialisation have enabled complex civilisation, and this in turn is likely to have enabled an expanded gamut of feelings due to the complexities of life as a member of a civilisation. It can be argued that entertainment in the form of books, plays and movies help us to think about a much richer range of situations than we are likely to experience for ourselves, and to thereby prepare ourselves for new eventualities when they arise.
There are disagreements as to how many distinct emotions there are, despite there being many words for feelings and emotions in the English language. Emotions are associated with a feeling and something they apply to. Valence describes whether feeling is positive, neutral or negative. Arousal describes whether feeling is calming or exciting. Moods are long lasting emotions that lack the cognitive element.
Primary emotions are directly triggered by particular situations and have direct benefits. Examples include: anger, sadness, fear, joy, interest, surprise, disgust, shame. Secondary emotions are triggered as a consequence of primary emotions, have weaker benefits and often have negative consequences, e.g. if you are angry with yourself, this can make it harder for others to help you. Secondary emotions are learned from our families, our culture and others. Examples include: anxiety, insecurity, low self esteem, hopelessness, depression, self-hatred, irritation, aggression and rage.
Emotions are triggered by perception, e.g. being frightened upon seeing a dangerous predator, by reasoning about situations, and by recall of emotive memories. Emotions have effects. Primary emotions may initiate instinctive behaviours, which are then subject to regulation through cognitive control. Emotions have a role in prioritising what you are thinking about and what feels important. Emotions further influence memory recall, laying down of new memories, reinforcement of existing memories and reinforcement learning of behaviours (rulesets). Feelings are fast and instinctive with rapid instinctive appraisal and response, avoiding the delay incurred with conscious thought, but subject to errors of judgement due to lack of thought. This points to a functional implementation as a feed-forward classification network.
An open question is how classifications are learned. One possibility is that classification errors are back propagated through a multi-layer network. This is unlikely to account for rapid single-shot learning in situations associated with a strong emotional response. That points to a more direct mechanism, e.g. to annotate cognitive models of things with emotional associations, and to process these via the limbic system. This would be applicable to dynamic models placed in the cortex by perception, as well as for the recall of memories by the cortico-basal ganglia circuit.
A further challenge is how new emotions are learned. As a young person, you may find yourself experiencing novel feelings of grief at some personal loss or jealousy in respect to some other person. Humans have a wide gamut of feelings. Perhaps these are learned in terms of underlying considerations for given situations, including valence, arousal, behavioural goals and motivations?
An effective theory needs to account for how a given feeling or emotion benefits the individual or others in a social group, what triggers this feeling or emotion, and how it is signalled to others. The theory must also include an account of how emotions influence thought and vice versa. Further work is needed to apply this to a range of emotions and to implement the models as demos. This is dependent on identifying scenarios that involves the chosen feeling or emotion without depending on large amounts of everyday knowledge.
Paul Ekman has worked extensively on how basic emotional attitudes are communicated through facial expressions: anger, sadness, fear, surprise, disgust, contempt, and happiness. An expanded list includes amusement, contentment, embarrassment, excitement, guilt, pride in achievement, relief, satisfaction, sensory pleasure, and shame. Emotional reactions that need to be executed rapidly, are appraised in an automatic, unreflective, unconscious or preconscious way. Emotions can also be subject to slow, deliberate and conscious thought processes.
Psychologists use the terms valence for whether an emotion is positive or negative, and arousal to describe degree of intensity, ranging from passive to active. Emotions can thus be considered to have an intensity and a direction. The details vary across theories, e.g. Russell's circumplex model versus Bradley et al's vector model.
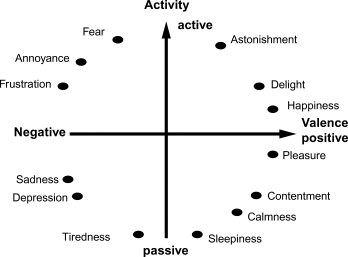
Russell's circumplex model of emotions
For a cognitive agent, we can choose which theory to apply, for instance, using a pair of numeric properties to represent the valence and arousal. Another choice, could be to use an enumerated property for the emotional attitude and a numeric value for the intensity. These correspond to the difference between cartesian and polar coordinates. These values can be adjusted by the execution of rules. Other rules are conditional on emotions, e.g. to direct behaviour and to resolve conflicting emotions. When reasoning about a choice between alternative courses of action, we need a way to compute their likely effects on the emotional state. This will be effected by past experience, and memories of previous events.
Feelings and emotions are a function of the Limbic System. The anterior cingulate cortex (ACC) has been shown to play a key role in how we appraise future reward or penalty, and how we resolve conflicting emotions, e.g. when we are torn between immediate self-interest and our desire to help those close to us.
Paul Gilbert proposes that we have three main kinds of emotion regulation systems. We managage our emotions by switching focus between threats, drives, and soothing behaviours. He claims that most psychological difficulties are caused by overuse of threats and drives, and an under-use of soothing.

Emotion regulation systems
Threats involve responding to actual and perceived threats. Drives are about goal directed behaviours and the perceived reward from accomplishments. Soothing is helpful, not harmful, care-giving/receiving, warmth, nurturing, supporting, forgiveness, encouragement, and attending to the needs of others as well as to your own needs, exploiting your emotional intelligence.
LeDoux and Brown describe a higher order theory of emotional consciousness in which sensory data is pre-processed at a non-conscious level into higher level representations that are then accessible to conscious awareness. This pre-processing system combines first-order representations of threats, along with relevant long-term memories, including emotion schema. This means that the brain's systems for storing and retrieving emotional and declarative memories operate in parallel, and are brought together under conscious control. The conscious awareness of emotions involves reference to self (including empathy for others as a reflection of self, by imagining yourself in their situation).
The rules that compute and act upon the emotional state can be regarded as heuristics for guiding appraisal and decision making. Such heuristics are fast compared to more extensive deliberative reasoning, but can lead to making what in hindsight were the wrong choices. This relates to Daniel Kahneman's ideas on System 1 vs System 2 in his book "Thinking fast and slow". He write: "System 1" is fast, instinctive and emotional; "System 2" is slower, more deliberative, and more logical. Most people tend to place too much confidence in human judgement (System 1).
When two people are talking with one another, gaze direction, facial expressions, head movements and hand gestures provide a complementary non-verbal communication channel, signaling overt or covert emotional state and attention. What would be needed for cognitive agents support non-verbal communication? This calls for rapid evaluation and generation. The intents include emphasis on particular parts of an utterance, and an emotional overlay that reinforces what is being said. Non-verbal communication is also used when you are listening to someone, e.g. to signal your interest, your emotional response, and to signal your acknowledgement of specific points. For both speaker and listener, this involves reasoning about the emotional implications and goals of the utterance.
This level of sophistication will need to build upon progress with earlier work on demonstrating how emotions can serve as a heuristic means to direct behaviour. Similarly, work on exploring humour as part of human-machine collaboration will need to build upon progress in dealing with non-verbal communication.
A lot has been written about consciousness and whether it will ever be possible to build conscious machines. For this work, a simpler position is taken which enables cognitive agents to be aware of themselves and others, and have access to an autobiographical record of their experience, goals and performance, through workable models of episodic memory. This further involves the means for cognitive agents to pause to reflect on their performance and goals. This relates to task management and attention as described in an earlier section, and can be likened to an operating system that manages the use of the central processing unit by a large set of running programs.
- See also Michael Graziano's attention schema theory of consciousness as resulting from our models of the attentional states of others as well as that of ourselves
The above implies the need for a parallel system for pre-processing sensory data in combination with access to long term memory, prior to being made available to the buffers belonging to the main rule engine. Subsequent emotional appraisal is integrated into the main loop for rule execution. The pre-processing system could rapidly transform stimuli to higher order representations, e.g. using some form of discrimination network. The cues and their interpretation in the current context require sophisticated models of social interaction. What kinds of use cases and datasets are needed to explore this?
Natural language processing
Natural language processing is needed to take a sequence of words and translate them into a network of chunks, and vice versa for natural language generation. This is a statistical process that needs to take the current context into account. The lexicon describes knowledge about words and their meanings. An approach inspired by how we hear, is to preprocess the text to ignore case and punctuation, and identify words or word compounds in the lexicon. The next step is to identify the likely part of speech for each word, as a basis for forming a dependency tree.
Words often have multiple meanings, and a spreading activation model can be used to account for priming effects in picking the most likely meaning in the current context. English verbs have patterns of slots which can be filled by the subject, object and prepositional phrases. This process of attachment also needs to take the semantic context into account. A further challenge is the binding of references from nouns and pronouns. These processes make use of graph algorithms for short and long term memory, in conjunction with rule based reasoning.
Individual natural language utterances take place in the context of a dialogue which itself is part of an social interaction model. The literal meaning needs to be supplemented by an emotional understanding, and this is guided by non-verbal communication that takes place concurrently. Natural language usage patterns evolve with practice and through listening to others. This has implications for how the lexicon and related knowledge is updated during natural language dialogues.
Natural language involves a great deal of everyday knowledge and so called common sense skills. This will depend on being able to teach and assess these skills through a series of lessons, starting with a core framework of built-in declarative and procedural knowledge that needs to be developed manually. There are plenty of opportunities for cognitive agents where natural language interaction is limited to a controlled subset of language. Richer use of language can come later and build upon experience gained with simpler systems.
This approach can contrasted with that of Marjorie McShane and Sergei Nirenburg who have defined a ontologically-grounded knowledge representation language (OntoAgent KRL), with around 9000 concepts in the ontology. This will be more expensive to develop and maintain compared to an approach based upon incremental language acquisition through natural language lessons and dialogue. Cognitive agents should be able to learn for themselves rather than relying on manual programming. This poses practical challenges for how to guess the meaning from the context, including neighbouring words and the current focus of conversation, along with compiling statistics on different meanings.
A good starting point will be to implement support for natural language dialogues for common scenarios such as ordering a meal at a restaurant. This has the advantage of well understood semantics and easily extendible dialogues to cope with variations. This will provide a check on the architectural components for language processing, paving the way for using language for machine learning experiments.
A challenge for future work will be to address the role of metaphor and idiom in understanding beyond the literal interpretation of an utterance. This is explored by Lakoff and Johnson in Metaphors we live by, see the review by Norvig, Carbonell's Metaphor: An Inescapable Phenomenon in Natural Language Comprehension, and Barden's Metaphor and artificial intelligence, why they matter to each other.
The brain as a prediction machine
The brain is essentially a prediction machine that is continuously trying to predict incoming information based on past experiences. The discrepancy between the predictions made by the brain and the actual sensory input is a source of surprise — Shahram Heshmat
This “surprise” raises our interest and makes us concentrate on new experiences and try to understand new patterns and integrate them with what we already know. This points to the role of algorithms used to recognise and learn patterns, as well as to how we can design cognitive agents that are able to learn continuously as part of their everyday experience. This applies broadly to many aspects, e.g. new words and forms of expression, unexpected behaviours of people and things, our understanding of music and more. Learning is also intertwined with our emotional experiences.
Different ways of learning
It is impractical to manually program cognitive agents with a broad range of everyday skills. We therefore need to explore ways for agents to be taught or learn for themselves. For this we can seek inspiration from how humans learn as infants, e.g. through observation, through direct manipulation, playing games and asking questions. What can we learn from studies of language acquisition and cognitive development milestones in infants? A related paper is Machine Common Sense by David Gunning (DARPA), which summarises some of the technical background, research ideas, and possible development strategies for achieving machine common sense.
One approach to exploring learning is to immerse cognitive agents in virtual worlds in which they can interact with other cognitive agents as well as with humans. Creating such virtual worlds will be a lot easier and safer than creating robots that interact in the real world. Such simulated environments don't need to involve full 3D virtual reality, and instead could be limited to text or speech based interactions, with human volunteers logging in via their browser to spend time with the developing agents.
Cognitive Databases
The architecture for chunk rules involves memory modules that act as cognitive databases, and which are accessed using a request/response pattern analogous to the way that Web pages are retrieved with HTTP. Cognitive databases have the potential to store vast amounts of information, similar to the human cortex. The analogy with Web architecture is further strengthened by the way that information is recalled based upon which chunks are likely to be the most valuable given prior knowledge and past experience. This can be likened to Web search engines which seek to provide the results most relevant to a particular user. There is no intent, and no point, in providing the complete set of matches, given huge scale of the Web.
Cognitive databases could support a variety of graph algorithms to support a range of cognitive tasks, e.g.
- Retrieval of a single chunk with a given chunk identifier
- Simple queries for chunks with matching types and properties
- Queries for sub-graphs matching patterns, similar to SPARQL
- Queries for sub-graphs based upon graph traversal automata
- Spreading activation models for word sense disambiguation
- Queries based upon structural similarities for analogical reasoning
- Covariance analysis for statistical significance across a dataset
- Other algorithms for data mining across big data
There can be a many to many relationship between cognitive agents and cognitive databases. This allows a single cognitive database to be shared with many cognitive agents via encrypted protocols such as HTTPS and Web Sockets Secure (WSS). Some information would be accessible by all agents, whilst other information would be restricted to a single agent or group of agents. This is made possible through the use of chunk contexts, see the earlier section on reasoning from multiple contexts.
The initial implementations are designed to work within Web pages for ease of demonstration. These demos fetch the database from the Web server hosting the Web page. Larger demos will require implementations that can scale to much larger databases, e.g. Gigabytes rather than Megabytes. This could be addressed through memory mapped files managed through a Web server. For even larger databases, it will become necessary to use a federated approach across server farms, with the means to run graph algorithms in a distributed way, and then gather the results back to respond to a given query. Redundancy will be needed to cope with the inevitable component failures to be expected in any sufficiently large system.
Further work is needed to consider how to scale rule databases, which need tighter integration with cognitive agents to provide the indexing speed needed for fast rule execution. In principle, machine learning across many cognitive agents could be pooled to accelerate learning. Another perspective would be provided by enabling open markets of declarative and procedural knowledge for specific application areas. As with today's software packages, licenses would be needed to describe the terms and conditions of use. Clients would benefit from regular updates.
Integration with RDF
To relate chunks to RDF, you should use @rdfmap. For instance:
@rdfmap {
dog http://example.com/ns/dog
cat http://example.com/ns/cat
}
You can use @base to set a default URI for names that are not explicitly declared in an @rdfmap
@rdfmap {
@base http://example.org/ns/
dog http://example.com/ns/dog
cat http://example.com/ns/cat
}
which will map mouse to http://example.org/ns/mouse.
You can likewise use @prefix for defining URI prefixes, e.g.
@prefix p1 {
ex: http://example.com/ns/
}
@rdfmap {
@prefix p1
dog ex:dog
cat ex:cat
}
It may be more convenient to refer to a collection of @rdfmap and @prefix mappings rather than inlining them, e.g.
@rdfmap from http://example.org/mappings
If there are multiple conflicting definitions, the most recent will override earlier ones.
Note: people familiar with JSON-LD would probably suggest using @context instead of @rdfmap, however, that would be confusing given that we want to use the term context in respect to reasoning in multiple contexts.
Further work is needed to consider use cases where integration with existing RDF based systems is important. It is likely that this will also involve work on context sensitive mapping of data between different vocabularies. It is anticipated that such mappings could be learned from a curated set of examples, by analogy with modern statistical approaches to machine translation of human languages.
Demonstrators for Chunk Rules
Here are some demos as proof of concept:
- Counting from 3 to 5 with support for single step execution.
Demo that models how people count by remembering which number comes next. This demo uses a mix of facts and rules.
- Simple decision trees
Demo for how rules can be used to decide whether to play golf. This demo just uses rules.
- Smart manufacturing
Demo where a cognitive agent controls factory machinery including a robot, conveyor belts, and filling and capping stations. This demo illustrates how rules support concurrent asynchronous control via message passing, along with delegation of actions to an emulation of the cortico-cerebellar circuit for real-time control of the robot arm and associated sound effects.
- Smart home
Demo of a smart home with two occupants: Janet and John who have different preferences for the lighting hue and room temperature. The demo incorporates a dynamic model of heat flows, and allows you to change who is present along with the time of day. The rules implement default reasoning that uses the facts to work out what control settings to use for a given combination of occupants and the time of day.
- Autonomous driving (under construction)
This demo uses the street map of the town of Frome, Somerset, UK, using data exported from Open Street Maps and converted from XML into chunks. There are modules for vision, car, map and rules. The demo shows a car moving along a route determined using the A* algorithm. The car brakes and signals when approaching a turn, then accelerates away. The map is rendered to an HTML Canvas2D using quad tree indexing based on the Cohen Sutherland algorithm for the intersection of lines and rectangles. Most people know how to drive and are thus familiar with the cognitive tasks involved.
- Test suite
This is a test suite for the chunks format covering major features. I plan to extend it to provide greater coverage over time.
- Natural Language Understanding
- Towers of Hanoi is a simple demo in which you can type or say commands to move discs between pegs. This was chosen to explore basic concepts for combining natural language parsing with cognition. Further demos will address a larger vocabulary, an expanded grammar, and how statistics, dialogue history and semantic context can contribute to resolving ambiguity.
- Natural Language Dialogues (early design stage)
This demo will feature typical dialogues between guests and a waiter at a restaurant (see examples). This involves agents that represent the waiter and two guests, Sarah and Joan, who are having dinner together. The output shows who is talking to whom, and what they said. I imagine a general plan with sub-plans for different aspects e.g. picking a table, drinks, starter and main course, dealing with preferences and temporal sequences, confirming choices, and adapting when the restaurant running out of specific items.
A second idea is to use natural language to communicate with a cognitive agent that controls a robot in a blocks world, e.g. “Put the yellow disc on the green triangle. Move the green triangle next to the red square. Where is the yellow disc?”. This is a more restricted environment and would be simpler as an initial demo.
These two demos features natural language for input and output, using a lexicon and models for how words map to graphs for the semantic representation, and algorithms such as spreading activation for word sense disambiguation. The predictable dialogue and the well understood meaning makes this a practical scenario to explore natural language processing in relation to situational plans.
The demo could provide a basis for future work on social and emotional reasoning as several agents interact with each other. Non-verbal gestures could be expressed as textual annotations to the dialogue, e.g. smiling, acknowledging, questioning, surprise, etc. that are conveyed separately from the concurrent verbal exchange.
It also will feed into future work on using natural language as the basis for teaching cognitive agents everyday skills, i.e. common sense. This will further involve learning algorithms and imagination using graph contexts for learning situations.
- Learning Knowledge Graphs (early design stage)
This involves learning classifications and relationships from a sequence of examples. This could involve full, weak or no supervision, as well as noisy data. In the absence of supervision, there needs to be metrics for good models that provide effective "explanations" of the data set. I have yet to identify suitable scenarios and data sets.
- Learning Rule Sets (early design stage)
This involves the use of heuristics to propose rules and reinforcement learning to select good rules from bad rules along with the use of stochastic temperatures. I have yet to identify suitable scenarios and data sets. A future demo could take this further by learning from imagining situations and applying rules to them. Other work could look at ideas for selecting appropriate heuristics using case based reasoning.
Further demos will feature different kinds of reasoning, including causal reasoning and reasoning from multiple perspectives, and a demo exploring social interaction, emotions and the theory of mind. Suggestions of use cases are welcomed. If you are interested in collaborating on any of these, please get in touch, as your help will be much appreciated.
The human mind is amazing, and as we understand it better, and learn how to replicate its capabilities, and go even further, strong AI has the potential change everything, paving the way to a sustainable high-level post fossil fuel civilisation, then reaching out first to the planets, and later to the stars! (mood music). This optimism is based on the assumption that we can use the increased productivity to redeploy and pay for people to do socially valuable work, which today is under staffed and under paid. Space travel is harsh, and strong AI will enable exploration and development at lower cost and without the risks of sending people. We can send replicas of our minds without our fragile bodies.
Dave Raggett <dsr@w3.org>
 This work is supported by the European Union's Horizon 2020 research and innovation programme under grant agreement No 780732, project Boost 4.0
This work is supported by the European Union's Horizon 2020 research and innovation programme under grant agreement No 780732, project Boost 4.0