Internationalization
Richard Ishida
Hello, I'd like to talk to you about the internationalization work which we've been doing recently at the W3C.
About i18n @ W3C
- Internationalization (i18n) WG key areas of activity include:
- Requirements (including Language Enablement) (users)
- Reviews & support (developers)
- Education & outreach (content authors & developers)
- Core work is supported by member funding, but additional resources are made available through the Internationalization Sponsorship program.
- Sponsored by Alibaba, APL, Apple, Monotype, Paciello Group
- Pleased to see renewals from APL, Apple (the rest are TBD)
On slide two, you can see that we grouped the work of the Internationalization Activity into three main bucket areas.
One is requirements work, which sets out to establish what needs to be done to make the Web world-ready.
One aspect of that is what we'll describe in this talk as language enablement.
The key stakeholders here are end users of the Web.
Another area of work is reviewing specifications and providing advice to developers.
And the third bucket is education and outreach.
Content authors and developers are the key stakeholders here.
The core work is supported by member funding, but additional resources are made available through the Internationalization Sponsorship Program.
We've been running that program for two years now thanks to sponsorship from Alibaba, the Advanced Publishing Lab in Japan, Apple, Monotype, and the Paciello Group, and we'd like to say a big thank you to them for their support.
The initial phase will end in the middle of this year and we are hoping we'll be able to extend the program beyond that date.
We already have received an intent to renew sponsorship from APL and Apple, and we're extremely grateful for that.
However, we need to find additional funders.
Talk outline
This talk will focus on work that has been facilitated by the Internationalization Sponsorship Program, particularly in the area of Language Enablement.
- review the language enablement framework we developed
- report progress against sponsorship program goals
- introduce the Language Enablement Index
- describe recent developments in Language Enablement tooling
Slide three gives an overview of what I plan to cover during this talk.
Time is short, so I'll focus in on the work that we've been able to do under the umbrella of the Internationalization Sponsorship Program and particularly in the area of language enablement.
Language enablement means ensuring that users around the world are able to use the Web in their own language.
We'll start by reviewing the framework we developed to support the language enablement work.
We'll also report progress against the sponsorship program goals.
Then I'll include two additional sections that are likely to be of more interest to developers.
I'll introduce the Language Enablement Index and describe the recent developments in language enablement tooling.
Language Enablement framework
So let's go to slide four and begin a quick overview of the language enablement framework that we put in place.
The framework is a set of tools and procedures we developed that are common to all of the groups who we currently have working on language enablement.
This enables us to centralize information and efficiently create new groups and get them up and running.
Language matrix
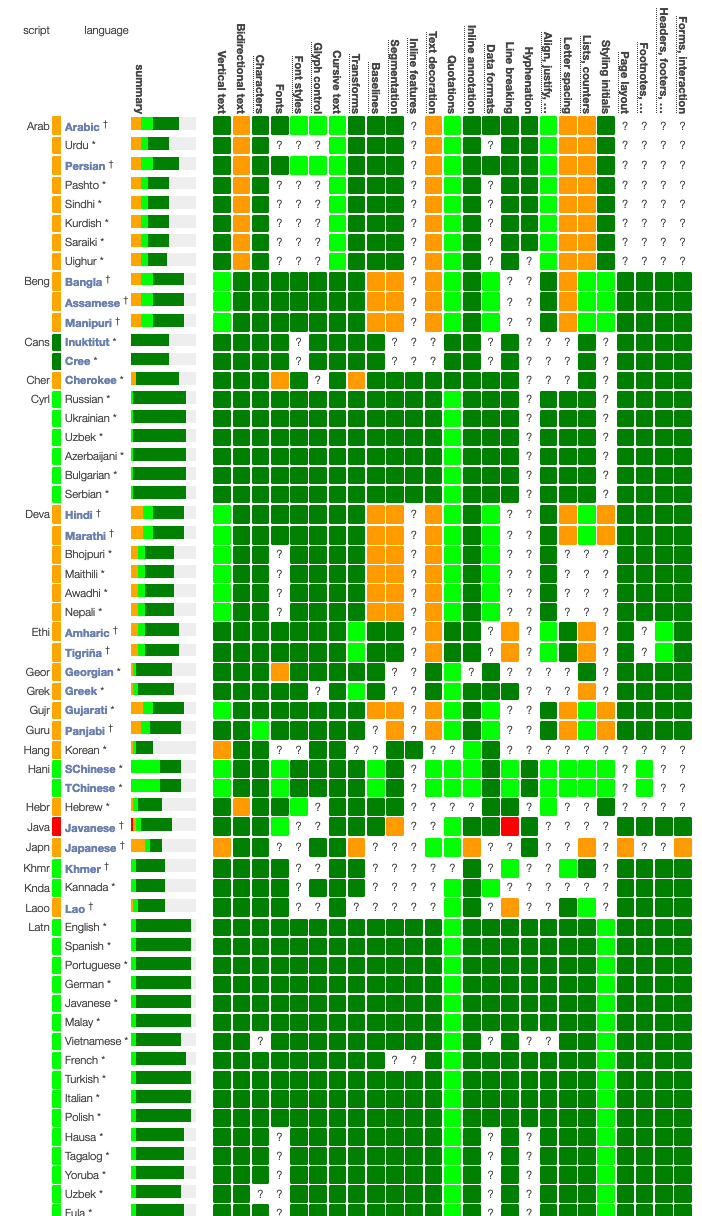
- Prioritised status for language/feature pairs.
- Cells link to gap-analysis doc sections.
On slide five, we see some pictures of the Language Matrix.
Note by the way that the images on the following slides are there to help you visualize what I'm talking about.
You don't need to read the detail if you're in a hurry.
The Language Matrix brings together all of the work that we're doing in the form of a heat map.
A set of languages appear down the left side, ordered by script, and across the top are a set of features that need to be supported if users around the world are going to successfully use their own language on the Web.
The intersection of the language row and the feature column is a coloured box that indicates (1) whether we have an issue to address, and (2) what is the severity of that issue if there is one.
So if a cell is coloured dark green we don't know of any issues, we think we're okay.
If the cell is coloured light green we believe that there are some barriers to use of the Web, though they tend to be particularly related to advanced features.
Orange squares, on the other hand, highlight basic issues that we believe users will come across regularly as they try to use the Web in their language, on an everyday basis.
If you click on any of the coloured squares it'll take you to the relevant section of a gap analysis document.
Gap analysis

- Describe & prioritise issues.
- Supported by tests.

You can see an example of part of the gap analysis document on slide six.
And in these documents we (1) describe the problem, (2) describe the current level of support in specifications and browsers, and (3) we attempt to indicate the severity of the problem for the user.
While you're doing gap analysis work, it's important to be able to quickly and easily create tests to explore and monitor what works and what doesn't.
I'll talk later about some recent innovations there that help.
Documenting requirements

- Supports the gap-analysis work.
- Provides guidance for developers.

Slide seven talks about documenting requirements.
As we document gaps, it's important to clarify what we expect to happen in an ideal situation.
So, for each of the gap analysis documents, we've tried to create a requirements document that explains how a script or a language works, at least for the gaps that we're pointing out.
Networking
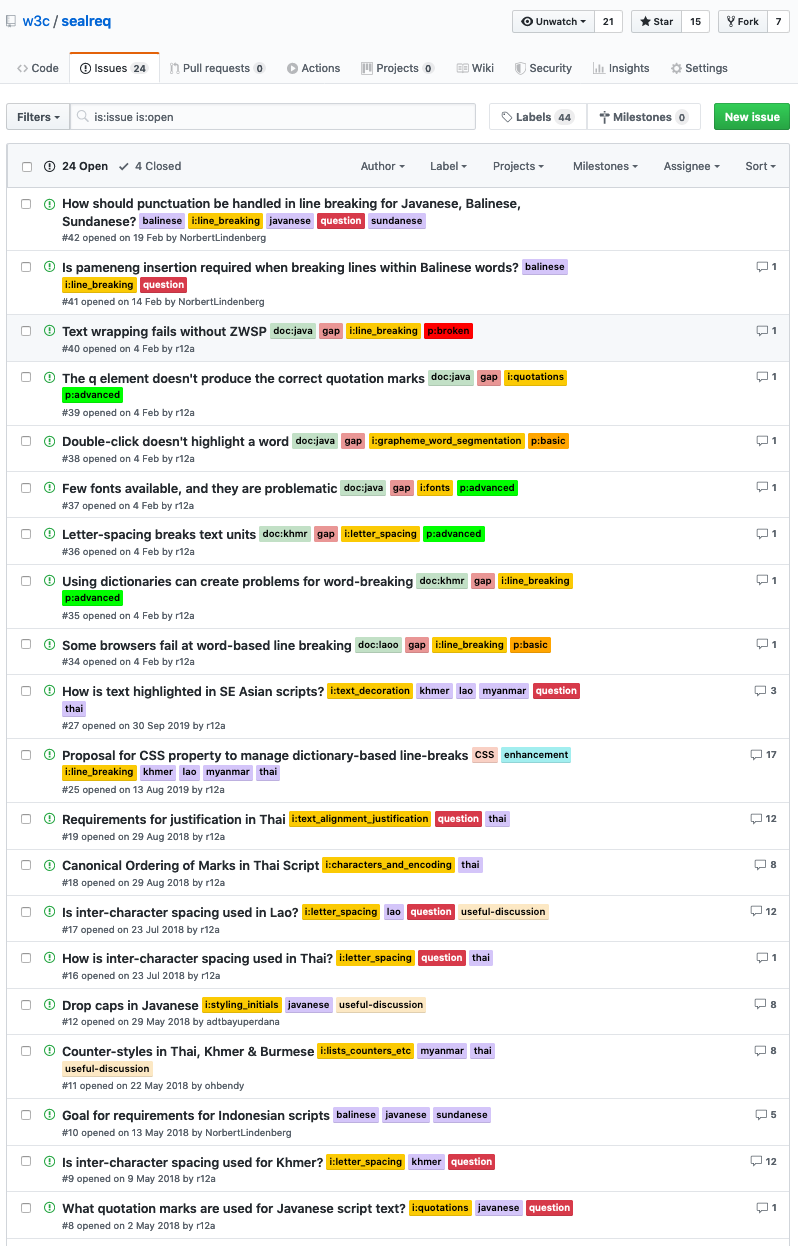
- Expert networks collaborate via GitHub issues.
- Daily digest notifications include related WG issues.
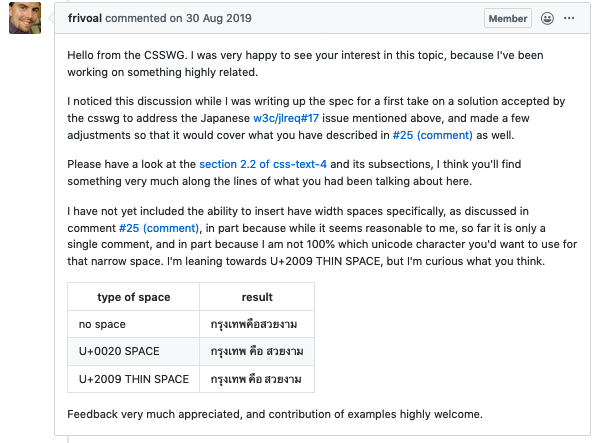
Slide eight is about networking.
An important aspect of the language enablement work is to allow experts around the world to collaborate and follow what's going on, and the framework we used needs to facilitate that communication.
So we use GitHub issues for our technical discussions, just like other working groups at the W3C, but we also pioneered the daily digest mechanism that informs the experts about developments related to their language of interest – not only in the GitHub issues of their own group, but also capturing issues raised by other working groups, such as CSS, HTML, TTML, SVG, et cetera, that have a bearing on their language, so that they remain informed about those developments too.
Implementer support
- Bugs raised against specs & implementations.
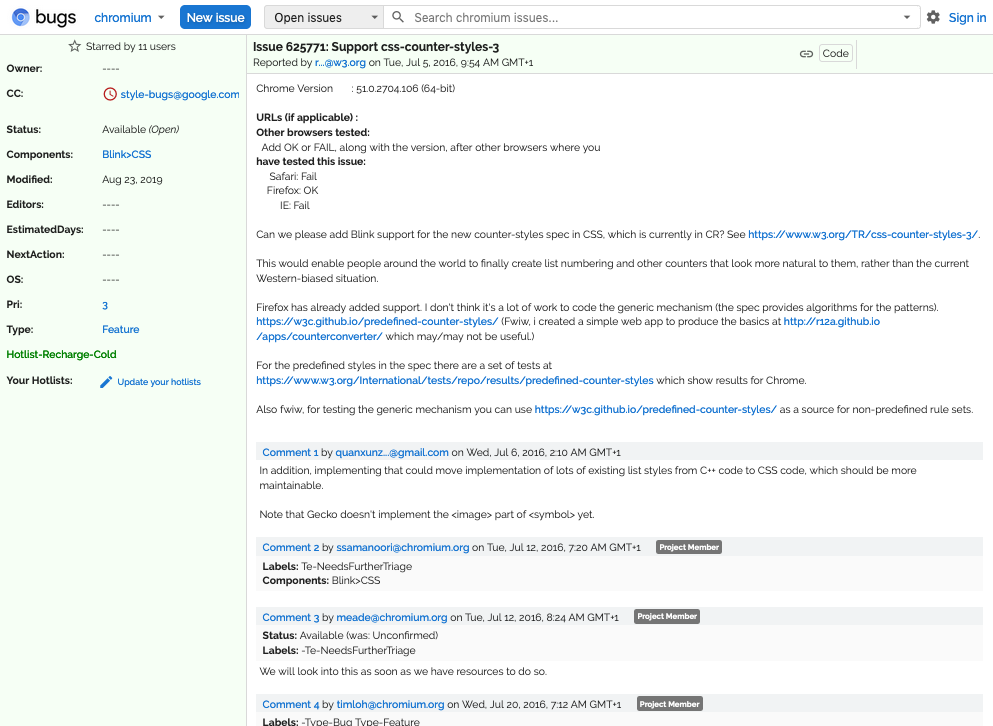
Moving to slide nine, the end goal of all this activity is of course to submit requests to spec developers and implementers where changes are needed.
So we've begun that process, although the larger focus so far has been on gathering information and establishing patterns.
But in the next phase we expect to increase the emphasis on this aspect and we have actually begun already.
Slide 10 summarizes the aspects of the framework that we just touched upon.
So now let's take a look at the achievements of the Internationalization Initiative during its first phase.
And there are five main goals that we set ourselves at the beginning.
i18n sponsorship program achievements
If we look at slide 12, we see the first of those, which is to widen participation of expert networks in language enablement groups and by extension in W3C work.
So there are still many places around the world where the W3C has not penetrated very far and those places often correspond quite closely with languages and scripts that are very different from English.
So a key objective of this exercise, is to reach out to people in these areas, make them aware of the work that we're doing at the W3C, and get them involved in improving the Web locally by participating in the groups that we set up.
Goals & results
- Widen participation of expert networks in LE groups, and by extension in W3C work
- Networks running for Arabic & Persian, Chinese, Ethiopic, Indic languages, Japanese, Mongolian, and SE Asian languages
- Initial group setup for African languages, European languages, Hebrew, and Tibetan.
- 103 expert contributors signed up to groups
- 259 subscriptions to notification lists, following the work
- 91 issues raised that put questions to the language experts
- 74 WG issues (eg. CSS/SVG/TTML/HTML/etc) brought to the attention of the experts
- 639 issues raised by LE groups in their work
Figures as of beginning of April 2020
Slide 12 shows some statistics around what we've achieved so far.
We have active networks running for Arabic and Persian, Chinese (Simplified and Traditional), for Ethiopic languages, for Indic languages, for Japanese, Mongolian and several Southeast Asian languages.
These are all separate groups dedicated to particular languages or regions but using the same framework.
We are currently in the process of establishing two more groups, one for African languages and another for European languages.
They're still in the early stages of setup and we welcome interest from potential participants.
In addition, we have two more groups, Hebrew and Tibetan, which we started a little while ago but where we need additional experts to drive that work forward.
So, in total we have 103 experts signed up to these groups as contributors.
That's 103 sign-ups.
These are people that we rely on to move the work forward and provide content and expertise.
We have 259 subscriptions to our notification lists.
So, this brings in around 150 additional people who are following the work and may sometimes participate in discussions.
It may help to measure the work done by looking at the issues raised in GitHub.
91 issues were raised that put questions to the language experts.
These are things that working groups at the W3C need to understand about how languages work.
And so their questions get passed on to the local experts.
In addition, we brought to the attention of these experts 74 issues that the W3C working groups had raised during their work, but which have a bearing on their particular language or writing system.
So overall, the language enablement groups have raised 639 GitHub issues while doing the work in this first phase, which is quite a good number.
Goals & results
- Increase scope and documented output of language enablement work.
- 14 gap-analysis docs in development:
Arabic & Persian, Chinese (Simplified & Traditional), Ethiopic (Amharic & Tigrinya), Devanagari (Hindi/Marathi), Bengali (Bangla & Assamese), Gurmukhi (Punjabi), Tamil, Gujarati, Japanese, Mongolian, Javanese, Khmer, Lao, Thai
- 6 additional provisional gap-analysis docs:
Cree & Inuktitut, Cherokee, Dutch, Georgian, Greek, Hungarian
- Japanese Layout Requirements (JLREQ) updated
- Simple ruby published as WG Note
- 15 issues tracking bugs raised for (typically multiple) browser implementers
- 9+ threads identified as useful resources in their own right
Figures as of beginning of April 2020
Slide 13 brings us to our second goal: to increase the scope and documented output related to language enablement work.
Let's run through a few more statistics give you an idea of what's been happening.
So, we have 14 gap analysis documents currently in active development. One for Arabic and Persian, another for Simplified and Traditional Chinese.
Another for Ethiopic, which covers the Amharic and Tigrinya languages.
Devanagari, which is Hindi and Marathi, Bengali (Bangla and Assamese), Gurmukhi, which covers the Punjabi language, Tamil, Gujarati, Japanese, Mongolian, Javanese in the Javanese script, Khmer, Lao, and Thai. And we have requirements documents backing up most of those documents too.
There are six additional gap analysis documents which we term 'provisional' and which have generally been submitted by an individual but have not been worked on by a group of experts.
They cover Cree and Inuktitut, Cherokee, Dutch, Georgian, Greek, and Hungarian.
In addition, the Japanese layout task force was re-activated during this phase and has been quite busy, not only producing an editorial update to the famous Japanese Layout Requirements document but also considering plans for new versions of that document.
By the time you read this presentation, they should have also published a shorter document called Simple Ruby as a Working Group Note which aims to establish a baseline for Ruby support on the Web.
I mentioned earlier that we raised 15 bugs, typically for multiple browser implementers, and we've also begun identifying GitHub issue threads that can be regarded as useful resources in their own right.
We've so far identified around nine of those, which give many useful details and examples related to a particular language or script.
Goals & results
- Skill building/succession planning
Atsushi Shimono (Keio) and Fuqiao Xue (Beihang) have broadened our ability to do core support and language enablement work, and spread W3C institutional knowledge for i18n.
- Significantly improve guidelines and self-review checklists for developers
I18n review checklist updated & new self-review checklist developed. Significant advances included publication of Character Model for the World Wide Web: String Matching and Strings on the Web: Language and Direction Metadata
- Investigate ways to extend the i18n test framework, including to support tests and results for paged media generators
Exploratory test framework developed with GitHub-based interface (details later in this talk). Many tests migrated to WPT repo. Paged media test formats still TBD..
Slide 14 lists the remaining goals.
The first is to address skill building and succession planning for internationalization.
And I'm happy to say that the program funding has allowed us to augment the staff resources dedicated to internationalization.
Atsushi Shimono from Keio and Fuqiao Xue from Beihang broadened our ability to do core support as well as adding additional support for language enablement work.
This also helps us to spread the institutional knowledge about internationalization through the W3C staff, much more effectively.
The fourth goal was to significantly improve guidelines and self-review checklists with developers.
The additional resources that I just mentioned helped us find more time for these core activities.
Not only were we able to improve the detailed I18n Review Checklist, but we also developed a new self-review checklist that W3C working groups can use to identify areas of their work that are potentially affected by internationalization considerations.
Significant advances also included the publication of the Character Model for the Worldwide Web: String Matching, and another document on strings for the Web and metadata related to language and direction.
Goal five was related to tests.
Earlier this year, we developed a new framework for exploratory testing, which I'll describe in more detail later.
This'll be a significant help for those doing gap analysis work, but it's also proving useful for other internationalization work too.
We also migrated a large number of tests from the i18n test suite to the Web Platform Tests repository.
Testing paged media, however, requires a different approach to the tests we've done so far, and we don't have a solution for this yet, but other groups around the W3C are beginning to look at this also and we look forward to collaborating with them on this.

SUMMARY
- Internationalization Sponsorship Program was successful in enabling additional work within and beyond the core.
- The Language Enablement initiative was also very successful in expanding the reach of the W3C into new areas around the globe.
- Overall progress • Latest update
- Initial phase is nearing completion, but much more remains to be done to ensure that people all around the world can interact with the Web in their own language and script.
- Please help us find more experts to extend our networks.
- Please contact Jeff Jaffe if your organisation can step up as a sponsor for the next round.
So in summary, on slide 15, the Internationalization Sponsorship Program was, in my opinion, successful in enabling additional work within and beyond the core.
The language enablement initiative was also very successful in expanding the reach of the W3C into new areas around the globe and bringing those people within the circle of the W3C.
So the initial phase is nearing completion, but much more obviously remains to be done to ensure that people all around the world can interact with the Web in their own language or writing system.
We therefore would like to ask you to please help us.
First of all, to find more experts to extend our networks, particularly in-country people who are motivated to make the Web work better for their language or script.
But also please contact Jeff Jaffe, if your organization can step up as a sponsor for the next round.
We need additional sponsors and this is the time when we need to hear from people.
So there are two more sections to this presentation, which I think are probably more of interest, as I said before, to technical people.
Language Enablement Index
I'm going to talk about the Language Enablement Index and I'm going to talk about some additional innovations that we've made recently with regard to the Language Enablement Framework.
Language Enablement Index

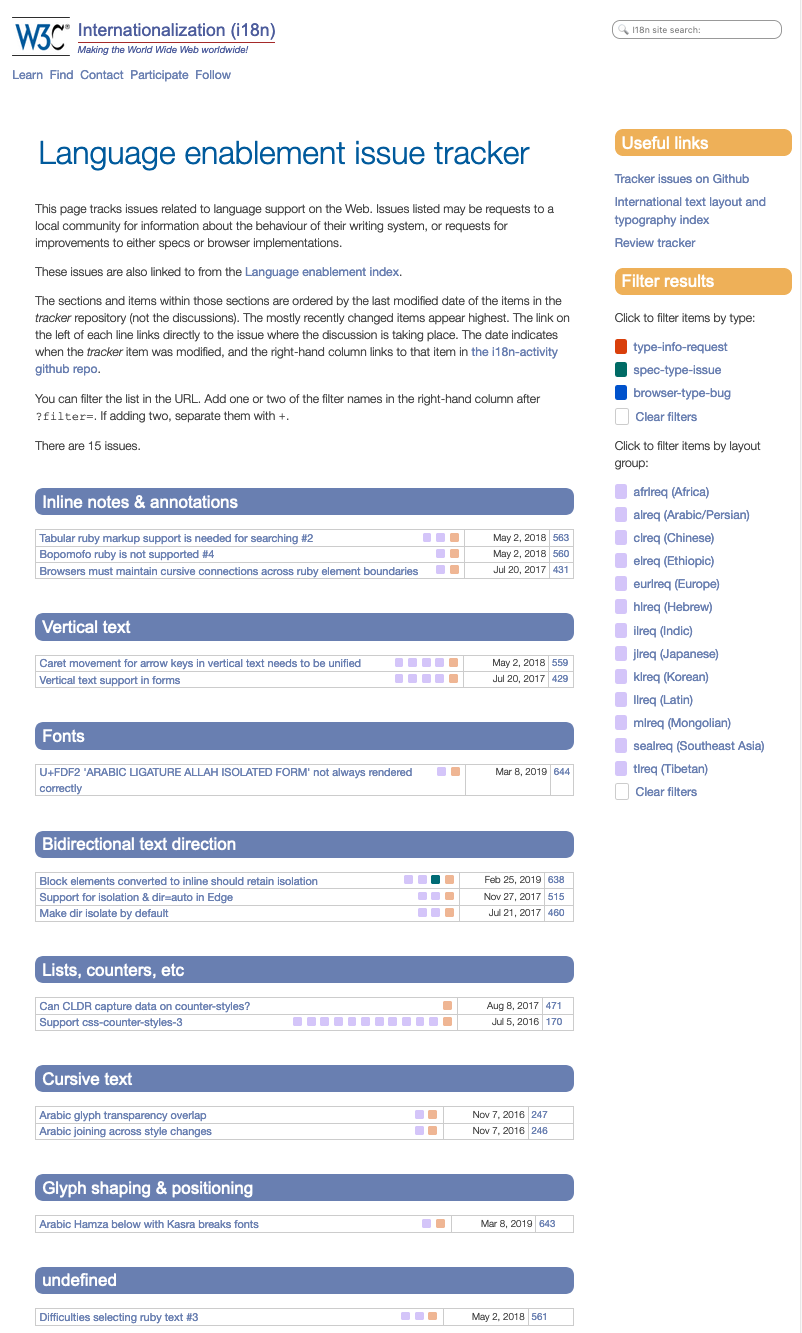
A place to find all the information we have been gathering.
Section headings harmonised across all LE framework deliverables.
The following examples are from the first subsection in the document: Vertical text.
So, on slide 17 we start talking about the Language Enablement Index.
Well, basically, this is a document on the Web which allows you to find all the useful information that we've been gathering so far in terms of requirements, and so on, and so forth.
I'll show you some examples of the kinds of things that you can find there.
And, it's broken into a number of sections and the section headings are harmonized as a way of categorizing features that we're interested in — harmonized across all of the Language Enablement Framework deliverables: so gap analysis, testing you name it, the Language Matrix as well, they use similar sections to this document.
So I'll take you through just very briefly to give you a flavor of what this document has, showing you a few examples.
The examples I will show are all taken from the first subsection in the document, which relates to vertical text.
Language Enablement Index
Links to requirements & specs

So, slide 18: you can see that the section on vertical text contains links to requirements and specifications that are relevant to that particular topic.
Language Enablement Index
Requests for information
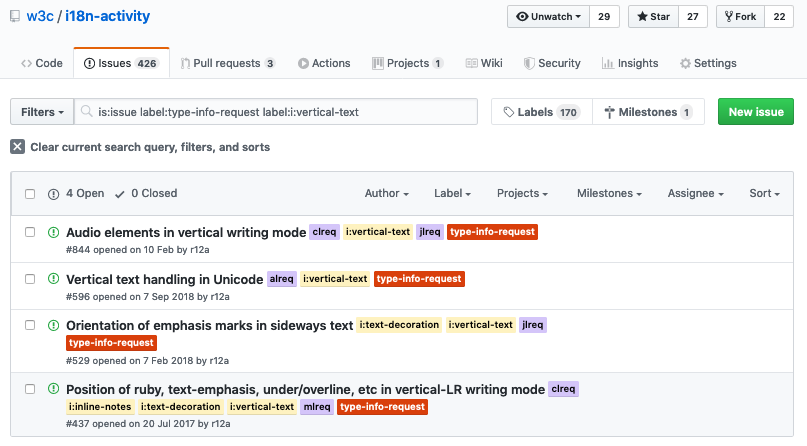
And on slide 19, we look at the result of clicking on one of the GitHub resources links.
This one is the link for requests for information and what you're seeing there is all the requests that we have out at the moment, still unanswered, related to vertical text.
So that's quite useful, if you are working on vertical texts and you want to see what questions are out there to be answered, then you can just click on that link and get there.
Language Enablement Index
Related issues in W3C WG specs
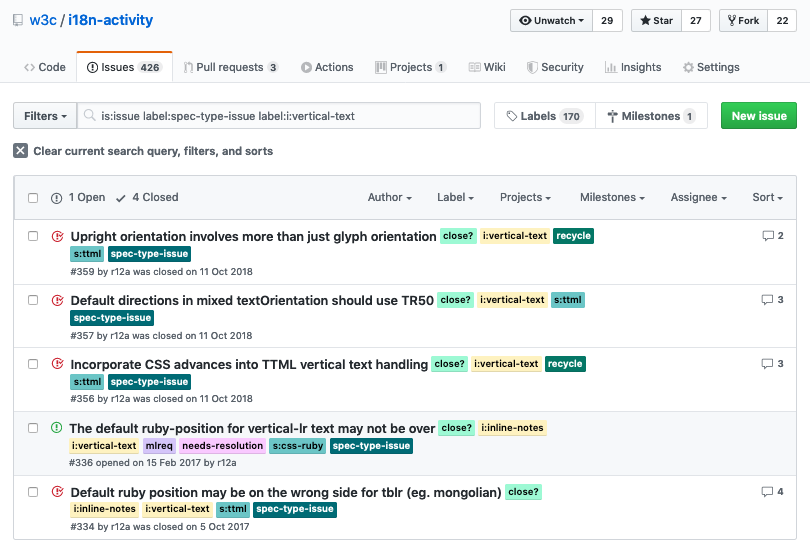
Similarly, we have another link which takes you to a set of related issues that have arisen while people were working on W3C working group specifications, and that's on slide 20.
Language Enablement Index
Implementation bugs raised
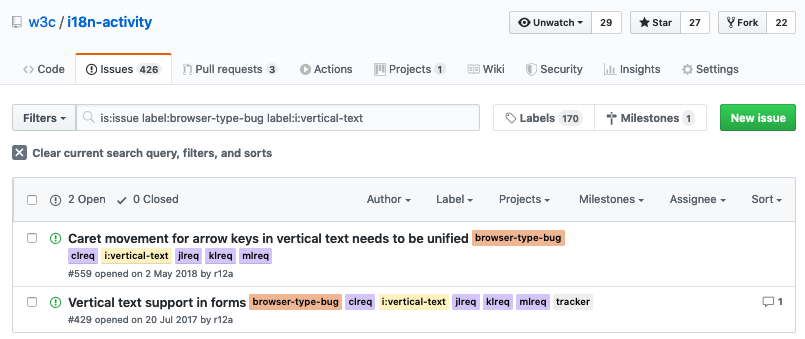
And slide 21: another link takes you to a list of implementation bugs that have been raised.
Language Enablement Index
Type samples

Slide 22: this is the link to type samples.
Our Type Samples database contains real samples of text features that are currently found in the wild.
And these are some of them, there's a few more for vertical text.
Language Enablement Index
I18n test suite
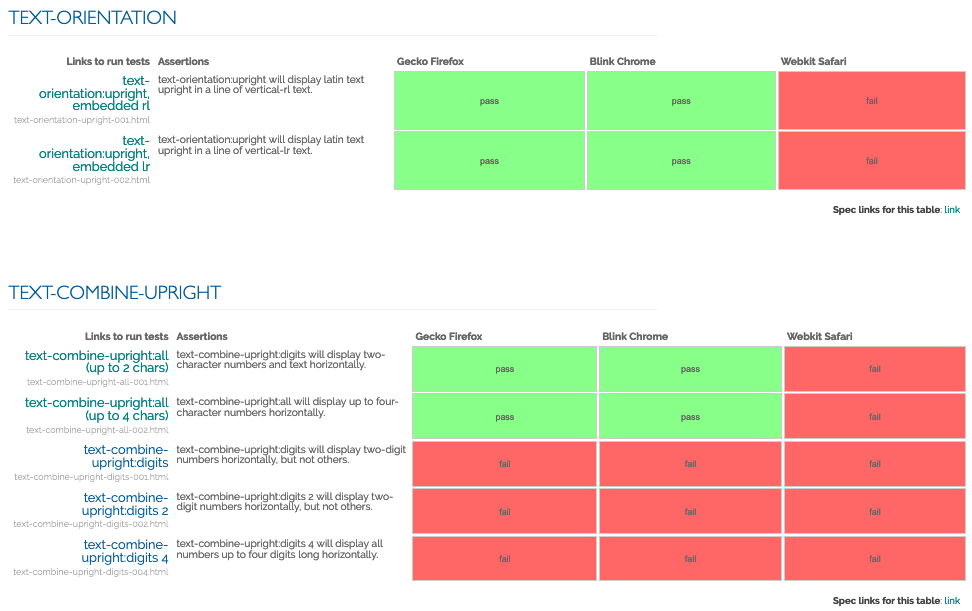
Slide 23: we also point to the I18n Test Suite, and you can see here an example of the results page for vertical or some of the vertical text tests.
Language Enablement Index
Exploratory tests

And we also point to the new exploratory tests, which I'll mention a bit more in a moment.
So again, here we have a results page but you can find the actual tests themselves by clicking on the links that are available there.
Summary
The Language Enablement Index is a place to find all the information we have been gathering.
- Links to requirements & specs
- Requests for information
- Related issues in W3C WG specs
- Implementation bugs raised
- Type samples
- Tests: i18n test suite & Exploratory tests
- Gap-analysis document sections
So in summary the Language Enablement Index is the place to find the information that we have been gathering.
Recent developments
Our final section starts on slide 26 and we're going to talk about some recent developments, which some of you may find quite interesting.
Gap analysis
Problem:
- GitHub pull requests appear formidable and difficult to use to many of the people we want to involve in developing gap-analysis.
Solution:
- Move content to GitHub issues
- Changes in issue immediately reflected in HTML doc
Benefits:
- Easier and faster to edit content
- Easier to hold and find discussions related to a particular topic
- Labels allow new and useful filtering of issues
And the first has to do with gap analysis.
And it starts from a problem statement.
And the problem is that GitHub pull requests appear formidable and difficult to use for many of the people that we want to involve in developing gap analysis.
And this has been, I think, affecting the contributions to the work.
So as a solution, we have moved the content of the gap analysis documents into GitHub issues.
And then we've put in place a system which means that any time you change the text which is in the first comment of a GitHub issue, that change is immediately reflected in the HTML document which brings everything together and allows you to find all the gap analysis texts in one place.
Benefits for this.
It's much easier and faster to edit content.
It's easier to hold and find discussions related to a particular topic because you can add comments to the particular topic that is in a given issue.
And the labeling that we've used on the GitHub issues allows us to filter issues in a new and useful way.
I'll just give you a couple of examples.
Gap analysis: HTML doc

On page 28, we see one of the sections from the actual HTML document.
And of course this is a longish document with many sections and many topics in it.
Gap analysis: Source in GitHub
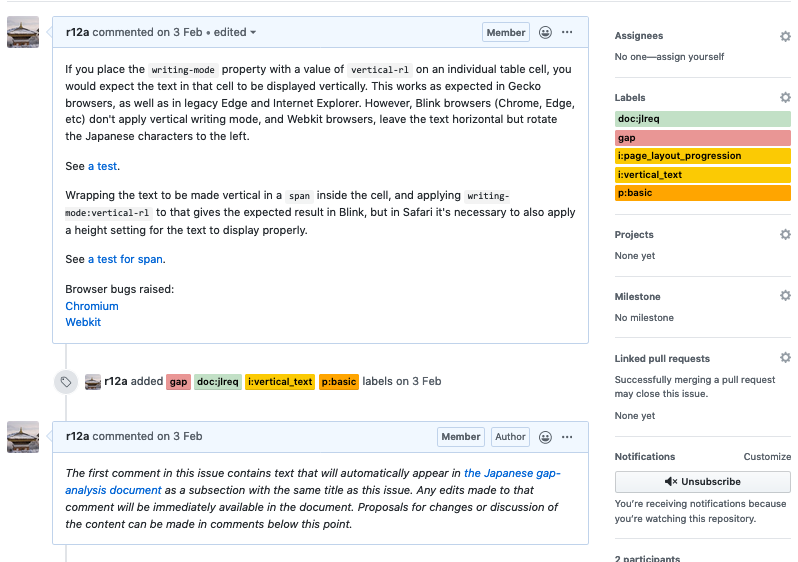
So this is about table cells not handling vertical text direction properly. But rather than edit the HTML you go over here to this GitHub issue and there's the actual text that was written that appears in the slide that you just saw (that is, in slide 29).
So that's quite easy for people to edit.
You'll see there's some labels on the right hand side.
Gap analysis: Discussion in GH
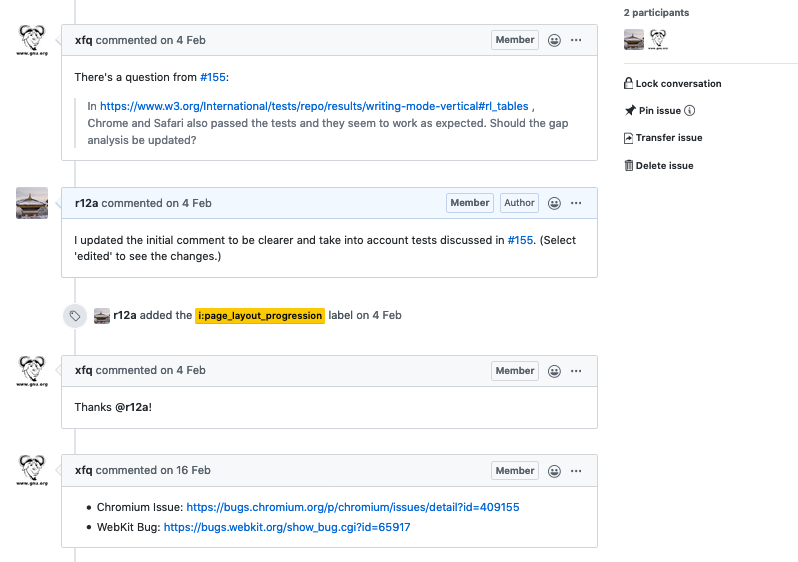
And then slide 30, we move down that issue a little and you can see an example of some comments that somebody raised against the text and that we then edited in the text.
And you can see the edits by pulling down the Edit pull down at the top of the issue.
Gap analysis: Filtering/sorting
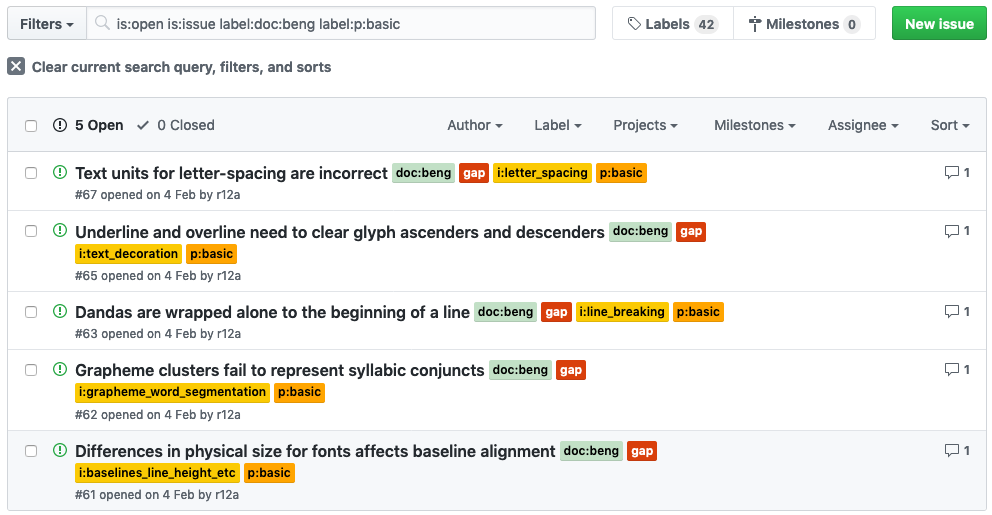
And slide 31 just shows several issues but we've applied some filtering here, so what you're actually seeing is all the basic issues for the Bengali language and nothing else.
And being able to filter and sort things in ways like that is a new thing that is enabled by the fact that we're using GitHub issues for the content.
That's quite useful.
So, so much for gap analysis.
Gap analysis: Filtering/sorting
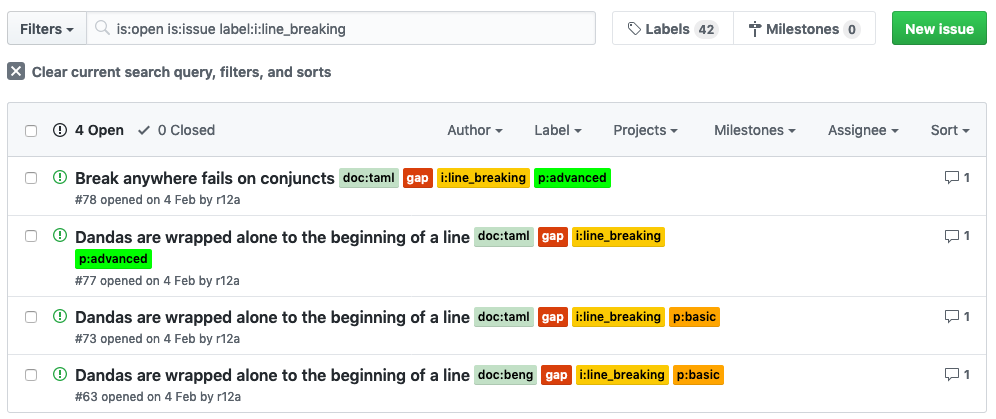
Oh, there's another slide (32) where we do a different type of filtering.
And so here we've got all the Indic languages that have an issue related to line-breaking and you can see what those are.
And this is very useful for comparing across languages and finding places where we have a comment that also applies to another language, and so on and so forth.
Exploratory tests
Problem:
- Difficult to learn to write WPT tests and time consuming to generate all the necessary files with the correct content.
- Especially important for gap-analysis work to have a fast & simple way to interactively create exploratory tests and record results.
Solution:
- Create test framework pages with form controls to add text, change language/font/box size/etc, and apply various CSS property values.
- Make a single button click record the state of any test page as a URL.
- Use GitHub issues to provide test instructions & detailed results.
- Changes in issue immediately reflected in HTML results summary docs.
So, the last topic has to do with exploratory tests.
The problem statement: it's difficult to learn how to write Web Platform Tests, and it's quite time consuming to generate all the necessary files with the correct content, especially when you're dealing with lots of languages or small tweaks that might affect lots of files.
And it's also especially important, for gap analysis work, to have a very fast and simple way to interactively create exploratory tests and record results.
So, our solution: we created test framework pages with form controls to add text. You can change languages as well, change the font, change the box size, and you can apply various CSS properties.
I'll show you an example of that in a moment.
And then you can click a single button and however you've set up that page, you can record that set up as a URL, which you can then paste to somebody in an email or, you could paste into a GitHub issue.
And so we've taken lessons from the gap analysis approach that we took.
We used GitHub issues to provide test instructions and detailed results.
Again, you'll see examples of these all in a moment.
And any changes in the issue that we have created for a particular test are immediately reflected in the HTML results summary documents.
So these are documents that summarize the results for a given set of tests.
Exploratory tests
Benefits:
- Significantly lowers the barriers for test production.
- Allows for very quick spot checks to be run up and circulated to others.
- Allows discussion of the tests, by using the issue comment fields.
- Especially useful for exploratory tests requiring many small tweaks and replication across multiple languages.
- Issue labelling allows for novel and useful ways of filtering & sorting tests.
Benefits: again, significantly lowers the barriers for test production, which is something that is very important for the gap analysis work.
It allows for very quick spot checks to be run up and circulated to others, not necessarily related to the language enablement stuff.
We've used it in the Internationalization Working Group for various things already, and you put a test together very quickly and make it into a URL and send it off to somebody.
It allows discussion of the tests because you have comment fields underneath the comment that contains the test information itself.
And it's especially useful for exploratory tests which require many small tweaks and replication across multiple languages.
And again issue labeling allows for novel and useful ways of filtering and sorting the tests that we have.
Exploratory tests: Test page
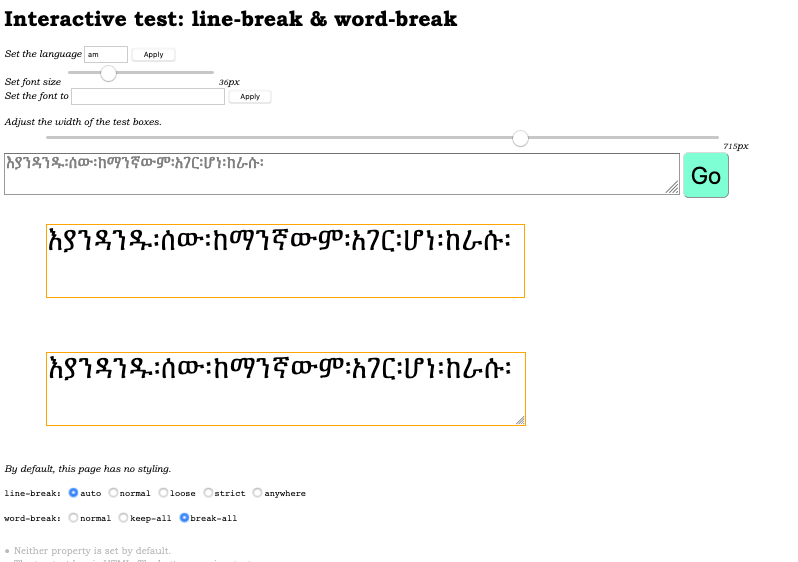
So, page 35, sorry, slide 35.
We have an example of a test page that has been filled out.
You can see I've set the language to Amharic.
I've set the width of the text boxes to a particular width and I've put some text below that slider which, when you press the GO button, appears in the two orange-bounded boxes below.
The top one is plain HTML and the one below it is a textarea.
So you can compare it and see whether there are differences. Sometimes there are.
Exploratory tests: Page snapshot
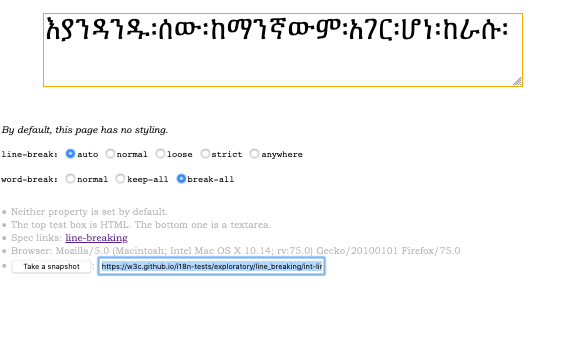
On slide 36, we slide down that page a little and you can see that we can also set various CSS properties related to line breaking and word breaking.
And then right at the bottom of the page there's a button, 'Take a snapshot'; you click on that and it puts a URL into the box alongside and highlights it for you, so you can just copy-paste it.
And there you have all the information to recreate that page the way that you had set it up.
Exploratory tests: Instructions & results
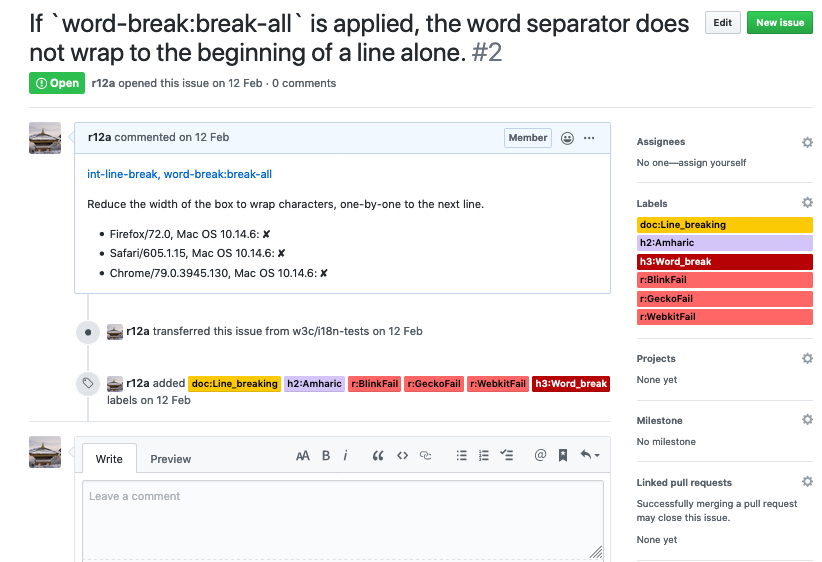
Then, if you want to keep that test and make it part of the test suites that we have, you go out to GitHub and you create a GitHub issue, like this, for example.
The assertion is in the title: “If word-break: break-all is applied, the word separator does not wrap to the beginning of a line alone”.
That's our assertion.
Then below that, we have the first comment, which contains a link to the test with the URL that we've generated.
It contains then some instructions on how to run the test.
And then below that it contains results, detailed results from the major browsers that we've tested.
Again, we have labels attached to that GitHub issue which enable us to aggregate the information.
Exploratory tests: Summarised results
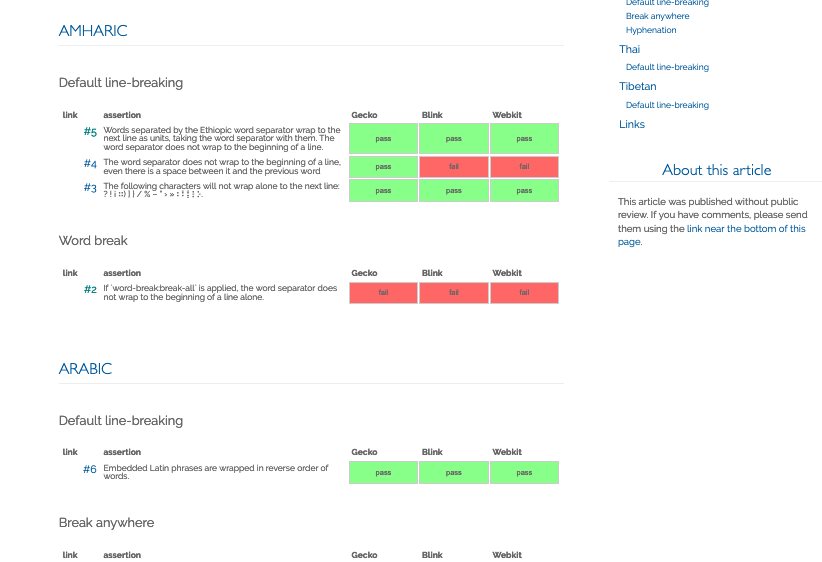
If you look on slide 38, you can see a test page (or part of a test page) which is related to line breaking, where we have some tests for Amharic and we show the results for the major browsers, and that information is generated automatically from the GitHub issues.
So, that's it really, those two innovations really should make it a lot easier for people doing gap analysis to do some of the critical work that they need to.
Summing up
So, on slide 39 and slide 40, summing up the Internationalization Sponsorship Program, as I've said, it's been running for a couple of years now.
Summary
- Developers and implementers are encouraged to:
We'd like to continue that but we need some more sponsors to step up.
So please contact Jeff Jaffe if your organization is able to step up to sponsor us to keep up this good work that we've been doing.
For the developers and implementers, we'd like to encourage you to use the Language Enablement Index to find information about worldwide Web support, to use the new exploratory test mechanism and check out the results, and to follow and contribute to the gap analysis work as well.
And that's all I have for today.
So thank you very much for listening.
And I look forward to working with you on internationalization at some point in the near future.