JSON-LD F2F Meeting, 2nd day — Minutes
Date: 2018-10-26
See also the Agenda and the IRC Log
Attendees
Present: Adam Soroka, Rob Sanderson, Benjamin Young, Gregg Kellogg, Simon Steyskal, Ivan Herman, Harold Solbrig, Dan Brickley
Regrets:
Guests: Eric Prud’hommeaux, Jean-Yves Rossi, Antoine Roulin, Luc Audrain, Dan Brickley, Hadley Beeman
Chair: Rob Sanderson, Benjamin Young
Scribe(s): Rob Sanderson, Adam Soroka, Benjamin Young

Content:
- 1. Issues
- 2. Disambiguate uses of @type #77
- 3. allow relative IRIs for @vocab
- 4. expanding
@vocabproperties consistently - 5. joint meeting with the Data Exchange WG
- 6. syntax/#8 - HTTP parameters for specifying context or frame
- 7. Discussions with the TAG representative
- 8. document loading related proposals
- 9. Resolutions
- 10. Action Items
1. Issues
1.1. blank node ids for graphs
link: https://github.com/w3c/json-ld-api/issues/26
Benjamin Young: white board from this morning:
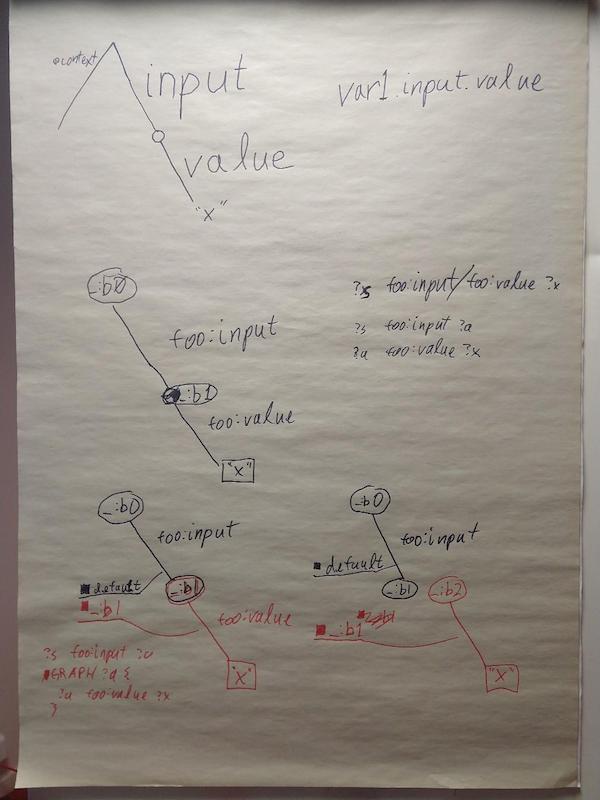
Eric Prud’hommeaux: the issue to talk about api#26 …
Eric Prud’hommeaux: … Gregg wrote it up. The issue is for @container: @graph — this property creates a blank node that ends up being a graph name for the embedded triples.
… so if we look at something without @graph, and we have a tree like […], we could access it like var.input.value
… In triples it turns into a graph b0 foo:input b1 ; b1 foo:value "x"
… We could get that with a graph path similar to the code
… Which is the same as the sparql ?a foo:input ?b ; ?b foo:value ?v
… In my proposal, If you create a graph it still ends up traversable
… but currently we end up with b0 input b1 ; b2:value "x" — it’s disconnected
… The things we normally use to get around don’t work
Adam Soroka: We need to make the bnodes the same?
Eric Prud’hommeaux: Yes. We would otherwise need higher level logic to merge them
… but we could just re-use the bnode
… this was used for verifiable claims. The bit that was in the input was only a tiny bit of stuff. So warlking around in a large graph looking for a triple was easy as the wrapper was very small, but that isn’t always the case
… you would also otherwise need application level logic, or you can’t query
… to traverse the data, you need to know it’s valid
Adam Soroka: And hence ShEX issues
Eric Prud’hommeaux: Yes, or SPARQL queries.
Eric Prud’hommeaux: The downside is that the blank node is the name of the graph, and a node in the outer graph
… this could be the default behavior. There might be other ways to connect them in the future
… need to get the same level of access in the RDF as in the JSON
… one more thing, the way to connect the nodes with more configuration and more of a pain, one construct is to say that b1 has a focus of b2
… that has a lot of reuse, but would mean writing into the rdf namespace
… e.g. in clinical data. Here’s a pairing of a graph name and a focus node
Eric Prud’hommeaux: Objection is typically that if there’s a property, is it about the graph or about the node
Gregg Kellogg: implies the name of the graph has meaning
Eric Prud’hommeaux: Yes, but it’s a blank node
… but what happens if it has @id? I think the answer there is both a node name and a graph name
Rob Sanderson: What’s the range of foo:input?
Eric Prud’hommeaux: union of named graph and the graph node class
… which doesn’t bother logicians, but does bug engineers
Gregg Kellogg: Not the use of every graph container
… where the graph appears with the value of a statement and doesn’t have their own declarative statement
… should we just use the graph name as the subject in that case
… which would allow for the follow your nose
Eric Prud’hommeaux: everything inside the input, all of those triples have the same subject
Adam Soroka: Trying to think of situations where I would want either way
Gregg Kellogg: You could just declare the subject
Benjamin Young: That maps cleanly to the expection when used — once typed out I expect it to work like that
… to end up detached would be bad.
… it breaks round tripping.
… there’s times when you use @graph like a packaging format
… here’s a bundle of stuff
Adam Soroka: as Gregg says in that case put in an explicit subject
Benjamin Young: In @container: @graph the implication is that they’re connected
… once you lose that, you’d just stay in JSON
Rob Sanderson: so the proposal is that for @container: @graph, when the subject is not explicitly set, then the default is to reuse the blank node
Ivan Herman: I have a more general uncomfortable feeling. We introduce another micro-rule. They all make sense by themselves, but when you pile them up you get a language that’s diifficult to understand
… we don’t take a simpler approach
Eric Prud’hommeaux: It seems the argument is more persuasive in the other direction
Ivan Herman: I don’t go into the particular issue, but that we just got as a proposal — if this and that and that, then …
… this is the proposal, it’s not a straightforward thing
… this is what I don’t like
… we pile up lots of these things and end up very complex.
… We should talk about URI resolution. e.g. with vocab and this and that. 90% of the people on the call didn’t follow what Gregg was explaining
… not anything wrong with what Gregg says, the reasoning steps are all okay by themselves, it’s the overall thing that becomes complicated
… the containers in 1.0 were used only for one thing, now we add a lot more
… we continue to do that. Don’t want to get to the technical details for this issue, just at the overall pattern
Eric Prud’hommeaux: I think the argument here is that the status quo is harder to explain, more surprising
Benjamin Young: Current situation is accidental.
… this proposal seems more natural
Adam Soroka: there’s some tension between avoiding surprise and keeping things easy to learn. In this case there is complexity, but its less surprising
Ivan Herman: As a zero level question, why do we need the container graph?
… Some community needs something, so we add a new quirk
Benjamin Young: @graph gets everyone’s hackles up. So we got @container: @graph
… from a JSON developer’s perspective, they need tools to get from the tree to the graph structure
… need to not annoy both groups
… this one to me resolves an issue from the RDF side
Benjamin Young: https://w3c.github.io/json-ld-syntax/#ex-85-implicitly-named-graph
Simon Steyskal: Going through the spec, in example 85, for graph containers. I wasn’t sure about the original sample
… it shows two graph objects, but if you look at the statements in the playground, it’s not what the original version has. They don’t match the expanded version in the spec
… the playground already does this reuse
Adam Soroka: People might be reliant on the feature?
Rob Sanderson: what does the spec say now?
Gregg Kellogg: it makes you create a new blank node
Ivan Herman: I repeat what I said in the issue comments :-( From a point of view of consistent view of how JSON-LD behaves, what is done today is the right thing to do
… the various things that a container contains is pieces of graphs. Inside is different nodes. So reusing the same bnode internally and for the graph, I understand it’s handy, but it does not fit the model for the JSON-LD world
… we could hack it around with a micro-rule, but from a JSON-LD consistency PoV it’s not right
… not a formal objection but I disagree
Adam Soroka: There’s a lot of opportunities — there’s other ways to do it
Eric Prud’hommeaux: If you could parameterize the behavior and let the user decide whether they get this behavior or the other
Ivan Herman: We have the syntax in the example. We can name the bnode explicitly
Gregg Kellogg: what does container: graph mean? You’re putting a box around some of the information so that it’s part of a separate graph.
… but it means that input has a value that is a named graph.
Ivan Herman: That’s what it means
Adam Soroka: You’re right, but eric is not asking to uniformly conflate them
Ivan Herman: then a separate syntax?
… we would have two types of containers, one graph container behaves as it should, and another that does something extra
… it pulls in the name into the internals of the graph
Adam Soroka: It’s a very common idiom
Ivan Herman: I understand. The problem is that we always follow perfectly valid rules, but we need to look at the overall result
… for many people JSON-LD is very scary because it’s so complicated
Eric Prud’hommeaux: But has better adoption
Ivan Herman: we do something very strange — and maybe we need to acknowledge it — we work with people from all corners of JSON usage and try to push them into the linked data world
… so you might lose the LD people as JSON-LD becomes an incredible mess
… you have people working with patterns of usage, but if I come from the LD world and just want to use JSON-LD as a serialization, and I know what I’m doing, then for me the usage is very complicated
… I don’t think in the fixed patterns, I just want to put a graph and get unexpected results
Eric Prud’hommeaux: In this case you have a disconnected graph, and you can do that with the expanded form
Rob Sanderson: [… more similar discussion …]
Rob Sanderson: So the alternate would be to have an explicit link. Would that be automatic, or put into the data?
Gregg Kellogg: I don’t think you can have the named graph in the source and the graph?
… within the named graph you have a triple whose subject is the graph
… can create a statement with a blank node, and the meaning lies with the predicate
… would not want to automatically introduce it
Eric Prud’hommeaux: When you have a graph that has two of those, what does it mean?
… it’s unattractive, and I’ve done it but was an interim measure
Gregg Kellogg: if we keep the status quo, and the name of the graph is not visible, the implications for writing a shape for trying to match things
Eric Prud’hommeaux: THere’s a step where you collect things. But when you get to the internal graph you’ve already collected it. You’d need to do cycles of gathering and validating
… without some predictable connection, there isn’t a way to do it without a procedural language
Adam Soroka: You have to assume validity in order to validate it
Eric Prud’hommeaux: Can do various things
Adam Soroka: But it’s application level knowledge
Eric Prud’hommeaux: Yes, you’d have to customize a lot of stuff
… here you do an unbound sparql query
… which is considerably more expensive
Adam Soroka: you still might need to apply application knowledge
Eric Prud’hommeaux: Could find nodes that don’t have inbound links, but you can’t assume that’s always the case with inverse properties etc
Rob Sanderson: (restates problem)
Ivan Herman: It comes from @container: @graph. As a value, I have an object whose keys refer to something specific
… a language refers to the language of the string
… but the graphs are very different beasts. They must have an identifier, or we generate them one
… it’s different from language, so maybe the container model is not fit for that purpose
… we must talk about identifiers and how they’re used elsewhere
… when I use the container for a language, it’s simple
… it’s by the natural language
… container is a way to categorize certain things, and they become keys
… I have a bunch of strings with a category, the language
… I create an object that uses the category as a term
Adam Soroka: Containers as maps
Gregg Kellogg: Not all though
Ivan Herman: Yes, @container: @list is a very different animal
Eric Prud’hommeaux: Not that it’s a graph, just the container
… if you want to build a named graph then have a different construct
Gregg Kellogg: Can have a map of graphs with @id
… an array of keys
Ivan Herman: should take a step back to look at containers and mapping
… is it possible to have a clearer model and separate the two things
… and then come back to it if there’s a more natural way to model it
… if it’s a blank node, then I can assign and reuse
… user has the choice to reuse.
Gregg Kellogg: If you use a graph id map, then they have to name them explicitly
… VC and WoT are in a similar situation, I think
Ivan Herman: Yes, but do we now add another special quirk??
Adam Soroka: Depends how many people are interested in it
Ivan Herman: Then we need a template language
… Propose to leave this alone for a little and look at containers in general
Adam Soroka: And “path” is in here too now (see discussions with WoT), for things people are asking for
Ivan Herman: Could use different term, they’re not containers like list or set
Gregg Kellogg: Could introduce @map
Ivan Herman: and then add in obsolete terms for indexing
Adam Soroka: Seeing patterns, and then clarifying how to get them into the syntax
… hence microrules
Gregg Kellogg: Also about the interpretation of the value space
Rob Sanderson: Exactly equivalent to https://github.com/w3c/json-ld-syntax/issues/77
Gregg Kellogg: raising warnings :( and makes algorithms harder
Rob Sanderson: priority of constituencies puts algorithms very close to the bottom
Ivan Herman: Can have a raise warning or not flag in the API
… algorithms will be slightly more complicated, but only affect 5 or 6 people
Adam Soroka: And we probably know most of them
Eric Prud’hommeaux: Regardless of how you construct the syntax, need to deal with nesting in JSON
Gregg Kellogg: There’s the expectation of connectivity
Eric Prud’hommeaux: Relatively simplisitic user, but that’s typical. If it’s more nuanced, I want the default to not produce pathological graphs
Gregg Kellogg: If we created a new @map thing and put graph / id maps in there, so would have a reduced use case for @container, and we’re back to the same issue
… container is a graph, and you’re in an implicitly named graph. Now where are the rest of the things?
Adam Soroka: syntactic mechanism. If containers were minimized, could be nicer. If we could add metadata to containers, we could maybe add the information. But would need very strong notion of containers
Eric Prud’hommeaux: That’s a step in the right direction
… trying to deal with existing sem web … two camps. People who abuse the node to be the graph name. And then there’s people who keep them separate.
… but theres a mechanism to connect them
… trick is normally HTTP fragments. Use the # and then HTTP connects them
… those two camps are not going to come together
… at least half the people are going to be miffed
… so putting in controls will help
Ivan Herman: more inclined to look at something more complicated, but long term more powerful, and accept that we need a transformation / template language
Ivan Herman: We see a user community that uses a template as that’s how they think. We try to come up with syntactic quirks so the templates fit in the model
… that’s where we get in trouble. If we had some transformation language, it could help.
… not sure it’s realistic, and not familiar with framing details
… can that be added to framing model? Not a rec, so don’t have backward compatibility restriction
… if we do something there, that would mean a cleaner separation
… if this is taken up by a frame and uses the same bnode. Can express it in JSON-LD. It’s all doable already.
Eric Prud’hommeaux: have about 100 hours thinking on this in ShEX. Both dealing with a case where there’s an algorithmic mapping between a graph node and a node in the graph
… need to get from one to the other
… expressivity we discovered we needed was at a minimum to chop off or add a hash based identifier
… for the range 14 folks
… ability to say it’s the same
… and then as you work down into the people who have pipeline techniques, you end up with regexps
… that lets you use node identifiers that are relative to the base
… two nodes that are different but related
… regexs look at the graph labels
… to deal with existing data
… question is how much you want RDF data to drive this.
Adam Soroka: And the other extreme is JSON devs who are told they have to do something. Some things don’t make any sense at one or the other end of the spectrum
Eric’s examples:
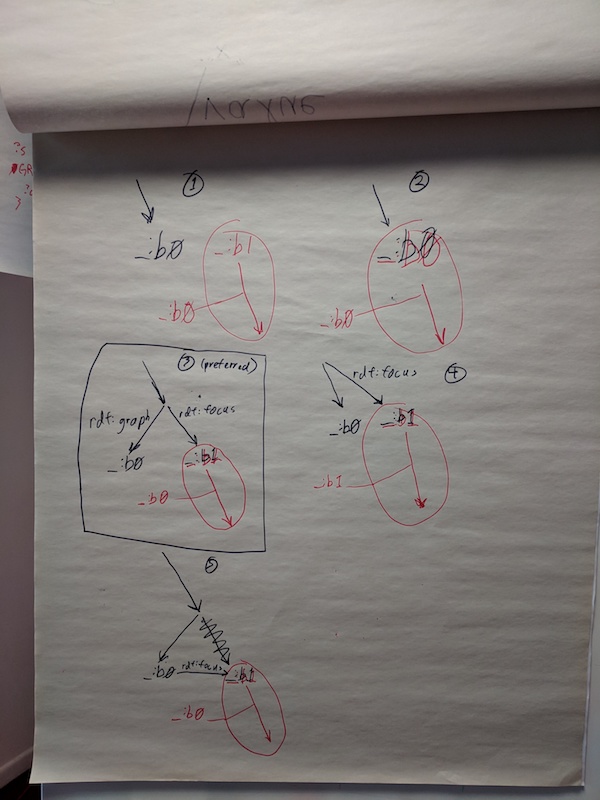
Proposed resolution: add a feature at risk that the implicitly identified graphs will share the bnode with the unidentified member of the graph, on the grounds that the user community most in need of this would expect it, and the community that would be horrified by it better understands the solution of explicit naming (Rob Sanderson)
Rob Sanderson: +1
Ivan Herman: +0.0000001
Simon Steyskal: +1
Gregg Kellogg: +1
Harold Solbrig: +1
Resolution #1: add a feature at risk that the implicitly identified graphs will share the bnode with the unidentified member of the graph, on the grounds that the user community most in need of this would expect it, and the community that would be horrified by it better understands the solution of explicit naming
Rob Sanderson: Assuming +1s from Adam and Benjamin
Adam Soroka: +1
2. Disambiguate uses of @type #77
Simon Steyskal: link: https://github.com/w3c/json-ld-syntax/issues/77
Ivan Herman: can @container be used with @type to separate string, dates, etc?
… if so that is again an argument to deconflate all the meanings of @container
Gregg Kellogg: might make sense but isn’t very useful
… the datatype for all variations would be rdf:HTML, so you wouldn’t be able to also work by languages
Ivan Herman: right. but even gkellogg had to think about whether you can use @type with @container, which tells us that we need to simplify
… a container-mapping for @dataype — it’s not clear whether it would be useful
Rob Sanderson: if rdf:Literal is the datatype…
… if you had some HTML, some strings, maybe you can sort it out then
Ivan Herman: so mapping via datatype is questionable
Gregg Kellogg: I understand the proposal to be a new keyword @datatype to be used in contexts to signal datatypes, as @type does today
… letting us mark that usage of @type as obsolete
Ivan Herman: even today, you could use it via aliasing.
Gregg Kellogg: compaction wouldn’t do what you want if you did that
Ivan Herman: we have an example from Publishing WG where the alias would be useful, and round tripping not necessary
Proposed resolution: add
@datatypefor use with value nodes that would be a synonym only in those situations for@type(Rob Sanderson)
Rob Sanderson: +1
Ivan Herman: +1
Adam Soroka: +1
Harold Solbrig: +0
Simon Steyskal: +1
Gregg Kellogg: +0.5
Adam Soroka: Assuming bigbluehat is +1
Resolution #2: add
@datatypefor use with value nodes that would be a synonym only in those situations for@type
3. allow relative IRIs for @vocab
Simon Steyskal: link: https://github.com/w3c/json-ld-syntax/issues/72
Gregg Kellogg: in JSON-LD, vocab-relative and document-relative IRIs are resolved differently. we’ve already looked at this problem
… and offered the ability to set @vocab=""
… which allows vocab to be resolved against the document base
… motivated at least in part because in other RDF formats, that distinction doesn’t exist
… so there was a parity issue against other serializations
… this issue goes further, and lets @vocab get set to any relative URI, which would then be evaluated against the document base
… the proposal includes that if a @vocab is already set and a new relative @vocab comes along, one simply string-appends the new one to the old one
Rob Sanderson: in the case of a base that came from HTTP with a # on the end, that would get lost
Gregg Kellogg: this also addresses the problem that Manu raised in the context of blank-node-properties.
Rob Sanderson: if you set vocab to ../# and you had example.org/ns then you get example.org/ns../#
Ivan Herman: as an editorial matter we must make very clear that this is string concatenation, not IRI concatenation
rob: are there good rules for determining relative vs. absolute IRIs?
Ivan Herman: Look for the scheme
Ivan Herman: I am almost sure that the URI spec defines that very clearly
Rob Sanderson: but this could be a security problem if a malicious actor sets a CURI prefix of “http” to some malicious address
Ivan Herman: also the same thing with base
Gregg Kellogg: We can’t really know
Rob Sanderson: we can just advise people of the security concerns
Action #1: Rob Sanderson to make a security consideration issue re relative IRI concatenation
Ivan Herman: do we check for “acceptable” scheme?
… what about Javascript URIs (bookmarklets)
Rob Sanderson: “@vocab”: “javascript:”
Action #2: Rob Sanderson to create security consideration re javascript URIs and relative IRIs
Gregg Kellogg: we don’t now check for defined schemes
Benjamin Young: it’s the responsibility of the document loader to worry about this
… it could just choose not to resolve troubling URIs
Ivan Herman: so you put together a URI from the JSON-LD (could happen in many ways).
… at that level, do we add a security check?
Benjamin Young: that’s the job of the person using the URI
Rob Sanderson: Or rather
"@vocab": "javascript:document.alert('hi!');"
Benjamin Young: this isn’t a job for the syntax
… e.g. data: can hide anything
… data: URIs
Gregg Kellogg: this could be used for maliciousness, but it’s on the users of the URIs to be careful
Rob Sanderson: we don’t do path expansion, we’re doing string concat here. so we won’t catch a lot of stuff
Benjamin Young: but the advantage of string concat is that it supports non-pathy URIs
Gregg Kellogg: @vocab is used only for properties
several: and generally people don’t dereference properties, and nothing in our algorithms says that they should
Gregg Kellogg: we can modify the API to return only URIs of some form.
Benjamin Young: we can say “we never use these URIs, so there’s no concern w/i JSON-LD, but if users choose to use them, the usual concerns about URIs from the wild apply”
Gregg Kellogg: we might consider softening the current restrictions in 3.6.3
… to use IRI expansion and not string concatenation
Rob Sanderson:
"@vocab": "http://example.org/ns/"and then"@vocab": "/"
Rob Sanderson: currently you get
"http://example.org/ns//"which is unexpected for relative IRIs
Rob Sanderson: And the expectation would be
"http://example.org/"
Ivan Herman: are we making the distinction between the two kinds of resolution disappear?
Gregg Kellogg: still the issue of concatenation vs. IRI resolution
Gregg Kellogg: how do I establish @vocab, vs. how do I use it?
Ivan Herman: if we are in @vocab we do string concat, it’s clean
… and users just have to know about that
… let’s don’t mingle concatenation and IRI resolution
Gregg Kellogg: we’re only interested in resolving `@vocab when it is relative, that’s all
Ivan Herman: You’re right, but that’s about implementing the system
… I’m talking about end users
… if we just have string concat for @vocab, that’s clean, I understand that
… even if we do IRI resolution instead over here
… somewhere else. but any problems with doubled slashes, etc., are users problems to deal with
Rob Sanderson: if we went all the way to have @vocab itself computed and vocab terms resolved via IRI resolution, it breaks things
… so lets stick cleanly to string concatenation
Gregg Kellogg: Ok, but these are different use cases.
Ivan Herman: there is an actual regexp to recognize absolute IRIs, so we can rely on that
Harold Solbrig: doesn’t the CURI spec speak to this?
Gregg Kellogg: we don’t use CURIEs, either
Harold Solbrig: why are we using something else?
Gregg Kellogg: every RDF serialization uses its own way to discuss short URIs
… (gkellogg then names more than you would think he could off the top of his head)
Rob Sanderson: we can’t necessarily construct all legit IRIs, but most of what we can’t is unusual enough not to be problematic
… if we stick with string concat, we avoid this
… if you construct stupid @vocabs, that’s your problem
Proposed resolution: Allow IRIs to be constructed by string concatenation with multiple
@vocabs(Rob Sanderson)
Proposed resolution: Allow IRIs to be constructed by string concatenation with multiple
@vocabs, with appropriate security consideration section (Rob Sanderson)
Adam Soroka: +1
Gregg Kellogg: +0.9
Rob Sanderson: +1
Simon Steyskal: +1
Adam Soroka: +1
Harold Solbrig: +1
Benjamin Young: +1
Resolution #3: Allow IRIs to be constructed by string concatenation with multiple
@vocabs, with appropriate security consideration section
Ivan Herman: +1
Benjamin Young: the Chaucer quote fwiw https://english.stackexchange.com/questions/139073/meaning-of-if-gold-rust-what-shall-the-iron-do
4. expanding @vocab properties consistently
Rob Sanderson: link: https://github.com/w3c/json-ld-syntax/issues/56
Gregg Kellogg: the concern is that the same term expands differently in different places
… gkellogg then describes the example in the issue
Rob Sanderson: the example has two triples in it:
Benjamin Young: triples from the playground from the first example in #56
Benjamin Young:
<http://example1.com/barney> <rdf:value> "the sidekick" .
Benjamin Young:
_:b0 <http://example1.com/fred> <http://example1.com/barney> .
Benjamin Young:
_:b0 <http://example1.com/fred> <http://example2.com/barney> .
Ivan Herman: I would say that in the second case (barney is a string) it’s the defn of barney that comes in
… nothing to do with that fred is defined by vocab
Gregg Kellogg: no, it does have to do with
… our rules are intentionally different for different kinds of values
… the complaint is that the rules for resolving IRIs vary
… in the example the value space of fred is vocab
… the fact that there is an entry in the vocab space for barney means nothing when we use barney as an ID.
Adam Soroka: that’s the two different spaces
Gregg Kellogg: unless it happens to be used in a CURI
Ivan Herman: this is confusing
Gregg Kellogg: in 1.0 there is a distinction between the vocabulary (properties, types) and values, which come from the document.
… if you have a term in the vocab with a name that is used as instance data, in each position they are resolved differently.
Benjamin Young: a remix of the example of #56 using 2 contexts in http://tinyurl.com/y7wpjogw
Gregg Kellogg: we’re getting back into deep history of 1.0 here. Qe felt there are good reasons to make this distinction, but we may have been wrong, of course
Adam Soroka: ivan is now showing examples on the projector, see http://tinyurl.com/yclwe2ax
Gregg Kellogg: when you have a doc, you ascribe meaning by bring properties and types to it.
… but you would want to resolve relative value URIs differently than vocab terms
Rob Sanderson: but this kind of problematic situation shouldn’t arise
Benjamin Young: sometimes you don’t get a choice
Rob Sanderson: you should be able to avoid it by inverting the order of multiple contexts, if they colliding in this way between them
Ivan Herman: in the first example with barney, http://example1.com/ is used for base and the first appearance of fred
Gregg Kellogg: the fact that barney is a term in the context doesn’t affect value expansion
Ivan Herman: if I change the base, various changes result
… we could pare down the example
Benjamin Young: this could confuse naive devs
Rob Sanderson: you should never get this to begin with
… what would be the use of interpreting barney as the same thing in the example
… you wouldn’t construct that data.
Benjamin Young: [uses his hands to construct a list of annotations]
… one past use case we’ve gotten is when you start with a list of ids,then you reference down into a list of inclusions.
… the use case from which this current issue came is gathering that up into a packaged graph with lots of graphs about the same stuff
Rob Sanderson: http://tinyurl.com/yb3olq5y
Benjamin Young: in JSON-LD we are constantly using many contexts, that raises the likelihood of this
Adam Soroka: more discussion about whether or not this situation can realistically arise
Rob Sanderson: the data in the OP example is meaningless
Adam Soroka: ivan brings more examples to the projector
Ivan Herman: here is a minimal situation to display the problem
Ivan Herman: A simpler version of the example:
{ "@context": { "fred": { "@id": "http://a.b.c", "@type": "@vocab" }, "barney": { "@id": "abc:def" } }, "fred": "barney" }
Adam Soroka: agreement that ivan’s new example minimally demonstrates the problem
Gregg Kellogg: why does one want to create terms with '@type':"@vocab" to begin with?
Ivan Herman: we should have a very clear example of this and explanation of this in the docs
Gregg Kellogg: I think we have examples
Ivan Herman: with lots of explanation
Gregg Kellogg: we have a document space and a vocab space, and the only time document terms get resolved in vocab space is in compact IRIs
… and when the term used as the property is defined as '@type':"@vocab"
Benjamin Young: this example wasn’t contrived—it came out of extant tooling
Adam Soroka: disagreement about how responsible users are to avoid these kinds of colisions when using other people context’s
Ivan Herman: Patrick (the OP) is a very expert user. What about the less-expert users?
… it’s a return to what I earlier said: what if I am semweb literate, and I come to this, and I can’t make my graph work sanely in JSON-LD
Benjamin Young: even with Patrick’s expertise he hit this problem, and not by trying to develop a curious example
… it was normal work
Gregg Kellogg: this might stem from divergent missions
… surprising that someone trying to turn Turtle into JSON-LD doesn’t find that obvious
Ivan Herman: might need to push this into the primer
… the doc as is tried to make it usable for JSON devs
… we may need to write from the other direction
… for RDF folks coming to JSON
Rob Sanderson: in Patrick’s defense, there is no good example for this
Gregg Kellogg: I can try to write this up
… one concern: we are still getting to “own” JSON-LD
… we all need to get to an adequate mastery level to be able to talk about this
… we could try assigning issues to people who raise them
Proposed resolution: Make #56 editorial to add a
"@type":"@vocab"example (Rob Sanderson)
Adam Soroka: +1
Proposed resolution: Make #56 editorial to add a
"@type":"@vocab"example and otherwise no change (Rob Sanderson)
Rob Sanderson: +1
Simon Steyskal: +1
Benjamin Young: +1
Gregg Kellogg: +1
Adam Soroka: +1
Harold Solbrig: +1
Resolution #4: Make #56 editorial to add a
"@type":"@vocab"example and otherwise no change
5. joint meeting with the Data Exchange WG
Ivan Herman: Minutes of the session in the DXWG Meeting Minutes
6. syntax/#8 - HTTP parameters for specifying context or frame
Benjamin Young: continuing conversation from #dxwg
Rob Sanderson: we can use space separated lists of URIs, so the profile=”” parameter can contain both the compaction, etc. defined URIs
… as well as a JSON-LD context or frame URI
… however, these URIs might collectively get quite long
Adam Soroka: if you specify a URI don’t you want it to be compacted?
Rob Sanderson: it could be a frame
Gregg Kellogg: or a bomb
Benjamin Young: or a cat photo
Adam Soroka: do we want to have a default use like it’s assumed it’s a context URI?
Ivan Herman: what would this look like in practice?
Rob Sanderson: I’ll write it up…one second…
Rob Sanderson:
ACCEPT: application/ld+json;profile="http://w3.org/ns/anno.jsonld"
Rob Sanderson: this would say, “I want this request compacted according to this context”
Gregg Kellogg: if that JSON-LD URL returns a context
Benjamin Young: don’t dereferences things found in profile params
… because proxies
Gregg Kellogg: right, security concerns/needs should be expressed
Benjamin Young: we used the entire string as the “media type” for Web Annotation
… with no expressed intent or idea of dereferencing that context URI
Adam Soroka: I’m not too worried about big headers
… if you’re going to be this particular about it, then that’s a “cost” you’ll face
Rob Sanderson: and the multiple URIs in profile=”” is not a problem?
Adam Soroka: no, I think that’s fine
Rob Sanderson: if you don’t care if you’re flattened or compacted, then don’t state it and use the context for whichever you’re returning
Benjamin Young: is there priority among these strings?
… or do they just work as flags?
Rob Sanderson: they’re just flags
Adam Soroka: do we want q=”” parameters for this?
Rob Sanderson: I’d say it’s an error condition to have multiple contexts given
Benjamin Young: is the intent to continue–as Web Annotation did–as a single opaque string?
… or are we switching on each piece?
… mostly it’s a question for me about upgrading existing Web Annotation servers (and the like)
… so are they opaque “whole” strings? or are we taking them apart in some way?
Rob Sanderson: so, in the case of compaction at least, we could have a default that maps to compaction
… which is how profile=”” is used in the cases that we know
Gregg Kellogg: are you going to help write these tests?
Rob Sanderson: sure. I’ll help write those tests
… and the paragraph/dependencies
Gregg Kellogg: and at the moment we don’t have complete HTTP header tests…but need those
Rob Sanderson: I know someone (bigbluehat) who’s done this already
Benjamin Young: we’re continuing the Web Annotation validation/testing tooling work at http://annotator.apache.org/
Gregg Kellogg: so, there are a few HTTP tests now
… they were originally in an .htaccess file
… but right now it’s left up to the implementations to act as if the headers were expressed in the responses or not
… the test suite should ideally run off a W3C mirror that implement these .htaccess
Benjamin Young: curious which bits you needed in .htaccess
Gregg Kellogg: there’s a remote access manifest in the API
Gregg Kellogg: https://github.com/w3c/json-ld-api/blob/main/tests/remote-doc-manifest.jsonld
Gregg Kellogg: for example https://github.com/w3c/json-ld-api/blob/main/tests/remote-doc-manifest.jsonld#L34
… this one tests a application/jldTest content type
… which in this case should fail
… others here deal with redirects
… also, another for the Link header https://github.com/w3c/json-ld-api/blob/main/tests/remote-doc-manifest.jsonld#L84
… for all of these we’re analyzing the JSON-LD result
… so we probably want similar ones analyzing the HTTP headers themselves
Proposed resolution: Add text to Iana Considerations explicitly allowing the request of a context or frame document, plus security consideration on whitelist, plus tests (Rob Sanderson)
Rob Sanderson: +1
Gregg Kellogg: +1
Adam Soroka: +1
Benjamin Young: +1
Ivan Herman: +1
Resolution #5: Add text to Iana Considerations explicitly allowing the request of a context or frame document, plus security consideration on whitelist, plus tests
7. Discussions with the TAG representative
Rob Sanderson: We want guidance from TAG because this crosses specs, specs that are at various process stages.
Gregg Kellogg: https://github.com/orgs/w3c/projects/4
7.1. What is ‘base’ for an embedded json-ld? (redux)
Gregg Kellogg: https://github.com/w3c/json-ld-syntax/issues/23
Rob Sanderson: the overall req is that for relative URIS, we must have a way to resolve them to absolute URIs.
… JSON-LD that is provided by itself, this only refers to the URI of the doc.
… so resolution is easy.
Rob Sanderson: but you can also embed JSON-LD w/in HTML
… there are various ways to determine the base of an HTML doc
… our issue is when we are resolving rel URIs inside a JSON-LD doc inside an HTML doc
… should we rely on that base or should we rely on the JSON-LD base (as it would otherwise be used)?
Ivan Herman: the base attribute in the DOM is inherited by the <script/> element that contains the JSON-LD
Hadley Beeman: use case?
Ivan Herman: every schema.org doc (in JSON-LD) is embedded. Billions of pages contain this.
Dan Brickley: Case 1: https://gist.github.com/danbri/0168ebcd731493ee88c20407e6cdb8bf raw: https://gist.githubusercontent.com/danbri/0168ebcd731493ee88c20407e6cdb8bf/raw/bff3ae0bed3fac72972bf1ccccd4137517111bc4/gistfile1.txt HTML includes a div setting a base. vs Case 2: https://gist.github.com/danbri/b04d835ebf227f8994001b304ac59acf https://gist.githubusercontent.com/danbri/b04d835ebf227f8994001b304ac59acf/raw/3cbea88cd905665cd158b5988b1a8839362e4f57/gistfile1.txt
Dan Brickley: I forgot to relative-ize some URLs
Hadley Beeman: what are you going to do with the absolute URI?
Rob Sanderson: the point is to get to RDF, which works on absolute URI
Dan Brickley: We just want to make links!
Benjamin Young: the dom tree inherits that base tag, and the base tag also supplies the base URI for the HTML doc
… the prevailing encouragement is to ignore the DOM
Rob Sanderson: the counterexamples are Microdata or RDFa. RDFa uses all the base URIs.
… they use the DOM, both of them
Gregg Kellogg: it would be nice if all these things agreed
Benjamin Young: we already have explicit base for JSON-LD
Hadley Beeman: how much is JSON-LD content vs. machine-parseable behavior?
… it’s not easy
Benjamin Young: Is the JSON-LD integrated in the doc, or is the doc just a carrier?
Gregg Kellogg: you might have multiple script blocks.
Dan Brickley: I redid the testcases: https://gist.github.com/danbri/0168ebcd731493ee88c20407e6cdb8bf vs https://gist.github.com/danbri/b04d835ebf227f8994001b304ac59acf (see raw links for … raw links)
Hadley Beeman: it’s content vs. structured data
… danbri and are have been discussing this
Hadley Beeman: my instinct is to prefer that data that is machine-readable before human-readable shouldn’t be tied up with the DOM
… but I’d like to discuss with my TAG colleagues to avoid breaking other things
Dan Brickley: 3 points about this
Dan Brickley: 1. Google at least, likely other search engines, extract JSON-LD after running headless browsers.
Dan Brickley: 2. Here’s a headless browser called from python (firefox), which ignores
<base href>and just pulls out<script>. It would be good for this not to get too much more complex.
Dan Brickley: 3. The big appeal of JSON-LD was its standalone nature.
Benjamin Young: this might be a good thing for RDF 2.0, but it would not be in a <script/> tag
… but a data block right now doesn’t inherit from the DOM
Hadley Beeman: if you come from the part of the Web where most stuff is in the DOM, then this would be natural for JSON-LD
… the desire to integrate in the future makes sense,
… but not doing that suddenly now
Dan Brickley: 1. we don’t want to get involved with browsery hell as a search engine.
… but what we do now is fragile
… but it’s easy for publishers
… we say that it works, but we’re not pushing it as the right thing to do
… 2. JSON-LD took off because it was self-contained
… unlike other structured data formats
… that self-contained character is the clincher here
… only do relative URIs if you know what you’re doing
Gregg Kellogg: these bleeds into other specs that might use <script> blocks
… how should rel URIs be interpreted there?
… I suspect that they should be resolved against the document URI
Benjamin Young: same deal if you have a CMS that is sticking metadata into pages—you should absolute-ize the URIs
… which we can do already in JSON-LD
Hadley Beeman: Create an issue on this please https://github.com/w3ctag/design-reviews
Gregg Kellogg: if we have input, we should give that to the TAG
Benjamin Young: could result in changes to the datablock spec
… or telling specs to advertise what they do here
… ultimately, if you don’t absolutize the URIs, you are entangling your data with the package
Benjamin Young: https://www.w3.org/TR/html5/semantics-scripting.html#data-block
Hadley Beeman: you used the word “package”
Benjamin Young: let me say “conveyance” instead
Dan Brickley: ..ooOO( if json ld is parsing from a.html and there’s an iframe of b.html, … do we have anything to say?)
Dan Brickley: what is the story with multiple script blocks?
Benjamin Young: we have other issues, but without this we can’t get to the others
7.2. Content addressable contexts
link: https://github.com/w3c/json-ld-syntax/issues/9
Rob Sanderson: equally or more cross-working-group to the last one
… VC et al have security concerns around contexts that must be led by a server before the server can understand the JSON-LD
Benjamin Young: you don’t have to fetch this every time you need it, you will cache contexts, etc.
… which comes around to how contexts (as web resources) change with time
… naming on the Web—easy?
… each of the communities using the tech can resolve these things. we need the TAG to advice on the nuances of things
… like content hashes, etc.
Rob Sanderson: you can solve it at 3 diff layers: HTTP, where you can last-modified, etags, etc.
… in the doc itself, which can declare versioning
… or in the URI, e.g. http/example.com/v2
Dan Brickley: but do you need a context at all?
Gregg Kellogg: you can put it into the instance doc itself, but it still exists.
Benjamin Young:
{"@context": {"@vocab": "http://example.com/"}, "name": "made up vocab"}
Gregg Kellogg: The notion is that JSON-LD provides the context within which to interpret your JSON
… strings sometimes are dates sometimes IRIs, sometimes something else
… you need to both distinguish between these things but also allow for idiomatic JSON
Benjamin Young: which creates
_:doc-id <http://example.com/name> "made up vocab"(in triples—where “doc-id” is completely random)
Gregg Kellogg: the context explains some of the things that API docs might explain
Dan Brickley: I had thought that the context could be derived in some other way
Benjamin Young: you can.
Adam Soroka: (from an HTTP header)
Dan Brickley: is this wrong then?
Dan Brickley:
{ "@vocab": "https://schema.org/", "@type": "Volcano", "sameAs": "https://www.wikidata.org/wiki/Q2586153", "name": "Zuidwal volcano", "description": "The Zuidwal volcano is an extinct volcano in the Netherlands at more than 2 km (6,600 ft) below ground ..."}
Benjamin Young: latest syntax spec https://w3c.github.io/json-ld-syntax/
Rob Sanderson: the TAG issue for guidance is — this caching question is much broader that JSON-LD.
… many systems do this kind of “apply one resource to another to clarify”
… e.g a CSS stylesheet—if it changes over time the rendered HTML will look very different
… in a knowledge graph context, that kind of change is much more dangerous
… guidance for mitigating those concerns in the spec rather than leaving it up to broader discussion about change over time on the web
Benjamin Young: Link header looks like:
Link: <context.jsonld>; rel="http://www.w3.org/ns/json-ld#context"; type="application/ld+json"
Hadley Beeman: so remote change can affect local things—how is this different from old concerns about linking?
Dan Brickley: the WoT folks chose a syntax that requires this additional context resource—that’s what causes this to be different
… as long as you need the context doc to interpret and act on the data, you have opened this security hole
Hadley Beeman: so what about caching?
Adam Soroka: WoT operates on much longer timescales — years in many cases.
Dan Brickley: one thing we care about is being a planet-scale search engine, the other is about lightbulbs in your home
Benjamin Young: you can’t change what happens in the lightbulb without changing the context used for data there
… you can update when you update the code
… the URI of the context really is a URI (an identifier), not a location, but it ends up being used as one
Hadley Beeman: I still hear this either being “we have to solve the problems of building the IoT” or “the network knows something about me because of what I looked at”
… which are both larger problems
Dan Brickley: no, it’s different — because now the lightbulb is not a user agent, but it is broadcasting info about you
Benjamin Young: our API spec says you can implement document loading any way you want, yay!
… but that doesn’t really solve the problem
… we have this elsewhere, e.g. clickjacking
… the answer is Single Domain policies, which is utterly inflexible and unwebby
… we want to have ids that can be safely resolved
… we would like a webby trust model
Hadley Beeman: if we do that, we say this is no longer a user agent (the light bulb)
… you are making an explicit decision that has privacy remifications—you need to be aware of that
Dan Brickley: (mitigation sketches being: parser reports, and web packaging for out-of-band context bundles with integrity checks, e.g. via homehubs etc)
Dan Brickley: I am unaware of any context that is useful and has gone unchanged for more than a few weeks
… we’re stuck between refreshing and getting the best new stuff
… and broadcasting your interests on the web
… but if not, you get out of date
… one thing would be for parsers to report what they’re done
Rob Sanderson: (and we carry on)
Rob Sanderson: (everyone disagrees about the weeks lifecycle, e.g. activitystreams, annotations, ldp, etc)
Dan Brickley: there are a lot of use cases for web packaging, this might connect with that
… your home env might have gotten this through some kind of bundled thing at lower frequencies.
Benjamin Young: you could have an API for updating the lightbulb
… but that can’t work from a pull side, because you can’t guarantee that the identifier will resolve the same way on the open web over time
… bringing us to blockchains, hashing, etc.
… there are lots of potential solutions on the list
… web packaging is one potential solution
Rob Sanderson: do you understand the issue well enough for us to send a ticket to TAG?
Hadley Beeman: what’s the header for this?
Benjamin Young: maybe “integrity”
Hadley Beeman: please write this up with use cases
… because otherwise we’re staying hypothetical
Benjamin Young: there is no requirement to do remote context dereferencing
… but people will
Dan Brickley: there are the specs, then there are ways you relay operate
… with JSON-LD, if you do it wrong, people flame you on the mailing list
… social pressure has forced us to become a component in a larger system—not cool!
Dan Brickley: we’d like people to get what they are expecting when they get contexts
Benjamin Young: many communities have this same problem
… with many different solutions
… that’s what makes it a TAG deal
… another big JSON-LD deployment is Mastodon (uses Activity Streams)
Adam Soroka: .. they haven’t updated their context for a long time
Benjamin Young: but it still works
… which is what makes this a Publishing WG problem—publishing that is broken because a system went down somewhere isn’t publishing as publishers understand it
8. document loading related proposals
Ivan Herman: I think it’s worthwhile to explore an “integrity” expression similar to SRI
… I don’t know how exactly it would be used at the API level
… I also have the expectation that other attributes with similar intent will come along
… but I feel that sealing is definitely not one of those
… and as an aside, our preference is to say that sealing is done within a context file for that context
Adam Soroka: I believe it’s only been context files who have asked us for sealing anyhow, is that correct?
Ivan Herman: yes. only context file authors
… and perhaps we should add to that issue that we could limit sealing to only a context file
… did we also talk about data documents?
Gregg Kellogg: I believe we talked about both
… we could do that for a context or a term definition
Benjamin Young: I still feel like this will result in unexpected behavior
Adam Soroka: syntax based security is false security
Gregg Kellogg: I’d just remove the sealed keyword from someone else context file if for some reason I couldn’t override it
Ivan Herman: so “sealing” does indeed give one a false sense of security
Gregg Kellogg: in Ruby there are private and protected methods
… but there’s also a send method that allows you to use either regardless
Ivan Herman: so. we have not made a decision on that
… but I am happy we have this one the minutes
9. Resolutions
- Resolution #1: add a feature at risk that the implicitly identified graphs will share the bnode with the unidentified member of the graph, on the grounds that the user community most in need of this would expect it, and the community that would be horrified by it better understands the solution of explicit naming
- Resolution #2: add
@datatypefor use with value nodes that would be a synonym only in those situations for@type - Resolution #3: Allow IRIs to be constructed by string concatenation with multiple
@vocabs, with appropriate security consideration section - Resolution #4: Make #56 editorial to add a
"@type":"@vocab"example and otherwise no change - Resolution #5: Add text to Iana Considerations explicitly allowing the request of a context or frame document, plus security consideration on whitelist, plus tests