Dave Raggett dsr@w3.org, W3C Data Activity Lead, December 2017
This study has been made with support from the Open Data Institute and Innovate UK.
The Web has had a huge impact on how we exchange and access information. W3C is the leading standards development organisation for Web technology standards, and has hosted community development of standards for both the Web of pages for use by people, and the Web of data for use by services. This report covers a study of W3C practices and tooling for Web data standardisation. A lengthy questionnaire was used to solicit input from a wide range of stakeholders. The feedback will be used as a starting point for making W3C a more effective, more welcoming and sustainable venue for communities seeking to develop Web data standards and exploit them to create value added services.
The report starts with an introduction to the Web of data and W3C’s standardisation activities. This is followed by a look at the design of the questionnaire and the feedback obtained for each of its sections. After this comes a section on the challenges for measuring the popularity of standards, the need to support the communities that develop and use them, and how to gather feedback that can be used to improve standards and identify gaps where new standards are needed. The report closes with a look at the potential of multidisciplinary approaches including AI, Computational Linguistics and Cognitive Science to transform the process of creating standards, and to evolve the Semantic Web into the Cognitive Web.
The Web is the World’s most successful vendor neutral distributed information system, enabling people to access applications and services right across the World from their smart phones, tablets, laptops and other computing devices. The Web is founded on the three pillars of addressing, document formats and network protocols. For the Web of pages as viewed with Web browsers, this involves URLs for addressing resources accessed by the Hypertext Transfer Protocol (HTTP), and document formats such as the Hypertext Markup Language (HTML), Cascading Style Sheets (CSS), image formats like JPEG and PNG, and Web page scripts using JavaScript.
Complementing the Web of pages, there is the Web of data which ranges from small amounts of data to vast datasets, and either which are open to all or restricted to a few. Data can be consumed by Web pages, downloaded for local processing, or accessed via network APIs that support remote processing. Data is often published without prior coordination with other publishers — let alone with precise modeling or common vocabularies. Standard data exchange formats, models, tools and guidance are needed to facilitate Web-scale data integration and processing.
This report surveys the W3C work in respect to Web Data standards that has already been done or which is ongoing, and looks to the future with a study of the challenges facing communities that are seeking to exploit the opportunities provided by the Web of Data. A lengthy questionnaire was created to elicit feedback from stakeholders across a broad range of topics, including the kinds of data standards of interest, sustainability and governance, scaling challenges, tooling and practices, liaisons, outreach and community building, and miscellaneous feedback on W3C groups. The analysis of this feedback will help W3C to improve its value proposition for communities seeking to develop and exploit Web Data standards, as part of W3C’s mission to bring the Web to its full potential.
This section of the report will look at the different kinds of standards that form the basis for the Web of Data. We will then review the different kinds of standardisation groups at W3C, and the current groups with an interest in the Web of Data.
The principal purpose of standards is to enable interoperability and facilitate the growth in services. Public services including government departments and cities are increasingly making data freely available for interested parties to make use of and add value to. Interoperability depends upon knowing the data formats and the vocabularies used for data items. Some common formats include Comma Separated Values, JSON (JavaScript Object Notation) and XML. To understand individual data items, you need to know their format, e.g. a number or string, and what they represent, e.g. a house number or street name. For values that represent physical measurements, you need to know the units and the scaling factor, as well as what is being measured, e.g. the level of Nitrogen Dioxide pollution at a given street location.
The development of services is simplified if different data providers use common representations for their data. We therefore need a way for data providers to describe their datasets and a means to reference definitions shared with other data providers. These descriptions may include constraints that can be used to validate the data as a basis for checking for internal consistency. Communities of data providers and consumers have a common interest in defining and using such standards. The kinds of standards will vary considerably. Some are community based, whilst others require international agreements involving a more formal approach for how they are developed and maintained.
W3C aims to support lightweight community based standards that can be incubated within W3C Community Groups, and if appropriate, transferred to Working Groups where a formal standards track process is desired, e.g. for core standards where a greater level of scrutiny is needed.
In his 1989 proposal for the Web, Tim Berners-Lee included a diagram depicting an example of a semantic network based upon named resources with labelled links between them.
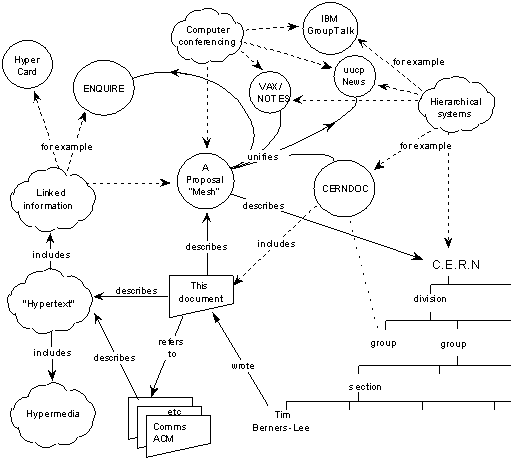
This idea was developed into W3C’s Resource Description Framework (RDF), where URLs are used for both resources and link labels. Each link (also known as a triple) thus consists of URLs for the subject, predicate and object, respectively. The URLs act as both a name and as a means to get further information by dereferencing the URL via an HTTP GET request on the URL. Over the years, W3C has developed a suite of standards around RDF.
Some standards related to the use of RDF to define models, e.g. RDF Core, RDF Schema and OWL. Others define data exchange formats for RDF, e.g. RDF/XML, N-Triples, Turtle, TriG, and JSON-LD. The Linked Data Platform (LDP) defines how to use HTTP for reading and writing triples. SPARQL is a query and update language for RDF analogous to SQL for relational data. SHACL provides a means to express validity constraints on a set of triples.
W3C hosts different kinds of standardisation groups according to the level of maturity of the work in question.
Here is a list of relevant Working and Interest Groups that are now closed:
For more details, see: closed groups
For more details, see: current Working Groups
For more details, see: current Interest Groups
There are many current W3C Community Groups with an interest in Web Data standards:
These groups vary considerably in how active they are and the kinds of opportunities they are addressing. Many groups make heavy use of GitHub for collaborative development of documents, e.g. use cases and requirements, specifications and test suites, primers and other introductory materials.
For more details, see: W3C Community Groups
The Web of Data has been growing steadily. One measure of this is the Linked Open Data Cloud diagram. Here is the May 2007 version:
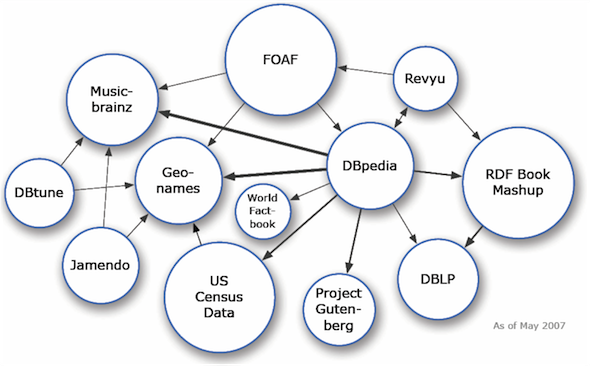
The 2017 version is shown below indicates the rapid growth in open data over the last 10 years. It was created by Andrejs Abele, John P. McCrae, Paul Buitelaar, Anja Jentzsch and Richard Cyganiak. See http://lod-cloud.net/
The diagrams above show datasets that have been published as Linked Data using HTTP in a variety of RDF data formats. Web Data is also available in other formats, e.g. JSON, Comma Separated Values (CSV), and embedded in PDF. The ability to integrate different data sources is dependent on standards for both the data formats and the data models along with the means to relate terms in different datasets.
The emergence of the Internet of Things is resulting in an increasing amount of data from a wide variety of sensors. Much of this is using incompatible platforms and standards, resulting in data silos. Over time the demand for services that combine different data sources will help to drive demand for open standards. This will in turn facilitate open markets of data and services and this will further drive demand for data. Another source of vast amounts of data is the scientific community combined with interest in virtual research environments.
It is easy to coordinate and work on a shared vocabulary if there is a small well knit community. However, it becomes very much harder as the community size grows, and when there are uncoupled or only weakly coupled communities. It is therefore inevitable that different communities will develop rival vocabularies, and that these will address different or perhaps overlapping requirements due to differences in the context. Some use cases may call for a greater level of detail than others. This can make it cumbersome for simpler use cases. When integrating data from across such vocabularies, it becomes challenging to relate terms from the different vocabularies. One example of this is where units of measure are needed for sensor readings. The abbreviations are not universal and may have different meanings in different fields.
Another challenge relates to dealing with evolving APIs. In some cases, this may just be a matter of ignoring named arguments that a given software client doesn’t know about. In other cases, there may be a need to negotiate over which version of the API is used so that a server is able to support both current and legacy clients.
The questionnaire was designed to address a broad range of questions and this resulted in a long form that took a considerable time for respondents to fill out. I am extremely grateful for the time they devoted to this. Where practical multiple choice questions are used to facilitate the generation of graphical presentations. However, the breadth of stakeholders makes it impractical to cover everyone’s specific choices, so the questionnaire makes a lot of use of free-form text fields for open ended questions. This report provides a summary of the points covered in the free-form text fields, along with a preliminary analysis. This questionnaire is just the first stage, and the idea is to follow up with a broader discussion as to the choices available to make W3C a better venue for communities to work on Web data standards.
The questionnaire was created to elicit feedback from stakeholders across a broad range of topics, including the kinds of data standards of interest, sustainability and governance, scaling challenges, tooling and practices, liaisons, outreach and community building, and miscellaneous feedback on W3C groups.
The questionnaire was not limited to W3C Member organisations or people involved in W3C Community Groups. The questionnaire was publicised via a W3C blog post, and emails to all of the relevant W3C groups. People were encouraged to spread the word further using their social connections.
The questionnaire starts with a section titled “About you” which ask for the respondent’s name, email address, organisation, organisation’s website and primary location (country) and the organisation’s interest in data standards. The name and email address were asked in order to be able to contact the respondent in case of any follow up questions in regard to the input provided by the respondent using the questionnaire.
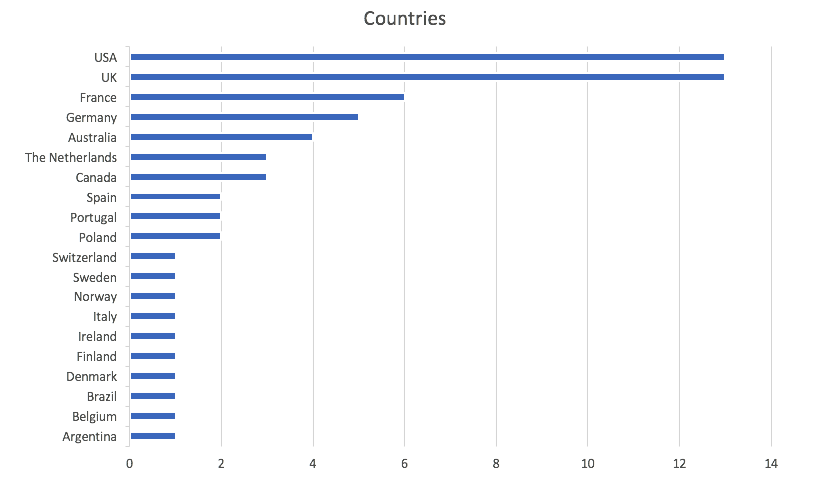
Here is a chart for the countries provided by respondents. The question used a text field, and this resulted in people using different name for the same country, e.g. US, USA United States. The data thus required some post processing.
The following organisations contributed to the questionnaire results:
Several people responded independently on their own behalf.
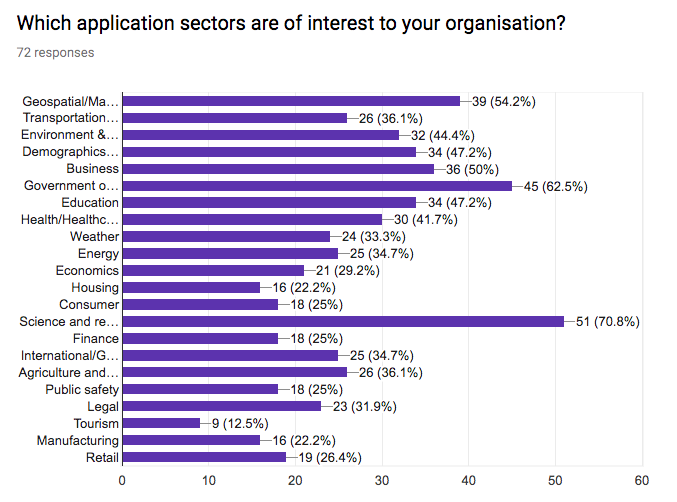
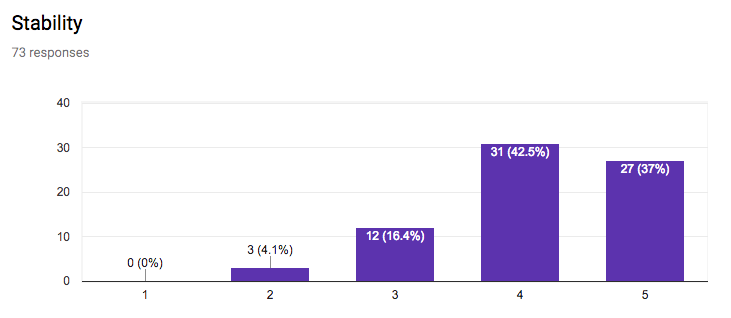
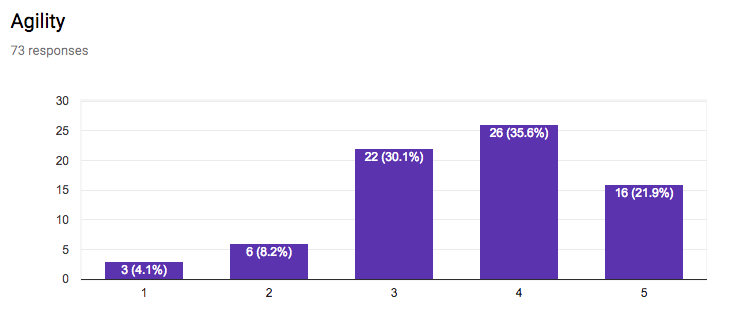
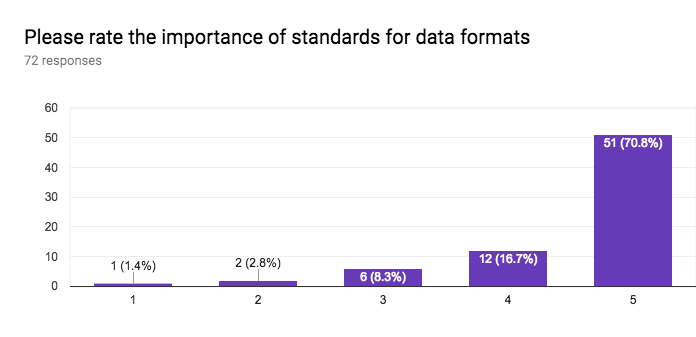
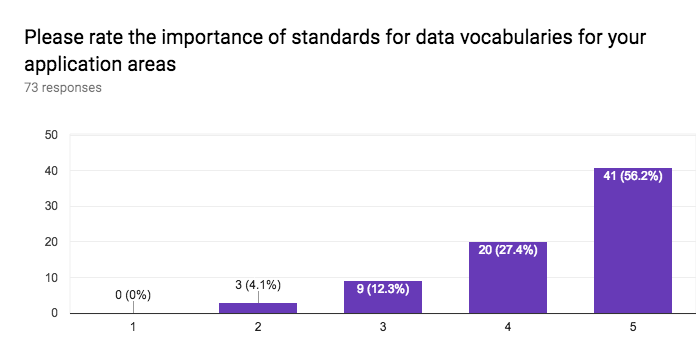
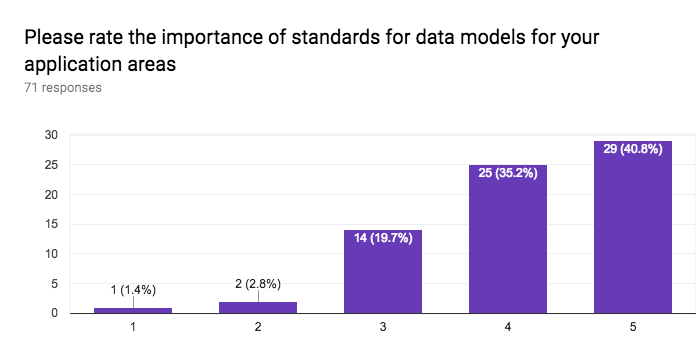
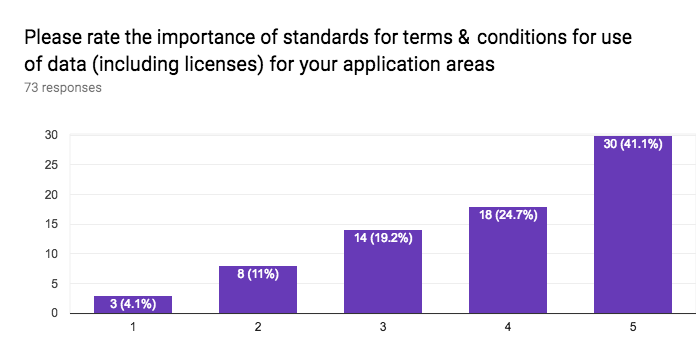
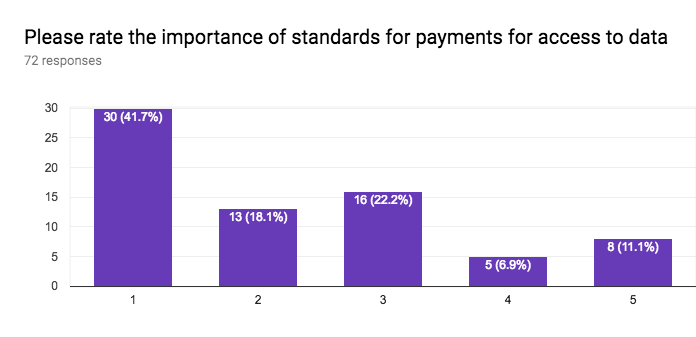
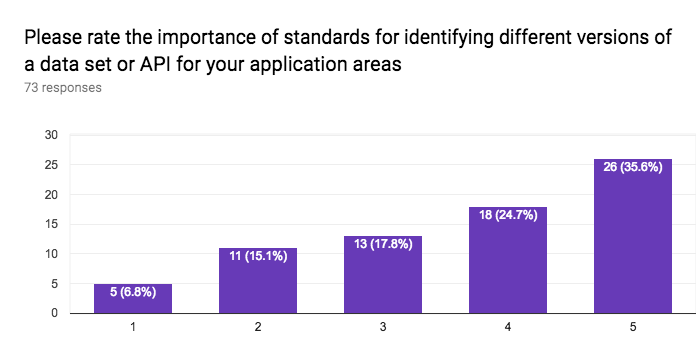
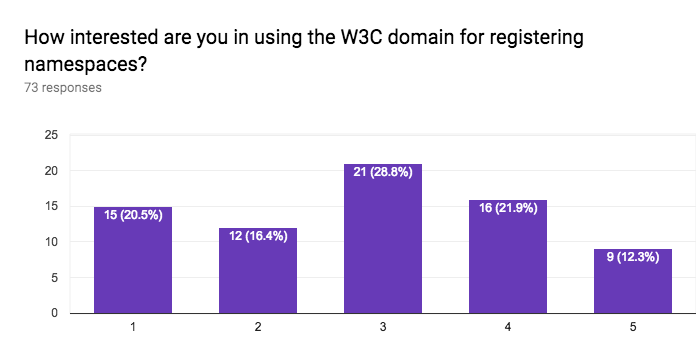
This section of the questionnaire gathers information about the interest in application sectors, approaches to data access, approaches for discovery of data and services, stability vs agility of standards, the importance of standards for data formats, data vocabularies, data models, terms & conditions (licenses), privacy policies, payments, versioning, longevity of standards, the role of W3C for registering namespaces, and internationalisation.

This section of the questionnaire considers how to fund and oversee the social and physical infrastructure needed to support standardisation.
Ad hoc short lived industry alliances funded by their consortium partners for specific needs - Some see this as a short term solution, but not reliable enough for standardisation work, but could be a nice addition if there is other, more reliable funding for sustainability and long term maintenance. Pro: quick and focused, Con: broader interoperability may be at risk. Tends to be brittle in face of changing business priorities.
Standards groups that are free to participate in, but require annual fees to be in the steering group or on the management board, along with greater visibility on group web pages, etc. - This makes it easy for small to medium sized enterprises (SMEs) to participate at the expense of giving larger organisations greater influence. There is a risk of increased business politics as companies lobby to get their way. Respondents are mixed in their like and dislike for this model of funding standards work.
Annual fee to belong to a standards development organisation, with no limits on the number of groups your organisation can participate in - This is how W3C currently operates in respect to Interest Groups and Working Groups, where the fee scales according to an organisation’s revenue and type. It can be onerous to get approval to pay the membership fees. Most respondents are comfortable with this approach to funding standardisation.
Advertising based sponsorship of standards groups - This is how many free to use web services are funded. Pro: solid source of revenue. Con: for some organisations the advertising will be an issue requiring consideration, given the curation that is likely to be enforced by W3C should not be a real issue but may be a perception problem. Most respondents weren’t keen on this approach to funding standardisation.
Sponsorship of standards meetings, workshops, interoperability testfests, etc. - This is a similar approach to advertising, and already used by W3C to avoid or lower attendance fees for events, including the all-groups meeting (TPAC) and W3C Workshops. This question invites respondents to comment and it is interesting to note that sponsorship of events is much more acceptable than including advertisements as part of the tooling for developing standards. Respondents are generally comfortable with sponsorship provided it follows regular norms for transparency, etc.
Fees for registering namespaces and hosting resources for standards - This would help to fund the costs for managing and hosting namespaces and associated resources on W3C servers. These resources include RDF and HTML documents as well as server configuration files. A beneficial side effect is the ability to observe the level of interest in terms of server hits. A downside is that this could put off many potentially interesting vocabularies done by independent groups or researchers. Some respondents were comfortable with this approach provided there is careful consideration to the fee structure. Others didn’t like the idea. A variant of the sponsorship approach is to seek endowments and voluntary contributions to support operational costs just like wikipedia. Of course this leads to the regular nuisance of the funding drives.
Fees for accessing resources for standards, e.g. specifications - This approach is used by ISO and other standards development organisations. W3C makes its standards (W3C Recommendations) available free of charge. The majority of respondents agree that access to specifications and related resources should be free of charge.
Fees for certification of compliance to standards - Organisations may find it beneficial for their sales team if their platform has been certified as complying with the standards it supports. This reassures customers as to the interoperability of the platform with others, and reduces concerns about being locked into a given vendor. W3C has considered a certification programme in the past, as a means to encourage interoperability as well as providing a funding stream. However, the costs of launching and managing such a programme are considerable. Respondents are comfortable with this approach provided it is thought through, e.g. fees should be differentiated according to factors such as public/private entities, size of the datasets, etc.
Other suggestions in respect to sustainability and governance - A standards development organisation could offer other services, e.g. training and consultancy, as a means to subsidise operations. Transparency and governance are important factors for effective standards development organisations.
This section invites respondents to comment on and provide suggestions for how to address scaling challenges for developing and maintaining data standards.
Encouraging sharing across weakly or uncoupled communities - People working in the same community gradually evolve a common mindset and language when it comes to the use cases they consider, and to the approaches they address or ignore. It is common for close knit communities to leave as implicit the assumptions they are working with, which can make it hard to communicate effectively with other communities. Respondents were asked what experience they had of this, and which approaches proved to be effective at countering it? It helps when groups can write in ways that are accessible to people outside of their group. This includes use cases, demos and assumptions. If groups are using different tools that can create a barrier. The ease of discovering work by other groups is a factor where having a common framework helps. The Web is valuable in supporting hyperlinks. Building a common understanding can be expensive when it involves the need for face to face meetings. People often prioritise their own work over the need for liaisons and outreach as needed to bridge communities.
Why are you reinventing the wheel - There is often social pressure to adopt another community's solution, but this can lead to resentment when the requirements turn out to be sufficiently different as to make the suggested solution a poor fit. This can lead to misunderstandings and a breakdown of trust. One dimension is the perceived complexity when one community feels that the other community's solution is overly complicated and too burdensome. In some cases, a central authority can impose order, but only at a cost of inefficient solutions that fail to match market needs. What steps can be taken to mitigate this? Ameliorating factors include effective outreach to share and discuss alternative approaches and their pros and cons. This can include tutorial materials, the use of lightweight profiles of complex standards, an easy and rapid means for companies to request updates to meet new needs, in order to avoid the temptation to create their own standards for greater ease of control, despite the interoperability problems that this is likely to entail. Modularity and ease of understanding helps. Less experienced newcomers tend not to realise the subtleties that drove the design for mature standards, so these need to be made apparent.
Mapping between different vocabularies - What are the approaches for mapping between different vocabularies as defined by different communities with somewhat overlapping requirements. One potential approach involves "upper ontologies" with very general terms that are applicable to the different communities. Another approach is to use rules that define how terms in the different vocabularies relate to each other in specific contexts. This may involve some form of fuzzy reasoning. Respondents were encouraged to discuss the pros and cons of different approaches and their implications for standardisation. Ontologies can provide shorthands for commonly used rules, but are not enough to address the diversity of requirements. Converging on a simple, sufficient rules language would be very helpful. RDF is often seen as too complex and finding simplifications would be helpful for wider adoption. Upper ontologies often complicate more than they help. Mapping may be challenging when the semantics aren’t sufficiently clear. Fuzzy matching is worth looking at and relates to rules that map terms in specific contexts. The best mapping may depend on what you’re trying to achieve.
This section of the questionnaire gathers feedback that will help W3C review the tools available to standardisation groups and the associated practices. As an example, W3C groups have made increasing use of GitHub for collaborative specification development, despite GitHub being originally designed for software development teams.
Use of GitHub - Widely used, but quite cumbersome and hard for non-programmers with a steep learning curve, though GitHub issues are well liked. This creates a barrier to contributions. Some concerns about potential risks for depending on GitHub as a long term system.
Use of wikis - Most W3C groups have access to wikis for their work if they choose to use it. Wikis are declining in use at W3C compared to GitHub markdown documents. Wikis can be challenging to maintain as they scale up, and are often out of date.
Use of teleconferences - Most groups use frequent teleconferences with a variety of systems, e.g. W3C’s WebEx, GoToMeeting, Zoom, Skype, Hangouts, Mattermost, Bluejeans, Viju, VideoNor. Time differences are a problem for international meetings. They may set a limit on the duration of the meeting or the engagement of certain parties. Connectivity can also be an issue, as well as feedback and background noise.
Use of remote screen sharing - Many online teleconferencing services offer screen sharing based on copying the screen pixels. This isn’t accessible to people with visual impairments. Respondents were asked how they use screen sharing, and what they do in respect to the accessibility issue. Screen sharing is only relied on by a small fraction of respondents. One work around for accessibility is to ensure that slides and other presentation materials are shared first through other channels, e.g. email.
Use of shared document editing - E.g. Google docs, Confluence, Etherpad and WebODF, which allow for collaborative online editing of shared documents. This is popular for making rapid progress on documents, but as the document stabilises, groups tend to switch to GitHub for more formal change tracking and editorial control. Collaborative editing is great for live meeting minutes, and sharing ideas. However, there are concerns about long term persistence and history.
Use of testbeds - Some groups use testbeds, but others don’t. Testbeds are seen as valuable for testing ideas to be included in new or revised standards. Testbeds are related to demonstrators as a means to provide concrete examples for learning and getting up to speed. Tests can be used to explore edge cases in proposed standards.
This section of the questionnaire sought input on the work done on reaching out beyond the standardisation group as a basis for successful standards.
External industry alliances and group - Some but not all groups liaise with industry alliances and external standards development organisations. Liaison may be left to group members, but it is often seen as important to the success of a group’s aims.
Other W3C groups - Some groups work on their own, but others liaise with relevant W3C groups. This can help with achieving successful outcomes to a group’s aims.
External events - Some groups regularly participate in external events to promote their standards work, e.g. presentations, panel sessions and demos at conferences and workshops. This is often done on an individual basis. Plugfests are another way to encourage interest.
Social media - Some groups use social media for outreach, e.g.Twitter, Blogger, LinkedIn, Facebook, Instagram and YouTube. This may involve some level of discipline and care over message points. Other groups recognise the potential and would like to set up to using social media to spread their message.
Soliciting feedback - This question focused on how groups solicit feedback e.g. on improving or extending standards. Respondents say they use email, GitHub (issues and pull requests), Blogs, Tweets, Wiki pages, social media.
Use cases - Some but not all groups gather and publish use cases for their work, whether as markdown documents on GitHub or as formal reports. Use cases are seen as important for creating a consensus around the scope of new standards.
Best practices - Some groups collect and publish best practices for use with their specifications. The W3C Data on the Web Best Practices is cited as a good example.
Education and training - Some groups would be interested in working with W3C to deliver education and training relating to the group’s aims. W3C has now had several years of experience with providing online courses. This could also provide an additional funding stream to support standardisation activities.
In this final section for the questionnaire, respondents were asked to describe which W3C groups they are involved in, what is working well, what problems they’ve seen, and their suggestions for improvements.
How successful are standards? To answer this question we need a way to measure the level of interest in particular standards. At the time this report was written W3C has done surprisingly little on measuring interest in standards.
One approach that could be implemented with modest resources would be to exploit the W3C website server logs, and to look at the requests for W3C technical reports and other documents from Working Groups, Interest Groups, Community Groups and Business Groups. W3C’s privacy policy states that W3C does not track users for behavioural tracking. Client IP addresses, and the HTTP Referer and User-Agent fields are logged to allow traffic to be analysed. The collected data is only used for server administration, site improvement, usage statistics, and Web protocol research.
The Webmaster helped with the analysis of the server logs for a select of URLs corresponding to W3C technical reports relevant to Web data standardisation. In keeping with the privacy policy IP addresses are only kept for a relatively short period of time - a quarter of year. This allows us to look at the popularity of different technical reports, and to see from which countries the requests were from.
The following figure shows the number of times each report was requested in the period covered (August - November 2017).
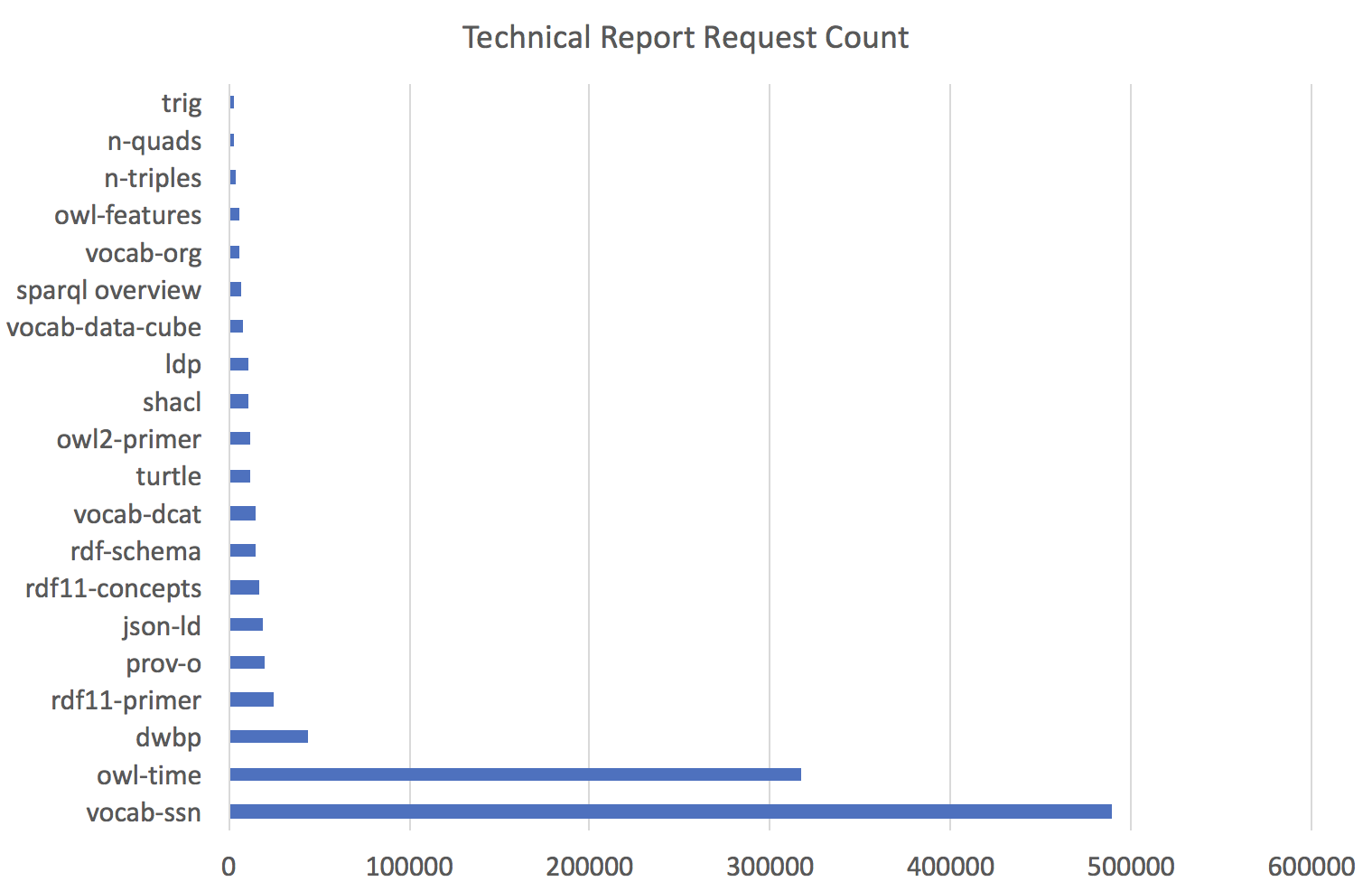
One observation is that the huge popularity of the Semantic Sensor Network ontology (vocab-ssn) and the Time Ontology in OWL (owl-time) is due to both them becoming W3C Recommendations in the recent past. The Shape Constraint Language (shacl) became a W3C Recommendation three months earlier, and has a similar download count to many other Linked Data technical reports. This suggests that reports are initially very popular but this rapidly decays away to a background level. There are exceptions, e.g. the Data on the Web Best Practices (dwbp) which shows persisting popularity, To track popularity patterns, W3C would need to regularly record the request counts for each technical report, e.g. on a monthly basis.
Another observation is that JSON-LD is more popular than other Linked Data serialisation formats, and is followed by Turtle. Other Linked Data formats such as n-triples and n-quads are much less popular. JSON-LD defines a way to use the JavaScript Object Notation (JSON) to represent Linked Data. Its relative popularity points to the huge popularity of JSON amongst web developers, superseding the previous high levels of interest in XML.
The Geolite2 dataset was used to derive the country from the client IP address as a basis for assessing which countries were most interested in Web data standardisation. The results show a very long tail of countries with small download counts. Take for example the Semantic Sensor Network ontology. This is most popular in the USA (88932 downloads), followed by China (65703), UK (38430), Netherlands (25625), France (25000), Germany (24541), and fading to a single download for South Sudan, and the Central African Republic. Here is the data as a pie chart, note that there were downloads from 214 countries, not all of which are listed due to lack of room. The mapping isn’t perfect with IPAddressnotfound and Republicof as cases where the algorithm failed to work correctly.

Further work is needed to figure out a sustainable solution for collecting such statistics across the W3C site on a long term basis and presenting the results in a way that can inform decisions on how W3C invests its limited resources.
The level of interest in Web data standards could be tracked in other ways, for example, citations from websites and research publications, and by providing a registration form for users. To make it worthwhile for users to register, this could be tied to a community based support service for W3C specifications. Community maintained support services are increasingly popular with companies as a way to provide good quality support at a lower cost. SMEs and independent consultants can benefit as their reputation as contributors boosts their business opportunities. Further investigation is needed on the detailed requirements and investment needed to kick start this approach.
As more and more people want to provide or consume data on the Web, this will increase the demand for open standards for data vocabularies. People will for the most part be interested in using existing vocabularies where appropriate. The challenge is then how to discover and assess such vocabularies, especially when they have been developed by isolated communities. Adopting an existing vocabulary has its risks - the vocabulary could have been designed for different requirements and be overly cumbersome in a different context or fail to adequately cover the chosen use cases.
A related challenge is that people from a like minded background tend to think in similar ways, and have a tendency to not make their shared assumptions explicit, instead going directly into the details of the solution they envisage. This makes it hard for other people from different communities to evaluate a given vocabulary to see if it is a good fit.
The Web is World wide, but people may be separated by living in different countries, having different languages, or working in different industries. With uncoupled or weakly coupled communities, and only partially overlapping requirements, we can expect the emergence of vocabularies that play similar roles, but which aren’t directly compatible. This creates challenges for services that need to integrate data from multiple such vocabularies.
In the simplest case, a term in one vocabulary can be declared as the same as a term in a different vocabulary. More generally, a term in one vocabulary might be declared as equivalent to a graph in another vocabulary. For instance, a single term might be used to indicate a combination of a unit of measure and a scaling factor, e.g. milliamps for electrical current. A second vocabulary could express these separately.
More generally still, terms may be relatable only in specific contexts. This can be compared to human languages, e.g. the words used for water ways such as rivers, streams, brooks, etc. where the taxonomy of words in different languages don’t have a direct correspondence. For instance, to pick the right word, you may need to know if the river in question flows into the sea or merges into another river.
This suggests the need for a way to describe how to transform Linked Data graphs to replace one vocabulary with another, potentially with some form of defaults when required. This is something where experimentation is needed, and should lead to open standards for Linked Data transformation languages. Is this something that W3C should be driving, and if so, how?
Another approach involves so called “upper ontologies”. These define domain concepts in terms of underlying general concepts that are applicable across domains. It can be challenging to understand how to relate domain specific concepts to these very general concepts, and likewise to implement software that can take advantage of these definitions.
The difficulty of manually creating complex ontologies can in principle be avoided through the use of machine learning algorithms that are applied to a training corpus. One approach for this makes use of a synthesis of cognitive science, AI, computational linguistics and sociology, building upon progress in each of these fields, enabling conversational cognitive agents that can be trained and assessed using lessons expressed in natural language.
This necessitates a means to translate natural language into semantic graphs, and back again for natural language generation. Cognitive architectures like John R. Anderson's pioneering work on ACT-R have proven themselves in terms of replicating common characteristics of human memory and learning. This points to opportunities for extending Linked Data with persistent link strengths and exponentially decaying node activation levels. Procedural knowledge can be expressed using production rules, and trained using reinforcement learning algorithms.
Cognitive agents will require support for episodic memory and counterfactual reasoning (i.e. knowledge about what/when and what/if), both for learning from narratives and as a means to support a level of self-awareness as a basis for monitoring progress and deciding when to switch to different ways of thinking, the importance of which has been emphasised by Marvin Minsky.
Linked Data uses explicit concepts with nodes connected by labelled arcs. This makes it easier to provide explanations as compared to approaches based upon artificial neural networks and deep learning. However, Linked Data can also be represented using vector spaces and tensor expressions for implementations based upon neural networks. Much remains to be done on exploring how to apply vector spaces to rich graph representations and procedural rule sets, and there is considerable potential for addressing the statistical basis for reasoning in terms of what has been found useful in past experience, as compared with the emphasis on logical inference and completeness found in conventional approaches to ontologies. This is also relevant to mimicking the human ability to track changes in the meaning of words based upon their patterns of usage.
In the long term, this can be expected to change the nature of standardisation from a direct consideration of linked data vocabularies to the curation of a corpus of training materials as based upon an agreed set of use cases. At its simplest, this involves examples and counter examples for data fields, as input to a machine learning algorithm. Natural language descriptions could be used to relate data fields to what they represent, e.g. the address of a house or flat. Such descriptions can also be used to define taxonomies of terms including generalisations and exceptions. There has been plenty of work on extracting named entities from text, but so far much less on understanding narratives as would be needed for natural language descriptions of use cases.
The opportunities for data on the Web are huge, both for publicly shared open data, and for data exchanged business to business. This potential is critically dependent on standards to enable interoperability, to reduce the effort and risk involved, and to unlock the network effect. This study of W3C practices and tooling for Web data standardisation has gathered feedback from a wide range of stakeholders on many different aspects of standardisation.
The rise of the Internet of Things will accelerate the need for work on standards for vocabularies that describe devices, services and the context in which they are situated. Likewise, for the rise of open data published by governments and other organisations, including the availability of scientific data for virtual research environments.
There are many challenges to be overcome, e.g.
There is a lot to improve from the current status. The W3C home page for the Web of Data needs revamping and bringing alive with regular news posts and links to useful resources. The Web of Data needs greater visibility both within the W3C Team, W3C Members and the public at large. Whilst the W3C Community Groups programme has been very successful with a large number of groups, there is a lack of guidance for communities interested in developing standards. For W3C to step up to the challenge of the huge potential demand for community standards, new approaches will be needed to sustain the level of resources needed.
Web developers often express negative sentiments about the Semantic Web, and this can in part be attributed to a them and us attitude in respect to people working on Linked Data and the Semantic Web. It is not helped by the perceived complexity often associated with OWL ontologies and the esoteric focus of much of the published work. This gulf needs to be filled by a greater focus on simpler approaches that are a good fit to the use cases of interest for Web developers. A community supported forum aimed at Web developers for exchanging information on use cases and accounts of how they were solved in a simple way would be a big help.
This study will be used as a starting point for further discussion on how to improve the services that W3C Data Activity offers for communities interested in developing Web data standards.
What kinds of new standards are needed for accelerating the adoption of data on the Web? This includes metadata standards, e.g. relating to privacy, terms & conditions, machine interpretable licenses, and payments. To assist with discovery, there is a need for websites to be able to describe data services in a standard way that facilitates indexing by search engines. This could be done in collaboration with schema.org. W3C is already working on updating the Data Catalog Vocabulary as a basis for describing datasets (see Dataset Exchange WG), but there is a gap when it comes to discovery of network APIs. There are existing solutions for describing RESTful APIs, but these focus on the data types rather than the semantics. The work on thing descriptions in the Web of Things Working Group seems relevant, along with fresh ideas for mapping JSON to Linked Data. Is there a need for a meta vocabulary to facilitate discovery of vocabularies? Another area ripe for investigation is the potential for a new standard for a rule language for context based mappings between Linked Data vocabularies with partially overlapping semantics.
What should W3C be doing to better support Working Groups and Community Groups? This could include better guidance about how to run effective Community Groups and advice on the different kinds of standards and how to incubate them and progress them along the standards track. What could W3C do to give Community Groups greater control over their home pages? What is needed to support training and outreach as part of the process of building momentum around new standards at various stages in their lifecycle. What changes to how groups are formed would provide the resources needed to provide better tooling? Is there a role for community maintained support services as part of this? This could include tools for facilitating sharing of advice and experience across different community groups. As data on the Web expands to cover new areas, what can W3C do to make it easier for communities with related goals to discover each other? The current study described in this report should be seen as a precursor to an ongoing dialogue to discuss the many questions raised. Perhaps it is time to consider organising a W3C workshop on how to better address the challenges of developing and supporting Web data standards? This could be co-organised with other organisations with shared goals, e.g. the Open Data Institute, and is likely to involve the need to find sponsors to cover some of the costs of running the workshop.
Grateful acknowledgements are due to the Open Data Institute and Innovate UK for funding this study. I would especially like to thank Leigh Dodds (ODI) for his efforts in coordinating the project and introducing me to others working on different aspects of data standardisation.
$Id: index.html,v 1.29 2018/01/04 16:22:27 coralie Exp $