Warning:
This wiki has been archived and is now read-only.
Data Quality Vocabulary (DQV)
A very early draft of the DQV conceptual scheme is provided in the following. It includes some of the basic requirements that have been discussed in the group so far. This concept scheme is just a first guess, which is expected to serve as a reference for internal discussion and, as a consequence, it is likely to change, to be refined or even be replaced with an entirely brand new schemas resulting from future discussions.
Contents
Concept schema
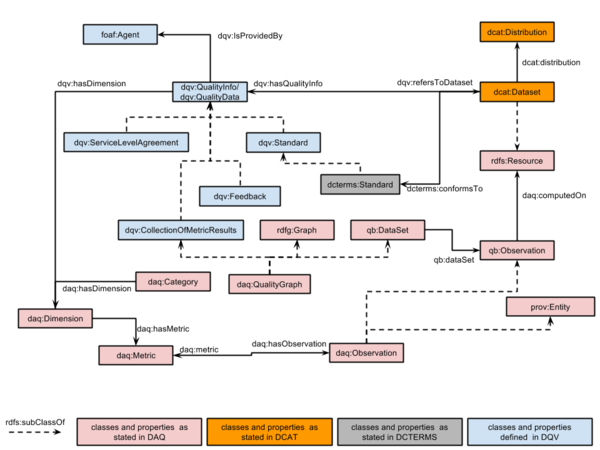
Requirements/group agreements considered in this early draft
- the adoption of DAQ as starting point especially to represent quality dimensions and computed metrics.
- the need that other representations of quality are somehow considered besides computed metrics, e.g., we should be able to say that the quality is described in an SLA (see related action), or the data set is compliant to a given "standard", best practice set ect.
After we get a kind of minimal agreement on this early data quality vocabulary, it shouldn't be very difficult to extend and refine the schema in order to meet most of the requirements listed in Requirements From FPWD BP and Quality Requirements From UCR
Design Issues
dqv:QualityInfo and its specialisation
dqv:QualityInfo is an abstract class, which can be specialised in different kinds of concrete ways to express quality information about a DCAT dataset. Each kind of dqv:QualityInfo refers to a dcat:Dataset, is provided by a foaf:Agent, and must refer to one or more quality dimensions (daq:Dimension). Quality info specialisations include
- metric-based (dqv:CollectionOfMetricResults) which is an collection of metrics result encoded in the DAQ-like fashion,
- association with a Service Level Agreement (dqv:ServiceLevelAgreement),
- statements pertaining datasets compliancy to standards (dqv:Standard),
- feedbacks about the datasets, feedbacks might include also issues that have been found by consumers (dqv:Feedback) .
others kinds of specialisations can be figured out as long as we go further in the design discussion.
The rationale behind a dqv:QualityInfo subsuming all the specialisations is to answer to question like “are any quality information associated to a dcat:dataset? what kind of quality information? what dimensions are discussed mentioned in the quality info?”
Among the issues to be addressed:
is dqv:QualityInfo the most appropriate name? would be dqv:QualityMetadata more appropriate?
[christophe:] a possible alternative could be dqv:Qualitydata.
[antoine:] QualityMetadata is my prefered by far. It allows us to inherit whatever BP will have been defined for metadata in the rest of the group's work. Especially, we could spare all work on representing provenance of quality data, because there must be BP defined for provenance of metadata in general. In other words this would allow us to put aside some the of the requirements that Riccardo had identified here (and which we had agreed to put aside)
are there other kinds of quality info that is worth to consider? e.g., opinions, report of known issues, ...
[chistophe:] why we don't check in Data Usage Vocabulary ?
[riccardo:] so far, we have added dqv:feedback ( see issue-165 )
how the service level agreement can be represented? it is a document on the web to refer to or we want to refer to something more structured? is there any specific property we should add to dqv:ServiceLevelAgreement?
[christophe:] According to (1) "An SLA is best described as a collection of promises". It is also a document which just lists a couple of things. We could either focus on the document aspect as a whole or try to model the list of promises and the list of related concepts. My gut feeling is that this could lead to writing an elaborated vocabulary that would span out of our scope so I'd say we should rather not do that. But we should nonetheless anticipate that someone may some day want to work on that.
What about then either not indicating any range or set Resource as a range ? Then everyone is free to model an SLA as he wants. And in the BPs would could hint that structured data is better and a PDF also ok.
[riccardo:] Very good point! I agree on leaving it open to further modelling of promises by explicitly mention this possibility, it sounds like a very good idea. Concerning your proposal to not indicating any range or set Resource as a range, I think we should at least suggest a concrete unique way to include a sla human readable descriptions, so that people don't have the chance to be too much creative attaching their html, pdf or whatever in the quality-related metadata.
how standard are represented under dqv:Standard? is the class dqv:Standard suitable to include ODI certificates, to represent that a DCAT dataset has a certain compliancy to 5 LOD stars, and other kind of bets practices?should we explicitly provide a list/taxonomy of standard/ certificated to consider? is the class dqv:Standard really necessary or we can rely directly on dcterm:Standard?
[christophe:] We should be flexible here. If we impose a specific class then ODI certificates and 5star models will have to subclass from it, so we should make it generic enough conceptually so that this works. To that respect I think dcterm:Standard is quite nice so we may want to re-use it. Or subclass from it our own Standard which is a verbatim copy of it in case some day the meaning of dcterm:Standard changes in a way that brake our vocabulary.
can we assume the following constraint ?
x a dcat:Dataset. x dcterms:conformsTo y imply x hasQualityInfo y. y dqv:Standard
[Christophe:] Think so. We should have more of these BTW :-)
dqv:CollectionOfMetricResults
is DQV connected to DAQ in the correct way? we have extended dqv:CollectionOfMetricResults with qb:DataSet instead of daq:QualityGraph because I remember some use case explicitly asking for statistics as quality information. Is that reasonable?
[christophe:] I don't see why the collection of metrics has to be a qb:Dataset
[riccardo:] daq:qualityGraph is now a direct specialisation of our dqv:CollectionOfMetricsResults ( I have opened the issue-164 to remind that we should discuss if dataset metrics are a kind of quality info and how to include them in the DVQ)
in the DAQ examples it seems that the actual rdf file is associated to each qb:Observation through daq:computedOn. However, in principle, having daq:computedOn ranging on rdfs:Resource, anything can be associated to qb:Observation through daq:computedOn. I’d like to have qb:Observation associated to a dcat:Dataset. Does it make sense? If it makes sense having “computed observation” forced to be connected to dcat:dataset, can we impose the following constraint
?x a dqv:CollectionOfMetricResults. ?x daq:dataset ?y. ?y daq:computedOn ?z iff ?x dqv:refersToDcatDataset ?z. ?z a dcat:Dataset
dcat:Dataset
dqv:QualityInfo is connected to dcat:Dataset, I have chosen dcat:Dataset, because this choice is the most coherent with the discussion we have had in the group so far.
- At the same time, I think that different distributions might have quite different quality, and depending to the kind of format adopted in the distribution also different metrics might apply. So I would suggest to put dqv:QualityInfo connected to both dcat:Dataset and dcat:Distribution, or alternatively, we might even add a class , let say a dqv:Dataset which subsumes both dcat:Dataset and dcat:Distribution?
- For those datasets that are in the LOD, I would like that the quality information are somehow connectable with DCAT and VOID. I think we should also reflect a little about the relation between VoID and DCAT: VoID is for data in RDF format, whist DCAT is neutral with regards to format, but it is not clear to me if we can consider void:Dataset as specialisation of dcat:Dataset or of dcat:Distribution or something completely separated from DCAT.