Warning:
This wiki has been archived and is now read-only.
ProvenanceExampleAndConcept1
WARNING: following the May 05 teleconference, it was agreed that the example would be made less technology specific. So, this page is kept for archival. Instead, please read ProvenanceExample.
This page was introduced in an email to the list on April 30th.
Contents
- 1 Provenance Concepts and Example
- 1.1 Data Journalism Example
- 1.2 Provenance Graph
- 1.3 Provenance Concepts from the Charter
- 1.3.1 1. Resource
- 1.3.2 2. Process execution
- 1.3.3 3. Recipe link
- 1.3.4 4. Agent
- 1.3.5 5. Role
- 1.3.6 6. Location
- 1.3.7 7. Derivation
- 1.3.8 8. Generation
- 1.3.9 9. Use
- 1.3.10 10. Ordering of Processes
- 1.3.11 11. Version
- 1.3.12 12. Participation
- 1.3.13 13. Control
- 1.3.14 14. Provenance Container
- 1.3.15 15. Views or Accounts
- 1.3.16 16. Time
- 1.3.17 17. Collections
Provenance Concepts and Example
The purpose of this page is twofold:
1 First, it presents a working scenario that exposes interesting provenance issues and that can be used to focus discussions of the WG
2 Second, it aims to illustrate key concepts identified in the Provenance WG charter by means of the example, so that WG members can build a shared understanding of provenance-related terminology
Presentation is deliberately informal to open the debate among WG participants. It also raises an initial set of issues for consideration by the WG. To get the ball rolling, the example contain little details about the Web architecture that underpins this application; these need to be further explored.
Issue: for each concept, agree on terminology
Issue: find a name for the model
Issue: expose architectural elements of the Web
Data Journalism Example
Outline
An online newspaper publishes a story making using of RDF data (GovData) provided through a government portal. The government portal not only makes the data available but also publishes how the data was generated. The newspaper publishes a story with a chart (i.e. a jpg) based on GovData. The story includes in the byline both the authors of the story but the creator of the chart as well. To be transparent, the newspaper publishes the provenance of the chart including where it got the data from but also what tools and assumptions it used to create the chart. This also contains a link to who created the chart. Importantly, because the GovData is in the public domain, the newspaper retains the copyright to its chart but does not own the underlying data.
A blogger looking at the chart spots what he thinks to be an error. Using the provenance, he is able to trace back the error not to the newspapers processing but an error in how the government translated the data into RDF. However, that error had been spotted and fixed by the government portal. The blogger is able to publish a new chart that is correct and gives it an open license. Thus, when searching for information on the story a user can find which figure is based on newer data.
Processing steps
- government converts data to RDF
- government publishes RDF data on a portal with a license
- newspaper downloads RDF from government portal
- newspaper generates a chart from the RDF using some software tools with statistical assumptions
- newspaper publishes the chart within a document includes a license
- blogger downloads data from government portal, determines that it's a different version of the same data
- blogger generates new chart based on the data
- blogger publishes the chart under an open license.
Provenance Graph
A provenance graph corresponding to the previous scenario can be represented as follows. File:ProvenanceGraph1.pdf
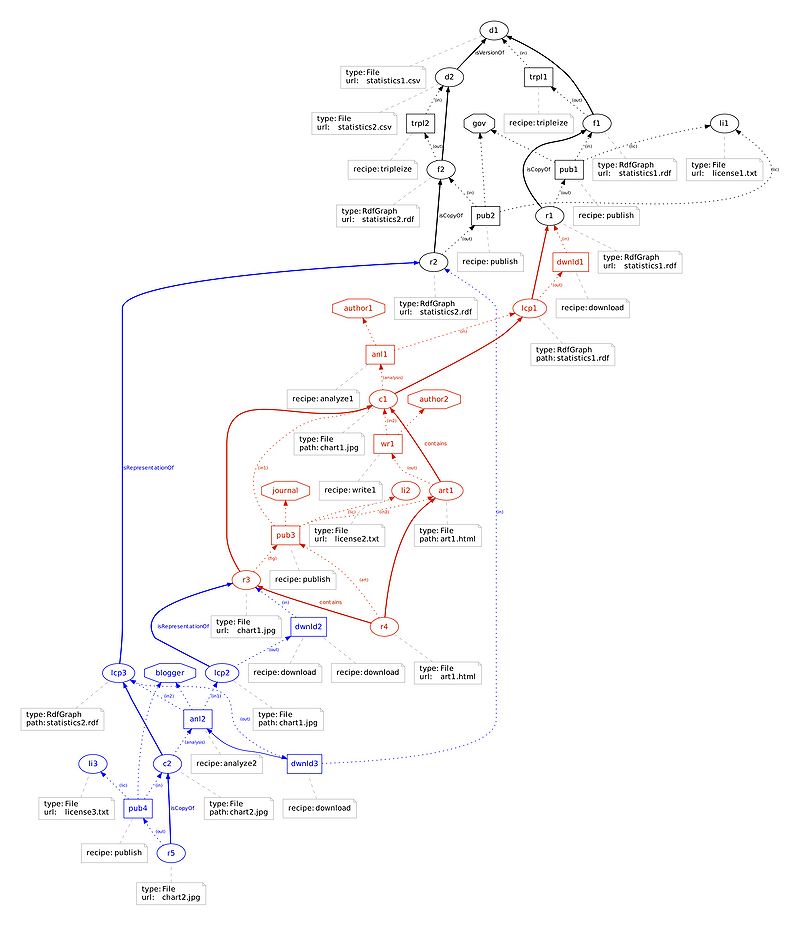
Key nodes
- d1: initial data set
- d2: revised data set
- f1: set of rdf triples for d1
- f2: set of rdf triples for d2
- r1, r2: published rdf graph resource (aka g-box), published by government portal under license li1
- lcp1, lcp3: "local copies", i.e. serialization of rdf graph, obtained by a get request, with appropriate content negotiation (aka g-text)
- c1: chart produced by analysis process anl1, controlled by author1
- art1: article written by author2 (and generated by process wr1), containing chart c1
- r3, r4: published resources, by journal, corresponding to chart c1 and article art1, under license li2
- lcp2: "local copy" of chart resource r3, analysed by blogger in process anl2
- anl2: analysis process by blogger, which triggers process dwnld3 to download r2, and results in new chart c2
- r5: published resource for chart c2, by blogger, under license li3
Provenance Questions
We list here questions whose answers draw on provenance information.
- Is chart c2 dependent on original data set d1?
- Does chart c1 constitute derivative work of d1?
- Is license li2 compatible with the terms of li1?
- What analysis processes were used to produce charts c1 and c2?
- Which chart uses the most up-to-date data?
- Who authored the chart included in article art1?
- ... more queries to be phrased
Provenance Concepts from the Charter
Concepts are listed below in the order they appear in the charter.
1. Resource
Resources can be mutable or immutable, and can have multiple representations (obtained by appropriate content negotiation, in the Web context). Each instance of a representation and of a state can have its own provenance. Hence, it is important to name such a concept, which is referred to as a 'resource state representation' in this document or RSR for short.
In the example graph, ellipses represent resource state representations.
Issue: the terminology 'resource state representation' is cumbersome. What terminology should we adopt instead?
Issue: should we define some useful types of resource state representations, e.g. data, document, query, rdf graph (e.g. g-text)
Issue: how do we identify an RSR? Is it sufficient to assume the existence of a URI? some RSRs (e.g. lcp1,lcp2,lcp3) seem to be local copies (possibly temporary) in a file system, are they assumed to also have a global unique URI?
Issue: how do we relate multiple RSRs, which are various instances of a same stateful resource (idea of a "continuant")?
Issue: how do we define the concept of RSR? we need to make sure that the concept of RSR is clearly defined in the context of the Web architecture.
Issue: is it meaningful to talk about the "provenance of a resource"? how does it relate to the "provenance of an RSR"
2. Process execution
Some entity is responsible for the creation of RSRs. We use the term 'process execution' for a running software programme or a running physical activity.
In the example graph, a process execution is represented as a rectangle. For instance, we distinguish multiple instances of the download activity: dwnld1, dwnld2 and dwnld3.
A process is marked by its beginning and end, which are two instantaneous events, which can be associated with a specific time information. Given that provenance refers to past activities, all processes must have started, though some may not have ended yet, at the time a record of execution is produced. The beginning of a process precedes its end.
Issue: process execution is also cumbersome technology? What term do we use to denote this concept?
Issue: a modelling decision to have process execution with a "duration". Alternative could be instantaneous processes? Which is supported by the WG?
Issue: how do we define this concept?
3. Recipe link
Process execution can be the result of invoking a program, a library or a workflow. We need a mechanism by which we can indicate which "recipe" was exploited to execute the process. We will not define what the recipe is, what we need here is just a standard way to refer to a recipe (i.e., a pointer). The development of standard ways to describe these recipes is out of scope.
In the example graph, a recipe is indicated by the process execution property "recipe", which has a URI as value, which represents the type of the program or workflow being executed.
Issue: do we want to point to an instance of a program or workflow, alternatively, do we want to point to a type, ... itself separately implemented by a program or workflow.
4. Agent
An agent is an entity (human or otherwise) involved in and controlling a process execution.
In the example graph, an agent is represented as an octagon. The Journal controls the pub3 publish process execution, whereas author1 did the analysis that led to chart c1.
Issue: an agent controls a process execution (see control below). What starts a process execution? what ends it?
Issue: can a process execution be started by agent 1 and ended by agent 2?
Issue: should an agent have states? A user today is not the same as yesterday.
Issue: can anything influence an agent?
5. Role
Since a process execution may use several RSRs, it is important to identify the roles under which these RSRs were used. Likewise, a process execution may have generated several RSRs, and each would have a specific role. Finally, a process execution may be controlled by multiple agents, each having a different role.
Hence, roles are similar to parameters of a function, except that they are used to distinguish inputs, outputs and controls of a process execution.
In the example graph, roles are marked in bracket. The analysis process anl2 used RSR lcp2 and lcp3, with respective roles in1 and in2. The publish process pub4 uses RSR li3 as a license (role lic).
Issue: are roles meaningful only in the context of the process execution they relate to?
Issue: should the WG define common roles for common process executions? where? in the model? in the best practice?
Issue: should the WG define positional roles, e.g. param0, param1, param2, ...?
6. Location
A link to a description of location. Defining how the spatial information is represented is out of scope, and we will point to an existing ontology.
No use of location in this example.
Issue: how can the WG formalize the notion of location with respect to provenance?
Issue: is location related to resources, process executions or agents?
Issue: how does this model of location in the context of provenance fit in the space-time model of physics?
7. Derivation
As information flows across systems, information is transformed, resulting in new information. Such a kind of transformation is captured by the notion of derivation. A derivation is a relation between two Resource State Representations that expresses that one RSR was influenced by the other RSR.
In the example graph, plain edges represent derivations. In some cases, these derivations have been subtyped: for instance, isCopyOf represents a copy of an resource state representation into another; isRepresentationOf represents the serialization of a resource state, following a request to download a resource, given some content negotiation.
Many notions of derivation are possible, from the simplest, representing a control link (an RSR was created before another), to a more involved causal influence. We do not expect the standard language to capture all these notions, but we anticipate that most could be defined as subtypes of a general notion of derivation.
Another useful notion is the transitive closure of the direct derivation. In the example graph, r5 was derived from c2, which was derived from lcp3, which was derived from r2, itself from f2, and itself from d2. So, we want to be able to infer that r5 was derived from lcp3, r2, f2, and d2.
Issue: what's the relation between process execution and derivation? Let us consider a process execution that used some RSRs a1 and a2 and generated RSRs a3 and a4, but a2 was used after a3 was generated. Hence, a3 cannot be directly derived from a2. Can a derivation be "inferred" from a process?
Issue: how should the WG formalize derivations?
Issue: should the WG define common derivations (and associated processes)?
8. Generation
Process executions create or generate RSRs. The event that represents such phenomenon is referred to as generation. In this model, given that RSRs are representations of resource states, RSR generation is instantaneous (i.e., each RSR generation occurs at a specific point in time, which may or may not be known, in a given provenance graph).
In the example graph, for instance resource r5 was generated by publication process pub4.
A form of transitive closure also exists for generation: in the example graph, r5 is indirectly generated by the second analysis process execution anl2, or the download process execution dwnld3, or process execution trpl2.
Issue: MUST an RSR be generated by at most one process execution (in a given account)?
Issue: how do we define generation formally? what are the constraints that a dependency must satisfy to be able to qualify as generation?
Issue: does a process execution always generate RSRs?
9. Use
Process executions consume Resource Representation States. The event that represents such phenomenon is referred to as use. In this model, RSR use is also instantaneous (i.e., each RSR use occurs at a specific point in time, which may or may not be known, in a given provenance graph).
A same RSR can be used by a same process execution multiple times under different roles. A same RSR can be used by multiple process executions.
Furthermore, use and creation times are related by the following temporal constraint: an RSR creation time precedes any of its use times.
In the example graph, for instance resource r2 was used by download process execution dwnld3.
A form of transitive closure also exists for use: in the example graph, r2 is indirectly used by the second analysis process execution anl2, or the publication process execution pub3.
Issue: how do we define use formally? what are the constraints that a dependency must satisfy to be able to qualify as use?
Issue: In a call-by-value Procedure Invocation, all the inputs are required to be available before the procedure is invoked. Should the WG define this type of use?
10. Ordering of Processes
In a process-oriented view of execution, it is useful to express that some information has flowed from one process execution to another, but without explicitly representing this information. This relation is captured by the relation was triggered by. This constitutes a specific kind of process (execution) ordering.
We note that this relationship is not transitive. Indeed, if information flowed from P1 to P2, and from P2 to P3, it does not mean that it flowed from P1 to P3.
In the example graph, process execution dwnld3 was triggered by anl2.
Issue: how do we define was-triggered-by formally? what are the constraints that a dependency must satisfy to be able to qualify as such a triggering relation?
Issue: do we need to formalize other notions of process ordering that are stricter, e.g. end of a process p1 precedes beginning of process p2. This notion would be transitive.
11. Version
Versioning is defined as a type of derivation, since a new version of an item can be seen as the result of a transformation applied to an older version of the item.
In the example graph, data set d2 is a more recent version of data set d1.
Issue: do we want just to indicate that an RSR isVersionOf another, or do we want to track version numbers?
12. Participation
Not defined in this example.
Issue: what is the meaning of participation in the context of provenance?
Issue: how can we formally distinguish participation and control?
13. Control
Process execution can be controlled by agents, in the sense that an agent can initiate or terminate a process execution.
In the example graph, process execution pub4 was controlled by the Blogger agent.
Issue: should there be a notion of responsibility attached to control?
Issue: how can we formally distinguish participation and control?
Issue: shouldn't we model control of a process as information (e.g. signal) flowing in a system, and resulting in the beginning of a process execution or its end.
14. Provenance Container
When one enquires about the provenance of a resource state representation, a system should be able to produce a set of provenance statements related to this RSR, based on the concepts introduced in this page. In some cases, it may be useful to package up all the statements in a single "graph construct", to which further metadata can be associated, such as entity of the provenance, or time at which provenance was generated. The graph itself could be signed (though we note that the method for signing a provenance graph is out of scope of this WG). The graph could be serialized or embedded in a document.
Issue: what algebraic property should the WG define for provenance graphs?
Issue: should the WG define a normalized representation of a provenance graph?
Issue: is a provenance container identified? how?
15. Views or Accounts
It is recognized that provenance can be described at multiple levels of abstraction (e.g. end-user view vs. system-level view). Likewise, multiple witnesses of an execution can provide different views of a same execution. An account is a set of provenance assertions sharing a common logic (e.g. issued by a same asserter, or at a given level of abstraction).
In the example graph, the subgraph in black is the "Government" account; the subgraph in red is the set of assertions by the Journal; the subgraph in blue is the blogger's account.
Two accounts overlap when they share some nodes. Two accounts are allowed to present a conflicting view of execution. A given account is intended to present a consistent view of execution.
Issue: how do we define the notion of account/view?
Issue: what's the relation between provenance container and account/view?
Issue: should the WG define relations between accounts, e.g. refinement?
Issue: is an account/view identified? how?
16. Time
This introduction to provenance concepts has identified four kinds of events: RSR Use, RSR Generation, Process Execution Beginning, Execution Process End. Each such event is instantaneous and can optionally be associated with time information.
Issue: what time constraints are implied by dependencies?
Issue: should we define other instantaneous events?
Issue: should the standard support non-instantaneous events, e.g. intervals?
Issue: should we allow for coarse time granularity in the observation of time?
17. Collections
A collection refers to a set of RSRs, whose contents can evolve over time.
An important relationship is the "containment" relationship, whose subject is a collection and object a member of the collection.
In the example graph, article r4 contains the plot r3.
Issue: what collection algebra do we support? what are the corresponding process exececutions (types) and derivations?
Issue: should we define Collection as a type of RSR? (cf type issue for RSR)?
Issue: where do we define this notion? in the core model or in the best practice?