Social 3.0
 Steven Pemberton,
CWI and W3C,
Amsterdam
Steven Pemberton,
CWI and W3C,
Amsterdam
Steven Pemberton,
CWI and W3C,
Amsterdam
At the end of the 80's built a system that you would now call a browser.
Organised 2 workshops at the first Web conference in 1994
Chaired the first style and internationalization workshops at W3C.
Co-author of HTML4, CSS, XHTML, XML Events, XForms, RDFa, etc
Past Editor-in-chief of SIGCHI Bulletin and interactions.

Introduction of new technologies - like the stages of grief: denial, anger, bargaining, acceptance.
Social web sites are useful
They help manage relationships, especially long-distance ones
I don't want to just treat the obvious examples of social sites, like Facebook, Hyves, or LinkedIn, but also oblique social sites, where the principle aim doesn't seem to be sociability, but where you end up creating networks anyway, like Flickr, or family tree sites, and many other Web 2.0 sites.
The term Web 2.0 was invented by a book publisher (O'Reilly) as a term to build a series of conferences around.
It conceptualises the idea of Web sites that gain value by their users adding data to them, such as Wikipedia, Facebook, Flickr, ...
But the concept existed before the term: Ebay was already Web 2.0 in the era of Web 1.0.
How do you decide which social networking site to join? Do you join several and repeat the work? I am currently being bombarded by emails from networking sites (LinkedIn, Dopplr, Plaxo, Facebook, MySpace, Hyves, Spock...) telling me that someone wants to be my friend, or business contact.
If you commit to a particular photo-sharing website, you upload thousands of photos, tagging extensively, and then a better site comes along. What do you do?
How about geneology sites? You choose one and spend months
creating your family tree. The site then spots similar people in your tree on
other trees, and suggests you get together. But suppose a really important tree
is on another site?
By putting a lot of work into a website, you commit yourself to it, and lock yourself into their data formats.
This is similar to, and just as bad as, data lock-in with software: when you use a proprietary program you commit yourself and lock yourself in. Moving comes at great cost.
And there is no standard way of getting your data out of one Web 2.0 site to get it into another.
How about if your chosen site closes down: all your work is lost.
This happened with MP3.com for instance. And Stage6. And Pownce. And Ficlets. And Jaiku. And Google Video. And loads more.
How about if the site has a disk crash and discovers it hadn't backed up properly: Magnolia for instance.
There was someone whose Google account got hacked, and so the account got closed down. Four years of email lost, no calendar, no Orkut.
Here is someone whose Facebook account got closed. Why? Because he was trying to download all the email addresses of his friends into Outlook.
Or the woman whose account was closed for the heinous crime of posting a photo of herself breastfeeding.
Or the journalist who was booted off Facebook and she didn't even know why! (Nor would they tell her).
The Web 2.0 examples are all examples of Metcalfe's law in action
Web 2.0 partitions the Web into a number of topical sub-Webs, and locks you in, thereby reducing the value of the network as a whole.
Metcalfe proposes that the value of a network is proportional to the square of the number of nodes.
v(n)=n2
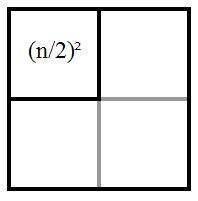 Simple maths shows that if you split a
network into two, it halves the total value:
Simple maths shows that if you split a
network into two, it halves the total value:
(n/2)2 + (n/2)2 = n2/4 + n2/4 = n2/2
This is why it is good that there is only one email network, and bad that there are so many Instant Messenger networks. It is why it is good that there is only one World Wide Web.
Your data is yours! Or at least it ought to be.
You should be able to store your data, and your list of friends, and your photos, and your comments, wherever you please, and say to Facebook "Hey! It's over here!" rather than giving it to them for good.
Then the social websites can come and harvest the information and aggregate it for you. But if they go out of business, or decide they don't like you, or forget to backup, you still have all your stuff.
And it allows social sites to compete on equal terms, just as search engines compete on equal terms now.
This also allows you to own your Amazon reviews and comments, and your IMDB reviews, and your Tweakers reviews, and the comments you make on blogs, and ... all the others.
Even better: It allows you to comment on things that don't have a comment form! Imagine a web service that warns you as you go to a webshop that one of your closest friends had big problems when dealing with the shop.
You could [Like] things that don't even have a Like button on them!
And: you get to decide your own privacy rules.
This doesn't disallow Facebook. They can still aggregate your status updates, and your comments, and your photos, and tell you when there are replies, and you can still go to your Facebook profile page, which is just harvested from your data.
In fact it would give them the opportunity to do even more: include the photos that would normally be on Flickr, or your movie reviews, or your book reviews, or whatever.
It doesn't matter where the data actually is, and most people would choose for third party hosting, though they could choose to run it on their own machine if they wanted.
Even Facebook could offer to host it for you. The only thing they couldn't do is own it, nor lock you in. And if you decided you didn't like them hosting it, you could just move it to another host.
And if they decided thay didn't like hosting you, you still have your data and can take it elsewhere.
Clearly we need some technology to support this, and in particular a standard format that everyone can use.
Enter RDFa.
My elevator speech for RDFa is: It is a layer of markup on top of HTML that makes a page machine-understandable, as well as human understandable. It does for meaning what CSS did for presentation.
When you go to a web page, you can usually recognise a person's name, or a date, or a city name. But not if you are a browser or a search engine. RDFa fixes that.
RDFa lets you add markup to a page so that the browser can see that a page is about an event, such as a conference, can see where it is, and when it is.
Why, it could even add it to your calendar, or show you a map, or look up hotels, or flights.
Dammit, it could even help you fill in the registration form!
Some people think that keyword searches are good enough for searches, or at least for most of them.
Well, it is fine for searches with unique words, like "RDFa", but try and find information about the play "ice cream", and see how long it takes you...
Or try and locate someone with the same name as a famous star, like my friend Michael Jackson...
RDFa lets you say "about that thing over there (a URI), this is a comment", or "this is a review", or "this is a tag", or, ...
So it doesn't matter what the aggregator is interested in, it can tell. The family-tree aggregator can collect family-tree information, the Amsterdam aggregator can collect information about Amsterdam; the news aggregator can collect news, the comment aggregator can collect comments, the review aggregator can collect reviews, the photo aggregator can collect photos.
This is not unlike what Google already does for news, where it uses special information about the structure of news sites. With RDFa, you can aggregate anything without specific knowledge of sites.
In fact aggregators are already collecting reviews specified in RDFa: both Yahoo and Google are doing it, and more are bound to follow.

Another area that is being aggregated is products for sale: Best Buy (USA) and Tesco (UK) are both publishing with RDFa. Best Buy reported:
And there are loads of other examples of people using RDFa, such as the US and UK governments, Newsweek, scientific libraries, even Facebook!
Trust: Social sites mediate between you and other people.
But don't forget it is already rather flimsy: if I could locate someone you knew who didn't have a Facebook account, I could fairly easily fake one, and befriend you without you suspecting anything.
This includes concepts like single log in. How can I gain reasonable confidence that the person saying they are you, and wanting to link with me is really you.
It's not enough for me to say "she's my friend", she has to say it too.
Social websites in all their forms are fun, useful and here to stay.
However, in their current incarnation, they have too much power over you, your data, and your privacy.
We need a distributed social networking system, where you own your data.
Aggregators can supply the same value as current social sites.
In fact they could do even more than they do now.
RDFa is a simple technology, already widely used, that would allow such an architecture.
Then you get the true web-effect, with its full Metcalfe value.
Are online.
If you can't find them, you're in the wrong business!
Here is a tutorial on RDFa: http://www.w3.org/MarkUp/2009/rdfa-for-html-authors