See also: IRC log
<dom> ScribeNick: Dom
Agenda review: since shadi won't be available tomorrow pm, we'll try to get to the relevant items for shadi before then
We'll start at 8am tomorrow to cater for the people leaving early
-> http://lists.w3.org/Archives/Public/public-mobileok-checker/2007Mar/0044.html Intermediate document revision
Shadi: HTTP in RDF in review
until Apr 20
... this note is based on a use case developed for EARL
(Evaluation And Report Language), in Last Call
... not everything is finalized
... overall concept is that EARL captures the result (e.g. a
given page failed a given test)
... and sometimes you need to capture some specific HTTP
interactions (e.g. content negotiation)
... there is another use case: when happens when during an HTTP
interaction, something occurs in the HTTP protocol that impacts
the interaction
... e.g. HTTP error, wrong HTTP header, etc
... there are 2 issues we're looking at:
... * the decomposition of headers into more elements (as
requested by Jo)
... but we still need to look at how the decomposed and
composed version relate to one another
... * the encapsulation of content inside RDF; e.g. if you want
to record the body you got from the server
... how to record that byte sequence in RDF taking into account
character encoding and XML limitations
... also, you probably don't want to re-encode XML you already
got from the server when the body is indeed xML
... there is an algorithm on the table to deal with this
Jo: the comments I sent were sent
on behalf of MTLD, but I think they reflect some of the
concerns this group has had with HTTP-in-RDF
... we need to be able to justify why a given analysis
triggered a given result
... This also means we may need to be able to have an exact
copy of the request exchanges rather than just the structured
version of the interaction in RDF
... the same applies to the body
... we both need to work on a structured document (e.g. in
XML), while also keep track of illformed documents
Dom: this relates to the encapsulation problem shadi was talking about
Jo: what kind of input do you
need from us?
... also, we need to have access to some of the XML data (xml
declaration, doctype)
Shadi: regarding the transcript
of the headers, we just need to add a property to record
this
... should be fairly simple to address
... it indeed makes sense to record the original un-transformed
set of requests/responses
... for encapsulating the body, it is a bit different
<shadi> http://www.w3.org/TR/2007/WD-HTTP-in-RDF-20070323/#body
Shadi: [shadi explains the algorithm as described by the diagram at http://www.w3.org/TR/2007/WD-HTTP-in-RDF-20070323/#body ]
[I wonder if MTOM is relevant here: http://www.w3.org/TR/2005/REC-soap12-mtom-20050125/ ]
[or rather, XML-binary Optimized Packaging http://www.w3.org/TR/2005/REC-xop10-20050125/ ]
scribe: one option to get access to the XML declaration and doctypes data would be to add the relevant propoerties in the body representation
Jo: I think in our work, we'll
end up with 2 representations of the body
... the original transcript, and the structured version of
it
... there seems to be 3 ways to encode the body in what you
describe
... given we're likely always want to have some kind of XML
version of the body (even if the original wasn't
well-formed)
... so that we can further process it
... so I think we would have both the base64 version and the
structured version based on fixes as needed, based on whatever
flavours of tidying
... so in our case, we'll always want to base64
... why base64 btw?
shadi: base64 is the encoding used for the data: URI scheme
dom: is this one or three properties?
shadi: right now, one, but we're
now considering having 3, one of which would be
"required"
... (i.e. that you can always assume you'll get)
dom: probably worth checking what the web services guys have been doing too
<scribe> ACTION: Shadi to get in touch with Yves on MTOM/XML-biniary Optimized Packaging [recorded in http://www.w3.org/2007/04/02-bpwg-minutes.html#action01]
trackbot, that's ok, we expected it
dom: at some point, we'll need to
draw a line
... e.g. consider HTTP as a blackbox
... we may also want to consider developing our own RDF
properties if our requirements go beyond the scope of
HTTP-in-RDF
shadi: would also know what's your schedule is, to see how we accommodate your needs
jo: Sean seems to think there is
less urgency in having a ref impl given that there already 2
reasonable implementations of mobileok
... dotMobi has a preference in having it developed in a stable
way, but don't want to have this takes too long either
shadi: my impression is that this
group wants to work pretty fast
... we're trying to develop something forward-compatible
... we're working with the W3C validator guys right now to get
practical feedback on EARL
... this also relates to UniCORN
... it would be interesting to see how this checker will fit
with the other W3C validators
... this also relates to the discussion on procedural vs
declarative / extensibility
... not sure about your timeline, but in our case, we're
expecting quite a bit of feedback on our documents
... feedback review finishg on Apr 20
... We're hoping to go for CR by June for EARL
... and hope to get another draft of HTTP-in-RDF before
publishing it as a Note
Jo: re decomposition of data, there is also the question of normalization (e.g. no-cache in Pragma headers)
Shadi: we have looked at it
briefly; some headers are case sensitive, some aren't
... at this time, we've decided NOT to do any kind of
normalization
Jo: it would be helpful to have a normalized version of the http headers for downstream processors
dom: I think one of the
difficulties reside in separating the format representation
from the processing
... you'll probably want to create some conformance rules for a
processor that would output HTTP-in-RDF
... e.g. with one doing the full decomposition and
normalization
... normalization could include to output everything as
lowercase for case-insensitive headers
shadi: will this group take a close look at the document and send comments?
jo: FWIW, we're in a no-process
land at this time
... we'll be integrated in BPWG charter 2
dom: probably not a big deal
shadi: would be very useful to have comments from the group as a group
jo: esp as we'll be implementing this spec most likely
dom: FWIW, not sure we need to
deal with implementing HTTP-in-RDF as a specific ref
implementation
... esp as this document in not going through CR
shadi: indeed, we probably don't
need a formal implementation
... as long as we can point to mobileOK as using this stuff
dom: I do think that we'll probably want to design our code so that the HTTP-in-RDF can be easily re-used
shadi: also would be useful for implementing a WCAG 2.0 tester
<scribe> ACTION: shadi to look at the RDF design of http:fieldName being both a literal and a resource [recorded in http://www.w3.org/2007/04/02-bpwg-minutes.html#action02]
Jo: can we parse this as XML rather than RDF?
Dom: I think the RDF output is
"simple" enough that it may be possible to output the RDF in a
less flexible fashing than what RDF allows
... and make it parseable as XML constrained at the XML schema
level
Shadi: we're hitting this problem
with EARL too
... we're not sure yet whether we'll be developing such a
schema yet
... although others have raised that concern
... some of the difficulties relate to subclasses
... we're hoping the RDF is simple enough at this time that an
XML schema could work
Jo: I personnally don't think
we'll have time to learn RDF in the timeframe of this
project
... I'm hoping we can rely on XML
Sean: that's what I have been assuming too
Chair+ Sean
<jo> scribenick: Jo
sean: we thought that there were
urgent timescales to rendez-vous with cadidate rec of
mobileOK
... less urgency now as there are two implementations
... no reason to slow down, though
... tentative and intermediate milestones
... completion of framework, document formats etc
[sean draws on whiteboard]

dom: need to fix on weekly meeting date
sean: proposal 1:00 UTC, 2:00 UK, 3:00 CET 9:00 EDT
<dom> (on Tuesday, I assume)
sean: need to check zakim
availability plus convenience to other participants
... on Thursday
<dom> sample of zakim calendar on Thusrdays: http://www.w3.org/Guide/1998/08/teleconference-calendar#D20070405
dom: should book it now or shall I wait?
sean: let's go ahead and change
if nacho, abel can't make iit
... agree on design in principle in next two weeks
... then deliverable no 1 (framework and 1 test) by May 1
... modulo some of the implementation being temporary
Jo: how much time can we put on this
(discussion)
Jo: roughly 60 person hours a
week
... 25% time writing test cases
dom: what does the results
document look like?
... probably some EARl describing the expected output
... should be OK for integration into JUNIT
sean: time will be burned on
deciding (25%) revising framework, refactoring etc.
... milestone 2, start of july for 20 tests
jo: need to do a pre release of
all tests as we will want a period for
... perforamnce and bugs etc
dom: need some kind of ui
thingy
... to do testing
sean: by July we will have done
75% tests
... so need more time for the remaining 25%
... allow 8 weeks for the remaining
... so start of september for all tests then
... milestone 3 is polish etc. by Sean's birthday on 17th
Sept
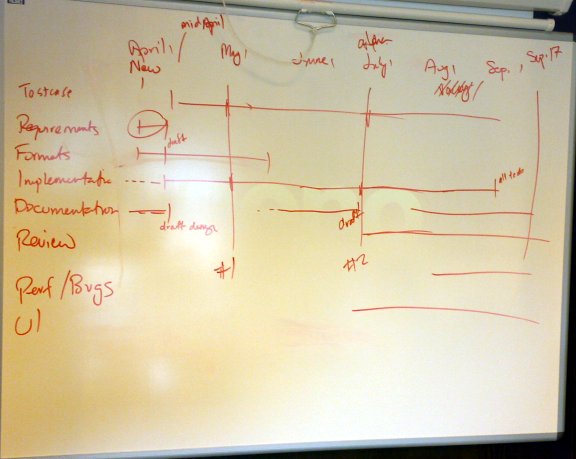
jo: probably as far as we can go
for now
... need review of schedule as a standing agenda item
... need to bring timetable in if we can
... also need to write up timetable
_ACTION: Sean to write up timetable etc.
<dom> ACTION: Sean to write up timetable etc. [recorded in http://www.w3.org/2007/04/02-bpwg-minutes.html#action03]
<dom> Sean's summary of the discussions on milestones/deliverables
<dom> ScribeNick: Ronan
jo: there is a question as to what we mean by validity
dom: we should use word
conformant rather than valid
... for xhtml valid means confirmant for for all others e.g.
CSS we should not use word valid
jo: xhtml validity is clearly very important for this project
dom: xhtml validity is fairly
well defined -- we can just pick some validator to start with,
and then decide what to do if it is buggy
... validating to DTDs is relatively straightforward .. should
not see too many bugs
jo: I'm more concerned about validity of gifs and jpegs
<dom> GIF specification
jo: We will be using
implementations that we don't know the details of e.g. standard
Java tools for reading jpegs
... There are assumptions embedded in these that we don't fully
understand
dom: All s/w implementations will have bigs and undefined behaviours. The various libraries that we use may not have the detail that we need
jo: We may need to make our
claims based on something else .. we use X validator to check
validity
... can we mix & match validity claims
... based on the underlying libraries etc
... Semantics of claim may need to be rich enough to embed this
information in claims
dom: Unless there are bugs in implementation or standard there is no room for disagreement
jo: agrees but specs may not have validity clauses in them
dom: If checker is used in legal framework there may be problems -- but doesn't think it is our job to address all bugs in underlying s/w -- we can have disclaimer for this
jo: DotMobi may be putting itself
in dangerous legal position
... claims should be based on a chain of trust
... checker should allow people to pick which validator they
wish to use
dom: thinks it too early to get into this depth
jo: the input to the check is not just the doc under test -- it should include (say) a reference to some validity checker for some part of the test
dom: value of tool could be reduced if you allow people this flexibility, plus it is less pragmatic
jo: allowing this configurability
would make tool more useful
... uniformity of results cannot be guaranteed in any case --
temporal changes etc
dom: still thinks it should not be a requirement
sean: thinks that this won't be a
problem in practice -- the libraries that we actually use are
likely to be more liberal than the phone s/w
... but it certainly doesn't hurt to report on the libraries
that were used
... but allowing substitutions of validators seems to be
solving a problem that we have
jo: this is worth thinking about up front because if it turns out to be a problem, it could be a very serious problem
sean: taking a real example if xhtml, people don't really seem to be confused about validity
jo: at a minimum we should report
on versions of libraries etc
... would like it to be at least possible to swop in other
validators
sean: isn't the fact that this is open source enough?
dom: this effect can be achieved in other ways - wrapping an existing service such that it can be built in -- doesn't need to be designed in from start
jo: audit trail is very important part of a claim
shadi: what exactly is a checker doing -- is it formally described?
dom: not formally described as
such -- it simply performs each of the 26 checks in mOK
Basic
... the open issue is to what extent the audit trail is part of
the result
jo: an analogy -- road worthiness certs (emissions etc) depend on who issued them -- this is just part of life
ruadhan: might be easier just to pick a validator and be open about versions
ronan: agrees
... unless code is really bad it should be be easy enough to
change implementations in any case
jo: outcome seems to be that we should *weakly* support the idea of changeable implementations of tests
<dom> JHOVE - JSTOR/Harvard Object Validation Environment
<dom> Jo: JHOVE does validation of various file formats, including JPEG and GIF
<dom> "The initial release of JHOVE includes modules for arbitrary byte streams, ASCII and UTF-8 encoded text, GIF, JPEG2000, and JPEG, and TIFF images, AIFF and WAVE audio, PDF, HTML, and XML; and text and XML output handlers."
<dom> GIF module in JHOVE
<dom> JPEG module in JHOVE
<dom> dom: unclear on what part of which specs their wf/validity criteria are based
Background: Ideally pre-processed
output could be sent through an XSLT to produce the EARL
result
... assuming no performance issues with this
... Auditability and extensibility are main reasons for
this
... Anything that can't be done with xpath etc will have to be
done as part of pre-processing
... Example of this might be UTF-8 testing
... The hard line on this is that anything that can't be done
with XSLT, XPATH etc has to be done in pre-processing
Sean: XPATH is for looking for things in docs rather than anything else
Dom: some of the extensions that you might want to do would require deep analysis of input e.g. JPEG testing
Sean: .. so result doc should include more information than you need for the basic tests
Jo: yes, so result doc should include original payload to enable this extensibility
Shadi: extensibility can also
include translation to other human languages
... XSLT might be enough to translate text to a different human
langauge
Sean: this implies that the
original doc must be well formed also
... Jo is proposing that there is some process that emits tests
results alongside a lot of other information
... everything that we know about the doc
Jo: agrees
... is in favour of using an approach that allows all tests
that actually require code to be done up front
Sean: seems like collecting all required information up front
Jo: there are some things that you just have to do in code
Dom: we will also be interested
in why something is not valid -- not just a true/false
... some kind of key that can be associated with human readable
document
... so how does this impact the development of this project?
Can we still postpone the harder tests until the end?
Sean: there are Java methods for internationalization of messages
Jo: but people may not have
access to Java compilers etc
... shows example of XSL
... to show how XSL can be used to capture test results from a
document
Dom: in this case the XSL is
doing some of the analsys as well as the presentation .. not a
very clean model
... this division of intelligence makes bug fixing smart
... you loose the benefits of modularization
... intelligence should not be built into this layer -- should
be limited to lighter tasks
Jo: having more intelligence in the XSL means that the test doc (the intermediate doc) is richer
Dom, Sean: There should be a line somewhere -- how much processing should be done up front
Jo: if the intermediate doc is not rich, you preclude the opportunity to decorate the original document -- this is a good way to add value
Dom: we could analyse the 26 tests and see how many of them lend themselves to pre-processing or not
Why not do both? Include both a summary and the extra detail in the intermediate doc
Jo: it may make sense to do the validity checking at the same time as the pre-processing
Sean: how strong is the case for
extensibility?
... Is this our goal?
Is this a reference implemention or a software building block?
Sean: it seems like there are 2 things here: 1) go get doc and do some analysis on it and 2) report on this
Dom: thinks that base implementation should do only minimal digest of tests
Jo: we need to think about
this
... one school of thought is that we add no extra information
to the result
... other schools that we add lots of data -- perhaps
everything we know -- into the result doc
... for value-add for other applications
Will revisit this discussion tomorrow
<dom> Evaluation and Report Language (EARL) 1.0 Schema, W3C Working Draft 23 March 2007
<dom> Outcome value in EARL
<shadi> http://www.w3.org/TR/2007/WD-EARL10-Schema-20070323/#testresult
<shadi> earl:info
<dom> 2.6. Test Result in EARL, with earl:info property
<dom> 2.6. Test Result in EARL, with earl:info property
Discussion about EARL's suitability to mOK
EARL does not have ability to group tests -- which is probably necessary for mOK
Jo: making the tests more atomic is not necessarily a solution for this
Sean: We could use the info elements to hold extra information
Dom: We should not be relying on human readable stuff
Sean: we can add an extension to
the EARL RDF vocabulary that will allow us to express mOK
tests
... the vocabulary should accomodate this
... to what extent does EARL let you describe your test
implementation?
Shadi: there is a compound assert element that can be used for this purpose
<dom> ACTION: Sean to draft comments on EARL 1.0 [recorded in http://www.w3.org/2007/04/02-bpwg-minutes.html#action04]
Discussion about how to represent XML etc in EARL
There is no defined way to do this
Jo: we should have a schema for
this so that XPATH can be used
... would be nice if all implementations used this schema - not
just ours
... we need to take our example of the result document much
further than it already is
Dom: we could look at the dotMobi XML mOK output and try to transform it to EARL
<dom> ACTION: Jo to transform an instance of Mr Dev output in our expected EARL output format [recorded in http://www.w3.org/2007/04/02-bpwg-minutes.html#action05]
<dom> shadi: EARL is perfect
<dom> ... don't you dare send comments
<shadi> clarification: this is of course a joke :)
<jo> tomorrow - zoom in on intermediate doc and the design doc and code, maybe, process ownership etc.