Abstract
This is the report of the W3C Emotion Incubator Group (EmoXG) as specified
in the Deliverables section of its charter.
In this report we present requirements for information that needs to be
represented in a general-purpose Emotion Markup Language in order to be
usable in a wide range of use cases.
Specifically the report:
- describes the range of use cases in which an emotion markup language
would be needed,
- presents a rich structured collection of requirements arising from the
use cases,
- describes how these requirements coincide with scientific models of
emotion,
- begins to assess syntactic issues in view of a future specification, by
evaluating existing markup languages in the light of the collected
requirements.
The report identifies various areas which require further investigation
and debate. The intention is that it forms a major input into a new Incubator
Group which would develop a draft specification as a proposal towards a
future activity in the W3C Recommendation Track.
Status of this document
This section describes the status of this document at the time of its
publication. Other documents may supersede this document. A list of Final Incubator Group
Reports is available. See also the W3C
technical reports index at http://www.w3.org/TR/.
This document was developed by the W3C Emotion Incubator Group. It
represents the consensus view of the group, in particular those listed in the
acknowledgements, on requirements for a generally usable emotion
markup language. The document has two main purposes:
- elicit discussion with other groups, notably the MMI and VoiceBrowser
groups at W3C, in view of a possible collaboration towards future
standards;
- serve as the basis for a draft specification document which should be
the output of a successor Incubator Group.
Publication of this document by W3C as part of the W3C Incubator Activity indicates
no endorsement of its content by W3C, nor that W3C has, is, or will be
allocating any resources to the issues addressed by it. Participation in
Incubator Groups and publication of Incubator Group Reports at the W3C site
are benefits of W3C
Membership.
Incubator Groups have as a goal to
produce work that can be implemented on a Royalty Free basis, as defined in
the W3C Patent Policy. Participants in this Incubator Group have made no
statements about whether they will offer licenses according to the licensing
requirements of the W3C Patent Policy for portions of this Incubator
Group Report that are subsequently incorporated in a W3C Recommendation.
Table of Contents
Foreword: A Word
of Caution
1. Introduction
2. Scientific Descriptions of
Emotion
3. Use Cases
4. Requirements
5. Assessment of Existing
Markup Languages
6. Summary and
Outlook
7. References
8.
Acknowledgements
Appendix 1: Use
Cases
Appendix
2: Detailed Assessment of Existing Markup Languages
Foreword: A Word of Caution
This document is a report of the W3C Emotion Incubator group,
investigating the feasibility of working towards a standard representation of
emotions and related states in technological contexts.
This document is not an attempt to "standardise emotions", nor is it an
attempt to unify emotion theories into one common representation. The aim is
not to understand the "true nature" of emotions, but to attempt a transfer -
making available descriptions of emotion-related states in
application-oriented technological contexts, inspired by scientific
proposals, but not slavishly following them.
At this early stage, the results presented in this document are
preliminary; the authors do not claim any fitness of the proposed model for
any particular application purpose.
In particular, we expressly recommend prospective users of this technology
to check for any (implicit or explicit) biases, misrepresentations or
omissions of important aspects of their specific application domain. If you
have such observations, please let us know -- your feedback helps us create a
specification that is as generally usable as possible!
1. Introduction
The W3C Emotion Incubator group was chartered "to investigate the prospects of defining a
general-purpose Emotion annotation and representation language, which should
be usable in a large variety of technological contexts where emotions need to
be represented".
What could be the use of such a language?
From a practical point of view, the modeling of emotion related states in
technical systems can by important for two reasons.
1. To enhance computer-mediated or human-machine communication. Emotions
are a basic part of human communication and should therefore be taken into
account, e.g. in emotional Chat systems or emphatic voice boxes. This
involves specification, analysis and display of emotion related states.
2. To enhance systems' processing efficiency. Emotion and intelligence are
strongly interconnected. The modeling of human emotions in computer
processing can help to build more efficient systems, e.g. using emotional
models for time-critical decision enforcement.
A standardised way to mark up the data needed by such "emotion-oriented
systems" has the potential to boost development primarily because
a) data that was annotated in a standardised way can be interchanged
between systems more easily, thereby simplifying a market for emotional
databases.
b) the standard can be used to ease a market of providers for sub-modules
of emotion processing systems, e.g. a web service for the recognition of
emotion from text, speech or multi-modal input.
The work of the present, initial Emotion Incubator group consisted of two
main steps: firstly to revisit carefully the question where such a language
would be used (Use cases), and
secondly to describe what those use case scenarios require from a language
(Requirements). These
requirements are compared to the models proposed by current scientific theory
of emotions (Scientific descriptions). In addition,
existing markup languages are discussed with respect to the requirements (Existing
languages).
The specification of an actual emotion markup language has not yet been
started, but is planned as future work (Summary and Outlook). This deviation from the
original plan was the result of a deliberate choice made by the group - given
the strong commitment by many of the group's members to continue work after
the first year, precedence was given to the careful execution of the first
steps, so as to form a solid basis for the more "applicable" steps that are
the logical continuation of the group's work.
Throughout the Incubator Activity, decisions have been taken by consensus
during monthly telephone conferences and two face to face meetings.
The following report provides a detailed description of the work carried
out and the results achieved so far. It also identifies open issues that will
need to be followed up in future work.
The Incubator Group is now seeking to re-charter as an Incubator group for
a second and final year. During that time, the requirements presented here
will be prioritised; a draft specification will be formulated; and possible
uses of that specification in combination with other markup languages will be
outlined. Crucially, that new Incubator group will seek comment from the W3C
MMI and VoiceBrowser working groups. These comments will be decisive for the
decision whether to move into the Recommendation Track.
1.1 Participants
The group consisted of representatives of 16 institutions from 11
countries in Europe, Asia, and the US:
- German Research Center for Artificial Intelligence (DFKI) GmbH, Germany
*
- Deutsche Telekom AG, T-Com, Germany *
- University of Edinburgh, UK *
- Chinese Academy of Sciences, China *
- Ecole Polytechnique Federale de Lausanne (EPFL), Switzerland *
- University of Southern California Information Sciences Institute (USC /
ISI), USA *
- Universidad Politecnica de Madrid, Spain *
- Fraunhofer Gesellschaft, Germany *
- Loquendo, Italy
- Image, Video and Multimedia Systems Lab (IVML-NTUA), Greece
- Citigroup, USA
- Limsi, CNRS, France +
- University of Paris VIII, France +
- Austrian Institute for Artificial Intelligence (OFAI), Austria +
- Technical University Munich, Germany +
- Emotion.AI, Japan +
* Original sponsor organisation
+ Invited expert
It can be seen from this list that the interest has been broad and
international, but somewhat tilted towards the academic world. It will be one
important aim of a follow-up activity to produce sufficiently concrete output
to get more industrial groups actively interested.
2. Scientific Descriptions of Emotion
One central terminological issue to be cleared first is the semantics of
the term emotion, which has been used
in a broad and a narrow sense.
In its narrow sense, as it is e.g. used by
Scherer (2000), the term refers to what is also called a prototypical emotional episode (Russell
& Feldman Barrett 1999), full blown
emotion, or emergent emotion
(Douglas-Cowie et al. 2006): a short, intensive, clearly event triggered
emotional burst. A favourite example would be "fear" when encountering a
bear in the woods and fleeing in terror.
Especially in technological contexts there is a tendency to use the term
emotion(al) in a broad sense, sometimes for almost everything that cannot be
captured as purely cognitive aspect of human behaviour. More useful
established terms -- though still not concisely defined -- for the whole
range of phenomena that make up the elements of emotional life are "emotion-related states" and "affective states".
A number of taxonomies for these affective states have been proposed.
Scherer (2000), e.g., distinguishes:
- Emotions
- Moods
- Interpersonal stances
- Preferences/Attitudes
- Affect dispositions
This list was extended / modified by the HUMAINE group
working on databases: in Douglas-Cowie et al. (2006) the following list is
proposed (and defined):
- Attitudes
- Established emotion
- Emergent emotion (full-blown)
- Emergent emotion (suppressed)
- Moods
- Partial emotion (topic shifting)
- Partial emotion (simmering)
- Stance towards person
- Stance towards object/situation
- Interpersonal bonds
- Altered state of arousal
- Altered state of control
- Altered state of seriousness
- Emotionless
Emergent emotions -- not without
reason also termed prototypical emotional episodes -- can be viewed as
the archetypical affective states and many emotional theories focus on them.
Empirical studies (Wilhelm, Schoebi & Perrez 2004) on the other hand show
that while there are almost no instances where people report their state as
completely unemotional, examples of full-blown emergent emotions are really
quite rare. As the ever present emotional life consists of moods, stances
towards objects and persons, and altered states of arousal, these indeed
should play a prominent role in emotion-related computational applications.
The envisaged scope of an emotion representation language clearly comprises
emotions in the broad sense, i.e.
should be able to deal with different emotion-related states.
2.2 Different components of emotions
There is an old Indian tale called "The
blind men and the elephant" that enjoys some popularity in the
psychological literature as an allegory for the conceptual difficulties to
come up with unified and uncontroversial descriptions of complex phenomena.
In this tale several blind men who never have encountered an elephant before,
try to come up with an understanding of the nature of this unknown object.
Depending on the body part each of them touches they provide strongly
diverging descriptions. An elephant seems to be best described as a rope if
you hang to its tail only, is a tree if you just touched its legs, appears as
a spear if you encountered a tusk etc.
This metaphor fits nicely with the multitude of definitions and models
currently available in the scientific literature on emotions, which come
with a fair amount of terminological confusion added on top. There are no
commonly accepted answers to the questions on how to model the underlying
mechanism that are causing emotions, on how to classify them, on whether to
use categorial or dimensional descriptions etc. But leaving these questions
aside, there is a core set of components that are quite readily accepted
to be essentialcomponents of emergent
emotions.
Subjective component: Feelings.
Feelings are probably what is most strongly associated with the term emotion
in folk psychology and they have been claimed to make up an important part of
the overall complex phenomenon of emotion.
Cognitive component: Appraisals
The most prominently investigated aspect of this component is the role of --
not necessarily conscious -- cognitive processes that are concerned with the
evaluation of situations and events in the context of appraisal models (e.g.
Arnold 1960, Lazarus 1966), i.e. the role and nature of cognitive processes
in the genesis of emotions. Another aspect are modulating effects of emotions
on cognitive processes, such as
influences on memory and perception (e.g. narrowing of the visual field in
fear).
Physiological component:
Physiological changes both in the peripheral (e.g., heart-rate,
skin-conductivity) and the central system (e.g. neural activity) are
obviously one important component of emergent emotions. This component is
also strongly interconnected with other components in this list: e.g. changes
in the muscular tone, also account for the modulation of some expressive
features in speech (prosody, articulatory precision) or in the appearance
(posture, skin color).
Behavioral component: Action tendencies
Emotions have a strong influence on the motivational state of a subject.
Frijda (1986) e.g. associated emotions to a small set of action tendencies, e.g. avoidance (relates
to fear), rejecting (disgust) etc. Action tendencies can be viewed as a link
between the outcome of an appraisal process and actual actions.
Expressive component:
The expressive component comprises facial expressions but also body posture
and gesture and vocal cues (prosody, voice quality, affective bursts).
Different theories may still strongly disagree on the relative importance of these components and
on interactions and cause-and-effect relations between them. However, the
fact that these components are relevant to some extent seems relatively
uncontroversial.
3. Use cases
Taking a software engineering approach to the question of how to represent
emotion in a markup language, the first necessary step for the Emotion
Incubator group was to gather a set of use cases for the language.
At this stage, we had two primary goals in mind: to gain an understanding
of the many possible ways in which this language could be used, including the
practical needs which have to be served; and to determine the scope of the
language by defining which of the use cases would be suitable for such a
language and which would not. The resulting set of final use cases would then
be used as the basis for the next stage of the design process, the definition
of the requirements of the language.
The Emotion Incubator group is comprised of people with wide ranging
interests and expertise in the application of emotion in technology and
research. Using this as a strength, we asked each member to propose one or
more use case scenarios that would represent the work they, themselves, were
doing. This allowed the group members to create very specific use cases based
on their own domain knowledge. Three broad categories were defined for these
use cases:
- Data Annotation,
- Emotion Recognition
- Emotion Generation
Where possible we attempted to keep use cases within these categories,
however, naturally, some crossed the boundaries between categories.
A wiki was created to facilitate easy collaboration and integration of
each member's use cases. In this document, subheadings of the three broad
categories were provided along with a sample initial use case that served as
a template from which the other members entered their own use cases and
followed in terms of content and layout. In total, 39 use cases were entered
by the various working group members: 13 for Data Annotation, 11 for Emotion
Recognition and 15 for Emotion Generation.
Possibly the key phase of gathering use cases was in the optimisation of
the wiki document. Here, the members of the group worked collaboratively
within the context of each broad category to find any redundancies
(replicated or very similar content), to ensure that each use case followed
the template and provided the necessary level of information, to disambiguate
any ambiguous wording (including a glossary of terms for the project), to
agree on a suitable category for use cases that might well fit into two or
more and to order the use cases in the wiki so that they formed a coherent
document.
In the following, we detail each broad use case category, outlining the
range of use cases in each, and pointing out some of their particular
intricacies. Detailed descriptions of all use cases can be found in Appendix 1.
3.1. Data annotation
The Data Annotation use case groups together a broad range of scenarios
involving human annotation of the emotion contained in some material. These
scenarios show a broad range with respect to the material being annotated,
the way this material is collected, the way the emotion itself is
represented, and, notably, which kinds of additional information about the
emotion are being annotated.
One simple case is the annotation of plain text with emotion dimensions or
categories and corresponding intensities. Similarly, simple emotional labels
can be associated to nodes in an XML tree, representing e.g. dialogue acts,
or to static pictures showing faces, or to speech recordings in their
entirety. While the applications and their constraints are very different
between these simple cases, the core task of emotion annotation is relatively
straightforward: it consists of a way to define the scope of an emotion
annotation and a description of the emotional state itself. Reasons for
collecting data of this kind include the creation of training data for
emotion recognition, as well as scientific research.
Recent work on naturalistic multimodal emotional recordings has compiled a
much richer set of annotation elements (Douglas-Cowie et al., 2006), and has
argued that a proper representation of these aspects is required for an
adequate description of the inherent complexity in naturally occurring
emotional behaviour. Examples of such additional annotations are multiple
emotions that co-occur in various ways (e.g., as blended emotions, as a quick
sequence, as one emotion masking another one), regulation effects such as
simulation or attenuation, confidence of annotation accuracy, or the
description of the annotation of one individual versus a collective
annotation. In addition to annotations that represent fixed values for a
certain time span, various aspects can also be represented as continuous
"traces" -- curves representing the evolution of, e.g., emotional intensity
over time.
Data is often recorded by actors rather then observed in naturalistic
settings. Here, it may be desirable to represent the quality of the acting,
in addition to the intended and possibly the perceived emotion.
With respect to requirements, it has become clear that Data Annotation
poses the most complex kinds of requirements with respect to an emotion
markup language, because many of the subtleties humans can perceive are far
beyond the capabilities of today's technology. We have nevertheless attempted
to encompass as many of the requirements arising from Data Annotation, not
least in order to support the awareness of the technological community
regarding the wealth of potentially relevant aspects in emotion
annotation.
3.2 Emotion recognition
As a general rule, the context of the Emotion Recognition use case has to
do with low- and mid-level features which can be automatically detected,
either offline or online, from human-human and human-machine interaction. In
the case of low-level features, these can be facial features, such as Action
Units (AUs) (Ekman and Friesen 1978) or MPEG 4 facial action parameters
(FAPs) (Tekalp and Ostermann, 2000), speech features related to prosody
(Devillers, Vidrascu and Lamel 2005) or language, or other, less frequently
investigated modalities, such as bio signals (e.g. heart rate or skin
conductivity). All of the above can be used in the context of emotion
recognition to provide emotion labels or extract emotion-related cues, such
as smiling, shrugging or nodding, eye gaze and head pose, etc. These features
can then be stored for further processing or reused to synthesise
expressivity on an embodied conversational agent (ECA) (Bevacqua et al.,
2006).
In the case of unimodal recognition, the most prominent examples are
speech and facial expressivity analysis. Regarding speech prosody and
language, the CEICES data collection and processing initiative (Batliner et
al. 2006) as well as exploratory extensions to automated call centres
(Burkhardt et al., 2005) are the main factors that defined the essential
features and functionality of this use case. With respect to visual analysis,
there are two cases: in the best case scenario, detailed facial features
(eyes, eyebrows, mouth, etc.) information can be extracted and tracked in a
video sequence, catering for high-level emotional assessment (e.g. emotion
words). However, when analysing natural, unconstrained interaction, this is
hardly ever the case since colour information may be hampered and head pose
is usually not directed to the camera; in this framework, skin areas
belonging to the head of the subject or the hands, if visible, are detected
and tracked, providing general expressivity features, such as speed and power
of movement (Bevacqua et al., 2006).
For physiological data, despite being researched for a long time
especially by psychologists, no systematic approach to store or annotate them
is in place. However, there are first attempts to include them in databases
(Blech et al., 2005), and suggestions on how they could be represented in
digital systems have been made (Peter and Herbon, 2006). A main difficulty
with physiological measurements is the variety of possibilities to obtain the
data and of the consequential data enhancement steps. Since these factors can
directly affect the result of the emotion interpretation, a generic emotion
markup language needs to be able to deal with such low-level issues. The same
applies to the technical parameters of other modalities, such as resolution
and frame rate of cameras, the dynamic range or the type of sound field of
the chosen microphone, and algorithms used to enhance the data.
Finally, individual modalities can be merged, either at feature- or
decision-level, to provide multimodal recognition. In this case, features and
timing information (duration, peak, slope, etc.) from individual modalities
are still present, but an integrated emotion label is also assigned to the
multimedia file or stream in question. In addition to this, a confidence
measure for each feature and decision assists in providing flexibility and
robustness in automatic or user-assisted methods.
3.3 Generation
We divided the 15 use cases in the generation category into a number of
further sub categories, these dealt with essentially simulating modelled
emotional processes, generating face and body gestures and generating
emotional speech.
The use cases in this category had a number of common elements that
represented triggering the generation of an emotional behaviour according to
a specified model or mapping. In general, emotion eliciting events are passed
to an emotion generation system that maps the event to an emotion state which
could then be realised as a physical representation, e.g. as gestures, speech
or behavioural actions.
The generation use cases presented a number of interesting issues that
focused the team on the scope of the work being undertaken. In particular,
they showed how varied the information being passed to and information being
received from an emotion processing system can be. This would necessitate
either a very flexible method of receiving and sending data or to restrict
the scope of the work in respect to what types of information can be
handled.
The first sub set of generation use cases were termed 'Affective
Reasoner', to denote emotion modelling and simulation. Three quite different
systems were outlined in this sub category, one modelling cognitive emotional
processes, one modelling the emotional effects of real time events such as
stock price movements on a system with a defined personality and a large ECA
system that made heavy use of XML to pass data between its various
processes.
The next sub set dealt with the generation of automatic facial and body
gestures for characters. With these use cases, the issue of the range of
possible outputs from emotion generation systems became apparent. While all
focused on generating human facial and body gestures, the possible range of
systems that they connect to was large, meaning the possible mappings or
output schema would be large. Both software and robotic systems were
represented and as such the generated gesture information could be sent to
both software and hardware based systems on any number of platforms. While a
number of standards are available for animation that are used extensively
within academia (e.g., MPEG-4 (Tekalp and Ostermann, 2000), BML (Kopp et al.,
2006)), they are by no means common in industry.
The final sub set was primarily focused on issues surrounding emotional
speech synthesis, dialogue events and paralinguistic events. Similar to the
issues above, the generation of speech synthesis, dialogue events,
paralinguistic events etc. is complicated by the wide range of possible
systems to which the generating system will pass its information. There does
not seem to be a widely used common standard, even though the range is not
quite as diverse as with facial and body gestures. Some of these systems made
use of databases of emotional responses and as such might use an emotion
language as a method of storing and retrieving this information.
4. Requirements
Overview
The following represents a collection of requirements for an Emotion
Markup Language ("EmotionML") as they arise from the use cases specified
above. Each scenario described through the use cases has implicit
requirements which need need to be made explicit to allow for their
representation through a language. The challenge with the 39 use case
scenarios collected in the Emotion Incubator group was to structure the
extracted requirements in a way that reduces complexity, and to agree on what
should be included in the language itself and what should be described
through other, linked representations.
Work proceeded in a bottom-up, iterative way. From relatively unstructured
lists of requirements for the individual use case scenarios, a requirements
document was compiled within each of the three use case categories (Data
Annotation, Emotion Recognition and Emotion Generation). These three
documents differed in structure and in the vocabulary used, and emphasised
different aspects. For example, while the Data Annotation use case emphasised
the need for a rich set of metadata descriptors, the Emotion Recognition use
case pointed out the need to refer to sensor data and environmental
variables, and the use case on Emotion Generation requested a representation
for the 'reward' vs. 'penalty' value of things. The situation was complicated
further by the use of system-centric concepts such as 'input' and 'output',
which for Emotion Recognition have fundamentally different meanings than for
Emotion Generation. For consolidating the requirements documents, two basic
principles were agreed on:
- The emotion language should not try to represent sensor data, facial
expressions, environmental data etc., but define a way of interfacing
with external representations of such data.
- The use of system-centric vocabulary such as 'input' and 'output'
should be avoided. Instead, concept names should be chosen by following
the phenomena observed, such as 'experiencer', 'trigger', or 'observable
behaviour'.
Based on these principles and a large number of smaller clarifications,
the three use case specific requirements documents were merged into an
integrated wiki document. After several iterations of restructuring and
refinement, a consolidated structure has materialised for that document. The
elements of that document are grouped into sections according to the type of
information that they represent: (1) Information about the emotion
properties, (2) Meta-information about the individual emotion annotations,
(3) links to the rest of the world, (4) information about a number of global
metadata, and (5) ontologies.
4.1. Information about the emotion properties (Emotion
'Core')
4.1.1. Type of emotion-related phenomenon
The language should not only annotate emergent emotions, i.e. emotions in
the strong sense (such as anger, joy, sadness, fear, etc.), but also
different types of emotion-related states.
The emotion markup should provide a way of indicating which of these (or
similar) types of emotion-related/affective phenomena is being annotated.
The following use cases require annotation of emotion categories and
dimensions:
4.1.2. Emotion categories
The emotion markup should provide a generic mechanism to represent broad
and small sets of possible emotion-related states. It should be possible to
choose a set of emotion categories (a label set), because different
applications need different sets of emotion labels. A flexible mechanism is
needed to link to such sets. A standard emotion markup language should
propose one or several "default" set(s) of emotion categories, but leave the
option to a user to specify an application-specific set instead.
Douglas-Cowie et al. (2006) propose a list of 48 emotion categories that
could be used as the "default" set.
The following use cases demonstrate the use of emotion categories:
4.1.3. Emotion dimensions
The emotion markup should provide a generic format for describing emotions
in terms of emotion dimensions. As for emotion categories, it is not possible
to predefine a normative set of dimensions. Instead, the language should
provide a "default" set of dimensions, that can be used if there are no
specific application constraints, but allow the user to "plug in" a custom
set of dimensions if needed. Typical sets of emotion dimensions include
"arousal, valence and dominance" (known in the literature by
different names, including "evaluation, activation and power"; "pleasure,
arousal, dominance"; etc.). Recent evidence suggests there should be a fourth
dimension: Roesch et al. (2006) report consistent results from various
cultures where a set of four dimensions is found in user studies: "valence, potency, arousal, and unpredictability".
The following use cases demonstrate use of dimensions for representing
emotional states:
4.1.4. Description of appraisals of the emotion or of
events related to the emotion
Description of appraisal can be attached to the emotion itself or to an
event related to the emotion. Three groups of emotional events are defined in
the OCC model (Ortony, Clore, & Collins, 1988): the consequences of
events for oneself or for others, the actions of others and the perception of
objects.
The language will not cover other aspects of the description of events.
Instead, there will be a possibility to attach an external link to the
detailed description of this event according to an external representation
language. The emotion language could integrate description of events (OCC
events, verbal description) and time of event (past, present, future).
Appraisals can be described with a common set of intermediate terms
between stimuli and response, between organism and environment. The appraisal
variables are linked to different cognitive process levels in the model of
Leventhal and Scherer (1987). The following set of labels (Scherer et al.,
2004) can be used to describe the protagonist's appraisal of the event or
events at the focus of his/her emotional state:relevance, implications Agency
responsible, coping potential, compatibility of the situation with standards.
Use cases:
4.1.5 Action tendencies
It should be possible to characterise emotions in terms of the action
tendencies linked to them (Frijda, 1986). For example, anger is linked to a
tendency to attack, fear is linked to a tendency to flee or freeze, etc. This
requirement is not linked to any of the currently envisaged use cases, but
has been added in order to cover the theoretically relevant components of
emotions better. Action tendencies are potentially very relevant for use
cases where emotions play a role in driving behaviour, e.g. in the behaviour
planning component of non-player characters in games.
4.1.6. Multiple and/or complex emotions
The emotion markup should provide a mechanism to represent mixed
emotions.
The following use cases demonstrate use of multiple and / or complex
emotions:
4.1.7. Emotion intensity
The intensity is also a dimension. The emotion markup should provide an
emotion attribute to represent the intensity. The value of attribute
intensity is in [0;1].
The following use cases are examples for use of intensity information on
emotions:
4.1.8. Emotion regulation
According to the process model of emotion regulation described by Gross
(2001), emotion may be regulated at five points in the emotion generation
process: selection of the situation, modification of the situation,
deployment of attention, change of cognition, and modulation of experiential,
behavioral or physiological responses. The most basic distinction underlying
the concept of regulation of emotion-related behaviour is the distinction of
internal vs. external state. The description of the external state is out of
scope of the language - it can be covered by referring to other languages
such as Facial Action Coding System (Ekman et al. 2002), Behavior Mark-up
Language (Vilhjalmsson et al. 2007).
Other types of regulation-related information can represent genuinely
expressed/felt (inferred)/masked(how well)/simulated, or inhibition/masking
of emotions or expression, or excitation/boosting of emotions or expression.
The emotion markup should provide emotion attributes to represent the
various kinds of regulation. The value of these attributes should be in
[0;1].
The following use cases are examples for regulation being of interest:
4.1.9. Temporal aspects
This section covers information regarding the timing of the emotion
itself. The timing of any associated behaviour, triggers etc. is covered in
section 4.3 "Links to the rest of the world".
The emotion markup should provide a generic and optional mechanism for
temporal scope. This mechanism allows different way to specify temporal
aspects such as i) start-time + end-time, ii) start-time+duration, iii) link
to another entity (start 2 seconds before utterance starts and ends with the
second noun-phrase...), iv) a sampling mechanism providing values for
variables at even spaced time intervals.
The following use cases require the annotation of temporal dynamics of
emotion.:
4.2.1. Acting
The emotion markup should provide a mechanism to add special attributes
for acted emotions such as perceived naturalness, authenticity, quality, and
so on.
Use cases:
4.2.2. Confidence / probability
The emotion markup should provide a generic attribute enabling to
represent the confidence (or, inversely, uncertainty) of detection/annotation
or more generally speaking of probability to be assigned to one
representation of emotion to each level of representation (category,
dimensions, degree of acting, ...). This attribute may reflect the confidence
of the annotator that the particular value is as stated (e.g. that the user
in question is expressing happiness with confidence 0.8), which
is important especially in masked expressivity, or the confidence of an
automated recognition system with respect to the samples used for training.
If this attribute is supplied per modality it can be exploited in
recognition use cases to pinpoint the dominant or more robust of the existing
modalities.
The following use cases require the annotation of confidence:
4.2.3. Modality
It represents the modalities in which the emotion is reflected, e.g. face,
voice, body posture or hand gestures, but also lighting, font shape, etc.
The emotion markup should provide a mechanism to represent an open set of
values.
The following use cases require the annotation of modality:
4.3. Links to the "rest of the world"
Most use cases rely on some media representation. This could be video
files of users' faces whose emotions are assessed, screen captures of
evaluated user interfaces, audio files of interviews, but also other media
relevant in the respective context, like pictures or documents.
Linking to them could be
accomplished by e.g. an URL in an XML node.
The following use cases require links to the "rest of the world":
4.3.2. Position on a time line in externally linked
objects
The emotion markup should provide a link to a time-line. Possible values
of temporal linking are absolute (start- and end-times) and
relative and refer to external sources (cf. 4.3.1) like snippets (as
points in time) of media files causing the emotion.
Start- and end-times are important to mark onset and offset of an
emotional episode.
The following use cases require annotation on specific positions on a time
line:
4.3.3. The semantics of links to the "rest of the
world"
The emotion markup should provide a mechanism for flexibly
assigning meaning to those links.
The following initial types of meaning are envisaged:
- The experiencer (who "has" the emotion);
- The observable behaviour "expressing" the emotion;
- The trigger/cause/emotion-eliciting event of the emotion;
- The object/target of the emotion (the thing that the emotion is about).
We currently envisage that the links to media as defined in section 4.3.1
are relevant for all of the above. For some of them, timing information is
also relevant:
- observable behaviour
- trigger
The following use cases require annotation on semantics of the links to
the "rest of the world":
Representing emotion, be it for annotation, detection or generation,
requires the description of the context not directly related to the
description of emotion per se (e.g. the emotion-eliciting event) but also the
description of a more global context which is required for properly
exploiting the representation of the emotion in a given application.
Specifications of metadata for multimodal corpora have already been proposed
in the ISLE Metadata Initiative [IMDI]; but they did
not target emotional data and were focused on an annotation scenario.
The joint specification of our three use cases led to the identification
of four groups of global metadata: information on persons involved, the
purpose of classification i.e. the intended or used application, information
on the technical environment, and on the social and communicative
environment. Those are described in the following.
The following use cases require annotation of global metadata:
4.4.1. Info on Person(s)
Information are needed on the humans involved. Depending on the use case,
this would be the labeler(s) (Data Annotation), persons observed (Data
Annotation, Emotion Recognition), persons interacted with, or even
computer-driven agents such as ECAs (Emotion Generation). While it would be
desirable to have common profile entries throughout all use cases, we found
that information on persons involved are very use case specific. While all
entries could be provided and possibly used in most use cases, they are of
different importance to each.
Examples are:
- For Data Annotation: gender, age, language, culture, personality
traits, experience as labeler, labeler ID (all mandatory)
- For Emotion Recognition: gender, age, culture, personality traits,
experience with the subject, e.g. web experience for usability studies
(depending on the use case all or some mandatory).
- For Emotion Generation:gender, age, language, culture, education,
personality traits (again, use case dependant)
The following use cases need information on the person(s) involved:
4.4.2. Purpose of classification
The result of emotion classification is influenced by its purpose. For
example, a corpus of speech data for training an ECA might be differently
labelled than the same data used for a corpus for training an automatic
dialogue system for phone banking applications; or the face data of a
computer user might be differently labeled for the purpose of usability
evaluation or guiding an user assistance program.These differences are
application or at least genre specific. They are also independent from the
underlying emotion model.
The following use cases need information on the purpose of the
classification:
4.4.3. Technical environment
The quality of emotion classification and interpretation, by either humans
or machines, depend on the quality and technical parameters of sensors and
media used.
Examples are:
- Frame rate, resolution, colour characteristics of video sources;
- Dynamic range, type of sound field of microphones;
- Type of sensing devices for physiology, movement, or pressure
measurements;
- Data enhancement algorithms applied by either device or pre-processing
steps.
Also should the emotion markup be able to hold information on which way an
emotion classification has been obtained, e.g. by a human observer monitoring
a subject directly, or via a life stream from a camera, or a recording; or by
a machine, utilising which algorithms.
The following use cases need information on the technical environment:
4.4.4. Social and communicative environment
The emotion markup should provide a global information to specify
genre of the observed social and communicative environment and more
generally of the situation in which an emotion is considered to happen (e.g.
fiction (movies, theater), in-lab recording, induction, human-human,
human-computer (real or simulated)), interactional situation (number
of people, relations, link to participants).
The following use cases require annotation of the social and communicative
environment:
4.5. Ontologies of emotion descriptions
Descriptions of emotions and of emotion-related states are heterogeneous,
and are likely to remain so for a long time. Therefore, complex systems such
as many foreseeable real-world applications will require some information
about (1) the relationships between the concepts used in one description and
about (2) the relationships between different descriptions.
4.5.1. Relationships between concepts in an emotion
description
The concepts in an emotion description are usually not independent, but
are related to one another. For example, emotion words may form a hierarchy,
as suggested e.g. by prototype theories of emotions. For example, Shaver et
al. (1987) classified cheerfulness, zest, contentment, pride, optimism
enthrallment and relief as different kinds of joy, irritation, exasperation,
rage, disgust, envy and torment as different kinds of anger, etc.
Such structures, be they motivated by emotion theory or by
application-specific requirements, may be an important complement to the
representations in an Emotion Markup Language. In particular, they would
allow for a mapping from a larger set of categories to a smaller set of
higher-level categories.
The following use case demonstrates possible use of hierarchies of
emotions:
4.5.2. Mappings between different emotion
representations
Different emotion representations (e.g., categories, dimensions, and
appraisals) are not independent; rather, they describe different parts of the
"elephant", of the phenomenon emotion. Insofar, it is conceptually possible
to map from one representation to another one in some cases; in other cases,
mappings are not fully possible.
Some use cases require mapping between different emotion representations:
e.g., from categories to dimensions, from dimensions to coarse categories (a
lossy mapping), from appraisals onto dimensions, from categories to
appraisals, etc.
Such mappings may either be based on findings from emotion theory or they
can be defined in an application-specific way.
The following use cases require mappings between different emotion
representations:
- 2b "Multimodal
emotion recognition" - different modalities might deliver their
emotion result in different representations
- 3b "the ECA
system", it is based on a smaller set of emotion categories compared
with the list of categories that are generated in use case 3a, so a
mapping mechanism is needed to convert the larger category set to a
smaller set
- 3b speech synthesis
with emotion dimensions would require a mapping from appraisals or
emotion categories if used in combination with an affective reasoner (use
case 3a).
4.6. Assessment in the light of emotion theory
The collection of use cases and subsequent definition of requirements
presented so far was performed in a predominantly bottom-up fashion, and thus
captures a strongly application centered, engineering driven view. The
purpose of this section is to compare the result with a theory centered
perspective. A representation language should be as theory independent as
possible but by no means ignorant of psychological theories. Therefore a
crosscheck to which extent components of existing psychological models of
emotion are mirrored in the currently collected requirements is performed.
In Section 2, a
list of prominent concepts that have been used by psychologists in their
quest for describing emotions has been presented. In this section it is
briefly discussed whether and how these concepts are mirrored in the current
list of requirements.
Subjective component: Feelings.
Feelings have not been mentioned in the requirements at all.
They are not to be explicitly included in the representation for the moment
being, as they are defined as internal states of the subject and are thus not
accessible to observation. Applications can be envisaged where feelings might
be of relevance in the future though, e.g. if self-reports are to be encoded.
It should thus be kept as an open issue on whether to allow for an explicit
representation of feelings as a separate component in the future.
Cognitive component: Appraisals
As a references to appraisal-related theories the OCC model (Ortony et al
1988), which is especially popular in the computational domain, has been
brought up in the use cases, but no choice for the exact set of appraisal
conditions is to be made here. An open issue is whether models that make
explicit predictions on the temporal ordering of appraisal checks (Sander et
al., 2005) should be encodable to that level of detail. In general,
appraisals are to be be encoded in the representation language via
attributing links to trigger objects.
The encoding of other cognitive aspects, i.e. effects of emotions on the
cognitive system (memory, perception, etc.) is to be kept an open issue.
Physiological component:
Physiological measures have been mentioned in the context of emotion
recognition. They are to be integrated in the representation via links to
externally encoded measures conceptualised as "observable behaviour".
Behavioral component: Action tendencies
It remains an issue of theoretical debate whether action tendencies, in
contrast to actions, are among the set of actually observable concepts.
Nevertheless these should be integrated in the representation language. This
once again can be achieved via the link mechanism, this time an attributed
link can specify an action tendency together with its object or target.
Expressive component:
Expressions are frequently referred to in the requirements. There is
agreement to not encode them directly but again to make use of the linking
mechanisms to
observable behaviours.
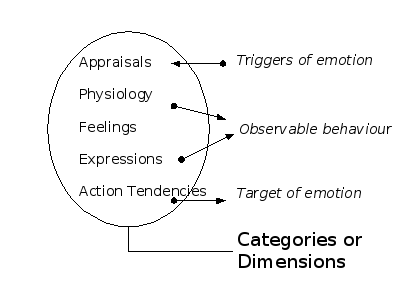
Figure 1. Overview of how components of emotions are to be linked to external
representations.
Emergent emotions vs. other emotion-related states
It was mentioned before that the representation language should
definitively not be restricted to emergent emotions which have received most
attention so far. Though emergent emotions make up only a very small part of
the emotion-related states, they nevertheless are sort of archetypes.
Representations developed for emergent emotions should thus be usable as
basis for the encoding of other important emotion-related states such as
moods and attitudes.
Scherer (2000) systematically defines the relationship between emergent
emotions and other emotion-related states by proposing a small set of
so-called design features. Emergent emotions are defined as having a
strong direct impact on behaviour, high intensity, being rapidly changing and
short, are focusing on a triggering event and involve strong appraisal
elicitation. Moods e.g. are in contrast described using the same set of
categories, and they are characterised as not having a direct impact on
behaviour, being less intense, changing less quickly and lasting longer, and
not being directly tied to a eliciting event. In this framework different
types of emotion-related states thus just arise from differences in the
design features.
It is an open issue whether to integrate means similar to Scherer's design features in the language. Because
probably not many applications will be able to make use of this level of
detail, simple means for explicitly defining the type of an emotion related
state should be made available in the representation language anyway.
5. Assessment of Existing Markup Languages
Part of the activity of the group was dedicated to the assessment of
existing markup languages in order to investigate if some of their elements
or even concepts could fulfill the Emotion language requirements as described
in section 4. In the perspective of an effective Emotional Markup design it
will be in fact important to re-use concepts and elements that other
languages thoroughly define. Another interesting aspect of this activity has
been the possibility to hypothesize the interaction of the emotion markup
language with other existing languages and particularly with those concerning
multimodal applications.
Seven markup languages have been assessed, five of them are the result of
W3C initiatives that led to recommendation or draft documents, while the
remaining are the result of other initiatives, namely the projects HUMAINE
and INTERFACE.
5.1 Assessment methodology
The assessments were undertaken when the requirements of the emotion
language were almost consolidated. To this end, the members of the group
responsible for this activity adopted the same methodology that basically
consisted in identifying among the markup specifications those elements that
could be consistent with the emotional language constraints. In some cases
links to the established Emotion Requirements were possible, being the
selected elements totally fulfilling their features, while in other cases
this was not possible even if the idea behind a particular tag could
nevertheless be considered useful. Sometimes, to clarify the concepts,
examples and citations from the original documents were included.
These analyses, reported in Appendix 2, were initially published on the Wiki page,
available for comments and editing to all the members of the incubator group.
The structure of these documents consists of an introduction containing
references to the analyzed language and a brief description of its uses. The
following part reports a description of the selected elements that were
judged as fulfilling the emotion language requirements.
The five W3C Markup languages considered in this analysis are mainly
designed for multimedia application. They deal with speech recognition and
synthesis, ink and gesture recognition, semantic interpretation and the
writing of interactive multimedia presentations. Among the two remaining
markup languages, EARL (Schröder et al., 2006), whose aim is the annotation
and representation of emotions, is an original proposal from the HUMAINE
consortium. The second one, VHML, is a language based on XML sub-languages
such as DMML (Dialogue Manager Markup Language), FAML (Facial Animation
Markup Language) and BAML (Body Animation Markup Language).
In detail, the existing markup languages that have been assessed are:
- SMIL Synchronized Multimedia Integration Language (Version 2.1) W3C
Recommendation 13 December 2005 [SMIL ]
- SSML Speech Synthesis Markup Language (Version 1.0) W3C Recommendation
7 September 2004 [SSML ]
- EMMA Extensible MultiModal Annotation markup language W3C Working Draft
9 April 2007 [EMMA ]
- PLS Pronunciation Lexicon Specification (Version 1.0) W3C Working Draft
26 October 2006 [PLS ]
- InkML Ink Markup Language (InkML) W3C Working Draft 23 October 2006 [InkML ]
- EARL Emotion Annotation and Representation Language (version 0.4.0)
Working draft 30 June 2006 [EARL
]
- VHML Virtual Human Markup Language (Version 0.3) Working draft 21
October 2001 [VHML ]
5.2 Results
Many of the requirements of the emotion markup language cannot be found in
any of the considered W3C markups. This is particularly true for the emotion
specific elements, i.e. those features that can be considered the core part
of the emotional markup language. On the other hand, we could find
descriptions related to emotions in EARL and to some extent in VHML. The
first one in particular provides mechanisms to describe, through basic tags,
most of the required elements. It is in fact possible to specify the emotion
categories, the dimensions, the intensity and even appraisals selecting the
most appropriate case from a pre-defined list. Moreover, EARL includes
elements to describe mixed emotions as well as regulation mechanisms like for
example the degree of simulation or suppression. In comparison VHML, that is
actually oriented to the behavior generation use case, provides very few
emotion related features. It is only possible to use emotion categories (a
set of nine is defined) and indicate the intensity. Beyond these features
there is also the emphasis tag that is actually derived from the GML (Gesture
Markup Language) module.
Beyond the categorical and dimensional description of the emotion itself,
neither EARL nor VHML provide any way to deal with emotion-related phenomena
like for example attitudes, moods or affect dispositions.
The analyzed languages, W3C initiatives or not, offer nevertheless
interesting approaches for the definition of elements that are not strictly
related to the description of emotions, but are important structural elements
in any markup language. In this sense, interesting solutions to manage timing
issues, to annotate modality and to include metadata information were
found.
Timing, as shown in the requirements section, is an important aspect in
the emotional language markup. Time references are necessary to get the
synchronization with external objects and when we have to represent the
temporal evolution of the emotional event (either recognized, generated or
annotated). W3C SMIL and EMMA both provide solutions to indicate absolute
timing as well as relative instants with respect to a reference point that
can be explicitly indicated as in EMMA or can also be an event like in SMIL
standard. SMIL has also interesting features to manage the synchronization of
parallel events.
Metadata is another important element included in the emotional markup.
The W3C languages provide very flexible mechanisms that could allow the
insertion of any kind of information, for example related to the subject of
the emotion, the trigger event, and finally the object, into this container.
Metadata annotation is available in SMIL, SSML, EMMA and VHML languages
through different strategies, from simple tags like the info element proposed
by EMMA (a list of unconstrained attribute-value couples) to more complex
solutions like in SMIL and SSML where RDF features are exploited.
Also referring to modality the considered languages provide different
solutions, from simple to articulated ones. Modality is present in SMIL,
EMMA, EARL and VHML (by means of other sub languages). They are generally
mechanisms that describe the mode in which emotion is expressed (face, body,
speech, etc.). Some languages get into deeper annotations by considering the
medium or channel and the function. To this end, EMMA is an example of an
exhaustive way of representing modalities in the recognition use case. These
features could be effectively extended to the other use cases, i.e.
annotation and generation.
Regarding interesting ideas, some languages provide mechanisms that are
useful to manage dynamic lists of elements. An example of this can be found
in the W3C PLS language, where name spaces are exploited to manage multiple
sets of features.
6. Summary and Outlook
This first year as a W3C Incubator group was a worthwhile endeavour. A
group of people with diverse backgrounds collaborated in a very constructive
way on a topic which for a considerable time appeared to be a fuzzy area.
During the year, however, the concepts became clearer; the group came to
an agreement regarding the delimitation of the emotion markup language to
related content (such as the representation of emotion-related expressive
behaviour). Initially, very diverse ideas and vocabulary arose in a bottom-up
fashion from use cases; the integration of requirements into a consistent
document consumed a major part of the time.
The conceptual challenges encountered during the creation of the
Requirements document were to be expected, given the interdisciplinary nature
of the topic area and the lack of consistent guidelines from emotion theory.
The group made important progress, and has produced a structured set of
requirements for an emotion markup language which, even though it was driven
by use cases, can be considered reasonable from a scientific point of view.
A first step has been carried out towards the specification of a markup
language fulfilling the requirements: a broad range of existing markup
languages from W3C and outside of W3C were investigated and discussed in view
of their relevance to the EmotionML requirements. This survey provides a
starting point for creating a well-informed specification draft in the
future.
There is a strong consensus in the group that continuing the work is
worthwhile. The unanimous preference is to run for a second year as an
Incubator group, whose central aim is to convert the conceptual work done so
far into concrete suggestions and requests for comments from existing W3C
groups: the MMI and VoiceBrowser groups. The current plan is to provide three
documents for discussion during the second year as Incubator:
- a simplified Requirements document with priorities (in time for
face-to-face discussions at the Cambridge meeting in November);
- an "early Incubator draft" version of an EmotionML specification, after
6 months;
- a "final Incubator draft" version of an EmotionML specification, after
12 months.
If during this second year, enough interest from the W3C constituency is
raised, a continuation of the work in the Recommendation Track is
envisaged.
7. References
7.1 Scientific references
Arnold, M., (1960). Emotion and
Personality, Columbia University Press, New York.
Batliner, A., et al. (2006). Combining efforts for improving automatic
classification of emotional user states. In: Proceedings IS-LTC 2006.
Bevacqua, E., Raouzaiou, A., Peters, C., Caridakis, G., Karpouzis, K.,
Pelachaud, C., Mancini, M. (2006). Multimodal sensing, interpretation and
copying of movements by a virtual agent. In: Proceedings of Perception and Interactive
Technologies (PIT'06).
Blech, M., Peter, C., Stahl, R., Voskamp, J., Urban, B.(2005). Setting up
a multimodal database for multi-study emotion research in HCI. In: Proceedings of the 2005 HCI International
Conference, Las Vegas
Burkhardt, F., van Ballegooy, M., Englert, R., & Huber, R. (2005). An
emotion-aware voice portal. Proc. Electronic Speech Signal Processing
ESSP.
Devillers, L., Vidrascu, L., Lamel, L. (2005). Challenges in real-life
emotion annotation and machine learning based detection. Neural Networks 18,
407-422
Douglas-Cowie, E., et al. (2006). HUMAINE deliverable D5g: Mid Term Report
on Database Exemplar Progress. http://emotion-research.net/deliverables/D5g%20final.pdf
Ekman, P., Friesen, W. (1978). The Facial
Action Coding System. Consulting Psychologists Press, San Francisco
Ekman, P., Friesen, W. C. and Hager, J. C. (2002). Facial Action Coding System. The Manual on CD
ROM. Research Nexus division of Network Information Research
Corporation.
Frijda, N (1986). The Emotions. Cambridge: Cambridge University
Press.
Gross, J. J. (2001). "Emotion regulation in adulthood: timing is
everything." Current Directions in Psychological Science 10(6). http://www-psych.stanford.edu/~psyphy/Pdfs/2001%20Current%20Directions%20in%20Psychological%20Science%20-%20Emo.%20Reg.%20in%20Adulthood%20Timing%20.pdf
Kopp, S., Krenn, B., Marsella, S., Marshall, A., Pelachaud, C., Pirker,
H., Thórisson, K., & Vilhjalmsson, H. (2006). Towards a common framework
for multimodal generation in ECAs: the Behavior Markup Language. In
Proceedings of the 6th International Conference on Intelligent Virtual Agents
(IVA'06).
Lazarus, R.S. (1966). Psychological stress and the coping process.
McGraw-Hill. New York.
Leventhal, H., and Scherer, K. (1987). The Relationship of Emotion to
Cognition: A Functional Approach to a Semantic Controversy. Cognition and
Emotion 1(1):3-28.
Ortony, A Clore, G.L. and Collins A (1988). The cognitive structure of emotions.
Cambridge University Press, New York.
Peter, C., Herbon, A. (2006). Emotion representation and physiology
assignments in digital systems. Interacting
With Computers 18, 139-170.
Roesch, E.B., Fontaine J.B. & Scherer, K.R. (2006). The world of
emotion is two-dimensional - or is it? Paper presented to the HUMAINE Summer
School 2006, Genoa.
Russell, J. A.. & Feldman Barrett L (1999). Core Affect, Prototypical
Emotional Episodes, and Other Things Called Emotion: Dissecting the
Elephant Journal of Personalityand Social Psychology,
76, 805-819.
Sander, D., Grandjean, D., & Scherer, K. (2005). A systems approach to
appraisal mechanisms in emotion. Neural Networks: 18, 317-352.
Scherer, K.R. (2000). Psychological models of emotion. In Joan C. Borod
(Ed.), The Neuropsychology of Emotion (pp. 137-162). New York: Oxford
University Press.
Scherer, K. R. et al. (2004). Preliminary plans for exemplars: Theory.
HUMAINE deliverable D3c. http://emotion-research.net/deliverables/D3c.pdf
Schröder, M., Pirker, H., Lamolle, M. (2006). First suggestions for an
emotion annotation and representation language. In: Proceedings of LREC'06 Workshop on Corpora for
Research on Emotion and Affect, Genoa, Italy, pp. 88-92
Shaver, P., Schwartz, J., Kirson, D., and O'Connor, C. (1987). Emotion
knowledge: Further exploration of a prototype approach. Journal of Personality and Social
Psychology, 52:1061-1086.
Tekalp, M., Ostermann, J. (2000): Face and 2-d mesh animation in MPEG-4.
Image Communication Journal 15,
387-421
Vilhjalmsson, H., Cantelmo, N., Cassell, J., Chafai, N. E., Kipp, M.,
Kopp, S., Mancini, M., Marsella, S., Marshall, A. N., Pelachaud, C., Ruttkay,
Z., Thórisson, K. R., van Welbergen, H. and van der Werf, R. J. (2007). The
Behavior Markup Language: Recent Developments and Challenges. 7th
International Conference on Intelligent Virtual Agents (IVA'07), Paris,
France.
Wilhelm, P., Schoebi, D. & Perrez, M. (2004). Frequency estimates of
emotions in everyday life from a diary method's perspective: a comment on
Scherer et al.'s survey-study "Emotions in everyday life". Social Science
Information, 43(4), 647-665.
7.2 References to Markup Specifications
- [SMIL]
- Synchronized Multimedia Integration Language (Version 2.1), W3C
Recommendation 13 December 2005 http://www.w3.org/TR/SMIL/
- [SSML]
- Speech Synthesis Markup Language (Version 1.0) W3C Recommendation 7
September 2004 http://www.w3.org/TR/speech-synthesis
- [EMMA]
- Extensible MultiModal Annotation markup language W3C Working Draft 9
April 2007 http://www.w3.org/TR/emma/
- [PLS]
- Pronunciation Lexicon Specification (Version 1.0) W3C Working Draft
26 October 2006 http://www.w3.org/TR/pronunciation-lexicon/
- [InkML]
- Ink Markup Language (InkML) W3C Working Draft 23 October 2006 http://www.w3.org/TR/InkML
- [EARL]
- Emotion Annotation and Representation Language (version 0.4.0)
Working draft 30 June 2006 http://emotion-research.net/earl
- [VHML]
- Virtual Human Markup Language (Version 0.3) Working draft 21 October
2001 http://www.vhml.org/
- [IMDI]
- ISLE Metadata Initiative (IMDI). http://www.mpi.nl/IMDI/
8. Acknowledgements
The editors acknowledge significant contributions from the following
persons (in alphabetical order):
- Paolo Baggia, Loquendo
- Laurence Devillers, Limsi
- Alejandra Garcia-Rojas, Ecole Polytechnique Federale de Lausanne
- Kostas Karpouzis, Image, Video and Multimedia Systems Lab (IVML-NTUA)
- Myriam Lamolle, Université Paris VIII
- Jean-Claude Martin, Limsi
- Catherine Pelachaud, Université Paris VIII
- Björn Schuller, Technical University Munich
- Jianhua Tao, Chinese Academy of Sciences
- Ian Wilson, Emotion.AI
Appendix 1: Use Cases
Use case 1: Annotation of emotional data
Use case 1a: Annotation of plain text
Alexander is compiling a list of emotion words and wants to annotate, for
each word or multi-word expression, the emotional connotation assigned to it.
In view of automatic emotion classification of texts, he is primarily
interested in annotating the valence of the emotion (positive vs. negative),
but needs a 'degree' value associated with the valence. In the future, he is
hoping to use a more sophisticated model, so already now in addition to
valence, he wants to annotate emotion categories (joy, sadness, surprise,
...), along with their intensities. However, given the fact that he is not a
trained psychologist, he is uncertain which set of emotion categories to use.
Use case 1b: Annotation of XML structures and files
(i) Stephanie is using a multi-layer annotation scheme for corpora of
dialog speech, using a stand-off annotation format. One XML document
represents the chain of words as individual XML nodes; another groups them
into sentences; a third document describes the syntactic structure; a fourth
document groups sentences into dialog utterances; etc. Now she wants to add
descriptions of the 'emotions' that occur in the dialog utterances (although
she is not certain that 'emotion' is exactly the right word to describe what
she thinks is happening in the dialogs): agreement, joint laughter, surprise,
hesitations or the indications of social power. These are emotion-related
effects, but not emotions in the sense as found in the textbooks.
(ii) Paul has a collection of pictures showing faces with different
expressions. These pictures were created by asking people to contract
specific muscles. Now, rating tests are being carried out, in which subjects
should indicate the emotion expressed in each face. Subjects can choose from
a set of six emotion terms. For each subject, the emotion chosen for the
corresponding image file must be saved into an annotation file in view of
statistical analysis.
(iii) Felix has a set of Voice portal recordings and wants to use them to
train a statistical classifier for vocal anger detection. They must be
emotion-annotated by a group of human labelers. The classifier needs each
recording labeled with the degree of anger-related states chosen from a bag
of words.
Beneath this, some additional data must be annotated also:
- for the dialog design, beneath to know IF a user is angry, it's even
more important to know WHY the user is angry: is the user displeased with
the dialog itself, e.g. too many misrecognitions? Does he hate talking to
machines as a rule? Is he dissatisfied with the company`s service? Is he
simply of aggressive character?
- often voice portal recordings are
- -not human but DTMF tones or
background noises (e.g. a lorry driving by) -not directed to the
dialog but to another person standing beneath the user
- the classifier might use human annotated features for
training, e.g. transcript of words, task in application, function in
dialog, ... this should be annotated also
(iv) Jianhua allows listeners to label the speech with multiple emotions
to form the emotion vector.
Use case 1c: Chart annotation of time-varying signals
(e.g., multi-modal data)
(i) Jean-Claude and Laurence want to annotate audio-visual recordings of
authentic emotional recordings. Looking at such data, they and their
colleagues have come up with a proposal of what should be annotated in order
to properly describe the complexity of emotionally expressive behaviour as
observed in these clips. They are using a video annotation tool that allows
them to annotate a clip using a 'chart', in which annotations can be made on
a number of layers. Each annotation has a start and an end time.
The types of emotional properties that they want to annotate are many.
They want to use emotion labels, but sometimes more than one emotion label
seems appropriate -- for example, when a sad event comes and goes within a
joyful episode, or when someone is talking about a memory which makes them at
the same time angry and desperate. Depending on the emotions involved, this
co-occurrence of emotions may be interpretable as a 'blend' of 'similar'
emotions, or as a 'conflict' of 'contradictory' emotions. The two emotions
that are present may have different intensities, so that one of them can be
identified as the major emotion and the other one as the minor emotion.
Emotions may be communicated differently through different modalities, e.g.
speech or facial expression; it may be necessary to annotate these
separately. Attempts to 'regulate' the emotion and/or the emotional
expression can occur: holding back tears, hiding anger, simulating joy
instead. The extent to which such regulation is present may vary. In all
these annotations, a given annotator may be confident to various degrees.
In addition to the description of emotion itself, Jean-Claude and Laurence
need to annotate various other things: the object or cause of the emotion;
the expressive behaviour which accompanies the emotion, and which may be the
basis for the emotion annotation (smiling, high pitch, etc.); the social and
situational context in which the emotion occurs, including the overall
communicative goal of the person described; various properties of the person,
such as gender, age, or personality; various properties of the annotator,
such as name, gender, and level of expertise; and information about the
technical settings, such as recording conditions or video quality. Even if
most of these should probably not be part of an emotion annotation language,
it may be desirable to propose a principled method for linking to such
information.
(ii) Stacy annotates videos of human behavior both in terms of observed
behaviors and inferred emotions. This data collection effort informs and
validates the design of our emotion model. In addition, the annotated video
data contributes to the function and behavior mapping processes.
Use case 1d: Trace annotation of time-varying signals
(e.g., multi-modal data)
Cate wants to annotate the same clips as Jean-Claude (1c i), but using a
different approach. Rather than building complex charts with start and end
time, she is using a tool that traces some property scales continuously over
time. Examples for such properties are: the emotion dimensions arousal,
valence or power; the overall intensity of (any) emotion, i.e. the presence
or absence of emotionality; the degree of presence of certain appraisals such
as intrinsic pleasantness, goal conduciveness or sense of control over the
situation; the degree to which an emotion episode seems to be acted or
genuine. The time curve of such annotations should be preserved.
Use case 1e: Multiparty interaction
Dirk studies the ways in which persons in a multi-party discussion
expresses their views, opinions and attitudes. We are particularly interested
in how the conversational moves contribute to the discussion, the way an
argument is settled, how a person is persuaded both with reason and rhetoric.
He collects corpora of multi-party discussions and annotates them on all
kinds of dimensions, one of them being a 'mental state' layer in which he
tries to describe the attitudes that participants express with respect to
what is being said and their emotional reactions to it. This layer includes
elements such as: surprise, scepticism, anger, amusement, enthusiasm. He
studies how these mental states are expressed and the functions of these
expressions within the conversation.
Use case 1f: annotation of emotional speech
Enrico wants to annotate a speech database containing emotional phrases.
This material is used to extract prosodic models that will be used to
appropriately select acoustic units in a corpus based speech synthesis
system. The database consists of short sentences that are recorded from many
speakers that read the scripts simulating certain emotional styles. Actually,
each sentence is read in different emotional styles (e.g. sad, happy, angry,
etc.) and a neutral style is also considered as the baseline. We want to
study the acoustic correlations of the considered emotional styles in order
to extract simple rules that account for the variation of some acoustic
parameters. To achieve this, he needs to annotate the speech data, taking
into account the intensity of the relative emotion and the level of valence.
Use case 1g: annotation of speech acts
In another case, Enrico wants to annotate pre-recorded illocutionary acts.
Most of these prompts are frequently used expressions that have a pragmatic
function such as greetings, thanks, regrets, disapprovals, apologies,
compliments, etc. Given their intrinsic nature, these sentences are read in
an expressive way. Enrico has to group these expressions into linguistic
categories and describe them in terms of emotional intensity. For instance
'Good morning!' could be read in different ways: it could be happy, excited,
or even sad. Moreover, given the emotional style, there could be different
levels of intensity that could be described quantitatively using a range of
values between 0 and 1.
Use case 1h: annotation of paralinguistic events
Enrico wants to annotate para linguistics events such as laughs, sighs,
pains or phenomena like these. These elements have to be described in terms
of event category and of the emotion which they refer to. It could be useful
also to describe quantitatively the effort of these events (for instance
there could be 'weak' laughs or 'exaggerated' laughs).
Use case 1i: Annotation of video clips of acted emotions
Tanja recorded a video corpus where actors under the supervision of a
director were instructed to produce isolated sentences with 10 different
(categorically defined) emotions. In addition some of these emotions had to
be produced with i) increased intensity ii) decreased intensity and iii) in a
manner as the person would try to (unsuccessfully) hide/suppress her emotion.
This way for each sentence its intended emotion, intensity and
possible regulation attempts are already known and can be directly encoded.
In a next step ratings of human annotators are added, who are rating the
quality of the actors' performance: i) on how well the intended
emotional content can be actually perceived (i.e. this is some skewed variant
of 'annotator confidence') and ii) a rating of on how believability and
naturalness of the performance.
In the future extracts of the corpus should be used in classical
rating experiments. These experiments may be performed on different
combinations of modalities (i.e. full-body video, facial video, each with and
without speech).
Use case 2: Automatic recognition / classification of
emotions
Use case 2a: Recognition from speech
(i) (Speech emotion classifier): Anton has built an emotion classifier
from speech data which had been annotated in a way similar to use case 1b:
emotion labels were assigned on a per-word basis, and the classifier was
trained with the acoustical data corresponding to the respective word. Ten
labels had been used by the annotators, but some of them occurred only very
rarely. Based on a similarity metric, Anton merged his labels into a smaller
number of classes. In one version, the classifier distinguishes four classes;
in another version, only two classes are used. The classifier internally
associates various probabilities to class membership. The classifier can
either output only the one emotion that received the highest probability, or
all emotions with their respective probabilities. Classifier results apply in
the first step to a single word; in a second step, the results for a sentence
can be computed by averaging over the words in the sentence.
(ii) Felix has a set of Voice portal recordings, a statistical classifier,
a group of human labelers and a dialog designer. The aim is for the
classifier to give the dialog designer a detector of a negative user state
in several stages so that he/she can implement dialog strategies to deal with
the user's aggression. The training data should be annotated like in use case
1b (iii) and it should be possible to use it for for several dialog
applications (i.e. classifiers), so there must be mechanisms to map several
emotion categories and stages into each other.
(iii) Jianhua allows listeners to label the speech with multiple emotions
to form the emotion vector and then trains a classification tree model to
predict emotion vectors from acoustic features. The final emotion recognition
results are used in the dialogue system on line. The dialogue system uses the
results to determine the prior level the task from customers. Negative
emotions will result in quick service.
(iv) Juan is working on robots. The Automatic Speech Recognition module of
his robot would be able to identify the emotional state of the speaker, not
only to transcribe the uttered sentences. This emotional identification data
could be used by the kernel to adapt the behavior of the robot to the new
situation (for example, the identification of happiness traces in the voice
of visitor could make the kernel change the dialogue in order to provide more
information about the last items that could have been the cause of that happy
state). The data to transfer should be the detected emotions (or ), the
intensity levels and the confidence values associated to each detected
emotion, and the time interval.
Use case 2b: Multimodal recognition
(i) (Multimodal emotion classifier): George has built a multimodal emotion
classifier that operates on facial, gesture and speech features. His main
issue is that facial features and gesture expressivity are usually annotated
on a frame level, gestures are described with timestamps in terms of phases,
and speech features may be annotated in terms of words, tunes or arbitrary
time windows. He would like to have an indication for each feature as to
whether it can be broken down in smaller chunks and still have the same value
or, inversely, be integrated across a wider window.
(ii) Christian is interested in software ergonomics and has built a system
that tracks users' behaviour while operating software or using web pages. The
system also collects emotion information on the user by use of several
sensing technologies. The system is equipped with various sensors for both,
behaviour tracking and emotion detection, like the following.
- sensors for emotion and behaviour tracking
- emotion mouse and keyboard with integrated pressure sensors
- eye/gaze tracker
- camera for facial feature tracking
- microphone for speech analysis
- chair with pressure, tilt, and inclination sensors
- sensors for physiological parameters (skin resistance, skin
temperature, pulse, respiration)
During a test, a user sits in the chair in front of the monitor and
performs a task. Unobtrusive sensors monitor her behaviour: the mouse
movements, mouse clicks, focal points, keyboard inputs; her posture and
movements in the chair, facial feature changes, and utterances; and ongoing
changes in her physiology. Robin also observes the user using the output of
the face camera, microphone, and a screen copy of the user's monitor. He
enters event markers into the system and adds comments on the user's
performance, environmental events like distracting sounds, spontaneous
assessments of the user's current emotions, or other observations he makes.
After the test, Robin also talks with her about her experiences, her likes
and dislikes on the software, and how she felt at particular situations using
the playback feature of his analysing tool. All the information collected are
of high value for Robin, who looks at the individual values of each modality
and input device, as well as the interrelations between them, their timely
order and changes over time. Robin also includes remarks on the user's
performance during the task and the results of the questionnaire, and puts
them in timely connection with the sensor data. Other information on the
setting, the software tested, environmental information like air temperature,
humidity, or air pressure, are available as meta data on the test as well.
Information on the subject, like gender, age, or computer experience, are
stored also.
(iii) Jianhua builds a Audio-visual system. In traditional human computer
interaction, the lack of the coordination mechanism of parameters under
multi-model condition quite limits the emotion recognition. The fusing of
different channels is not just the combination of them, but to find the
mutual relations among them. Jianhua builds an emotion recognition system
which is based on audio-visual information. Both facial and audio data were
recorded, the detailed features, such as facial expression parameters, voice
quality parameters, prosody parameters, etc. were figured out. The mutual
relations between audio-visual information were also analyzed. With all above
work, the multimodal parameters were integrated into a recognition model.
(iv) Stacy works with ECAs. For the ECA's perception of other agents or
humans, there is a roughly inverse mapping process (inverse compared to
affective reasoning as in Use case 3a). That is, there are recognition
processes that map from the surface behavior of others to the behavioral
markup and then map the behavioral markup to a functional markup.
Use Case 2c: Digital Radio Presenter
Robert envisages building a "Digital Radio Presenter application", using
natural language and dialogue generation technology. The system would present
radio shows which would include introducing music, interviewing guests and
interacting with listeners calling in to the show.
- A speech recognition component would need to pass information
concerning the emotional state of interviewees or callers to the dialogue
manager.
- Both quantitative and qualitative information and timing information
(or some other means of reference) would be needed to align the emotional
characteristics to orthographic or semantic information.
Use case 2d: Induction of emotional behavior using games
Lori wants to train an audiovisual emotion classifier and needs to record
data. She would like to associate user reactions with specific events
happening to the user; so, she builds a simple computer game (e.g. a
left-to-right space shooter) where the enemies can be controlled by the
person responsible for the recordings. In this framework, sudden incidents
occur (e.g. such as enemies appearing out of nowhere) inducing positive or
negative reactions from the user.
Use case 2e: Automatic emotion identification from plain
text
Juan works an automatic person-machine interactive system (such as a
robot) that could include a Natural Language module to identify the emotional
state or attitude of the user by analyzing the sequence of words that have
been recognized by the ASR (Automatic Speech Recognition) module or that have
been written by the user in the computer interface.
As a result of this detection, if the automatic system has been insulted
(one or more times) it should get progressively more and more angry;
otherwise, when praised, the self esteem of the robot should go higher and
higher. If the machine is really emotional, the interpretation of the
emotional content can be influenced by the emotional state of the machine
(when angry, it is more probable for the system to detect negative words in
the text).
Use case 3: Generation of emotional system behavior
Use case 3a: Affective reasoner
(i) Ruth is using an affective reasoning engine in an interactive virtual
simulation for children. Taking into account the current knowledge of the
virtual situation, the affective reasoner deduces the appropriate emotional
response. To do that, the situation is first analysed in terms of a set of
abstractions from the concrete situation, capturing the emotional
significance of the situation for the agent. These abstractions are called
'emotion-eliciting conditions' or 'appraisals' depending on the model used.
These 'appraisals' can then be interpreted in terms of emotions, e.g. emotion
categories.
(ii) Ian has developed an engine that uses a core functional property of
emotional behavior, to prioritize and pay attention to important real time
events within a stream of complex events, and wishes to apply this system to
the task of prioritizing real time stock quotes and alerting users to data
they, personally, would find important, surprising and interesting. A user
would personalize the system to match their own personality (or a different
one should they so wish) so the systems behavior would roughly match the
users own were they physically monitoring the real time stream of stock data.
The system would present the user with only that information it determined to
be interesting at any point in time. The presentation of data could be from a
simple text alert to a more complex visual representation. A central server
could receive the stream of real time events, assign values to each and then
send those packaged events to each user where their own, personally
configured, system would determine the importance of that particular event to
that particular user.
(iii) The cognitive-emotional state of ECAs (cf. UC 1c) inform their behavior in a multi step process. First
the communicative intent and cognitive-emotional state of the agent is
conveyed via an XML functional markup to a behavior generation process. That
process in turn specifies a behavioral plan (surface text, gestures, etc)
using a xml-based behavioral markup.
- We have separate functional and behavioral markups (we are following
the SAIBA framework (Kopp et al. 2006)) for the multi-step process
mentioned above)
- To maximally leverage the work across all the above uses, we want to
use the same markup scheme across the uses.
- The emotional state information in the functional markup follows the
emotion theory we are modeling. The focus of our work is appraisal theory
so our markup allows not only emotional category tags (e.g., fear) and
intensity, but also the specification of causal antecedents of emotion -
appraisal variables such as desirability of the event, who is blameworthy
for the event, etc. These appraisals all have an intensity.
- There are also more persistent affective information that can be
conveyed from our model, such as trait affect and mood.
- To do the behavioral markup, we need to know additional information on
the appraisals such as who did the blameworthy act. Obviously, it has
different behavioral consequences if the cause of the emotion is the
addressee of an utterance or a third party that is not present, for
example.
- The behavior manifestations of felt emotions is distinct from
intentionally communicated emotions that are not felt. In addition there
are distinctions based on whether the emotion expression is being either
suppressed or masked. So we need our markups to support that distinction.
- Different constituents of an utterance will have different emotions
associated with them, so markups have to annotate those parts separately.
- In our model, there may be multiple emotions in play at a time.
Behaviorally, that suggests emotion blends.
- Both emotions and the physical expressions of emotions have durations
and dynamics. There is a question of the extent to which the dynamics
should be encoded in the annotations as opposed to the emotion model that
drives the annotations or the animation controllers that model the
physical motion of the expression.
Use case 3b: Drive speech synthesis, facial expression
and/or gestural behavior
(i) Marc has written a speech synthesis system that takes a set of
coordinates on the emotion dimensions arousal, valence and power and converts
them into a set of acoustic changes in the synthesized speech, realized using
diphone synthesis. If the speech synthesizer is part of a complex generation
system where an emotion is created by an affective reasoner as in use case
3a, emotions must be mapped from a representation in terms of appraisals or
categories onto a dimensional representation before they are handed to the
speech synthesizer.
(ii) Catherine has built an ECA system that can realize emotions in terms
of facial expressions and gestural behavior. It is based on emotion
categories, but the set of categories for which facial expression definitions
exist is smaller than the list of categories that are generated in use case
3a. A mapping mechanism is needed to convert the larger category set to a
smaller set of approximately adequate facial expressions. Catherine drives an
ECA from XML tags that specifies the communicative functions attached to a
given discourse of the agent. Her behavior engine instantiates the
communicative functions into behaviors and computes the animation of the
agent. The begin and end tags of each function mark the scope of the
function. We synchronize communication function and speech in this way.
Given tags describing emotions, Catherine's difficulty is to translate
them into animation commands. She is looking for specification that would
help this process. For the moment we are using a categorical representation
of emotions.
(iii) Alejandra wants to build an ontology driven architecture that allows
animating virtual humans (VH) considering a previous definition of their
individuality. This individuality is composed of morphological descriptors,
personality and emotional state. She wants to have a module that
conceptualizes the emotion of a VH. This module will serve as input to
behavioral controllers that will produce animations and will update the
motioned emotion module. The main property that has to have this definition
of emotion is to allow plugging algorithms of behavior to allow the reuse of
animations and make comparisons with different models of behavior or
animation synthesis.
(iv) Ian has developed an engine that generates facial gestures, body
gestures and actions that are consistent with a given characters age, gender
and personality. In the application of a web based visual representation of a
real person Ian would like to allow users to add those visual representations
of their friends to their blog or web site for example. In order for each
character to represent its own user it needs to update the visual
representation, this can be achieved based on received 'event' data from the
user. Using this data a locally installed emotion engine can drive a 3D
character for example to represent the emotional state of a friend. Events
would be generated remotely, for example by actions taken by the friend being
represented, these events would be sent to the users local emotion engine
which would process the events, update the model of the friends emotional
state (emotion dimensions) and then map those dimensional values to facial
gesture, body gesture parameters and actions.
(v) Christine built a system that implements Scherer's theory to animate
an agent: going from a set of appraisal dimensions the system generates the
corresponding facial expressions in their specific time. Contrarily as when
using categorical representation the facial expression of the emotion does
not appear instantaneously on the face but facial regions by facial regions
depending on the appraisal dimensions that have been activated. She raised a
number of issues that are quite interesting and that are not specified in
Scherer's theory (for example how long does an expression of a given
appraisal dimension should last).
(vi) Jianhua generated an Emotional Speech System with both voice/prosody
conversion method (from neutral speech to emotional speech) and Emotion
Markup Languages (tags). The system is integrated into his TTS system and
used for dialogue speech generation in conversational system.
(vii) Jianhua also works on expressive facial animation. He is doing a new
coding method which can give more detailed control of facial animation with
synchronized voice. The coding system was finally transferred into FAPs which
is defined in MPEG-4. The coding method allows the user to configure and
build systems for many applications by allowing flexibility in the system
configurations, by providing various levels of interactivity with
audio-visual content.
(viii) The face, arms and general movement of Juan's robot could be
affected by the emotional state of the robot (it can go from one point to
another in a way that depends on the emotional state: faster, slower,
strength, etc.). The input would be the emotional state, the item (face,
arm...), the interval (it could be a time interval - to be happy from now to
then-, or a space interval -to be happy while moving from this point to that
point, or while moving this arm, etc.)
(ix) The Text To Speech module of Juan's robotic guide in a museum should
accept input text with emotional marks (sent by the kernel or dialogue
manager to the speech synthesiser): the intended emotions (or emotion
representation values), the first and the last word for each emotion, the
degree of intensity of the intended emotional expression. The TTS module
could also communicate to the NL module to mark-up the text with emotional
marks (if no emotional mark is present and the fully-automatic mode is
active).
Use case 3c: generation of speech acts
In this example, Enrico wants to insert pre-recorded illocutionary acts
into a corpus based speech synthesis system. If appropriately used in the
unit selection mechanism, these prompts could convey an emotional intention
in the generated speech. The input text (or part of it) of the synthesis
system should be annotated specifying the emotional style as well as the
level of activation. The system will look for the pre-recorded expression in
the speech database that best fits the annotated text.
Use case 3d: generation of paralinguistic events
Enrico wants to generate synthetic speech containing para linguistics
events such as laughs, sighs, pains or phenomena like these, in order to
strengthen the expressive effect of the generated speech. These events are
pre-recorded and stored in the TTS speech database. The speech synthesis
engine should appropriately select the best speech event from the database,
given an effective annotation for it in the text that has to be synthesized.
These events could be inserted at a particular point in the sentence or could
be generated following certain criteria.
Use case 3e: Digital Radio Presenter
Robert envisages building a "Digital Radio Presenter application", using
natural language and dialogue generation technology. The system would present
radio shows which would include introducing music, interviewing guests and
interacting with listeners calling in to the show.
- The language generation component would need to pass information
regarding emotion to a speech synthesis component.
- The digital presenter would use emotion (possibly exaggerated) to
empathise with a caller.
Appendix 2: Detailed assessment of
existing markup languages
A2.1 W3C SMIL2.0 and Emotion Markup Language
According to http://www.w3.org/TR/SMIL/ SMIL has the following design goals.
Quote:
- Define an XML-based language
that allows authors to write interactive multimedia presentations. Using
SMIL, an author can describe the temporal behavior of a multimedia
presentation, associate hyper-links with media objects and describe the
layout of the presentation on a screen.Allow reusing
of SMIL syntax and semantics in other XML-based languages, in particular
those who need to represent timing and synchronization.
...
Though SMIL is clearly designed for the purpose of encoding
output-specifications, it nevertheless offers some interesting general
purpose concepts.
A2.1.1 Overall Layout: Modularization and Profiling
Cf. http://www.w3.org/TR/SMIL2/smil-modules.html
Quote:
- Modularization is an approach
in which markup functionality is specified as a set of modules that
contain semantically-related XML elements, attributes, and attribute
values. Profiling is the creation of an XML-based language through
combining these modules, in order to provide the functionality required
by a particular application.
- Profiling introduces the
ability to tailor an XML-based language to specific needs, e.g. to
optimize presentation and interaction for the client's capabilities.
Profiling also adds the ability for integrating functionality from other
markup languages, releasing the language designer from specifying that
functionality.
In the overall design of SMIL
much emphasis is put on defining it in terms of sub-modules that can be
individually selected and combined for being directly used or embedded into
other XML-languages.
This ability to be integrated
in parts or as a whole into other XML-languages is a very desirable feature.
Though the degree of
sophistication in SMIL probably is not necessary for our purpose (SMIL is
split into more than 30 modules!), the design of SMIL should nevertheless be
inspected in order to see how its modularity is achieved in technical terms
(i.e. name spaces etc.)
Cf. http://www.w3.org/TR/SMIL2/metadata.html
Metadata in SMIL refers to properties of a document (e.g., author/creator,
expiration date, a list of key words, etc.), i.e. it holds information
related to the creation process of the document.
In the Emotional Language
Requirements Meta data covers a more extended range of information types.
Nevertheless, it is worthwhile to consider the SMIL Metadata as well, both in
terms of XML syntax as well as in content.
SMIL provides two elements
for specifying meta-data.
1) <meta>
This is an empty element with
the 2 attributes: name and content.
<smil:meta name="Title" content="The Wonderful EmoDataBase"/>
<smil:meta name="Rights" content="Copyright by Mr. Hide"/> ...
The choice for values of the
attribute 'name' is unrestricted, i.e. any meta-data can be encoded BUT users
are encouraged not to invent their own tags but to use the set of names from
the "Dublin Core"-initiative.
"Dublin Core Metadata Initiative", a Simple Content Description
Model for Electronic Resources, Available at http://dublincore.org/
Dublin Core Elements: http://dublincore.org/documents/usageguide/elements.shtml
2) <metadata>
This is new since SMIL 2.0 and now allows for the specification
of metadata in RDF syntax. Its only sub-element is <rdf:RDF>, i.e. an
element that holds RDF-specifications. It is claimed that (Quote)
RDF is the appropriate
language for metadata.RDF
specifications can be freely chosen but again the usage of the (RDF-version
of) Dublin Core metadata specification is encouraged.
A2.1.3 SMIL Timing Module
Cf. http://www.w3.org/TR/SMIL/smil-timing.html
This module deals with the
specification of the synchronization of different media objects and thus
provides one of the core-functionalities of SMIL. In SMIL the synchronization
of objects is specified via (possibly) nested <seq> and <par>
tags, enclosing media-objects that are to be presented in sequential and
parallel order respectively. In addition to this sequential/parallel layout,
for each media object start- and end-times can be specified either in terms
of absolute values (e.g. start="2.5s") or in terms of events
(start="movieXY.end+3.5s).
This mechanism for temporal
layout is very attractive for all sorts of systems where multiple streams
need to be synchronized. Most specifically it has inspired the implementation
of timing modules in a number of representation languages for Embodied
Conversational Agents (ECA).
This specification definitely
is very handy for the purpose of the specification of timing in generation
systems. It is very likely to be able to fulfill demands in the requirement
regarding the Position on a time line in externally linked objects (section
4.3.2). Nevertheless it still needs to be evaluated whether this
specification that is clearly biased towards generation should be part of the
Emotion Markup Language.
A much more modest but still
attractive candidate for re-using encodings from SMIL is the syntax for
'Clock Values', i.e. for time-values:
http://www.w3.org/TR/SMIL/smil-timing.html#Timing-ClockValueSyntax
A2.2 W3C SSML 1.0 and Emotion Markup Language
According to W3C SSML Recommendation 7 September 2004 (http://www.w3.org/TR/speech-synthesis ) the goal of this markup language is to
provide a standard way to control different aspects in the generation of
synthetic speech.
Quote:
- The Voice Browser Working Group
has sought to develop standards to enable access to the Web using spoken
interaction. The Speech Synthesis Markup Language Specification is one of
these standards and is designed to provide a rich, XML-based markup
language for assisting the generation of synthetic speech in Web and
other applications. The essential role of the markup language is to
provide authors of synthesizable content a standard way to control
aspects of speech such as pronunciation, volume, pitch, rate, etc. across
different synthesis-capable platforms.
Current work on SSML is to define a version 1.1 which will
better address internationalization issues. A SSML 1.1 first working draft
was released on 10 January 2007 (http://www.w3.org/TR/speech-synthesis11 ). The publication of a second working draft is
imminent.
SSML is oriented to a
specific application that is speech synthesis, i.e. the conversion of any
kind of text into speech. Consequently, the elements and attributes of this
markup are specific to this particular domain. Only the meta, metadata and
maybe desc elements could be considered as fulfilling the requirements of the
Emotional Markup Language, while all the other elements refer to something
that is outside of the emotion topic. On the other hand SSML should interact
with "Emotion ML", speech being one of the available modalities in the
generation of emotional behavior. By means of specific processing, the
Emotional Markup annotation should be converted into an SSML document
containing the constraints regarding, for example, the prosody of the speech
that has to be synthesized.
Cf. http://www.w3.org/TR/speech-synthesis/#S3.1.5
The meta and metadata elements are used as containers for any
information related to the document. The metadata tag allows the use of a
metadata scheme and thus provides a more general and powerful mechanism to
treat these typology of data. The meta element requires one of the two
attributes "name" (to declare a meta property) or "http-equiv". A content
attribute is always required. The only predefined property name is seeAlso
and it can be used to specify a resource containing additional information
about the content of the document. This property is modelled on the seeAlso
property in Section 5.4.1 of Resource Description Framework (RDF) Schema
Specification 1.0 RDF-SCHEMA .
<speak version="1.0" ...xml:lang="en-US">
<meta name="seeAlso" content="http://example.com/my-ssml-metadata.xml"/>
<meta http-equiv="Cache-Control" content="no-cache"/>
</speak>
The metadata element exploits a metadata schema to add
information about the document. Any metadata schema is allowed but it is
recommended to use the XML syntax of the Resource Description Framework (RDF)
RDF-XMLSYNTAX in conjunction with the general metadata properties defined in
the Dublin Core Metadata Initiative DC .
Quote:
- The Resource Description Format
[RDF] is a declarative language and provides a standard way for using XML
to represent metadata in the form of statements about properties and
relationships of items on the Web. Content creators should refer to W3C
metadata Recommendations RDF-XMLSYNTAX and RDF-SCHEMA when deciding which metadata RDF schema to use in their
documents. Content creators should also refer to the Dublin Core Metadata
Initiative DC , which is a set of generally applicable
core metadata properties (e.g., Title, Creator, Subject, Description,
Rights, etc.).
<speak version="1.0" ... xml:lang="en-US">
<metadata>
<rdf:RDF
xmlns:rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs = "http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc = "http://purl.org/dc/elements/1.1/">
<!-- Metadata about the synthesis document -->
<rdf:Description rdf:about="http://www.example.com/meta.ssml"
dc:Title="Hamlet-like Soliloquy"
dc:Description="Aldine's Soliloquy in the style of Hamlet"
dc:Publisher="W3C"
dc:Language="en-US"
dc:Date="2002-11-29"
dc:Rights="Copyright 2002 Aldine Turnbet"
dc:Format="application/ssml+xml" >
<dc:Creator>
<rdf:Seq ID="CreatorsAlphabeticalBySurname">
<rdf:li>William Shakespeare</rdf:li>
<rdf:li>Aldine Turnbet</rdf:li>
</rdf:Seq>
</dc:Creator>
</rdf:Description>
</rdf:RDF>
</metadata>
</speak>
Emotion ML might use a
similar mechanism to address the metadata information related to the
emotions.
A2.2.2 SSML desc element
Cf. http://www.w3.org/TR/speech-synthesis/#S3.3.3
The SSML desc element is used
in conjunction with the audio element to add a description about the event
itself. It is particularly useful when there is the need to textually explain
paralinguistic information related to the audio. A mechanism like this could
be generalized and used also in the emotion markup language to add
descriptions to any generated event.
<speak version="1.0" ...xml:lang="en-US">
<voice xml:lang="de-DE">
<audio src="ichbineinberliner.wav">Ich bin ein Berliner.
<desc xml:lang="en-US">Kennedy's famous German language gaffe</desc>
</audio>
</voice>
</speak>
A2.3 W3C EMMA and Emotion Markup Language
According to W3C EMMA working draft 9 April 2007 (http://www.w3.org/TR/emma/ ) this markup language is oriented to the interpretation of user
input of a multimodal system.
Quote:
- The W3C Multimodal Interaction
working group aims to develop specifications to enable access to the Web
using multimodal interaction. This document [...] provides details of an
XML markup language for containing and annotating the interpretation of
user input. Examples of interpretation of user input are a transcription
into words of a raw signal, for instance derived from speech, pen or
keystroke input, a set of attribute/value pairs describing their meaning,
or a set of attribute/value pairs describing a gesture. The
interpretation of the user's input is expected to be generated by signal
interpretation processes, such as speech and ink recognition, semantic
interpreters, and other types of processors for use by components that
act on the user's inputs such as interaction managers.
As EMMA is an annotation
scheme oriented to recognition applications, some of its elements and
concepts could fulfill in particular the Use case 2 requirements of the
emotional language markup. In the following paragraphs, only those EMMA
specific elements that could be extended to the emotion markup are
considered.
The main EMMA element is
<emma:interpretation> . It comprises different attributes and values
and holds a single interpretation represented in application specific markup.
Each interpretation element is univocally identified by means of the "id"
attribute (of type xsd:ID).
A2.3.1 EMMA Container elements
Cf. http://www.w3.org/TR/emma/#s3.3
These elements are used to manage the
interpretations and to group them according to different criteria.
EMMA considers three types of container elements:
emma:one-of emma:group emma:sequence
The first one is used to
indicate a set of mutually exclusive interpretations of the input and maybe
it could be used in the emotion markup in Use case 2. The second container
element is intended for multiple interpretations provided by distinct inputs
(speech, gesture, etc.) but that are used for a common task. The last element
is used for interpretations that are sequential in time. In the emotion
markup these containers could be also used to manage interpretations. The
one-of mechanism is useful when more results are available and a choice among
them has to be carried out. The group concept could be generalized and used,
for example, to treat multiple or complex emotions. The last container is
also useful to describe the evolution of an emotional phenomenon.
Beyond these elements EMMA
reports also the <emma:lattice> container, that is tightly linked to
speech recognition applications. More interesting is the <emma:literal>
element that is a child element of the interpretation and is used when the
semantic results of the EMMA component are string literals without any
surrounding application namespace markup. It could be useful also in the
emotion markup to describe something not included in the application
namespace.
<emma:interpretation>
<emma:literal>boston</emma:literal>
</emma:interpretation>
A2.3.2 EMMA Annotation elements
Cf. http://www.w3.org/TR/emma/#s4.1
EMMA model element
The <emma:model> is an
annotation element used to express constraints on the structure and content
of instance data and is specified as one of the annotations of the instance.
It is identified by means of an "id" attribute, while a "ref" attribute is
used to reference the data model. Within a single EMMA document, it is
possible to refer to multiple data models. Since the emotion markup will
consider different and also alternative representations to describe emotions,
an element like the "model" could be used to manage different constraints to
represent data. Models could also be used to manage domain specific sets of
emotion categories or types.
<emma:model id="model1" ref="http://myserver/models/city.xml"/>
<emma:interpretation id="int1" emma:model-ref="model1">
<city> London </city>
<country> UK </country>
</emma:interpretation>
</emma:model>
EMMA info element
The <emma:info> element
acts as a container for vendor and/or application specific metadata regarding
a user's input. In the emotion markup a tag like this could be a location for
metadata. It could be used to add information about the subject and the
object of the analyzed phenomenon/event. Moreover this tag can include
markups that are not specific to EMMA, but something extensible and adaptable
to specific requirements.
<emma:info>
<caller_id>
<phone_number>2121234567</phone_number>
<state>NY</state>
</caller_id>
<customer_type>residential</customer_type>
<service_name>acme_travel_service</service_name>
</emma:info>
A2.3.3 EMMA Annotation attributes
Cf. http://www.w3.org/TR/emma/#s4.2
EMMA process attribute
The <emma:process>
attribute refers to the process that generates the interpretation. This
annotation may include information on the process itself, such as grammar,
type of parser, etc. There is no normative regarding the description of the
process. This is something linked to the "rest of the world" in the emotion
requirements and could be useful to indicate which process has produced the
result that has to be interpreted, or also which process has to be used to
generate the output, if we extend this concept to use case 3.
<emma:interpretation id="better" emma:process="http://example.com/mysemproc1.xml">
<origin>Boston</origin>
<destination>Denver</destination>
<date>tomorrow</date>
</emma:interpretation>
EMMA signal and media-type attributes
The <emma:signal>
attribute is a URI reference to the signal that originated the input
recognition process while the <emma:media-type> attribute specifies the
data format of the signal that originated the input. Also these attributes
are links to the "rest of the world" and could be used to annotate, for
example, audio and/or video sources.
<emma:interpretation id="intp1" emma:signal="http://example.com/signals/sg23.bin">
<origin>Boston</origin>
<destination>Denver</destination>
<date>03152003</date>
</emma:interpretation>
<emma:interpretation id="intp1" emma:media-type="audio/dsr-202212; rate:8000; maxptime:40">
<origin>Boston</origin>
<destination>Denver</destination>
<date>03152003</date>
</emma:interpretation>
EMMA confidence attribute
The emma:confidence attribute
is a score in the range from 0.0 (minimum) to 1.0 (maximum) included, that
indicates the quality of the input. It may state for the confidence of
whatever processor was responsible for the creation of the EMMA result and it
can also be used to assign confidences to elements in instance data in the
application namespace. In the emotion language requirements this attribute is
considered with the same meaning as in EMMA, and it could be used at
different levels of representation and therefore could be applied to
different elements.
<emma:interpretation id="meaning1" emma:confidence="0.6">
<destination emma:confidence="0.8"> Boston</destination>
<origin emma:confidence="0.6"> Austin </origin>
</emma:interpretation>
EMMA cost attribute
The emma:cost attribute is
used to indicate the weight or cost associated with a user's input or part of
it. It is conceptually related to the output of a recognition process when
there are more interpretations. Values span from 0.0 to 10000000.
<emma:interpretation id="meaning1" emma:cost="1600">
<location>Boston</location>
</emma:interpretation>
<emma:interpretation id="meaning2" emma:cost="400">
<location> Austin </location>
</emma:interpretation>
A2.3.4 Timestamps in EMMA
In Emma time references are
indicated by using either relative or absolute timestamps. The time unit is
the millisecond and absolute timestamps are the time in milliseconds since 1
January 1970 00:00:00 GMT. Absolute timestamps are indicated using the
<emma:start> and <emma:end> tags. Regarding relative timestamps,
EMMA defines the attribute <emma:time-ref-uri> that is a URI used to
anchor the relative time and can be also an interval. The
<emma:offset-to-start> attribute specifies the offset in milliseconds
for the start of input from the anchor point. It is also possible to indicate
timestamps relative to the end of the reference interval by setting the "end"
value in the <emma:time-ref-anchor-point> attribute. Finally, the
<emma:duration> attribute can be used to annotate the input duration
and can be used independently of absolute or relative timestamps. In EMMA it
is possible to have both absolute and relative timestamps in the same
container.
<emma:interpretation id="int2"
emma:time-ref-uri="#int1"
emma:time-ref-anchor-point="start"
emma:offset-to-start="5000">
<destination>Chicago</destination>
</emma:interpretation>
A2.3.4 Modality in EMMA
Modality is a key concept in
the emotion language. For annotating the input modality EMMA considers two
attributes <emma:medium> and <emma:mode>. The first one is a sort
of broad classification. Its values are acoustic, tactile, visual. The second
attribute specifies the mode of communication through the channel (values:
speech, dtmf_keypad, ink, video, photograph, ...). It is also possible to
classify inputs with respect to their communicative function by using the
<emma:function> attribute whose values are, for example : recording,
transcription, dialog, verification, ...
<emma:one-of id="nbest1">
<emma:interpretation id="interp1"
emma:confidence="0.6"
emma:medium="tactile"
emma:mode="ink"
emma:function="dialog"
emma:verbal="true">
<location>Boston</location>
</emma:interpretation>
<emma:interpretation id="interp2"
emma:confidence="0.4"
emma:medium="tactile"
emma:mode="ink"
emma:function="dialog"
emma:verbal="false">
<direction>45</direction>
</emma:interpretation>
</emma:one-of>
A2.4 W3C PLS and Emotion Markup Language
According to W3C PLS (Pronunciation Lexicon Specification)
second last call working draft 26 October 2006 (http://www.w3.org/TR/pronunciation-lexicon/ ), PLS is designed to enable interoperable
specification of pronunciation information for both ASR and TTS engines
within voice browsing applications.
The "role" attribute of the
lexeme element (see Section 4.4) is the only reviewed aspect of the PLS
language.
A2.4.1 The role attribute
The values of the role attribute are based on QNAMES defined in
Section 3.2.1.8 of XML Schema Part2: Datatypes Second Edition XML-SCHEMA . A
QNAME or "qualified name" is composed of two parts separated by colon, where
the first part is the qualification (a namespace prefix) and the second is a
value defined in the namespace, e.g. "claws:VVI" for the value "VVI" in the
namespace associated to the prefix "claws". The namespace guarantees that the
values are unique and that they are extensible, if the namespace is changed,
a different set of values is possible.
The QNAMES might be used to
represent categorization that cannot be easily defined. In PLS the example
were the Part-Of-Speech (POS), which are used in differnt ways in the NL and
ASR communities.
This is an example of the use
of the role attribute in PLS:
<?xml version="1.0" encoding="UTF-8"?>
<lexicon version="1.0"
xmlns="http://www.w3.org/2005/01/pronunciation-lexicon"
xmlns:claws="http://www.example.com/claws7tags"
alphabet="ipa"
xml:lang="en">
<lexeme role="claws:VVI claws:VV0 claws:NN1">
<!-- verb infinitive, verb present tense, singular noun -->
<grapheme>read</grapheme>
<phoneme>ri:d</phoneme>
<!-- IPA string is: "riːd" -->
</lexeme>
<lexeme role="claws:VVN claws:VVD">
<!-- verb past participle, verb past tense -->
<grapheme>read</grapheme>
<phoneme>red</phoneme>
</lexeme>
</lexicon>
A2.5 W3C InkML and Emotion Markup Language
This mark up language (http://www.w3.org/TR/2006/WD-InkML-20061023/ ) is quite far removed from the work of this
group, being a specification for passing around information captured from pen
like input devices.
Quote:
- This document describes the
syntax and semantics for the Ink Markup Language for use in the W3C
Multimodal Interaction Framework as proposed by the W3C Multimodal
Interaction Activity. The Ink Markup Language serves as the data format
for representing ink entered with an electronic pen or stylus. The markup
allows for the input and processing of handwriting, gestures, sketches,
music and other notational languages in applications. It provides a
common format for the exchange of ink data between components such as
handwriting and gesture recognizers, signature verifiers, and other
ink-aware modules.
It does share some of the
high level concepts that we would like to have within the EmoXG group
specification, namely:
- Capture (or input) of data
- Events and streams of real time events
- Output processing
It also has an emphasis on
interoperability with other XML specifications, for example SMIL to allow for
multi modal exchange of data.
The specifics of the markup language are bound to pen devices,
which is not directly relevant for the Emotion markup language. Perhaps of
interest is the way in which this is an example of a multi modal
specification (http://www.w3.org/TR/mmi-reqs/ ).
Of further interest is in how their specification is put
together, it seems similar in size and scope to what we would want to achieve
and could be an interesting template. Their requirements document could also
be a useful template (http://www.w3.org/TR/inkreqs/ ).
A2.5.1 Multi Modal Interaction
Of more interest is the Multi
Modal Interaction guidelines (http://www.w3.org/TR/mmi-reqs/ )
which it seems we would be wise to follow if possible, an excerpt from the
requirements document is relevant:
"We are interested in defining the requirements for the design
of multi modal systems -- systems that support a user communicating with an
application by using different modalities such as voice (in a human
language), gesture, handwriting, typing, audio-visual speech, etc. The user
may be considered to be operating in a delivery context: a term used to
specify the set of attributes that characterizes the capabilities of the
access mechanism in terms of device profile, user profile (e.g. identify,
preferences and usage patterns) and situation. The user interacts with the
application in the context of a session, using one or more modalities (which
may be realized through one or more devices). Within a session, the user may
suspend and resume interaction with the application within the same modality
or switch modalities. A session is associated with a context, which records
the interactions with the user."
Some of the key components of
this specification are:
- Input (modality, processing system)
- Events (handlers, sources, time stamps)
- Output (modality, processing systems)
- User profiles (identify, preferences and usage patterns)
- Sessions (suspend, resume, context)
- Situation (interaction history)
- Interaction (management, synchronization)
A2.6 HUMAINE EARL and Emotion Markup Language
According to HUMAINE EARL language (Emotion Annotation and
Representation Language) version 0.4.0, 30 June 2006 (http://emotion-research.net/earl ) this markup language is oriented to the
representation and annotation of emotion in the use cases corpus annotation,
recognition and generation of emotions in the first place.
Quote:
- This report proposes a syntax
for an XML-based language for representing and annotating emotions in
technological contexts. In contrast to existing markup languages, where
emotion is often represented in an ad-hoc way as part of a specific
language, we propose a language aiming to be usable in a wide range of
use cases, including corpus annotation as well as systems capable of
recognising or generating emotions. We describe the scientific basis of
our choice of emotion representations and the use case analysis through
which we have determined the required expressive power of the language.
We illustrate core properties of the proposed language using examples
from various use case scenarios.
This said, EARL is by definition highly
related to the envisaged use cases and specification and provides many
solutions to the named requirements. As general evaluation, EARL provides
several highly valuable mechanisms and sets of items for the given
requirements. The proposed ability of "plug-ins" seems a must, as well. The
main drawback of EARL to be overcome is its lack of mechanisms for the
description of Global Metadata and Classification Schemes for Emotions /
Ontologies, as named in the EmoXG requirements. Some minor lacks are: no
provision of emotion-related phenomenon, no real acting reference, sparse/no
position on a time line and semantic links to the "rest of the world".
The next sections report a detailed evaluation by requirements with
examples.
A2.6.1 Emotion Core
A2.6.1.1 Type
of emotion-related phenomenon
EARL does not allow for a
specification of the emotion-related phenomenon as emotions, moods,
interpersonal stances, etc.
A2.6.1.2
Emotion categories
EARL allows for "plug-ins" or
dialects and provides presets for emotion categories that are valuable for
re-consideration.
<emotion category="pleasure">Hello!</emotion>
A set of 48 default
categories is provided following Cowie et al.
A2.6.1.3
Emotion dimensions
These are provided within
EARL. Suggested dimensions are arousal, power, valence.
<emotion xlink:href="face12.jpg" arousal="-0.2" valence="0.5" power="0.2"/>
A2.6.1.4
Description of appraisals of the emotion or of events related to the
emotion
These are also provided
within EARL. 19 appraisals are suggested following Scherer's works.
<emotion xlink:href="face12.jpg" suddenness="-0.8" intrinsic_pleasantness="0.7" goal_conduciveness="0.3" relevance_self_concerns="0.7"/>
A2.6.1.5 Action tendencies
This is not covered by the EARL draft specification.
A2.6.1.6Multiple
and/or complex emotions
It is possible to attach
several tags to one event.
<complex-emotion xlink:href="face12.jpg">
<emotion category="pleasure" probability="0.5"/>
<emotion category="friendliness" probability="0.5"/>
</complex-emotion>
A2.6.1.7
Emotion intensity
It is possible to associate
intensities for emotions.
<complex-emotion xlink:href="face12.jpg">
<emotion category="pleasure" intensity="0.7"/>
<emotion category="worry" intensity="0.5"/>
</complex-emotion>
A2.6.1.8
Regulation
Descriptors for regulation
are also found in EARL.
<complex-emotion xlink:href="face12.jpg">
<emotion category="pleasure" simulate="0.8"/>
<emotion category="annoyance" suppress="0.5"/>
</complex-emotion>
A2.6.1.9
Temporal aspects
Start/end time labels for
emotions are as well included as a mechanism for continuous description of
emotion changes in the FEELTRACE manner.
<emotion start="2" end="2.7">
<samples value="arousal" rate="10">
0 .1 .25 .4 .55 .6 .65 .66
</samples>
<samples value="valence" rate="10">
0 -.1 -.2 -.25 -.3 -.4 -.4 -.45
</samples>
</emotion>
A2.6.2.1
Acting
No general mechanism exists
with respect to acting apart from the regulation descriptors.
A2.6.2.2
Confidence / probability
A probability tag is foreseen
in EARL. In general, it is also possible to assign this probability to any
level of representation.
<emotion xlink:href="face12.jpg" category="pleasure" modality="face" probability="0.5"/>
A2.6.2.3
Modality
A modality tag exists in EARL
and allows for assignment of emotion labels per modality.
<complex-emotion xlink:href="clip23.avi">
<emotion category="pleasure" modality="face"/>
<emotion category="worry" modality="voice"/>
</complex-emotion>
A2.6.3 Links
to the "rest of the world"
A general hyperref link
mechanism allows for links to media. However, this is not intended to connect
further media with objects, in the first place.
<complex-emotion xlink:href="face12.jpg">
...
</complex-emotion>
A2.6.3.2
Position on a time line
Apart from the possibility to
assign emotion labels in start/end time and continuous manner, no links e.g.
for recognition results in absolute and relative manner are provided.
A2.6.3.3 The semantics of links to the "rest of the
world"
Links to e.g. the
experiencer, trigger of emotion, target of emotion, etc. are not included in
EARL.
Mechanisms for the provision
of none of the following is provided in EARL:
- Info on Person(s)
- Purpose of classification
- Technical Environment
- Social & Communicative Environment
A2.6.5
Classification Schemes for Emotions / Ontologies
As for global meta-data
description, EARL is lacking the possibility to construct a hierarchy of
emotion words. Mapping mechanisms are also not provided.
A2.7 VHML and Emotion Markup Language
The Virtual Human Markup Language
(VHML) was created within the European Union 5th Framework Research and
Technology Project InterFace . It is described in http://www.vhml.org/ . VHML is a markup language intended to be used
for controlling VHs regarding speech, facial animation, facial gestures and
body animation. It is important to notice that VHML has a simple
representation of Emotion, however, it can be an example of the requirements
formulated in Use case 3.
Quote:
- The language (VHML) is designed
to accommodate the various aspects of human computer interaction with
regards to facial animation, text to speech production, body animation,
dialogue manager interaction, emotional representation plus hyper and
multi media information. It uses existing standards and describes new
languages to accommodate functionality that is not catered for. The
language is XML/XSL based, and consists of the following sub
languages:
- EML Emotion Markup Language
- GML Gesture Markup Language
- SML Speech Markup Language
(based on SSML)
- FAML Facial Animation Markup Language
- BAML Body Animation Markup Language
- XHTML
eXtensibleHyperText Markup Language
- DMML Dialogue Manager
Markup Language (based on W3C Dialogue Manager or
AIML)
The next sections report a detailed evaluation by requirements with
examples.
A2.7.1.
Emotion Core
A2.7.1.1
Type of emotion-related phenomenon
As VHML is for HCI using
Virtual Humans, its representations can be considered as Affect dispositions.
A2.7.1.2
Emotion categories
Within EML used by VHML the
categories of emotions used are: afraid, angry, confused, dazed, disgusted,
happy, neutral, sad, surprised, default-emotion.
A2.7.1.3
Emotion dimensions
This aspect is not specified by VHML.
A2.7.1.4
Description of appraisals of the emotion or of events related to the emotion
This aspect is not specified by VHML.
A2.7.1.5 Action tendencies
This aspect is not specified by VHML.
A2.7.1.6
Multiple and/or complex emotions
This aspect is not specified by VHML.
A2.7.1.7
Emotion intensity
Intensity can be based on numeric values (0-100), or low-medium-high
categories.
<afraid intensity="50"> Do I have to go to the dentist? </afraid>
A2.7.1.8
Regulation
Within the Gesture Markup
Language (GML) of VHML, there is the definition of an emphasis element.
Depending on the modality, speech or face, the element is synthesized.
<emphasis level="strong"> will not </emphasis> buy this record, it is scratched.
A2.7.1.9
Temporal aspects
VHML specifies two temporal attributes for an emotion: 1. Duration, in
seconds or milliseconds that the emotion will persist in the Virtual Human.
2. Wait, represents a pause in seconds or milliseconds before continuing with
other elements or plain text in the rest of the document.
<happy duration="7s" wait="2000ms"/> It's my birthday today.
A2.7.2.1
Acting
This aspect is not specified by VHML.
A2.7.2.2
Confidence / probability
This aspect is not specified by VHML.
A2.7.2.3
Modality
Modalities that can be
established by referring to other ML: GML a gesture, FAML a facial animation,
SML a spoken and BAML body animation.
<happy>
I think that this is a great day.
<smile duration="2s" wait="1s"/>
<look-up>
Look at the sky. There is <emphasislevel="strong">not a single </emphasis> cloud.
</look-up>
<agree duration="3500ms" repeat="4"/>
The weather is perfect for a day at the beach.
</happy>
A2.7.3 Links
to the "rest of the world"
EML allows having elements of
the other markup languages to specify the modality.
A2.7.3.2.
Position on a time line
This aspect is not specified by VHML.
A2.7.3.3. The semantics of links to the "rest of the world"
This aspect is not specified by VHML.
A2.7.4.1
Info on Person(s)
VHML specifies the speaker of
the text, regarding gender, age and category as well as with which emotion it
is supposed to speak and act in general.
The person element contains
the following attributes: age category (child, teenager, adult, elder),
gender, name (specifies a platform specific voice name to speak the contained
text), variant (specifies a preferred variant of another person to speak the
contained text), disposition (specifies the emotion that should be used as
default emotion for the contained text - the name of any of the EML
elements).
<person age="12" gender="male" disposition="sad" variant="fred:1">
...
</person>
<person variant="fred:2">
...
</person>
None of the following
information can be explicitly indicated in VHML:
- Purpose of classification
- Technical Environment
- Social & Communicative Environment
A2.7.5
Classification Schemes for Emotions / Ontologies
VHML is lacking the
possibility to construct a hierarchy of emotion words and provide mapping
mechanisms.