See also: day 1 IRC log, day 2 IRC log
Day 1
Day 2
<danbri> Re Restaurant, I think it is here, but jjc will confirm: http://www.conradatjamesons.co.uk/location/index_location.htm
<libby> yep that's the one
propose to swap RDF-in-HTML and ADTF slots, so Bristol folk can move to the teleconf room
RDF-in-HTML will be discussed at 1530 UTC, ADTF will be discussed at 1330 UTC,
tomorrow afternoon discussion on breadth of work and ways to bring in other participants
<RalphS> [ PORT (aka Thesaurus) TF description is http://www.w3.org/2004/03/thes-tf/mission ]
al: brief intro to skos core spec
... SKOS Core is an
RDF vocabulary for thesaurii
... vocabulary is managed like FOAF; each property in the vocabulary has its
own level of stability
... classes and properties summarised in a table, with their properties
... and a brief mention of the management policy for skos core
... and a brief note re community involvement
... list of vocab details
... that bit of document generated from the schema itself, hence table
created from script
... navigation at side of document
ralph: stepping back briefly...
... feeling a bit out of sync with this task force
... how does this vocab serve as being the most important answer right now to
get thesauri ported to the semweb
... what's the feedback you've got that makes you confident in this as a
solution
al: coming from the other point
of view, within dig library community, for thesauri alone there is currently
no dominant interchange format
... so v little reuse of tools etc within that community
jjc: how much is skos yet another format that won't be a standard
al: will answer that one later
... skos is part of a family of similar systems, thesauri, subject heading
schemes, glossaries, which have all been developed with walls in between them
... they all share a lot of common features
... another thing in the thesaurus community is that moving beyond print
environment is still a new thing
guus: do you have indication how
many of the vocabs out there have such a structure that can be usefully
mapped to skos
... eg mesh not something that you can...
al: i'd say 98%
DanBri: work that is written-up
here [SKOS] has a heritage back to other work, including a write-up I did for
the W3C Query Workshop in 1998
... vocabulary as written is good
... some commentors suggest it could be more term-centric
... this is low-hanging fruit
... could relate to future Topic Map discussions
al: i've presented this at a few
digital library workshops
... the single feature that i've picked up on that people have liked...
... use of rdf means people can add new features, and extensible, you can
specialise classes and properties
... v attractive as people want to refine thesauri standards to be more
precise
phil: i'm kinda concerned that this might be a closed community
ralph: why are Wordnet and MESH hard examples for SKOS?
guus: wordnet isn't a
conventional thesaurus in the ISO sense
... nor mesh
... but in the library world, ppl have been making thesauri for ages
ralph: can we target a specific thesaurus?
al: sure. we already have
gemmet(?) who use a prev version of skos
... also uk govt categories
... in swad-e we did a cycle of review/test/etc
ralph: i didn't realise it had been used, wasn't clear from the docs
al: is linked from the swad-e pages
<libby> http://www.w3.org/2001/sw/Europe/reports/thes/
<libby> usecases: http://www.w3.org/2001/sw/Europe/reports/thes/usecase.html
DanBri: the Digital Library
community likes this because RDF allows them to use many representation types
and specialize
... worries me because of a view toward "facet modelling"
... I think they don't realize what can be done with OWL
... in the RDF & OWL world we can say "subClassOf"
... in the thesaurus world they are accustomed to want to say 'broader' and
'narrower'
Al:SKOS attempts to not replicate things that are already in OWL
DanBri: 'denotes' relationship
bridges models
... http://www.w3.org/2001/sw/Europe/reports/thes/8.8/
... subtle distinction between modelling in RDF and OWL over modelling
thesaurii -- will be important for us to explain this
al: of whole skos core vocab, the broader property is the most important one in there
david: al, you said the thesaurus
community only recently thinking beyond print... can you expand?
... what are the changes?
al: single biggest impact of
that, working in the print community, you have a thesaurus which is a book,
terms, record cards...
... you fill terms from thesaurus into record card
... so term-centric
... as people working with this
... a problem with that, 'cos in a thesaurus you have two kinds of term,
preferred descriptors and non-preferred terms
... a descriptor is a main label for a concept
... ...so confounding of term as unique id vs usage in natural language
david: i'm with you ... but ... so what?
al: althought a thesaurus is supposed to be concept oriented, in practice it is term oriented
<Benjamin> WN draft might be : http://www.w3.org/2001/sw/BestPractices/WNET/wordnet-sw-20040713.html
guus: all these communities have
built vocabs, they're v domain specific, terms represent agreements within a
community
... if people commit to this particular terminology
al: as we move into networked world
Guus: even within a community there will be conflicts and disagreements in usage
al: where two vocabs collide in networked world, this is a new problem/issue to pre-electronic version
<Guus> sure!
david: can you make that explicit in the document
ACTION: Alistair make explicit in skos core doc the fact that you're trying to deal with potential for multiple thesauri using the same terms, overlap etc., different from paper publishing world
Steve: this is an area in which Published Subjects might be helpful
guus: not sure ... that this is
specifically work for this tf
... happy to see port tf to propose a skos-based convention for represnting
real-life thesauri in rdf/xml
... could be very short
... my main problem is ?size of doc / quickstart / primer
DanBri: note comment from Brad @ Siderean
phil: you're looking at having
multiple independent domain specific thesauri, but not at detailed cross
domain mappings
... are we looking at the problem of translating across domains; e.g. medical
to something else?
Al: that's part of SKOS Mapping
DanBri: faceted browser for
Dublin Core was built using a term-centric approach
... the developer said the term-centric approach was easier to deal with,
though less elegant
ralph: this discusssion positions
what you've done better for me, in space of problem we're trying to solve.
... is particularly important to emphasise the point that guus just made,
perhaps in skos core guide, that the motivation be given right up front...
... with examples
... there's a risk that community rivalry might project from perceived
qualities of a thesaurus to skos itself
... so show several!
... so skos would be more persausive if described this way
... so important distinction, between basic thesaurus representation versus
fancy stuff on mapping
... get basics out asap, showing some use for thesaurus world without getting
bogged down in mapping
phil: suggesting that words on these constraints needed in the doc?
ralph: not sure we need to write
it that explicitly, just make sure we work through real use case examples
... by implication this shows our priorities
jjc: felt to me that al's later examples could have been more prominent
guus: i was visiting sound and
vision institute
... tv and radio archive of the netherlands
... dutch
... simple textual file, i just want to have a document to give them, to
translate that
... simple use cases are there
... another one, dutch royal library, GOO (general object something)
... v simple, uses 3 or 4 things from skos
... term, broader term, related, ...
... give them something to allow their developers something to build an rdf
representation
ralph: so speed is important?
al: totally agree; with skos-core guide, as short and simple as possible, ...
<danbri> [libraries-> web not sw; blogs, instances]
al: suggestions welcomed
DanBri: several things going on
here; lots of historical context for wanting to help migrate things to
Semantic Web
... librarians want to see their role in Sem Web
... many cheaper and scruffier examples being generated
... SKOS is interesting because it is right in the middle
... it fits with the light-weight data sharing things like FOAF but it also
fits into the library world
... I'd like to see 2 classes of examples; a dump syntax for thesaurii and
syntaxes that mix into the rest of the RDF world
... with the move from print to electronic, what's changed in the library
world is how they operate
... there now are blog operators that create thousands of categories that
point to a page
... hierarchical categories in SKOS have been shown to work nicely
... can now show to the library world that their work on thesaurii can show
up in this new blog category world
phil: a point about pragmatics
... a solution space for semantic tech for library world
... as they're potentially an early adopter, could be some pain there
... is it within our remit to help with take up
... ? there's some responsibility within this team to act as a reference
point, or respond to, frustrations from early adopters
... is that a wg responsibility?
david: this is our constant
problem. charter is v broad. i wouldn't say that it is the wrong thing to do.
potentially too hard for the group as it currently stands.
... we could do less of something else we're doing, or else find someone out
there to help with this
phil: from my standpoint in industry, when you're trying to become an early adopter of this technology, BP seems to be an ideal home for channeled frustrations
jjc: i disagree
david: a pain registry would be
good in theory...
... but because i'm sensitive to what this group is being asked to do
DanBri: the people who
participate in WGs are not generic reassignable resources; they have some
role in their host organization
... for example, those of us funded by EU are here to create supporting
materials
... when this goes out to WD, the WG has the responsiblity to respond to
public comment
ralph: SWBPD wg charter is, for
better/worse, v broad
... i view the intent of the charter of this wg to help the real world use
the sw tech
... migrate to it, etc
... we can't afford to take on every user community whose pain we feel
... but we should be confident that everything we work on addresses some
genuine user community problem
... what i've been pushing here is for the materials that we deliver to show
the real world problem that is being addressed
... depending on the prob, we may or may not be able to demonstrate we solved
it all
... so be clear about what probs we want to be seen as solving
... agree w/ phil that some of that is needed, but also +1 david's point re
resource limitations
david: ralph likes to (rightfully
I think!) pick up the concept of use cases... If a discussion comes up, Ralph
will remind us to define a use case, also in document review. This is a
really good idea. When we talk about what use cases we're going to do, the
same short list comes up; It's always FOAF and DOAP. We have a short list of
a common candidates for use cases
<DanBri>: [DOAP vs DOPE]
drug ontology thing
<libby> DOPE: http://www.informatik.uni-bremen.de/swc/dope.html
david: if we use same list across
all our note candidates...
... eg. we could look back and say, 'we did xyz to bring foaf into mainstream
fold, ...
... so we should probably come up with list of these use cases
jjc: back to phil's earlier
point... i think it is important that we don't do support of individual users
... ralph talked about communities not individuals
... we do latter on jena-dev list
phil: I agree
David: I see indivs supported in IG; communities supported by WG
steve: re topicmaps angle... this
skos looks like a v interesting project
... collab, make sure whatever we do in the rdf/tm tf is consistent
al: thanks, agree; Kal Ahmed,
...[missed names] have been active w/ skos
... re Published Subject Indicator, currently discussing whether to have a
PSI property in SKOS
... re spec document, people seem ok with that, concerns have been with the
guide document
... guide is at an early stage, built from our wiki content
... feasible to publish for end of november
guus: more discussion tommorrow?
al: might be useful to run new
features of skos core past the WG
... because of the subject indicator discussion
guus: so i hear two issues; 1st
is potential examples, 2nd is to talk about topic maps [& denotes
property]
... ie. open issues within task force; alongside discussion of rel'n to
topicmaps tf
ralph: david commented about
standard use casees
... guus has emphasised that there are use cases; please lets pick some.
... concern i have with foaf is that it is simple and intuitive
... but foaf is already developed, and rdf friendly
guus: foaf is a description template, not a vocab
ralph: not clear useful to list
foaf as a skos use case
... anything we do, there's some community out there, who we should know
about and whoese needs we should address
al: I could've written this by showing classic print thesauri followed by skos version; could do that, but foaf developer folks wouldn't follow. There are different communities who need different kinds of example.
guus: who is main community? digital library?
al: point is that this is skos
core guide... is that the right title for the right document?
... another point is a primer specifically for using skos w/ thesauri
<RalphS> "Expressing Your Thesaurus in the Semantic Web"
guus: how about not having skos in title
Steve: not just thesaurii; also controlled vocabularies, subject headings
(various proposals uncaptured; discussion of whether just thesauri ...)
all: great work alistair!
<DanBri>: RalphS, I believe the intro to http://www.w3.org/2001/sw/BestPractices/WNET/wordnet-sw-20040713.html explains how SKOS, Wordnet, and RDF/OWL fit together. Would be great if you could review that bit of the doc in particular.
Guus: history: history wordnet in
rdf several times - but none endorsed by princeton
... phase one - wordnet datastructures in RDF/OWL - no changes, make it so
that everytime wornet is updated, get an rdf/owl version too
... Brian has been working on a draft: http://www.w3.org/2001/sw/BestPractices/WNET/wordnet-sw-20040713.html
... details to be worked on: wordnet has synsets, a group of terms. many
linguistic relationships between the synsets and the terms
... main problem with the phase one conversion is lack of people's time: more
work on the document and then liase with princeton
... Christianne Fellbaum someone was definitely interested in working on
this
... which maybe enough
<RalphS> [ WordNet Task Force description is http://www.w3.org/2001/sw/BestPractices/WNET/tf ]
guus: issues: what shoudl the
base uri be for wordnet; how shoudl updates be handled? and how shoudl words
be repreesnted
... this is the only document we have really. focus discussion on how to get
more effort into here
danbri: everyone wants to do the exciting stuff not phase one stuff: this is hard wor
guus: would love to do it if he had the time
danbri: good for all to review
the introduction to this...easy to confuse the differnt tasks, e.g. could
skos grow to address any of the wordnet tasks?
... some of these are research questions e.g. similarity of structures
between thesaurus and a lexical database
jeremy: maybe just a few terms to connect those...maybe in a separate namespace
brian: issue in modelling wordnet is : what is it you're modelling - a lexical concept, a sequence of characters?
<RalphS> [Christiane attended our 27-May WG meeting to talk about WordNet-SWBP collaboration; see http://lists.w3.org/Archives/Public/public-swbp-wg/2004May/0149.html ]
brian: people using it in RDF want a large set of classes not "the word bicycle"
danrbi: yes - two traditions
guus: we decided to do the lexical one first and the classes one in phase 2
some text from guus: http://www.cs.vu.nl/~guus/public/wn.txt
jeremy: we could just discuss the resource issue?
david: do it with skos?
jeremy: complexifying stage 1
guus: problem is too many representations and people like a common reference
ralph: has princeton endorsed any rdf reepresentations?
benjamin: decker one linked form their page
david: but none of these are complete representations
<danbri> [they'll list anything that uses wordnet; they don't QA those links]
jeremy: could a grad student take this document through the process?
guus: it's not just a grad student exercise....
ralph: but we could help answer
some of teh harder questions
... any candidates? even at princeton maybe?
guus: might have a candidate, btu would need a group to ask questions of
ralph: a student might drive the group by asking specific questions
david: do we gain anything as a wg by using skos for this/investigating this link
guus: doesn;t think there's much of a link betwewen skos and stage 1
david: librarian case - their terms have a lexical route, they might benefit
guus: librarians and wordnet are
distinct communities
... wants to get something out fast
aliman: agrees that 1st step, skos not appropriate. pragmatic point - people don;t want two solutions for one problem: cleaner at first anyway to offer one solution
danbri: agrees with that. also
peopel confuse teh powers of skos and the powers of rdf, lots of education to
do there. cobining the two will confuse matters even more.
... already acknowldged in teh docs that these could become closer later,
leave it at that
... wordnet is a model of the english language - work in other places to
generalize the model to other languages e.g. euroowordnet, japanese
danbri: be exiting to have this language neurtral stuff later. plenty of simple work for now
ralph: generalization can make it less attractive to a particular community; specialization in documents helps us more in deployment
<danbri> (http://www.w3.org/2001/sw/Europe/talks/200404-nict/Overview-2.html I plugged wordnet (class model) to NICT folks nr Kyoto)
guus: we just say: use this one (with princeton) - and not say why ercept ina background document
danbri: "use this one" worries me
- as there are naturally 2
... you (guus) are talking about adding to the lexical version with classes
later....
guus: class representation is too difficult, one taht we all agree on...
danbri: make it a brutish one
guus: the revisions are the issue
... agreement in the TF telecon is to work wioth princeton to help with
representation at the lexical level plus discuss with them transformations
tools that could help with different versiosn
... in the maintenance phase the schema doesn;t change, just the content; for
the rdf classes version the schema does change
ralph: do we know the mechanics of how they update the database?
danbri: they do a release every 6 months or so
<aharth> ftp download at ftp://ftp.cogsci.princeton.edu/pub/wordnet/
brian: 4things to do in TF: basic
schema; talk to people whove done other represerntations and involve them;
needs to interact with princeton, getting them to include it in their
distribution etc; finally build some tools to create the RDF representation
... all depends on the first one
... lots of work in this TF above producing the document
guus: first step is critical but not the only thing
brian apologises for not having got further with this. happy for someone to pick it up and finish it; otherwise brian will find the time to get a first cut by the end of the year
danbri: q for brian: do you ahve a sense of how much more work needs ot be done on the document before a pre-working draft release of teh document. impacts on interacting with other producers
brian: betweeb 2 weeks (grad student) and end Dec (brian, given his time contraints)
ralph: would it be harmful to
toss a coin to pick an existing representation?
... would like to keep the tf around until we get more resources rather than
suspend it
guus started with the swiss one... [scribe missed name]
scribe: we're very close to that one
danbri: my version is not a lexical version, can't use that
<libby>[[
- KID Group, Univ. of Neuchatel, OWL representation
http://taurus.unine.ch/GroupHome/knowler/wordnet.html
]]
http://www.cs.vu.nl/~guus/public/wn.txt
<danbri> [as are half the others; this WD-draft is as good as it gets, I think]
<danbri> http://www-106.ibm.com/developerworks/xml/library/x-think6.html ... article by Uche coding to Melnik's version
<libby> [Univ. of Neuchatel version is the one the TF drafts are close to]
ralph: perhaps there is soemthign in jeremy's suggestion for a grad student to do
guus: steve - is there a link between PSIs and this work?
steve: yep
guus: could use these as publisheed subjects
steve: yep
<RalphS> i.e. if there is content that Guus and Brian already have that is not yet represented in a new version of the Working Draft, it sounds like there's a place for an editorial resource to help
danbri: might be interested in contacting say uche, re contacting developers
guus: Univ. of Neuchatel version is a more complete version of the melnik version
danbri: would like a few words on the spec about lexical vs class representation - could do this text
ralph: design rationale - useful but not essential...
guus: would be nice
ralph: basic design would not wait for the design rationale
brian: danbri's offer to interface with develeopers in this area would be very useful
ACTION: brian and danbri need to talk about what need to do for Wordnet document to be good enough
guus: review the decisions that need to be taken on this document tomoorw? 11.30 -1
[missed brian's comment sorfry]
danbri: worried about not knwoing when we've got it right
guus: this what the working draft
will do
... considers all the other parts as very important, incl class
representation, how to use the lingistic representtaion for annotation of
images, say
<RalphS> [yes, publication of the working draft will get visibility for the design which then gets feedback on the correctness]
--break for lunch
guus: people want to see showcase
applications that show added value of the technology
... some nontechnical examples to make that point
<RalphS> http://esw.w3.org/mt/esw/archives/cat_applications_and_demos.html
guus: semantic web challenge 2003: AKTive Space, DOPE, Building Finder, Museum
<RalphS> [ADTF description is http://esw.w3.org/topic/SemanticWebBestPracticesTaskForceOnApplicationsAndDemos ]
guus: things in common: integrate
different large data sources, RDF/OWL used for syntactical interoperability
... storage and access issues the main things to worry about
... schema mapping required
... use of owl:sameAs was an issue
... information integration and presentation is an issue
... unfortunately only in-house because it's about computer science
...DOPE: very typical based on a thesaurus
... uses EMTREE thesaurus based on mesh
... 5M Medline abstracts, 500k full-text articles
... disambiguation of search terms an issue
... use case: search for information about aspirin
... medicine is important area, professionally used
... won a technology award recently
... BuildingFinder:> USC
... use various sources (satellite images, roadmap info, address
information)
... BuildingFinder: reverse address lookup not possible in some eu countries
... image alignment algorithms
... point to a satellite image and find out the name of the person who lives
there
... combination of structural and image processing techniques (multimedia
info)
... Finnish museums on the web
... BuildingFinder: unfortunately in finnish
... weblog providing us already with some decent material, maybe not
sufficient
<RalphS> [Longwell would be another good addition to http://esw.w3.org/mt/esw/archives/cat_applications_and_demos.html ; http://simile.mit.edu/longwell/ ]
<RalphS> -> http://atlas.isi.edu/semantic/servlet/SemanticServlet BuildingFinder
libby: presents weblog
... how to get rdf descriptions out of the weblog
... weblog started out of part of the swad-e project weblog
... plan to use the weblog as part of the skos effort
... application page: title, uri, descriptions about projects
... who to contact, more information, categories
... 17 applications in the weblog already
... bit cumbersome to fill in the template
... because of spans in the template it's possible to use GRDDL and XSLT to
extract the information
... uses doap (description of a project) vocab to encode information about
the projects
... mixed-and-matched with dc and foaf
<danbri> ah, <html xmlns="http://www.w3.org/1999/xhtml">
<danbri> <head profile="http://swordfish.rdfweb.org/discovery/2004/06/adtf/#">
<danbri> ...in head of http://esw.w3.org/mt/esw/archives/cat_applications_and_demos.html
libby: uses swed: ns for categories
<danbri> DOAP, see http://usefulinc.com/doap
<danbri> (not to be confused with DOPE?)
libby: swed (semantic web environment and directory): facetted browser
<RalphS> [ SWED is at http://www.swed.org.uk/swed/ ]
libby: contains environmental
information
... SWED browser worked quite nicely for the semweb applications and demos
... SWED uses SKOS to describe categories
... categorization by name, and other properties
... build-in harvester can be used to add data from remote sites
<danbri> example of Redland w/ SKOS and DOAP descriptions... [another great swad-europe deliverable :-]
<RalphS> [I wonder if SWED has any provenance yet]
libby: possible to add data and
filter on properties
... creation of records about projects could be done by the application
authors themselves
<jjc> http://swordfish.rdfweb.org:8080/adtf/ is top level uri for what libby is presenting
libby: then harvested
... doap uses freshmeat categories for software projects
jjc: question about harvesting and control policy
libby: possible to trust a certain domain name
ralphs: maintaining provenance data?
libby: really uses SWED as an
application, keeps track of trusted sources and other sources
... jen golbeck's work is related
davidw: difficult for users to
accept is presentation of raw uri's
... we are providing human-readable labels
... non-technical users focus on longish uris
ralphs: that's what rdfs:label is for
danbri: truncation mabye?
<danbri> [aside: recent sobering experience re slipping into geek assumptions; the woman sat next to me on plane on friday hadn't heard of iPods/MP3, and I found myself realising I was suprised]
ralphs: in this case truncation doesn't work
Guus: OpenDirectory is the closest existing categorization
davidw: open directory is used for categorization, but is not really appropriate
<RalphS> [yes, left-most truncation on the DOAP category example Libby was projecting contains the only human-interpretable information; that freshmeat and sourceforge were part of the classification]
libby: need labels and uris
davidw: having demos that are compelling to end users tucana is interested it
aliman: got a student who's looking at a wiki tool for building a thesaurus
guus: demos page is a
demonstration in itself
... how to operate this?
<Zakim> danbri, you wanted to seek confirmation that we're happy with community project self-description (trust ppl not to be vain selfpromoting dorks)
guus: 18 new applications in the
semantic web challenge
... what areas are missing?
danbri: what's the motivation for making vocabularies owl dl friendly?
guus: most applications use rdf
and owl:sameAs
... maybe it's too early for owl applications, takes two years for
applications to use new stuff
jjc: maybe have options on what semantic web technologies are used in the applications
ralphs: maybe a bit technical
... what's the process of maintaining the software package?
<danbri> [for listing RDF vs OWL DL vs Full etc., I find narrative content ("what we did was...:") much much more valuable than simple checkboxes ("we use OWL DL.").]
guus: later on maybe do a survey,
keep the barrier low for data entry
... have to depend on ongoing projects that showcase applications
<RalphS> saying what technologies are used is also liable to be out-of-date; will someone remember to update the "Now uses full OWL" entry when they go beyond the DL subset?
guus: owl and xml datatype discussion
<RalphS> [XSCH Task Force description is http://lists.w3.org/Archives/Public/public-swbp-wg/2004Apr/0125.html ]
jjc: issues the task force is
addressing came up in the webont and RDF Core wg
... two questions about how to use XML Schema datatypes with RDF
... current situation is a compromise between what's ideal and what's
possible
... user-defined datatypes
... issue here that there's no agreement what uris to use for user-defined
datatypes
... when are two type literals the same
... issue here: are 0 as a float and 0 as an integer the same?
... rdf and owl testcases don't include testcases on this question
... datatypes come from xml schema, not part of the semantic web activity
<RalphS> [JJC discussing http://lists.w3.org/Archives/Public/www-archive/2004Oct/att-0049/xsh-sw-note.html ]
jjc: some response from the xml
schema wg
... need the buy-in of the xml community, but need to progress as well
... xquery/xslt are also working with the xml schema datatype
... a lot of w3c groups are potentially involved
<Guus> Related issue: numeric ranges require iser-defined datatypes: http://lists.w3.org/Archives/Public/public-swbp-wg/2004Apr/0066.html
ralphs: producing a sketch that people can comment on maybe a good idea
jjc: possible solutions;
... the DAML+OIL solution works for datatypes that has a name
... using name attribute to fragID the xml schema descriptions
... however, not in conformance with RFC2396 and xml schema mime type
... for sw people, this solution is better
...alternative: xml schema component designators wd
... powerful solution to navigate in the schema using xpointer
... however, quite complex
... possible solution: use both id and name
ralphs: it's important to distinguish between a concept and a particular description of the concept
danbri: made the conflation using uri's for identification and getting the description by dereferencing the uri
jjc: xml refers to syntactic
objects, on semantic web the resource that denotes itself is interesting
... uri of a description is the uri of the thing described
ralphs: other ways of constructing an uri: bnode xpointer scheme?
jjc: both the id solution and the
xscd solution could work
... next item: comparison of values
... comparison between float's and int's
... simplest possible solution: all the types are different
... but somewhat counterintuitive
... long and int are derived from the same primitive type
guus: number datatype would help
davidw: we have super datatype of number
<RalphS> XML Schema 'decimal' type is http://www.w3.org/TR/xmlschema-2/#decimal
davidw: implemented in product because of customer demand
<RalphS> XML Schema 'float' type is http://www.w3.org/TR/xmlschema-2/#float
jeffp: what are the current answers from the xml datatype spec?
jjc: no consensus within the xml
schema group regarding the issues
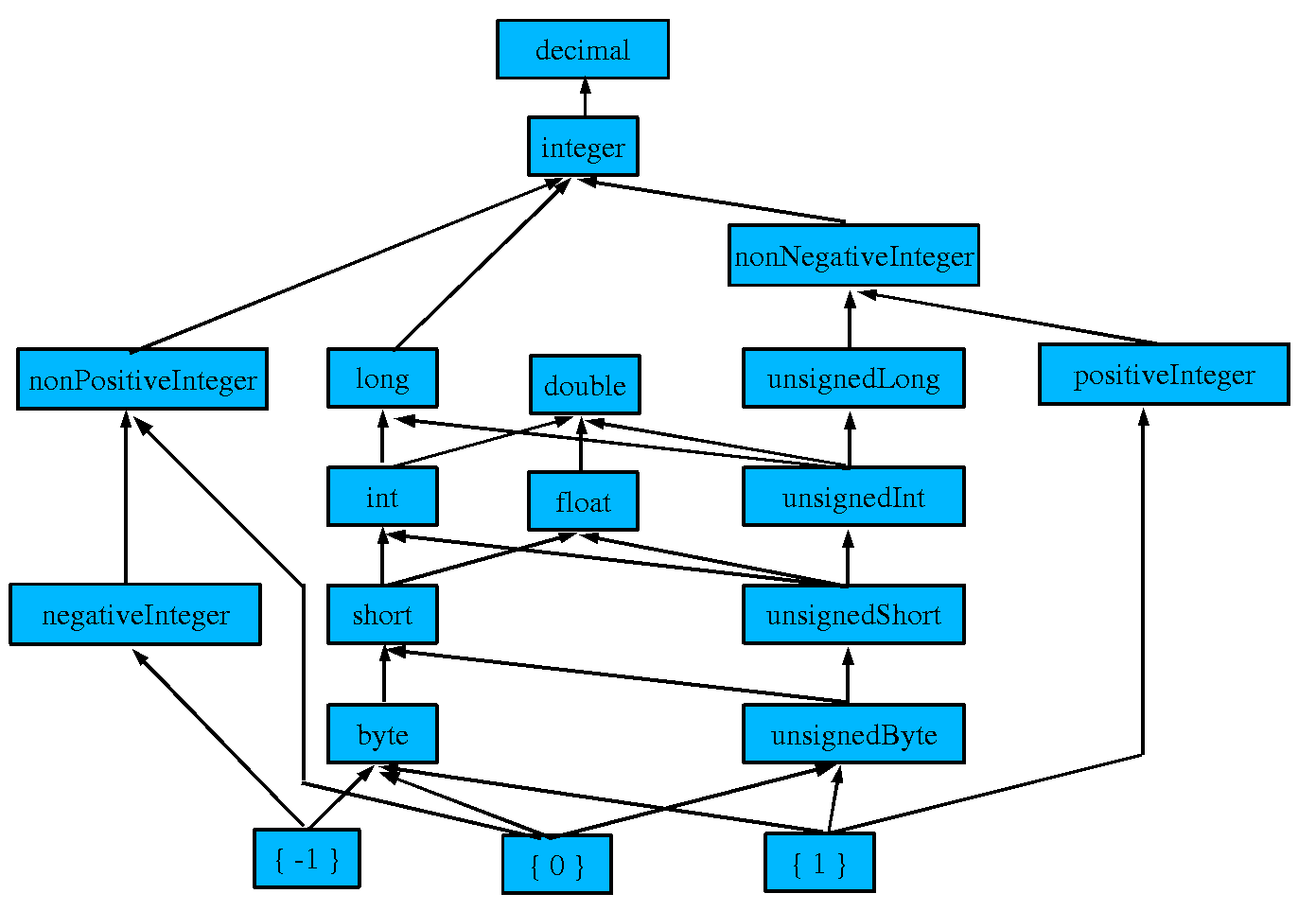
... the document should be clear about that though. http://lists.w3.org/Archives/Public/www-archive/2002Nov/att-0092/04-num-hierarchy.png
jeffp: is it a subsumption hierarchy or definition hierarchy?
jjc: two extremes: all types are different vs. strong mathematical representation
<danbri> [ context: http://www.w3.org/TR/2004/WD-rdf-sparql-query-20041012/#extendedtests ]
jjc: xpath 2.0 documents mention
the eq operator that says "2.0 eq 2" is true
... xslt have typed literal objects and operations can be done on these
literals
guus: what next steps need to be taken?
jjc: key question: publish a
document without xml community?
... continue to work on the document and then ask for input on an editor's
draft
... timeline could be distribution to the other wg's before chrismas
<RalphS> [I was unaware of the XML Schema Component Designators work -- looking at it now, it does appear to be a strong connection with this datatype issue]
danbri: relationship to DAWG/SPARQL and xquery operators?; see http://www.w3.org/TR/2004/WD-rdf-sparql-query-20041012/#extendedtests
<RalphS> [XML Schema: Component Designators
<RalphS> http://www.w3.org/TR/2004/WD-xmlschema-ref-20040716/
<RalphS> W3C Working Draft 16 July 2004
<RalphS> ]
jjc: following the xslt 2.0 is more likely to be in line with the dawg group
<Zakim> RalphS, you wanted to say that mathematicians will laugh if we adopt the viewpoint that xsd:decimal has a disjoint value space from xsd:float
ACTION: jjc review SPARQL WD re http://www.w3.org/TR/2004/WD-rdf-sparql-query-20041012/#extendedtests
[Ben Adida calls in for this session]
-> http://lists.w3.org/Archives/Public/public-swbp-wg/2004Nov/0003.html [HTML] Status for RDF/XHTML [BenA]
Ben: RDF-in-XHTML-TF has been in
existence since 1999
... users include FOAF, TrackBack, GEO-URL
... Dublin Core, and more recently Creative Commons
... main issue is how to embed RDF triples in HTML
... have been focussing now on the sections that are dependent on the HTML
WG's current timetable
... working in parallel on making sure we understand our requirements
<benadida> http://www.w3.org/2003/03/rdf-in-xml.html
Ben: ... there are items in the
27 May 2003 document that we are no longer sure still make sense
... e.g. direct embedding of RDF/XML syntax
[Tom Baker calls in at this point]
Ralph: the problem is complicated
because at least 2 WGs need to cooperate, and possibly 3.
... also, the HTML WG's charter does not allow them to request certain
changes of XML schema (for example)
... Jeremy sent proposals to make RDF A simpler
... need to offer proposals to HTML WG before last call
Jeremy: initial review (from 1
week ago) some issues came up
... have done implementation of RDF A
... serious issue: RDF A is too complicated
... some of the rules are too complicated
... the number of different ways of representing a triple in RDF A is 432
... if you run examples from spec you get more triples than the author
said
Ralph: the spec needs more work
either to represent authors intent, or to fix triples
... opportunity: the words in the spec could be simpler
... and could fix triples at same time
Jeremy: some clear
simplifications but doesn't go far enough l ...
... more functionality ...
<Ralph> -> http://lists.w3.org/Archives/Public/public-rdf-in-xhtml-tf/2004Nov/0001.html Jeremy's simplification of RDF/A
Ben:it's good because can
represent more complex triples, literals
... and an RDF triple in an HTML clickable way
... without duplicating anything in markup
... which is good property of GRDDL
<Zakim> danbri, you wanted to check familiarity with new W3C Compound Documents WG
Danbri: new WG at W3C Compound Documents
Ben: lot's of important
techinical detais re RDF A - please take a look!
... Now get some initial feedback asap for html WG
... look at 3 line statement from Ben's email
... important message to HTML WG: we';re moving in the right direction.
Ralph: This meeting output: statement that Ben put in his mail from today ...
<benadida> statement: We find RDF/A to be a big step forward and encourage the HTML WG to use it in place of the 22 July MetaInformation module. Our forthcoming detailed comments and suggestions on RDF/A are intended to perfect this work in fulfilling the long-standing needs of the RDF deployment community to embed semantic web data within HTML documents.
Ben: Can we all endorse that statement?
Guus: are willing to make this direction statement?
ralph: what questions does the WG want to ask of the TF before deciding on the endorsement?
Phil: direction is superb
... pragmatics - concerned about potential abuse within XHTML user
community
... question need to push forward incolusion of metadata for XHTML 2
...rather than hold back and look at richer set of use cases
... concerned about the potential abuse of RDF/A within HTML, perhaps focus
on RDF/XML embedding
... use of metadata inside XHTML may be misinterpreted by general public
... if I were writing metadata in web page now, would do it to drive search
engines.
Guus: this is important point, but outside scope of this WG
Ben: what do you consider abuse?
ACTION: Phil to write up concerns on email
Danbri: how strongly are we
pushing this as as a new RDF syntax?
... originally to handle FOAF namespace ...
... hoped that the FOAF namespace document could be validated for RDF content
...
... so do we support the practise that e..g. the FOAF RDF description be
written as embedded in an XHTML document?
... I.e. should we write ontologies in RDF A?
<RalphS> [me says No!]
<danbri> [in which case, 1 original FOAF use case remains unmet]
Ben: goal is to produce alternative serialisation for RDF ...
Ralph: goal?
Ben: requirement to embed
arbitrarily complex RDF statements in XHTML
....to satisfy this requirement is a goal.
<RalphS> [but it would be an interesting exercise to see how much of the expression of an ontology in RDF/A could be done]
Guus: meant to e used mainly for annotation purposes ..
Jeremy: RDF A IS a new RDF syntax ...
Ralph: but this in itself is not
a goal.
... i.e. implies something wrong with existing syntaxes.
... The result is to create a new syntax
.... but this is soultion to original requirement.
... Use RDF A to express an OWL ontology? No, not a goal or
recommendation.
Danbri: what about my original
FOAF use case?
... I want a single resource for both humans and machines
... my use case was to write a single document at my namespace that could be
both presentation and RDF without content negotiation
<DavidW> RDF/XML has known problems as an XML vocabulary and as a serialization format
Phil: This new variant of RDF will become the defacto standard syntax ...
Guus: can people outside the TF support positive statement for RDFA
danbri: on the fence, wants to talk to compound docs WG
SteveP: opening a can of worms
... lead to trouble
... but in the mandate of the TF support for complete RDF
... think RDF subset for simple annotations sufficient.
... the problem is that the requirement was for complete RDF support, not
"just enough" to write metadata _about_ a document
ACTION: Steve to email on concerns for RDF in XHTML
David: should not treat RDF/XML
as sacrosanct
... problems with it ... we have an opportunity to recognise that RDF is to
concept, NOT the syntax
... this proposal leads to use cases for HTML authors ... and more
... would rather clean this up than see RDF/XML fixed, or RDF/XML in
XHTML.
Danbri: In RDF Core, test cases
used rigorously
... worried that design work so far happened without test case infrastructure
...
ralph: we have an action to express all RDF test cases ...
Ben: I have an action to make sure this works with creative commons and with FOAF ...
<RalphS> [make sure that DanBri differentiates between users of FOAF and the FOAF namespace document]
David: we have to get formal comments to HTML WG before use case work.
Guus: very positive about this
work, with reservations about test cases
... but if going to happen, then happy.
Jeremy: political goal to be positive.
Guus: propose to make general positive statement, with technical caveats
<danbri> me: "It's great and it's useful and it's progress... but it doesn't address my use case (FOAF namespace documentation: RDF/XML inside XHTML); I want to know how that'll be progressed. Shoudl we begin a conversation w/ Compound Documents WG?"
Guus: add wording about test cases
David concurs
Danbri: fulfil SOME of the needs; who should do test cases?
Ralph: ask them to do all of our test cases
<danbri> maybe 'many of the...'
Danbri: they should be using test case driven framework.
Ralph: don't want them to feel that all test cases must be met.
Guus: rephrase the statement?
ACTION: David to reword the statement on RDF A to HTML WG.
Jeremy: they need DIFFERENT test
cases
... RDF Core test cases are a starting point ... may not want to use all
...
Danbri: framework for doing it using NTRIPLES.
Ben: HTML WG meets next week ...
not all will agree to RDFA
... if impose too constraints now, they may revert to metainformaiton
approach
... can we include test cases in detailed comment s to come?
Guus: in fact test cases are
implicit in any spec
... so can leave this out of comment
<DavidW> Try this one: We find RDF/A to be a big step forward and encourage the HTML WG to use it in place of the 22 July MetaInformation module. Our forthcoming detailed comments and suggestions on RDF/A are intended to perfect this work in fulfilling long-standing needs of the RDF deployment community to embed semantic web data within HTML documents.
Guus: proposed to send this as comment to HTML WG
second Jeremy
motion carried
ACTION: Ben to send this statement to HTML WG via email
Guus: outline current docs and issues please.
<RalphS> [VM Task Force description is http://www.w3.org/2001/sw/BestPractices/VM/ ]
Tom: sent out timetable ...
<RalphS> [Tom's timetable is in http://lists.w3.org/Archives/Public/public-swbp-wg/2004Oct/0147.html ]
Tom: put document on list before
holidays
... Move to CVS for finer editing by January
... First public release mid Feb
... Other section try to describe some principles of good practise
... then third section discussing unclear issues
... After discussion ... there are some points could be added
... Do we have large scalse vocab to use as example of good practise ?
... or discuss this in open issues?
... but before getting into issues - is the timetable realistic, does the
outline look good?
... aim to quickly flesh out the draft with low hanging fruit
... agree on main points ... then begin refinement.
Guus: timeschedule?
... ambitious but feasible (good to be ambitious)
... also fits well with charter for TF to produce results within 2-4months
David: there has been interest re
ontaria
... interest in evaluating ontologies posted on ontaria against VM
recommendations
... and posting compliance ont he site
... i.e. this is the kind of use this thing will be put to.
Tom: compliance is a heavy
word
... we are trying to get agreement on some basic principles
... to evaluate ontologies against these principles could be good but
... we are talking about quite geenral principles ...
Guus: this note does say anything about 'compliance' but customers may ask about 'compliance' ...
ralph: this WG is producing docs
with are 'best practises'
... whatever can be mechanically tested will be.
Danbri: part of this TF leaving
machine readable evidence for management of a vocab
... but machines cannot tell if statements are true ot not
... wories me when people look for a big pile of 'good' or 'bad' ontologies
...
Guus: N.B. we are talking about
vocabulary management
... proper usage criteria
... we can endorse this without going into a good/bad debate.
David: there is good/bad URIs and issues without going near whether an ontology is itself good for a specific job ...
<Tbaker> agree with David
Jeremy: can these principles say:
use RDFS label?
... and re 'conformance' this says rec rather than note ... would rather not
go there.
David: we can put out a series of
good ideas as a best practise group
... without taling about compliance
... but as Guus says, people may choose to evaluate compliance relative to
our note
... even though it is not a W3C recommendation.
David withdraws the word 'compliance' :)
Tom: a suggestion came up to have
an example vocab that provides example of good practise points
... examples of different types of vocabulary
... describe FOAF, DC, SKOS, .... illustrate range of vocab tyupes
... pointer to how management is done for these vocabs
... still not clear to do about the really large ontologies
... there are some big vocabs that do not use URIrefs
... what should we use re large complex ontology as example?
... e.g. FAO fisheries, wordent, NCI ..
guus: we take some simple vocab
for section 2
... want to keep as simple as poss.
Tom: so OK to feature simpler
vocabs in section 2
... leave high end onts for esction three?
Guus: exactly.
... which vocabs on the table as examples?
Tom: FOAF DC SKOS Wordnet
... + maybe major medical/life sciences vocab
... Wordent section 2/3?
Guus: FOAF excellent example
Danbri: good example, shares stuff with DC ...
Guus: also nice to hive more
terminology style vocab
... e.g. FAO thesaurus
... I.e. maintained RDF representation by owning authority
Danrbi: two classes of thing to
do:
... 1. interview people on how they managed older vocabs
... 2. manage specifically in relation to RDF representations ...
Guus: my preference would be to choose something that is already expressed in RDF by its owning organization
Alistair: opportunity to pick something that already has a history of evolution
David: spoke to NCI guys last
week
... have 5-6 guys
... + chief editor who merges by hand changes
... process is painful
... want standard tools to handle change ... i.e. real world problem
... difficult for large onts edited by multiple peoplle
... so people appreciate guidance on how to markup an ontology
... to support change management.
<Zakim> DavidW, you wanted to ask Tom whether the VM TF has addressed guidance for multi-user editing and merging of edits for very large ontologies.
Guus: any more on sample vocabs?
Tom: for people coming new to
W3C
... want to collect issues into one place
... this note would be helpful if could summarise in 2-3 paras
... what the major papers are, what there scope is etc.
Guus: agree
ACTION: VM TF to compile list of sample vocabs for the note ...
Guus: Candidates FOAF, DC, and
one thesaurus style vocab (missing candidate)
... look into candidate for this ...
Ralph: we need to find someone who'll keep maintaining things in good way ...
Jeremy: also need to choose example with good modelling, even though modelling is not the focus.
Steve: (on published subjects)
... what about vocabs where don't use URIs ...
<Zakim> RalphS, you wanted to say that in the VM case the only reason to push to an external example (e.g. non-FOAF) is to engage some specific community
ralph: whatever we pick for
third, need to be reasonably confident about their current practise, or that
they will follow our best practise
... OASIS may be possibility ...
<RalphS> [specifically, if we can nudge OASIS in a better direction by involving their Published Subjects in this work, that might improve the world]
Jeremy: published subjects good if meet quality threshold.
Steve: may meet in DC at XML conf 2004 week of nov 14-
Guus: summarising:
... positive feedback on outline and timeschedule
... endorsemenet of using DC and FOAF as examples
ACTION: VM TF with help from Guus to find thesaurus like example and high end onts to section 3
Tom: final point: appreciate help setting up wiki.
danbri volunteers
<RalphS> [I accept the actions listed by my name in http://lists.w3.org/Archives/Public/public-swbp-wg/2004Oct/0150.html ]
Guus issue to discuss: how do we
get additional people involved in some task forces? e.g. Sandpiper
... according to current W3C policy it is difficult to ask people to become
invited experts from companies
Ralph: Reminds all members of W3C
economics and the benefits of joining. There are good reasons not to invite
experts from non-member companies unless they have skills we specifically
need and cannot get in another manner.
... Invited experts may also join when an organization's joining is in
progress.
Guus: Good for everyone to know policy.
Deb: This particular request was from a very small company. Joining may be difficult for very small companies.
Ralph has an action to discuss this with the company.
David: Companies are responsible for making the decision to join or justify the reason not to.
Guus: Editors of documents do not have to be members of WGs or W3C.
Ralph: Not sure that is a good precident to set.
David: Since Ralph has an action, we should move onto OEP business.
Deb: There are other companies
who are in the same position. Should we generate our Note with them as
authors, but not members?
... OWL Time would be another note that would benefit from the involvement of
individuals who are from non-Member companies
Jeremy: I have a preference that editors and authors be bound by the patent policy.
<jjc> http://lists.w3.org/Archives/Public/public-rdf-in-xhtml-tf/2004Nov/0004.html was msg from DanC I mentioned half hour ago
Guus: More about the priorities for the OEP work?
Deb: Reviewing http://www.w3.org/2001/sw/BestPractices/OEP/
Deb: regarding ADTF -- suggest that there be a connection to SemWebCentral site
<dlm> http://www.semwebcentral.org/
Guus: SemWebCentral is more oriented to tools
Deb: yes, but it's a general resource for the community
Libby: I was not aware of SemWebCentral -- I will take a look at it
Guus: candidate for TF breakouts
tomorrow are: HTML, WordNet, XSCH,
... Topic Maps (to draft a TF description)
DanBri: maybe this WG should work with the TAG on hash vs. slash
Guus: hash vs. slash might be on agenda for Technical Plenary
<pepe> Short background reading for RDF/TM session: http://www.ontopia.net/tmp/RDFTM-TF-DoW.html
Steve presents http://www.ontopia.net/tmp/RDF-TM-interop.ppt
Ralph: will this be a stable URI?
Steve: no, I will put it someplace more permanent after I correct the typos
Steve: Extreme Markup staged "confrontation" between Eric Miller and Eric Freese (in 2002) was unfortunate in that it created a perception of a rivalry
[slide 4] TMCL is Topic Maps Constraint Language
XTM - XML Topic Maps
HyTM - SGML-based Topic Maps exchange syntax
LTM - text-based "linear Topic Maps" syntax, developed by Ontopia
Topic Maps were developed while trying to identify the underlying semantics of a back-of-book index
RDF is resource-centric, Topic Maps are subject-centric
Steve: but with a subtle shift in the meaning of "resource", this apparent difference becomes more dialectic than diametric
<danbri> http://dictionary.reference.com/search?q=seamless [[Having no seams: seamless stockings.
<danbri> Perfectly consistent: a seamless plot in the novel.]]
Steve: the distinction between
the symbol ("Topic") and the referent ("subject") is quite distinct in Topic
Maps
... Subject is explicitly defined as "Anything whatsoever, regardless of
whether it exists or has any other specific characteristics, about which
anything whatsoever may be asserted by any means whatsoever"
Guus: re: 3 types of assertions in Topic Maps, my mental map is association corresponds to general statements, names correspond to rdfs:label, occurrences correspond to rdf:type statements
Steve: not quite for occurrences; there is a built-in notion of type
Guus: a kind of part-of semantics?
Steve: not really, it's like
'about' but the other way around
... occurrences are a special form of association; they are always binary and
express relationships between a concept (Topic) and an "information
resource"
... "information resource" is some kind of document in the broadest sense
... rdf:Resource corresponds to tm:Subject
... tm:Resource is an abbreviation for tm:InformationResource
<Ralph> [re: slide 14, Ralph wonders if 'basename' is a relationship in some built-in Topic Maps vocabulary]
Steve: in order to know the exact semantics of a particular relationship you need to know the role that each thing takes
David: where are the definitions of these associations?
Steve: associations have types
... an association type and an association role type is a topic
... so to create a new type, you create a new Topic
... syntactically these are XML elements within your Topic Map document
Ralph: syntactically, can you get from a document that has instances to the XML document that defines the Topics?
Steve: yes
DanBri: are there logcial rules associated with a Topic Map that defines, e.g., a creator association?
Steve: TMCL is the language in which to capture such constraints
<danbri> [I wonder how much of TM semantics could be captured in something like Lbase, http://www.w3.org/TR/2003/NOTE-lbase-20030905/]
JJC: reification in rdf never
meant what it seemed to mean; it isn't very usable
... RDF Core WG did not remove reification from the spec recognizing that
there is legacy use of it. But RDF Core did not want to encourage further
use.
DanBri: 2 parts to the puzzle; the reification vocabulary (rdf:Statement, rdf:subject, rdf:predicate, rdf:object) and the reification syntax
JJC: the bagID stuff got removed
DanBri: originally implementors thought they had to always create the reification triples. this is no longer the case.
<danbri> cf. http://www.w3.org/TR/1999/REC-rdf-syntax-19990222/#higherorder and http://www.w3.org/TR/1999/REC-rdf-syntax-19990222/#model
JJC: the rules for identify of literals is the task of the XSCH Task Force
Steve: Topic Maps distinguish between "names" and "identifiers"
Brian: please define "names" and "identifiers" as you use them
Guus: let's defer that discussion
DanBri: RDF is very clear on this point
Steve: a URI attached to a topic
that represents an information resource is a "Subject locator"
... arbitrary subjects that are not information resources do not have a
subject location.
... Topic Maps uses an indirection mechanism in this case
... the information resource is the subject indicator
... the URI of the information resoruce is the "Subject identifier"
... such a distinction between subject locator and subject identifier does
not exist in RDF
DanBri: objection -- this distinction is provided at a different level
Guus: the RDF metamodel does not contain this distinction
Steve: the same Topic can have
many identifiers; this expresses the fact that the identifiers identify the
same thing
... Published Subjects: a distributed mechanism for assigning unique, global
identifiers -- based on URLs -- to arbitrary subjects
Guus: are published subjects for both subject identifiers and subject locators?
Steve: subject identifiers only
DanBri: slide 27 suggests that different URIs definitely means not the same subject
Steve: not necessarily the same subject; you can never establish that two things are absolutely different
<danbri> [which would create a landgrab; I could create a psi for Ralph Swick, meaning that nobody else could. Which would destroy the soughtafter grassroots pluralism]
<danbri> [re slide 28, I'd like to revisit Q of how a PSI provider would help people distingushi a museum-as-building vs museum-as-organization]
<Ralph> [I think the Topic Maps PSI mechanism differs in practice from RDF/OWL only in that Topic Maps _requires_ that the URI be dereferenced to determine the identity of the subject]
<danbri> [I get adequate facilities from a primaryTopic rdf property, has v similar characteristics to those advertised for TM I think]
[Steve promises to put a version of http://www.ontopia.net/tmp/RDF-TM-interop.ppt at a more persistent URI after corrections]
[slide 47; Procedure and deliverables]
DanBri: I think it is important to keep OWL close by from the beginning of the discussion
<danbri> ['cos owl:InverseFunctionalProperty critical to discussion of merging, identity reasoning etc]
Guus: focus discussion on particular steps to be taken
Jeremy: the published subject
stuff is the most exciting bit of Topic Maps work from an RDF perspective
... it would be nice to write something that permits the RDF community to use
the PSI work
<Zakim> danbri, you wanted to to offer to contrast the foaf:topic and foaf:primaryTopic design [possible lunch topic if no time...]
DanBri: I have a strawman on a
'primaryTopic' relation
... so you can scoop up data and use OWL reasoning;
... my strawman: http://xmlns.com/foaf/0.1/#term_primaryTopic
... "The foaf:primaryTopic property relates a document to the main thing
that the document is about."
Guus: is there a metamodel for Topic Maps? I think it would be easy to write one in RDF Schema
Steve: a couple of people have written such metamodels but none are viewed as sufficient by the Topic Maps community
David: some of Steven's slides that he skipped do give reasons why a simplistic mapping should be rejected
<danbri> [aliman has some stuff in SKOS in this area, too...]
<aliman_> proposal for 'skos:subjectIndicator' ...
<aliman_> which I think (danbri?) could be inverse of foaf:primaryTopic?
<aliman_> (skos:subjectIndicator as an inverse functional prop)
<danbri> it's related, possibly the same. i'd be happy migrating that piece of work into SKOS rather than FOAF if functionality is being duplicated.
<aliman_> could leave them as each others inverse in both vocabs ... ?
<aliman_> ... actually realise foaf:primaryTopic and skos:subjectIndicator couldn't be full inverse, ...
<aliman_> because not all pages described with a primary topic would qualify as a PSI
<Benjamin> [on the rdf topic map mapping : http://www.w3.org/2002/06/09-RDF-topic-maps/ ]
Jeremy: W3C WGs work better when
they start with a completed proposal -- one that is viewed as 'finished',
then the WG finds the parts that really were not finished
... may be premature to start WG work when a [full proposal for] mappings do
not yet exist
Steve: I view this as similar to DAWG where there are a number of attempts at mappings now
Jeremy: published subjects looks like an easy piece of work to get early success
Steve: while published subjects
are important to RDF-Topic Maps interoperability, that is not all they do
... PSI will be important for vocabulary management
Alistair: there's been a lot of discussion in SKOS about a new predicate that would support the published subject paradigm
DanBri: does the creator of a page have to plan that page to be a PSI?
Steve: that is the recommendation
-- a published subject page should be something that was explicitly written
to be a PSI
... it does not necessarily have to contain machine-readable content, though
there are recommendations regarding the content
Guus: who might be interested in participating in a TF on RDF-Topic Maps interaction?
[Ralph sees Steve, DanBri, Alistair's hands and assert that one of {Eric Miller, Ralph} is likely to want to participate]
breakouts will be:
1. RDF/TM TF description (Steve, Alistair, David, Libby)
2. RDF/XHTML issues + XML Schema datatypes (Benjamin, Felix, Jeff, Ralph, Phil, Jeremy)
3. WordNet phase (Andreas, Guus, Dan, Brian)
<aliman> http://www.w3.org/2004/11/02-swbptm-irc#T14-24-51
Aliman: happy with TF description
<aliman> http://www.ontopia.net/tmp/RDFTM-TF-DoW.html
Aliman: only those in the meeting today
<danbri> [re TF membership, I have a few things I want to contribute, not sure yet quite how much time I'll have for TF overall...]
mailist identier?
Guus: suggest rdftm
Aliman: we frame the initial
statement
... to combine the two families
... to provide transformation between the two objects:
... three longer term objects
Ralph: note additional W3C Process requirements if the RDFTM TF intends to produce a Recommendation (or a "Recommendation-track document")
Steve: that means sth not part of the short term objectives
Alima
n: The initial focus is on features defined in ISO 13250 Topic
Maps.
... Other Topic Maps-related standards (such as TMCL and TMQL) may be
considered at a later date.
Steve: we discuss on various detailed issues, and suggest consider them later on
Alistair: DELIVERABLES
<RalphS> [discussion of dropping the word 'complete' in approach "2. Choose one or more of these as a starting point for defining a complete methodology." ]
Guus: what do mean by "Note"?
David: we can intent to have a "note"
Guus: WG note on this issue.
Steve: any W3C member can provide note?
Ralph: note true; member submission vs. WG note
Guus: WG note is different from
recommendation
... we can use working draft
... our note is not for public review yet
Alistair: DEPENDENCIES are left updated by steve, dependency on PORT TF for SKOS
David: by the next teleconf
... are you addressing any use case in this TF?
Guus: it might get lots of
attention from other communities
... suggest two co-ordinaters; one for W3C and the other for ISO
David: not sure if we need coordinators
Steve: we can get some publications out of it
ACTION: David to contact Eric Miller re his interest in joining the RDFTM TF.
Dan: someone might write about it at xml.com
ACTION: Steve to finish rdftm TF description
Ralph: are you soliciting public feedback?
Steve: the note should cover all the existing approaches
Ralph: WG Note implies we don't
have further version of it
... otherwise it is a Working Draft
Steve: TF only produce draft?
Ralph: TF provides proposed
draft
... WG decide if it can become WG working draft
Steve: what are the final output from WG
Ralph: recommendation or a WG
note
... WG provides last call working draft
... provide evidence to director
Ralph: change the second point [change 'Working Draft' to 'Note']
Guus: WG consensus can lead to a
WG note
... time?
... rdf/xhtml
Ralph has sent notes to the mailing list
Ralph: Phil concerned that RDF/A
addresses a closed community; the opportunity
... to express a variety of use cases around RDF/A is limited.
... Phil agrees to provide some use cases
... Jeremy says good tools are part of the solution to manage proper
usage.
... Benjamin and Jeff willing to help
... Jeff agrees to give comments of current draft
... Jeremy points out there are two related working drafts had last call last
year
... hard to get further comemnts
Guus: can we handle the late suggestion?
Jeremy: we should have done it much earlier
Guus: is it critical?
David: waht about rdf/a
Jeremy: w.r.t. the value space question, the most critical thing is that implementors do the same thing -- which choice is made won't matter as much
David: we should be prepared to comment on rdfa in the next few months
Jeremy: i have made all the negative points in their mailing list
David: Mark has been had his way
Ralph: we have to be persuade
<danbri> today's negative comment on rdf/a: http://lists.w3.org/Archives/Public/public-rdf-in-xhtml-tf/2004Nov/0007.html
<danbri> see: wordnet breakout: raw notes
Guus: TF draft will be ready after their f2f meeting
Guus: we revise the TF
... we look at the prolog source of WN
... and went through the list of all issues
... requirement that URI should be humna readable
... we should do some test on URIs
... we postpone discussion on some issues
... ask Jan to write transformation into RDF/OWL
... we include wn:lexicaForm
... we also resolve Prinston team re requirements
... resolved not to add a verb group for mow
... we provide two versions of WN
... we can complte by the end of the year
... move to class-centred representation
Guus: 1. UML stuff
... we can also talk about location of next f2f
... teleconf is useful
... ODM group is more ambitious now
... also do metamodel mapping
... they use OWL full
... as the anchor point for translations
... other metamodels: rdf, topic maps
... also mapping to scl but only one way
... they will have a two way UML - OWL Full mapping
... mapping between ER models and OWL Full
... possible for express as well
... they expect our feedback
... we should review their draft in Dec
... we should plan in advance for review
Jeremy: HP agees to review
Dan: comments? 6 pages or 2 lines comments?
Phil: they mainly want to be awared
Guus: which part HP want to review?
Jeremy: not sure
Guus: TM TF should review the
connection between OWL full and TM
... if their work is good, we can take it
Steve: we can include it into our previous work
ACTION: Jeremy Clarify which parts of UML docs HP is most interested in reviewing
ACTION: find someone to do the review the part of UML about TM
Guus: two chapters; TM metamodels and its mapping to OWL Full
Guus: Dec will be the review period
Guus: I can do metamodel of OWL
full and mapping to UML
... ask PatH to review the scl part
... who are interested in OWL full to ER?
David: Tate Jones can do that
Guus: it makes sense to help them as much as possible
David: will the OWL to ER be chapter review?
Guus: yes
next f2f at W3C Tech Plenary
<libby> 28 February- 4 March 2005, Boston, MA, USA, Hyatt Harborside Hotel
Guus: whole week meeting; WG f2f meeting and TF meetings; up to us to decide
Jeremy: should be working with XML schema working group etc.
Steve: we can have TF meetings first then WG meetings; i.e. 4 days of meetings?
Ralph: we can ask
Guus: ok for everyone?
... Nov 18 next teleconf
Ralph: 2pm boston time
<RalphS> 2pm Boston is now 1900 UTC
Guus: Nov 18, 1900 UTC; after that we stick to two weeks schedule
<RalphS> 2 December 1500 UTC
Guus: www panel
<RalphS> 16 December 1900 UTC
<RalphS> (noting that 2 December is during the Advisory Committee meeting)
David: WWW2005 May 10 2005,
japan
... we need strong representation from this WG
... who will be in Japan then and want to be involved
Steve: I am tempted but need to
talk to the boss
... good chance to present our work
David: panel submission dl:
shortly
... Steve, Jeremy, ...
David: someone from NI ...
Guus: review
... table about TF and
members
... Felix agrees to help ADTF
... we decided to drop some TFs ...
<RalphS> Guus is showing the table in the 2004-03-04 F2F minutes: http://www.w3.org/2004/03/04-SWBPD
David: one to explain SW to developpers
Phil willing to participate in TF revise
<DavidW> WRLD TF to be considered again in March/April 2005, after some TFs complete (maybe VM, WORDNET, RDFHTML?).
<DavidW> David, Phil, probably Jim H willing to participate in WRLD TF next year.
thank the local host Jeremy!
very nice service!
<danbri> jjc++
We will do a good job in our first year!
Steve: thanks to Free University of Amsterdam for dinner!
{kind=link}