Weaving Meaning: The Semantic Web
Eric Miller, W3C Semantic Web Activity Lead
American Association of Law Libraries
2002-07-23
Orlando, FL USA
Slides available at:
http://www.w3.org/Talks/0723-aall-em/

Overview
- Background and Context
- The Problem
- Introduction to Enabling echnologies
- Semantic Web and Law Libraries
- Future Directions
- Additional Information
The Semantic Web: What is it?
- Many things to many people...

The Semantic Web
- An interesting bed-time story... still!

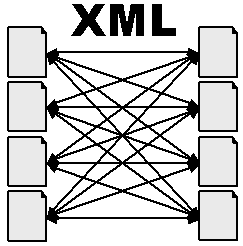
The Current Web
- Resources:
- identified by URI's
- untyped
- Links:
- href, src, ...
- limited, non-descriptive
- User:
- Exciting world - semantics of the resource,
however, gleened from content
- Machine:
- Very little information available - significance
of the links only evident from the context around the
anchor.
|
|
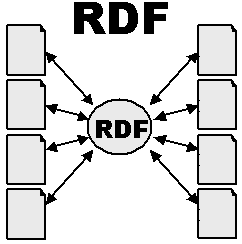
The Semantic Web - A Simple Extension to the Current
Web
- Resources:
- Globally Identified by URI's
- or Locally scoped (Blank)
- Extensible
- Relational
- Links:
- Identified by URI's
- Extensible
- Relational
- User:
- Even more exciting world, richer user
experience
- Machine:
- More processable information is available
- Computers and people:
- Work, learn and exchange knowledge
effectively
|
|
What is the Semantic Web?
The Semantic Web is an extension of the current web, in
which information is given well defined meaning, better
enabling computers and people to work in cooperation.
Information that has well defined meaning is in a form that
machines can understand, rather than simply display.
Machine understandable documents does not imply some
magical artificial intelligence allowing machines to comprehend
human speech, rather it relies solely on the machine's ability
to solve well defined problems by performing well
defined operations on well defined data.
or, another way to think about it...
The Semantic Web is a mesh of information linked up in such
a way as to be easily processable by machines, on a global
scale.
You can think of it as being an efficient way of
representing data on the World Wide Web, or as a globally
linked database.
Overview
1. Web resources
2. Non-Web resources
2.1 Physical objects
- Cars, people, houses, etc.
2.2 Abstract concepts
- Sizes, colors, verbs, "love", etc.
- "Creator" (e.g., the creator of a document)
- "Location"
- "Airline reservation"
- "Airline reservation service"
Unambiguously Identifying Web Resources
Solution (trivial): URLs
- http://www.example.org/index.html
Unambiguously Identifying Physical Objects
Many human systems:
- Vehicle Identification Numbers (VIN)
- Product serial numbers
- UPC product codes
- Employee numbers
- Etc.
Problems:
- Too many formats
- Most are not global in scope
Solution: Convert to URIs
- http://www.example.com/employeeid/85740
Unambiguously Identifying Abstract Concepts
Solution: Use URIs
Problem: Which URIs?
- Need to agree on common vocabulary
- Helpful if communities develop naming policies
Solution: Ontology
Ontology
- "Formal description of concepts and their
relationships"
In other words:
-
Vocabulary of terms
- "book", "publication", "derivative", "right"
-
And their relationships
- "book is-a-kind-of publication"
- "derivative is-a-kind-of right"
Dublin Core
- Dublin Core
- One well-known ontology
-
Defines 15 basic terms useful for discovery:
- "title", "author/creator", "subject",
"publisher"
-
Each term unambiguously identified by URI
- http://purl.org/dc/elements/1.1/creator
One Global Ontology?
No. Not realistic.
- Multiple ontologies will co-exist
- Often specialized for problem domain
But:
- Can be merged later
- "Popularity contest"
- URIs => No danger of accidentally using the same name
for different concepts
Does an Ontology Really Define Meaning?
No
- Meaning is determined by use.
- But an ontology helps
Example: RFC
2119
- Defines terms "MUST", "SHOULD", "MAY", etc.
- RFC 2119 could be ambiguous
- But its adoption in our specs is still helpful
Ontologies and Legal Community
- What does
<foo:Plantiff> mean?
- Is
<foo:Plaintiff> the same as
<bar:Plaintiff> Is?
- Is
<foo:Plaintiff> a kind of
<legal:Entity> Is?
- Web application must agree on semantics
- Ontologies can help
Example of Unambiguous Identification
To say: "Web page foo.html was created
by John Smith"
Need to unambiguously identify 3 things:
- Web page:
http://www.example.org/foo.html
- "was created by":
http://purl.org/dc/elements/1.1/creator
- "John Smith":
http://www.example.org/staffid/85740
Summary
Adding meaning to web, making the web more "semantic"
-
Identifying the key problems:
- Ambiguity
- Complexity of information formats
-
Solving the ambiguity problem
Problem 2: Complexity of Information Formats
-
Web pages use complex information formats:
- English grammar, page layout, etc.
- Easy for human to parse / understand
- Hard for machine to parse / "understand"
Example: "Time flies like an arrow"
- How to parse?
- Which is Subject? Verb?
Object?
Need a common, machine-processible information format
Important Characteristics for a Machine-Processible
Format
- Scalable (the whole Web!)
-
General
- Allow any info to be expressed
-
Extremely flexible:
-
Allow new data to be added
- From any source
- Without breaking existing data/systems
- Allow any kind of query
- Easily combine/join data in new ways
A solution: RDF
What Is RDF?
-
"Resource Description Framework"
- (But think: "Relational
Data Format")
- W3C
Recommendation
- Language for making statements about things
-
Primarily for metadata
- Author, title, subject, date-of-last-access
- Can be used for any kind of statements
- Has XML syntax: "RDF/XML"
- Uses (simplified, explicit) entity-relational data
model
Why a Relational Data Model?
- 30+ years of database history
- Hierarchical before ~1975
- Relational since ~1975
- Relational model is remarkably flexible
-
Supports graceful evolution
- Change => Add another table
- Existing queries are unaffected
-
Easily accommodates new data
- Without affecting existing queries
- Allows data to be easily combined ("joined") in new
ways
Adapting the Relational Model for the Web
- Use URIs as keys
-
Use subject-verb-object triples instead of tables
- (Simplified relational model)
URIs and Database Keys
- How do you unambiguously identify something?
Relational database mantra:
"The key, the whole key, and nothing but the key"
Web mantra:
"The URI, the whole URI, and nothing but the URI"
RDF Triples
- All info expressed as triples:
<subject> <verb> <object>
<subject> <property> <value>
- Simplified relational model
Example Triple
(Not RDF/XML syntax):
http://www.example.org/foo.html |
(Subject) |
http://purl.org/dc/elements/1.1/creator |
(Verb/Property) |
http://www.example.org/staffid/85740 |
(Object/Value) |
Meaning: "Web page foo.html was created
by John Smith"
Representing Relational Data as Triples
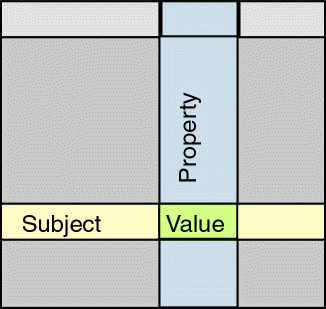
Representing Tables as Triples
Any relational data can be represented as triples
- Row Key --> Subject
- Column --> Verb/Property
- Value --> Value

Table as Collection of Triples
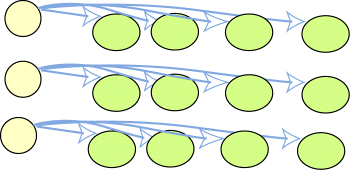
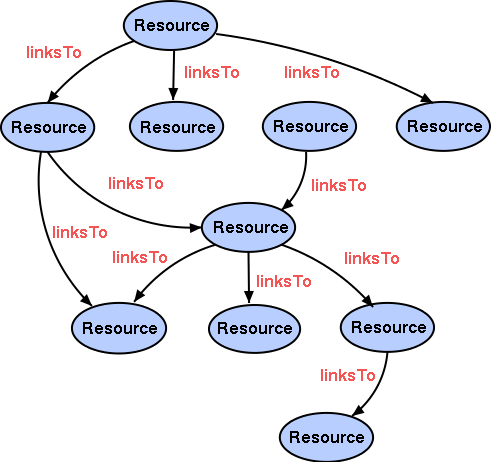
Joining Triples to Create a Graph
- Triples can be viewed as links in a graph
- Equivalent of "joining" in relational database
-
Joining is automatic in RDF, because:
- Nodes are URIs (unambiguous)
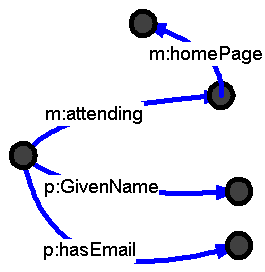
Joining Data from Multiple Sources
Trivial: Same URI => same node.
Application Integration: XML Versus RDF
Summary
Concepts of RDF
- What is RDF?
- RDF as relational data
- RDF graphs
- RDF and application integration
SECTION 5: Conclusions, Example Applications and
Demo
Solutions to Key Problems
Goal: "Machine processible information"
-
Problem 1: Ambiguity
- Solution: URIs (and ontologies)
-
Problem 2: Complexity of information formats
- Solution: RDF (or mappable to RDF)
Purpose: Find, share and combine
information more easily
What information could be machine processible?
Ideally: All Web data. (Not realistic)
| Consumer |
Producer |
Solution |
| Machine |
Machine |
Easy. Use RDF/mappable* |
| Machine |
Human |
Easy. Use RDF/mappable* |
| Human |
Machine |
Easy. Include RDF/mappable* with human
format |
| Human |
Human |
Harder: Must manually add RDF/mappable*,
requiring:
- Expertise
- Tools (e.g., in HTML editors), or
- AI
|
*"RDF/mappable" = RDF or RDF-mappable
Where to put machine-processible information?
A: Several possibilities:
- Mixed in with xhtml
- In HTTP headers
- In linked documents
- In databases (e.g., search engines)
- Etc.
Example RDF / Semantic Web Applications
Demo of TAP Semantic Search
W3C's Current Search
Search
W3C's Semantic
Search Service
What I Hoped to Achieve
-
Convey basics of Semantic Web
- Purpose
- Reasoning behind it
- (Fill in gaps)
- Purpose of ontologies
- Purpose of RDF
Creative Commons
RDF Legal Dictionaries
http://rdf.lexml.de/ Open Source Development of an RDF
Dictionary Open source development of a multi-lingual and
multi-jurisdictional RDF Dictionary for the legal world.
Legal Citations
Example...
Example
Caveat: Everything i learned from legal citations I learned from
http://philip.greenspun.com/politics/litigation/reading-cites.html
-- the promise of the "semantic web" is automating
(parts of) social protocols, and those social protocols
are often grounded in law
-- there are established conventions for legal citations
-- more and more legal proceedings are published via the web
all the time
-- those legal proceedings are often copied in many places,
and there's no recognized canonical URI for them, so
-- caches don't help
-- my browser doesn't tell me I've been there before
-- etc.
So... some ideas...
-- an RDF schema for legal citations
(probably one schema per jurisdiction, with lots of
sharing and sublcassing)
-- a corresponding HTML form for each jurisdiction that, in effect,
allows you to compute the address of a document
To take the example from philg's tutorial:
Ford Motor Co. v. Lonon, 2117 Tenn 400, 398 S.W.2d 240 (1966)
Perhaps in RDF, I'd spell that:
<rdf:Description rdf:about = "uri">
i <plaintiff>Ford Motor Co.</plaintiff>
<defendant>Lonon</defendant>
<volume>2117</volume>
<jurisdiction>Tenn</jurisdiction>
<page>400</page>
</rdf:Description>