W3C | TAG | Previous: 11 Nov teleconf | Next: 25 Nov teleconf
Minutes of 18 Nov 2002 TAG face-to-face meeting
Nearby: Teleconference details · issues list · www-tag archive
1. Administrative
- Roll call: SW (Chair), TBL, TB, NW, DO, DC (Afternoon), CL, PC, IJ
(scribe), Martin Duerst (Morning). Regrets: RF
- Did not yet accept 4 Nov
minutes
- Accepted this agenda
- Next meeting: 25 Nov teleconf.
- No meetings: 23, 30 December.
1.1 Completed actions
- Action SW, TB, DO: Send slides for AC discussion to TAG for review.
- Publish HTML slides submitted by SW, TB, DO. TAG should comment on
draft slide presentations on the TAG mailing list.
- Submit three items to the Comm Team for the AC: TAG summary, SW's
summary of XLink, Arch Doc.
1.2 February meeting
The TAG may reschedule its February meeting (both days and location).
Follow-up on the TAG list.
1.3 Presentation at W3C AC meeting
The TAG reviewed slides for its presentation at the W3C Advisory Committee
meeting (Nov 2002).
2. Technical
- IRIEverywhere-27
- See reply
from Paul Grosso asking the TAG to address this issue
quickly.
- Status of URIEquivalence-15. Relation
to Character Model of the Web (chapter 4)? See text from TimBL on URI
canonicalization and email
from Martin in particular. See more comments
from Martin.
- CL 2002/08/30: Ask Martin Duerst for suggestions for good practice
regarding URI canonicalization issues, such as %7E v. &7e and
suggested use of lower case. At 16
Sep meeting, CL reports pending; action to send URI to message to
TAG.
- [Ian]
- SW: Time for a finding?
TB: I think we are ready for a finding on matching semantics.
- CL: There are tough issues (e.g., proxy caches, etags) in different
communities. I'd like to declare some issues out of scope so we can get
quick agreement on smaller sets.
- TBL: I think we need to explain where IRIs fit in architecturally. My
understanding is that there's a URI space and an IRI space, and a
function that maps from one to the other. We can talk about equality
among URIs, and we can talk about mappings from IRI -> URI. We need
to point out that IRIs are a way to talk about URIs (like relative URIs
map to absolute ones).
- TBL: We are not changing the URI space by talking about IRIs. There
is not a function from URIs to IRIs.
- CL: Why would someone want to go from URIs to IRIs?
- MD: Sometimes you go to URIs to early.
- CL: But that's a repair issue.
- TBL: People *will* want to display URIs in IRI syntax.
- [Chris]
- rrsagent, pointer?
- [RRSAgent]
- See http://www.w3.org/2002/11/18-tagmem-irc#T14-44-48
- [Ian]
- MD: If you define some URIs to be very strictly equivalent in all
cases (including namespace matching) it makes it natural to define some
IRIs to be equivalent to those URIs in all cases. Suppose U1 is
equivalent to U2. It makes a lot of sense to say that I3 is always
equivalent to them.
- TB: It's not, unless you fix the % escape case matching.
- [Chris]
- I suspected they were not equivalent, but wanted to be clear
- [Ian]
- TBL: If IRIs stand for URIs, then comparing IRIs doesn't make sense.
You always talk about equivalence of URIs.: I advise you strongly to
not redefine HTTP and MAILTO for IRIs...
- CL: To compare I1 and I2, you have to convert them and compare U1 and
U2.
- [Discussion about escaping]
- TBL: We can give you a set of circumstances under which you can know
that two URIs are the same. You know that if URIs are byte-by-byte
equivalent, they are the same. We can add to that canonicalization of
%7e and %7E. There are other things you can know from other specs that
lead to equivalence. We should say "don't rely on that other
stuff".
- [Chris]
- CL was asking a question of TimBL not stating a position
- [Ian]
- TBL: We suggest you use the same byte sequence for the same URI.:
Basically, don't be clever.
TB: Three ways to test URI equivalence:
- "Schema-specific canonicalization and comparison" (e.g., HTTP
URIs with normalizing on "..").
- "RFC2396-based
canonicalization". (e.g., maximum canonicalization, or lightweight
canonicalization such as canonicalization of hex escapes)
- Compare ASCII character
values.
- TB: All of these are potentially reasonable (though (c) is most
questionable). The namespace Rec says "character by character"
comparison, so there's some ambiguity. In any sane universe %7e and %7E
are the same character. At the very least, we should document the
multiple levels of comparision, and document the application contexts
where it would be reasonable to do these things. And we strongly
recommend that specs be entirely specific about what they require.
- TBL: NO! URI equivalence is not spec-specific. Equivalence is not a
property of other specs.
- TB: You can't make the judgment calls go away. It's perfectly ok to
not be sensitive to HTTP-specific issues when you're dealing with
general URIs.
- SW: Different degrees of "equivalence". There are many equivalence
relationships.
- TBL: String identity is the highest form of equivalence in our
context. If you have string identity, it implies every other form of
equivalence. Expanding circles are: ascii string THEN %7e <=> ~
THEN %7e <=> %7E THEN ".." and "." THEN HTTP/DNS THEN SMTP, etc.
...
- [Chris]
- <foo bar="HelloWorld"/>
- <foo bar="HelloWorld"/>
- <foo bar="Hello&dubya;orld"/>
- [Ian]
- TB: I think most appications would throw on the floor and xml doc
with a namespace with W3.ORG in uppercase.
- CL: If the value of bar is "any URI", are those three the same? I
think so, since they are the same strings after XML processing.
- [Chris]
- after xml parsing al three are the safe and will match under option 3
- [Unanimous]
- [Ian]
- IJ: Should the TAG say "Do up to and including level X?"
- TBL: Since practice varies we should not tell people they can rely on
level 3.
- TB: But we could tell people for future practice to do a particular
level.
- [Chris]
- [Discussion on 2396 and whether it does foo/../bar
canonicalization]
- TBL: relative uris require that /../ must be equivalent to /
- SW: want to see this explicit
- TB: RF is fixing this we believe
- [timbl]
- TBL: RFC2396 dioes indeed not say that xxx/./yyy is equivalnet to
xxx/yyy fopr any xxx and yyy. However, the only tenable situation is
that they are equivalent. because we require that any URI can be
relative-ized and absolute-ized back to its original. That is an
(unspoken) axiom.
- When you relative-ize things and re-absolutize then, you cannot
distinguih between the two, and so they HAVE to be equivalent. The URI
spec should say that.
- Resolved: unanimously (except for IJ,
who stepped out of the room).
- [Ian]
- TB summarizing:
- we should talk about mapping from IRIs to URIs and URI-based
equivalence testing. Show the Venn diagram of URI comparison
levels.
- We may have agremeent about levels of Venn diagram that specs
should say.
- Explain drawbacks of doing different levels.
- [Chris]
- Should also indicate strengths and drawbacks of different choices
- [Ian]
- IJ: What does this mean for XML Namespaces? What story would you
tell?
- TB: I think it would be helpful to tell the core group which level to
use. Meanwhile, I don't think we can say when to use IRIs since they're
not baked yet.
- IJ: But we can tell them how they fit in./
- CL: I think we can respond to initial query. We can tell people to
plan on using IRIs when they're done.: We can tell people to design
specs to use URIs, but to prepare for the introduction of IRIs. Tell
them how to not paint themselves into a corner.
- NW: The XML Core WG is trying to decide what to put into the next
version of the namespaces spec. They have a capsule summary of what
IRIs are, to be replaced by a ref to the IRI spec later. I can't tell
from the discussion here whether we are telling the core WG if it's ok
to do what they're doing.
- Initial
questions from Jonathan Marsh
- Action TB: Write a finding for
URIEquivalence-15 on IRI relation to URI, different levels of
equivalence.
- TBL: If a spec transitions from URIs to IRIs, new documents will
break old software (which used to only handle URIs). Typically, what
happens is that user agents evolve but authors SHOULD NOT use the new
stuff for a while. We could tell people that it's ok for the software
to accept IRIs but authors should not use them for a while.
- SW: I think we need a thought-out transition plan.
- CL: "anyURI" in the XML Schema spec is already IRI-ready.
- IJ: Specs should not handle this differently. Can we give them text
for their documents?
- MD: Some specs may have to do this differently.
- NW: People use "stringcmp" to compare namespace strings.
- SW: What should our response to Jonathan Marsh be?
- TB proposal:
- We view IRI activity with favor.
- Software should prepare for IRIs
- IRI spec not done, practices such as XML 1.0 sys id seem to be
reasonable, but they need to figure out how to bring themselves
into sync with IRIs when they become available.
- MD: I agree that developers need to think about the transition
issue.
- TBL: We can't tell people what's best to do for their applications
(since so many variables, policies, etc.). We can describe the
framework.
- CL: We need to explain the risk of not moving to IRIs: proprietary
approaches if IRIs not adopted.
- PC: XML Query has an "anyURI-equal" funtion. Described as being on a
"codepoint-by-codepoint" basis.
- PC: If you are looking for behavior of anyURI, don't look in schema,
look in query. See XQuery definition
of an op:anyURI-equal function See XQuery definition
of an op-resolve-uri function.
- [timbl]
- TB, please point to the layer of the onion which corresponds to
schema:anyURI.Equal()
- [Ian]
- PC: See Functions and Operators.
- NW: For namespaces 1.1, the backwards-compatibility issue already
exists. It's safe to say "they can be IRIs"; breaking software is
probably not a huge issue yet.
- TBL proposal:
- Specs (e.g., an XML application) that use Unicode should call out
IRIs.
- Refer to the upcoming IRI spec, which we hope will stabilize
soon.
- Warn people that authors should stick to URIs during a transition
period, that will vary according to their transition period.
- CL: Namespace 1.1 should say that a particular usage is being brought
up to date with other usage.
- TBL: We need to write down the axioms: if you take a URI, make it
relative w.r.t. a base URI, then make it absolute w.r.t. the same base
URI, you get the same starting URI...
- CL: I think the finding should explain pros and cons as we said
above, what people with old specs should do, and what people with new
specs should do.
- Action MD: Write up text about
IRIEverywhere-27 for spec writers to include in their spec.
- Action CL: Write up finding for
IRIEverywhere-27 (from TB and TBL, a/b/c), to include MD's text.
See also: findings.
- Findings in progress:
- deepLinking-25
- TB 2002/09/09: Revise "Deep
Linking" in light of 9 Sep
minutes. Status of finding?
- Arch Doc
- Continued action CL 2002/09/25: Redraft section 3, incorporating
CL's existing text and TB's structural proposal (see minutes of 25 Sep ftf
meeting on formats).
- Completed action NW 2002/09/25: Write some text for a section on
namespaces (docs at namespace URIs, use of RDDL-like thing). Done
- Continued action DC 2002/11/04: Review "Meaning" to
see if there's any part of self-describing Web for the arch doc.
See 15 November
2002 Architecture Document. See some comments
from Tim Bray.
- [Ian]
- TB: In the principles, the distinction between "constraints",
"practices", and "principles" still needs work. Perhaps we can move
- simply to "practices" and "principles" - it's really unclear that
"Use URIs" is really different in its nature from a bunch of things
labeled "practices".
- [Some disagreement from CL, TBL on this]
- TB: The principles in 2.2.4 and 2.2.5 are really the same principle.
The explanatory text in 2.2.5 is just a rehash of the Moby Dick
example.
- IJ: I can explain why this was done: I have been trying to
distinguish case of "representations that vary inconsistently" and
"meaning of use" discussions.
- TBL: Previous draft for me was too vague. Too general to say that
"ambiguity is a bad thing". To say that a mailto URI identifies a book
is wrong. The RFC says different. To couch that as ambiguity is wrong.
One spec owns the definition.
- TB: In the real world, the marketing dept and the IT dept may use
URIs internally differently.
- SW: What about namespace names. We are expecting to put documents at
the end of the namespace URI. In RDF, how do I make assertions about
the document and assertions about the namespace.
- TBL: You have to be able to deal with the different levels.
- TB summarizing:
- We agree that ambiguity is bad.
- When dealing with these things, you follow specs (e.g., don't use
mailto URIs to identify things other than mailboxes).
- SW: The generic statement is "follows specs".
- IJ: Please confirm that there is some authoritative meaning; I can
only understand ambiguity w.r.t. some reference.
- TB: The arch of the web talks about resources and representations.:
2.2.4 as written is ok. It implies inconsistency in identity of
resource. The other issue is that using the web in a way that goes
against specs is wrong.
- IJ: You can use mailto uris to talk about mailboxes. I presume you
can also use http URIs.
- TBL: Not to refer mailboxes as defined by RFC 2368
- TB: Ambiguity is bad, on server or client. Don't fly in the face of
specs.
- TBL: We need to also highlight *design choices* in the architecture
document.
- TB: Two other suggestions: Arguing about the range of URIs will not
be useful right now. I have some proposals for sections 3 and 4.
- DO: I think we haven't resolved yet what are the components of this
document (constraints, principles, etc.).
- [Chris]
- 3.4 third list item "Allow for Web-wide linking, not just internal
document linking." I would like to discuss that as low hanging
fruit.
- [Ian]
- Discussion ofproposals
from Tim Bray.
- IJ: I am not currently working on a "model" that fits together
constraints, principles, etc. Too hard to rip up the document at this
time.
- PC: I think a glossary of those terms would be useful.
- IJ: The terms I had listed were: constraint, principle, design
choice, good practice, required property.
- TB: Sections 3 and 4 have been languishing. We should just start
putting in nuggets and then fill in with language around them.
- Proposed CP1 "When designing a data format to be used in
representing Web Resources, the use of XML should be considered
carefully. - some issues concerning XML pros and cons, - refer to IETF
'Guidelines
for the Use of XML within IETF Protocols'."
- CL: That document does describe pros and cons.
- IJ: Add XML Accessibility
Guidelines for use of XML in protocols doesn't talk about
accessibility.
- Action IJ: Send notes to TAG with
comments on using xml.
- Resolved: Add CP1 to spec.
- Proposed CP3 "When specifying the use of URIs, designers SHOULD
NOT constrain the
- use of URI schemes."
- TBL: In some constrained applications, you may want to e.g.,
constrain to some class of URNs.
- CL: What about something like "You must support the HTTP protocol on
this element, and may support others".
- TBL: Yes, that's ok.
- [Chris]
- Except for phones that haver no http stack?
- [Ian]
- Resolved: Add CP2 to spec. Provide a
counter-example.
- Proposed CP3: "When using XML, designers SHOULD NOT introduce
syntax constraints beyond those involved in the definition of
XML."
- CL: Different specs impose additional syntactic constraints (e.g.,
namespaces).
- TB: E.g., what SOAP did about not having an internal subset is wrong.
SOAP imposes a severe cost (you can't use an off-the-shelf XML parser).
You can't enforce the SOAP constraints by using off-the-shelf
products.
- DO: I disagree with the principle.
- TB: There's a big difference between profiling, and saying "you can
use single quotes only but not double quotes".
- Resolved: CP3 rejected as proposed.
- Proposed CP4: "XML-based languages MUST be given a namespace name
and the elements of the language MUST be placed in that namespace.
Designers SHOULD make available a representation of the namespace which
is human-readable and SHOULD make available a representation which is a
machine-readable directory of resources which are related to that
namesapce."
- Amendment: "XML-based languages for widespread common use MUST be
given a namespace name and the elements of the language MUST be placed
in that namespace."
- PC: What about data types and functions?
- TB: There's room for argument about things other than elements; there
are other design choices.
- PC: An XML-based language might have other components. Does the arch
doc not need to make statements about those other components?
- TB: XML namespaces only refers to elements and attributes, not other
types of things.
- Amendment: "XML-based languages for widespread common use MUST be
given an XML namespace name and the elements of the language MUST be
placed in that namespace."
- TBL: I agree with TB's more specialized statement, but I think that
important resources such as those functions and operators need to be
identifiable by URI.
- [Discussion that TAG has not yet agreed on all of second sentence
of CP4.]
- Resolved: Accept "XML-based languages
for widespread common use MUST be given an XML namespace name and the
elements of the language MUST be placed in that namespace."
- SW: Can it draw on elements from other languages?
- TB: If you important elements from another language, that's fine.
- TBL Proposed: "If you are designing and XML language, in which the
required functionality is available from elements in another namespace,
there is benefit from the reuse those elements."
- CL: There's a problem of content types.
- General agreement for a statement encouraging the reuse of
previously defined elements where appropriate.
- CL: I had wanted style properties to be in a namespace....
- TB: CL, I suggest you write down a principle.
- Proposed CP5: " For languages whose contents are intended for
rendering to humans, the repertoire of formatting semantics SHOULD be
consistent across the universe of W3C recomnmendations."
- Resolved: Accept CP5, with examples
(e.g., style sheets). Link to relevant finding (and similarly for other
of these proposals).
- Proposed CP6: "When designing a language that includes linking or
hypertext functionality, designers SHOULD design that functionality so
it supports Web-side rather than merely local linking."
- CL: About CP6 - in SVG you can point from a fill to a gradient. We
could have made this an idref, but we made it a link so you can reuse
gradients.
- TB: Another way to say this is "Don't use IDREF"....
- DO: In SOAP, they use ID and IDREF.
- NW: Does anybody here disagree with CP6?
- Resolved: Accept CP6.
- Proposed CP7:"Designers of languages which will be used in
resource representations MUST arrange for the registration of an
Internet Media
- Type for that language, and SHOULD consider the recommendations
of RFC3023 in carrying out that registration. This registration MUST
include a specification of the handling of fragment identifiers for
resource representations in the language being designed."
- [TB notes that we have a finding on this.]
- CL: Note that "+xml" does not define fragment semantics.
- TB: I don't think we should rely on default semantics. Be explicit if
you expect to change semantics later.
- DO: Indicate that there is no default fragment identifier semantics
for XML.
- TBL: See RFC3023:
"As of today, no established specifications define identifiers for
XML media types. However, a working draft published by W3C, namely "XML
Pointer Language (XPointer)", attempts to define fragment identifiers
for text/xml and application/xml. The current specification for
XPointer is available athttp://www.w3.org/TR/xptr."
- CL: My worry is not that the spec doesn't say something....
- DO: If XPointer goes to Rec, will RFC3023 be revised?
- TB: Even if XPointer goes to Rec, that doesn't help much. You don't
know what ID elements are unless you have a DTD.... For CP7, the point
is "read RFC3023 and think about it."
- Action CL: Incorporate resolutions above
into a proposal for chapter 3. [Scribe presumes this supersedes
previous action from 2002/09/25]
LUNCH
DC arrives.
- [RRSAgent]
- See http://www.w3.org/2002/11/18-tagmem-irc#T18-32-01
- [Ian]
- Resolved: Accept CP7 with language
about warning about no default meaning for frag ids. [See below for
amendment.]
- DC: WebOnt WG is currently wondering what media type to use. Owl? I
conclude that application/rdf+xml is the right thing
- TB: You should arrange for the registration "unless one existst that
you can use."
- [Question: "What MIME type should I use?"]
- TBL: If you know that the XML app is going to dispatch on the root
element, you can use text/xml with impunity. RF pointed out that for
the infrastructure, it's useful for, e.g., SVG, to have its own mime
type. We agreed that it's better to dispatch on the mime type.
- [Chris]
- ... where the best choice is an existing media type
- [Ian]
- DC: I think that CP7 will lead to more questions from WGs.
- TB: I think it's useful to say that languages at W3C should have mime
types unless there's really a good reason not to.l
- Resolved: In CP7, say "SHOULD arrange"
instead of "MUST arrange".
- Proposed CP8: "Designers of languages which are to be
interchanged on the Web MUST include a discussion of error-handling,
with specific recommendations on the correct behavior upon detection of
certain classes of errors. - example classes: XML well-formedness vs.
semantic brokenness (eg SVG circle with negative radius)"
- CL: SVG spec can't revise error handling of XML spec, though.
- DC: What about general principle about being liberal in what you
accept and conservative in what you produce?
- CL: No.
- DC: Then I object to this point.
- TB: RFC3023
includes some discussion of this.
- [DanC]
- The word "liberal" does not occur in RFC3023.
- [Ian]
- DC and CL agree that the liberal/conservative Internet principle
should be mentioned because IT IS NOT universal.
- [Chris]
- "Forbid working around xml well-formedness"
- [Ian]
- IJ: I find CP8 too broad.
- DC: No, there's something more basic: Don't silently throw away error
messages.
- TBL: It only makes sense to define processing where the protocol
gives you some guarantee through the processing.
- CL: SVG has error-handling.
- TB: I think W3C specs shouldn't advance if they don't discuss
error-handling.
- DC: To me, the core principle is about evolvability or
scalability.
- Resolved: CP8 rejected as proposed.
2.3 RDDL, namespaceDocument-8
- See 8 Nov 2002
version of RDDL from TB and Jonathan Borden and issue namespaceDocument-8.
[Ian]
- TB: RDDL goes back several years. Some principles: (1) be
human-readable (2) be able to find style sheets and schemas and other
stuff. Need metadata: (1) purpose and (2) nature. I should be able to
say "Get me an xml schema" and use the metadata in the RDDL document to
find one (or one from several, according to additional purpose or
nature constraints). Natures and purposes are URIs. nature->
xlink:role, purpose->xlink:arcrole
- Some disputes about that choice. I created a RDDL in RDF draft. But
some people pointed out that this was done in a way that wasn't
kosher.
- [Chris]
- this is an ongoing discussion n xml dev
- what should we do?
- already committed to write a note, using rdddl, could have the xlink
encoding or the rdf
- in the latter case, lots more discussion needed
- or use another RDDL namespace
- first draft should do all three and discuss
- dc: use cases where this would help?
- tb: ms office 11 stores everything as xml, it is al well formed and
uses namespaces heavily
- also, stop using urns, use http instead and point to persistent urls
and point to schemas
- RDDL would be handy for this
- point to stylesheets, .net etc etc
- dc: why not point to these from the schema?
- cl: same reason as not pointing to the schema from the .net everyone
wants to be top
- so a neutral, easy to parste format to point to these
- dc: why mix them up
- tb: because the one url serves this
- dc, tbl: use coneg
- tbl: or put in html, advantage is mixomg metadata and html
- tbl; many sites do not do coneg anyway
- [TBray]
- also many people who publish to webservers don't have control of the
conneg settings on the server
- [PaulC]
- Latest Q&A on MS
Office 11 XML support.
- [Chris]
- cl: cause for concern of using a multi-namespace xml design in a
system (html browser) that is not xml
- dc: html wg should be part of the design
- skw: who is the authorship of this
- tb: jb and i to publish as a w3c note
- do: wsdl havea requireent to identify the elements that are
semantically interesting. If a document is replicated, it no longer has
a unique uri. Namespace name is consistent across these
representations.
- [DanC]
- reviewing minutes
from Sep ftf, we didn't decide anything about RDDL; we just
actioned TB to propose something.
- [Chris]
- do: Want to use ns name as base uri for these constructs, eg port
type. How to write a uri reference that identifies the port type?
without ids. Don't want to generate ids for all elements. NS name of
the service, append the construct
- [do draws on whiteboard]
- piza delivery web service
- wsdl specifies interface info (astract) and physical deployment
- two pizza shops have to publish at different urls
- do: so .... multiple users of one wsdl file, all clients have the
same instance
- no single master url for this document
- this is the 'locally stored copy' issue
- only common thing is the namespace url of the service
- they did GET copies
- just, not every time they want a new pizza
- [DanC]
- er... he said the didn't. or at least: I heard that.
- [Chris]
- do: so they want a wsdl-specific xpointer scheme - but that depends
on the media type, so we cant use this inside a xhtml document in
there
- [DanC]
- (it's sooo frustrating paying the cost of not just using RDF)
- [Chris]
- so need to dereference through the rddl document to their scheme
- dc: ok I see the problem
- tbl: not a problem unless you use html. RDF uses barenames not
xpointer schemes, but also appends onto namespace names, but keeps the
same ns name for all the multiple copies
- [Ian]
- TBL: There's a solution - say that for HTML elements, # refers to
element, but for WSDL, refers to a real-life thing.
- [Chris]
- skw .wsdl means you could have a separate media type
- dc: but rddl in the middle would break that connection
- [Ian]
- DO: If we go down RDDL path, we need to define frag id semantics.
- [Chris]
- tb: he wants t point into his rddl doc using his xpointer scheme
- cl; ok, but that means he can only point to wsdl documents
- [dc writes on whiteboard]
- dc: schema for html block elements. Schema for p, p extends block,
etc.
- urlofdoc#p
- no, because urlofdoc#style
- is that the style elemnt or the style attribute?
- xptr can point into this
- RDF answer is to ensure its a directed labelled graph
- then, turn the crank and get the syntax
- pc: does not solve the anonymous types issue
- nw: nun ensures that all the anonymous types have distinct uris
- dc: so now we see the cost of wsdl not doing this
- do: referring to wsdl issue 120 about unique adressability was raised
by SW folks. WSDL has requirements above the requirements of SW.
- [Roy]
- I'm at ApacheCon in Las Vegas. No phone, but will hang out on IRC if
there are any questions. [No opinion on RDDL]
- [PaulC]
- XML
Schema Nun proposal (W3C member only)
- [Ian]
- Specific example from Jonathan Borden:
<rddl:resource ID="XSD">
<rddl:title>XML Schema</rddl:title>
<rddl:nature resource="http://www.w3.org/2001/XMLSchema"/>
<rddl:purpose resource="http://www.rddl.org/purposes#schema-validation"/>
<rddl:related resource="http://example.org/L.xsd"/>
<rddl:prose>
<p>An XML Schema for the L language .</p>
</rddl:prose>
</rddl:resource>
TB: I want to be able to reach into a RDDL document and find
"purpose: validation". I want to be able to reach into a RDDL document
and find "purpose of validation".
- DC: In RDF you would say "purposes:validation". Nature and purpose
are not symmetric.
- TBL: The community mismodeled nature and purpose.
- TB: Whenever you put in something more complicated than http://lists.xml.org/archives/xml-dev/200211/msg00719.html,
people get unhappy.
- [DanC]
- <rddl:resource ID="XSD">
- <rddl:title>XML Schema</rddl:title>
- <rddl:nature resource="http://www.w3.org/2001/XMLSchema"/>
- <p:schema-validation resource="http://example.org/L.xsd"/>
- <rddl:prose parseType="Literal">
- <p>An XML Schema for the L language .</p>
- </rddl:prose>
- </rddl:resource>
- [Ian]
- PC: Schema WG has rejected using namespace name for locating frag
ids. Sounds like multiple WGs tackling same problem with different
solutions.
- [PaulC]
- XML
Schema Designator of Schema (Member only)
- [DanC]
- p is http://www.rddl.org/purposes#
- [Ian]
- TB: Jonathan suggested what DC suggested.
- DC: Problem with the RDDL approach is that I can't cut and paste
directory entries (or merge them).
- [DanC]
- The "implicit" design contradicts the "anyone can say anything about
anything" principle of RDF
- [Ian]
- CL: But we *are* talking about namespace docs, so the namespace URI
is implicit.
- DC: But the namespace doc is a common place to look for it. It
doesn't mean that you shouldn't be able to copy it and preserve the
meaning. You could change "id" to "about' and put the namespace
there.
- PC: Perhaps we need some more time to discuss this.
- TB: Note that http://lists.xml.org/archives/xml-dev/200211/msg00719.html
has received a lot of support. We should not make more complicated than
we need. Dan's representation is more accurate.
- NW: If you are using predefined purposes, you could avoid extra
namespace.
- TB: DC's version makes purpose less obvious. RDDL was sold to the
world as having nature and purpose.
- CL: I propose that the first draft show different possible syntaxes,
with their pros and cons.
- PC: I think that the work
done on this by Schema (Member-only) is material to this
discussion.
- TB: For the record, I promoted RDDL as a way to do a 2-field lookup.
I'm not going to be in favor of requiring any bending over backwards to
accomplish this effect.
- [DC proposal]
- Suppose L is a namespace about lunch. Namespace URI:
http://example.com/L. There are two related resources: L.xsd and
L.css.
- TB: L.xsd is a nature (xml schema) and a purpose (for
validation).
- [DC does circles and arrows graph, a facsimile of which
is below. See also SVG and
dot]
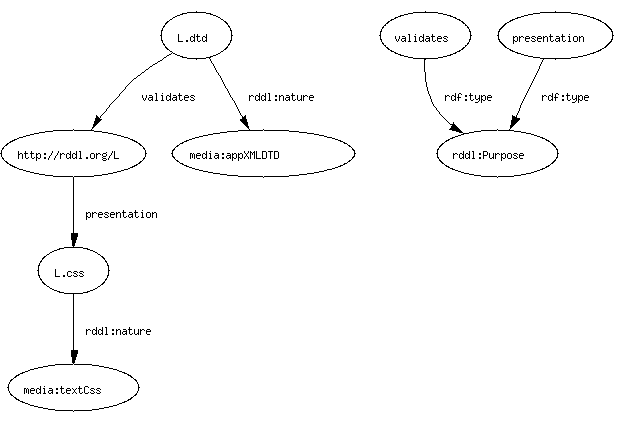
- TB: Add a CSS style sheet as well. Purpose is "Onscreen
presentation". There's a reserved word for that in RDDL... The nature
of the style sheet includes IANA stuff, and more...(Arguably there's a
better way to do this).
- DC: Two resources are related by "purpose".
- TB: Sample application - build a menu of available actions in a RDDL
document. I'll buy DC's graph. However, using RDF syntax I would need
an RDF engine.
- DC: So we need to pick one syntax.
- TBL: We could propose a canonical xml serialization of RDF.
- CL: application/rddl+rdf?
- TB: That's a hard problem, too..
- CL: We have two contradictory principles for W3C specs - you need to
validate v. mixing multiple namespaces.
- TB: I personally think RDDL is important. I think we need to converge
quickly on a suggested right way to do this.
- Action TB: Solicit proposals for what a
namespace doc should look like for the particular case of a namespace
document that refers to a DTD and a style sheet. TB will collate the
responses. TB's solicitation should ask submitters for their own pros
and cons.
- Action NW: Take a stab at indicating pros
and cons for the various designs.
Seeissue
xlinkScope-23.
- [Ian]
PC: What's our next step?
- TBL: I think there's a clear need for a common anchor element in the
XLink namespace.
- NW: Content model problem....
- CL: OBJECT has three URIs and two bases. Can't use xbase.
- TB: Maybe right answer is the summit at the tech plenary
- PC: That may not happen.
- TB: This is pressing. People want multiend links and are hacking
horribly to do this.
- NW: When XLink was done, it was made a little too general.
- TB: See my concrete proposal, with support from Ann Navarro
- [Scribe stops minuting since discussion and scribe a bit
unfocused]
- PC Summarizing some options for moving forward:
- We listen to the AC tomorrow and Weds
- Work on a charter, and send to AC for discussion.
- Wait for special meeting in March (if it happens). But several
people think this is too late.
- NW: I think we should do this sooner rather than later. We should
convene interested parties before Mar 2003.
- DC: We could invite people to our Feb ftf meeting to discuss
this.
- [Chris]
- html, smil, xforms, svg
- Action SW: Create such a special-interest
telcon
The following people committed to attending such as meeting: TB, CL,
NW.
- DC: people who are the right hot people should be there. Docbook
folks, too. Client builders (e.g., Tantek Celik and others). Ask for
attendance by way of the HMTL Coordination Group and the XML
Coordination Group.
- contentPresentation-26
- Action CL 2002/09/24: Draft text on the principle of separation of
content and presentation for the Arch Doc.
- rdfmsQnameUriMapping-6
- The Schema WG is making progress; they will get back to us when
they're done. See XML
Schema thread on this topic.
- uriMediaType-9:
- Action DC 2002/08/30: Write a draft Internet Draft based on this
finding (Deadline 11 Nov). This action probably
subsumes the action on TBL to get a reply from the IETF on the TAG
finding.
- Status of discussions with WSA WG about SOAP/WSDL/GET/Query strings?
Ian Jacobs, for TimBL
Last modified: $Date: 2007/01/11 14:36:56 $