{kind=link}
Author: Dan Brickley (danbri@w3.org)
This document explores some techniques for SOAP data aggregation and testing using the SOAP Encoding Data Model.
To do so, it provides an account of the SOAP Encoding Data Model in terms of edge-labelled graphs, URI references and the XML Namespaces specification. To test this model, it also proposes a mapping of this abstract model to a simple text format for quality assurance and testing for SOAP Encoding implementations. This is compared to existing unit test frameworks for SOAP toolkits, and the application of this approach to data aggregation is demonstrated using an RDF-based object-relational query application. This provides context for a discussion of the goals and technical issues relating to a proposed mapping between the SOAP Encoding Model and W3C's RDF data format.
This document addresses a number of related technology issues; some familiarity with the basics of SOAP, XML Namespaces and RDF is assumed.
TODO:
The SOAP 1.2 specification from W3C's XML Protocol Working Group (XMLP) includes a "SOAP Encoding" framework that can be used to serialize and de-serialize complex data structures in XML. The SOAP Encoding is widely used in Remote Procedure Call (RPC) applications to provide a language and platform-neutral representation of programmatic data structures. SOAP toolkits typically offer object marshalling and unmarshalling facilities which exploit the SOAP Encoding simplify the creation of Web-based applications and services.
This document explores the details of the data model and its wider applicability to Web data and service aggregation. Although typically deployed in a transitory, protocol-oriented (messaging) context, the SOAP encoding is an XML document format (like SVG, XHTML, MathML) in its own right, and may prove useful in non-protocol non-RPC (and non-protocol) contexts. If this is the case, it is important to clarify any subtleties in the specification of the SOAP Encoding Data Model, since the assumptions shared by RPC-oriented applications may not be shared by other users of the specification. To this end, a SOAP Encoding test case format is proposed, based on an alternative non-XML serialization of the SOAP Data Model.
A (tentative) account of the SOAP Encoding Data Model is presented below, followed by a worked example showing the concrete encoding of this data model in XML. The model is presented first, and without examples, to illustrate the difficulty of abstracting an account of the Data Model in isolation from its intended use and XML representation. It may be useful to re-read this section after studying the Encoding examples that follow.
The SOAP Encoding Data Model is a subset of the Directed Labeled Graph (DLG) class of data models. As such it provides a simple type system that is a generalization of common features found in type systems in programming languages, databases and semi-structured data. Edges in the graph are labelled with simple ("locally scoped") string values or ("globally scoped") URI-qualified names corresponding to the XML namespace mechanism. Nodes in the graph are either simple (datatyped) values or represent complex objects that are described by an aggregation of relations (labeled edges) to other values. Node datatyping as represented using URI references (for example to the XML Schema datatypes).
The SOAP Encoding Data Model abstracts away from the details of the referencing mechanisms (such as XML ID/IDREF, URI, XML element containment) that support any particular concrete encoding of a SOAP data graph. SOAP Encoding Data Model instances, regardless of encoding format, can be merged to aggregate the encoded information by folding together the abstract edge-labeled data graphs. Globally scoped (URI-named) edges and nodes provide one of many strategies to support SOAP data model merging. A node in the SOAP Encoding Data Model graph structure is said to be "URI-ref" labelled if it has an type of xsd:URIRef (@@check specs). SOAP graph merging provides one strategy to support Web service composition, by providing a common representation in which information fragments acquired from multiple Web serves can be combined.
The SOAP data model provides an abstract view of XML-encodable data graphs, represented as an unordered set of node-edge-node 3-tuples. XML serializations of the SOAP data model are by necessity ordered. All concrete XML encodings of the SOAP data model must therefore specify the significance of document (Infoset) ordering with respect to the abstract edge-labeled graph model. Within a compound value (complex node), each relation to another node is potentially distinguished by a role name, ordinal or both. In this latter case, the edge name itselfs corresponds to a pair of ordinal and role name. Datatyping information can be reflecting in the abstract graph structure through 'type' edges from literal nodes, with the 'type' pointing from some literal data to a node (typically URI-labelled) that reprsents the datatype of the literal node.
The SOAP data model is consistent with, but does not specify, a number of mechanisms for describing a "DLG Schema" corresponding to meta-information about node and edges types in the SOAP data graph. UML, RDF and other representational formalisms may provide additional information about the node and edge types that occur in a SOAP data model instance. SOAP does not mandate the use of any particular mechanism for this. DLG-schema information can be used to support the concrete serialization of SOAP data graphs into XML, for example by providing information about cardinality or domain and range constraints on (globally scoped) edge types.
The SOAP Encoding Data Model can more easily be presented through the use of examples that show SOAP Encoding deployed in SOAP 1.2 XML protocol messages. The goal of this document is to draw a distinction between SOAP Encoding as typically used and SOAP Encoding as it could be used. So we start with SOAP Encoding as typically used...
The Encoding format represents ideas from a number of contexts, but is most closely alligned with the RPC tradition. It is frequently used to translate programmatic object (instances of Java classes, Perl, C#, Ruby, Python etc.) into a more neutral form for communication to other Web applications. Often these objects will themselves be transitory things, representations of structured information stored in relational or object databases. Since the SOAP Encoding uses XML Schema datatypes, datatyped information can be mapped between database, software and XML representations with relative ease. Most SOAP tools seem to focus on the software side of things rather than directly hooking SOAP Encoding up with the 'raw' information sources (RDBMS etc). (The examples shown here will be elaborated on later to show how SOAP Encoding might have a natural mapping to database structures too.)
These examples are based on some experimental implementation work using the Ruby programming language. As such it is fitting to draw our examples from the Ruby community. The Ruby Application Archive (@@ref) is a Web-accessible listing of software packages for the Ruby language. It is available online as HTML documents, and a SOAP interface is also available, offering a variety of ways to access the data.
Our example takes a single 'record' from the RAA, and shows its representation in Ruby, and in the SOAP Encoding wire format. We begin with the XML form, encoded using the SOAP Data Model Encoding of SOAP 1.2:
So what do these records look like on the wire? Here's a dump from a logged SOAP protocol session (note that we are using SOAP 1.1 not the current 1.2 spec; the basic approach hasn't changed (much?@@)). This is the XML that gets sent through the network (possibly via intermediary SOAP nodes):
(examples/soap-eg1.xml.esc)
<?xml version="1.0" encoding="utf-8" ?>
<env:Envelope xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:env="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<env:Body>
<n2:getInfoFromNameResponse
env:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:n1="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:n2="http://www.ruby-lang.org/xmlns/soap/interface/RAA/0.0.1">
<return xsi:type="n2:Info">
<update xsi:type="xsd:dateTime">2001-06-18T08:43:46Z</update>
<owner xsi:type="n2:Owner">
<email xsi:type="xsd:string">hd@rubylinks.de</email>
<id xsi:type="xsd:string">hd@rubylinks.de-Hans-Dieter Stich</id>
<name xsi:type="xsd:string">Hans-Dieter Stich</name>
</owner>
<product xsi:type="n2:Product">
<download xsi:type="xsd:string">http://www.rubylinks.de/download/ruby-spread-0.1.tar.gz</download>
<homepage xsi:type="xsd:string">http://www.rubylinks.de/</homepage>
<status xsi:type="xsd:string">just started, first alpha release</status>
<description xsi:type="xsd:string">Ruby/Spread is an interface to
the Spread Library at
http://www.spread.org/. Spread is a toolkit and daemon that
provides multicast and group communications support to
applications across local and wide area networks. Spread is
designed to make it easy to write groupware, networked
multimedia, reliable server, and collaborative work
applications.
</description>
<version xsi:type="xsd:string">0.1</version>
<license xsi:type="xsd:string">LGPL</license>
<name xsi:type="xsd:string">Ruby/Spread</name>
</product>
<category xsi:type="n2:Category">
<minor xsi:type="xsd:string">Distributed Communication</minor>
<major xsi:type="xsd:string">Library</major>
</category>
</return>
</n2:getInfoFromNameResponse>
</env:Body>
</env:Envelope>
What happens at the other end, when this XML is received? Some SOAP library turns this Encoding back into objects that a programmer can work with (perhaps manipulate, show to a user, or store in a database, or use in conjunction with other objects/data from elsewhere in the Web. The receiving application needn't be written in the same language as the original service, but the SOAP library will provide some mapping between the Encoding format and a representation that is more convenient to work with. Our example here shows one mapping from the SOAP Encoding Data Model into Ruby classes and objects. SOAP 1.2 facilitates, rather than specifies, such mappings.
This is the data structure we're ultimately interested in. It defines classes and properties, and is implemented using the Ruby-SOAP marshalling system. (@@ref).
Ruby code (@@TODO: get permission to quote this, cite src properly):
module RAA InterfaceNS = "http://www.ruby-lang.org/xmlns/soap/interface/RAA/0.0.1" class Category
include SOAP::Marshallable
@@typeNamespace = InterfaceNS attr_reader :major, :minor def initialize( major, minor = nil )
@major = major
@minor = minor
end def to_s
"#{ @major }/#{ @minor }"
end def ==( rhs )
if @major != rhs.major
false
elsif !@minor or !rhs.minor
true
else
@minor == rhs.minor
end
end
end class Product
include SOAP::Marshallable
@@typeNamespace = InterfaceNS attr_reader :name
attr_accessor :version, :status, :homepage, :download, :license, :description def initialize( name, version = nil, status = nil, homepage = nil, download = nil, license = nil, description = nil )
@name = name
@version = version
@status = status
@homepage = homepage
@download = download
@license = license
@description = description
end
end class Owner
include SOAP::Marshallable
@@typeNamespace = InterfaceNS attr_reader :id
attr_accessor :email, :name def initialize( email, name )
@email = email
@name = name
@id = "#{ @email }-#{ @name }"
end
end class Info
include SOAP::Marshallable
@@typeNamespace = InterfaceNS attr_accessor :category, :product, :owner, :update def initialize( category = nil, product = nil, owner = nil, update = nil )
@category = category
@product = product
@owner = owner
@update = update
end
end Methods = {
'getAllListings' => [ 'Array' ],
'getProductTree' => [ 'Hash' ],
'getInfoFromCategory' => [ 'Array', 'category' ],
'getModifiedInfoSince' => [ 'Array', 'time' ],
'getInfoFromName' => [ 'Info', 'name' ],
}
end
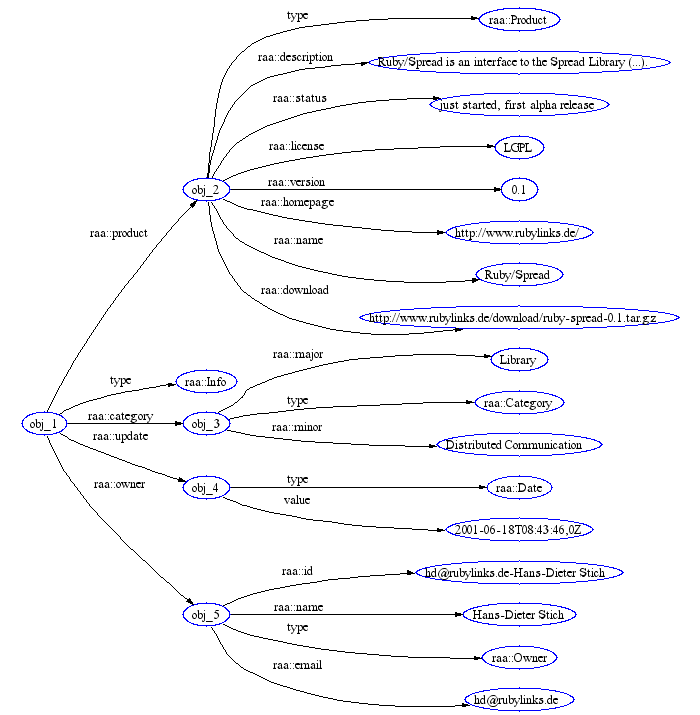
Here is an actual instance of this Ruby class, pretty printed using the Ruby inspect() method, with indenting added to show the structure:
<RAA::Info:0x401eba18
@product
= #<RAA::Product:0x401e9880
@download
="http://www.rubylinks.de/download/ruby-spread-0.1.tar.gz",
@homepage
="http://www.rubylinks.de/",
@description
="Ruby/Spread is an interface to the Spread
Library at http://www.spread.org/. Spread is a toolkit and
daemon that provides multicast and group communications
support to applications across local and wide area
networks. Spread is designed to make it easy to write
groupware, networked multimedia, reliable server, and
collaborative work applications.",
@version="0.1",
@status="just started, first alpha release",
@license="LGPL",
@name="Ruby/Spread"
>,
@category
= #<RAA::Category:0x401e823c
@major="Library",
@minor="Distributed Communication"
>,
@update
= #<Date: 105929806913/43200,0,2299161>,
@owner
=#<RAA::Owner:0x401eaaa0
@id = "hd@rubylinks.de-Hans-Dieter Stich",
@email="hd@rubylinks.de",
@name="Hans-Dieter Stich"
>
>
This is pretty straightforward so far. From a ruby perspective, we have the following classes and properties:
For example, the value of the 'update' property of our RAA:Info object is an object of type RAA:Date; the value of the 'product' property is an object of the (similarly named) class RAA:Product. This code follows the common convention of using initial capitals for class names.
So what do these various representations have in common? Broadly, that the can be thought of as representing data structured in a directed labelled graph, with objects as the nodes, and labelled arcs connecting them. Each triple of node/arc/node that makes up the graph must somehow be exported using XML's syntactic constructs (angle brackets, element names, attribute names, namespaces, datatyping). The role of the SOAP Encoding portion of the specification is exactly that: to account for the detail of how we write down XML descriptions of these graph structures in a way that is well defined and easily processed.
The data model can be seen quite clearly when represented diagrammatically:
This diagram does not include datatyping information, although the full (see below) SE-Triples representation of the graph would include a number of 'type' edges connecting the literal data nodes to nodes that stand for their datatype. The exact treatment of the date node is unmotivated: why did we use a 'value' arc rather than make the content the label for the typed date node? In short, because it looked like the date was a proper class and not just a datatyping convention.
Note that our current example is very simple, since there are no loops in the graph. In the general case SOAP Encoding can be used to serialize arbitrary edge labelled graphs, not just trees. The SOAP Encoding syntax uses XML's ID and IDREF mechanism to achieve this. This maps well onto the needs of RPC applications, since objects may have references to objects that have already been serialized.
For now we focus on a simple case; the full utility of the SOAP Encoding graph Data Model only really becomes apparent when we explore the composition of multiple SOAP-based Web services through merging partial information from multiple sources. For example, consider a second SOAP Web service that contains "white pages" information about the individuals named in the records described by the RAA Web service, or a third SOAP Web service that contained detailed package management information (dependency charts) or documentation for the software packages described by RAA. Web services will only reach their full potential when multiple such services can be cheaply combined across the Web. To achieve this, we need mechanisms such as the SOAP Encoding Data Model that provide a general purpose abstraction into which complementary chunks of data can be mapped.
Discussing the SOAP Encoding Data Model in the abstract is hard, and discussing it in terms of the SOAP 1.2 serialization rules for encoding that model in XML can be misleading. The approach adopted here is to focus on the abstract model, made concrete in a simple test cases format called 'SE-Triples' and illustrated graphically using "node and arc" diagrams.
This has two benefits. Firstly, we acquire a test cases format for SOAP Encoding implementations that, critically, is independent from the details of the RPC applications which have to date been the main users of the syntax. Secondly, we gain an (experimental, not W3C REC-track) graph format that allows us to experiment with mapping SOAP Encoding instance data into other formalisms. This is explored further in the final sections of this document.
Focussing on the abstract graph structure (via the SE-Triples data dump syntax) allows the wider Web community to explore the value of this data format, since it makes no assumptions about intended use. The SOAP Encoding model could be processed through a SOAP-specific API, mapped directly into object/relational database structures, or (as is common) used to create programmatic objects (instances of Java classes etc.). A data format for testing SOAP Encoding implementations needs to be neutral across all such applications, since SOAP itself is intended to provide a neutral platform for integrating these diverse environments.
One technique for ensuring interoperability between applications that use SOAP Encoding is to test that some objects (Java etc) can be turned into XML and reconstructed again. This works pretty well for RPC-oriented applications. The approach explored here is intended to complement that approach, providing a basis for data-oriented applications to test their interpretation of the SOAP Encoding component of SOAP 1.2.
SE-Triples is a simple, line oriented text representation of the abstract data graph. It is based upon the RDF Core WG's 'N-Triples' (@@ref) syntax, which serves a similar role in clarifying the RDF syntax specification and testing the performance of RDF parsers. In this draft, SE-Triples is identical with N-Triples. These may diverge or the mapping may be confirmed, on the basis of feedback from SOAP implmentors.
An SE-Triples document has a tabular structure. Each row (line in a text file) corresponds to a node-edge-node construction in a SOAP Encoding Data Model graph. The three columns stand for the object reference, property type, and actual value for that data fragment. Since all SOAP Encoding instances can be decomposed into object/property/value triples corresponding to this graph structure, we can use simple text files as a test case format for representing the content carried by the SOAP Encoding XML syntax. In practice, there are some complications (which we'll come to later).
Note that the use of the RDF namespace for the edge labels "type" and "value". The first prototype was produced using RDF-based tools, and it wasn't clear which namespace to use for these constructs (XML Schema ns, the SOAP Encoding ns, or RDF's). Since SE-Triples is based on NTriples from RDF Core, we currently use some RDFisms. Our primary goal here is not, however, to map the SOAP Encoding Data Model to RDF's, but to explore the utility of that Data Model and some tools for testing adherence to it. Mapping to RDF (to RDF's graph model, or to specific graph constructs from the RDF world) is a means to an end, not an end in itself.
| Object ID | Property type | Property value |
|---|---|---|
| <_:o1> | <http://example.ruby-language.org/rda-vocab#owner> | <_:o5> . |
| <_:o5> | <http://example.ruby-language.org/rda-vocab#name> | "Hans-Dieter Stich" . |
| <_:o5> | <http://example.ruby-language.org/rda-vocab#email> | "hd@rubylinks.de" . |
| <_:o5> | <http://example.ruby-language.org/rda-vocab#id> | "hd@rubylinks.de-Hans-Dieter Stich" . |
| <_:o5> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://example.ruby-language.org/rda-vocab#Owner> . |
| <_:o1> | <http://example.ruby-language.org/rda-vocab#update> | <_:o4> . |
| <_:o4> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#value> | "2001-06-18T08:43:46,0Z" . |
| <_:o4> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://example.ruby-language.org/rda-vocab#Date> . |
| <_:o1> | <http://example.ruby-language.org/rda-vocab#category> | <_:o3> . |
| <_:o3> | <http://example.ruby-language.org/rda-vocab#minor> | "Distributed Communication" . |
| <_:o3> | <http://example.ruby-language.org/rda-vocab#major> | "Library" . |
| <_:o3> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://example.ruby-language.org/rda-vocab#Category> . |
| <_:o1> | <http://example.ruby-language.org/rda-vocab#product> | <_:o2> . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#name> | "Ruby/Spread" . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#license> | "LGPL" . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#status> | "just started, first alpha release" . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#version> | "0.1" . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#description> | "Ruby/Spread is an interface to the Spread Library at http://www.spread.org/. Spread is a toolkit and daemon that provides multicast and group communications support to applications across local and wide area networks. Spread is designed to make it easy to write groupware, networked multimedia, reliable server, and collaborative work applications." . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#homepage> | "http://www.rubylinks.de/" . |
| <_:o2> | <http://example.ruby-language.org/rda-vocab#download> | "http://www.rubylinks.de/download/ruby-spread-0.1.tar.gz" . |
| <_:o2> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://example.ruby-language.org/rda-vocab#Product> . |
| <_:o1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://example.ruby-language.org/rda-vocab#Info> . |
@@writeme. Axis, soapbuilders etc.
@@writeme. SOAP merging, SOAP Encoding as a data format, hypertext and REST.
@@introduce SQuish as a SOAP Query language. Show loading of this data into SQL, query, results.
There have for some years been discussions about the relationship between SOAP Encoding and RDF, as well as concerning other related representations (UML/XMI, XML Topic Maps, XLink etc.). The goal in this document has been to explore the value we might find in doing so, rather than treating such a mapping as a means to an end. For the SOAP developer community, value can be found through the adoption of an implementation and language neutral test cases format, and from an exploration of the wider applicability of the graph model implicit in the SOAP Encoding. By showing that SOAP Encoding is not just for RPC, some of the concerns recently aired in the 'REST' debates may be addressed. SOAP Encoding documents can be deployed in the Web as documents not just message payload. Alongside RDF/XML, XMI and other formats, they can be parsed into their abstract structure, merged with other relevant data, and queried using simple graph-matching techniques.
If there is value in elaborating (through SE-Triples) on the detail of the SOAP Encoding Data Model, there is probably also some value in providing background on the situation in the RDF community. RDF, like SOAP, provides a graph encoding syntax. Unlike SOAP, this syntax has a "striped" pattern. One cannot read a chunk of RDF data and read all the XML elements as labels for the edges in a graph. Consequently the RDF syntax can be hard to understand, initially. The introduction below was written to provide techniques for XML developers to quickly acquire a basic familiarity with the RDF syntax.
It should also be noted that RDF's original XML syntax was somewhat underspecfied. The 1999 RDF Model and Syntax specification did not make a clear distinction between RDF's abstract data model and its specific encoding in one form of XML. Recent work in the RDF Core WG has begun to address this. The N-Triples test case syntax has been a critical part of this work, and the utility of the approach motivates the advocacy of this same approach for SOAP Encoding. While the SOAP and RDF graph models may differ (we don't know yet), the SE-Triples approach can still be a useful technique for SOAP implementors to explore.
Note: appendix A to this document was originally a separate document. It should probably be reworked here (eg. use the same examples) and perhaps turned into an appendix.
This section provides a brief overview of RDF's standard XML encoding, and the "striping" convention it adopts for encoding DLGs within XML.
Many RDF developers encounter the details of the RDF XML syntax at a relatively late stage. RDF distinguishes carefully between the edge-labeled graph information model and the encoding of this model in XML documents. This allows a lot of work to be done without familiarity with the XML syntax in which RDF is written. Some familiarity with the XML syntax is still valuable, and for developers familiar with XML in general and with the RDF graph model, this knowledge can be acquired fairly easily.
The notion of "striping" is a very useful conceptual tool for understanding RDF/XML: the RDF 1.0 syntax has been informally described as a "striped" graph encoding syntax. Striping is described in more detail below.
Two other tools are also useful when learning RDF/XML: parsers and visualisers. The first such tool was Janne Sareela's SiRPAC; there are now a large number of RDF parsers available, in a variety of programming languages. An RDF parser is a tool that takes an XML encoding ("serialization") of an RDF graph, and returns a textual or programmatic representation of the graph. Playing with an RDF parser such as ARP, the parser used by W3C's RDF Validation Service makes it easy to experiment with RDF/XML files and see the associated node-edge-node triples that constitute the corresponding graph structure.
The other tool that can help an RDF developer get to grips with the syntax is GraphViz, or one of the GraphViz-based RDF visualization tools such as RDFViz. GraphViz is a graph visualisation toolkit. It can take descriptions of (various kinds of) graph and generate reasonably pretty pictures in various image formats. There are now a variety of filters that take the output from an RDF/XML parser and generate .dot input files for GraphViz. This can be incredibly useful when learning the RDF/XML syntax, or debugging RDF content. A GraphViz-based RDF visualizer is now also part of W3C's RDF Validator service.
So, armed with parsers, visualisation tools and the RDF syntax spec, all of which are available from the RDF home page, how can a content-producer get a quick feel for the structure of RDF/XML? The basic concept to understand when looking at the XML syntax is striping. This can give one a handle on the essential organising principle of RDF's XML syntax. It should be noted, however, that this emphasis is slightly contrary to the way the original RDF spec is organised.
To learn how to read and write RDF in XML syntax, you need to feel comfortable with the graph-based information model at the heart of RDF. Objects ('resources') linked together by typed relationships or 'properties'. And you need to be at ease with the way RDF tries to use names in URI syntax wherever possible, to name both resources, their types ('classes') and their attributes and interelationships ('properties'). If you're happy with all that, you'll also need some mental baggage from the XML side of things. RDF graphs are encoded in XML, and this encoding makes use of some features of XML. You need to know about the basic abstract structure of all XML documents: the tree of elements (some decorated with attribute/value pairs), and about the way these are manifested as nested hierachies of opening and closing angle-bracketted "tags" in XML documents. You'll also perhaps have heard of the notion of a well-formed XML document, of 'namespaces', of DTDs, of XML Schemas and various other features. These are all good to know about, but the critical concepts to possess here are the notions of (i) well-formedness, and (ii) XML namespaces, backed up by general comfort with XML's elements/attributes/nesting structure. Having gotten this far, it isn't such a big leap to grasp the basic pattern that underlies the RDF/XML serialization syntax: striping.
An XML syntax for RDF specifies a strategy for encoding the node-edge-node structure that RDF cares about in terms of the (attribute-decorated) element hierarchy that XML cares about. There are a number of ways this can be done. RDF 1.0 adopts a style that we term 'striped'; other conventions have been proposed, but the focus here is on RDF 1.0. The XML syntax needs to map from RDF's URI-named resources, properties and classes ( nodes, edge-types, node types... if you prefer a more visual terminology) into a class of well-formed XML documents. The XML namespace mechanism is used for this. So our main task here is to explain how the node-edge-node structures from RDF become element and attribute structures in XML. To do this, we can focus on the notion of striping and forget some annoying details for now.
disclaimer: not all RDF/XML fits this pattern (but a lot of it does). You could do worse than learn the striping style, and pick up on the variations later. The online validation service is your friend: it checks your syntax, and can generate tabular and graphical views of the graph so you can make sure you're written what you mean to write.
So, this is what we mean about striping.
Consider a graph of nodes, each with a type (ie. category or 'class'), and each having a bunch of named properties (relationships) connecting it to other nodes, which might be simply string-y values, or further nodes that are themselves at the sharp and/or blunt ends of various other edges in the graph. We need to create XML elements (possibly with associated attributes) that stand for these nodes and arcs. RDF's convention for doing this is called striped because, as you look at the XML element nesting structure, elements alternately represent nodes and edges.
Here we're saying, loosly, that "there exists a Person with a name, 'John', and that person 'livesWith' a Person that has a father that is a Person with a name 'Fred' ". That's all our example piece of RDF/XML tells us.
The RDF node-and-edge view of this is shown graphically below. To undestand striping, we need compare the abstract graph structure of RDF to the details of the XML nesting structure, ie. the way some elements are 'inside' (rather than alongside) others.
note: this RDF/XML example is numbered, to
show the levels of XML nesting inside the
rdf:RDF wrapper element.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/rdf-syntax-ns#"
xmlns="http://example.com/some-dlg-schema#">
1:<Person>
2: <name> John </name>
2: <livesWith>
3: <Person>
4: <father>
5: <Person>
6: <name> Fred </name>
5: </Person>
4: </father>
3: </Person>
2: </livesWith>
1:</Person>
</rdf:RDF>
This RDF/XML encodes the graph depicted in the following diagram. Note that the blank nodes indicate resources that were mentioned but not explicitly named with URIs in the XML serialization.
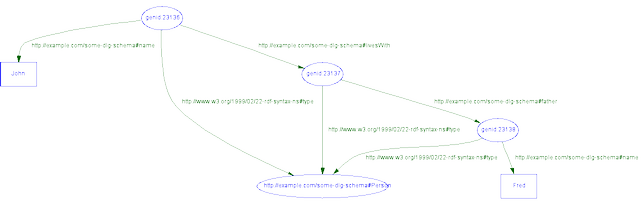
Represented as triples, the graph is as follows:
The RDF graph is a collection of triples that represent statements about the named properties of resources. The 'subject' denotes the resource described; the 'predicate' denotes a property of that resource, and the 'object' indicates a value of that property for the specified resource. Predicates correspond to edges in the graph, and to the even-numbered stripes in the XML document hierarchy shown here.
| Number | Subject | Predicate | Object |
| 1 | genid:23334 | http://example.com/some-dlg-schema#name | John |
| 2 | genid:23336 | http://example.com/some-dlg-schema#name | Fred |
| 3 | genid:23336 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | http://example.com/some-dlg-schema#Person |
| 4 | genid:23335 | http://example.com/some-dlg-schema#father | genid:23336 |
| 5 | genid:23335 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | http://example.com/some-dlg-schema#Person |
| 6 | genid:23334 | http://example.com/some-dlg-schema#livesWith | genid:23335 |
| 7 | genid:23334 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | http://example.com/some-dlg-schema#Person |
The same data, presented in the RDF Core WG's "ntriples" graph dump syntax is written as:
_:j23337 <http://example.com/some-dlg-schema#name> " John " . _:j23339 <http://example.com/some-dlg-schema#name> " Fred " . _:j23339 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.com/some-dlg-schema#Person> . _:j23338 <http://example.com/some-dlg-schema#father> _:j23339 . _:j23338 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.com/some-dlg-schema#Person> . _:j23337 <http://example.com/some-dlg-schema#livesWith> _:j23338 . _:j23337 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://example.com/some-dlg-schema#Person> .
Here is an informal walk-through of the XML document's
structure. The first level of XML elements, our first
occurance of Person, stands for a node (some
specific instance of the type of thing we're calling
'Person'). And then the striping starts. The
next level in, we see two XML elements: one is
'name', the other 'livesWith'.
These stand not for nodes in the graph, but edges. The first
is an edge labeled 'name' connecting our person to the node
whose content is the string 'John'. The second
is an edge labeled 'livesWith' that points from
our first Person node to a second
Person node.
So now we're into the third level of XML nesting, and the
striping pattern means that this odd-numbered level of
nesting is describing a node. Any XML sub-elements below it
in the XML tree are, accordingly, representations of that
Person's properties, ie. edges in the graph. We
have one such edge, 'father', whose XML element
contains the third 'Person' element (standing
for a node of type Person). That element has
just one sub-element, 'name', which provides a
label for an edge connecting the third person to a node whose
content is the string 'Fred'.
So to recap we've seen: a node (of type Person), with edge ('name': John), and edge ('livesWith') pointing at a node (of type Person) having an edge ('father') pointing at a node (of type Person) with an edge ('name': John).
The XML elements at the 1st, 3rd, and 5th levels of nesting all stand for individual nodes, in our scenario they happen to all be of the same type, Person. The XML elements at the 2nd, 4th, and 6th levels of nesting represent labeled edges in the graph, ie. RDF properties.
We alternate between node-describing and edge-describing XML elements, starting always with the description of a node. For node-describing elements the XML element name maps onto the type, or class of the resource represented by the node. For edge-describing elements, the XML element name supplies a label for the RDF property that connects the associated resources.
This is RDF striping. Understanding this basic representational convention is all you need to understand most RDF/XML examples you'll encounter.
You can't tell, without starting at the top and counting on your fingers, whether an XML element in the RDF serialisation represents an edge, or a node. But often you can cheat! Look again at the example, and notice that edge even-numbered layer of XML, the red 'edge label' stripes, has a name beginning with a lower case letter. Many RDF vocabularies (including the core RDF specs themselves) adopt this convention. We name properties with a lower case, and classes of thing with an upper case name (eg. 'Person').
I haven't mentioned the rdf:Description element. The RDF 1.0 Model and Syntax spec gives this a lot of attention when presenting the RDF syntax. Basically it can occur on any of the node-describing XML elements (ie. odd-numbered) in the striped syntax. It is redundant, and a bit confusing since apart from the option of putting rdf:Description on the node-describing elements, we can always map from the name of these nodes to an RDF type that is a class for the thing the node describes. In our example, 'Person'. So the existence of rdf:Description in the syntax complicates things. Whenever you see it, pretend you saw a node called 'Resource' instead; that way, you can read it as 'there exists a Resource...'.
We've said nothing about namespaces here yet. RDF uses the XML namespace mechanism to associate all these classes and properties with Web identifiers (URIs). We've said nothing here about the use of XML attributes. Here's a short version. When you see an attribute on a node-level element, eg on the 'Person' elements in the example above, it always stands for an RDF property, whose value is always written a simple literal string.. Except for some some special cases, of course, otherwise things would be too simple. One special case is important: the rdf:about attribute. When you see rdf:about, this is RDF's way of telling you that we know a URI name for the thing concerned. These are not treated as properties, but are in a sense 'built in' to RDF at a deep level. Also rdf:ID, and xmlns:*, xml:lang, xml:base and probably some others. See the syntax spec for details. But the basic idea is: when you see attributes on a node-level XML element (the ones whose names often begin with capital letters), the attribute represents an edge pointing to a literal value.
Another important case: representing edges that point to nodes that are described elsewhere (within the same document but not within this part of the element tree; or elsewhere in the Web). For this, RDF has the rdf:resource attribute. This always appears at the edge-level of the XML document, ie. on elements that stand for edges rather than for nodes. Apart from that, it functions similarly to the rdf:about, in that it uses URIs to point off to a node instead of describing it inline.
There are many other corner cases in the spec. RDF's rdf:parseType attribute, for example, complicates the simplistic striping model described here. But for many common cases, the notion of 'striped syntax' will provide some useful mental scaffolding that'll help you read the XML not just "as XML", but as an XML description of the abstract RDF graph. If in doubt, experiment with the free online parsing and visualisation service at W3C.
@@writeme
$Id: Overview.html,v 1.9 2002/03/10 16:25:08 danbri Exp $