![]()
Multimodal Interaction at W3C — An overview
Bert Bos <bert@w3.org>
W3C/ERCIM
Sophia-Antipolis, France





The taxis in Bonn have a car navigation system that shows the driver the route to take. The system gets input from a GPS device, so it updates its status, shows the current position and the next action to take, which is also communicated by voice. When the driver fails to follow the directions, the system notices and computes a new route. The output seems to have been well thought out. However, the input is a bit cumbersome: a single button can either turn or be pressed and it is used to select from a menu. Entering a street name, even with the predictive menus, takes time and can't be done safely while driving. Though drivers do it anyway, of course…
Described in Use Cases document. Examples:
a very complex problem…
Speech, pen, mouse, keyboard, remote control... Separate or in combination: select with a pen on a graphic, then speak additional information: "I want this [points to image] pizza, but without olives."
Set up a session, e.g., a route planner, at home with a PC, then get in the car and continue the same session.
… that's why there is quite a big working group…
The MMI working group started in Feb 2002
Subgroups for:
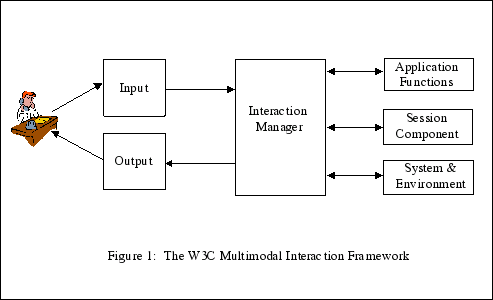
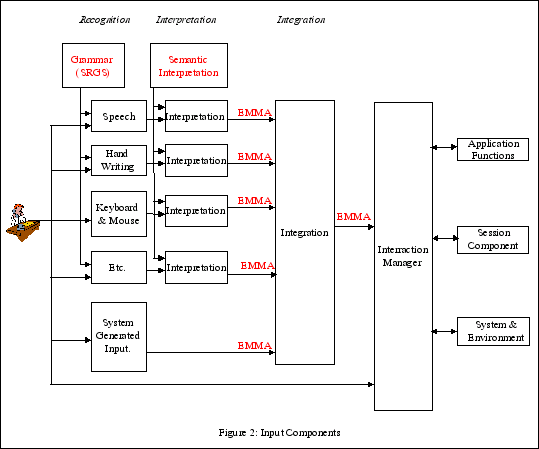
This is again a logical framework, the boxes do not necessarily correspond to devices or even to processes, but to tasks. Several tasks may be integrated or they may be distributed. There may be one client and one server or there may be proxies in between that perform part of the task.
The existence of EMMA allows the system to be built out of components, since it provides a format for transporting (partially processed) inputs of all kinds, with standard metadata to describe the state of processing.
Reuse of existing markup: XHTML, CSS, SVG for output, XForms for input.
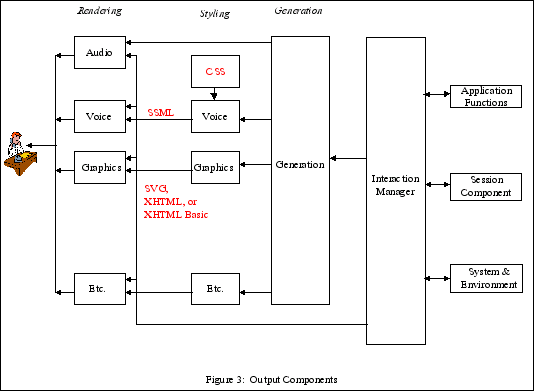
Built on existing technologies: CSS (styling), SVG (graphics), SSML (speech)…
Current focus is:
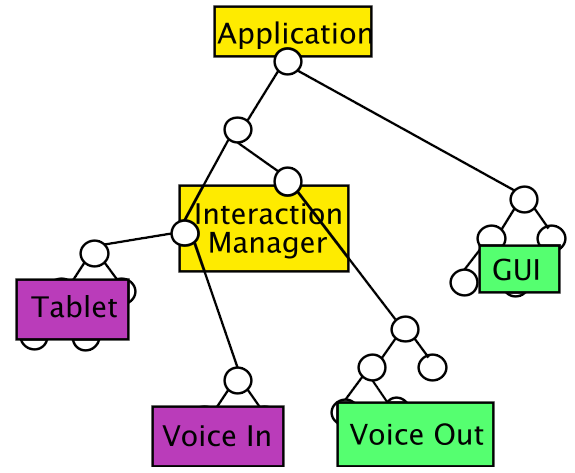
Going down one level, it is necessary to specify interfaces between components. The whole framework can be seen as a distributed DOM, or it can be seen as components passing messages between each other, in the form of markup.
The "objects" in this model are elements and attributes in the various formats that are used (SVG, SMIL, SSML, etc.) but also the user interface (windows, keyboard, pen, microphone, etc.)
Ideally, somebody building a system should not have to worry about which objects are on which machine and whether a function call is executed on the same machine or on a different one.
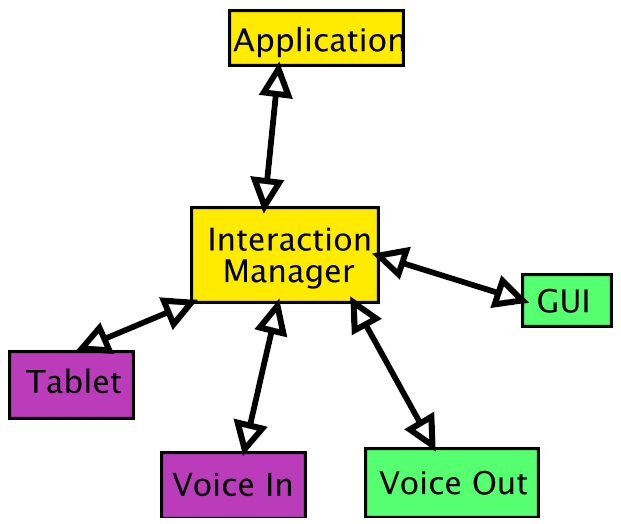
Message passing infrastructure
Stresses that the various parts may exist on separate machines.
Not yet decided what model the working group will develop: (remote) function calls or message passing. But there should not be much difference in practice: in either case the objects passed back and forth are XML-like structures of elements and attributes, whether or not they ever get serialized to a text file.
VIO requirements
Work with Voice Browser working group (VoiceXML, SSML)
DTMF = tones generated by buttons on a phone.
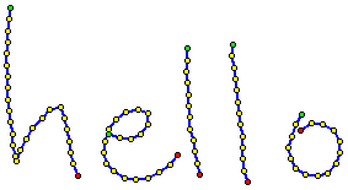
Markup for pen-based input devices
Compact, easy to generate notation. Metadata in XML.
For many kinds of output there are existing formats that can be used. For input there isn't much. InkML fills the gap for pen input. It describes the path traced by a pen, with optional pressure, height, tilt and other information.
InkML is still a working draft. The syntax isn't fixed yet. The goal is to create a relatively compact format that is easy to generate. But with structure and metadata in XML, so it can be inspected with standard XML tools.
Markup for input annotations strong>
(Extensible MultiModal Annotation language)
Extensible = written in XML; Multimodal = independent of devices and media; Annotation = the language adds metadata to the inputs returned from the user.
The annotations allow to say, e.g., that there are two possible interpretations with different confidence scores, or that an interpretation is derived from another interpretation (and thus has to be rejected if the other one is rejected, e.g.). They can also describe the device context.
This is also an early working draft. There are two possible directions for the syntax proposed, one based on RDF and one based on a wrapper element with attributes, which may be more compact but also more limited. In both cases, there are still details to be worked out.
XForms is one possible way to pass the template and the instructions for filling it to the user's device, but not the only one. Nevertheless, if you read "form" for "template," you'll see that XForms was designed precisely for this function.
<emma:emma xmlns:emma=... xmlns:rdf=...
<emma:one-of
<emma:interpretation rdf:ID="int1">
<trip>
<origin>Boston</origin>
<destination>Denver</destination>
<date>03112003</date>
</trip>
</emma:interpretation>
<emma:interpretation rdf:ID="int2">
<trip>
<origin>Austin</origin>
<destination>Denver</destination>
<date>03112003</date>
</trip>
</emma:interpretation>
</emma:one-of>
<rdf:RDF>
<rdf:Description
about="#xpointer(id('int1')/date)"
emma:start="2003-03-26T10:07:00.15"
emma:end="2003-03-26T10:07:00.2"/>
</rdf:RDF>
</emma:emma>
This example shows a mixed XML/RDF syntax. It is one of the syntaxes currently being considered.
The example shows that there are two intrepretations at this point. The receiver of these two interpretations (further to the right in the framework) will have to do something to decide among them.
The example also shows an RDF annotation on the "date" field. It says that the input of that field was received on 26 March at 10:07 and the user took less than a second to create it.
(This talk: http://www.w3.org/Talks/2003/0923-MMI-Erfurt/all)
A high-level overview of the Multimodal Interaction activity at W3C, its aims and output so far.