![]()
This talk deals with (X)HTML, CSS, XSLT, RDF, and:
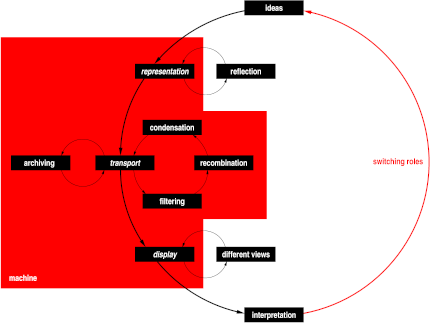
This is a graphic I made in 1998 for a conference on electronic publishing and I've used it several times since, because it explains well where various technologies fit in the whole process of human communication via the Web. And also because I think it looks nice as a picture...
Style sheets (CSS and XSL) deal with the small circle at the bottom ("display - different views"). Search engines operate mostly on the middle circle. Web sites take care of the small circle on the left ("archiving"). Many data formats (HTML, SVG, MathML, SMIL, etc.) are concerned with the small circle at the top ("representation - reflection").
(Just examples; other browsers do the same, with different UI)
[demo: Opera] [demo: Mozilla]
HTML:
<link... media="screen"> <link... media="projection">
CSS:
@media screen {...}
@media projection {...}
Browser can be more than just a viewer
[demo: Amaya]
Style sheets allow the user fine-grained control over the style [demo: Konqueror]
Normal HTML, when used correctly, is sufficient for encoding multiple things at once. Example:
but:
Let's make a list of all working drafts!
Although some working groups originally started by copying the page of some other group, they all diverge over time, adding new sections, replacing table by lists and vice versa, formatting titles differently, sorting them by date or by topic, keeping lists of superceded drafts or not, intermingling them with links to meeting minutes, etc.
But despite the differences, it is actually very easy to overlay another structure on them, that identifies just the things we are interested in, in this case: the working drafts the group is working on. Typically all the parts (title, date, link) are already marked up, because they play a role in the structure of the page itself, and it is very easy to flag the parts we want.
The class attribute allows elements to be specialized
class=draft to every mention of a WDclass=title to the mention of the titleclass=date to the publication daterel=details to the link to the actual draftdraft is required, the rest is inferred)<li class="draft"><a rel="details" href="css3-background/Overview.html" class="title">Background</a> - Tim Boland <span class="date">28 Sep 2001</span>
The rel attribute is used for the link instead of the
class attribute, because we want to categorize the type of link,
not the textual content of the a element. The A element in this example, in
fact, has both rel and class, because the content
of the element happens to be the title.
Most of the classes can be omitted if certain elements are used: H3 for the title, A for the link, etc.
Harvest and publish the data:
[Result]
The XSLT is run on every working group page and looks for
class=draft. It extracts the data it needs and outputs a simple
HTML list. All those lists together form a complete list of all drafts being
worked on by the various working groups.
In this case the output is another HTML page, but it could have been something else: simple text, SQL, statistics, a graph, etc.
RSS is a news syndication format
[Demo: KDE desktop panel] [Demo: Meerkat]
Many news sites provide a sort of table of contents for their news items, often ordered by topic (channels). This table of contents is an RDF file (although some still use version 0.9, which was XML, but not yet RDF) using the RSS vocabulary.
Originally, RSS was developed by Netscape to allow sites to describe themselves briefly, so that the site could be used in the "What's related" button of Navigator. Since then it has been picked up as a general news syndication format and you can now get today's news from CNN, from Heise Online, from Slashdot and many other sites in RSS format.
Syndication means that one news site can use news items that originate on another site. Thus, e.g., O'Reilly's Meerkat server is an automated system that collects news items and generates several pages, each with items related to a particular topic. In the case of Meerkat, those are computer-related topics, such as XML, RDF, Web services, Linux and Macintosh.
Various dedicated "news tickers" also exist. One is built-in to the KDE desktop panel. By default it simply scrolls all the current headlines in a continuous loop, but you can click on a headline to open the complete story.
Adding them together:
Result:
[Demo: W3C home page] [Demo: W3C news in RSS]
A similar piece of XSLT is used to get the news items from the W3C home page. The news items are written in simple HTML, the author doesn't have to know any RDF, but only has to be consistent in the mark-up: every news item has an H2 as title, starts with a date and has a link to more information.
In this case the RSS is not generated once per day, but on demand. But that is an implementation detail.
The goal of this talk is to show how single-source publishing fits in the overall idea of the "semantic Web." The semantic Web (SemWeb) is not a particular kind of Web, but an idea about how the Web can be used to advantage. By taking care that information is encoded sufficiently rich and at the right level for current technology, we can use the Web to enhance the information it contains and get more out of it than the sum of its parts.
Although the term "semantic Web" is only now starting to become known, it was in fact first used (i.e., written) by Tim Berners-Lee around 1994 and all W3C's efforts have always tried to develop technologies on the basis of this idea. That is why we can now, using just (correct) HTML, CSS, XSLT and other technologies, already show how to derive additional value from existing Web pages. RDF is not needed for that, although one of the examples below also shows one of the early applications of RDF.