Abstract
The W3C Voice Browser working group aims to develop
specifications to enable access to the Web using spoken
interaction. This document is part of a set of specifications for
voice browsers, and provides details of an XML markup language
for describing the meanings of individual natural language
utterances. It is expected to be automatically generated by
semantic interpreters for use by components that act on the
user's utterances, such as dialog managers.
Status of this Document
This document is a W3C Working Draft for review by W3C members
and other interested parties. It is a draft document and may be
updated, replaced, or obsoleted by other documents at any time.
It is inappropriate to use W3C Working Drafts as reference
material or to cite them as other than "work in progress". A list
of current public W3C Working Drafts can be found at http://www.w3.org/TR.
This specification describes markup for representing natural
language semantics, and forms part of the proposals for the W3C
Speech Interface Framework. This document has been produced as
part of the W3C Voice Browser
Activity, following the procedures set out for the W3C Process. The
authors of this document are members of the Voice Browser Working
Group (W3C Members only). This document is for public review,
and comments and discussion are welcomed on the public mailing
list <www-voice@w3.org>. To
subscribe, send an email to <www-voice-request@w3.org>
with the word subscribe in the subject line (include the
word unsubscribe if you want to unsubscribe). The archive
for the list is accessible online.
General Issues
The NL semantics representation uses the data models of the W3C
XForms draft specification to represent application-specific
semantics. While XForms syntax may change in future revisions of
the specification, it is not expected to change in ways that
affect the NL Semantics Markup Language significantly.
Table of Contents
This document presents an XML specification for a Natural
Language Semantics Markup Language, responding to the
requirements documented in W3C Natural Language
Processing Requirements for Voice Browsers. This markup
language is intended for use by systems that provide semantic
interpretations for a variety of inputs, including but not
necessarily limited to, speech and natural language text input.
These systems include Voice Browsers, web browsers and accessible
applications.
It is expected that this markup will be used primarily as a
standard data interchange format between Voice Browser
components; in particular, it will normally be automatically
generated by a semantic interpretation component to represent the
semantics of users' utterances and will not be directly authored
by developers.
The language is focused on representing the semantic
information of a single utterance, as opposed to (possibly
identical) information that might have been collected over the
course of a dialog. See the Future Study section for a detailed
discussion of returning information from a dialog.
The language provides a set of elements that are focused on
accurately representing the semantics of a natural language
input. The following are the key design criteria.
-
Fidelity: The representation should be capable of
accurately reflecting the user's intended meaning in terms of the
application's goals. However, it should also provide a semantic
interpreter with the means to represent vagueness and ambiguity
when the user's meaning cannot be fully determined with the
information available to the semantic interpreter.
-
Interoperability: The representation should support
use along with other W3C specifications including (but not
limited to) the Dialog Markup Language, Speech Grammar Markup
Language, SMIL
and XForms.
-
Implementability: The required elements of the
specification should be implementable with existing, generally
available technology.
-
Extensibility: The specification should be extensible
to accommodate emerging and future capabilities of
automatic speech recognizers (ASR's), natural language
interpreters, and voice browsers. For example, it should be
compatible with statistical ASR's, mixed initiative dialogs and
multi-modal components.
-
Architectural Neutrality: The specification should
attempt wherever possible to avoid specifications which imply
commitments to particular Voice Browser architectures, for
example whether multi-modal integration takes place before or
after natural language interpretation.
-
Portability: The specification should be able to
support consistent behavior across platforms.
This specification includes a set of draft elements and attributes and includes a draft DTD.
The general purpose of the NL Semantics Markup is to represent
information automatically extracted from a user's utterances by a
semantic interpretation component, where utterance is to
be taken in the general sense of a meaningful user input in any
modality supported by the platform. Referring to the sample Voice
Browser architecture in
Introduction and Overview of the W3C Speech Interface
Framework, a specific architecture can take advantage of this
representation by using it to convey content among various system
components that generate and make use of the markup.
Components that generate NL Semantics Markup:
- ASR
- Natural language understanding
- Other input media interpreters (e.g. DTMF, pointing,
keyboard)
- Reusable dialog component
- Multimedia integration component
Components that use NL Semantics Markup:
- Dialog manager
- Multimedia integration component
A platform may also choose to use this general format as the
basis of a general semantic result that is carried along and
filled out during each stage of processing. In addition, future
systems may also potentially make use of this markup to convey
abstract semantic content to be rendered into natural language by
a natural language generation component.
A semantic interpretation system that supports the Natural
Language Semantics Markup Language is responsible for
interpreting natural language inputs and formatting the
interpretation as defined in this document. Semantic
interpretation is typically either included as part of the speech
recognition process, or involves one or more additional
components, such as natural language interpretation components
and dialog interpretation components. See the Voice Browser
Architecture described in http://www.w3.org/TR/voice-intro/
for a sample architecture.
The elements of the markup fall into the following general
functional categories:
Input formats and ASR information:
The "input" element, representing the
input to the semantic interpreter.
Interpretation:
Elements and attributes representing the semantics of the
user's utterance, including the "result",
"interpretation", "model", and "instance"
elements. The "result" element contains the full result of
processing one utterance. It may contain multiple
"interpretation" elements if the interpretation of the utterance
results in multiple alternative meanings due to uncertainty in
speech recognition or natural language understanding. There are
at least two reasons for providing multiple interpretations:
- another component, such as a dialog manager, might have
additional information, for example, information from a database,
that would allow it to select a preferred interpretation from
among the possible interpretations returned from the semantic
interpreter.
- a dialog manager that was unable to select between several
competing interpretations could use this information to go back
to the user and find out what was intended. For example, Did
you say "Boston" or "Austin"?
The "model" is an XForms data model for the semantic
information being returned in the interpretation. The "model" is
a structured representation of the interpretation and allows for
type checking. The "instance" is an instantiation of the data
model containing the semantic information for a specific
interpretation of a specific utterance. For example, the
information in a travel application might include three groups of
information: flights, car rental and hotels. The flight
information, in turn, could contain values for "to_city",
"from_city", "departure_date" and so on, which would be typed as
strings.
Side Information:
Elements and attributes representing additional information
about the interpretation, over and above the interpretation
itself. Side information includes
-
Whether an interpretation was achieved (the "nomatch" element)
and the system's confidence in an interpretation (the
"confidence" attribute of "interpretation").
-
Alternative interpretations ("interpretation")
Multi-modal integration:
When more than one modality is available for input, the
interpretation of the inputs needs to be coordinated. The "mode"
attribute of "input" supports this by
indicating whether the utterance was input by speech, dtmf,
pointing, etc. The timestamp attributes of "input" also provide
for temporal coordination by indicating when inputs occurred.
This figure shows a graphical view of the relationships among
the elements of the Natural Language Semantics markup.
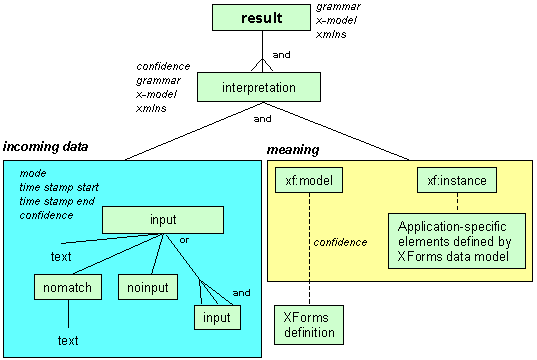
The elements shown in the graphic fall into two
categories:
- description of the input to be processed; shown in the left
box, "incoming data" in blue.
- description of the meaning which was extracted from the
input; shown in the right box, "meaning", in yellow.
Next to each element in the graphic are its attributes in
italics. In addition, some elements can contain multiple
instances of other elements. For example, a "result" can contain
multiple "interpretations", each of which is taken to be an
alternative. The element "xf:model" is an XForms data model as
specified in the XForms data
model draft, and therefore is not defined in this
document.
To illustrate the basic usage of these elements, as a simple
example, consider the utterance ok. (interpreted as "yes")
The example illustrates how that utterance and its interpretation
would be represented in the NL Semantics markup.
<result x-model="http://theYesNoModel"
xmlns:xf="http://www.w3.org/2000/xforms"
grammar="http://theYesNoGrammar>
<interpretation>
<xf:instance>
<myApp:yes_no>
<response>yes</response>
</myApp:yes_no>
</xf:instance>
<input>ok</input>
</interpretation>
</result>
This example includes only the minimum required information,
i.e., it does not include any of the optional information defined
in this document. There is an overall "result" element which
includes one interpretation. The data model is defined externally
by referring to the URI for "theYesNo Model". This external model
defines a "response" element. The "myApp" namespace refers to the
application-specific elements that are defined by the XForms data
model.
Attributes: grammar, x-model, xmlns
The root element of the markup is "result". The "result"
element includes one or more "interpretation" elements. Multiple
interpretations result from ambiguities in the input or in the
semantic interpretation. If the "grammar", "x-model", and "xmlns"
attributes don't apply to all of the interpretations in the
result they can be overridden for individual interpretations at
the "interpretation" level.
Attributes:
- grammar: The grammar or recognition rule matched by
this result. (The format of the grammar attribute will match the
rule reference semantics defined in the grammar
specification.) The grammar can be overridden by a grammar
attribute in the "interpretation" element if the input was
ambiguous as to which grammar it matched.
- x-model: The URI which defines the XForms data model
used for this result. The data model used by the interpretation
can either be specified here or by an in-line data model using
the " model" element. (optional) The x-model can be overridden by
an x-model attribute in the "interpretation" element if the input
was ambiguous as to which x-model it matched.
- xmlns: An XML namespace declaration is required to
define the namespace used by XForms elements and attributes. The
DTD defaults the "xmlns" namespace declaration to a standard
location, since it will rarely change.
<result grammar="http://grammar" x-model="http://dataModel"
xmlns:xf="http://www.w3.org/2000/xforms"
<interpretation/>
</result>
Attributes: confidence, grammar, x-model, xmlns
An "interpretation" element contains a single semantic
interpretation.
Attributes:
- confidence: an integer from 0-100 indicating the
semantic analyzer's confidence in this interpretation. At this
point there is no formal, platform-independent, definition of
confidence. (optional)
- grammar: The grammar or recognition rule matched by
this interpretation (if needed to override the grammar
specification at the "interpretation" level.) The dialog markup
interpreter needs to know the grammar rule that is matched by the
utterance because multiple rules may be simultaneously active.
The value that is filled in is the grammar URI used by the dialog
markup interpreter to specify the grammar. The format of the
grammar attribute will match the rule reference semantics defined
in the grammar
specification. Specifically, the rule reference will be in
the external XML
form for grammar rule references. This attribute will only be
needed under "interpretation" if it is necessary to override a
grammar that was defined at the "result" level.) (optional)
- x-model: The location of the XForms data model used
for this interpretation. The XForms data used by the
interpretation may either be specified here or by an in-line data
model using the "model" element. (As in the
case of "grammar", this attribute only needs to be defined under
"interpretation" if it is necessary to override the x-model
specification at the "interpretation" level.) (optional)
Interpretations must be sorted best-first by some measure of
"goodness". The goodness measure is "confidence" if present,
otherwise, it is some platform-specific indication of
quality.
The x-model and grammar are expected to be specified most
frequently at the "result" level, because most often one data
model will be sufficient for the entire result. However, it can
be overridden at the "interpretation" level because it is
possible that different interpretations may have different data
models - perhaps because they match different grammar rules.
The "interpretation" element includes an "input" element which contains the input being
analyzed, optionally a "model" element
defining the XForms data model and an "instance" element containing the
instantiation of the data model for this utterance. The data
model would be empty if the interpreter was not able to produce
any interpretation.
<interpretation confidence="75" grammar="http://grammar"
x-model="http://dataModel"
xmlns:xf="http://www.w3.org/2000/xforms">
...
</interpretation>
The "model" element contains an XForms data model for the data
and is part of the X-Forms name space. The XForms data model
provides for a structured data model consisting of groups, which
may contain other groups or simple types. Simple types can be one
of: string, boolean, number, monetary values, date, time of day,
duration, URI, binary. For further information on XForms data
models see the X-Forms
data model specification. Note that XForms fields default to
optional.
If no data model is supplied by either the "model" element or
the "x-model" attribute then it is assumed that the data model
will be provided by the dialog (or whatever other process
receives the NL semantic mark-up).
It is an error to specify both an x-model attribute and a
"model" element.
Example: An XForms data model for name and address.
<model>
<xf:group name="nameAddress">
<string name="name"/>
<string name="street"/>
<string name="city"/>
<string name="state"/>
<string name="zip">
<mask>ddddd</mask>
</string>
<xf:/group>
</model>
The "instance" element contains an instance of the XForms data
model for the data and is part of the XForms name space.
Attributes:
- confidence: All elements of the data instance may have
an optional confidence attribute, defined in the NL semantics
namespace. The confidence attribute contains an integer value in
the range from 0-100 reflecting the system's confidence in the
analysis of that slot. The meaning of confidence scores has not
been defined in a platform-independent way. (optional)
The use of a confidence attribute from the NL semantics
namespace does not appear to present any document validation
problems. However if future XForms specifications support an
equivalent attribute then that would be preferable to the current
proposal.
<xf:instance name="nameAddress">
<nameAddress>
<street confidence=75>123 Maple Street</street>
<city>Mill Valley</city>
<state>CA</state>
<zip>90952</zip>
</nameAddress>
</xf:instance>
<input>
My address is 123 Maple Street,
Mill Valley, California, 90952
</input>
The "input" element is the text representation of a user's
input. It includes an optional "confidence" attribute which
indicates the recognizer's confidence in the recognition result
(not the confidence in the interpretation, which is indicated by
the "confidence" attribute of "interpretation"). Optional
"timestamp-start" and "timestamp-end" attributes indicate the
start and end times of a spoken utterance, in ISO 8601 format (http://www.iso.ch/markete/8601.pdf
).
Attributes:
- timestamp-start: The time at which the input began.
(optional)
- timestamp-end: the time at which the input ended.
(optional)
- mode: The modality of the input, for example, speech,
dtmf, etc. (optional)
- confidence: the confidence of the recognizer in the
correctness of the input (optional)
Note that it doesn't make sense for temporally overlapping
inputs to have the same mode; however, this constraint is not
expected to be enforced by platforms.
When there is no time zone designator, ISO 8601 time
representations default to local time.
There are three possible formats for the "input" element.
a) The "input" element can contain simple text:
<input confidence = "100" mode="speech">onions</input>
b) The "input" element can also contain additional "input"
elements. Having additional input elements allows the
representation to support future multi-modal inputs as well as
finer-grained speech information, such as timestamps for
individual words and word-level confidences.
<input>
<input mode="speech" confidence="50"
timestamp-start="2000-04-03T0:00:00"
timestamp-end="2000-04-03T0:00:00.2">fried</input>
<input mode="speech" confidence="100"
timestamp-start="2000-04-03T0:00:00.25"
timestamp-end="2000-04-03T0:00:00.6">onions</input>
</input>
c) Finally, the "input" element can contain "nomatch" and
"noinput" elements, which describe situations in which the speech
recognizer (or other media interpreter) received input that it
was unable to process, or did not receive any input at all,
respectively.
The "nomatch" element under "input" is used to indicate that
the natural language interpreter was unable to successfully match
any input. It can optionally contain the text of the best of the
(rejected) matches.
<interpretation>
<instance/>
<input>
<nomatch/>
</input>
</interpretation>
The "noinput" element under "input" is used to indicate that
there was no input-- a timeout occurred in the speech recognizer
due to silence.
<interpretation>
<instance/>
<input>
<noinput/>
</input>
</interpretation>
If there are multiple levels of inputs, it appears that the
most natural place for the "nomatch" and "noinput" elements is
under the highest level of "input" for "no input", and under the
appropriate level of "input" for "nomatch". So "noinput" means
"no input at all" and "nomatch" means "no match in speech
modality" or "no match in dtmf modality". For example, to
represent garbled speech combined with dtmf "1 2 3 4", we would
have the following:
<input>
<input mode="speech"><nomatch/></input>
<input mode="dtmf">1 2 3 4</input>
</input>
The natural language requirements state that the semantics
specification must be capable of representing a number of types
of meta-dialog and meta-task utterances. This specification is
flexible enough so that meta utterances can be represented on an
application-specific basis without defining specific formats in
this specification.
Here are two examples of how meta-task and meta-dialog
utterances might be represented.
System: What toppings do you want on your
pizza?
User: What toppings do you have?
<interpretation grammar="http://toppings"
xmlns:xf="http://www.w3.org/2000/xforms">
<input mode="speech">
what toppings do you have?
</input>
<xf:x-model>
<xf:group xf:name="question"/>
<xf:string xf:name="questioned_item"/>
<xf:string xf:name="questioned_property"/>
</xf:group>
</xf:x-model>
<xf:instance>
<xf:question>
<xf:questioned_item>toppings</xf:questioned_item>
<xf:questioned_property>
availability
</xf:questioned_property>
</xf:question>
</xf:instance>
</interpretation>
User: slow down.
<interpretation grammar="http://generalCommandsGrammar"
xmlns:xf="http://www.w3.org/2000/xforms">
<xf:model>
<group name="command"/>
<string name="action"/>
<string name="doer"/>
</group>
</xf:model>
<xf:instance>
<myApp:command>
<action>reduce speech rate</action>
<doer>system</doer>
</myApp:command>
</xf:instance>
<input mode="speech">slow down</input>
</interpretation>
This specification can be used on an application-specific
basis to represent utterances that contain unresolved anaphoric
and deictic references. Anaphoric references, which include
pronouns and definite noun phrases that refer to something that
was mentioned in the preceding linguistic context, and deictic
references, which refer to something that is present in the
non-linguistic context, present similar problems in that there
may not be sufficient unambiguous linguistic context to determine
what their exact place in the data instance should be. In order
to represent unresolved anaphora and deixis using this
specification, the developer must define a more surface-oriented
representation that leaves the interpretation of the reference
open. (This assumes that a later component is responsible for
actually resolving the reference)
Example: (ignoring the issue of representing the input from
the pointing gesture.)
System: What do you want to drink?
Use: I want this (clicks on picture of large root
beer.)
<result>
<interpretation>
<xf:model>
<group name="genericAction">
<string name="doer">
<string name="action">
<string name="object">
</group>
</xf:model>
<xf:instance>
<doer>I</doer>
<action>want</action>
<object>this</object>
</xf:instance>
<input>
<input mode="speech">I want this</input>
</input>
<interpretation>
</result>
One of the natural language requirements states that the
specification must be extensible. The specification supports this
requirement because of its flexibility, as discussed in the
discussions of meta utterances and anaphora. The markup can
easily be used in sophisticated systems to convey
application-specific information that more basic systems would
not make use of, for example defining speech acts, if this is
meaningful to the dialog manager. Defining standard
representations for items such as dates, times, etc. could also
be done.
Compliance issues are deferred until a later revision of the
specification.
(TBD)
Leading and trailing spaces in utterances are not significant.
This will be defined in the DTD by specifying
"xml:space=default".
System: To which city will you be
traveling?
User: I want to go to Pittsburgh.
<result xmlns:xf="http://www.w3.org/2000/xforms"
grammar="http://flight">
<interpretation confidence="60">
<input mode="speech">
I want to go to Pittsburgh
</input>
<xf:model>
<group name="airline">
<string name="to_city"/>
</group>
</xf:model>
<xf:instance>
<myApp:airline>
<to_city>Pittsburgh</to_city>
</myApp:airline>
</xf:instance>
</interpretation>
<interpretation confidence="40"
<input>I want to go to Stockholm</input>
<xf:model>
<group name="airline">
<string name="to_city"/>
</group>
</xf:model>
<xf:instance>
<myApp:airline>
<to_city>Stockholm</to_city>
</myApp:airline>
</xf:instance>
</interpretation>
</result>
System: What would you like?
User: I would like 2 pizzas, one with pepperoni and cheese,
one with sausage and a bottle of coke, to go.
This representation includes an order object which in turn
contains objects named "food_item", "drink_item" and
"delivery_method". This representation assumes there are no
ambiguities in the speech or natural language processing. Note
that this representation also assumes some level of
intrasentential anaphora resolution, i.e., to resolve the two
"one's" as "pizza".
<result xmlns:xf="http://www.w3.org/2000/xforms"
grammar="http://foodorder">
<interpretation confidence="100" >
<xf:model>
<group name="order">
<group name="food_item" maxOccurs="*">
<group name="pizza" >
<string name="ingredients" maxOccurs="*"/>
</group>
<group name="burger">
<string name="ingredients" maxOccurs="*/">
</group>
</group>
<group name="drink_item" maxOccurs="*">
<string name="size">
<string name="type">
</group>
<string name="delivery_method"/>
</group>
</xf:model>
<xf:instance>
<myApp:order>
<food_item confidence="100">
<pizza>
<xf:ingredients confidence="100">
pepperoni
</xf:ingredients>
<xf:ingredients confidence="100">
cheese
</xf:ingredients>
</pizza>
<pizza>
<ingredients>sausage</ingredients>
</pizza>
</food_item>
<drink_item confidence="100">
<size>2-liter</size>
</drink_item>
<delivery_method>to go</delivery_method>
</myApp:order>
</xf:instance>
<input mode="speech">I would like 2 pizzas,
one with pepperoni and cheese, one with sausage
and a bottle of coke, to go.
</input>
</interpretation>
</result>
A combination of dtmf input and speech would be represented
using nested input elements. For example:
User: My pin is (dtmf 1 2 3 4)
<input>
<input mode="speech" confidence ="100"
timestamp-start="2000-04-03T0:00:00"
timestamp-end="2000-04-03T0:00:01.5">My pin is
</input>
<input mode="dtmf" confidence ="100"
timestamp-start="2000-04-03T0:00:01.5"
timestamp-end="2000-04-03T0:00:02.0">1 2 3 4
</input>
</input>
In this mark-up ambiguities are only represented at the
top-level, using separate interpretation elements. Representation
of "local" ambiguities, for example, at the level of an ambiguity
between two ingredients (peppers vs. pepperoni)
would be useful, but represents validation problems because of
multiple namespaces unless the XForms specification includes it.
The more compact representation using local ambiguities has not
been defined for three reasons:
- It is not possible to combine ambiguities with the XForms
notation and retain the ability to validate NL semantics
documents using XML schema or DTDs.
- When multiple filler elements are allowed, as for example
with pizza toppings, representation of ambiguity can become very
complex and confusing.
- Although fully spelling out ambiguities at the top level
results in a more verbose representation, current practical
systems seldom make use of more than 2 alternative
interpretations, so the increase in verbosity from spelling out
redundant information should not be too significant in
practice.
Local ambiguities may be supported in the future if
representation of ambiguity becomes part of the XForms
standard.
If there is more than one interpretation, it may be useful to
add an attribute specifying the source of the ambiguity, for
example, "natural_language", "speech", "ocr", or "handwriting"
Speech ambiguities originate in uncertainties about the speech
recognition result, for example, Austin vs. Boston.
"handwriting" and "ocr" are analogous to speech. Natural language
ambiguities result from syntactic, semantic, or pragmatic
ambiguities in a single recognizer result. For example in I
want fried onions and peppers, there are two interpretations,
one in which the peppers are to be fried and one in which they
are not to be fried. This attribute would not be meaningful if
there is only one interpretation. This information could be used,
for example, by a dialog manager to construct a more helpful
response (e.g. I didn't hear that vs. I didn't
understand that) or by a scoring algorithm that treats
different ambiguity sources differently.
In many cases identical information can be conveyed in one
utterance or over the course of several dialog turns. This
situation can occur both in the case of a subdialog or in the
case of a reusable component. For example, if the system's goal
in the subdialog or the reusable component is to collect travel
information from a user, the ultimate information is the same
whether the user says I want to go from Pittsburgh to Seattle
on January 1, 2001, in a single utterance or whether the same
information is elicited from the user during several dialog
turns, as in
System: Where will you be departing from?
User: Pittsburgh.
System: Where will you be traveling to?
User: Seattle.
etc.
It should be possible to use a substantially similar semantic
representation in both of these situations. The main issue is
that in the case of information collected over the course of a
dialog it becomes very difficult to tie that information back to
the original inputs. Elements such as "input" and attributes such
as "timestamp-start", "timestamp-end", "grammar", and "mode"
which relate the semantic interpretation directly to the input
become less meaningful when the information is collected in a
dialog. Moreover, they also become less useful to the main dialog
component, since presumably it's the function of the subdialog or
reusable component to make use of this low-level information
internally to guide its own dialog and to shield the main dialog
from these details. One strategy under consideration is simply to
omit these aspects of the markup for dialog-based semantic
information. This issue may also be dealt with in the reusable
components group, since the issue of return information is key to
its charter.
Some utterances could potentially make use of more than one
data model in their semantic representations. For example it is
possible in a mixed initiative situation for the user to combine
multiple functions in one utterance, as in:
System: I heard you say you want to go to Pittsburgh, is
that correct?
User: Yes, and I'll be leaving around 8:00 a.m.
It would be natural for there to be a generic data model for
the "yes" and also an application-specific model for the flight
arrangements. One possibility would be for the interpreter to
create one joint data model on the fly from these models. Or, the
developer could define one data model that includes both elements
for "yes_no" and for the application-specific information. If
there are two data models, and consequently two instances, then
it is necessary to consider the problem of associating the
instances with the correct data models.
This is deferred until the specification for multi-modal
inputs is better defined, except for dtmf (for dtmf, see the example above)
It would be highly desirable if components in the dialog
system could extend the data model so that grammars or reusable
components could return information that is additional to a base
data model for, say, a time or date component or grammar. With
the current XForms specification it would be necessary to provide
a complete new data model in these cases. It is possible that the
XForms working group may extend the XForms specification to
include extensibility of the data model.
Similarly, the current XForms data model definition does not
provide for the re-use of complex type definitions, i.e. groups,
in multiple locations. Thus, to represent travel information
consisting of both an outbound flight and an inbound flight, it
is not possible to define a single complex type "flight_details"
that is used for both outbound and inbound flight information.
(See the section on "Shared Datatype Libraries" in the XForms Data
Model document for additional discussion.)
Some systems may find it useful to represent generic syntactic
parse trees in natural language output. Generic parse trees
cannot be represented by current XForms data models because they
do not support any recursion. However, it is not clear how
frequently this capability would be required.
An "unanalyzed" element could be used to represent a part of
the input that was left unanalyzed in the current interpretation.
This element could be used by a dialog manager to decide if
enough of the input had been analyzed for the dialog to proceed,
or if the dialog manager should ask for a clarification from the
user. The dialog manager could also use the unanalyzed material
to help it decide which of several alternative interpretations is
correct. Each "unanalyzed" element would contain "input" elements
which would contain the portions of the full utterance that was
unanalyzed.
"unanalyzed" has not been included in the current version of
the spec for several reasons:
-
It's not clear that it has a platform-independent
interpretation.
-
It's not clear that current applications would make use of
it.
-
Although there is a requirement for representing "unanalyzed",
this can be accommodated in the current specification if the
developer incorporates "unanalyzed" into the data model in an
application-specific manner. In addition, natural language
interpreters can take unanalyzed information into account
internally when they are computing confidences, so that this
information is available indirectly to dialog managers through
the confidence attributes.
The most important consideration appears to be whether in fact
the ability to represent unanalyzed material is of interest to
current or near future applications.
Note that the use of "unanalyzed" would be mainly useful for
systems with robust natural language interpreters which are
capable of ignoring portions of the speech recognizer result that
don't match the natural language grammar. In the case of tightly
coupled ASR/NL systems which require that all of the input match
a speech recognizer grammar the notion of "unanalyzed" isn't
useful, since all of the input is required to be analyzed by the
nature of the system. Similarly, keyword spotting systems with
garbage models will not be able to make use of this element
because the speech recognition process discards any
unrecognizable speech before the natural language interpretation
process begins.
Example:
System: Where do you want to go?
User: I'd like to fly from Boston and then continue on to
Philadelphia.
(assuming that "and then continue on" is not included
in the speech grammar.)
<unanalyzed>
<input>and then continue on</input>
</unanalyzed>
If there is duplicated unanalyzed material, as in Please
get my email please, every unanalyzed item should be
represented individually, so please should be duplicated
if both occurrences are unanalyzed.
This document was written with the participation of the
members of the W3C Voice Browser Working Group (listed in
alphabetical order):
Daniel Austin, Ask Jeeves, Inc.
Dan Burnett, Nuance
Andrew Hunt, SpeechWorks
Robert Keiller, VoxSurf International
Andreas Kellner, Philips
Bruce Lucas, IBM
Dave Raggett W3C/Phone.com