This document defines syntax for representing N-Gram
(Markovian) stochastic grammars within the W3C Speech Interface
Framework. The use of stochastic N-Gram models has a long and
successful history in the research community and is now more and
more effecting commercial systems, as the market asks for more
robust and flexible solutions. The primary purpose of specifying
a stochastic grammar format is to support large vocabulary and
open vocabulary applications. In addition, stochastic grammars
can be used to represent concepts or semantics. This
specification defines the mechanism for combining stochastic and
structured (in this case Context-Free) grammars as well as
methods for combined semantic definitions.
Status of this Document
This document is a W3C Working Draft for review by W3C members
and other interested parties. It is a draft document and may be
updated, replaced, or obsoleted by other documents at any time.
It is inappropriate to use W3C Working Drafts as reference
material or to cite them as other than "work in progress". A list
of current public W3C Working Drafts can be found at http://www.w3.org/TR.
This specification describes markup for representing
statistical language models, and forms part of the proposals for
the W3C Speech Interface Framework. This document has been
produced as part of the W3C
Voice Browser Activity, following the procedures set out for
the W3C
Process. The authors of this document are members of the Voice Browser Working
Group (W3C Members only). This document is for public review,
and comments and discussion are welcomed on the public mailing
list <www-voice@w3.org>. To
subscribe, send an email to <www-voice-request@w3.org>
with the word subscribe in the subject line (include the
word unsubscribe if you want to unsubscribe). The archive
for the list is accessible online.
This document defines syntax for representing N-Gram
(Markovian) stochastic grammars within the W3C Voice Browser
Markup Language. The parent language for specification of a
stochastic grammar is XML, however for efficiency some variance
from strict XML syntax will be used. Elements of the grammar
specification already defined in the XML specification will not
be repeated here (e.g. character encoding), thus avoiding any
potential inconsistency with the current or future XML
specifications.
The primary purpose of specifying a stochastic grammar format
is to support large vocabulary and open vocabulary applications.
In addition, stochastic grammars can be used to represent
concepts or semantics. This specification defines the mechanism
for combining stochastic and structured (in this case
Context-Free) grammars as well as methods for combined semantic
definitions. Since some structured grammars are also stochastic,
we will avoid confusion from here on by only referring to these
grammars as N-Gram grammars, or in some cases simply N-Grams.
An N-Gram grammar is a representation of an N-th order Markov
language model in which the probability of occurrence of a symbol
is conditioned upon the prior occurrence of N-1 other symbols.
N-Gram grammars are typically constructed from statistics
obtained from a large corpus of text using the co-occurrences of
words in the corpus to determine word sequence probabilities.
N-Gram grammars have the advantage of be able to cover a much
larger language than would normally be derived directly from a
corpus. Open vocabulary applications are easily supported with
N-Gram grammars.
This specification is influenced by a variety of preceding
N-Gram grammar formats. This specification is not explicitly
based on any particular preceding format. Concepts are similar
but the syntax is largely original in this specification due to
the XML parent language.
This specification is written to be consistent with the
corresponding Context-Free Grammar (CFG) XML format specified in
a companion document entitled "Speech
Recognition Grammar Specification for the W3C Speech Interface
Framework". At some point in the near future it is expected
that these documents will be unified to ensure consistency among
the common components of the specifications. To simplify this
unification this document also borrows from some of the CFG
examples. In maintaining such consistency the XML form of the
deterministic grammar format will the primary definition followed
in this specification to maintain compatibility with the XML
based N-Gram format defined here. Specifications will be defined
in lavender boxes and
examples will be given in green
boxes.
Why N-Grams?
In simple speech recognition/speech understanding systems, the
expected input sentences are often modeled by a strict grammar
(such as a CFG). In this case, the user is only allowed to utter
those sentences, that are explicitly covered by the (often
hand-written) grammar. Experience shows that a context free
grammar with reasonable complexity can never foresee all the
different sentence patterns, users come up with in spontaneous
speech input. This approach is therefore not sufficient for
robust speech recognition/understanding tasks or free text input
applications such as dictation.
N-Gram language models are traditionally used in large
vocabulary speech recognition systems to provide the recognizer
with an a-priori likelihood P(W) of a given word sequence
W. The N-Gram language model is usually derived from large
training texts that share the same language characteristics as
expected input. This information complements the acoustic model
P(W|O) that models the articulatory features of the
speakers. Together, these two components allow a system to
compute the most likely input sequence W' = argmaxW
P(W|O), where O is the input signal observations as
W' = argmaxW P(O|W) P(W).
In contrast, N-Gram language models rely on the likelihood of
sequences of words, such as word pairs (in the case of bigrams)
or word triples (in the case of trigrams) and are therefore less
restrictive. The use of stochastic N-Gram models has a long and
successful history in the research community and is now more and
more effecting commercial systems, as the market asks for more
robust and flexible solutions.
There are many possible ways to combine N-Gram models and
context free grammars within a single voice browser system such
as
- using an N-Gram model in the recognizer and a CFG in a
(separate) understanding component
- integrating special N-Gram rules at various levels in a CFG
to allow for flexible input in specific context
- using a CFG to model the structure of phrases (e.g. numeric
expressions) that incorporated in a higher-level N-Gram model
(class N-Grams)
For this reason, cross-referencing between N-Gram models and
CFGs is an important feature of the markup described below.
Most former publicly available N-Gram grammar file formats use
log probabilities to represent the word sequence probabilities.
For small amount of training data or missing data sequences,
backoff weights are also often precomputed and included in the
format. In the format presented here we depart from this
tradition and represent the core statistical information with
word sequence event counts.
Motivations for using counts includes:
- using counts leaves the decision on the actual implementation
of the N-Gram model to the platform
- counts allow for a data reduction (both, by using integer
instead of float and by allowing for pruning)
- counts are more robust in terms of manipulations of the
tree
Backoff weights are eliminated from the required components of
the format since these weights may be computed easily from the
count data. Backoff weights may optionally be included as an
addendum, to be described later.
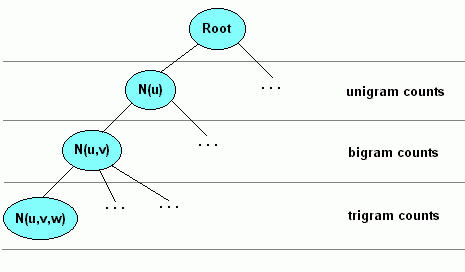
Another departure from traditional N-Gram file formats is the
presentation of data in depth-first rather than breadth-first
order. The two main advantages of this ordering are the
elimination of some redundancy, hence reducing file size, and
more convenient ordering for stream processing and data
loading.
The file format consists lines of data tuples, each
representing a branch and the succeeding node of the grammar
tree. The branch data is a list of indices representing the word
sequence of the N-Gram. Following the word sequence data is a
list of one or two integers representing the node branching
factor and event count. Consistent with this tuple per line
format, the first entry is a 'zerogram', a virtual null branch
with successor node being the actual root of the grammar tree
(see pseudo-code example later).
The root node is followed by the corresponding unigram branch
and node data, followed by similar data for p=2,3,...,L until the
leaf ply L is reached (a ply is the set of branches
at a given depth). If cutoff has been applied, then L<N, the
order of the N-Gram model. This is followed by other set members
of plies (L-1) and (L) until the branch set of ply (L-1) is
exhausted, at which point another member of ply (L-2) is
presented and the process repeated at ply (L-1). This process is
continued until all branches of ply p=1 have been exhausted.
The N-Gram Grammar declaration is consistent with the XML
format of the structural grammar specification as described in
Section 4.2 of that document. The document type
definition for the N-Gram specification is given in Section
11.
The following example, borrowed and modified from that
specification, is extended as shown, where []'s indicate optional
components. Following the XML convention the language and variant
are indicated by a "xml:lang" attribute on the root "grammar"
element.
<N-Gram xml:lang="en-US">
[importation declarations]
[lexicon declaration
[N-Gram event counts
[backoff weights] [semantic tags]]]
[interpolation of models]
</n-gram>
A single optional grammar declaration is allowed in the XML
grammar document. This grammar declaration may be imported into a
parent N-Gram or CFG declaration and may in turn import other
N-Gram or CFG declarations as described by import rules (cf. Section 4). The lexicon, which is required if
N-Gram counts are specified, contains index definition of symbols
that may represent speech events (i.e. words) or references to
other grammars or grammar rules (cf. Section
5). The N-Gram event counts are presented in a depth-first
order format described in Section 6.
Optionally, precomputed backoff weights may be declared (cf. Section 7), and optional distant or skip N-Grams
may be declared (cf. Section 8). In the event
that all optional sections of the grammar declaration are
missing, the grammar is a null grammar equivalent to an
epsilon-transition or zerogram model.
Importation declarations in the superior grammar may be used
to import components of an inferior grammar. Importation
declarations of inferior N-Gram grammars may be used to declare
additional event counts to be added to the union of N-Gram event
counts in the superior grammar. If desired, the entire superior
N-Gram grammar may be constructed solely from imported grammars.
This is particularly useful for applying variable count cutoff
computation at the server using a CGI query, as illustrated in
the first example, thus altering the default cutoff to save
download time. Importation of backoff weights is generally not
useful since modification of the event counts generally alters
the full set of backoff weights, which should be recomputed after
all N-Gram event counts are compiled.
An arbitrary number of importation rules may optionally be
declared as follows:
<import uri="protocol://host/path/path_info?query_string"
name="namestring"/>
The name attribute is optional. The absence of the
name attribute indicates that the imported grammar, which must be
an N-Gram grammar, will be treated as a contribution to the
superior N-Gram grammar and added to the union of N-Gram event
counts of the superior grammar. The presence of a
name attribute indicates that the imported grammar is
an inferior grammar to be referenced by the superior grammar as
described later.
For example:
<import uri=
"http://www.example.com/ngram.pl/mygrammar.g?depth=3"/>
<import uri=
"http://www.grammars.com/cities-states.xml"
name="places"/>
... <gramref import="mygrammar"/> ...
... <ruleref import="places#start"/> ...
In the first import example the general purpose Perl script
ngram.pl can process any raw N-Gram event count
file, such as mygrammar.g, to produce the proper XML
formatted N-Gram declaration while trimming the file contents at
the server. The second import example is a simple file transfer
of an inferior named N-Gram grammar.
The corresponding CFG compatible references are shown. The
first example shows a reference to a grammar. Generally starting
tokens are determined by the monogram probabilities of the N-Gram
model. The second example shows a reference to a grammar and a
particular starting symbol. The starting symbol in this case can
be acoustically null and used simply to set preconditions for the
real starting symbols. Then the real starting symbols will be
conditioned only on the start symbol or histories starting with
the start symbol.
In principle, it is possible to import named N-Gram grammars
into a CFG and vice versa. Yet another alternative is to import a
named inferior N-Gram grammar into a superior N-Gram grammar. In
practice, the utility of some combinations may be limited,
however since it is easy to define the appropriate syntax, this
is done to provide maximum flexibility.
Each of these alternatives requires an additional reference
mechanism. To be consistent with the CFG rule reference
specification,
Section 2.2, this rule reference format may also be used
in the N-Gram lexicon declaration (cf. Section
5). Hence, a symbol in an N-Gram lexicon can reference a
named N-Gram grammar, N-Gram rule, or a CFG rule. Several start
symbols can be defined for an N-Gram grammar and referenced by an
appropriate <ruleref ...>.
The N-Gram lexicon section consists of a single lexicon tag
set containing lexical entries to define indices for the
succeeding N-Gram event count rules. A lexical entry may contain
a word symbol or rule reference. Rule references are always
references to an external inferior grammar rule.
A lexicon may optionally be declared as follows:
<lexicon>
<token index="1">
word1
</token>
<token index="4">
how many
</token>
<token index="2">
<ruleref import="cfg_places#city"/>
</token>
<token index="3">
<ruleref import="ngram_places#ngram_places"/>
</token>
<token index="5">
<ruleref import="ngram_class#ngram_class"/>
</token>
...
</lexicon>
or as follows:
<lexicon order="sequential">
<token>
word1
</token>
<token>
how many
</token>
<token>
<ruleref import="cfg_places#city"/>
</token>
<token>
<ruleref import="ngram_places#ngram_places"/>
</token>
<token>
<ruleref import="ngram_class#ngram_class"/>
</token>
...
</lexicon>
Tokens must be indexed with non-negative integers. Numbering
should be contiguous to minimize storage needed for indexing, but
this is not required and the data can be presented in any
particular order. If the order="sequential"
attribute is present then indexing is implicitly numbered
sequentially starting from one.
In the first example a simple word token is declared. This is
the most conventional lexicon entry. The second example indicates
a "super-word" or word phrase that is used when the co-occurrence
of words is so frequent that they might as well be treated as a
single word.
The third example shows a reference to an external CFG rule.
In practice such grammars have not been used, but in principle it
is possible to parse and count small CFG phrase sequences in a
corpus to generate event counts. The fourth and fifth examples
are references to external named N-Gram grammars, the last being
treated as a class or category grammar element (cf. Section 10).
The format of the N-Gram event count declaration deviates from
the pure XML format because of the need for the efficiency of a
compact representation. N-Gram grammars are generally quite large
and would require very large file sizes, thus putting a burden on
the communications network.
To clearly explain the depth-first N-Gram event count
specification format a pseudo-code example is first presented.
Suppose we have the pseudo-corpus "A B A B C".
Then the pseudo-coded N-Gram specification for N=3 is:
// zerogram: 3 seen unigrams; total token count is 5
"" <3> 5
// unigram: 1 seen bigram preconditioned on "A"; 2 instances
"A" <1> 2
// bigram: 2 trigrams preconditioned on "A B"; 2 instances
"A B" <2> 2
"A B A" <0> 1 // trigram: leaf of tree; 1 instance
"A B C" <0> 1
"B" <2> 2
"B A" <1> 1
"B A B" <0> 1
"B C" <0> 1
"C" <0> 1
Zerogram information represents the root node of a tree. In
this case 5 token instances of 3 distinct token types were seen
in the corpus. The leaf nodes are indicated by specifying zero
inferior branches. Since this value is always zero at the leaves,
this information can simply be deleted.
The token types can be super-word tokens or even grammar
instances. For example, if "A B" is a token then the
pseudo-corpus would appear to consist of 3 tokens total and there
would be 2 token types. In the event that tokens like "A A" are
chosen and the corpus contains long strings of "A" then it is the
responsibility of the N-Gram designer to determine the proper
interpretation.
A grammar token example can be treated in similar manner.
Consider a token defined by the grammar "A B (A | C)", that is
the string "A B" followed by either "A" or "C". Then the
pseudo-corpus has 2 instances of this "token". Interpretation of
string overlaps in the corpus is at the discretion of the N-Gram
designer. The N-Gram declaration is defined with the
tree element and requires a lexicon
declaration. The <tree> element can have an
additional 'gap' attribute which is used for distant N-Grams (see
Section 8).
Following the example a complete declaration is:
<lexicon>
<token index="1"> A </token>
<token index="2"> B </token>
<token index="3"> C </token>
</lexicon>
<tree>
3,5;
1,1,2;
2,2,2;
1,1;
3,1;
2,2,2;
1,1,1;
2,1;
3,1;
3,1;
</tree>
Intraline delimiters are commas and semi-colons are used to
indicate the end of an N-Gram rule. White space is not
significant within the <tree> scope. Note that if pruning
has been performed then the branching values must be recomputed
accordingly. The depth of the tree is implied by the structure of
the data. Line breaks are significant in this format since the
leaf branch counts have been elided.
Backoff weights can be declared in the case of a simple N-Gram
declaration without importation.
Following the example a declaration of backoff weights is:
<lexicon>
<token index="1"> A </token>
<token index="2"> B </token>
<token index="3"> C </token>
</lexicon>
<tree>
3,5;
1,1,2:0.543;
2,2,2:0.54;
1,1;
3,1;
2,2,2:0.54;
1,1,1:0.543;
2,1;
3,1;
3,1;
</tree>
Weight delimiters are colons. Backoff weights may only be
attached to non-leaf elements and are indicated by a leading
colon. The computation of backoff weights follows the well-known
ARPA format.
In addition to floating point format, a scaled integer format
is supported. The <tree> element is modified to include a
scale attribute as follows:
Following the example a scaled integer equivalent declaration
of backoff weights is:
<lexicon>
<token index="1"> A </token>
<token index="2"> B </token>
<token index="3"> C </token>
</lexicon>
<tree backoff-scale="1000">
3,5;
1,1,2:543;
2,2,2:540;
1,1;
3,1;
2,2,2:540;
1,1,1:543;
2,1;
3,1;
3,1;
</tree>
Weight delimiters are colons. Backoff weights may only be
attached to non-leaf elements and are indicated by a leading
colon. Backoff weights are computed by dividing the scaled
integer by the backoff-scale.
Distant or skip N-Grams are used to cover long-range
dependencies with N-Gram models with a small N. This is done by
introducing a gap of a certain length between a word and its
history.
For the corpus "A B C D E F G H", a regular trigram model
would provide counts for the events "A B C", "B C D", and so on.
From these counts, the likelihood P(C | A B), P(D | B C) and so
on can be derived. In contrast, a distant N-Gram with a gap of 1
provides counts for AB..D, BC..E, and so on to create likelihood
Pgap(D | A B), Pgap(E | B C).
For the corpus "A B C A B D E" we could get the following
gap=1 declaration:
<tree gap="1" depth="3">
5,7; // "" <5> 7 zerogram
1,1,2; // "A" <1> 2 unigram; 1 seen (regular) bigram; 2 instances
2,2,2; // "AB" <2> 2 bigram; 2 distant trigrams, 2 instances
3,1; // "AB_C <0> 1
4,1; // "AB_D <0> 1
2,2,2; // "B" <2> 2 unigram; 2 seen (regular) bigram; 2 instances
3,1,1; // "BC" <1> 1 bigram; 1 distant trigram, 1 instance
1,1; // "BC_A <0> 1
4,1,1; // "BD" <1> 1 bigram; 1 distant trigram, 1 instance
5,1; // "BD_E <0> 1
3,1,1; // "C" <1> 1 unigram; 1 seen (regular) bigram; 1 instance
1,1,1; // "CA" <1> 1 bigram; 1 distant trigram, 1 instance
2,1; // "CA_B <0> 1
4,1,1; // "D" <1> 1 unigram; 1 seen (regular) bigram; 1 instance
5,1; // "DE" <1> 1 bigram; 0 distant trigram, 1 instance
</tree>
Distant N-Grams are stored in the same tree structure as
regular N-Grams. Assuming that the 'gap' always occurs between
the current word and its history, only the length of the gap has
to be specified. This is done using the 'gap' attribute of the
<tree> tag. The value of this optional
parameter defaults to zero, which is identical to a regular
N-Gram model.
Note: In this tree format, we can only fall back from the
distant trigram to a regular bigram, not to a distant bigram.
Fallback to gap N-Grams would require a different ordering of the
tree.
9.1 Linear Interpolation
An N-Gram language model can be constructed from a linear
interpolation of several models. In this case, the overall
likelihood P(w|h) of a word w occurring after the history h is
computed as the arithmetic average of P(w|h) for each of the
models.
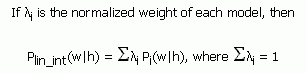
Interpolated models are represented by the
<interpolation> element. This contains
multiple <component> elements, which represent
each model. The 'weight' attribute on the
<component> element is used to specify the
relative weight of each model. The sum of all weights for each
<interpolation> element does not have to add
up to 1.0, and the platform is responsible for normalization.
For interpolated models, no common lexicon is defined. Instead
each of the <component> models specifies its
own lexicon. The platform is responsible for combining these
lexica.
Example:
<n-gram>
<import uri="http://www.example.com/classlms.xml"
name="lm1" />
<import uri="http://www.example.com/trigram.xml"
name="lm2" />
<interpolation type="linear">
<component weight=0.25>
<ruleref import="lm1"/>
</component>
<component weight=0.75>
<ruleref import="lm2"/>
</component>
</interpolation>
</n-gram>
9.2 Log-Linear Interpolation
The default interpolation method is linear interpolation. In
addition, log-linear interpolation of models is possible. In this
case, the 'type' attribute on the
<interpolation> must be set to "log".
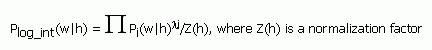
Class grammars, sometimes also called category grammars, can
be declared using the N-Gram grammar format with N=1. Therefore
no additional special markup language is needed for the
declaration of class grammars. Continuing the example of Section 6, let us declare that "A" and "C" are
equally probable members of a class named "firstclass".
Declare the class in a separate grammar file as follows:
<n-gram>
<lexicon>
<token index="1"> A </token>
<token index="2"> C </token>
</lexicon>
<tree>
2,2;
1,1;
2,1;
</tree>
</n-gram>
Note that since this is a grammar of depth one it can easily
be recognized and treated as a class. If desirable, non-uniform
probability distribution can be assigned by defining the
appropriate counts.
Then the class based N-Gram grammar for our pseudo-corpus is
declared as follows:
<n-gram>
<import uri="http://www.example.com/firstclass.xml"
name="firstclass" />
<lexicon>
<token index="1">
<ruleref import="firstclass#firstclass"/>
</token>
<token index="2"> B </token>
</lexicon>
<tree>
2,5;
1,1,3;
2,1,2;
1,2;
2,1,2;
1,1,2;
2,1;
</tree>
</n-gram>
Given this N-Gram declaration the input string "A B A B C" is
now interpreted to yield "X(A) B X(A) B X(C)" where "X(A)"
represents an instance of member "A" of class "firstclass".
This is the XML document type definition for the N-Gram
specification:
<!-- W3C Stochastic Language Model (N-Gram) Specification -->
<!-- this is the root element -->
<!ELEMENT N-Gram (import*, ((lexicon, tree) | interpolation)?)>
<!ATTLIST N-Gram
xml:lang NMTOKEN #IMPLIED>
<!ELEMENT import>
<!ATTLIST import
uri CDATA #REQUIRED
name NMTOKEN #IMPLIED>
<!ELEMENT lexicon (token+)>
<!ATTLIST lexicon
order (default | sequential) "default">
<!ELEMENT token (#PCDATA | ruleref | gramref)>
<!ATTLIST token
index NMTOKEN #IMPLIED>
<!ELEMENT ruleref>
<!ATTLIST ruleref
import CDATA #REQUIRED>
<!ELEMENT gramref>
<!ATTLIST gramref
import CDATA #REQUIRED>
<!ELEMENT tree (#PCDATA)>
<!ATTLIST tree
backoff-scale NMTOKEN #IMPLIED
gap NMTOKEN "1"
depth NMTOKEN #IMPLIED>
<!ELEMENT interpolation (component+)>
<!ATTLIST interpolation
type (linear | log) "linear">
<!ELEMENT component (ruleref | gramref)>
<!ATTLIST component
weight NMTOKEN #IMPLIED>
The following pure XML format is not required for compliance,
but is suggested for those who prefer use a pure XML reader.
The N-Gram declaration is defined with the tree
element and requires a lexicon declaration.
Following the example a complete declaration is:
<lexicon>
<token index="1"> A </token>
<token index="2"> B </token>
<token index="3"> C </token>
</lexicon>
<tree>
<node branches="3" count="5" />
<node index="1" branches="1" count="2" />
<node index="2" branches="2" count="2" />
<node index="1" count="1" />
<node index="3" count="1" />
<node index="2" branches="2" count="2" />
<node index="1" branches="1" count="1" />
<node index="2" count="1" />
<node index="3" count="1" />
<node index="3" count="1" />
</tree>
Note that if pruning has been performed then the branching
values must be recomputed accordingly. The depth of the tree is
implied by the structure of the data.
Yet another suggested XML format is somewhat more compact and
less readable, but is not dependent upon line breaks for proper
reading.
The N-Gram declaration is defined with the tree
element and requires a lexicon declaration.
Following the example a complete declaration is:
<lexicon>
<token index="1"> A </token>
<token index="2"> B </token>
<token index="3"> C </token>
</lexicon>
<tree>
<node> 3 5 </node>
<node> 1 1 2 </node>
<node> 2 2 2 </node>
<node> 1 1 </node>
<node> 3 1 </node>
<node> 2 2 2 </node>
<node> 1 1 1 </node>
<node> 2 1 </node>
<node> 3 1 </node>
<node> 3 1 </node>
</tree>
Semantic tags can be attached to N-Gram events. This may be
particularly useful for class grammars where several alternative
expressions with the same semantics should yield the same output,
i.e. the semantic tag. If defined, semantic tags take precedence
over other interpretations.
Continuing our example, we declare the occurrence of "B X" and
"X B" to be identical semantic events of type "BX", where "X"
represents an instance of class "firstclass".
Then the class based N-Gram grammar for our pseudo-corpus is
declared as follows:
<n-gram>
<import uri="http://www.example.com/firstclass.xml"
name="firstclass" />
<lexicon>
<token index="1">
<ruleref import="firstclass#firstclass"/>
</token>
<token index="2"> B </token>
</lexicon>
<tree>
2,5;
1,1,3;
2,1,2;<tag name="BX"/>;
1,2;
2,1,2;
1,1,2;<tag name="BX"/>;
2,1;
</tree>
</n-gram>
Semantic tags are written in XML format and appended to the
appropriate N-Gram count declaration. Please note that further
study is planned for semantic markup for N-Grams.
The following pure XML format is not required for compliance,
but is suggested for those who prefer to use a pure XML reader.
Following the example a complete declaration is:
<n-gram>
<import uri="http://www.example.com/firstclass.xml"
name="firstclass" />
<lexicon>
<token index="1">
<ruleref import="firstclass#firstclass"/>
</token>
<token index="2"> B </token>
</lexicon>
<tree>
<node branches="2" count="5" />
<node index="1" branches="1" count="3" />
<node index="2" branches="1" count="2" name="BX" />
<node index="1" count="2" />
<node index="2" branches="1" count="2" />
<node index="1" branches="1" count="2" name="BX" />
<node index="2" count="1" />
</tree>
</n-gram>
Naming a node replaces the normal syntactic output with the
semantic tag name. Hence, input string "A B A B C" will now yield
the interpretation "BX BX X(C)" indicating the occurrence of two
semantic events "BX" followed by an instance of member "C" of
class "X". This can be treated as the only interpretation if
precedence of semantic tags is imposed. Without precedence other
possible interpretations include: "BX X(A) BX"; "BX X(A) B X(C)";
"X(A) BX BX"; "X(A) BX B X(C)"; "X(A) B BX X(C)"; "X(A) B X(A)
BX"; "X(A) B X(A) B X(C)".
For further information on stochastic language models, you
are recommended to look at:
"Speech and Language Processing: An introduction to Natural
Language Processing, Computational Linguistics, and
Speech Processing", Daniel Jurafsky & James H. Martin,
published 2000 by Prentice-Hall. ISBN 0-13-095069-6.