W3C Multimodal Interaction
Framework
W3C NOTE 06 May 2003
- This version:
-
http://www.w3.org/TR/2003/NOTE-mmi-framework-20030506/
- Latest version:
-
http://www.w3.org/TR/mmi-framework/
- Previous version:
-
http://www.w3.org/TR/2002/NOTE-mmi-framework-20021202/
- Editors:
- James A. Larson, Intel
- T.V. Raman, IBM
- Dave Raggett, W3C & Canon
- Contributors:
- Michael Bodell, Tellme Networks
- Michael Johnston AT&T
- Sunil Kumar V-Enable Inc.
- Stephen Potter, Microsoft
- Keith Waters France Telecom
Copyright © 2003 W3C® (MIT, ERCIM,
Keio), All Rights Reserved. W3C
liability,
trademark,
document use
and software
licensing rules apply.
Abstract
This document introduces the W3C Multimodal Interaction
Framework, and identifies the major components for multimodal
systems. Each component represents a set of related functions. The
framework identifies the markup languages used to describe
information required by components and for data flowing among
components. The W3C Multimodal Interaction Framework describes
input and output modes widely used today and can be extended to
include additional modes of user input and output as they become
available.
Status of this Document
This section describes the status of this document at the
time of its publication. Other documents may supersede this
document. The latest status of this document series is maintained
at the W3C
.
W3C's Multimodal
Interaction Activity is developing specifications for extending
the Web to support multiple modes of interaction. This document
introduces a functional framework for multimodal interaction and is
intended to provide a context for the specifications that comprise
the W3C Multimodal Interaction Framework.
This document has been produced as part of the
W3C Multimodal Interaction
Activity, following the procedures set out for the
W3C Process .
The authors of this document are members of the
Multimodal Interaction
Working Group
(W3C Members
only ). This is a Royalty Free Working Group, as described in
W3C's Current
Patent Practice NOTE. Working Group participants are required
to provide patent
disclosures .
Please send comments about this document to the public mailing
list:
www-multimodal@w3.org
(public
archives ). To subscribe, send an email to
www-multimodal-request@w3.
org with the word subscribe in the subject line
(include the word unsubscribe if you want to
unsubscribe).
A list of current W3C Recommendations and other technical
documents including Working Drafts and Notes can be found at
http://www.w3.org/TR/ .
1. Introduction
The purpose of the W3C multimodal interaction framework is to
identify and relate markup languages for multimodal interaction
systems. The framework identifies the major components for every
multimodal system. Each component represents a set of related
functions. The framework identifies the markup languages used to
describe information required by components and for data flowing
among components.
The W3C Multimodal Interaction Framework describes input and
output modes widely used today and can be extended to include
additional modes of user input and output as they become
available.
The multimodal interaction framework is not an
architecture . The multimodal interaction framework is a level
of abstraction above an architecture. An architecture indicates how
components are allocated to hardware devices and the communication
system enabling the hardware devices to communicate with each
other. The W3C Multimodal Interaction Framework does not describe
either how components are allocated to hardware devices or how the
communication system enables the hardware devices to communicate.
See Section 6 for descriptions of several example architectures
consistent with the W3C multimodal interaction framework.
2. Basic Components of the W3C Multimodal Interaction
Framework
The Multimodal Interaction Framework is intended as a basis for
developing multimodal applications in terms of markup, scripting,
styling and other resources. The Framework will build upon a range
of existing W3C markup languages together with the
W3C Document Object Model
(DOM). DOM defines interfaces whereby programs and scripts
can dynamically access and update the content, structure and style
of documents.
Figure 1 illustrates the basic components of the W3C multimodal
interaction framework.
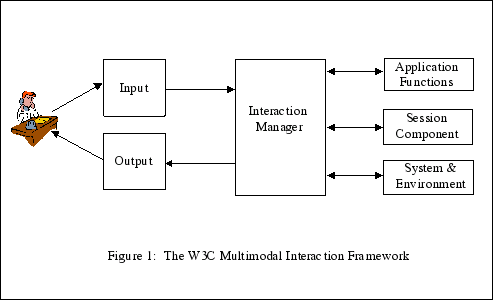
Human user — A user who enters input into the
system and observes and hears information presented by the system.
In this document, we will use the term "user" to refer to a human
user. However, an automated user may replace the human user for
testing purposes. For example, an automated "testing harness" may
replace human users for regression testing to verify that changes
to one component do not affect the user interface negatively.
Input — An interactive multimodal implementation
will use multiple input modes such as audio, speech, handwriting,
and keyboarding, and other input modes. The various modes of input
will be described in Section 3.
Output — An interactive multimodal implementation
will use one or more modes of output, such as speech, text,
graphics, audio files, and animation. The various modes of output
will be described in Section 4.
Interaction manager — The interaction manager is
the logical component that coordinates data and manages execution
flow from various input and output modality component interface
objects. The input and output modality components are as described
in Section 5.
The interaction manager maintains the interaction state and
context of the application and responds to inputs from component
interface objects and changes in the system and environment. The
interaction manager then manages these changes and coordinates
input and output across component interface objects. The
Interaction manager is discussed in section
6.
In some architectures the interaction manager may be implemented
as one single component. In other architectures the interaction
manager may be treated as a composition of lesser components.
Composition may be distributed across process and device
boundaries.
Session component — The Session component
(discussed in Section 7) provides an interface to
the interaction manager to support state management, and temporary
and persistent sessions for multimodal applications. This will be
useful in the following scenarios but is not limited to these:
- A user is interacting with an application which runs on
multiple devices.
- The application is session based e.g. multiplayer game,
multimodal chat, meeting room etc.
- The application provides multiple modes of providing input and
receiving output.
- The application runs on a single device and needs to experience
multimodality by switching modes.
System and Environment component — This component
enables the interaction manager to find out about and respond to
changes in device capabilities, user preferences and environmental
conditions. For example, which of the available modes, the user
wishes to use — has the user muted audio input? The
interaction manager may be interested in the width and height of
the display, whether it supports color, and other capability and
configuration information. For more information see
Section 8
3. Input Components
Figure 2 illustrates the various types of components within the
input component.

-
Recognition component — Captures natural input
from the user and translates the input into a form useful for later
processing. The recognition component may use a grammar described
by a grammar markup language. Example recognition components
include:
- Speech — Converts spoken speech into text. The
automatic speech recognition component uses an acoustic model, a
language model, and a grammar specified using the W3C Speech
Recognition Grammar or the Stochastic Language Model (N-Gram)
Specification to convert human speech into words specified by the
grammar.
- Handwriting — Converts handwritten symbols and
messages into text. The handwriting recognition component may use a
handwritten gesture model, a language model, and a grammar to
convert handwriting into words specified in a grammar.
- Keyboarding — Converts key presses into textual
characters
- Pointing device — Converts button presses into
x-y positions on a two-dimensional surface
Other input recognition components may include vision, sign
language, DTMF, biometrics, tactile input, speaker verification,
handwritten identification, and other input modes yet to be
invented.
-
Interpretation component — May further process
the results of recognition components. Each interpretation
component identifies the "meaning" or "semantics" intended by the
user. For example, many words that users utter such as "yes,"
"affirmative," "sure," and "I agree," could be represented as
"yes."
-
Integration component — Combines the output from
several interpretation components
Some or all of the functionality of this component could be
implemented as part of the recognition, interpretation, or
interaction components. For example, audio-visual speech
recognition may integrate lip movement recognition and speech
recognition as part of a lip reading component, as part of the
speech recognition component, or integrated within a separate
integration component. As another example, the two input modes of
speaking and pointing are used in
"put that," (point to an object), "there,"
(point to a location)
and may be integrated within a separate integration component or
may be integrated within the interaction manager component.
Information generated by other system components may be
integrated with user input by the integration component. For
example, a GPS system generates the current location of the user,
or a banking application generates an overdraft to prohibit the
user from making additional purchases.
The output for each interpretation component may be expressed
using EMMA, a language for representing the semantics or meaning of
data. Either the user or the system may create information
that may be routed directly to the interaction manager without
being encoded in EMMA. For example, audio is recorded for later
replay or a sequence of keystrokes is captured during the creation
of a macro.
4. Output Components
Figure 3 illustrates the components within the output
component.
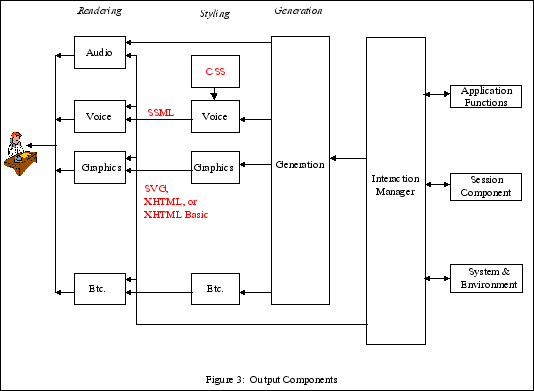
Information from the interaction manager may be routed directly
to the appropriate rendering device without being encoded in an
internal representation. For example, recorded audio is send
directly to the audio system.
-
Styling component — This component adds
information about how the information is "layed out." For example,
the styling component for a display specifies how graphical objects
are positioned on a canvas, while the styling component for audio
may insert pauses and voice inflections into text which will be
rendered by a speech synthesizer. Cascading Style Sheets (CSS)
could be used to modify voice output.
-
Rendering component — The rendering component
converts the information from the styling component into a format
that is easily understood by the user. For example, a graphics
rendering component rectangle displays a vector of points as a
curved line, and a speech synthesis system converts text into
synthesized voice.
Each of the output modes has both a styling and rendering
component.
The voice styling component constructs text strings containing
Speech Synthesis Markup Language tags describing how the words
should be pronounced. This is converted to voice by the voice
rendering component. The voice styling component may also select
prerecorded audio files for replay by the voice rendering
component.
The graphics styling component creates XHTML, XHTML Basic, or
SVG markup tags describing
how the graphics should be rendered. The graphics rendering
component converts the output from the graphics styling component
into graphics displayed to the user.
Other pairs of styling and rendering components are possible for
other output modes.
SMIL may be used for
coordinated multimedia output.
5. Specification of input and output components
This section describes how the input and output components of
sections 3 and 4 are specified. In brief, input and output
components of the user interface will be specified as DOM objects
that expose interfaces pertaining to that object's functionality.
This enables the modality objects to be accessed and
manipulated in the interaction management environments described in
section 6.
(The use of the term "object" in this section is intended in the
sense of "object" as used in the Document Object Model, and is not
intended to imply a particular class or object hierarchy.)
5.1 Encapsulated interfaces based on DOM
User interface components make their functionality available to
interaction managers through a set of interfaces, and can be
considered as receiving values from and returning values to the
host environment. Here, values can be simple or complex types, and
components can specify the location for binding the received data,
perhaps using XPath, which is W3C's language for addressing parts
of an XML document, and was originally designed to be used by both
XSLT and XPointer. The set of interfaces will be built on DOM, and
thereby provide an object model for realizing the functionality of
a given modality.
The functionality of a user interface component can therefore
usefully be encapsulated in a programming-language-independent
manner into an object exposing the following kinds of
features:
- a set of properties (e.g. presentation parameters or
input constraints);
- a set of methods (e.g. begin playback or recognition);
and
- a set of events raised by the component (e.g. mouse
clicks, speech events).
The DOM defines a platform-neutral and
programming-language-neutral interface to documents, their
structure and their content. The user interface
objects extend this model by adding modality-specific
interfaces. In this way, user interface objects can
define abstract interfaces which are usable across different host
environments.
In multimodal applications, multiple user interface components
are controlled and coordinated individually by the interaction
manager.
User interface objects should follow certain
guidelines to integrate into the multimodal framework:
- adhere to the principles of encapsulation, that is, the
features of a given modality should relate only to the modality in
question;
- adopt common or recommended interfaces where possible;
- In order to insure that the framework is sufficiently
general to accommodate both local and distributed
architectures, avoid blocking calls and threading
issues.
- Consider what kinds of message exchange patterns are
needed, for instance, publish/subscribe, broadcast, and
specifically addressed messages. This is also an important
consideration for insuring that the framework is neutral with
respect to local and distributed architectures.
In general, the formalization of features into properties,
methods and events should not be taken to imply that the
manipulation of the interface can take place only in local DOM
architectures. It is the intention of this design that modality
interfaces should remain agnostic to component architectures where
possible. So the object feature definitions should be considered as
abstract indications of functionality, the uses of which will
probably differ according to architectural considerations (for
example property setting may take different forms, and
implementation mechanisms for event dispatch and handling are not
addressed here.)
5.2 Interface formalization
Each user interface object will specify a set of
interfaces in terms of properties, events and methods, using a
formal interface definition language. Bindings into XML, ECMAScript
and other programming languages will also be defined.
In addition to formal definition of markup and DOM interfaces, a
description of the execution model of the user interface
object will be defined, that is, the behaviour of the
object when used. Further, a user interface
object should also describe how it is
controlled in different interaction management environments, for
example, those which support:
- limited environments without programmatic capabilities;
- XHTML and its flavours, including scripting, DOM eventing,
XForms, etc.
- SMIL
- HTML
- SVG
- etc.
As work proceeds on the definition of individual modality
interfaces, sufficient commonality of features may be found such
that it is desirable to standardize in some way those features
across different modalities. As such, the MMI group will
investigate the possibilities for establishing a set of common
interfaces that may be shared among all relevant modalities
6. Specification of interaction management
component
6.1 Host Environments for interaction management
The interaction manager is a logical component. The interaction
manager is contained in the host environment that hosts interface
objects. Interface objects influence one another by interacting
with the Host Environment. A host environment provides data
management and flow control to its hosted interface objects. Some
languages that may be candidates as Host Environment languages
include SVG,
XHTML (possibly
XHTML+
XForms), and
SMIL.
A Host Environment's hosted interface objects may range from the
simple to the complex. Authors will be able to specify the
interface object components through a mixture of markup, scripting,
style sheets, or any other resources supported by their Host
Environment's functionality. The Host Environment design makes
possible architectures where the interface objects may each have
their own thread of execution independent from context of the Host
Environment. The design also supports each component communicating
asynchronously with the Host Environment (however familiarity with
synchronization primitives such as mutexes will not be required to
successfully author multimodal documents).
In some architectures, it is possible to have a hierarchical
composition of Host Environments similar in spirit to Russian
nesting dolls. Different aspects of interaction management may be
handled at different levels of the hierarchy. For example,
"barge-in", where speech output is cut off on the basis of user
input, is an interaction management mechanism that may handled by
one lower level Environment that just hosts the basic speech input
and speech output objects while a different higher level Host
Environment coordinates the multimodal application. Hierarchical
interaction management also enables the delegation of complex input
tasks to lower levels of the hierarchy. As an example, a date
dialog might encapsulate the necessary interaction management logic
needed to produce appropriate tapered prompts, error handling, and
other dialog constructs to eventually collect a valid date. This
form of nesting enables the creation of hierarchical interaction
management that reflects the task hierarchy within the overall
application.
7. Session Component
An important goal of the W3C Multimodal Interaction Framework is
to provide a simplified approach for authoring multimodal
applications whether on a single system/user or distributed across
multiple systems/users. The framework is architecture neutral, and
abstractly relies on passing messages between the various framework
components. The session component provides a means to simplify the
author's view of how resources are identified in terms of source
and destination of such messages. The session component is
particularly important for distributed applications involving more
than one device and/or user. It hides the details of the resource
naming schemes and protocols used and provides a high-level
interface for requesting and releasing resources taking part in the
session.
7.1 Functions of Session Component
7.1.1 Session as basis of state replication and
synchronization
The session component can be used for replicating state across
devices, or across processes within the same device. In a graphical
interface scenario running on a hand held device coupled to a voice
interface running in the network. The user can choose to navigate
or enter data using the device keypad or using speech. When filling
out a form, this gives two ways to update the field's value. The
session provides a scope for the replication mechanism and provides
a way to keep multiple modes in sync.
7.1.2 Temporary/Persistent Sessions
For certain applications the session is short lived. In theses
cases the same session may last for a single page or for several
pages as the user navigates through the application, for example
when visiting a web site. This makes it practical to retain state
information for the duration of the application. For applications
that involve persistent sessions such as meeting rooms, multiplayer
games, there is a need for session management, and a means to
locate, join and leave such sessions.
7.1.3 Simplifying Applications
In a distributed environment there are several ways to identify
a resource. The session component provides a means to query
descriptions of resources, including the type of the resource, what
properties the resource has, and what interfaces it supports.
7.2 Use Cases
The following use case provides the basis of defining session
component:
- Mobile Devices with sequential capability
Devices with limited capability provide a good example of the
importance of a session component. The sequential multimodality
allows user to experience multiple modes but only one mode at a
time. In such a scenario the user has to switch between modes to
experience multiple modes. In an application where the user is
filling out a form using voice as the input mode since voice is
preferred/easier mode for providing input. After the user has
provided the input the application saves the form fields in a
session object and switches the mode to visual. In visual mode the
application retrieves the values from session and uses the form
fields for further processing. An example of such application would
be Driving Directions application where the user provides source
and destination using voice mode and then selects directions from
visual mode to see the directions.
Form filling presents another use case for a session component.
Especially when partial information is filled using the keypad
attached to the device and partial information is filled using the
speech processed at the speech server in the network. For example
in an airline reservation system the user can provide date of
travel by clicking on appropriate dates in the calendar and provide
source and destination using speech which is processed in the
network. A session component helps in synchronizing the input
provided in either mode and provides filled form information back
to the application.
The session in this case is persistent and users join/leave the
session during the application. A session component allows a user
to query the session environment. A session environment would
consist of the resources and the values of the attributes in the
resources. In case of meeting room application the user can query:
i) who else is in the meeting room. ii) Get the information about a
particular member in the meeting room e.g. contact information,
whether the member is online etc.? The resources that application
wants its user to share is stored and proper interfaces are
provided to access the attributes of the resource.
- Multiple Device Applications
For multimodal applications running across multiple devices, the
session component can play an important role in the synchronization
of state across the devices. For example a user may be running an
application while sitting in a car using a device attached to the
car. The user gets off the car and goes to his office and wants to
continue with the application on his laptop that he was running in
the car. The session component provides interfaces to save the
state of the whole application on a device and reinstating the
whole state on another device. The few examples of such
applications could be video conferencing, online shopping, airline
reservations etc. For example in an airline reservation system, the
user selects the itinerary while he is still in the car. The user
gets out of the car and buys the same ticket using his laptop in
his office.
8. System and Environment Component
The W3C Multimodal
Interaction Requirements call for the ability for developers to
be able to create applications that
dynamically
adapt to changes in device capabilities, user preferences and
environmental conditions. The multimodal interaction framework must
allow the interaction manager to determine what information is
available, as this will be system dependent. In addition, the
framework must support stand-alone as well as distributed scenarios
involving multiple devices and multiple users (see
section 7 for more details).
It is expected that the system and environment component will
make use of the work of the
W3C Device Independence
activity, in particular the
CC/PP language, whose
aim is to standardize ways of expressing device features and
settings, and to describe how they are transmitted between
components. Profiles regarding multimodal-specific properties, such
as those listed below, are expected to be defined in accordance to
the CC/PP
Structure and Vocabularies specification.
8.1 User Case Scenarios
To illustrate the components functionality it is worth
considering the following few user case scenarios:
-
Mobile devices typically have limited capabilities and
resources, so that applications need to be tailored to the
specifics of the device. For example, many mobile phones have small
monochrome displays, while others have rich, fast color displays.
The following are typical characteristics of mobile devices that
can be provided to the Interaction Manager through the System and
Environment component:
-
Location information can be provided by an increasing
number of mobile devices. Typically this information is derived
from cell quadrant (cellular radio networks), GPS satellite data or
dead reckoning based on motion sensors. The Location
Interoperability Forum - now part of the
Open Mobile
Alliance — has been responsible for much of the work on
this to date. Location-based services (LBS) provide time stamped
location data of varying accuracy, in some circumstances, this can
be to within a few meters. This information can be provided upon
request at sub-second intervals. Multimodal applications can use
such information to orient maps and to provide geographically
relevant information.
-
Signal strength provides information on network
connectivity as well as the quality of service that can be
provided. As signal strength decreases a Multimodal application
could adapt accordingly. This could be as simple as switching to an
alternative low-bandwidth mode of communication.
-
Aural noise level for mobile devices is an important
consideration because of the variety of situations where the device
can be used, for example, noise from passing vehicles, other people
talking nearby, or loud music. Speech recognition can be tailored
based on noise levels returned by the System and Environment
component.
-
Battery level provides information on the remaining
operational time. Such a notification to the Interaction Manager is
particularly revelant to small un-tethered devices where power
consumption is critical.
-
Automotive — Multimodality is typically an on-board
capability that senses the local environment to determine what
services can be adapted to the drivers situation, for example:
-
Aural noise Level within the car can be generated and
modified by numerous environmental factors for example driving with
the windows down, radio volume, the AC/Fan on/off or windscreen
wipers on/off. Environmental conditions of the vehicle, controlled
by the driver, can be notified via the System Environment component
to the Interaction Manager to adapt the speech recognition.
-
In gear notifications could provide information on the
drivers ability to use a touch screen in a Multimodal application.
In addition there are legal ramifications associated with the
driver operating devices whilst the vehicle is in motion. Therefore
the general behavior of a Multimodal application may need to adapt
according to whether the vehicle is parked or "in-drive".
-
GPS notifications are an important feature of an on-board
Multimodal navigation system. The update frequency and accuracy of
updates being higher than typical LBS mobile services (see Mobile
section).
-
Desktop — Multimodal applications can be tailored
to the user's preferences. These choices can be dynamic or static
for example:
-
Static user preferences — the default volume
setting, the rate in words per minute for playing text to speech, a
general preference to using speech rather than a keyboard. People
with visual impairments may opt for easy to see large print text
and high contrast color themes.
-
Dynamic preferences — the user may suddenly mute
audio output, or switch from speech to pen input, and expect the
application to adapt accordingly. The application itself may
monitor's the user's progress, and react appropriately, for
example, prompting the user to use a pen after successive failures
with speech recognition.
8.2 System and Environment Component Categories
The above examples give a general indication of the
functionality that the System and Environment component offers as a
means for enabling applications to be tailored to adapt to device
capabilities, user preferences and environmental conditions.
-
Environmental conditions can be monitored and reported to
to the Interaction Manager. One way to look at these
characteristics is to inspect interference channels:
-
Auditory
-
Environment too noisy and bad for listening - the
application should adapt to this change to provide a better
experience.
-
A speaker system/headphone attached? A speaker system
allows the user to see the screen as well as listen at the same
time.
-
Car environment factors - radio on/off, radio volume,
AC/Fan on/off, windscreen wipers on/off windows up/down.
-
Visual
-
Tactile
-
System notifications can be derived from numerous
environmental sources, particularly within mobile and automotive
applications. Notifications from the System and Environment
component to the Interaction Manger can range from GPS location
information to the fact that the laptop has been closed. Many of
these system notifications indicate that the application should
switch to an alternative mode of operation.
-
User preferences help with tailoring the application to
the user. These characteristics are most apparent in rich
Multimodal scenarios such as the desktop where resources are less
of an issue (large screens and fast CPU's). Preferences can be
modified to best suit user choices. Furthermore, it is possible to
dynamically adapt to the users preferences overtime.
9. Illustrative Use Case
To illustrate the component markup languages of the W3C
Multimodal Interaction Framework, consider this simple use case.
The human user points to a position on a displayed map and speaks:
"What is the name of this place?" The multimodal interaction system
responds by speaking "Lake Wobegon, Minnesota" and displays the
text "Lake Wobegon, Minnesota" on the map. The following summarizes
the actions of the relevant components of the W3C Multimodal
Interaction Framework:
Human user — Points to a position on a map and
says, "What is the name of this place?"
Speech recognition component — Recognizes the
words "What is the name of this place?"
Mouse recognition component — Recognizes the x-y
coordinates of the position to which the user pointed on a map.
Speech interpretation component — Converts the
words "What is the name of this place?" into an internal
notation.
Pointing interpretation component — Converts the
x-y coordinates of the position to which the user pointed into an
internal notation.
Integration component — Integrates the internal
notation for the words "What is the name of this place?" with the
internal notation for the x-y coordinates.
Interaction manager component — Stores the
internal notation in the session object. Converts the request to a
database request, submits the request to a database management
system which returns the value of "Lake Wobegon, Minnesota". Add
the response to the internal notation in the session object The
interaction manager converts the response into an internal notation
and sends the response to the generation component.
Generation component — Access the Environment
component to determine that voice and graphics modes are available.
Decides to present the result as two complementary modes, voice and
graphics. The generation component sends internal notation
representing "Lake Wobegon, Minnesota" to the voice styling
component, and sends internal notation representing the location of
Lake Wobegon, Minnesota on a map to the graphics styling
component.
Voice styling component — Converts the internal
notation representing "Lake Wobegon, Minnesota" into SSML.
Graphics styling component — Converts the
internal notation representing the "Lake Wobegon, Minnesota"
location on a map into HTML notation.
Voice rendering component: Converts the SSML notation
into acoustic voice for the user to hear.
Graphics styling component: Converts the HTML notation
into visual graphics for the user to see.
10. Examples of Architectures Consistent with
the W3C Multimodal Interaction Framework.
There are many possible multimodal architectures that are
consistent with the W3C multimodal interaction framework. These
multimodal architectures have the following properties:
Property 1. THE MULTIMODAL ARCHITECTURE CONTAINS A SUBSET OF THE
COMPONENTS OF THE W3C MULTIMODAL INTERACTION FRAMEWORK. A
multimedia architecture contains two or more output modes.
A multimodal architecture contains two or more input
modes.
Property 2. COMPONENTS MAY BE PARTITIONED AND COMBINED. The
functions within a component may be partitioned into several
modules within the architecture, and the functions within two or
more components may be combined into a single module within the
architecture.
Property 3. THE COMPONENTS ARE ALLOCATED TO HARDWARE DEVICES. If
all components are allocated to the same hardware device, the
architecture is said to be centralized architecture . For
example, a PC containing all of the selected components has a
centralized architecture. A client-server architecture
consists of two types of devices, several client devices containing
many of the input and output components, and the server which
contains the remaining components. A distributed
architecture consists of multiple types of devices connected
by a communication system.
Property 4. THE COMMUNICATION SYSTEMS ARE SPECIFIED. Designers
specify the protocols for exchanging messages among hardware
devices.
Property 5. THE DIALOG MODEL IS SPECIFIED. Designers specify how
modules are invoked and terminated, and how they interpret input to
produce output.
The following examples illustrate architectures that conform to
the W3C multimodal interaction framework.
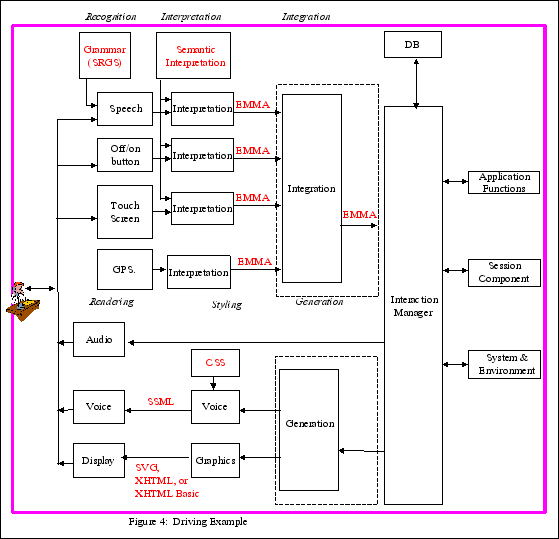
Example 1: Driving Example (Figure 4)
In this example, the user wants to go to a specific address from
his current location and while driving wants to take a detour to a
local restaurant (The user does not know the restaurant address nor
the name). The user initiates service via a button on his steering
wheel and interacts with the system via the touch screen and
speech.
Property 1. The driving architecture contains the components
illustrated in Figure 4: a graphical display, map database, voice
and touch input, speech output, local ASR, TTS Processing and
GPS.
Property 2. No components are partitioned or combined with the
possible exception of the integration and interaction manager
components, and the generation and interaction components. There
are two possible configurations, depending upon whether the
integration component is stand alone or combined with the
interaction manager component:
-
Information entered by the user may be encoded into EMMA
(Extensible MultiModal Annotation Markup Language, formerly known
as the Natural Language Semantic Markup Language) and combined by
an integration component (shown within the dotted rectangle in
Figure 4) which is separate from the interaction manager.
-
Information entered by the user may be recognized and
interpreted and then routed directly to the interaction manager,
which performs its own integration of user information
There are two possible configurations, depending upon whether
the generation component is stand alone or combined with the
interaction manager component:
-
Information from the interaction manager may be routed to the
generation component, where multiple modes of output are generated
and the appropriate synchronization control created.
-
Information may be be routed directly to the styling components
and then on to the rendering components. In this case, the
interaction manager does its own generation and
synchronization.
Property 3. All components are allocated to a single client side
hardware device onboard the car. In Figure 4, the client is
illustrated by a pink box containing all of the components.
Property 4. No communication system is required in this
centralized architecture.
Property 5. Dialog Model: The user wants to go to a specific
address from his current location and while driving wants to take a
detour to a local restaurant . (The user does not know the
restaurant name or address.) The user initiates service via a
button on his steering wheel and interacts with the system via the
touch screen and speech.
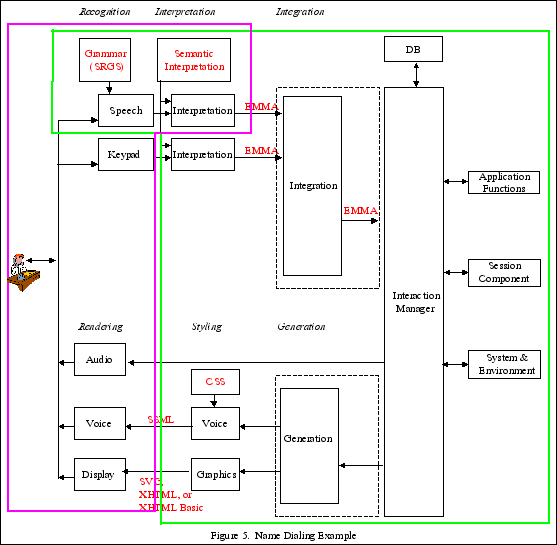
Example 2: Name dialing (Figure 5)
The Name dialing example enables a user to initiate a call by
saying the name of the person to be contacted. Visual and spoken
dialogs are used to narrow the selection, and to allow an exchange
of multimedia messages if the called person is unavailable. Call
handling is determined by a script provided by the called person.
The example supports the use of a combination of local and remote
speech recognition.
Property 1: The architecture contains a subset of the components
of the W3C Multimodal Interface Framework.
Property 2: No components have been partitioned or combined with
the possible exception of the integration component and interaction
component, and the generation component and the interaction
component (as discussed in example 2).
Property 3. The components in pink are allocated to the client
and the components in green are allocated to the server. Note that
the speech recognition and interpretation components are on both
client and server. The local ASR recognizes basic control commands
based upon the ETSI DES/HF-00021 standardized command and control
vocabulary, and the remote ASR recognizes names of individuals the
user wishes to dial. (The vocabulary of names is too large to
maintain on the client, so it is maintained on the server.)
Property 4. Communications system is SIP.
SIP
is a session initiation protocol and is a means for initiating
communication sessions involving multiple devices, and for control
signaling during such sessions.
Property 5. Navigational and control commands are recognized by
the ASR on the client. When the user says "call John Smith," the
ASR on the client recognizes the command "call" and transfers the
following information ("John Smith") to the server for recognition.
The application on the server then connects the user with John
Smith's telephone.
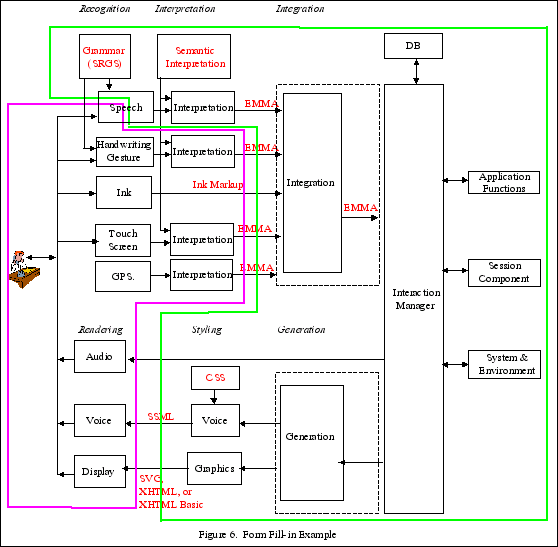
Example 3: Form fill-in (Figure 6)
In the Form fill-in example, the user wants to make a flight
reservation with his mobile device while he is on the way to work.
The user initiates the service by means of making a phone call to a
multimodal service (telephone) or by selecting an application
(portal environment metaphor). The dialogue between the user and
the application is driven by a form-filling paradigm where the user
provides input to fields such as "Travel Origin:", "Travel
Destination:", "Leaving on date", "Returning on date". As the user
selects each field in the application to enter information, the
corresponding input constraints are activated to drive the
recognition and interpretation of the user input.
Property 1: The architecture contains a subset of the components
of the W3C Multimodal Interface Framework, including GPS and
Ink.
Property 2: The speech recognition component has been
partitioned into two components, one which will be placed on the
client and the other on the server. The integration component and
interaction component, and the generation component and the
interaction component may be combined or left separate (as
discussed in example 2).
Property 3. The components in pink are allocated to the client
and the components in green are allocated to the server. Speech
recognition is distributed between the client and the server, with
the feature extraction on the client and the remaining speech
recognition functions performed on the server.
Property 4. Communications system is SIP.
SIP
is a session initiation protocol and is a means for initiating
communication sessions involving multiple devices, and for control
signaling during such sessions.
Property 5. Dialog Model: The user wants to make a flight
reservation with his mobile device while he is on the way to work.
The user initiates the service via means of making a phone call to
a multimodal service (telephone metaphor) or by selecting an
application (portal environment metaphor). The dialogue between the
user and the application is driven by a form-filling paradigm where
the user provides input to fields such as "Travel Origin:", "Travel
Destination:", "Leaving on date", "Returning on date". As the user
selects each field in the application to enter information, the
corresponding input constraints are activated to drive the
recognition and interpretation of the user input. The capability of
providing composite multimodal input is also examined, where input
from multiple modalities is combined for the interpretation of the
user's intent.