Annotations are typically used to convey information about a resource or associations between resources. Simple examples include a comment or tag on a single web page or image, or a blog post about a news article.
The Web Annotation Data Model specification describes a structured model and format to enable annotations to be shared and reused across different hardware and software platforms. Common use cases can be modeled in a manner that is simple and convenient, while at the same time enabling more complex requirements, including linking arbitrary content to a particular data point or to segments of timed multimedia resources.
The specification provides a specific JSON format for ease of creation and consumption of annotations based on the conceptual model that accommodates these use cases, and the vocabulary of terms that represents it.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at https://www.w3.org/TR/.
This specification was derived from the Open Annotation Community Group's outcomes, and details of the differences between the two are maintained in the Acknowledgment appendix.
This document has been reviewed by W3C Members, by software developers, and by other W3C groups and interested parties, and is endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the Web.
Annotating, the act of creating associations between distinct pieces of information, is a pervasive activity online in many guises. Web citizens make comments about online resources using either tools built in to the hosting website, external web services, or the functionality of an annotation client. Comments about shared photos or videos, reviews of products, or even social network mentions of web resources could all be considered as annotations. In addition, there are a plethora of "sticky note" systems and stand-alone multimedia annotation systems. This specification describes a common approach to expressing these annotations, and more.
The Web Annotation Data Model provides an extensible, interoperable framework for expressing annotations such that they can easily be shared between platforms, with sufficient richness of expression to satisfy complex requirements while remaining simple enough to also allow for the most common use cases, such as attaching a piece of text to a single web resource.
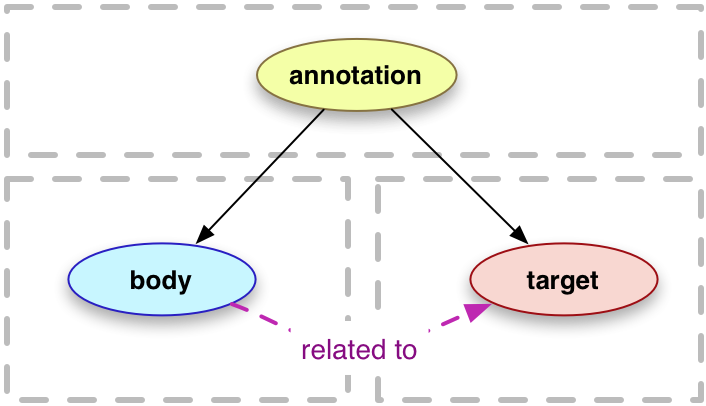
An annotation is considered to be a set of connected resources, typically including a body and target, and conveys that the body is related to the target. The exact nature of this relationship changes according to the intention of the annotation, but the body is most frequently somehow "about" the target. This perspective results in a basic model with three parts, depicted below. The full model supports additional functionality, enabling content to be embedded within the annotation, selecting arbitrary segments of resources, choosing the appropriate representation of a resource and providing styling hints to help clients render the annotation appropriately. Annotations created by or intended for machines are also possible, ensuring that the Data Web is not ignored in favor of only considering the human-oriented Document Web.
The Web Annotation Data Model does not prescribe a transport protocol for creating, managing and retrieving annotations. Instead it describes a resource oriented structure and serialization of that structure that could be carried over many different protocols. The related [annotation-protocol] specification describes a recommended transport layer, which may be adopted separately.
1.1 Aims of the Model
The primary aim of the Web Annotation Data Model is to provide a standard description model and format to enable annotations to be shared between systems. This interoperability may be either for sharing with others, or the migration of private annotations between devices or platforms. The shared annotations must be able to be integrated into existing collections and reused without loss of significant information. The model should cover as many annotation use cases as possible, while keeping the simple annotations easy and expanding from that baseline to make complex uses possible.
The Web Annotation Data Model is a single, consistent model that can be used by all interested parties. All efforts have been made to keep the implementation costs for both producers and consumers to a minimum. A single method of fulfilling a use case is strongly preferred over multiple methods, unless there are existing standards that need to be accommodated or there is a significant cost associated with using only a single method. While the Data Model is built using Linked Data fundamentals, the design is intended to allow rich and performant non-graph-based implementations. As such, inferencing and other graph-based queries are explicitly not a priority for optimization in the design of the model.
1.2 Serialization of the Model
The examples throughout the document are serialized as [JSON-LD] using the Context given in Appendix A of the Annotation Vocabulary [annotation-vocab], which is the preferred serialization format. The media type of this format is defined in Section 3 of the Annotation Protocol [annotation-protocol] as application/ld+json;profile="http://www.w3.org/ns/anno.jsonld".
When the only information that is recorded in the annotation is the IRI of a resource, then that IRI is used as the value of the relationship, as in Example 1. When there is more information about the resource, the IRI is the value of the id property of the object which is the value of the relationship, as in Example 2.
1.3 Conformance
As well as sections marked as non-normative, all authoring guidelines, diagrams, examples, and notes in this specification are non-normative. Everything else in this specification is normative.
The key words MAY, MUST, MUST NOT, NOT RECOMMENDED, RECOMMENDED, SHOULD, and SHOULD NOT are to be interpreted as described in [RFC2119].
1.3.1 Conformance Requirements Related to Selectors
Not all Selectors are relevant for all media types; some combinations are meaningless or not formally defined. An implementation may therefore ignore certain types of Selectors in case the corresponding media types are not handled by that particular implementation.
The table in A.Correspondence Among Media Types and Selectors shows the correspondence among the main media types addressed in this specification and Selector types. The meaning of the table elements, and their effect on implementation conformance, is as follows.
A “✔︎” sign in the table means that the Selector type is relevant for that particular media types. A conforming implementation MUST implement that particular combination if it handles the corresponding media type.
A “✘” sign in the table means that the Selector type is not relevant for that particular media types. Conforming implementations SHOULD ignore that particular combination.
A “?” means that it is not possible to specify, in general, whether that particular combination is meaningful (e.g., fragment identifiers are defined for specific media types, i.e., specific text media types other than plain text may have fragments defined but they are not listed in the table). In other cases the usefulness of such combination is not clear (e.g., Data Position selectors for binary images). Conforming implementations MAY implement that particular combination.
1.4 Terminology
IRI
An IRI, or Internationalized Resource Identifier, is an extension to the URI specification to allow characters from Unicode, whereas URIs must be made up of a subset of ASCII characters. There is a mapping algorithm for translating between IRIs and the equivalent encoded URI form. IRIs are defined by [rfc3987].
Resource
An item of interest that MAY be identified by an IRI.
Web Resource
A Resource that MUST be identified by an IRI, as described in the Web Architecture [webarch]. Web Resources MAY be dereferencable via their IRI.
External Web Resource
A Web Resource which is not part of the representation of the Annotation, such as a web page, image, or video. External Web Resources are dereferencable from their IRI.
Property
A feature of a Resource, that often has a particular data type. In the model sections, the term "Property" is used to refer to only those features which are notRelationships and instead have a literal value such as a string, integer or date. The valid values for a Property are thus any data type other than object, or an array containing members of that data type if more than one is allowed.
Relationship
In the model sections, the term "Relationship" is used to distinguish those features that refer to other Resources, either by reference to the Resource's IRI or by including a description of the Resource in the Annotation's representation. The valid values for a Relationship are: a quoted string containing an IRI, an object that has the "id" property, or an array containing either of these if more than one is allowed.
Class
Resources may be divided, conceptually, into groups called "classes"; members of a class are known as Instances of the class. Resources are associated with a particular class through typing. Classes are identified by IRIs, i.e., they are also Web Resources themselves.
An element of a group of Resources represented by a particular Class.
2. Web Annotation Principles
The Web Annotation Data Model is defined using the following basic principles:
An Annotation is a rooted, directed graph that represents a relationship between resources.
There are two primary types of resource that participate in this relationship, Bodies and Targets.
Annotations have 0 or more Bodies.
Annotations have 1 or more Targets.
The content of the Body resources is related to, and typically "about", the content of the Target resources.
Annotations, Bodies and Targets may have their own properties and relationships, typically including creation and descriptive information.
The intent behind the creation of an Annotation or the inclusion of a particular Body or Target is an important property and represented by a Motivation resource.
The following principles describe additional distinctions regarding the exact nature of Target and Body:
The Target or Body resource may be more specific than the entity identified by the resource's IRI alone.
In particular,
The Target or Body resource may be a specific segment of the resource.
The Target or Body resource may be styled in a specific way.
The Target or Body resource may be a specific state of the resource.
The Target or Body resource may be included in the Annotation to play a specific role.
The Target or Body resource may be any combination of the above.
The resource with these constraints is a separate resource from the Annotation, Body or Target, and is called a SpecificResource.
The SpecificResource refers to the source resource and the constraints that make it more specific.
The identity of the SpecificResource is separate from the descriptions of the constraints.
The Body resource may be a choice between multiple resources.
The properties of external resources, such as Bodies and Targets, included in the Annotation document are intended as hints to the client, and are not to be considered authoritative information. This includes properties such as the created time, the creating agent, the modification time, any rights assertions, format, language or text direction of the external resource.
3. Web Annotation Framework
3.1 Annotations
An Annotation is a Web Resource. Typically, an Annotation has a single Body, which is a comment or other descriptive resource, and a single Target that the Body is somehow "about". The Annotation likely also has additional descriptive properties.
Example Use Case: Alice has written a post that makes a comment about a particular web page. Her client creates an Annotation with the post as the body resource, and the web page as the target resource.
Model
Term
Type
Description
@context
Property
The context that determines the meaning of the JSON as an Annotation.
The Annotation MUST have 1 or more @context values and http://www.w3.org/ns/anno.jsonldMUST be one of them. If there is only one value, then it MUST be provided as a string.
id
Property
The identity of the Annotation.
An Annotation MUST have exactly 1 IRI that identifies it.
type
Relationship
The type of the Annotation.
An Annotation MUST have 1 or more types, and the Annotation class MUST be one of them.
Annotation
Class
The class for Web Annotations.
The Annotation class MUST be associated with an Annotation using type.
body
Relationship
The relationship between an Annotation and its Body.
There SHOULD be 1 or more body relationships associated with an Annotation but there MAY be 0.
target
Relationship
The relationship between an Annotation and its Target.
There MUST be 1 or more target relationships associated with an Annotation.
The Web is distributed, with different systems working together to provide access to content. Annotations can be used to link those resources together, being referenced as the Body and Target. The Target resource is always an External Web Resource, but the Body may also be embedded within the Annotation. External Web Resources may be separately dereferenced to retrieve a representation of their state, whereas the embedded Body does not need to be dereferenced as the representation is included within the Annotation's representation.
3.2.1 External Web Resources
Web Resources are identified with a IRI and have various properties, often including a format or language for the resource's content. This information may be recorded as part of the Annotation, even if the representation of the resource must be retrieved from the Web.
Example Use Case: Beatrice records a long analysis of a patent, and publishes the audio on her website as an mp3. She then creates an Annotation with the mp3 as the body, and the PDF of the patent as the target.
Model
Term
Type
Description
id
Property
The IRI that identifies the Body or Target resource.
Bodies or Targets which are External Web Resources MUST have exactly 1 id with the value of the resource's IRI.
format
Property
The format of the Web Resource's content.
The Body or Target SHOULD have exactly 1 format associated with it, but MAY have 0 or more. The value of the property SHOULD be the media-type of the format, following the [rfc6838] specification.
language
Property
The language of the Web Resource's content.
The Body or Target SHOULD have exactly 1 language associated with it, but MAY have 0 or more, for example if the language cannot be identified or the resource contains a mix of languages. The value of the property SHOULD be a language code following the [bcp47] specification.
processingLanguage
Property
The language to use for text processing algorithms such as line breaking, hyphenation, which font to use, and similar.
Each Body and Target MAY have exactly 1 processingLanguage. The value of the property SHOULD be a language code following the [bcp47] specification. If this property is not present and the language property is present with a single value, then the client SHOULD use that language for processing requirements.
textDirection
Relationship
The overall base direction of the text in the resource.
The Body or Target MAY have exactly 1 textDirection associated with it. The value of the property MUST be one of the directions defined below (ltr, rtl, or auto).
ltr
Instance
The direction that indicates the value of the resource is explicitly directionally isolated left-to-right text.
rtl
Instance
The direction that indicates the value of the resource is explicitly directionally isolated right-to-left text.
auto
Instance
The direction that indicates the value of the resource is explicitly directionally isolated text, and the direction is to be programmatically determined using the value.
Note
The [iana-media-types] document provides the official registry of media types that can be used with the format property. The [w3c-language-tags] article provides a good overview of the values that implementers can expect to encounter in the language property. The notion of text direction and the definitions of auto, ltr and rtl values are taken explicitly from the HTML5 [html5] dir attribute. Please also note that if information provided by the external resource contradicts the information provided by the annotation about it, then the external resource is authoritative and the information from the annotation should be disregarded.
It is useful for clients to know the general type of a Web Resource in advance. If the client cannot render videos, then knowing that the Body is a video will allow it to avoid needlessly downloading a potentially large content stream. For resources that do not have obvious media types, such as many data formats, it is also useful for a client to know that a resource with the format text/csv should not simply be rendered as plain text, despite the first part of the media type, whereas application/pdf may be able to be rendered by the user agent despite the main type being 'application'.
Example Use Case: Corina shoots a video of her comment about a website on her phone and uploads it. She associates the video with the website via an Annotation, and her client adds types as a hint to consuming systems.
Model
Term
Type
Description
type
Relationship
The type of the Body or Target resource.
The Body or Target MAY have 1 or more types, and if so, the value SHOULD be drawn from the list of classes below, but MAY come from other vocabularies.
Dataset
Class
The class for a resource which encodes data in a defined structure.
Image
Class
The class for image resources, primarily intended to be seen.
Video
Class
The class for video resources, with or without audio.
Sound
Class
The class for a resource primarily intended to be heard.
Text
Class
The class for a resource primarily intended to be read.
Many Annotations involve part of an External Web Resource, rather than its entirety. In the Web [webarch], segments of resources are identified using IRIs with a fragment component that at the same time both describes how to extract the segment of interest from the resource, and identifies the extracted content. For simple Annotations, it is valuable to be able to use these IRIs with a fragment component as the identifier for either Body or Target.
Example Use Case: Dawn wants to describe a particular region of an image. She highlights that area in her client and types in the description. Her client then constructs an IRI with an appropriate fragment component as the target.
Model
Term
Type
Description
id
Property
The IRI that identifies the Body or Target resource.
Bodies or Targets which are External Web Resources MUST have exactly 1 id with the value of the resource's IRI, and that IRI MAY have a fragment component.
Note
Note that other properties of resources such as type, format and language, plus those described in the Other Properties section below, can be applied to the segment of the resource, just like for the full resource.
It is important to be aware of the consequences of using an IRI with a fragment component, and the restrictions that using them places on implementations.
Fragments are defined with respect to individual media types. For example, HTML has a specific set of semantics regarding the meaning of the fragment part of the IRI.
Not every media type has a fragment specification. For example, Office documents might have a media-type and be published on the web, but not have semantics associated with the fragment part of the IRI.
Even if a media type does have a fragment definition, it is often not possible to describe the segment of interest sufficiently precisely. For example, fragments for HTML cannot be used to describe an arbitrary range of text.
It is not possible to determine with certainty what is being identified without knowing the media type, as the same fragment string might be possible in different specifications. For example, the same fragment string could identify either a rectangular area in an image, or a strangely named section of an HTML document.
IRIs with a fragment component are not compatible with other methods of describing the segment more specifically. For example, it is not possible to describe how to retrieve the correct representation, add style information, or associate a role with the resource, using such IRIs. The method to accomplish these requirements is described in the Fragment Selector portion of the Specific Resources section.
As IRIs are considered to be opaque strings, annotation systems may not discover annotations with fragment components when searching by means of the IRI without the fragment. For example, an Annotation with the Target
http://example.com/image.jpg#xywh=1,1,1,1 would not be discovered in a simple search for
http://example.com/image.jpg, even though it is part of it.
For more information regarding the use of IRIs with fragment components, please see the Best Practices for Fragment Identifiers and Media Type Definitions [fragid-best-practices].
In many situations, the Body of the Annotation will be in a text format, and created at the same time as the Annotation without a separate IRI. In these cases, the Body's text can be included as part of the Annotation to avoid having to interact with multiple systems. The Body may also have the features of External Web Resources, including especially the language of the text and the format that it is conveyed in.
Example Use Case: Emily writes a comment about how much she likes an image on a photo sharing website. Her client creates an Annotation with the comment embedded within it, and adds that it is in French and formatted using HTML.
Model
The fundamental features of a Textual Body are:
Term
Type
Description
id
Property
The IRI that identifies the Textual Body.
The Body MAY have exactly 1 IRI that identifies it.
type
Relationship
The type of the Textual Body resource.
The Body SHOULD have the TextualBody class, and MAY have other classes.
TextualBody
Class
A class assigned to the Body for embedding textual resources within the Annotation.
The Body SHOULD have the TextualBody class.
value
Property
The character sequence of the content of the Textual Body. There MUST be exactly 1 value property associated with the TextualBody.
Systems SHOULD assume that Textual Bodies have the Text class, described in Classes above, even if it is not explicitly included in the type property.
The properties of External Web Resources, such as language and format also apply to embedded Textual Body resources.
The simplest type of Body is a plain text string, without additional information or properties. This type of Body is useful for the simplest of Annotations only, and is NOT RECOMMENDED for uses where the Body may need to be referred to from outside of the Annotation.
Example Use Case Franceska wants to create a quick Annotation from a simple, command line client. She creates the JSON serialization in a text file and sends it to her Annotation server to maintain.
Model
Term
Type
Description
bodyValue
Property
The string value of the Body of the Annotation.
There MAY be exactly 1 bodyValue for an Annotation, and the value MUST conform to the requirements below. If the bodyValue property is present, then the body relationship MUST NOT also be present.
There are several restrictions on when this form may be used and how it is to be interpreted.
The string Body:
MUST be a single xsd:string and the data type MUST NOT be expressed in the serialization.
MUST NOT have a language associated with it.
MUST be interpreted as if it were the value of the value property of a Textual Body.
MUST be interpreted as if the Textual Body resource had a format property with the value text/plain.
MUST NOT have the value of other properties of the Textual Body inferred from similar properties on the Annotation resource.
If any of the interpretations above are not correct, then the TextualBody constructionMUST be used instead.
Note
Systems MAY rewrite Annotations to instead use the TextualBody construction, rather than maintaining the bodyValue form. The TextualBody construction is preferred, as language and format information are important for clients processing the Annotation.
Some Annotations may not have a Body at all, such as a simple highlight or bookmark without any accompanying text. It is also possible for an Annotation to have multiple Bodies and/or Targets. In this case, each Body is considered to be equally related to each Target individually, rather than to the set of all of the Targets.
Example Use Case: Gretchen highlights a particular region of her ebook in green and, knowing what such a highlight means, she does not give a comment. Her client associates a stylesheet with the Annotation, and does not create a body at all.
Example Use Case: Hannah associates a tag and a description with two images using a single annotation.
Model
The body relationship is omitted when there is no Body for the Annotation.
The body and/or target relationships of the Annotation may be arrays rather than a single object. The values may be either strings containing the IRI of the resource or objects.
A Choice has an ordered list of resources from which an application should select only one to process or display. The order is given from the most preferable to least preferable, according to the Annotation's creator or publisher.
Example Use Case: Irina writes up her discussion of a particular website in both French and English. As the two posts are equivalent, there is no need to display both, and instead she wants French speakers to see the French comment, and everyone else to see the English version. Her client creates as Choice with the English comment listed first.
Model
Term
Type
Description
id
Property
The IRI that identifies the Choice.
The Choice MAY have exactly 1 IRI that identifies it.
type
Relationship
The type of the resource.
The Choice MUST have exactly 1 type, and it MUST be the CHOICE class.
Choice
Class
A construction that conveys to a consuming application that it SHOULD select one of the listed resources to display to the user, and not render all of them.
items
Relationship
A list of resources to choose from, with the default option listed first.
Note
Clients MAY use any algorithm to determine which resource to choose, and SHOULD make use of the information present to do so automatically, but MAY present a list and require the user to make the decision.
It is often important to have information about the context in which the Annotation and any External Web Resources were created, modified and used. In particular,
When was the resource created, modified or generated
Who created, modified or generated the serialized form of the Annotation or other resource, and who is it intended for
Why was the resource included in the annotation, or the annotation created
What other identities the resource has
How can the resource be used, according to its rights and licensing
Note
Beyond the features described in this section, other properties MAY be added features of the Annotation or any resource in the model. Please see the Extension section of [annotation-vocab] for more information about how to do this.
3.3.1 Lifecycle Information
The person, organization or machine responsible for the Annotation or referenced resource deserves credit for their contribution, and the time at which those resources are created is useful for display ordering and filtering out old, potentially irrelevant content. The creator of the Annotation is also useful for determining the trustworthiness of the Annotation. The software used to create and serialize the Annotation, along with when that activity occurred, is useful for both advertising and debugging issues.
Example Use Case: Jane writes a review of a restaurant online, and wishes to be associated with that review so that her friends know that it was her review and can trust it. Her client adds her account's identity, and its own identity, to the Annotation and the appropriate timestamps for when the resources were created.
Model
Term
Type
Description
creator
Relationship
The agent responsible for creating the resource. This may be either a human, an organization or a software agent.
There SHOULD be exactly 1 creator relationship for Annotation and Body, but MAY be 0 or more than 1, as the resource's creator may wish to remain anonymous, or multiple agents may have worked together on it. The relationships MAY be associated with other resources.
created
Property
The time at which the resource was created.
There SHOULD be exactly 1 created property for Annotation and Body, and MUST NOT be more than 1. The property MAY be associated with other resources. The datetime MUST be a xsd:dateTime with the UTC timezone expressed as "Z".
generator
Relationship
The agent responsible for generating the serialization of the Annotation.
There MAY be 0 or more generator relationships per Annotation
generated
Property
The time at which the Annotation serialization was generated.
There MAY be exactly 1 generated property per Annotation, and MUST NOT be more than 1. The datetime MUST be a xsd:dateTime with the UTC timezone expressed as "Z".
modified
Property
The time at which the resource was modified, after creation.
There MAY be exactly 1 modified property for Annotation and Body, and MUST NOT be more than 1. The property MAY be associated with other resources. The datetime MUST be a xsd:dateTime with the UTC timezone expressed as "Z".
More information about the agents involved in the creation of an Annotation is normally required beyond an IRI that identifies them. This includes whether they are an individual, a group or a piece of software and properties such as real name, account nickname, and email address.
Example Use Case: Kelly wants to submit an Annotation to a system that does not manage her identity, and would like a pseudonym to be displayed. Her client adds this information to the Annotation to send to the service.
Model
Term
Type
Description
id
Property
The IRI that identifies the agent.
An Agent SHOULD have exactly 1 IRI that identifies it, and MUST NOT have more than 1.
type
Relationship
The type of the Agent.
An Agent SHOULD have 1 or more classes, from those listed below.
Person
Class
The class for a human agent.
Organization
Class
The class for an organization, as opposed to an individual.
Software
Class
The class for a software agent, such as a user's client or a machine learning system that creates Annotations.
name
Property
The name of the agent.
Each agent SHOULD have exactly 1 name property, and MAY have 0 or more.
nickname
Property
The nickname of the agent.
Each agent SHOULD have exactly 1 nickname property, and MAY have 0.
email
Relationship
The email address associated with the agent, using the mailto: IRI scheme [rfc6086].
Each agent MAY have 1 or more email addresses.
email_sha1
Property
The text representation of the result of applying the sha1 algorithm to the email IRI of the agent, including the 'mailto:' prefix and no whitespace. This allows the mail address to be used as an identifier without publishing the address publicly. Each agent MAY have 1 or more values in the email_sha1 property.
homepage
Relationship
The home page for the agent. Each agent MAY have 1 or more home pages.
Beyond the agents that are associated with the creation and management of the Annotation and other resources, it is also useful to know the audience or class of consuming agent that the resource is intended for. This allows for the roles (such as teacher versus student) or properties of the class (such as a suggested age range) of the intended audience to be recorded.
Example Use Case: Lynda writes some notes about using a particular textbook to teach a class. She adds that the intended audience of the Annotation is teachers (who are using the textbook), to distinguish from other Annotations that might have an audience of the students (who are also using the textbook, but to learn from).
Model
Term
Type
Description
id
Property
The IRI that identifies the Audience.
There MAY be exactly 1 IRI given that identifies the Audience.
type
Relationship
The type of the Audience, from the schema.org class structure. The Audience SHOULD have 1 or more types and they SHOULD come from the schema.org class structure.
audience
Relationship
The relationship between an Annotation and its intended Audience.
There MAY be 0 or more Audiences for each Annotation.
Further properties that describe the audience are used from schema.org's Audience classes. The properties and class names MUST be prefixed in the JSON with schema: to ensure that they are uniquely distinguished from any other properties or classes.
The use of audience does not imply nor enable any access restriction to prevent the annotation from being seen. Systems SHOULD use the information for filtering the display of Annotations based on their knowledge of the user, and not assume that the Annotation or other resources will require authentication and authorization.
Access to information is recognized as a basic human right by the United Nations. The Web is able to remove barriers to communication and interaction regardless of various physical impediments. This supports social inclusion, but also increases the potential audience of the information. For resources that are used as the Body or Target of an Annotation, it is valuable to record the features of that resource that provide easier access for users with various and diverse ranges of ability.
Example Use Case: Megan has very limited ability to hear sound, and prefers to read captions when interacting with videos. She uses her annotation client to make a comment on such a video, and to help others in the same situation, the client includes that the video has this accessibility feature.
Model
Term
Type
Description
accessibility
Property
One or more strings from an enumerated list of values that each describes an accessibility feature that the resource has.
There MAY be 0 or more accessibility features listed for each Body or Target resource.
Note
The current list of values is referenced from the schema.org description of the accessibilityFeature property.
In many cases it is important to understand the reasons why the Annotation was created, or why the Textual Body was included in the Annotation, not just the times and agents involved. These reasons are provided by declaring the motivation for the Annotation's creation or the purpose for the inclusion of the Textual Body in the Annotation; the "why" rather than the "who" and "when" described in the previous sections.
Example Use Case: Noelle annotates a resource intending to bookmark it for future reference, and provides a description and a tag to make it easier to find again. Her client adds the right motivations to the Annotation and the Textual Body resources to capture this.
Model
Term
Type
Description
motivation
Relationship
The relationship between an Annotation and a Motivation.
There SHOULD be exactly 1 motivation for each Annotation, and MAY be 0 or more than 1.
purpose
Relationship
The reason for the inclusion of the Textual Body within the Annotation.
There MAY be 0 or more purposes associated with a TextualBody.
Motivation
Class
The Motivation for an Annotation is a reason for its creation, and might include things like Replying to another annotation, Commenting on a resource, or Linking to a related resource.
Motivations
assessing
Instance
The motivation for when the user intends to assess the target resource in some way, rather than simply make a comment about it. For example to write a review or assessment of a book, assess the quality of a dataset, or provide an assessment of a student's work.
bookmarking
Instance
The motivation for when the user intends to create a bookmark to the Target or part thereof. For example an Annotation that bookmarks the point in a text where the reader finished reading.
classifying
Instance
The motivation for when the user intends to classify the Target as something. For example to classify an image as a portrait.
commenting
Instance
The motivation for when the user intends to comment about the Target. For example to provide a commentary about a particular PDF document.
describing
Instance
The motivation for when the user intends to describe the Target, as opposed to (for example) a comment about it. For example describing the above PDF's contents, rather than commenting on their accuracy.
editing
Instance
The motivation for when the user intends to request a change or edit to the Target resource. For example an Annotation that requests a typo to be corrected.
highlighting
Instance
The motivation for when the user intends to highlight the Target resource or segment of it. For example to draw attention to the selected text that the annotator disagrees with.
identifying
Instance
The motivation for when the user intends to assign an identity to the Target. For example to associate the IRI that identifies a city with a mention of the city in a web page.
linking
Instance
The motivation for when the user intends to link to a resource related to the Target.
moderating
Instance
The motivation for when the user intends to assign some value or quality to the Target. For example annotating an Annotation to moderate it up in a trust network or threaded discussion.
questioning
Instance
The motivation for when the user intends to ask a question about the Target. For example to ask for assistance with a particular section of text, or question its veracity.
replying
Instance
The motivation for when the user intends to reply to a previous statement, either an Annotation or another resource. For example providing the assistance requested in the above.
tagging
Instance
The motivation for when the user intends to associate a tag with the Target.
Note
For more information about how Motivations can be inter-related and new Motivations created, please see the Annotation Vocabulary document [annotation-vocab]. Section 4.1 describes how to associate a Motivation with and external web resource.
Example
Example 15: Motivation and Purpose
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno15",
"type": "Annotation",
"motivation": "bookmarking",
"body": [
{
"type": "TextualBody",
"value": "readme",
"purpose": "tagging"
},
{
"type": "TextualBody",
"value": "A good description of the topic that bears further investigation",
"purpose": "describing"
}
],
"target": "http://example.com/page1"
}
3.3.6 Rights Information
It is common practice to associate a license or rights statement with a resource, in order to describe the conditions under which it may be used. This allows the user to make appropriate use of the resource, as well as allowing some automated systems to confirm that the usage is permitted. As the Annotation, Bodies, and Targets might be created with different licences or rights, each can be described separately. The rights of resources other than the Annotation itself are considered informative hints to a consuming client application.
Example Use Case: Ophelia writes a review of a product and wishes to be known as the author of the review, however does not mind how the Annotation that relates the review and the product together is used. She asserts these two separate rights statements with the Annotation and Body individually. She does not know the rights asserted on the target resource, so does not specify any.
Model
Term
Type
Description
rights
Relationship
The relationship between an Annotation, Body or Target and a Web Resource that contains the rights statement or license under which the resource may be used.
There MAY be at exactly 0 or more rights statements or licenses linked from each resource, and the value MUST be an IRI.
In a massively distributed system such as the Web, information is often copied. In order to track the provenance of the Annotation and other related resources, it is possible to record additional IRIs that also identify the resource. These may be dereferencable "permalinks", identities assigned by a client offline without any knowledge of the web, or simply the location where the current harvesting system discovered the resource.
Example Use Case: Petra creates an Annotation and sends it to multiple systems to maintain, one personal and one public. She wants to ensure that the copies can be aligned, and so she sets a UUID as the canonical IRI, allowing the service to assign an HTTP IRI for it. A subsequent system then harvests the public copy, maintaining the canonical UUID as discovered, then moves the original HTTP IRI to via, replacing it with an IRI under its control.
Model
Term
Type
Description
canonical
Relationship
The relationship between an Annotation, Body or Target and the IRI that SHOULD be used to track its identity, regardless of where it is made accessible. If this property is set, then systems MUST NOT change or delete it. Systems SHOULD NOT assign a canonical IRI without prior agreement if one is not present, as the Annotation could already have a canonical IRI elsewhere.
There MAY be exactly 1 canonical IRI for each resource.
via
Relationship
The relationship between an Annotation, Body or Target and the IRI of where that resource was obtained from by the system that is making it available.
There MAY be 0 or more IRIs provided in via for each resource.
While it is possible using only the constructions described above to create Annotations that reference parts of resources by using IRIs with a fragment component, there are many situations when this is not sufficient. For example, even a simple circular region of an image, or a diagonal line across it, are not possible. Selecting an arbitrary span of text in an HTML page, perhaps the simplest annotation concept, is also not supported by fragments. Furthermore, there are non-segment use cases that require a client to retrieve a specific state or representation of the resource, to style it in a particular way, to associate a role with the resource that is specific to the Annotation's use of it, or for the Annotation to only apply when the resource is used in a particular context.
The Web Annotation Data Model uses a new type of resource to capture these Annotation-specific requirements: a SpecificResource. The SpecificResource is used in between the Annotation and the Body or Target, as appropriate, to capture additional information about how it is used in the Annotation. The descriptions are typically referenced from the SpecificResource as separate entities and can be of various types to capture the different requirements. For example, if the Target of the Annotation is a circular region of an image, then the SpecificResource is the circular region, it is described by a Selector, and is also associated with the source Image resource.
Specific Resources and Specifiers MAY be External Web Resources with their own IRIs, such as in the example for the Selector construction, however it is RECOMMENDED that they be included in the Annotation's representation to avoid requiring unnecessary network interactions to retrieve all of the information needed to process the Annotation.
The types of additional specificity that are defined by this document:
Purpose: Describe the purpose of including the source resource in the Annotation
Selector: Describe the desired segment of the source resource for the Annotation
State: Describe the desired representation of the source resource for the Annotation
Style: Describe the style in which the source resource should be presented for the Annotation
Rendering: Describe the system used by the client for rendering the resource when the annotation was created
Scope: Describe the scope in which the source resource applies for the Annotation
Model
Term
Type
Description
id
Property
The identity of the Specific Resource.
A Specific Resource MAY have exactly 1 IRI that identifies it.
type
Relationship
The class of the Specific Resource.
The Specific Resource SHOULD have the SpecificResource class.
SpecificResource
Class
The class for Specific Resources.
The SpecificResource class SHOULD be associated with a Specific Resource to be clear as to its role as a more specific region or state of another resource.
source
Relationship
The relationship between a Specific Resource and the resource that it is a more specific representation of.
There MUST be exactly 1 source relationship associated with a Specific Resource. The source resource MAY be described in detail, as defined above, or be just the resource's IRI.
The same Specific Resource and Specifier classes are used for both Target and Body. The examples in this section only use one of these, however the same model applies for both.
4.1 Purpose for External Web Resources
As well as Textual Bodies, External Web Resources may also be given a Motivation as to their inclusion within the Annotation. This is done using the Specific Resource pattern, as the purpose specifies the way in which the resource is used in the context of the Annotation in the same way as a Selector describes the segment or a State describes the representation.
Example Use Case: Qitara wants to tag a photo with an identifier for a city, rather than just type the city's name which could be ambiguous. Her client uses a well-known IRI for the city having done a search for it, and creates a Specific Resource to manage that purpose assignment.
Model
Term
Type
Description
purpose
Relationship
The reason for including the Web Resource in the Annotation.
There MAY be 0 or more Motivations associated with the SpecificResource using purpose.
Many Annotations refer to part of a resource, rather than all of it, as the Target. We call that part of the resource a Segment (of Interest). A Selector is used to describe how to determine the Segment from within the Source resource. The nature of the Selector will be dependent on the type of resource, as the methods to describe Segments from various media-types will differ. Multiple Selectors can be given to describe the same Segment in different ways in order to maximize the chances that it will be discoverable later, and that the consuming user agent will be able to use at least one of the Selectors.
Example Use Case: Ramona wants to associate a selection of text in a web page, with a slice of a dataset. She selects both using her client, and creates the Annotation with a SpecificResource that has a Selector for each of the Body and the Target.
Model
Term
Type
Description
selector
Relationship
The relationship between a Specific Resource and a Selector.
There MAY be 0 or more selector relationships associated with a Specific Resource. Multiple Selectors SHOULD select the same content, however some Selectors will not have the same precision as others. Consuming user agents MUST pick one of the described segments, if they are different.
As the most well understood mechanism for selecting a Segment is to use the fragment part of an IRI defined by the representation's media type, it is useful to allow this as a description mechanism via a Selector. This allows existing and future fragment specifications to be used with Specific Resources in a consistent way. To be clear about which fragment type is being used, the Selector may refer to the specification that defines it.
Example Use Case: Sally wants to associate part of a video as the description of an image. She selects the time range within the video and clicks that it is describing the target. Her client then creates the Annotation using a SpecificResource with a FragmentSelector and the describing Motivation.
Model
Term
Type
Description
type
Relationship
The class of the Selector. FragmentSelectors MUST have exactly 1 type and the value MUST be FragmentSelector.
FragmentSelector
Class
A resource which describes the Segment through the use of the fragment component of an IRI.
value
Property
The contents of the fragment component of an IRI that describes the Segment. The FragmentSelector MUST have exactly 1 value property.
conformsTo
Relationship
The relationship between the FragmentSelector and the specification that defines the syntax of the IRI fragment in the value property.
The Fragment Selector SHOULD have exactly 1 conformsTo link to the specification that defines the syntax of the fragment and MUST NOT have more than 1.
It is RECOMMENDED to use FragmentSelector as a consistent method compatible with other means of describing SpecificResources, rather than using the IRI with a fragment directly. Consuming applications SHOULD be aware of both.
The following IRIs are some of the specifications that define the semantics of fragments, and hence may be used with the conformsTo relationship. Other IRIs MAY also be used.
The IRI that uses the fragment may be reconstructed by concatenating the source, a #, and the value. For example, the IRI from the example below would be http://example.org/video1#t=30,60.
One of the most common ways to select elements in the HTML Document Object Model is to use CSS Selectors [CSS3-selectors]. CSS Selectors allow for a wide variety of well supported ways to describe the path to an element in a web page, and thus cover many of the basic use cases for Web Annotation. Results are not defined for when a CSS Selector is applied to a representation that does not conform to the Document Object Model.
Note that CSS may also be used for styling a resource within an annotation. This class is specifically to re-use the CSS Selector mechanism to select a segment of a resource that conforms to the Document Object Model.
Example Use Case: Teynika selects a paragraph in a web page that she wishes to write a note about. Her client calculates a CSS path that cleanly identifies that element and adds it to the annotation.
Model
Term
Type
Description
type
Relationship
The class of the Selector. CssSelectors MUST have exactly 1 type and the value MUST be CssSelector.
CssSelector
Class
The type of the CSS Selector resource.
CSS Selectors MUST have this class associated with them.
value
Property
The CSS selection path to the Segment.
There MUST be exactly 1 value associated with a CSS Selector.
Note
Implementers SHOULD use only commonly supported features of CSS that directly contribute to selection of an element or content, rather than styling or transformation, in order to maximize interoperability between systems.
Another common method of selecting elements and content within a resource that supports the Document Object Model (DOM), such as documents in XML or HTML, is to use an XPath selection [DOM-Level-3-XPath]. XPath allows a great deal of flexibility when describing the path through the structure to the selected content. Results are not defined for when an XPath Selector is applied to a representation that does not conform to the DOM.
Note
Implementers should note that the HTML5 specification allows parsers to add elements into the DOM that are considered to be missing. XPaths SHOULD be constructed to include these elements, rather than from the element structure in the document.
Example Use Case: Ulrika selects a span within a table in an HTML page and writes a note about the content. To refer explicitly to this element, her client carefully constructs an XPath to identify it as the target of the Annotation.
Model
Term
Type
Description
type
Relationship
The class of the Selector. XPath Selectors MUST have exactly 1 type and the value MUST be XPathSelector.
XPathSelector
Class
The type of the XPath Selector resource.
XPath Selectors MUST have this class associated with them.
value
Property
The xpath to the selected segment.
There MUST be exactly 1 value associated with an XPath Selector.
Note
Implementers SHOULD use only commonly supported features of XPath that directly contribute to selection of an element or content in order to maximize interoperability between systems.
This Selector describes a range of text by copying it, and including some of the text immediately before (a prefix) and after (a suffix) it to distinguish between multiple copies of the same sequence of characters.
For example, if the document were again "abcdefghijklmnopqrstuvwxyz", one could select "efg" by a prefix of "abcd", the match of "efg" and a suffix of "hijk".
Example Use Case: Valeria selects a typo ('anotation') in a web page and adds a comment that it should be replaced with the correct spelling ('annotation').
Model
Term
Type
Description
type
Relationship
The class of the Selector. Text Quote Selectors MUST have exactly 1 type and the value MUST be TextQuoteSelector.
TextQuoteSelector
Class
The class for a Selector that describes a textual segment by means of quoting it, plus passages before or after it.
The TextQuoteSelector MUST have this class associated with it.
exact
Property
A copy of the text which is being selected, after normalization.
Each TextQuoteSelector MUST have exactly 1 exact property.
prefix
Property
A snippet of text that occurs immediately before the text which is being selected.
Each TextQuoteSelector SHOULD have exactly 1 prefix property, and MUST NOT have more than 1.
suffix
Property
The snippet of text that occurs immediately after the text which is being selected.
Each TextQuoteSelector SHOULD have exactly 1 suffix property, and MUST NOT have more than 1.
The selection of the text MUST be in terms of unicode code points (the "character number"), not in terms of code units (that number expressed using a selected data type). Selections SHOULD NOT start or end in the middle of a grapheme cluster. The selection MUST be based on the logical order of the text, rather than the visual order, especially for bidirectional text. For more information about the character model of text used on the web, see [charmod].
The text MUST be normalized before recording in the Annotation. Thus HTML/XML tags SHOULD be removed, and character entities SHOULD be replaced with the character that they encode. Note that this does not affect the state of the content of the document being annotated, only the way that the content is recorded in the Annotation document.
If, after processing the prefix, exact, and suffix, the user agent discovers multiple matching text sequences, then the selection SHOULD be treated as matching all of the matches.
Note
If the content is under copyright or has other rights asserted on its use, then this method of selecting text is potentially dangerous. A user might select the entire text of the document to annotate, which would not be desirable to copy into the Annotation and share. For static texts with access and/or distribution restrictions, the use of the Text Position Selector is perhaps more appropriate.
Example
Example 23: Text Quote Selector
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno23",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/page1",
"selector": {
"type": "TextQuoteSelector",
"exact": "anotation",
"prefix": "this is an ",
"suffix": " that has some"
}
}
}
4.2.5 Text Position Selector
This Selector describes a range of text by recording the start and end positions of the selection in the stream. Position 0 would be immediately before the first character, position 1 would be immediately before the second character, and so on. The start character is thus included in the list, but the end character is not.
For example, if the document was "abcdefghijklmnopqrstuvwxyz", the start was 4, and the end was 7, then the selection would be "efg".
Example Use Case: Wendy writes a review of an ebook that does not allow its content to be extracted and copied. Her client describes the selection using its start and end position in the content.
Model
Term
Type
Description
type
Relationship
The class of the Selector. Text Position Selectors MUST have exactly 1 type and the value MUST be TextPositionSelector.
TextPositionSelector
Class
The class for a Selector which describes a range of text based on its start and end positions.
The TextPositionSelector MUST have this class associated with it.
start
Property
The starting position of the segment of text. The first character in the full text is character position 0, and the character is included within the segment.
Each TextPositionSelector MUST have exactly 1 start property, and the value MUST be a non-negative integer.
end
Property
The end position of the segment of text. The character is not included within the segment.
Each TextPositionSelector MUST have exactly 1 end property, and the value MUST be a non-negative integer.
The text MUST be selected and normalized in the same way as for the Text Quote Selector before counting the number of characters to determine the start and end positions.
Note
The use of this Selector does not require text to be copied from the Source document into the Annotation graph, unlike the Text Quote Selector, but is very brittle with regards to changes to the resource. Any edits or dynamically transcluded content may change the selection, and thus it is RECOMMENDED that a State be additionally used to help identify the correct representation.
Similar to the Text Position Selector, the Data Position Selector uses the same properties but works at the byte in bitstream level rather than the character in text level.
Example Use Case: Xena writes comments about regions of online disk images for forensic purposes and describing emulation requirements. Her client generates the start and end positions from the binary stream, rather than the more human readable display she is using.
Model
Term
Type
Description
type
Relationship
The class of the Selector. Data Position Selectors MUST have exactly 1 type and the value MUST be DataPositionSelector.
DataPositionSelector
Class
The class for a Selector which describes a range of data based on its start and end positions within the byte stream.
The DataPositionSelector MUST have this class associated with it.
start
Property
The starting position of the segment of data. The first byte is character position 0.
Each DataPositionSelector MUST have exactly 1 start property.
end
Property
The end position of the segment of data. The last character is not included within the segment.
Each DataPositionSelector MUST have exactly 1 end property.
An SvgSelector defines an area through the use of the Scalable Vector Graphics [SVG11] standard. This allows the user to select a non-rectangular area of the content, such as a circle or polygon by describing the region using SVG. The SVG may be either embedded within the Annotation or referenced as an External Web Resource.
Note that the SvgSelector uses SVG to select an area of a resource. Segments of an SVG representation may also be selected using selectors, including the FragmentSelector or even an SvgSelector.
Example Use Case: Yadira is tagging an old map online with a diagonal region for a historical road. Her client creates SVG polygon to describe the region, relative to the image content.
Model
Term
Type
Description
type
Relationship
The class of the Selector. SVG Selectors MUST have exactly 1 type and the value MUST include SvgSelector.
SvgSelector
Class
The class for a Selector which defines a shape for the selected area using the SVG standard.
The Selector MUST have this class associated with it.
value
Property
The character sequence of the SVG content. There MAY be exactly 1 value property associated with the Selector, and if so the value of the property MUST be well-formed SVG XML.
The dimensions of the SVG shape or canvas MUST be relative to the dimensions of the Source resource, such that scaling the shape's size to the full size of the image correctly describes the desired area.
Note
Implementers SHOULD use only commonly supported features of SVG that directly contribute to describing a region, rather than styling or transformation, in order to maximize interoperability between systems. It is NOT RECOMMENDED to include style information within the SVG element, nor Javascript, animation, text or other non-shape oriented information. Clients SHOULD ignore such information if present.
Selections made by users may be extensive and/or cross over internal boundaries in the representation, making it difficult to construct a single selector that robustly describes the correct content. A Range Selector can be used to identify the beginning and the end of the selection by using other Selectors. In this way, two points can be accurately identified using the most appropriate selection mechanisms, and then linked together to form the selection. The selection consists of everything from the beginning of the starting selector through to the beginning of the ending selector, but not including it.
Example Use Case: Zara wants to comment on two adjacent cells in a table that is part of a web page. She selects the two cells and her client constructs XPaths to the the first cell, and the cell that immediately follows the second. Her client then creates a Range Selector with the first XPath Selector as the start, and the second XPath selector as the end.
Model
Term
Type
Description
type
Relationship
The class of the Selector. Range Selectors MUST have exactly 1 type and the value MUST be RangeSelector.
RangeSelector
Class
The type of the Range Selector resource.
Range Selectors MUST have this class associated with them.
startSelector
Relationship
The Selector which describes the inclusive starting point of the range.
There MUST be exactly 1 startSelector associated with a Range Selector.
endSelector
Relationship
The Selector which describes the exclusive ending point of the range.
There MUST be exactly 1 endSelector associated with a Range Selector. Both startSelector and endSelectorSHOULD be of the same class.
It may be easier, more reliable or more accurate to specify the segment of interest of a resource as a selection of a selection, rather than as a selection of the complete resource. Particularly for resources that contain other resources, such as various packaging formats, this also allows decomposition of the selection mechanisms when the components do not have unique identifiers. This is accomplished by having selectors chained together, where each refines the results of the previous one.
Example Use Case: Alexandra selects a paragraph of text and then a short phrase within it to comment on. Her client records the phrase as a TextQuoteSelector that further modifies a FragmentSelector used to identify the paragraph that the phrase is part of.
Model
Term
Type
Description
refinedBy
Relationship
The relationship between a broader selector and the more specific selector that SHOULD be applied to the results of the first.
A Selector MAY be refinedBy 1 or more other Selectors. If more than 1 is given, then they are considered to be alternatives that will result in the same selection.
Example
Example 29: Refinement of Selection
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno29",
"type": "Annotation",
"body": "http://example.org/comment1",
"target": {
"source": "http://example.org/page1",
"selector": {
"type": "FragmentSelector",
"value": "para5",
"refinedBy": {
"type": "TextQuoteSelector",
"exact": "Selected Text",
"prefix": "text before the ",
"suffix": " and text after it"
}
}
}
}
4.3 States
A State describes the intended state of a resource as applied to the particular Annotation, and thus provides the information needed to retrieve the correct representation of that resource. Web resources change over time, and a State might be used to describe how to recover the intended previous version. Web resources also have multiple formats, and a State might equally be used to describe how to retrieve that particular format. Multiple States may be given to describe the same representation in order to maximize the chances that the representation will be retrievable by the consuming user agent.
Example Use Case: Britney makes a comment about a web page that changes frequently. Her client records information to allow other clients to hopefully reconstruct the original target of the annotation.
Model
Term
Type
Description
state
Relationship
The relationship between the SpecificResource and the State.
There MAY be 0 or more state relationships for each SpecificResource. Multiple States SHOULD describe the same representation, however some States will not have the same precision as others. Consuming user agents MUST pick one of the described representations, if they are different.
States MUST be processed before processing Selector or Style information.
A Time State resource records the time at which the resource is appropriate for the Annotation, typically the time that the Annotation was created and/or a link to a persistent copy of the current version. The timestamp for the resource could be resolved via the Memento protocol, described in RFC 7089 [rfc7089].
Example Use Case: Carla makes a note about the current state of the front page of a news website, and flags that the page is likely to change often. Her client adds in a State with the current time to describe the version of the page being annotated.
Model
Term
Type
Description
type
Relationship
The class of the State. Time States MUST have exactly 1 type and the value MUST be TimeState.
TimeState
Class
A description of how to retrieve a representation of the Source resource that is temporally appropriate for the Annotation.
The State MUST have this class associated with it.
sourceDate
Property
The timestamp at which the Source resource SHOULD be interpreted for the Annotation.
There MAY be 0 or more sourceDate properties per TimeState. If there is more than 1, each gives an alternative timestamp at which the Source may be interpreted. The timestamp MUST be expressed in the xsd:dateTime format, and MUST use the UTC timezone expressed as "Z". If sourceDate is provided, then sourceDateStart and sourceDateEndMUST NOT be provided.
sourceDateStart
Property
The timestamp that begins the interval over which the Source resource SHOULD be interpreted for the Annotation.
There MAY be exactly 1 sourceDateStart property per TimeState. The timestamp MUST be expressed in the xsd:dateTime format, and MUST use the UTC timezone expressed as "Z". If sourceDateStart is provided then sourceDateEndMUST also be provided.
sourceDateEnd
Property
The timestamp that ends the interval over which the Source resource SHOULD be interpreted for the Annotation.
There MAY be exactly 1 sourceDateEnd property per TimeState. The timestamp MUST be expressed in the xsd:dateTime format, and MUST use the UTC timezone expressed as "Z". If sourceDateEnd is provided then sourceDateStartMUST also be provided.
cached
Relationship
A link to a copy of the Source resource's representation, appropriate for the Annotation.
There MAY be 0 or more cached relationships per TimeState. If there is more than 1, each gives an alternative copy of the representation.
As there are potentially many representations that can be delivered from a resource with a single IRI, and a Specific Resource may only apply to one of them, it is important to be able to record the HTTP Request headers that need to be sent to retrieve the correct representation. The HttpRequestState resource maintains a copy of the headers to be replayed when obtaining the representation.
Example Use Case: Devina retrieves a PDF representation of a web resource that can deliver HTML, PDF or plain text and then writes a description about it. She signals that her description is only about the PDF representation. Her client then includes a State to describe how to retrieve the target representation.
Model
Term
Type
Description
type
Relationship
The class of the State. Request Header States MUST have exactly 1 type and the value MUST be HttpRequestState.
HttpRequestState
Class
A description of how to retrieve an appropriate representation of the Source resource for the Annotation, based on the HTTP Request headers to send on the request.
The State MUST have this class associated with it.
value
Property
The HTTP request headers to send as a single, complete string.
An HttpRequestState MUST have exactly 1 value property.
Note
The representation retrieved from the server by the original annotator's client might not be completely determined by request headers alone. For example, the IP address of the client might also determine the language of the representation, based on the language of the country the user was present in at the time. If the server returns a Content-Location header, then the client might instead use it as the target of the Annotation, rather than the IRI that was requested.
Similar to the refinement of selection, it may be easier, more reliable or more accurate to specify the appropriate state of the resource as a hierarchy of atomic State resources. This is particularly appropriate for representing the combination of a State that reflects an internal transformation along with the results of a State that describes an external request. This decomposition is accomplished by having the states chained together in the same way as Selectors.
Further, given that the State(s) will likely result in a specific representation, there may be specific Selectors that are appropriate for describing the segment of the representation. In order to accommodate this, States may also be refined by Selectors.
Example Use Case: Erin writes a comment about a travel e-book which has many versions available over time, and is available in different formats. She is particularly commenting on a specific version and format, so her client adds both a TimeState to capture the time and an HttpRequestState to capture the format, and then a particular FragmentSelector that is appropriate to that format.
Model
Term
Type
Description
refinedBy
Relationship
The relationship between a broader State and either a more specific State or a Selector that SHOULD be applied to the results of the first.
Each State MAY be refinedBy 1 or more other States or Selectors. If more than 1 is given, then they are considered to be alternatives that will result in the same result.
The interpretation of a particular Annotation, or the Annotation's Body, may rely on the rendering style of the Annotation being consistent across implementations. For Annotations on binary content such as Images or Video, the background color of the Target may not be accessible to the annotation client, and the default coloring may be difficult to perceive, such as a black rectangle rendered as the target area on an image of the night sky. Rendering information is recorded using CSS stylesheets and references to classes defined in those stylesheets.
Example Use Case: Felicity highlights two paragraphs in a document, and selects in her client that one should be highlighted in red and the other in yellow. She then makes a comment that the yellow part contradicts the red part. Her client records that she selected the red and yellow coloration of the targets.
Model
Term
Type
Description
type
Relationship
The class of the Style. CSS Stylesheets MAY have a type and if included the value MUST be CssStylesheet.
CssStylesheet
Class
A resource which describes styles for resources participating in the Annotation using CSS.
The class MAY be associated with the stylesheet resource.
stylesheet
Relationship
The relationship between an Annotation and the Style.
There MAY be 0 or 1 stylesheet relationships for each Annotation.
styleClass
Property
The name of the class used in the CSS description that SHOULD be applied to the Specific Resource. There MAY be 0 or more styleClass properties on a Specific Resource.
The CSS Stylesheet is associated with the Annotation itself, and the content provides the rendering hints about the Annotation's constituent resources. It MAY have its own dereferenceable IRI that provides the information, or it may be embedded within the Annotation. This is to avoid having single line stylesheets each associated with different resources, and instead to allow reference to a single IRI that governs the full set of styles for a particular implementation.
Publishing systems MUST NOT assume that they will be processed; they are only provided as hints rather than requirements.
When rendering a Specific Resource, consuming applications SHOULD check to see if it has a styleClass property. If it does, then the application SHOULD attempt to locate the appropriate selector in the CSS document, and then apply the css-value block. If a Specific Resource has a styleClass value, but no such class is described by a stylesheet attached to the Annotation, then the styleClassMUST be ignored.
It may be valuable to know the software that was used to process and/or render the Target resource when the annotation was created. This information can be used by later systems to potentially recreate the environment to ensure that the annotation can be more easily and more accurately reconnected with the appropriate part of the Target's representation. This life cycle information is associated with the Specific Resource, as it is very likely to change between Annotations for the same Target, and thus cannot be associated with the Target resource directly.
Example Use Case: Gabrielle is using a browser based client to render a PDF of a scholarly article. Her browser uses a particular library to render the PDF as HTML. She annotates a paragraph in the view that she sees, the HTML rendering, and her client records that the library that was used for rendering in the annotation, along with her comment and the target PDF.
Model
Term
Type
Description
renderedVia
Relationship
The relationship between the Specific Resource that represents the Target in the annotation, and the piece of software or other system that was used to render the Target when the annotation was created.
There MAY be 0 or more renderedVia relationships for each Specific Resource.
Note
Other properties may be associated with the rendering system, including such things as schema:softwareVersion, accessibility functions, labels, references to the actual code, and so forth. These extensions are beyond the scope of this specification, but please see the Extensions section of [annotation-vocab].
It is sometimes important for an Annotation to capture the context in which it was made, in terms of the resources that the annotator was viewing or using at the time. This does not imply an assertion that the annotation is only valid for the image in the context of that page, it just records that the page was being viewed.
Example Use Case: Heather makes a comment about an image in a particular web page to say that it is not the right organization's logo. Her client includes the page that the image is being rendered in, however the annotation is associated with the image resource itself.
Model
Term
Type
Description
scope
Relationship
The relationship between a Specific Resource and the resource that provides the scope or context for it in this Annotation.
There MAY be 0 or more scope relationships for each Specific Resource.
It is often useful to be able to collect Annotations together into a list, called an Annotation Collection. This list, which is always ordered, serves as a means to refer to the Annotations that are contained within it, and to maintain any information about the Collection itself.
The Collection model is divided into two sections: the Annotation Collection that manages the identity of the list and its description, and Annotation Pages that list the Annotations which are members of the Collection.
Example Use Case: Ingeborg works for a publishing house and has transformed the author's commentary on their steampunk novel into a set of annotations for sale. The company wishes to have them available as an add-on for customers that have already bought the novel, and also in a bundle for new sales.
5.1 Annotation Collection
As Annotation Collections might get very large, the model distinguishes between the Collection itself and sequence of component pages that in turn list the Annotations. The Collection maintains information about itself, including creation or descriptive information to aid with discovery and understanding of the Collection, and also references to at least the first Page of Annotations. By starting with the first Annotation in the first Page, and traversing the Pages to the last Annotation of the last Page, all Annotations in the Collection will have been discovered.
Annotations MAY be within multiple Collections at the same time, and the Collection MAY be created or maintained by agents other than those that create or maintain the included Annotations.
Model
Term
Type
Description
@context
Property
The context that determines the meaning of the JSON as an Annotation Collection.
The Collection MUST have 1 or more @context values and http://www.w3.org/ns/anno.jsonldMUST be one of them.
id
Property
The identity of the Collection. The Collection MUST have exactly 1 IRI that identifies it.
type
Property
The type of the Collection. The Collection MUST have 1 or more types, and the AnnotationCollection class MUST be one of them.
AnnotationCollection
Class
The class for ordered Collections of Annotations. This class MUST be associated with the Collection using type.
label
Property
A human readable label intended as the name of the Collection. Collections SHOULD have 1 or more labels, and the value MUST be a string.
total
Property
The total number of Annotations in the Collection. Collections SHOULD have exactly 1 total, and if present it MUST be an xsd:nonNegativeInteger.
first
Relationship
The first page of Annotations that are included within the Collection. A Collection that has a total number of Annotations greater than 0 MUST have exactly 1 first page of Annotations. The first Page MAY be embedded within the representation of the Collection, or it MAY be given as an IRI.
last
Relationship
The last page of Annotations that are included within the Collection. A Collection that has a total number of Annotations greater than 0 SHOULD have a reference to the IRI of the last page of Annotations.
Other properties MAY be added to the Collection to describe its use, intellectual property rights, provenance and any other features that are considered useful. These properties SHOULD come from those described in this specification if possible, but MAY come from any appropriate vocabulary.
An Annotation Page is part of an Annotation Collection, and has an ordered list of some or all of the Annotations that are within the Collection. Each Collection may have multiple pages, and these are traversed by following the next and prev links between the pages.
Model
Term
Type
Description
@context
Property
The context that determines the meaning of the JSON as an Annotation Collection Page.
If the Page is NOT embedded within a Collection, it MUST have 1 or more @context values and http://www.w3.org/ns/anno.jsonldMUST be one of them. If it is embedded, then it SHOULD NOT have an @context property.
id
Property
The identity of the Page. The Page MUST have exactly 1 IRI that provides its identity.
type
Property
The type of the Page. The Page MUST have 1 or more types, and the AnnotationPage class MUST be one of them.
AnnotationPage
Class
The class of Annotation Pages. This class MUST be associated with the Page using type.
partOf
Relationship
The relationship between the Page and the Annotation Collection that it is part of. Each Page SHOULD have a exactly 1 partOf relationship, with the value being either the IRI of the Collection or an object with some or all of the Collections properties, including at least its id.
items
Relationship
The list of Annotations that are the members of the Page. Each Page MUST have an array of 1 or more Annotations as the value of items.
next
Relationship
A reference to the next Page in the sequence of pages that make up the Collection. If the current page is not the last page in the Collection, it MUST have a reference to the IRI of the page that follows it.
prev
Relationship
A reference to the previous Page in the sequence of pages that make up the Collection. If the current page is not the first page in the Collection, it SHOULD have a reference to the IRI of the page that it follows.
startIndex
Property
The relative position of the first Annotation in the items list, relative to the Annotation Collection. The first entry in the first page is considered to be entry 0. Each Page SHOULD have exactly 1 startIndex, and MUST NOT have more than 1. The value MUST be an xsd:nonNegativeInteger.
The table below shows the relationships among major media types and selector types. It is relevant to the 1.3Conformance section of this document.
Fragment
CSS
XPath
Text Quote
Text Position
Data Position
Svg
HTML (text/html)
✔︎
✔︎
✔︎
✔︎
✔︎
✘
✘
CSV (text/csv)
✔︎
✘
✘
✔︎
✔︎
✘
✘
Plain Text (text/plain)
✔︎
✘
✘
✔︎
✔︎
✘
✘
Other text files (text/*)
?
✘
✘
✔︎
✔︎
✘
✘
EPUB2, EPUB3 (application/epub+zip)
✔︎
✘
✘
✔︎
✘
✘
✘
PDF (application/pdf)
✔︎
✘
✘
✔︎
✔︎
✘
✘
XML (application/xml, application/*+xml)
✔︎
✔︎
✔︎
✔︎
✔︎
✘
✘
SVG (image/svg+xml)
✔︎
✔︎
✔︎
✔︎
✔︎
✘
✔︎
Image, other than SVG (image/gif, image/jpeg, image/png, image/tiff)
✔︎
✘
✘
✘
✘
?
✔︎
Video (video/*)
✔︎
✘
✘
✘
✘
?
✔︎
Binary Data Files
?
✘
✘
✘
✘
✔︎
✘
A.1 Additional Media Types/Selector Combination
This section is non-normative.
The table below contains some other, possible combinations of media types and selector types, which MAY be implemented but are not mandated by this specification. Some of these combinations may also form the basis for defining new, implementation-specific selector extensions.
Additional relationships among other media types and selector types
Fragment
CSS
XPath
Text Quote
Text Position
Data Position
Svg
CSS (text/css)
✘
✘
✘
✔︎
✔︎
✘
✘
TSV (text/tab-separated-values)
✔︎✝
✘
✘
✔︎
✔︎
✘
✘
RDF/Turtle (text/turtle)
✔︎✝
✘
✘
?
?
✘
✘
JSON (application/json, application/*+json)
✘
✘
✘
✔︎
?
✘
✘
Programming languages (application/javascript, python files, etc.)
✘
✘
✘
✔︎
?
✘
✘
✝Fragments are not formally defined through IETF, though there are well-known connections to existing fragments or practices
B. Complete Example
This section is non-normative.
Entirely Contrived Example Use Case: Juliet wants to associate a comment that she wrote in English within the annotation or an external mp3 of the same content in German by someone else, plus a tag, with a range of characters from a particular element in an XML representation of a document as it was at a certain point in time, and for it to be displayed in a particular way.
While it is possible to annotate multiple targets, the meaning of that annotation is that each Body applies independently to each of the Targets. This might not be the intent of the annotator, such as when all of the targets are required for the annotation to be correctly understood. In order to allow annotators to capture these requirements, a resource similar to Choice could be used, such as a Composite (unordered) or List (ordered).
The technical implementation of this pattern is not difficult, as it is practically identical to Choice, however the implementation of a user interface that can manage a human user's interactions such that the client can recognize the distinctions has proven to be very challenging. As such, the pattern is noted in this appendix for future consideration.
Example Use Case: Karin comments on a set of web pages as, together, providing evidence towards her research hypothesis. Her client creates a Composite, as there is no inherent order to the set of web pages.
Example Use Case: Lana tags a list of pages within a book as being important. As the pages have an order in the book, her client creates a List to maintain that order.
Example Use Case: Melanie annotates a set of images to classify them as portraits. As the classification applies to each image independently, her client creates a Independents resource to group them.
Proposed Model
Term
Type
Description
id
Property
The IRI that identifies the set.
The set resource MAY have exactly 1 IRI that identifies it.
type
Relationship
The type of the resource.
The set MUST have exactly 1 type class, taken from the options below.
Composite
Class
A set of resources, all of which are required for the Annotation to be correctly interpreted.
List
Class
An ordered list of resources, all of which are required in order for the Annotation to be correctly interpreted.
Independents
Class
A set of resources, each of which is being annotated separately with the same interpretation as having multiple bodies or targets directly associated with the Annotation.
items
Relationship
The list of resources in the Composite, List, or Independents.
Examples
Example 42: Composite
{
"@context": "http://www.w3.org/ns/anno.jsonld",
"id": "http://example.org/anno39",
"type": "Annotation",
"motivation": "commenting",
"body": {
"type": "TextualBody",
"value": "These pages together provide evidence of the conspiracy"
},
"target": {
"type": "Composite",
"items": [
"http://example.com/page1",
"http://example.org/page6",
"http://example.net/page4"
]
}
}
The Web Annotation Working Group gratefully acknowledges the contributions of the Open Annotation Community Group. The output of the Community Group was fundamental to the current data model. In particular the editors would like to thank Herbert Van de Sompel of Los Alamos National Laboratory for his editorial contributions throughout the Community Group process.
The following people have been instrumental in providing thoughts, feedback, reviews, content, criticism and input in the creation of this specification:
Vladimir Alexiev, Art Barstow, Tim Berners-Lee, Chris Birk, Dan Brickley, Sarven Capadisli, Paolo Ciccarese, Tim Cole, Ray Denenberg, TB Dinesh, Sergiu Gordea, Benjamin Goering, Amy Guy, Ivan Herman, Frederick Hirsch, Antoine Isaac, Jacob Jett, Takeshi Kanai, Gregg Kellogg, Andreas Kuckartz, Randall Leeds, Hugo Manguinhas, Shane McCarron, Ben De Meester, Luc Moreau, Addison Phillips, Davis Salisbury, Robert Sanderson, Felix Sasaki, Doug Schepers, Tzviya Siegman, Stian Soiland-Reyes, Manu Sporny, Nick Stenning, Jon Stroop, Lutz Suhrbier, Kyrce Swenson, Raphaël Troncy, Simeon Warner, Erik Wilde, Dan Whaley, Benjamin Young
F. Candidate Recommendation Exit Criteria
This section is non-normative.
For this specification to be advanced to Proposed Recommendation, there must be at least two independent implementations of each feature described below. Each feature may be implemented by a different set of products, and there is no requirement that any single product implement every feature.
Features
For the purposes of evaluating exit criteria, the following are considered as features:
The Annotation class and required properties.
The Agent class and required properties, as related to an Annotation.
The Agent class and required properties, as related to a resource used as the Body of an Annotation.
Embedded TextualBody class and required properties.
External web resources, used as the Body of an Annotation.
A Choice of resources, used as the Body of an Annotation.
The SpecificResource class and required properties, used as the Body of an Annotation.
External web resources, used as the Target of an Annotation.
The SpecificResource class and required properties, used as the Target of an Annotation.
The AnnotationCollection class and required properties.
The AnnotationPage class and required properties.
Software that does not alter its behavior in the presence or lack of a given feature is not deemed to implement that feature for the purposes of exiting the Candidate recommendation phase.
G. Changes from Previous Versions
This section is non-normative.
G.1 Changes from the Proposed Recommendation of 2017-01-17
No significant changes.
G.2 Changes from the Candidate Recommendation of 2016-11-22
Removed unnecessary appendix
Updated SVG reference to 1.1
G.3 Changes from the Candidate Recommendation of 2016-09-06
Move Composite, List and Independents classes to an informative appendix. (These classes were marked as "at Risk" in earlier versions.)
Remove the use of Choice with Targets, and associating Agents with Targets.
Clarify the possibility of embedding Collection information in a Page using partOf.
Improve description of multiple rights statements about resources.
Improve description of textDirection and note that value definitions are explicitly from HTML5, as well as the property.
Link to the media type in protocol from the introduction.
Clarified that processingLanguage should also have a BCP47 formatted value.
Clarified that TextualBody can be the source of a Specific Resource, and the target of an Annotation.
Add informative principle that features of externally referenced resources described in an Annotation are not intended to be authoritative, and the remote resource is the source of truth about itself.
Clarified the scope of the purpose property with respect to TextualBody resources.
G.4 Changes from the Candidate Recommendation of 2016-07-05